
Importanța rețelei semantice pentru SEO: crearea de rețele de conținut semantic cu șabloane de interogări și documente – studiu de caz
Publicat: 2022-01-11O rețea semantică este conectată la conceptul de bază de cunoștințe care poate reprezenta informații din lumea reală pentru lucruri care au conexiuni relaționale. O bază de cunoștințe poate avea mii de tipuri de relații cu miliarde de entități și trilioane de fapte. O rețea semantică poate fi creată din orice existență din lumea reală cu caracteristici reciproce, cum ar fi greutatea, dimensiunea, tipul, mirosul sau culoarea. Relația dintre Rețelele Semantice și Web-ul Semantic este creată de motoarele de căutare semantice și optimizare.
Rețelele semantice sunt utilizate în analiza semantică, dezambiguarea sensului cuvântului, crearea WordNet, teoria graficelor, procesarea limbajului natural, înțelegerea și generarea. Perspectiva unei rețele semantice poate fi utilizată în cadrul Optimizării semantice pentru motoarele de căutare prin furnizarea unei rețele de conținut semantic.
În acest studiu de caz SEO, două site-uri web diferite cu două metode diferite cu aceeași perspectivă vor fi explicate pe baza șabloanelor de interogare, document, intenție și perechile entitate-atribut din spatele lor.
Folosind o înțelegere a modului în care motoarele de căutare reprezintă cunoștințele și modul în care își extind reprezentarea cunoștințelor, sunt capabil să o folosesc pentru a produce rezultate incredibile de clasare. Odată ce înțelegeți conceptele de bază, vă voi explica cum le-am aplicat pe cele două site-uri diferite, apoi voi detalia metodele pe care le-am folosit.
Cum vă pot ajuta rețelele semantice clasarea site-ului dvs.?
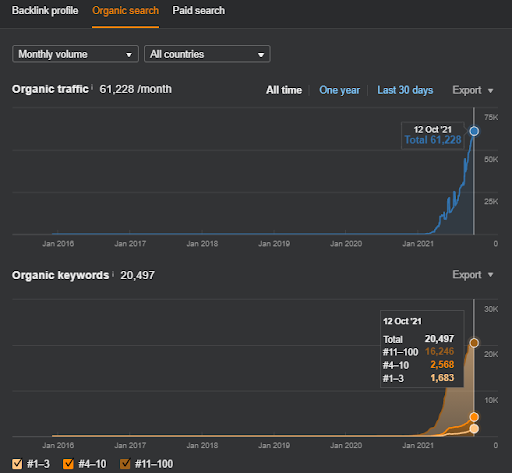
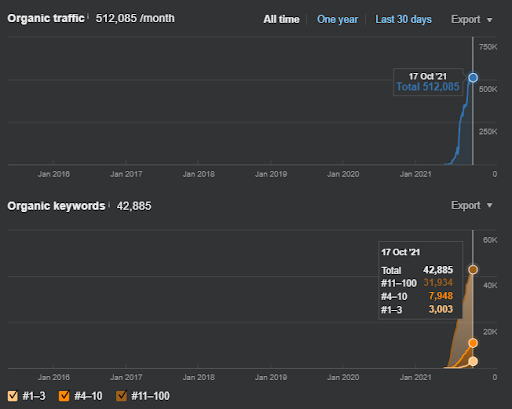
Mai jos, veți găsi rezultatele brute generale pentru Proiectul I.
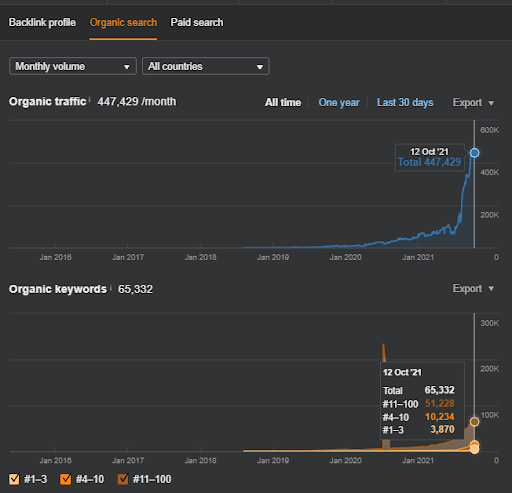
Rezultate pentru Project One care este IstanbulBogaziciEnstitu.com. Pentru a demonstra că „Rețelele semantice” pot fi folosite pentru SEO cu șabloane de interogări și documente, voi demonstra două rețele de conținut diferite din Project One. Project One va avea rezultate mult mai bune în viitorul apropiat datorită Rețelei de conținut Semantic Two. Clientul va fi responsabil pentru lansarea acestei a doua rețele, dar voi explica și logica acesteia.
17 zile mai târziu, iată progresul înregistrat la Proiectul I: 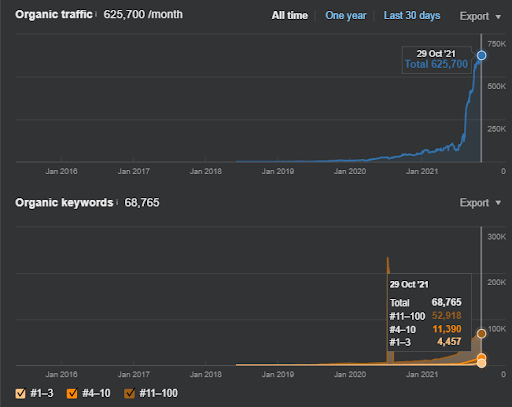
17 zile mai târziu, procesul de re-clasificare a Rețelei de conținut semantic este mai clar.
Conceptele rețelei de conținut semantic ne ajută să înțelegem valoarea interogării, intenției de căutare, comportamentului și șabloanele de documente pentru entitățile de același tip. În acest studiu de caz SEO centrat pe rețeaua semantică, anterior Autoritatea topică și Studiul de caz semantic SEO vor fi aprofundate prin intermediul celor două noi site-uri web care utilizează rețele de conținut create semantic în jurul acelorași tipuri de entități.
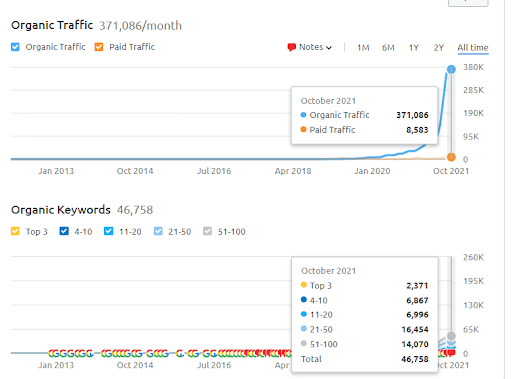
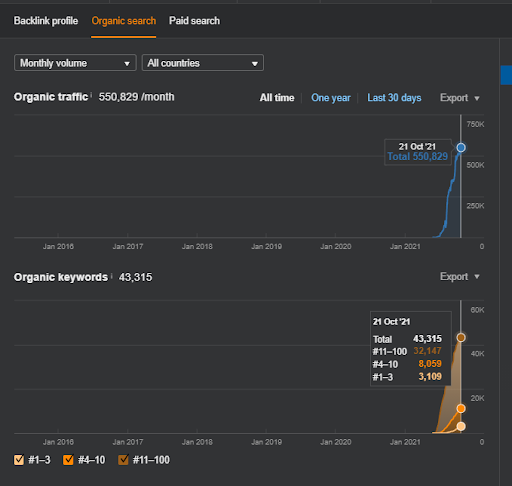
Acesta este graficul SEMRush a Primului Proiect. De asemenea, trebuie să menționez că acest site a pierdut Actualizarea Algoritmului Broad Core din iunie, dacă nu și-ar pierde „Rankability”, rezultatele ar fi mai bune. Pentru următoarea actualizare a algoritmului Broad Core, cu o autoritate topică, acoperire și date istorice mai bune, poate recupera cu ușurință „Rankability”.
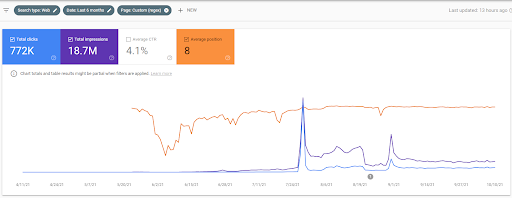
Numele celui de-al doilea proiect este Vizem.net. Spre deosebire de Project One, puteți vedea că Vizem.net are o creștere mai lentă, dar constantă. Se datorează faptului că folosesc rețelele de conținut semantic cu perspective ușor diferite. Mai jos, puteți vedea rezultatele Ahrefs ale celui de-al doilea proiect.
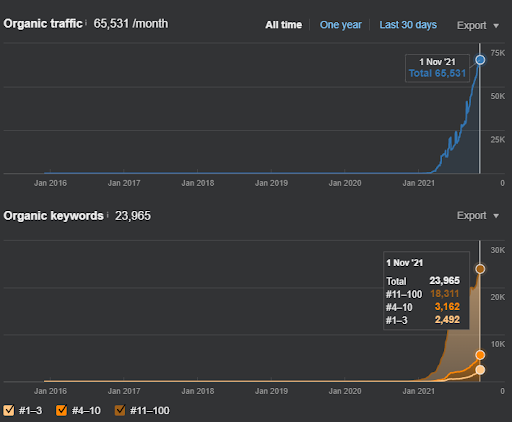
Rezultatele celui de-al Doilea Proiect reprezintă un „Proces lent de re-clasificare” prin îmbunătățirea gradată a Acoperirii Topice și a Autorității. Termenii „Re-clasificare” și „Clasare inițială” vor fi explicați după conceptele legate de Rețelele de Conținut Semantic. Dacă îți dai seama de „stabilitatea” din cadrul graficii, este pentru că am încetat să mai public conținut nou în sursă. Și afectează procesul de re-clasificare, așa cum vă dați seama din contorizarea celor mai importante 3 numere de interogări. Relațiile „Momentum” și „Re-clasificare” pot fi găsite după explicațiile conceptelor fundamentale.
Mai jos, puteți găsi rezultatele SEMRush ale Vizem.net.
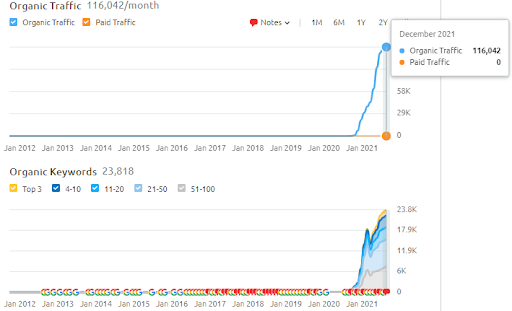
Traficul real al acestui site web este de 3 ori mai mare decât numărul indicat în SEMRush. Puteți realiza aceeași „stabilitate” și conceptele de „impuls” și în cadrul acestor grafice.
În timp ce scriam Studiul de caz pentru autoritatea topică SEO, i-am mulțumit lui Bill Slawski că mi-a educat perspectiva. O repet și pentru Studiul de caz SEO al rețelei de conținut semantic. Pentru a înțelege conceptele „Re-clasificare” și „Clasare inițială”, ar trebui citit „Moduri în care motoarele de căutare pot reclasifica rezultatele căutării”.
Pe 18 martie 2021, Oncrawl, RankSense și Holistic SEO & Digital au publicat un webinar Python SEO și Data Science. În cadrul webinarului, SERP a fost înregistrat pentru a anima diferențele de rezultate. Se poate observa că motorul de căutare schimbă clasamentele anumitor surse cu altele cu o frecvență similară.
Înainte de a continua, știu că acesta este un articol lung. Dar, de fapt, aceasta este o scurtă explicație a unei metodologii SEO extrem de complexe. Rețelele de conținut semantic necesită prea multă gândire în timpul proiectării lor și luni de educație pentru clienți, autori și odată cu integrarea. Astfel, în acest articol, vreau să mă concentrez pe definițiile conceptelor cu cele mai bune sugestii scurte executabile și brevete importante Google și ale altor motoare de căutare, lucrări de cercetare împreună cu propriile concepte. În versiunea lungă (practic, o carte), m-am concentrat pe „clasificarea inițială” și „re-clasificarea” rețelelor de conținut semantic.
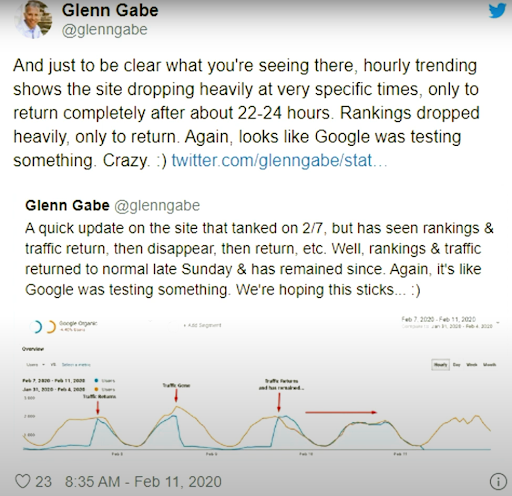
Din 11 februarie 2020, Glenn Gabe are un bun exemplu pentru metodologia de re-clasificare și testare vizuală a motoarelor de căutare.
