
Crawling, indexare și Python: tot ce trebuie să știți
Publicat: 2021-05-31Aș dori să încep acest articol cu o ecuație foarte simplă: dacă paginile tale nu sunt accesate cu crawlere, ele nu vor fi niciodată indexate și, prin urmare, performanța ta SEO va avea întotdeauna de suferit (și va împuțita).
Ca o consecință a acestui fapt, SEO trebuie să se străduiască să găsească cea mai bună modalitate de a face site-urile lor accesabile cu crawlere și de a oferi Google cele mai importante pagini ale lor pentru a le indexa și a începe să obțină trafic prin intermediul lor.
Din fericire, avem multe resurse care ne pot ajuta să îmbunătățim accesul la crawlere a site-ului nostru web, cum ar fi Screaming Frog, Oncrawl sau Python. Îți voi arăta cum te poate ajuta Python să analizezi și să-ți îmbunătățești indicatorii de indexare și ușurință pentru crawling. De cele mai multe ori, aceste tipuri de îmbunătățiri conduc, de asemenea, la o clasare mai bună, o vizibilitate mai mare în SERP-uri și, în cele din urmă, mai mulți utilizatori care ajung pe site-ul dvs.
1. Solicitarea de indexare cu Python
1.1. Pentru Google
Solicitarea de indexare pentru Google se poate face în mai multe moduri, deși, din păcate, nu sunt foarte convins de niciunul dintre ele. Vă voi prezenta trei opțiuni diferite cu avantajele și dezavantajele lor:
- Selenium și Google Search Console: din punctul meu de vedere și după ce l-am testat și restul opțiunilor, aceasta este soluția cea mai eficientă. Cu toate acestea, după mai multe încercări, este posibil să apară un pop-up captcha care îl va sparge.
- Pingul unui sitemap: cu siguranță ajută ca sitemapurile să fie accesate cu crawlere așa cum este solicitat, dar nu adrese URL specifice, de exemplu în cazul în care au fost adăugate pagini noi pe site.
- Google Indexing API: nu este foarte fiabil, cu excepția radiodifuzorilor și a site-urilor web ale platformelor de locuri de muncă. Ajută la creșterea ratelor de accesare cu crawlere, dar nu la indexarea anumitor adrese URL.
După această scurtă prezentare generală despre fiecare metodă, haideți să le aruncăm pe rând pe rând.
1.1.1. Selenium și Google Search Console
În esență, ceea ce vom face în această primă soluție este să accesăm Google Search Console dintr-un browser cu Selenium și să replicăm același proces pe care l-am urma manual pentru a trimite multe URL-uri pentru indexare cu Google Search Console, dar într-un mod automat.
Notă: nu abuzați de această metodă și trimiteți o pagină pentru indexare numai dacă conținutul acesteia a fost actualizat sau dacă pagina este complet nouă.
Trucul pentru a vă putea conecta la Google Search Console cu Selenium este să accesați mai întâi OUATH Playground, așa cum am explicat în acest articol despre cum să automatizați descărcarea raportului GSC cu crawlere.
#Importăm aceste module
timpul de import
de la selenium import webdriver
din webdriver_manager.chrome import ChromeDriverManager
din selenium.webdriver.common.keys import Keys
#Instalăm driverul nostru Selenium
driver = webdriver.Chrome(ChromeDriverManager().install())
#Accesăm contul OUATH pentru a vă conecta la Serviciile Google
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=40740871819google.contents.google.com .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#Așteptăm puțin pentru a ne asigura că randarea este completă înainte de a selecta elemente cu Xpath și de a introduce adresa noastră de e-mail.
timp.somn (10)
form1=driver.find_element_by_xpath('//*[@]')
form1.send_keys(„<adresa ta de e-mail>”)
form1.send_keys(Taste.ENTER)
#La fel și aici, așteptăm puțin și apoi introducem parola noastră.
timp.somn (10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys(„<parola ta>”)
form2.send_keys(Taste.ENTER)
După aceea, putem accesa adresa URL a Google Search Console:
driver.get('https://search.google.com/search-console?resource_id=your_domain”')
timp.somn(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /div[1]/input[2]')
box.send_keys(„URL_dvs”)
box.send_keys(Taste.ENTER)
timp.somn(5)
indexare = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexation.click()
timp.somn(120)
Din păcate, așa cum sa explicat în introducere, se pare că după o serie de solicitări începe să necesite un captcha puzzle pentru a continua cu cererea de indexare. Deoarece metoda automată nu poate rezolva captcha, acesta este ceva care handicapează această soluție.
