
Controlul accesării cu crawlere și indexării: un ghid SEO pentru Robots.txt și etichete
Publicat: 2019-02-19Optimizarea pentru bugetul de accesare cu crawlere și blocarea roboților din paginile de indexare sunt concepte cunoscute de mulți SEO. Dar diavolul este în detalii. Mai ales că cele mai bune practici s-au modificat semnificativ în ultimii ani.
O mică modificare a unui fișier robots.txt sau a etichetelor robots poate avea un impact dramatic asupra site-ului dvs. web. Pentru a ne asigura că impactul este întotdeauna pozitiv pentru site-ul dvs., astăzi vom aborda:
Optimizarea bugetului de accesare cu crawlere
Ce este un fișier Robots.txt
Ce sunt etichetele Meta Robots
Ce sunt X-Robots-Tags
Directive roboți și SEO
Lista de verificare a celor mai bune practici pentru roboți
Optimizarea bugetului de accesare cu crawlere
Un păianjen de motor de căutare are o „alocație” pentru câte pagini poate și dorește să acceseze cu crawlere pe site-ul dvs. Acest lucru este cunoscut sub denumirea de „buget cu crawl”.
Găsiți bugetul de accesare cu crawlere al site-ului dvs. în raportul „Statistici de accesare cu crawlere” Google Search Console (GSC). Rețineți că GSC este un agregat de 12 roboți care nu sunt toți dedicați SEO. De asemenea, adună roboți AdWords sau AdSense, care sunt roboți SEA. Astfel, acest instrument vă oferă o idee despre bugetul global de accesare cu crawlere, dar nu despre repartiția exactă a acestuia.
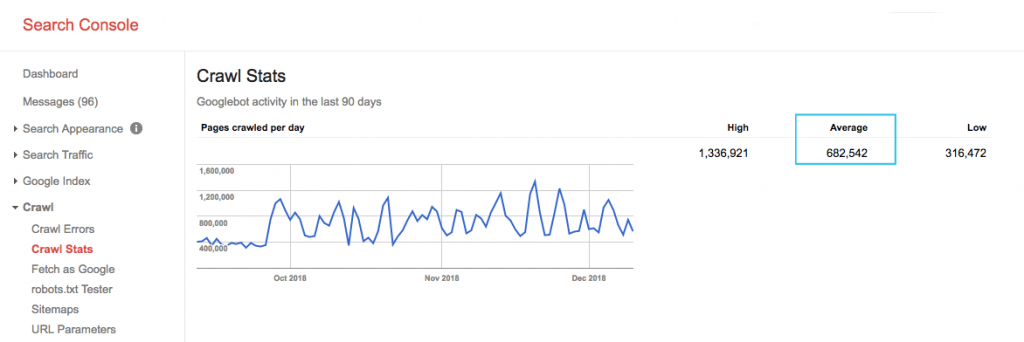
Pentru a face numărul mai ușor de acționat, împărțiți numărul mediu de pagini accesate cu crawlere pe zi la numărul total de pagini care pot fi accesate cu crawlere de pe site-ul dvs. – puteți să cereți dezvoltatorului dvs. numărul sau să rulați un crawler nelimitat. Acest lucru vă va oferi un raport de accesare cu crawlere așteptat pentru care să începeți optimizarea.
Vrei să mergi mai adânc? Obțineți o detaliere mai detaliată a activității Googlebot, cum ar fi ce pagini sunt vizitate, precum și statistici pentru alte crawler-uri, analizând fișierele jurnal ale serverului site-ului dvs.
Există multe modalități de optimizare a bugetului de accesare cu crawlere, dar un loc ușor de început este să verificați raportul GSC „Acoperire” pentru a înțelege comportamentul actual de accesare cu crawlere și indexare al Google.