Dacă doriți să aflați mai multe, citiți „Importanța clasamentului inițial și a re-clasării pentru SEO”.
Pentru a se scufunda adânc în datele din lumea reală pentru Studiul de caz SEO, conceptele pentru înțelegerea Rețelei de conținut semantic ar trebui procesate cu o perspectivă de înțelegere-comunicare a motorului de căutare.
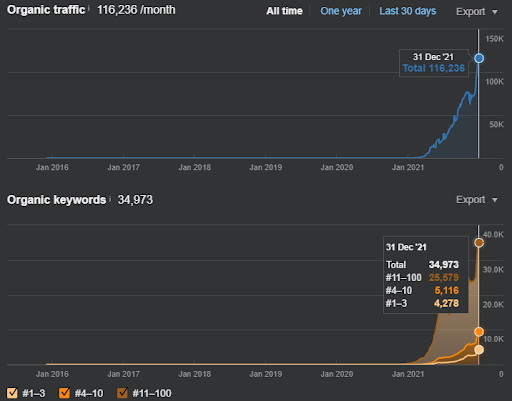
Ca exemplu de re-clasificare a Vizem.net, situația actualizată poate fi văzută mai sus. În secțiunile viitoare ale Studiului de caz SEO, vor exista mai multe explicații pentru algoritmii de re-clasificare ai Google pentru SEO.
Ce este o rețea semantică?
O rețea semantică poate fi utilizată pentru conectarea și analiza internetului lucrurilor. Poate fi benefică pentru recunoașterea potențialilor cumpărători de pe piața tehnologiei sau doar analiza co-cuvântului pentru crearea și gruparea de rețele de cuvinte cheie. O rețea semantică poate fi folosită pentru a susține navigarea și a dezvălui structura relațiilor sau importanța relativă a unui lucru față de altul. Rețeaua semantică are componentele de mai jos:
- Semantică lexicală: înțelegerea ce cuvânt și concept sunt legate de care altele, cu ce diferențe.
- Componentă structurală: înțelegerea nodului care este conectat la ce margine cu ce informații.
- Componenta semantică: Definirea faptelor.
- Parte procedurală: Ajută la crearea de conexiuni suplimentare între componente.
Deoarece rețelele semantice sunt multifuncționale, algoritmii NLP pot fi utilizați și în scopuri foarte diverse, cum ar fi pentru a ajuta la identificarea problemelor complicate de sănătate. Aceeași structură de rețea semantică poate fi implementată în mai multe alte zone, atâta timp cât aceste alte zone au o relație semantică între ele.
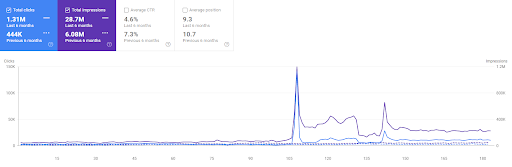
Comparația din ultimele 6 luni a Primului Proiect.
Ce este o bază de cunoștințe?
O bază de cunoștințe este o bibliotecă de informații cu clasificare într-o formă care poate fi citită de mașină. O bază de cunoștințe poate fi folosită ca o enciclopedie care poate fi restrânsă și aprofundată pe baza interogării. O bază de cunoștințe poate fi formată pe baza propozițiilor, extragerea faptelor și extragerea informațiilor. Relația dintre o rețea semantică și o bază de cunoștințe este că tot ceea ce este în rețeaua semantică va fi plasat în baza de cunoștințe în timp ce se extrag faptele.
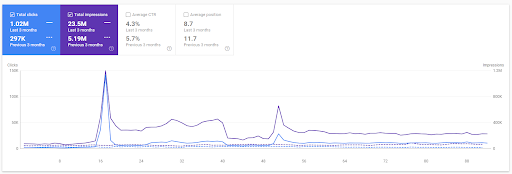
Comparația din ultimele 3 luni a Primului Proiect
Ce este o rețea de conținut semantic?
Rețeaua de conținut semantică reprezintă o rețea de conținut care a fost pregătită pe baza componentelor și înțelegerii rețelei semantice. O rețea de conținut semantic poate include mai multe atribute de la o entitate sau entități din același grup pentru a oferi o bază de cunoștințe cu mai multe detalii.
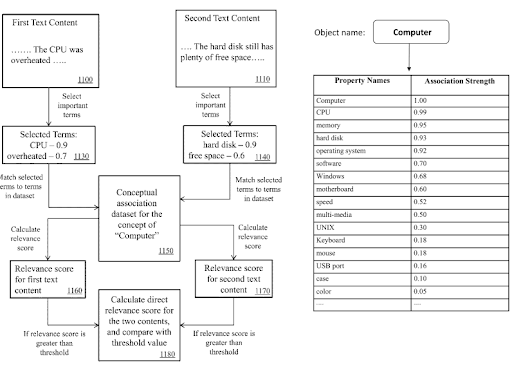
În cadrul unei rețele de conținut semantic, termenii domeniului de cunoaștere și triplele pot fi utilizați pentru a semnala scopul principal al unui document și posibilele părți de conținut de vecinătate.
Un motor de căutare își poate compara propria bază de cunoștințe cu baza de cunoștințe care poate fi generată din conținutul unui site web. Dacă site-ul web are un nivel ridicat de acuratețe și exhaustivitate pentru diferite straturi contextuale, motorul de căutare își poate îmbunătăți propria bază de cunoștințe din conținutul site-ului. Dacă un motor de căutare își îmbunătățește și își extinde propria bază de cunoștințe dintr-o altă sursă de pe web deschis, este un semnal al unei încrederi bazate pe cunoștințe de nivel înalt.
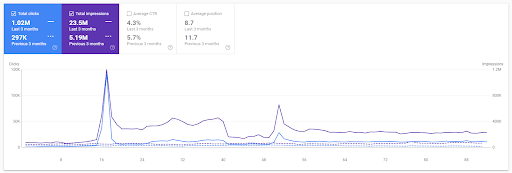
Comparație an peste an pentru ultimele 3 luni pe baza primului proiect.
Ce este încrederea bazată pe cunoștințe?
Încrederea bazată pe cunoștințe se concentrează pe web deschisă bazată pe „acuratețea informațiilor”, nu pe „PageRank”. Este un algoritm similar cu RankMerge. Încrederea bazată pe cunoștințe implică tripleți, extragerea faptelor, verificarea acurateții și înțelegerea textului prin eliminarea ambiguității textului. Încrederea bazată pe cunoștințe poate fi dobândită prin furnizarea de rețele de conținut semantic care au componentele puternic conectate din articol, bazate pe straturi contextuale diferite, dar relevante.
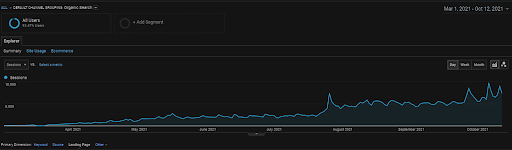
Sesiunea organică a Vizem.net din GA pentru ultimele 6 luni.
Mai jos, veți vedea un exemplu de prezentare de încredere bazată pe cunoștințe de la Luna Dong. Acesta arată cum un motor de căutare se poate concentra pe „factorii de clasare interni” în loc de factorii de clasare exogeni. Acesta explică faptul că un PageRank ridicat nu poate reprezenta calitate și acuratețe înaltă pentru conținut în sine. Deci, a avea un KBT (Knowledge-based Trust) este important.
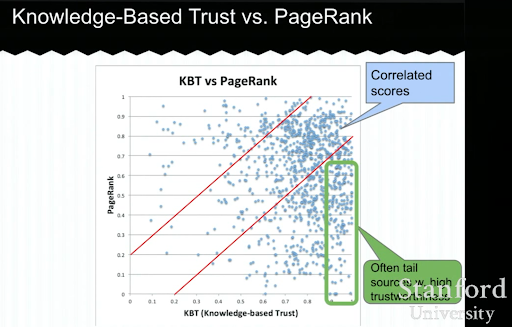
Mulțumesc mult lui Arnout Hellemans care mi-a împărtășit această prelegere educațională în timpul unui chat privat SEO. Dacă doriți să aflați mai multe despre încrederea bazată pe cunoștințe: Seminarul Stanford – Seif de cunoștințe și încredere bazată pe cunoștințe
Ce este Acoperirea contextuală?
Acoperirea contextuală și Acoperirea topică nu sunt la fel ca domeniul de cunoaștere și domeniul contextual nu sunt la fel. O acoperire contextuală reprezintă unghiurile de procesare ale unui concept. Un concept poate fi procesat pe baza punctelor sale reciproce față de celelalte lucruri. De exemplu, dacă entitatea este o țară, poziția sa față de criza de mediu poate fi procesată. Dacă alte țări sunt procesate din același unghi, înseamnă că acoperim un domeniu contextual.

Motorul de căutare Google își construiește lucrările de cercetare și brevetele în timp. Citatul din dreapta din secțiunea de mai sus este un atribut al „vectorilor de context”, în timp ce secțiunea din stânga este un atribut al „taxonomiei frazei”. Lucrul interesant este că, chiar și exemplul este același, care este „camera digitală”.
Detaliile și subpărțile aprofundate ale acestor combinații reprezintă straturile contextuale dintr-un domeniu contextual. Fiecare entitate, indiferent dacă este numită sau nu, are multe domenii contextuale. Astfel, Google extrage mai multe domenii contextuale și utilizatorii caută interogări mai lungi în fiecare an. Când procesarea limbajului natural și înțelegerea limbajului natural sunt dezvoltate, interogările și documentele se extind împreună în termeni de detaliu și context.
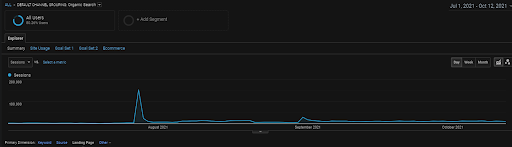
Grafica GA Organic Sessions pentru ultimele 4 luni ale Proiectului BogaziciEnstitu. Datorită „Etapei de obținere a datelor istorice” a proiectului, detaliile crescute nu sunt clare pentru a fi văzute ca fiind liniare.
O acoperire contextuală poate fi înțeleasă prin „calificatorii de context”. Un calificativ de context poate fi un adjectiv, adverbial sau orice altă prepoziție, cum ar fi fraze care încep cu „pentru, în, la, în timpul, în timp ce”. Întrebările legate de entitate de mai jos nu sunt aceleași în ceea ce privește domeniul contextual:
- Care sunt cele mai utile fructe pentru copiii cu insomnie?
- Care sunt cele mai utile fructe pentru copiii cu anxietate?
Întrebările legate de entitate de mai jos nu sunt aceleași în ceea ce privește stratul contextual:
- Care sunt cele mai utile fructe pentru copiii cu insomnie severa peste 6 ani?
- Care sunt cele mai utile fructe pentru copiii cu un nivel scăzut de anxietate sub 6 ani?
Întrebările legate de entități de mai jos nu sunt aceleași în ceea ce privește domeniile de cunoaștere:
- Care sunt cele mai utile cărți pentru copiii cu insomnie severă peste 6 ani?
- Care sunt cele mai utile jocuri pentru copiii cu anxietate scăzută sub 6 ani?
Dar toate aceste întrebări pot fi în aceeași rețea de conținut semantic, deoarece toate sunt aproximativ același „concept” și „zonă de interes” cu activitate de căutare similară și activitate din lumea reală legată de căutare.
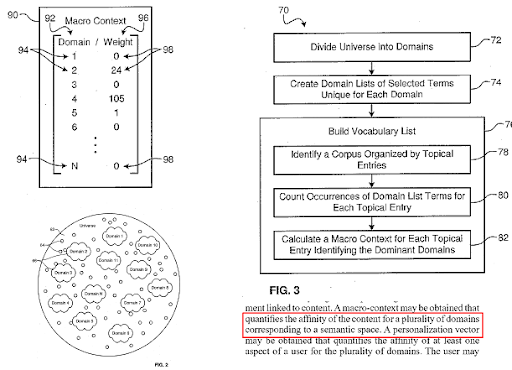
Un motor de căutare împarte web-ul în diferite domenii de cunoștințe și calculează scorurile macro și micro contextului pentru o sursă, o pagină web și o secțiune de pagină web în același timp.
Știu că am o mulțime de concepte noi pentru tine și, deoarece aceasta este versiunea pe scurt a acestui articol, nu voi putea vorbi despre totul aici, dar într-un viitor Curs SEO semantic voi procesa aceste lucruri precum diferența dintre „activitate de căutare” și „activitate din lumea reală legată de căutare”.
Să continuăm puțin la lucrurile mai concrete.