1.1.2. Ping-ul unui sitemap
Adresele URL ale sitemapului pot fi trimise la Google prin metoda ping. Practic, ar trebui doar să faceți o solicitare către următorul punct final, introducând adresa URL a sitemapului dvs. ca parametru:
http://www.google.com/ping?sitemap=URL/of/file
Acest lucru poate fi automatizat foarte ușor cu Python și solicitări, așa cum am explicat în acest articol.
import urllib.request url = „http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml” răspuns = urllib.request.urlopen(url)
1.1.3. API-ul de indexare Google
API-ul de indexare Google poate fi o soluție bună pentru a vă îmbunătăți ratele de accesare cu crawlere, dar de obicei nu este o metodă foarte eficientă de a vă indexa conținutul, deoarece ar trebui să fie utilizat numai dacă site-ul dvs. are fie JobPosting, fie BroadcastEvent încorporat într-un VideoObject. Cu toate acestea, dacă doriți să îl încercați și să îl testați singur, puteți urma următorii pași.
În primul rând, pentru a începe cu acest API, trebuie să accesați Google Cloud Console, să creați un proiect și o autentificare pentru contul de serviciu. După aceea, va trebui să activați API-ul de indexare din Bibliotecă și să adăugați contul de e-mail care este dat cu acreditările contului de serviciu ca proprietar de proprietate pe Google Search Console. Poate fi necesar să utilizați versiunea veche a Google Search Console pentru a putea adăuga această adresă de e-mail ca proprietar de proprietate.
Odată ce urmați pașii anteriori, veți putea începe să cereți indexarea și deindexarea cu acest API utilizând următoarea bucată de cod:
din oauth2client.service_account import ServiceAccountCredentials
import httplib2
SCOPES = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = „https://indexing.googleapis.com/v3/urlNotifications:publish”
client_secrets = „path_to_your_credentials.json”
credentials = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
dacă credentials este None sau credentials.invalid:
acreditări = tools.run_flow(flow, storage)
http = credentials.authorize(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
pentru iterație în interval (len(list_urls)):
continut = '''{
'url': "'''+str(list_urls[iteration])+'''",
„tip”: „URL_UPDATED”
}'''
răspuns, conținut = http.request(ENDPOINT, method="POST", corp=conținut)
imprimare (răspuns)
imprimare (conținut)Dacă doriți să solicitați dezindexarea, va trebui să schimbați tipul de solicitare din „URL_UPDATED” în „URL_DELETED”. Partea anterioară de cod va tipări răspunsurile de la API cu orele de notificare și stările acestora. Dacă starea este 200, atunci cererea va fi făcută cu succes.
1.2. Pentru Bing
De foarte multe ori când vorbim despre SEO ne gândim doar la Google, dar nu putem uita că în unele piețe există și alte motoare de căutare predominante și/sau alte motoare de căutare care au o cotă de piață respectabilă precum Bing.
Este important de menționat de la început că Bing are deja o funcție foarte convenabilă pe Bing Webmaster Tools, care vă permite să solicitați trimiterea a până la 10.000 de adrese URL pe zi în majoritatea cazurilor. Uneori, cota zilnică poate fi mai mică de 10.000 de adrese URL, dar aveți opțiunea de a solicita o creștere a cotei dacă credeți că veți avea nevoie de o cotă mai mare pentru a vă satisface nevoile. Puteți citi mai multe despre acest lucru pe această pagină.
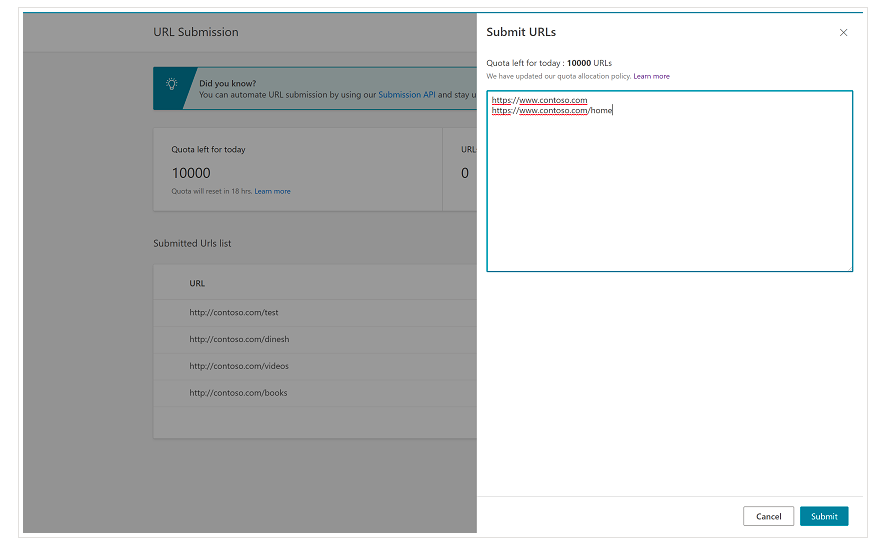
Această funcție este într-adevăr foarte convenabilă pentru trimiterile de adrese URL în bloc, deoarece va trebui doar să introduceți adresele URL în rânduri diferite în instrumentul de trimitere URL din interfața normală a Instrumentelor pentru webmasteri Bing.