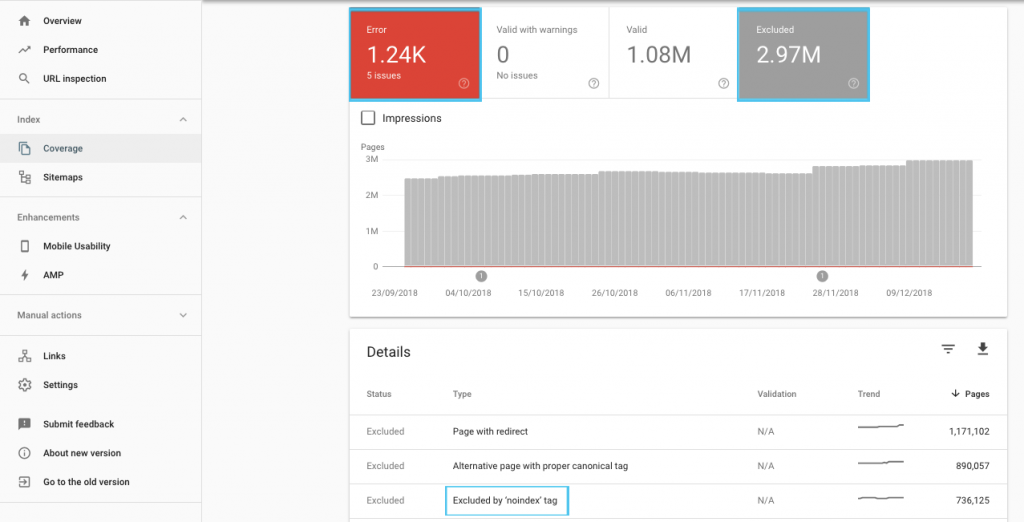
Dacă vedeți erori precum „Adresa URL trimisă marcată cu „noindex”” sau „Adresa URL trimisă blocată de robots.txt”, colaborați cu dezvoltatorul pentru a le remedia. Pentru orice excluderi de roboți, investigați-i pentru a înțelege dacă sunt strategici din perspectiva SEO.
În general, SEO ar trebui să urmărească reducerea la minimum a restricțiilor de accesare cu crawlere la roboți. Îmbunătățirea arhitecturii site-ului dvs. pentru a face URL-urile utile și accesibile pentru motoarele de căutare este cea mai bună strategie.
Înșiși Google observă că „o arhitectură solidă a informațiilor este probabil o utilizare mult mai productivă a resurselor decât concentrarea pe prioritizarea accesului cu crawlere”.
Acestea fiind spuse, este benefic să înțelegeți ce se poate face cu fișierele robots.txt și cu etichetele robots pentru a ghida accesarea cu crawlere, indexarea și transmiterea link-urilor. Și mai important, când și cum să-l folosești cel mai bine pentru SEO modern.
[Studiu de caz] Gestionarea accesării cu crawlere a botului Google
 Citiți studiul de caz
Citiți studiul de cazCe este un fișier Robots.txt
Înainte ca un motor de căutare să acceseze orice pagină, acesta va verifica robots.txt. Acest fișier le spune roboților ce căi URL au permisiunea să le viziteze. Dar aceste înregistrări sunt doar directive, nu mandate.
Robots.txt nu poate împiedica în mod fiabil accesarea cu crawlere ca un firewall sau protecția cu parolă. Este echivalentul digital al unui semn „te rog, nu intra” pe o ușă descuiată.
Crawlerele politicoase, cum ar fi motoarele de căutare majore, vor respecta în general instrucțiunile. Crawlerele ostile, cum ar fi scraper-urile de e-mail, spamboții, programele malware și păianjenii care scanează vulnerabilitățile site-ului, adesea nu acordă atenție.
În plus, este un fișier disponibil public . Oricine vă poate vedea directivele.
Nu utilizați fișierul robots.txt pentru a:
- Pentru a ascunde informațiile sensibile. Utilizați protecția prin parolă.
- Pentru a bloca accesul la site-ul dvs. de organizare și/sau dezvoltare. Utilizați autentificarea pe partea serverului.
- Pentru a bloca în mod explicit crawlerele ostile. Utilizați blocarea IP sau blocarea user-agent (denumită în continuare blocarea unui anumit crawler cu o regulă în fișierul dvs. .htaccess sau un instrument precum CloudFlare).
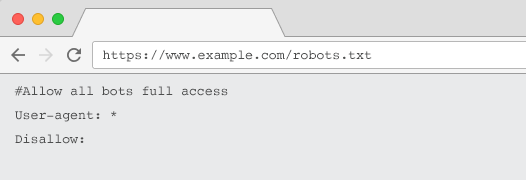
Fiecare site web ar trebui să aibă un fișier robots.txt valid cu cel puțin o grupare de directive. Fără unul, tuturor roboților li se acordă acces complet în mod implicit – astfel încât fiecare pagină este tratată ca accesabilă cu crawlere. Chiar dacă acesta este ceea ce intenționați, este mai bine să clarificați acest lucru pentru toate părțile interesate cu un fișier robots.txt. În plus, fără unul, jurnalele serverului dvs. vor fi pline de cereri eșuate pentru robots.txt.
Structura unui fișier robots.txt
Pentru a fi recunoscut de crawler-uri, robots.txt-ul dvs. trebuie:
- Fii un fișier text numit „robots.txt”. Numele fișierului face distincție între majuscule și minuscule. „Robots.TXT” sau alte variante nu vor funcționa.