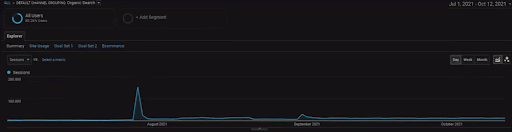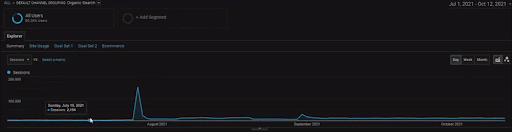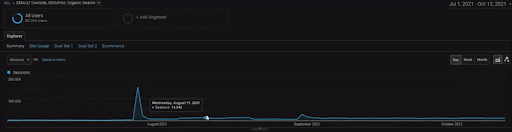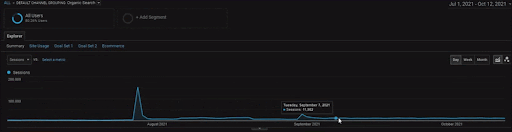
Pentru a afișa detaliile Proiectului BogaziciEnstitu, puteți verifica versiunea cu imagine interactivă. Procesul de testare și re-clasificare a motoarelor de căutare este mai clar pe acest proiect după evenimentul sursei de date istorice.
Cum este MuM legat de rețelele de conținut semantic?
Multitask Learning with a Unified Transformer sau Multitask Unified Model antrenează modele lingvistice pentru a evalua intrările vizuale, precum și textul. Este capabil să genereze text împreună cu înțelegerea. În plus, MuM este independent de limbă, cu alte cuvinte, SEO semantic depinde de abilitățile lingvistice, dar nu este limitat la o limbă. Deoarece entitățile nu au un limbaj și sensul este universal, MuM folosește informațiile din mai multe limbi și mai multe contexte într-o singură bază de cunoștințe.
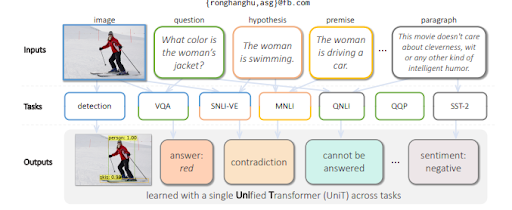
Pentru a răspunde la întrebări dintr-o imagine, MuM generează întrebări bazate pe obiectele detectate dintr-o imagine. În viitorul apropiat, vor putea fi generate și întrebări legate de audio și video.
MuM folosește diferite domenii pentru detectarea obiectelor și înțelegerea limbajului natural cu o structură de encoder-decodor transformator. Fiecare intrare vine dintr-o zonă diferită a web-ului deschis, în timp ce toate sunt evaluate de la un singur decodor partajat. Mai jos, veți putea vedea un alt exemplu din lucrarea de cercetare.
Ca o notă, MuM poate fi de 1000 de ori mai puternic decât BERT, dar BERT este încă folosit în Text Encoder al MuM. Principalul avantaj al MuM este că poate fi folosit pentru imagini și audio direct, motiv pentru care poate fi numit model „multitask”. Al doilea avantaj este că înlătură direct toate barierele lingvistice. Al treilea avantaj este că este capabil să conecteze totul la alt lucru fără a fi nevoie de intermediari suplimentari. Al patrulea avantaj este că MuM poate genera și text, spre deosebire de BERT.
Legătura dintre MuM, baza de cunoștințe, rețele semantice și acoperire contextuală este că motorul de căutare este capabil să găsească mult mai mult domeniu contextual prin intermediul calificatorilor de context și combinațiile acestora cu posibilele domenii de cunoștințe. Astfel, o rețea de conținut semantic bine structurată, care este modelată cu o hartă topică și un context sursă adecvat, poate îmbunătăți încrederea în baza de cunoștințe, împreună cu autoritatea topică.
Care este contextul sursei?
Contextul sursei reprezintă două lucruri. Internetul de căutare centrală a sursei și activitatea de căutare centrală care se poate face cu activitatea de căutare aferentă. Pentru un site de comerț electronic, contextul sursă este achiziționarea unui anumit produs sau a unui anumit tip de produs. Dacă este un site de călătorie, contextul sursei merge undeva din alt loc pentru diferite tipuri de alimente, peisaje sau doar afaceri. Pe baza contextului sursei, designul rețelei de conținut semantic și harta topică vor trebui configurate în continuare. Acest lucru necesită alegerea secțiunilor centrale din harta topică și a secțiunilor suplimentare din cadrul hărții topice.
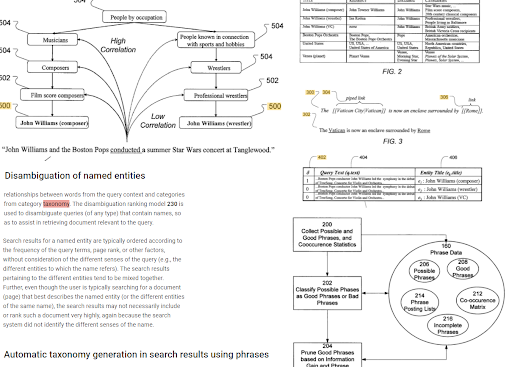
Indexarea bazată pe fraze și înțelegerea căutării orientate către entitate sunt conectate între ele pe baza semanticii. Mai sus, „Dezambiguizarea entității numite” și „Generarea automată a taxonomiei în rezultatele căutării folosind expresii” pot fi văzute împreună pentru a determina „contextul”. Frazele bune și informațiile unice, dar corelate pentru un subiect vor ajuta la o mai bună re-clasificare inițială.
Din nou, unele dintre aceste concepte, „configurarea hărții de actualitate”, „designul rețelei de conținut semantic” nu au fost încă definite, iar acesta nu este locul potrivit pentru asta. Dar, activitatea de căutare aferentă a fost explicată împreună cu intenția de căutare canonică și expresii reprezentative pentru aceste intenții de căutare canonice.
Contextul studiului de caz SEO centrat pe rețeaua semantică
Pe baza conceptelor de mai sus, am folosit rețelele semantice pentru a crea un studiu de caz SEO. Ne vom uita la cele două proiecte de site web pe care le-am menționat la începutul acestui articol și vom examina rezultatele și modul în care am implementat rețelele semantice pentru a le produce.
Pentru a vă face o idee despre cât de puternice pot fi aceste rețele, rezultatele legate de SEO pentru Studiul de caz SEO centrat pe rețeaua semantică sunt enumerate mai jos.
- Înțelegerea rețelei semantice este o necesitate pentru a crea o hartă topică adecvată.
- Pentru ambele proiecte, SEO tehnic nu este utilizat pentru a izola efectele SEO semantic.
- Optimizarea vitezei paginii nu este utilizată, din același motiv.
- Designul și optimizarea WUX (Website User Experience) nu sunt utilizate.
- Backlink-urile (Referințe externe și fluxul PageRank) nu sunt utilizate.
- Ambele mărci nu au date istorice. Vizem.net este complet nou, BogaziciEnstitusu are o istorie mai veche dar era mai mică decât firma actuală.
- SEO OnPage sau alte verticale ale SEO nu sunt utilizate.
- Ambele mărci au un server mai bun decât exemplul anterior al studiului de caz Topical Authority.
Acest studiu de caz SEO centrat pe rețeaua semantică îi va ajuta pe cei care doresc să-și îmbunătățească perspectiva SEO semantică cu două metodologii și concepte diferite care se concentrează pe două site-uri web diferite.
Proiectul doi: Vizem.net se concentrează pe Procesul de solicitare a vizei. Înainte de a scrie, de a publica sau chiar de a lansa aceste proiecte, le-am arătat de multe ori ambele site-uri web celorlalți clienți sau parteneri ai mei. Și, Vizem.net și-a început călătoria „Autoritate actuală” recent.
SEO bazat pe Studiul de caz de rețele semantice a fost scris în două versiuni diferite. Dacă doriți să citiți toate brevetele aferente, lucrările de cercetare și examinările profund detaliate, interpretările din punct de vedere al motorului de căutare, în timp ce înțelegeți mai departe arborele de decizie ai motoarelor de căutare, puteți citi Importanța clasării inițiale și a re-clasării SEO. Studiu de caz articol care are mai mult de 30.000 de cuvinte. Dacă nu aveți suficiente cunoștințe teoretice pentru SEO și antecedentele istorice, puteți continua să citiți rezumatul executiv.
Mai jos, puteți vedea graficul al doilea proiect (Vizem.net) de la SEMRush.
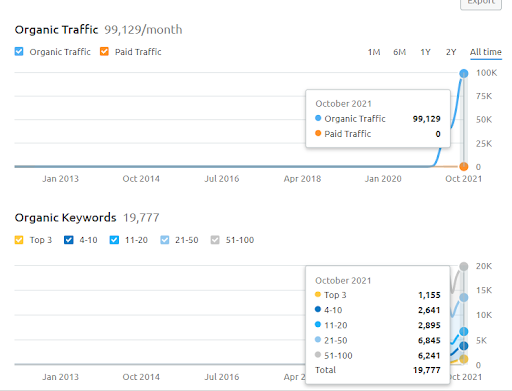
Grafica SEMRush a celui de-al doilea site web. Vizem.net este o sursă complet nouă, care vizează industriile cu un nivel înalt de concurenți înrădăcinați, cum ar fi „Aplicația Visa”. Mai ales, datorită celor mai recente evenimente din Turcia, nivelul concurenței industriei este în creștere. Astfel, utilizarea perspectivei Rețelei semantice pentru crearea unei rețele de conținut este utilă.
Primul proiect: Istanbul Bogazici Enstitusu: Creștere de 600% clic organic în 3 luni – Date istorice valorificate și clasament inițial
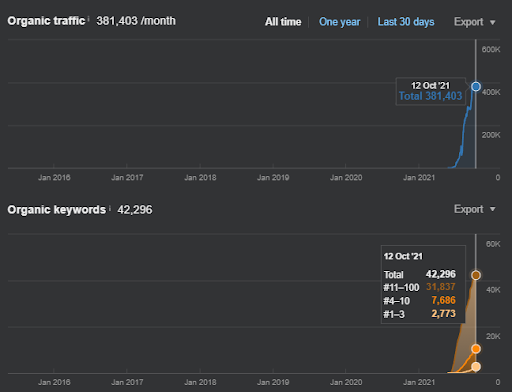
IstanbulBogazici Enstitusu este unul dintre cele mai grele studii de caz SEO pe care le-am efectuat, nu din cauza motoarelor de căutare, ci din cauza oamenilor și a problemelor mele de sănătate. Astfel, am părăsit proiectul și nu am publicat a treia rețea de conținut semantic care este concepută pentru a completa relațiile semantice bazate pe contextul sursei. Chiar dacă nu are termeni din domeniul cunoștințelor și fraze contextuale implementate corespunzător, este configurat cu suficiente niveluri de conexiuni semantice și acuratețe, pentru a permite o performanță generală de căutare organică de peste trei milioane de sesiuni pe lună dacă a treia rețea de conținut este publicat în viitor, ținând cont și de efectul crescând al celei de-a doua rețele de conținut semantic.
Mai jos, veți vedea grafica în schimbare a IstanbulBogazici Enstitusu pe GSC în ultimele 12 luni. Proiectul a fost lansat în mai 2021 într-un mod adecvat și s-a încheiat în septembrie 2021 prin publicarea a două rețele de conținut semantic.
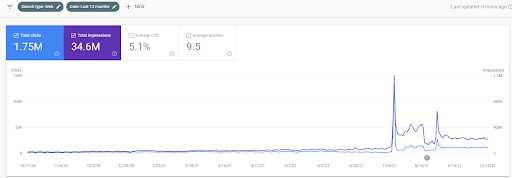
Mai jos puteți vedea versiunea mai detaliată. De la 1400 de clicuri zilnice la 140000 de clicuri, apoi peste 10.000 de clicuri obișnuite pe zi pot fi observate în cadrul performanței Căutării organice
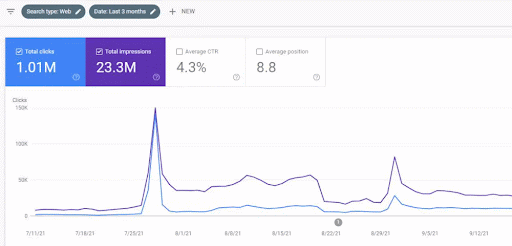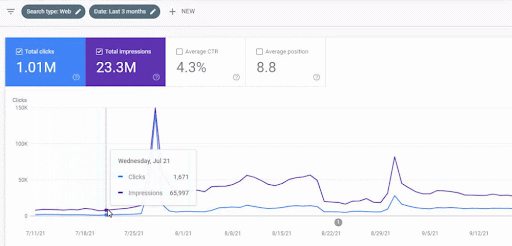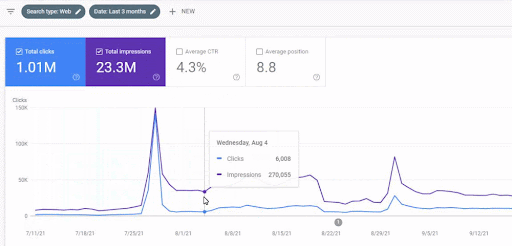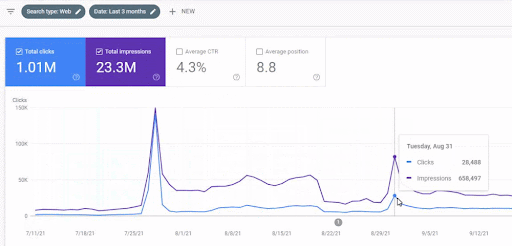
Creșterea traficului primei rețele de conținut după lansare poate fi văzută mai jos.