1.2.1. API-ul de indexare Bing
Bing Indexing API poate fi folosit cu o cheie API care trebuie introdusă ca parametru. Această cheie API poate fi obținută pe Bing Webmaster Tools, mergând la secțiunea de acces API și după aceea, generând cheia API.
Odată ce cheia API a fost obținută, ne putem juca cu API-ul cu următorul cod (ar trebui doar să adăugați cheia API și adresa URL a site-ului):
cereri de import
list_urls = ["https://www.example.com", "https://www.example/test2/"]
pentru y în list_urls:
url = „https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey”
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
headers = {'Content-type': 'application/json; set de caractere=utf-8'}
x = requests.post(url, data=myobj, headers=headers)
print(str(y) + ": " + str(x))Aceasta va tipări adresa URL și codul său de răspuns la fiecare iterație. Spre deosebire de Google Indexing API, acest API poate fi folosit pentru orice fel de site web.
[Studiu de caz] Creșteți vizibilitatea prin îmbunătățirea accesării cu crawlere a site-ului web pentru Googlebot
 Citiți studiul de caz
Citiți studiul de caz2. Analiza, crearea și încărcarea sitemapurilor
După cum știm cu toții, hărțile de site sunt elemente foarte utile pentru a oferi roboților motoarelor de căutare adresele URL pe care am dori să le acceseze cu crawlere. Pentru a le permite roboților motoarelor de căutare să știe unde se află hărțile noastre de site, acestea trebuie să fie încărcate în Google Search Console și Bing Webmaster Tools și incluse în fișierul robots.txt pentru restul roboților.
Cu Python putem lucra în principal pe trei aspecte diferite legate de sitemap-urile: analiza acestora, crearea și încărcarea și ștergerea din Google Search Console.
2.1. Importarea și analiza sitemapului cu Python
Advertools este o bibliotecă grozavă creată de Elias Dabbas, care poate fi folosită pentru importul de sitemap, precum și pentru multe alte sarcini SEO. Veți putea importa sitemap-uri în Dataframes doar folosind:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
Această bibliotecă acceptă hărți de site XML obișnuite, hărți de site de știri și hărți de site video.
Pe de altă parte, dacă sunteți interesat doar să importați adresele URL de pe harta site-ului, puteți utiliza și solicitările bibliotecii și BeautifulSoup.
cereri de import
de la bs4 import BeautifulSoup
r = requests.get("https://www.example.com/your_sitemap.xml")
xml = r.text
supă = BeautifulSoup (xml)
urls = soup.find_all("loc")
urls = [[x.text] pentru x în urls]
Odată ce harta site-ului a fost importată, vă puteți juca cu adresele URL extrase și puteți efectua o analiză de conținut, așa cum a explicat Koray Tugberk în acest articol.
2.2. Crearea de sitemap-uri cu Python
De asemenea, puteți utiliza Python pentru a crea sitemaps.xml dintr-o listă de adrese URL, așa cum a explicat JC Chouinard în acest articol. Acest lucru poate fi util în special pentru site-urile web foarte dinamice ale căror adrese URL se schimbă rapid și, împreună cu metoda ping care a fost explicată mai sus, poate fi o soluție excelentă pentru a oferi Google noile adrese URL și pentru a le accesa cu crawlere și indexează rapid.
Recent, Greg Bernhardt a creat și o aplicație cu Streamlit și Python pentru a genera sitemap-uri.
2.3. Încărcarea și ștergerea sitemapurilor din Google Search Console
Google Search Console are un API care poate fi folosit în principal în două moduri diferite: pentru a extrage date despre performanța web și pentru a gestiona sitemap-urile. În această postare, ne vom concentra asupra opțiunii de încărcare și ștergere a sitemapurilor.
În primul rând, este important să creați sau să utilizați un proiect existent din Google Cloud Console pentru a obține o autentificare OUATH și pentru a activa serviciul Google Search Console. JC Chouinard explică foarte bine pașii pe care trebuie să-i urmezi pentru a accesa API-ul Google Search Console cu Python și cum să faci prima ta cerere în acest articol. Practic, putem folosi complet codul său, dar doar introducând o modificare, în domenii vom adăuga „https://www.googleapis.com/auth/webmasters” în loc de „https://www.googleapis.com”. /auth/webmasters.readonly”, deoarece vom folosi API-ul nu numai pentru a citi, ci și pentru a încărca și șterge sitemap-uri.