- Fiți localizat în directorul de nivel superior al domeniului dvs. canonic și, dacă este relevant, al subdomeniilor. De exemplu, pentru a controla accesarea cu crawlere pe toate adresele URL de sub https://www.example.com, fișierul robots.txt trebuie să fie localizat la https://www.example.com/robots.txt și pentru subdomain.example.com la subdomeniu.example.com/roboți.txt.
- Returnează o stare HTTP de 200 OK.
- Utilizați sintaxă robots.txt validă – Verificați folosind instrumentul de testare robots.txt Google Search Console.
Un fișier robots.txt este format din grupări de directive. Intrările constau în principal din:
- 1. User-agent: Se adresează diferitelor crawler-uri. Puteți avea un singur grup pentru toți roboții sau puteți folosi grupuri pentru a denumi anumite motoare de căutare.
- 2. Disallow: Specifică fișierele sau directoarele care urmează să fie excluse de la accesarea cu crawlere de către agentul utilizator de mai sus. Puteți avea una sau mai multe dintre aceste linii pe bloc.
Pentru o listă completă de nume de agenți de utilizator și mai multe exemple de directive, consultați ghidul robots.txt de pe Yoast.
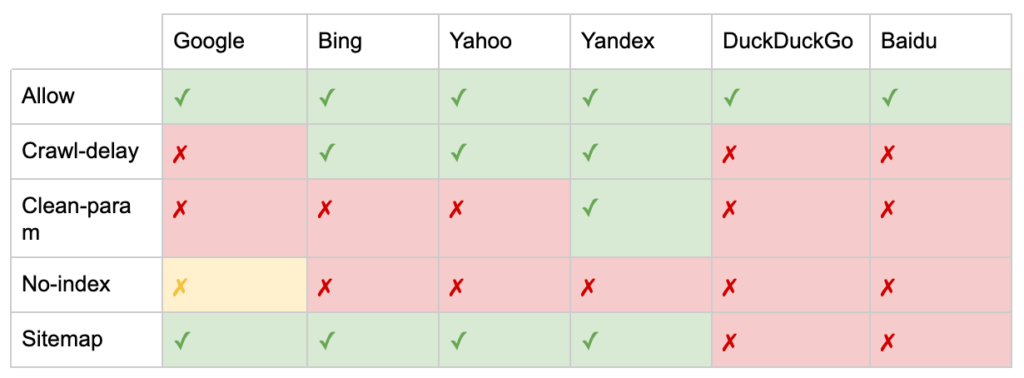
Pe lângă directivele „User-agent” și „Disallow”, există câteva directive non-standard:
- Allow: Specificați excepții de la o directivă disallow pentru un director părinte.
- Întârzierea accesului cu crawlere: accelerați crawlerele grele spunându-le roboților câte secunde să aștepte înainte de a vizita o pagină. Dacă obțineți puține sesiuni organice, întârzierea accesului cu crawlere poate economisi lățimea de bandă a serverului. Dar aș investi efortul numai dacă crawlerele cauzează în mod activ probleme de încărcare a serverului. Google nu acceptă această comandă, oferă opțiunea de a limita rata de accesare cu crawlere în Google Search Console.
- Clean-param: evitați să accesați din nou cu crawlere conținutul duplicat generat de parametrii dinamici.
- Fără index: conceput pentru a controla indexarea fără a utiliza niciun buget de accesare cu crawlere. Nu mai este susținut oficial de Google. Deși există dovezi că poate avea încă un impact, nu este de încredere și nu este recomandat de experți precum John Mueller.
@maxxeight @google @DeepCrawl Aș evita cu adevărat să folosesc noindex acolo.
— ???? Ioan ???? (@JohnMu) 1 septembrie 2015
- Harta site-ului: modalitatea optimă de a trimite harta site-ului dvs. XML este prin Google Search Console și Instrumentele pentru webmasteri ale altor motoare de căutare. Cu toate acestea, adăugarea unei directive de hartă de site la baza fișierului robots.txt ajută alți crawler-uri care s-ar putea să nu ofere o opțiune de trimitere.
Limitările robots.txt pentru SEO
Știm deja că robots.txt nu poate împiedica accesarea cu crawlere pentru toți roboții. De asemenea, interzicerea crawlerelor dintr-o pagină nu împiedică includerea acesteia în paginile cu rezultate ale motorului de căutare (SERP-uri).
Dacă o pagină blocată are alte semnale puternice de clasare, Google poate considera că este relevant să fie afișat în rezultatele căutării. În ciuda faptului că nu ați accesat pagina cu crawlere.
Deoarece conținutul acelei adrese URL este necunoscut de Google, rezultatul căutării arată astfel:

Pentru a bloca definitiv apariția unei pagini în SERP-uri, trebuie să utilizați o metaetichetă roboți „noindex” sau un antet HTTP X-Robots-Tag.