Această captură de ecran arată a 4-a lună a primei rețele de conținut semantic.
După cum puteți vedea din grafic, traficul general al întregului site a fost dominat și afectat de Prima Rețea de Conținut Semantic, care se concentrează pe „ramurile educaționale”. A doua rețea de conținut pe care am lansat-o cu acest site web poate fi văzută mai jos din Google Search Console. Captura de ecran de mai jos este din a 16-a zi a celei de-a doua rețele de conținut semantic.
Clasamentul inițial și re-clasificarea au fost utilizate în cadrul articolului deoarece definesc fazele algoritmilor de clasare împreună cu tipurile și scopurile acestora înainte de a testa o sursă și o pagină web din sursă în cadrul SERP pentru interogări mai importante care au o popularitate. .
Pe ce se concentrează prima rețea de conținut semantic a primului proiect?
„Rețeaua de conținut semantică” folosește o rețea semantică dintr-o bază de cunoștințe pentru a explica relațiile principale, secundare și terțiare dintre lucrurile din baza de cunoștințe. Astfel, crearea unei rețele de conținut semantic necesită proiectarea următoarei rețele de conținut semantic pe baza contextului sursei, care este funcția principală a site-ului. În acest context, prima rețea de conținut semantic s-a concentrat pe „catedrele universitare, ramurile educaționale și necesitățile unui învățământ universitar într-o anumită organizație și ramură”.
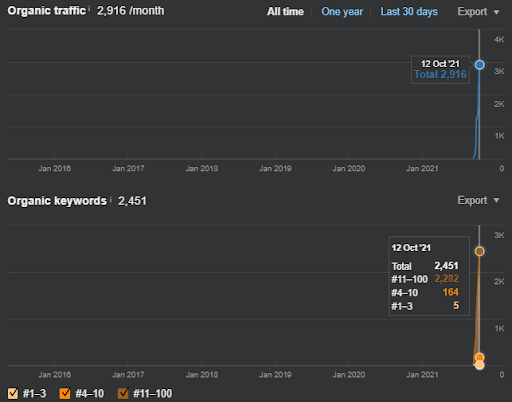
Mai jos, veți găsi graficul Ahrefs al First Semantic Content Network.
Acesta este cinci zile mai târziu de la captura de ecran anterioară.
„Root: istanbulbogazicienstitu.com/bolum”, după prima fază de clasare inițială, procesul de reclasare este mai eficient și mai productiv.
Puteți vedea versiunea cu patru zile mai jos, pentru a susține natura „reclasării”.
Pe ce se concentrează a doua rețea de conținut semantic a primului proiect?
A doua rețea de conținut semantic sa concentrat pe ocupații, locuri de muncă, abilități și educație necesară pentru aceste abilități sau rutină. Pe baza primei rețele de conținut semantic, a fost acceptată a doua rețea de conținut semantic. Și, conform „șabloane de interogare-șabloane de intenție”, încă două rețele semantice diferite de subconținut sunt create și plasate cu „conexiunile relaționale” în timp ce sunt conectate la nivelurile ierarhice superioare similare.
Știu că aceste secțiuni sunt complicate pentru tine pentru că nu ai văzut încă o definiție pentru lucrurile de mai jos.
- Rețeaua de conținut semantic
- Contextul sursei
- Rețeaua semantică de subconținut
- Bază de cunoștințe
- Conexiuni relaționale
- Clasamentul inițial
- Reclasificare
- Acoperire contextuală
- Clasamentul de comparație
- Extragerea faptelor
După explicarea celui de-al doilea site web, va fi mai ușor de înțeles aceste concepte și propoziții.
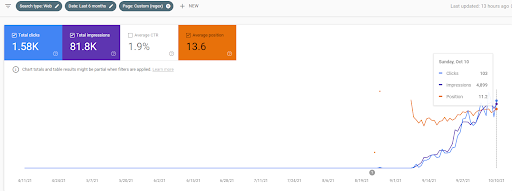
Vizem.net: de la 0 la 9.000+ de clicuri zilnice pe zi în 6 luni – Clasare comparativă valorificată cu acoperire contextuală
Puteți vedea graficul Vizem.net pentru ultimele 12 luni. Pentru acest proiect, din cauza Covid-19, am avut o mulțime de probleme economice, deoarece investitorul este din industria sălii de sport. Astfel, pot spune că problemele economice au încetinit proiectul și au cauzat o oarecare latență pentru „procesele de re-clasificare”.
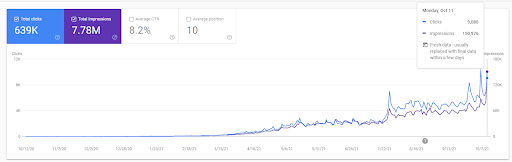
Pentru a înțelege clasamentul inițial și re-clasificarea puțin mai departe, puteți folosi graficul de mai jos.
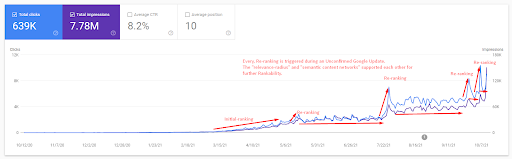
Unele dintre definițiile legate de clasamentul inițial și reclasamentul din graficul de mai sus pot fi găsite mai jos.
- Marile salturi de clasament au avut loc în timpul actualizărilor Google neconfirmate. Unele teste au oferit câteva fragmente recomandate, iar oamenii au pus și întrebări.
- Unele teste de la Google au eliminat veniturile FS și PAA.
- De fiecare dată, intervalul de timp dintre două procese de re-clasificare a fost mai scurt.
- Procesele de re-clasificare au îmbunătățit de fiecare dată Rankability a sursei.
- Sursa și-a îmbunătățit întotdeauna raza de relevanță în timp ce extindea clusterele de interogări.
Ca doar o notă, pot lăsa o propoziție mai jos.
Dacă un motor de căutare indexează pagina dvs. web, aceasta nu înseamnă că motorul de căutare a înțeles pagina web. Indexarea are loc mai repede decât înțelegerea și, de cele mai multe ori, un motor de căutare clasifică o pagină web cu predicții, „inițial”. După înțelegere, are loc „reclasificarea”. 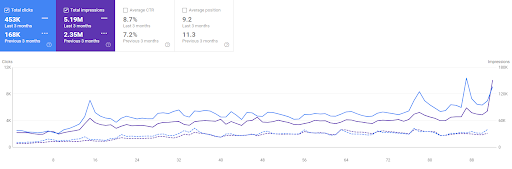
Comparația ultimelor 3 luni a Vizem.net
Cum este rețeaua de conținut semantic a Vizem.net?
Îmi amintesc că pentru mulți dintre clienții mei, prietenii sau grupurile secrete SEO, în timpul întâlnirilor, am demonstrat ambele site-uri web spunând „vor exploda”. Și, în timp ce scriu acest articol, vă spun asta:
Urmărește Rețeaua de conținut semantic „istanbulbogazicienstitu.com/meslek”, pentru că va exploda. Și, puteți găsi un videoclip pe care l-am publicat înainte de a scrie acest articol, în timp ce demonstrez „Date istorice” dintr-un eveniment sezonier și efectul acestuia asupra proceselor inițiale și de re-clasificare. O puteți vedea mai jos.
Pe baza acestui fapt, Rețeaua de conținut semantic a Vizem.net nu este asemănătoare cu IstanbulBogazici Enstitusu, prin urmare, nu am folosit un „nivel intens de acoperire topică și creștere a datelor istorice”, aveam nevoie să creez autoritatea legată de anumite tipurile de entități, atributele acestora și posibilele acțiuni din spatele interogărilor pentru aceste perechi entitate-atribut. Vizem.net nu are doar „filiale educaționale universitare” sau „ocupațiile și cursurile online” în cadrul acestuia. Are „țări pentru cereri de viză”. Astfel, crearea unui nivel suficient de Autoritate Topică necesită coerență în timp cu cel puțin 190 de rețele de conținut semantic diferite.
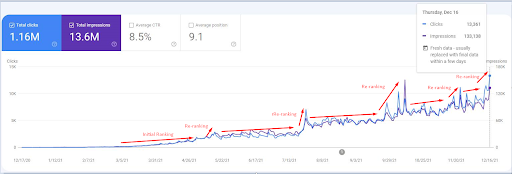
O captură de ecran din 18 decembrie 2021. Puteți vedea re-clasificarea și creșterea continuă a afișărilor și a clicurilor. Aceasta este 4 săptămâni mai târziu de la captura de ecran anterioară.
Pentru a vedea evenimentele de re-clasificare, puteți compara versiunea goală a graficului performanței căutării organice care demonstrează efectul SEO semantic. 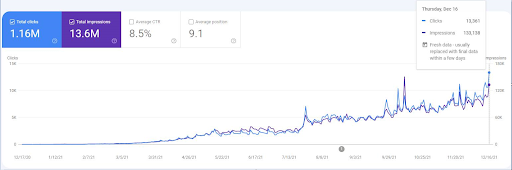
Aceste 190 de rețele de conținut semantic diferite sunt modelate pe baza „țarii” în sine, iar țările sunt plasate în centrul hărții topice cu fiecare strat contextual posibil pentru a îmbunătăți acoperirea activității de căutare.
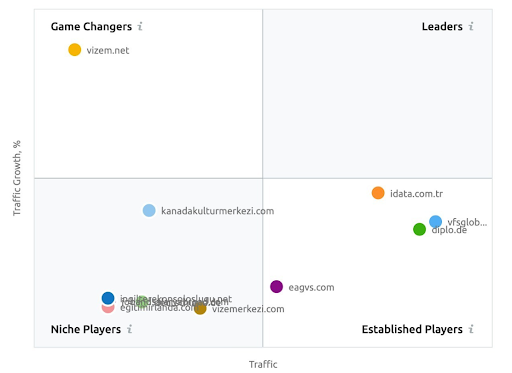
O captură de ecran de la SEMRush care arată percepția lor pentru Vizem.net, spre deosebire de alți jucători din industrie.
Am mai publicat un videoclip, doar pentru Vizem.net. În acest videoclip, ultima situație a site-ului nu există, astfel încât, cred, oferă și o comparație frumoasă între azi și ziua respectivă.
În cele din urmă, publicarea lucrurilor irelevante într-un articol, un segment de site web sau o sursă irelevante poate reduce relevanța generală a entității web pentru domeniul de cunoștințe specific. Vizem.net își va arăta valoarea reală, iar Rankability în viitor va fi mult mai bună.
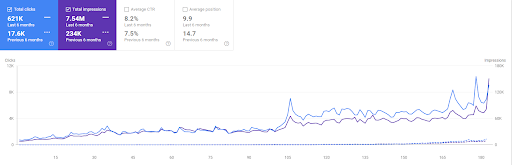
Comparația ultimelor 6 luni a Vizem.net.
Înainte de a continua, știu că acesta este un articol lung. Dar, de fapt, aceasta este o scurtă explicație a unei metodologii SEO extrem de complexe. Rețelele de conținut semantic necesită prea multă gândire în timpul proiectării lor și luni de educație pentru clienți, autori și odată cu integrarea. Astfel, în acest articol, vreau să mă concentrez pe definițiile conceptelor cu cele mai bune sugestii scurte executabile și brevete importante Google și ale altor motoare de căutare, lucrări de cercetare împreună cu propriile concepte. În versiunea lungă (practic, o carte), m-am concentrat pe „clasificarea inițială” și „re-clasificarea” rețelelor de conținut semantic.
Dacă doriți să aflați mai multe, citiți „Importanța clasamentului inițial și a re-clasării pentru SEO”.
Până acum, am procesat lucrurile de mai jos.
- Rețeaua semantică
- Bază de cunoștințe
- Rețeaua de conținut semantic
- Încredere bazată pe cunoștințe
- Acoperire contextuală
- Domeniu contextual și straturi
- Relevanța MuM pentru rețelele de conținut semantic
- Contextul sursei
Aceste concepte sunt pentru a înțelege cum funcționează rețelele de conținut semantic și cum pot fi utilizate cu o hartă topică. Următoarele secțiuni vor fi despre modul în care un motor de căutare clasifică rețelele de conținut semantic, inițial și mai târziu, în modificare. În acest context, lucrurile de mai jos vor fi procesate.
- Clasamentul inițial
- Reclasificare
- Șablon de interogare
- Șablon de document
- Șablon de intenție de căutare
- Ce ar trebui să faceți pentru a folosi rețelele de conținut semantic
Ce este clasamentul inițial pentru SEO?