În acest caz, nu permiteți pagina în robots.txt , deoarece pagina trebuie accesată cu crawlere pentru ca eticheta „noindex” să fie văzută și respectată. Dacă adresa URL este blocată, toate etichetele roboților sunt ineficiente.
În plus, dacă o pagină a acumulat o mulțime de link-uri de intrare, dar Google este blocat să acceseze cu crawlere acele pagini prin robots.txt, în timp ce linkurile sunt cunoscute de Google, se pierde capitalul link -urilor.
Ce sunt etichetele Meta Robots
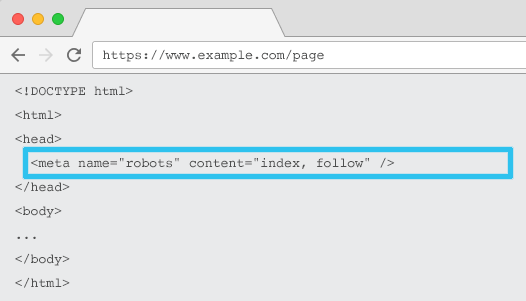
Plasat în codul HTML al fiecărei adrese URL, meta name="roboți" le spune crawlerilor dacă și cum să „indexeze” conținutul și dacă să „urmărească” (adică să acceseze cu crawlere) toate linkurile de pe pagină, transmițând echitatea link-urilor.
Folosind meta name-ul general = „roboți”, directiva se aplică tuturor crawlerelor. De asemenea, puteți specifica un anumit agent utilizator. De exemplu, meta name="googlebot". Dar este rar să fie nevoie să folosiți mai multe meta-roboți pentru a seta instrucțiuni pentru anumiți păianjeni.
Există două considerații importante atunci când utilizați etichetele meta robots:
- Similar cu robots.txt, metaetichetele sunt directive, nu mandate, deci pot fi ignorate de unii roboți.
- Directiva robots nofollow se aplică numai linkurilor de pe pagina respectivă. Este posibil ca un crawler să urmărească linkul de pe altă pagină sau site web fără un nofollow. Deci botul poate ajunge și indexa pagina dvs. nedorită.
Iată lista tuturor directivelor meta robots tag:
- index: Spune motoarele de căutare să afișeze această pagină în rezultatele căutării. Aceasta este starea implicită dacă nu este specificată nicio directivă.
- noindex: Spune motoarele de căutare să nu arate această pagină în rezultatele căutării.
- follow: Spune motoarele de căutare să urmeze toate linkurile de pe această pagină și să treacă echitate, chiar dacă pagina nu este indexată. Aceasta este starea implicită dacă nu este specificată nicio directivă.
- nofollow: Spune motoarelor de căutare să nu urmeze niciun link de pe această pagină sau să nu treacă capitalul propriu.
- all: Echivalent cu „index, follow”.
- none: echivalent cu „noindex, nofollow”.
- noimageindex: Spune motoarelor de căutare să nu indexeze nicio imagine de pe această pagină.
- noarchive: Spune motoarele de căutare să nu afișeze un link stocat în cache către această pagină în rezultatele căutării.
- nocache: La fel ca noarchive, dar folosit doar de Internet Explorer și Firefox.
- nosnippet: le spune motoarelor de căutare să nu afișeze o meta-descriere sau o previzualizare video pentru această pagină în rezultatele căutării.
- notranslate: Spune motorului de căutare să nu ofere traducerea acestei pagini în rezultatele căutării.
- unavailable_after: Spuneți motoarelor de căutare să nu mai indexeze această pagină după o dată specificată.
- noodp: Acum depreciat, a împiedicat odată motoarele de căutare să folosească descrierea paginii din DMOZ în rezultatele căutării.
- noydir: Acum depreciat, a împiedicat odată Yahoo să folosească descrierea paginii din directorul Yahoo în rezultatele căutării.
- noyaca: Împiedică Yandex să folosească descrierea paginii din directorul Yandex în rezultatele căutării.
După cum a documentat Yoast, nu toate motoarele de căutare acceptă toate metaetichetele roboților sau chiar sunt clare ce fac și ce nu acceptă.
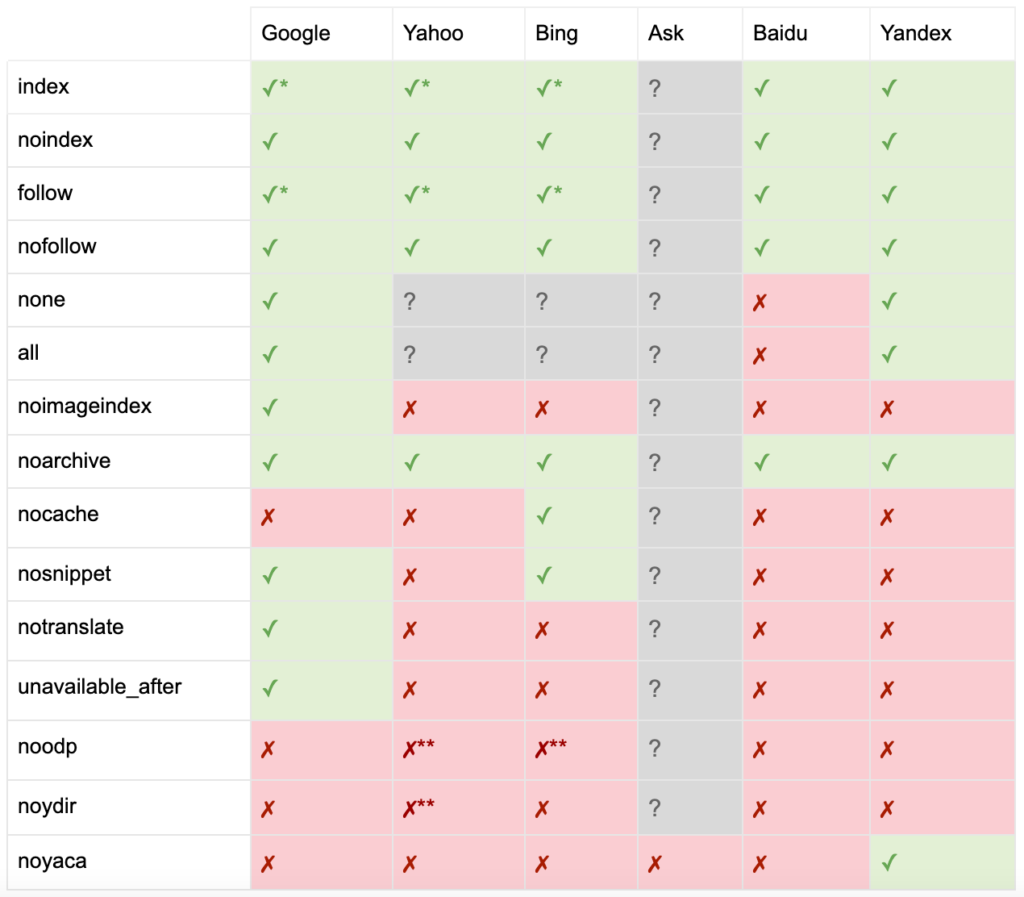
* Majoritatea motoarelor de căutare nu au documentație specifică pentru acest lucru, dar se presupune că suportul pentru excluderea parametrilor (de exemplu, nofollow) implică suport pentru echivalentul pozitiv (de exemplu, follow).
** În timp ce atributele noodp și noydir pot fi încă „suportate”, directoarele nu mai există și este probabil ca aceste valori să nu facă nimic.

De obicei, etichetele roboților vor fi setate la „indexare, urmărire”. Unii SEO văd adăugarea acestei etichete în HTML ca fiind redundantă, deoarece este implicită. Contraargumentul este că o specificare clară a directivelor poate ajuta la evitarea oricărei confuzii umane.
Rețineți: adresele URL cu eticheta „noindex” vor fi accesate cu crawlere mai rar și, dacă sunt prezente pentru o perioadă lungă de timp, vor determina în cele din urmă Google să nu urmărească linkurile paginii.
Este rar să găsești un caz de utilizare pentru a „nofollow” toate linkurile dintr-o pagină cu o etichetă meta robots. Este mai frecvent să vedeți „nofollow” adăugat pe link- uri individuale folosind un atribut de link rel="nofollow”. De exemplu, poate doriți să luați în considerare adăugarea unui atribut rel="nofollow" la comentariile generate de utilizatori sau linkurile plătite.
Este și mai rar să existe un caz de utilizare SEO pentru directivele etichetelor roboților care nu abordează indexarea de bază și urmăresc comportamentul, cum ar fi stocarea în cache, indexarea imaginilor și gestionarea fragmentelor etc.
Provocarea cu etichetele meta roboți este că acestea nu pot fi utilizate pentru fișiere non-HTML, cum ar fi imagini, videoclipuri sau documente PDF. Aici puteți apela la X-Robots-Tags.