Acesta este un termen și un concept nou pentru SEO, dar unul vechi pentru motoarele de căutare. Versiunea lungă a „Studiului de caz SEO centrat în rețeaua semantică” se concentrează pe algoritmii de clasare bazați pe algoritmi dependenți de interogări, dependenți de documente, dependenți de sursă și mai multe brevete. Algoritmii de regăsire predictivă a informațiilor sau de clasificare predictivă încearcă să scadă costul calculului. Și, chiar dacă indexarea are loc într-o singură zi, înțelegerea unui document poate dura luni sau chiar ani. Calcularea unui clasament inițial este, prin urmare, o modalitate de a îmbunătăți calitatea SERP, scăzând în același timp costul. Unele sarcini legate de Motorul de căutare au prioritate mai mare decât altele pentru a menține indexul viu, proaspăt și de o calitate suficient de înaltă.

Termenul de clasare inițială apare în zeci de mii de brevete Google și lucrări de cercetare diferite, deoarece este o perspectivă clasică în rândul constructorilor de motoare de căutare. Astfel, mai sus, puteți vedea diferite documente de brevet cu continuarea acelorași paragrafe și termeni cu modificări minore în jurul termenului de rang inițial.
Clasamentul inițial reprezintă rangul unui document pe SERP imediat după ce a fost indexat. Clasamentul inițial al unui document reprezintă autoritatea generală și relevanța sursei pentru subiectul specific, șablonul de interogare și intenția de căutare. Același conținut poate fi clasificat diferit în ceea ce privește clasarea inițială între diferite surse. Clasamentul inițial este important în timpul utilizării rețelelor de conținut semantic pentru a vedea creșterea calității generale și a autorității sursei. Fiecare document nou își mărește clasamentul inițial în timp ce scade întârzierea de indexare dacă designul rețelei de conținut semantic este structurat corect.
Clasamentul inițial sprijină procesul de re-clasificare și eficiența acestuia pentru sursă. Și „Rankability of a source” ar trebui să fie procesată cu acești doi termeni, inițial și re-clasificare.
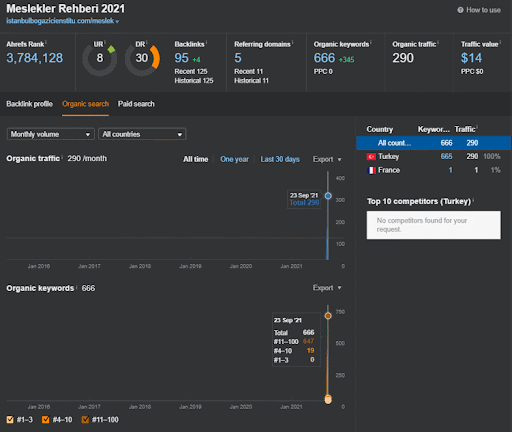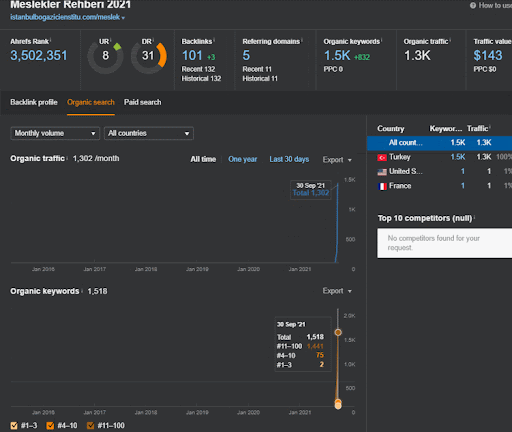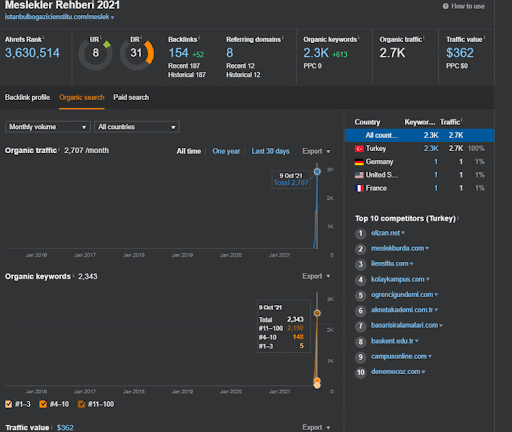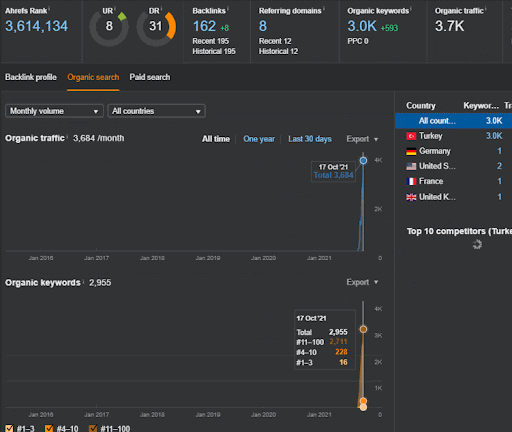
Puteți urmări primele 20 de zile ale schimbării organice a performanței celei de-a doua rețele de conținut din Proiectul I.
În acest context, ori de câte ori Vizem.net publică un document nou, sau ori de câte ori IstanbulBogazici Enstitu publică o nouă rețea de conținut semantic, clasamentul inițial este mai bun decât înainte, în timp ce conținutul este indexat mai rapid.
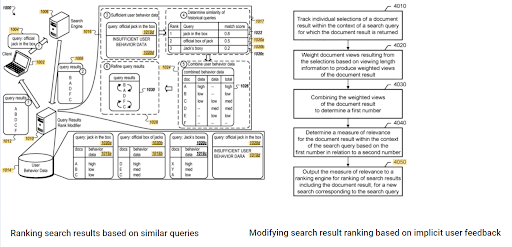
Proeminența clasamentului inițial și a datelor istorice pot fi observate între aceste două brevete Google complementare. Unul este pentru documentele inițiale și de re-clasificare pe baza feedback-ului implicit al utilizatorului. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 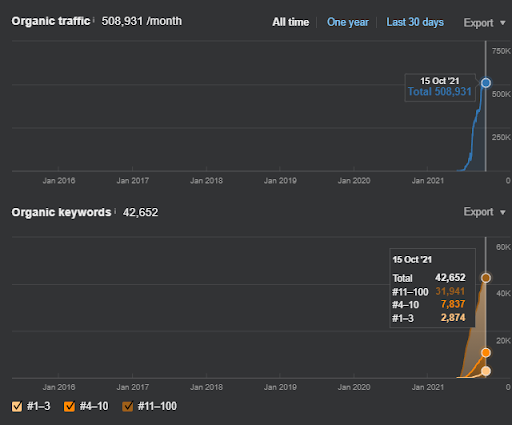
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 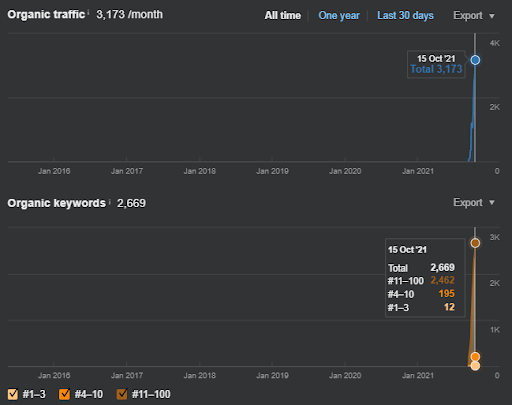
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 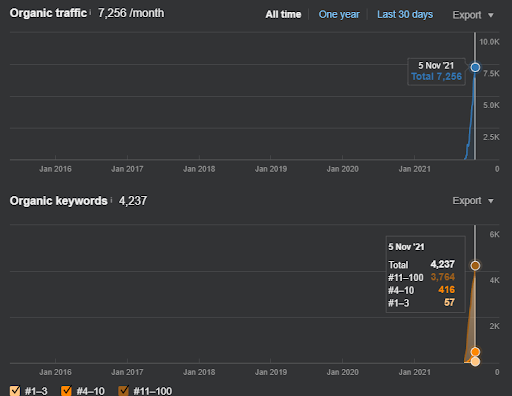
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 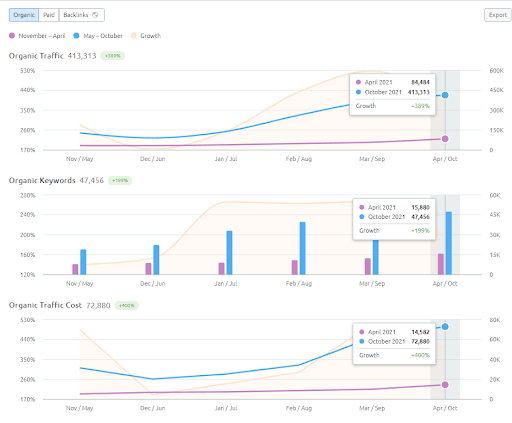
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Date oncrawl³
 Află mai multe
Află mai multeWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 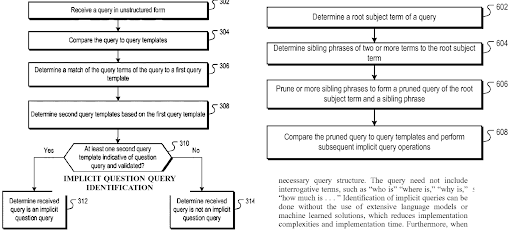
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
Da, ei sunt. Clasamentul probabilistic și Clasamentul cu relevanță degradată sunt principalele coloane ale unui motor de căutare semantic pentru înțelegerea utilizatorilor și crearea celui mai bun SERP posibil de cea mai înaltă calitate, care este pregătit pentru stări de posibilități. 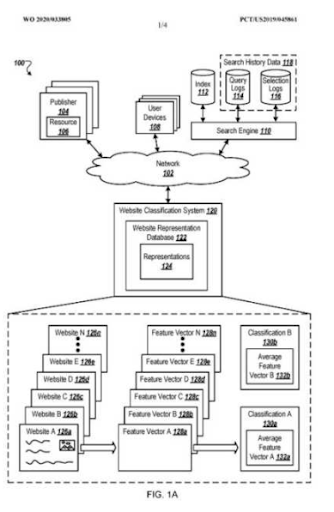
Anterior, pentru a face din „designul site-ului web, și aspectul sau tonalitatea” un argument pentru învățarea reprezentării pentru site-uri web, Bill Slawski a scris „Vectorii de reprezentare a site-ului web”.
Ce este un șablon de intenție de căutare?
Un șablon de intenție de căutare poate fi reprezentat de nevoia din spatele șablonului de interogare. Un șablon de interogare-document poate fi unit pe baza unui șablon de intenție. Având un șablon de intenție de căutare cu posibilă înțelegere „Clasare de relevanță degradată” și „Clasare probabilistică” va ajuta la crearea celei mai bune activități de căutare posibile și acoperirea intenției de căutare cu ordinea corectă. În timpul creării unei rețele de conținut semantic, cel mai important lucru este ajustarea șablonului de intenție de interogare a documentului pe baza contextului sursei pentru a completa o rețea semantică bazată pe un domeniu de cunoaștere prin îmbunătățirea acoperirii contextuale pentru a îmbunătăți încrederea bazată pe cunoștințe și autoritatea actuală. . 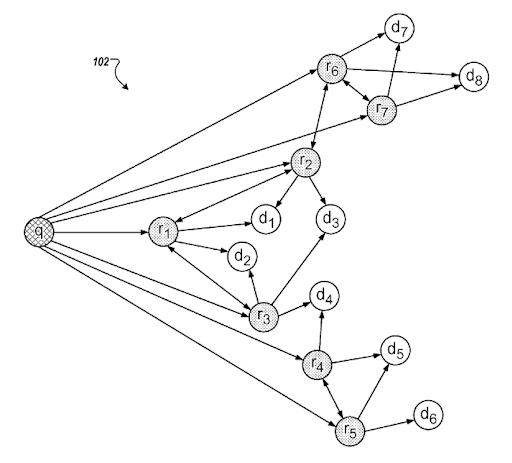
O secțiune din „Rafinări ale interogărilor bazate pe intenția dedusă” de la Google. Funcționează prin grupuri de interogări și șabloane de intenții cu conexiuni semantice. Îl puteți experimenta pe diferite niveluri de taxonomie a frazelor.
Înainte de a trece la câteva exemple concrete și sugestii pentru a vă ajuta să creați o rețea de conținut semantică mai bună, trebuie să vă spun că chiar și versiunea simplă a acestui studiu de caz SEO necesită un nivel înalt de înțelegere a motorului de căutare și abilități de comunicare. Astfel, deși simt că dau informații la nivel înalt, știu că cursul SEO semantic pe care îl voi crea vă va arăta câteva exemple concrete mai multe și mai bune. 
Același brevet explică conexiunile adecvate dintre diferitele „căi de interogare” și „schimbări de context”.