Ce sunt X-Robots-Tags
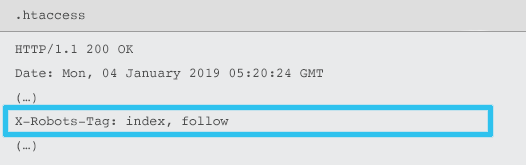
X-Robots-Tag sunt trimise de server ca element al antetului de răspuns HTTP pentru o anumită adresă URL folosind fișiere .htaccess și httpd.conf.
Orice directivă de metaetichetă a roboților poate fi specificată și ca o etichetă X-Robots. Cu toate acestea, un X-Robots-Tag oferă o oarecare flexibilitate și funcționalitate suplimentară.
Ați folosi X-Robots-Tag peste etichetele meta roboți dacă doriți:
- Controlați comportamentul roboților pentru fișierele non-HTML, mai degrabă decât fișierele HTML numai.
- Controlați indexarea unui anumit element al unei pagini, mai degrabă decât a paginii în ansamblu.
- Adăugați reguli dacă o pagină ar trebui sau nu să fie indexată. De exemplu, dacă un autor are mai mult de 5 articole publicate, indexați pagina de profil.
- Aplicați indexați și urmați directivele la nivel de site, mai degrabă decât specifice paginii.
- Folosiți expresii regulate.
Evitați utilizarea atât a meta-roboților, cât și a etichetei x-robots pe aceeași pagină - ar fi redundant.
Pentru a vizualiza X-Robots-Tags, puteți utiliza funcția „Preluare ca Google” din Google Search Console.
Directive roboți și SEO
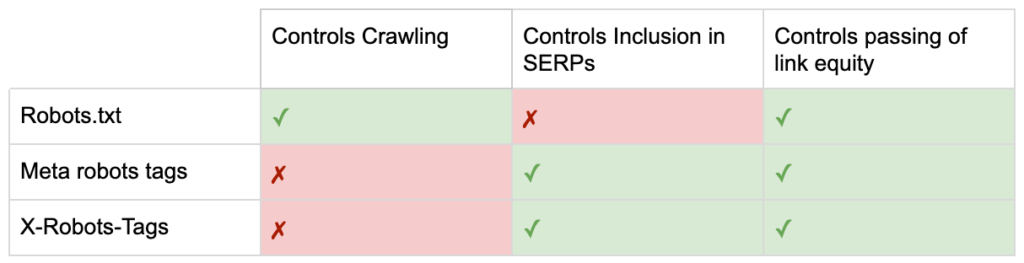
Deci acum cunoașteți diferențele dintre cele trei directive roboți.
robots.txt se concentrează pe economisirea bugetului de accesare cu crawlere, dar nu va împiedica afișarea unei pagini în rezultatele căutării. Acesta acționează ca primul gatekeeper al site-ului dvs., direcționând roboților să nu acceseze înainte ca pagina să fie solicitată.
Ambele tipuri de etichete de roboți se concentrează pe controlul indexării și transmiterii echității link-urilor. Metaetichetele Robots sunt eficiente numai după ce pagina sa încărcat . În timp ce anteturile X-Robots-Tag oferă un control mai granular și sunt eficiente după ce serverul răspunde la o solicitare de pagină.
Cu această înțelegere, SEO pot evolua modul în care folosim directivele roboților pentru a rezolva provocările de crawling și indexare.
Blocarea botilor pentru a salva lățimea de bandă a serverului
Problemă: Analizând fișierele de jurnal, veți vedea mulți agenți de utilizator care iau lățime de bandă, dar oferă puțină valoare înapoi.
- Crawlerele SEO, cum ar fi MJ12bot (de la Majestic) sau Ahrefsbot (de la Ahrefs).
- Instrumente care salvează offline conținut digital, cum ar fi Webcopier sau Teleport.
- Motoarele de căutare care nu sunt relevante pe piața dvs., cum ar fi Baiduspider sau Yandex.
Soluție suboptimală: blocarea acestor păianjeni cu robots.txt, deoarece nu este garantat să fie onorat și este o declarație destul de publică, care ar putea oferi părților interesate perspective competitive.
Abordarea celor mai bune practici: directiva mai subtilă de blocare a user-agent. Acest lucru poate fi realizat în diferite moduri, dar de obicei se face prin editarea fișierului .htaccess pentru a redirecționa orice solicitări spider nedorite către o pagină 403 – Interzis.
Pagini interne de căutare pe site folosind bugetul de accesare cu crawlere
Problemă: pe multe site-uri web, paginile interne cu rezultatele căutării pe site-uri sunt generate dinamic pe adrese URL statice, care consumă apoi bugetul de accesare cu crawlere și pot cauza conținut redus sau probleme de conținut duplicat dacă sunt indexate.
Soluție suboptimă: nu permiteți directorul cu robots.txt. Deși acest lucru poate preveni capcanele cu crawler, vă limitează capacitatea de a vă clasa pentru căutările cheie ale clienților și pentru ca astfel de pagini să treacă link-uri.
Abordarea celor mai bune practici: Hartați interogări relevante, cu volum mare, către adresele URL existente pentru motoarele de căutare. De exemplu, dacă caut „telefon Samsung”, în loc să creez o pagină nouă pentru /search/samsung-phone, redirecționez către /phones/samsung.
Acolo unde acest lucru nu este posibil, creați o adresă URL bazată pe parametri. Apoi, puteți specifica cu ușurință dacă doriți ca parametrul să fie accesat cu crawlere sau nu în Google Search Console.
Dacă permiteți accesarea cu crawlere, analizați dacă astfel de pagini sunt de o calitate suficient de înaltă pentru a fi clasate. Dacă nu, adăugați o directivă „noindex, follow” ca soluție pe termen scurt în timp ce stabiliți o strategie pentru a îmbunătăți calitatea rezultatelor pentru a ajuta atât SEO, cât și experiența utilizatorului.
Blocarea parametrilor cu roboți
Problemă: parametrii șirului de interogări, cum ar fi cei generați de navigarea fațetă sau de urmărire, sunt notori pentru consumarea bugetului de accesare cu crawlere, crearea de adrese URL de conținut duplicat și împărțirea semnalelor de clasare.
Soluție suboptimală: nu permiteți accesarea cu crawlere a parametrilor cu robots.txt sau cu o metaetichetă robots „noindex”, deoarece ambele (prima imediat, cea mai târziu pe o perioadă mai lungă) vor împiedica fluxul de echitate a linkurilor.
Abordare de cea mai bună practică: Asigurați-vă că fiecare parametru are un motiv clar pentru a exista și implementați reguli de ordonare, care folosesc cheile o singură dată și împiedică valorile goale. Adăugați un atribut rel=canonical link la paginile cu parametri adecvate pentru a combina capacitatea de clasare. Apoi configurați toți parametrii în Google Search Console, unde există opțiuni mai detaliate pentru a comunica preferințele de crawling. Pentru mai multe detalii, consultați ghidul de gestionare a parametrilor din Search Engine Journal.
Blocarea zonelor de administrare sau de cont
Problemă: împiedicați motorul de căutare să acceseze cu crawlere și să indexeze orice conținut privat.
Soluție suboptimală: utilizarea robots.txt pentru a bloca directorul, deoarece nu este garantat să păstrați paginile private în afara SERP-urilor.
Abordarea celor mai bune practici: utilizați protecția cu parolă pentru a preveni accesarea crawlerilor la pagini și o retragere a directivei „noindex” în antetul HTTP.
Blocarea paginilor de destinație de marketing și a paginilor de mulțumire
Problemă: de multe ori trebuie să excludeți adresele URL care nu sunt destinate căutării organice, cum ar fi e-mailurile dedicate sau paginile de destinație ale campaniilor CPC. De asemenea, nu doriți ca oamenii care nu s-au convertit să vă viziteze paginile de mulțumire prin intermediul SERP-urilor.
Soluție suboptimală: nu permiteți fișierele cu robots.txt, deoarece acest lucru nu va împiedica includerea linkului în rezultatele căutării.
Abordarea celor mai bune practici: utilizați o metaetichetă „noindex”.
Gestionați conținutul duplicat la fața locului
Problemă: Unele site-uri web au nevoie de o copie a unui anumit conținut din motive legate de experiența utilizatorului, cum ar fi o versiune a unei pagini pentru imprimantă, dar doresc să se asigure că pagina canonică, nu pagina duplicată, este recunoscută de motoarele de căutare. Pe alte site-uri web, conținutul duplicat se datorează unor practici slabe de dezvoltare, cum ar fi redarea aceluiași articol spre vânzare pe adrese URL de mai multe categorii.
Soluție suboptimală: interzicerea adreselor URL cu robots.txt va împiedica transmiterea paginii duplicate de-a lungul oricăror semnale de clasare. Noindexarea pentru roboți va duce în cele din urmă la Google să trateze linkurile ca „nofollow”, va împiedica pagina duplicată să transmită orice link-uri.
Abordarea celor mai bune practici: dacă conținutul duplicat nu are niciun motiv să existe, eliminați sursa și redirecționați 301 către adresa URL prietenoasă pentru motorul de căutare. Dacă există un motiv pentru a exista, adăugați un atribut rel=canonical link pentru consolidarea semnalelor de clasare.