Ce ar trebui să știți despre utilizarea rețelelor de conținut semantic?
Pentru a crea o rețea de conținut semantic, uneori chiar și un simplu rezumat de conținut semantic și design poate dura o oră, dacă puneți toate detaliile relevante pe baza semanticii lexicale sau a tipurilor de relații dintre entități și fraze. Folosind mai multe unghiuri în același timp, cum ar fi indexarea bazată pe fraze și vectorii de cuvinte sau vectorii de context pentru a calcula relevanța contextuală a unui conținut în ansamblu pentru un domeniu contextual sau relevanța acestuia pe baza tipurilor individuale de subconținut, necesită un nivel înalt de înțelegere semantică a motorului de căutare.
Astfel, folosirea unei metodologii generative va ușura totul cu conceptele pe care vi le-am explicat mai sus, pentru că, chiar dacă pregătiți perfect fiecare parte a rețelei de conținut semantic, autorii și scriitorii nu vor putea să o scrie sau managerii de conținut. nu vă va putea urmări viziunea. Astfel, s-ar putea să te obosească degeaba și să te facă să părăsești un proiect așa cum am făcut eu pentru unele dintre aceste proiecte de studiu de caz SEO, după ce demonstrez conceptul într-un mod suficient, viu și auditabil.
Sugestiile de mai jos vor fi doar pentru pași ușori executabili și scurti care vă vor ajuta.
1. Nu utilizați legături fixe din bara laterală de la fiecare rețea de conținut semantic
Fiecare link ar trebui să aibă o descriere a conexiunii între două documente hipertext, ca fiecare cuvânt dintr-o pagină web. Utilizarea semantică HTML poate ajuta la specificarea poziției și a funcției unui document pe o pagină web, ajutând în același timp motoarele de căutare să pondereze secțiunile în mod diferit în ceea ce privește contextul.
În exemplul Vizem.net, nu am folosit același design de bară laterală. Bara laterală nu arăta cele mai recente postări sau cele mai critice. Barele laterale arată doar atributele entităților centrale și nu sunt fixe, sunt dinamice. Cu alte cuvinte, pe baza ierarhiei din cadrul hărții topice, rețelele de conținut semantic se schimbă chiar dacă sunt în bara laterală. 
Gândirea la modelele Reasonable Surfer și Cautious Surfer poate ajuta un SEO să creeze o relevanță mai bună între diferitele documente hipertext.
În plus, legătura curge din punct de vedere al proeminenței, iar popularitatea ar trebui să urmeze contextul sursei din cele mai bune conexiuni posibile. Mai jos, puteți vedea secțiunile din bara laterală cu coduri HTML semantice ajustate. 
În funcție de ierarhia articolului care este activ în sesiunea utilizatorului, filele, ordinea filelor, legăturile din cadrul filelor se vor schimba. Exemplul de mai sus este din ierarhia breadcrumb de mai jos. ![]()
2. Sprijiniți rețelele de conținut semantic cu PageRank
Chiar dacă PageRank-ul extern nu este obligatoriu din sursele externe, dacă ești capabil să-l folosești, îți vei da seama că clasamentul inițial și re-ranking-ul vor fi mai bune. Pentru ambele proiecte, nu le-am folosit, dar de data aceasta nu a fost scopul. Pentru Vizem.net, au existat probleme economice și nu am vrut să cheltuiesc bugetul pe PR digital și pe divulgare. Pentru Istanbul BogaziciEnstitusu, am aranjat câteva „surse interconectate la nivel local” pentru a susține autenticitatea sursei pentru subiectul specific, dar, din nou, compania nu a putut implementa acest lucru din cauza problemelor bugetare și de disciplină organizațională. 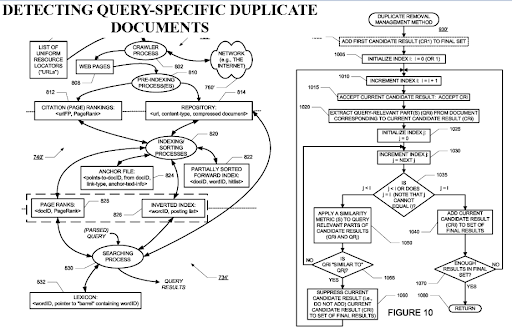
Detectarea documentelor duplicate specifice unei interogări este o perspectivă importantă din motoarele de căutare, deoarece PageRank poate ajuta un document să fie filtrat ca fiind valoros chiar dacă este duplicat. Deoarece rețelele de conținut semantic foarte organizate pot fi similare între ele, fluxul PageRank și datele istorice sunt utile.
Când vine vorba de alegerea punctului de flux extern PageRank pentru aceste tipuri de rețele de conținut semantic, utilizați sursele cu date istorice. În cazul meu, aranjasem aceste puncte finale PageRank mai devreme, înainte să lansez și să public prima rețea de conținut semantic. Astfel, am reușit să iau referințe externe de la concurenți direcți, dar când am publicat rețeaua de conținut semantic, concurenții au renunțat să mai lege sursa pentru că au văzut creșterea în masă a sursei ca concurent.
Această situație ne duce la a treia sugestie. Dacă am putea folosi fluxul PageRank de la referințe externe, procesul de re-clasificare ar fi mai rapid, iar clasarea inițială ar fi mai mare.
3. Utilizați diferite texte de ancorare din subsol, antet și conținut principal pentru părțile proeminente ale rețelei de conținut semantic
Textele ancora sau „textul link” din punctul de vedere al motorului de căutare semnalează relevanța unui document hipertext pentru altul. Conform documentului original al PageRank, numărul de linkuri este proporțional cu fluxul PageRank. Dar, mai târziu, Google a schimbat acest lucru pentru a preveni „încărcarea de linkuri” și a limitat linkurile care pot trece efectiv de PageRank. Pe baza acestui lucru, sunt dezvoltate modelele TrustRank, Cautious Surfer, Hilltop Algorithm sau Reasonable Surfer. 
Acestea sunt două link-uri către cele două rețele de conținut semantic diferite pentru BogaziciEnstitusu, dar din moment ce nu am implementat îmbunătățiri tehnice SEO sau UX, vă puteți da seama de „ieftinitatea” designului butoanelor.
Potrivit Google, același link nu poate trece PageRank a doua oară către o altă pagină web, în timp ce PageRank va fi transmis doar de la primul link. Și, în forma originală a algoritmului PageRank, un document hipertext se poate conecta pentru a-și îmbunătăți PageRank, sau redirecționările 301 pot fi folosite pentru a lua PageRank din documentul țintă a linkului. Ambele situații au creat tehnici vechi Black Hat, cum ar fi redirecționarea temporară a unei pagini web către alta pentru a-și lua PageRank. Aceasta a fost din zilele în care SEO-ii au putut să vadă PageRank-ul unei pagini web din Google Search Console sau din SERP. Mai târziu, Google a început să reducă PageRank cu fiecare redirecționare, în timp ce Danny Sullivan a explicat că 301 de redirecționări vor trece pe deplin de PageRank. Pe lângă toate aceste modificări, lucrul important aici este că, chiar dacă al doilea link nu trece de PageRank, totuși trece de relevanța textului linkului. 
Secțiunile proeminente ale rețelei de conținut semantic au fost conectate de la pagina de pornire pe baza „rafinărilor de interogare de mijloc”, care includ „verbe, predicate” sau „activități ale căutării”.
Astfel, secțiunile proeminente ale Rețelei de conținut semantic ar trebui să fie legate din meniul antet și subsol cu secțiunile de taxonomie superioare, iar textele linkurilor ar trebui să fie diferite unele de altele. În aceste exemple, am folosit legăturile de antet cu textele de link proeminente, dar scurte, în timp ce am păstrat exemplele de subsol mai mult timp. 
O secțiune a „Indexarea etichetelor de ancorare într-un sistem de crawler web”, aceasta rezumă importanța unui text de ancorare și a unui text de adnotare pentru a poziționa o pagină web în grupurile de interogări și grupurile de pagini web.
Dacă secțiunea Rețeaua de conținut semantic este prea proeminentă, pentru a trece corect PageRank și prioritatea de accesare cu crawlere, am legat cele mai importante secțiuni cu texte de link adecvate și paragrafe explicative care includ atributele proeminente cu diferite variații ale N-Grams relevante. 
Aceasta este a doua zonă legată de pe pagina de pornire a Vizem.net, se află în spatele unui acordeon și se concentrează pe țările din interogări și leagă secțiunea de mijloc a rețelei de conținut semantic.
Notă: În jurul textelor Anchor, întotdeauna, a fost folosit un „text de adnotare” planificat pentru a îmbunătăți precizia scopului link-ului.
4. Limitați restricția privind numărul de linkuri și potrivirea legăturilor desktop și mobile și a conținutului principal
Ambele proiecte sunt limitate să aibă mai puțin de 150 de link-uri interne pe pagină web. Cu ajutorul HTML-ului semantic, locurile legăturilor și funcțiile legăturilor sunt clarificate pentru crawler-uri. IstanbulBogazici Enstitusu avea peste 450 de link-uri pe pagină web, iar unele dintre acestea erau auto-linkuri (un link de la aceeași pagină către aceeași pagină). Partea cea mai rea este că jumătate dintre aceste link-uri nu existau în versiunea mobilă a conținutului. 
Scorul de păstrare URL, Scorul de accesare cu crawlere și alte tipuri de scoruri pot fi utilizate pentru a determina importanța unui link în Harta URL internă, iar etichetele de identificare a documentelor din diferitele niveluri pot fi folosite pentru a sorta indexul pe baza scorurilor de relevanță independente de interogare.
Deoarece Google folosește indexarea numai pentru dispozitive mobile, dacă conținutul nu există în versiunea mobilă, acesta va fi ignorat și nu va fi folosit în scopuri de evaluare a relevanței și de clasare. Astfel, conținutul mobil și desktop a fost configurat pentru a se potrivi unul cu celălalt. Chiar dacă Google tolerează nepotrivirile de conținut între versiunile desktop și cele mobile, tot îngreunează înțelegerea și clasarea unei pagini web pentru motoarele de căutare. 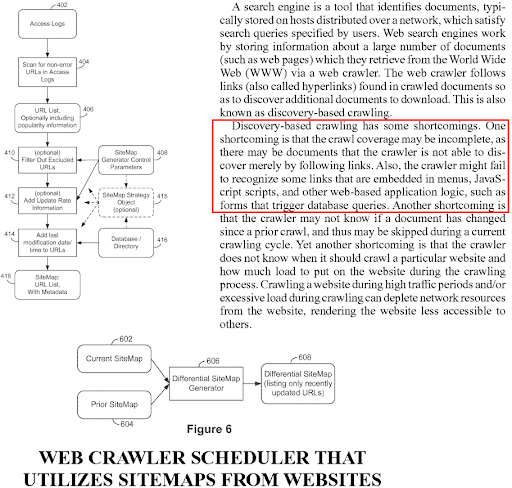
Un motor de căutare poate genera un sitemap pentru site-ul web, iar acest sitemap poate fi regenerat într-o buclă, dacă link-urile și metadatele URL nu sunt potrivite între user-agents sau cronologie. Prin urmare, este important să păstrați calea de accesare scurtă, coada de accesare scurtă și consecvența legăturilor interne.
Alături de legăturile dintre diferite pagini web, sunt folosite și link-uri pentru subsecțiunile paginilor web cu „tabelul de conținut” și „Fragmentele URL”. Aceste fragmente de URL vizează o anumită subsecțiune a paginii web în timp ce o denumesc corect, iar secțiunea specifică a fost plasată într-o etichetă de secțiune cu h2. Cu ajutorul fragmentelor URL cu „linkuri de navigare în pagină”, aterizarea unui utilizator din SERP la secțiunea specifică a paginii web a fost mai ușoară, în timp ce secțiunile inferioare ale conținutului au fost făcute mai proeminente pentru a satisface nevoia din spatele site-ului. interogare.
5. Aveți o disciplină de nivel militar pentru proiectele dvs. SEO
Acesta este cu totul alt subiect și se poate scrie un alt articol pentru a defini ce înseamnă disciplina la nivel militar sau de ce este utilă pentru un Proiect SEO. Dar, trebuie să vă spun că, în ultimele 2 luni, am pregătit o mulțime de CEO și SEO de la alte agenții, împreună cu echipele lor, pentru a vedea dacă designul cursului meu va funcționa bine sau nu.
Ori de câte ori văd succes și un nivel ridicat de înțelegere pentru sesiunile de educație pe care le fac, există o voință puternică și perseverență. Principala problemă este că SEO semantic este mult mai greu decât celelalte verticale SEO. SEO tehnic este universal și are chiar și ghiduri scrise pentru fiecare pas. SEO OnPage sau WUX și Layout Design pot fi urmărite cu măsurători numerice. Când vine vorba de Semantică, este practica de a uni perspectiva unei mașini care funcționează pe baza unui sistem adaptativ complex cu homo-sapiens care nu înțeleg cum funcționează mașina.