Conținut subțire al paginilor accesibile contului
Problemă: Paginile legate de cont, cum ar fi autentificarea, înregistrarea, coșul de cumpărături, finalizarea comenzii sau formularele de contact, sunt adesea ușor de conținut și oferă o valoare mică pentru motoarele de căutare, dar sunt necesare pentru utilizatori.
Soluție suboptimală: nu permiteți fișierele cu robots.txt, deoarece acest lucru nu va împiedica includerea linkului în rezultatele căutării.
Abordarea celor mai bune practici: pentru majoritatea site-urilor web, aceste pagini ar trebui să fie foarte puține la număr și este posibil să nu observați niciun impact KPI al implementării manipulării roboților. Dacă simțiți nevoia, cel mai bine este să utilizați o directivă „noindex”, cu excepția cazului în care există interogări de căutare pentru astfel de pagini.
Etichetați paginile utilizând bugetul de accesare cu crawlere
Problemă: etichetarea necontrolată consumă bugetul de accesare cu crawlere și adesea duce la probleme de conținut redus.
Soluții suboptimale: interzicerea utilizării robots.txt sau adăugarea unei etichete „noindex”, deoarece ambele vor împiedica clasarea etichetelor relevante pentru SEO și (imediat sau eventual) vor împiedica transmiterea echității link-urilor.
Abordarea celor mai bune practici: evaluați valoarea fiecăreia dintre etichetele dvs. actuale. Dacă datele arată că pagina adaugă puțină valoare motoarelor de căutare sau utilizatorilor, 301 îi redirecționează. Pentru paginile care supraviețuiesc sacrificării, lucrați pentru a îmbunătăți elementele de pe pagină, astfel încât acestea să devină valoroase atât pentru utilizatori, cât și pentru roboți.
Accesarea cu crawlere a JavaScript și CSS
Problemă: Anterior, roboții nu puteau accesa cu crawlere JavaScript și alte conținuturi rich media. Acest lucru s-a schimbat și acum este recomandat să permiteți motoarele de căutare să acceseze fișierele JS și CSS pentru a reda opțional paginile.
Soluție suboptimală: interzicerea fișierelor JavaScript și CSS cu robots.txt pentru a economisi bugetul de accesare cu crawlere poate duce la o indexare slabă și poate avea un impact negativ asupra clasamentelor. De exemplu, blocarea accesului motorului de căutare la JavaScript care difuzează o reclamă interstițială sau redirecționarea utilizatorilor poate fi considerată ca desimulare.
Abordarea celor mai bune practici: verificați dacă există probleme de randare cu instrumentul „Preluare ca Google” sau obțineți o imagine de ansamblu rapidă a resurselor blocate cu raportul „Resurse blocate”, ambele disponibile în Google Search Console. Dacă sunt blocate resurse care ar putea împiedica motoarele de căutare să redea corect pagina, eliminați codul robots.txt disallow.
Oncrawl SEO Crawler
 Află mai multe
Află mai multeLista de verificare a celor mai bune practici pentru roboți
Este înfricoșător de comun ca un site web să fi fost eliminat accidental de pe Google de o eroare de control al roboților.
Cu toate acestea, manipularea roboților poate fi un plus puternic pentru arsenalul tău SEO atunci când știi cum să-l folosești. Doar asigurați-vă că procedați cu înțelepciune și prudență.
Pentru a vă ajuta, iată o listă de verificare rapidă:
- Securizează informațiile private utilizând protecția prin parolă
- Blocați accesul la site-urile de dezvoltare folosind autentificarea pe server
- Restricționați crawlerele care folosesc lățime de bandă, dar oferă puțină valoare înapoi cu blocarea user-agent
- Asigurați-vă că domeniul principal și orice subdomeniu au un fișier text numit „robots.txt” în directorul de nivel superior, care returnează un cod 200
- Asigurați-vă că fișierul robots.txt are cel puțin un bloc cu o linie user-agent și o linie interzisă
- Asigurați-vă că fișierul robots.txt are cel puțin o linie de hartă a site-ului, introdusă ca ultima linie
- Validați fișierul robots.txt în testerul robots.txt GSC
- Asigurați-vă că fiecare pagină indexabilă își specifică directivele etichetelor roboți
- Asigurați-vă că nu există directive contradictorii sau redundante între robots.txt, metaetichetele robots, X-Robots-Tags, fișierul .htaccess și manipularea parametrilor GSC
- Remediați erorile „Adresa URL trimisă marcată cu „noindex”” sau „Adresa URL trimisă blocată de robots.txt” din raportul de acoperire GSC
- Înțelegeți motivul oricăror excluderi legate de roboți în raportul de acoperire GSC
- Asigurați-vă că numai paginile relevante sunt afișate în raportul GSC „Resurse blocate”.
Verifică-ți roboții și asigură-te că o faci corect.