Această distincție necesită o bază concretă care ar trebui pusă din prima zi a proiectului. De cele mai multe ori, folosesc regulile de mai jos.
- Designurile de conținut și rețeaua de conținut semantică nu trebuie să fie logice pentru un autor sau scriitor.
- Sarcina managerului de conținut este de a audita compatibilitatea conținutului cu designul conținutului.
- Sarcina autorului este scrierea conținutului cu informațiile aferente care includ un nivel ridicat de acuratețe și detaliu.
- Legăturile, definițiile, dovezile, comparațiile, propozițiile, referințele ar trebui făcute cu exemple concrete, nu cu puf.
- Fiecare cuvânt inutil este o diluare pentru context și concept.
Când citești, s-ar putea să sune ușor de implementat, dar nu este atât de ușor. Astfel, pot spune că chiar eram pe cale să-i concediez pe unii dintre propriii mei angajați. Mă bucur că nu am făcut-o, cel puțin deocamdată. În condiții normale, vor fi o mulțime de întrebări la care vi se vor pune, dacă proprietarul întrebării nu este SEO sau proprietar al companiei, nu răspundeți. Economisiți-vă energia în stocarea de date a motorului de căutare, care vă va stoca feedback-ul pozitiv, nu feedback-ul redundant și irelevant pentru clasamente.
6. Extindeți sursa cu relevanță contextuală
Această secțiune se referă în totalitate la înțelegerea nevoii Google de a crea MuM. Când proiectați o hartă topică, aceasta va include o mulțime de rețele de conținut semantic care vor oferi o bază de cunoștințe mai bună la nivel de site. Astfel, în timp ce publică aceste sub-secțiuni, ar trebui să se poată conecta la contextul sursei sau poate schimba modul în care motorul de căutare vede sursa, iar tema site-ului poate trece la un alt domeniu de cunoștințe. De exemplu, conectarea lucrurilor în jurul conceptelor și zonelor de interes cu acțiuni posibile necesită înțelegerea conexiunilor complicate ale semnificațiilor între ele. A face aceste conexiuni clare pentru un utilizator, un scriitor și, de asemenea, o mașină în același timp este procesul de creare a rețelei de conținut semantic. 
Pentru a realiza acest lucru, fiecare secțiune nouă pentru site-ul web ar trebui să poată fi conectată la secțiunea centrală a hărții topice. Aceste punți contextuale pot fi văzute din designul și explicația LaMDA de la Google.
Întâlnesc o mulțime de întrebări precum „ar trebui să scriu despre un alt subiect”, „dacă am două nișe diferite, va face rău?”. Dacă conectați toate aceste sub-secțiuni, segmente de site-uri web ca componente puternic conectate, aceste rețele de conținut semantic se vor sprijini reciproc pentru o clasare mai bună, în loc să împartă identitatea mărcii și autoritatea de actualitate pentru două subiecte diferite și irelevante.
7. Creați trafic real și auditați cu Segmentarea personalizată Google Analytics
Traficul real este conectat la RankMerge în același mod în care încrederea bazată pe cunoștințe este conectată la PageRank. În curând, mă gândesc să scriu un alt articol cu titlul „When the PageRank Lies…” pentru a explica de ce motorul de căutare încearcă să afecteze PageRank cu semnale secundare. De fapt, PageRank nu este un semnal definitiv care arată autoritatea, expertiza și credibilitatea unei surse. Poate fi un semnal pentru clasare și un factor, dar nu poate fi de încredere singur. RankMerge este procesul de unire a traficului site-ului web și a PageRank-ului într-un mod în care site-ul web poate avea sens pentru motorul de căutare. PageRank ridicat și trafic scăzut pot semnala „traficul nepopular” sau „manipularea PageRank”.
Astfel, pentru a îmbunătăți datele istorice ale sursei, am folosit Evenimentele SEO sezoniere și am mărit interogările „brand + termen generic”. Traficul direct și paginile web marcate sunt crescute cu traficul real și autentic.
Aceste tipuri de date ajută un motor de căutare să aibă încredere în el pentru a-l clasa din ce în ce mai sus pe SERP.
Pentru a putea audita acest trafic real care provine din Rețeaua de conținut semantic, un SEO poate crea un segment personalizat din Google Analytics pentru a vedea cum vin ca trafic direct. De asemenea, pot fi create obiective personalizate, cum ar fi crearea unei posibile călătorii de căutare de la prima rețea de conținut semantic la a doua rețea de conținut. Aceasta este dovada conceptului că rețeaua semantică este construită în jurul intereselor, conceptelor și posibilelor acțiuni legate de căutare.
Mai jos, veți găsi un singur exemplu pentru cea dintre paginile web care sunt plasate în prima Rețea de Conținut Semantic pentru demonstrarea traficului direct achiziționat prin trafic organic. 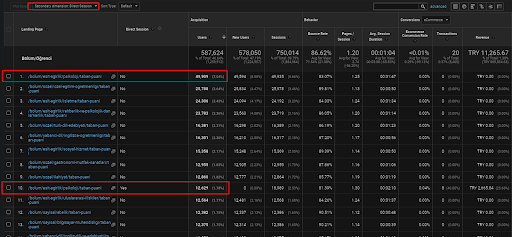
În ultimele 3 luni, o singură pagină web din prima rețea de conținut semantic a fost folosită de cei 49.000 de utilizatori organici. Și, 12.900 de utilizatori în plus au venit ca trafic direct, care a fost achiziționat prin căutare organică pentru prima dată. Și, valorile sesiunii/paginii și durata medie a sesiunii sunt mai mari pentru aceste segmente de utilizatori.
După cum s-a spus mai înainte, un motor de căutare poate grupa interogări, documente, intenții, concepte, interese, acțiuni, dar și poate grupa utilizatori. Dacă un grup de utilizatori lasă feedback pozitiv în timp ce creează o valoare a mărcii adăugând aceste pagini web la marcaje, tastând direct bara de adrese și căutând termenii generici împreună cu numele mărcii, aceasta arată că sursa își îmbunătățește autoritatea și motorul de căutare. este capabil să recunoască totul de la SERP, Chrome și propriile adrese DNS. 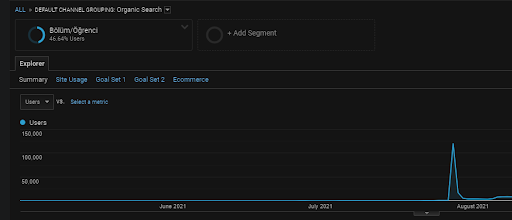
Mai sus, puteți vedea segmentul de utilizator al First Content Network. Puteți crea un segment de utilizator pentru fiecare rețea de conținut semantic cu obiective personalizate și puteți adăuga segmente de sub-utilizator și pentru rețelele de conținut secundar semantic.
8. Sprijiniți rețelele de conținut semantic cu sub-secțiuni bazate pe activități de căutare
Această secțiune este, de asemenea, despre rezoluția atributelor de entitate și despre analiză, care este un alt subiect. Dar, simplu spus, unele atribute ale acestor entități bazate pe domenii contextuale ar trebui plasate într-o ierarhie inferioară, nu în ierarhia superioară. În acest caz, „Vizem.net” poate da un exemplu mai bun, în timp ce pentru Bogazici Enstitusu, se poate demonstra cu „Salariile ocupațiilor”, și „Punctele de examen ale universităților”. Aceste două atribute proeminente au fost plasate pe baza șabloanelor de interogare și documente în rețelele semantice de subconținut. 
Identificarea unităților semantice din interiorul unei interogări de căutare este un alt brevet Google care împarte expresiile în diferite categorii semantice și cumulează relevanța unui document în funcție de apropierea acestuia de toate variațiile interogării.
Într-un studiu de caz SEO anterior, nu am urmat acest tip de structură, am creat o cale de crawlere bazată pe „cronologie” și legăturile interne care sunt strict limitate. În aceste articole, valoarea link-urilor interne plasate în principalul conținut este mai mare decât cea anterioară.
9. Folosiți cuvinte tematice în URL-uri
Dacă Google întâlnește două adrese URL diferite cu același conținut fără niciun semnal de canonizare, o alege pe cea scurtă drept cea canonică. Deoarece, adresele URL scurte sunt mai ușor de analizat, rezolvat și solicitat. Când aveți trilioane de pagini web pe care le reîmprospătați de miliarde de ori în fiecare zi, chiar și literele din adrese URL pot arăta „echilibrul cost/calitate” al unui site web. După cum am spus mai devreme, „costul de recuperare” ar trebui să fie mai mic decât „costul de nerecuperare”. Dacă doriți să fiți înțeles de un motor de căutare, ar trebui să puneți „semnalele de context ordonate și complementare” la fiecare nivel, inclusiv adresele URL. 
O secțiune din clasamentul „bazat pe dovezi” prin agregarea probelor. Acesta explică modul în care un răspuns poate fi asociat cu o întrebare.
În acest context, de cele mai multe ori, folosesc un singur cuvânt în URL. Acestea pot reflecta ierarhia și structura rețelei de conținut semantic. Unii încă mai cred că „numărul de straturi” din adresa URL afectează frecvența de accesare cu crawlere, înainte de 2019, era adevărat. Dar, atâta timp cât conținutul are sens și satisface utilizatorii dintr-un subiect popular sau proeminent, nu va fi afectat de o astfel de situație.
Pentru a-l demonstra, puteți urma exemplul de mai jos.
- Domeniu-rădăcină/rețea-de-conținut-semantic-1/tip-1/parte-de-rețea-sub-conținut-pentru-tip-1
- Domeniu-rădăcină/rețea-de-conținut-semantic-2/tip-2/parte-de-rețea-sub-conținut-pentru-tip-2
Aceste două rețele de conținut semantic se pot lega reciproc din aceeași ierarhie și se pot lega și pe baza relevanței. Există mai multe lucruri despre care putem vorbi aici, cum ar fi „Conținutul grupului de entități – Conținut tip hub”, dar subiectul unei alte zile.
Notă: A treia rețea de conținut semantic planificată poate fi procesată și ca o „rețea de conținut conceptuală de grupare”. Și, dacă este publicat, cu efectul celei de-a doua rețele de conținut semantic, Traficul organic total poate fi de peste 3 milioane de sesiuni pe lună.
10. Înțelegeți diferența dintre imbricare și conectare
Ca diferență metodologică practică, conectarea este conectarea lucrurilor similare între ele pe baza unui domeniu contextual, în timp ce imbricarea este gruparea conținutului similar cu același scop împreună. Această grupare va ajuta un motor de căutare să găsească mai rapid conținut similar unul cu celălalt și să creeze un scor de calitate sursă pentru aceste grupuri, sau aceste conținuturi imbricate bazate pe o rețea semantică va fi mai ușor. 
Imaginați-vă că există două căi de accesare diferite, ca mai jos.
- Calea de accesare cu crawlere 1: întâlnește adrese URL aleatoriu, fără un șablon, asemănare și relevanță contextuală.
- Calea de accesare cu crawlere 2: întâlnește adrese URL care au sens chiar și din adresa URL în sine, cu un șablon, un nivel înalt de similaritate și relevanță în funcție de context.
Dacă chiar și din calea de accesare cu crawlere, conținutul are sens, „clasificarea inițială” și „reclasificarea” vor fi mai bune datorită „declanșării re-clasării bazate pe înțelegerea acoperirii motorului de căutare”.
Notă: Folosirea legăturilor interne cu taxonomia expresiei într-un mod adecvat este importantă pentru imbricare și conectare.
Acest lucru ne duce la ultimele două metodologii practice, pe scurt. Și, această secțiune este din nou legată de nivelul înalt de disciplină și de suficiență organizațională. 
Un brevet de la Trystan Upstill și Steven D. Baker pentru recunoașterea termenilor concomitenți din Listele HTML. Proeminența acestui brevet este că arată valoarea unei singure liste HTML pentru a determina listele de termeni concomitente pentru un subiect sau o parte a expresiei taxonomie.
11. Înțelegeți când să publicați o rețea de conținut semantic cu o frecvență ajustată
Acest lucru a fost explicat înainte, dar într-unul dintre aceste proiecte de studiu de caz SEO, am publicat aproape 400 de conținut într-o singură zi. Când vine vorba de celălalt, am început să public doar 10-15 conținut dintr-o dată, apoi am crescut viteza în timp cu o constantă până încep problemele economice legate de Covid.
Dacă o nouă sursă creează o nouă Rețea de conținut semantic, publicarea acesteia în prima zi ar putea fi puțin mai dificilă decât credeți, verificarea tuturor legăturilor interne, gramaticilor și informațiilor de pe pagina web nu este atât de ușoară. Dar, dacă tot conținutul provine doar dintr-un singur subiect și dintr-un șablon de interogare și dacă sursa nu are nicio istorie pe acel subiect, publicarea cea mai mare parte a rețelei de conținut semantic are avantaje precum indexarea, înțelegerea și înțelegerea mai rapidă. reclasificare.
În situația mea a fost și un eveniment istoric cu sezonalitate. Deci, scopul meu a fost să am suficient nivel de poziție medie până când voi putea fi testat de motorul de căutare pentru entitățile specifice și activitățile de căutare față de sursele mai vechi. Astfel, am publicat prima Rețea de Conținut Semantic cu un nivel înalt de pregătire înainte de cele 45 de zile de la evenimentul sezonier.
Apoi, puteți vedea cum Motorul de căutare a testat sursa în mod repetat, ca mai jos. 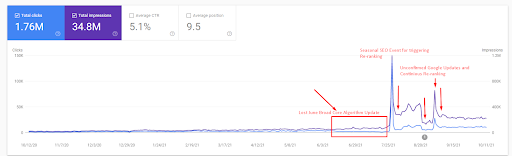
O explicație mai detaliată poate fi găsită mai jos. 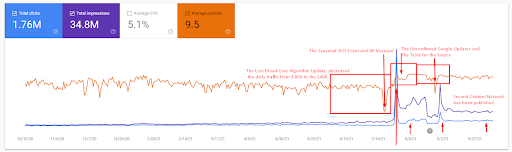
O verificare rapidă a faptelor poate fi găsită mai jos pentru explicația capturii de ecran de mai sus.
- Actualizarea algoritmului Broad Core a redus traficul site-ului web cu peste 200%.
- Site-ul a pierdut, de asemenea, peste 15.000 de interogări.
- Acest lucru a afectat indexarea generală a sursei pentru noua rețea de conținut semantic, deoarece articolul detaliat despre Studiul de caz SEO a fost explicat mai bine.
- Datorită Evenimentului SEO sezonier, re-clasificarea a avut loc mai devreme, iar după evenimentul SEO sezonier, motorul de căutare a normalizat clasarea sursei pe baza traficului real în timpul actualizărilor neconfirmate.
- Interogările și clasamentele care sunt obținute datorită Primei rețele de conținut semantic și evenimentului sezonier au fost protejate și îmbunătățite în continuare.
- Prima rețea de conținut semantic a susținut și noua și a doua rețea de conținut semantic.
Pierderea interogărilor și pierderea medie în clasament pot fi, de asemenea, văzute din Ahrefs, ca mai jos. Puteți verifica efectul Google Broad Core Algorithm Update (GBCAU) din iunie 2021 împreună cu efectul actualizării neconfirmate. 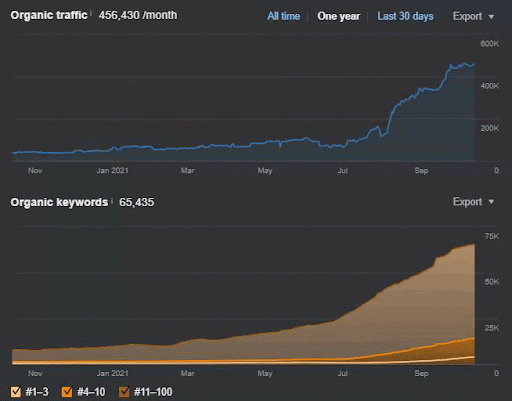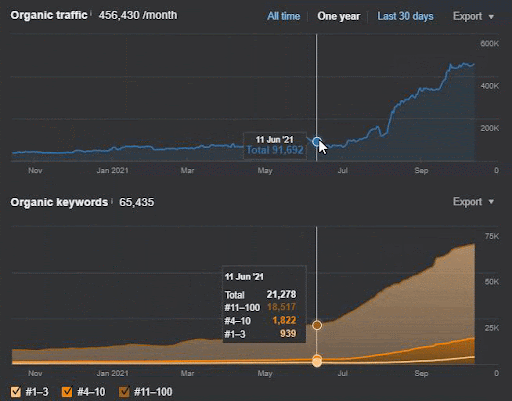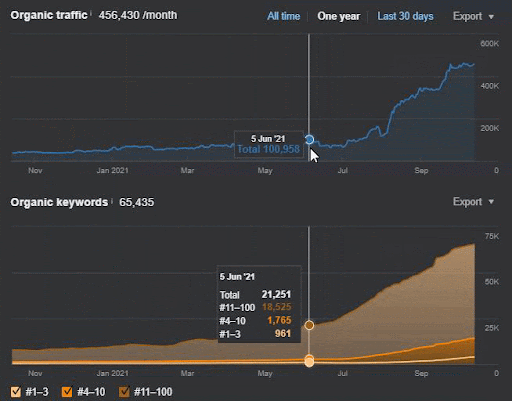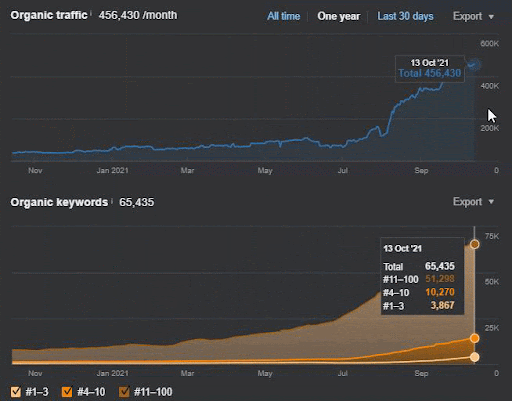
Astfel, utilizarea unei rețele de conținut semantic cu multiple strategii posibile este o necesitate. Chiar dacă GCBAU este pierdut, totuși, datorită altor factori legați de motorul de căutare natura poate ajuta un SEO. Astfel, vă puteți imagina de ce să explicați aceste lucruri unui autor sau unui client este mai greu decât SEO tehnic. SEO semantic nu folosește valori numerice, ci folosește cunoștințe teoretice care provin din înțelegerea motoarelor de căutare prin brevete, lucrări de cercetare, experiență și anunțuri istorice.
12. Utilizați optimizarea propoziției în pagină pentru o mai bună structură faptică
Pentru a fi sincer, chiar și a 10-a listare este un subiect complet nou și poate necesita chiar și scrierea a 20.000 de cuvinte aici. Dar, voi începe cu un exemplu simplu.
- X este Y.
- Y este X.
Pentru exemplele de propoziții de mai sus, puteți înțelege lucrurile de mai jos.
- Propozițiile de mai sus nu sunt conținut duplicat.
- Propozițiile de mai sus sunt duplicate.
- Explicațiile relaționale dintre două propoziții sunt aceleași.
- Etichetele rolului semantic sunt 100% diferite.
- Ieșirea de recunoaștere a entității numite este 100% aceeași.
Optimizarea propozițiilor în pagină este legată de algoritmii de generare a întrebărilor și tehnologiile de împerechere întrebare-răspuns. Un format de întrebare necesită un anumit tip de propoziție. Și la anumite tipuri de întrebări ar trebui să se răspundă cu anumite tipuri de propoziții. Formatul de conținut, NER și Extragerea faptelor vor fi afectate de optimizarea structurii propoziției. 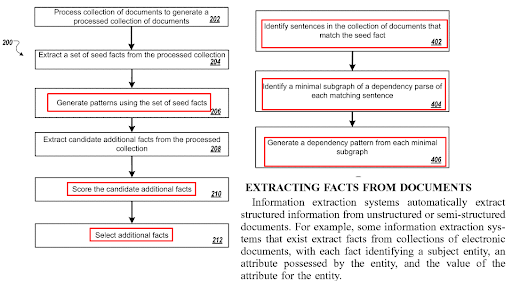
Tripleții (un obiect, două subiecte) pot fi extrase și verificate din punct de vedere al preciziei mai rapid. Două propoziții similare nu înseamnă că sunt duplicate, înseamnă că sunt apropiate una de cealaltă în ceea ce privește structura propoziției. Atâta timp cât propunerea este diferită, utilizarea propozițiilor similare între șabloane de documente similare pentru diferite perechi de interogare-intenție este o necesitate pentru crearea rețelei de conținut semantic. 
Structurile de propoziții clare, cu un model adecvat, sunt utile pentru a face elementele de text mai relevante unele pentru altele, ajutând în același timp un motor de căutare să recunoască entitățile numite, și subiectele, atributele, împreună cu valorile lor unul față de celălalt.
De asemenea, vă va ajuta să vedeți ce secțiune a unui articol poate fi îmbunătățită și în Topical Nets, unde conținutul dvs. se clasează mai bine pentru ce tipuri de perechi de cuvinte, vectori de cuvinte și intenții. Deoarece, dacă anumite tipuri de structuri de propoziție pentru anumite tipuri de întrebări pot fi observate pe mai multe pagini web, va fi de ajutor pentru testele SEO A/B avansate cu cantități nesfârșite de mostre de date și mostre de testare. Puteți crea mai multe modele de propoziții în pagină pentru a verifica modul în care un motor de căutare extrage faptele pentru a le compara. 
Când vine vorba de a oferi faptele, „Seiful cunoașterii” și Luna Dong ar trebui amintite.
13. Oferiți informații din lumea reală cu precizie și consecvență, nu opinii cu Fluff
Precizia aici înseamnă a putea fi comparat cu valori numerice, sau relații conceptuale concrete. Consecvența înseamnă că îți protejezi poziția față de propunerea specifică. De exemplu, nu spuneți că „Produsul X este cel mai bun pentru Y” pentru fiecare recenzie de produs legată de Y. Nu oferiți propuneri contradictorii la nivelul întregului site. Și, dacă produsul este cel mai bun, care este dovada acestuia? Material, dimensiune sau culoare și miros? Fluff în text înseamnă că folosiți cuvinte-punte inutile sau nu spuneți lucruri care nu pot fi dovedite sau contraziceți adevărul.
În contextul acestor instrucțiuni nedefiniționale care sunt susținute de unele dintre exemple, puteți verifica unul dintre modelele de limbaj ale Google, care este KeALM.
Este pentru generarea de text dintr-o bază de date cu modelele date-to-text și pentru verificarea acurateței conținutului. 
KELM este un exemplu de audit de acuratețe pentru propunerile cu metode text-to-data.
Aceasta este, de asemenea, puțin despre definiția „Tripletului” și „Extracție deschisă de informații pentru entități necunoscute”, dar după cum știți, aceasta este versiunea pe scurt și cred că am spus destule. Practic, atunci când oferiți informații greșite pe site-ul dvs., asigurați-vă că Google este capabil să le înțeleagă pentru a scădea încrederea bazată pe cunoștințe a sursei. Aici, ar putea fi necesar să știți că, deoarece puteți extinde baza de cunoștințe, un motor de căutare își poate schimba propria bază de cunoștințe pe baza informațiilor dvs., dacă aveți o sursă corelată cu PageRank și încredere în baza de cunoștințe. cu mare precizie și tripleți unici.
14. Înțelegeți Arborele de dependență semantică pentru entități
Arborele de dependență semantică înseamnă că atributele care semnalează relațiile cu alte entități au o dependență ierarhică între ele. Arborele de dependență semantică poate fi observat prin verificarea mai multor profiluri și unghiuri de entitate, cum ar fi o țară poate fi membră a unei organizații și, ca altă entitate, această organizație poate avea alte atribute care pot fi atribuite țărilor conectate cu relații deduse.
Mai jos, veți putea vedea un exemplu simplu din Motorul de căutare, direct. 
REALM este o metodă care utilizează arbori de dependență semantică pentru a extrage informații din text ambiguu.
Pe web deschis, extragerea informațiilor deschise poate recunoaște noi entități denumite și poate extrage aceleași entități care apar împreună cu alte entități. Aceste co-apariții și atribute reciproce din articol pot atribui un context și un tip de relație candidat între entități. Pe baza conexiunilor și tipului entității, poate fi creat arborele de dependență semantică. Aceeași logică se întâmplă și pentru Semantica Lexicală. Cuvântul „băiat” are unele semnificații posibile și unele exact alte sensuri. Cum ar fi, un băiat este un bărbat și probabil un adolescent care nu este căsătorit. Poate fi folosit și aproape de elev. Cuvântul „regină”, pe de altă parte, include alte sensuri laterale și exacte, cum ar fi „femeie” și „a fi guvernator”. Astfel, a avea ceva de guvernat este o ierarhie naturală a arborelui de dependență semantică care poate semnala anumite tipuri de șabloane de interogare, cum ar fi „Queen of...” sau „For Quen”. These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 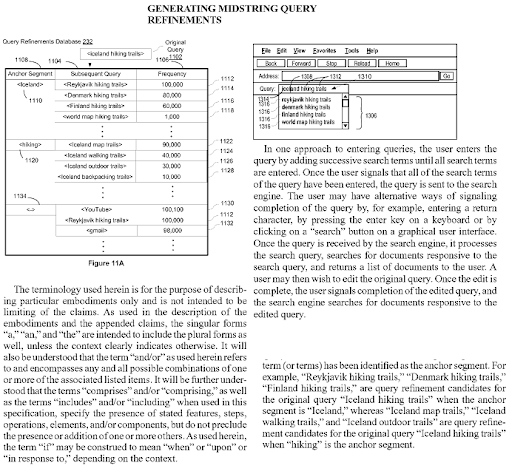
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.