Odată ce ne conectăm cu API-ul, putem începe să ne jucăm cu acesta și să listăm toate hărțile de site din proprietățile noastre Google Search Console cu următoarea bucată de cod:
pentru site_url în verified_sites_urls:
imprimare (site_url)
# Preluați lista de sitemap-uri trimise
sitemaps = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
dacă „sitemap” în sitemap:
sitemap_urls = [s['cale'] pentru s în sitemap['sitemap']]
print (" " + "\n ".join(sitemap_urls))
Când vine vorba de sitemap-uri specifice, putem face trei sarcini pe care le vom elabora în secțiunile următoare: încărcarea, ștergerea și solicitarea de informații.
2.3.1. Încărcarea unui sitemap
Pentru a încărca un sitemap cu Python, trebuie doar să specificăm adresa URL a site-ului și calea sitemap-ului și să rulăm această bucată de cod:
WEBSITE = „proprietatea dvs. GSC” SITEMAP_PATH = „https://www.example.com/page-sitemap.xml” webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2. Ștergerea unui sitemap
Cealaltă parte a monedei este momentul în care am dori să ștergem un sitemap. De asemenea, putem șterge hărțile de site din Google Search Console cu Python folosind metoda „șterge” în loc de „trimite”.
WEBSITE = „proprietatea dvs. GSC” SITEMAP_PATH = „https://www.example.com/page-sitemap.xml” webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3. Solicitarea de informații de pe sitemap-urile
În sfârșit, putem solicita informații și de pe harta site-ului folosind metoda „get”.
WEBSITE = „proprietatea dvs. GSC” SITEMAP_PATH = „https://www.example.com/page-sitemap.xml” webmasters_service.sitemaps().get(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
Acest lucru va returna un răspuns în format JSON, cum ar fi: 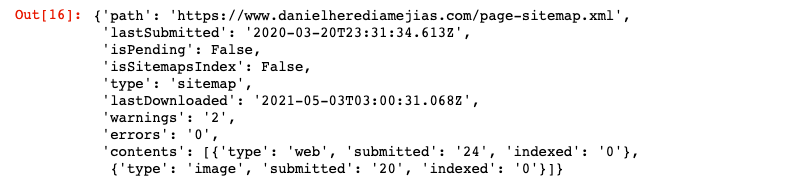
3. Analiza internă a legăturilor și oportunități
A avea o structură internă adecvată de legături este foarte utilă pentru a facilita accesarea cu crawlere a site-ului dvs. de către roboții motoarelor de căutare. Unele dintre principalele probleme pe care le-am întâlnit în urma auditării unui număr de site-uri web cu setări tehnice foarte sofisticate sunt:
- Link-uri introduse cu evenimente on-click: pe scurt, Googlebot nu face clic pe butoane, deci dacă linkurile dvs. sunt inserate cu un eveniment on-click, Googlebot nu le va putea urmări.
- Link-uri randate pe partea clientului: în ciuda faptului că Googlebot și alte motoare de căutare devin mult mai bune la executarea JavaScript, este încă ceva destul de dificil pentru ei, așa că este mult mai bine să redați aceste link-uri pe partea de server și să le serviți în HTML brut pentru roboții motoarelor de căutare decât să se aștepte ca ei să execute scripturi JavaScript.
- Ferestre pop-up de conectare și/sau de vârstă: ferestrele pop-up de conectare și porțile de vârstă pot împiedica roboții motoarelor de căutare să acceseze cu crawlere conținutul care se află în spatele acestor „obstacole”.
- Utilizarea excesivă a atributelor Nofollow: utilizarea multor atribute nofollow care indică către pagini interne valoroase va împiedica roboții motoarelor de căutare să le acceseze cu crawlere.
- Noindex și follow: din punct de vedere tehnic, combinația dintre noindex și follow directive ar trebui să permită roboților motoarelor de căutare să acceseze cu crawlere linkurile care se află pe pagina respectivă. Cu toate acestea, se pare că Googlebot încetează să acceseze cu crawlere acele pagini cu directive noindex după un timp.
Cu Python, putem analiza structura noastră internă de conectare și găsim noi oportunități de conectare internă în modul în bloc.
3.1. Analiza legăturii interne cu Python
Cu câteva luni în urmă, am scris un articol despre cum să utilizați Python și biblioteca Networkx pentru a crea grafice pentru a afișa structura internă de legături într-un mod foarte vizual:
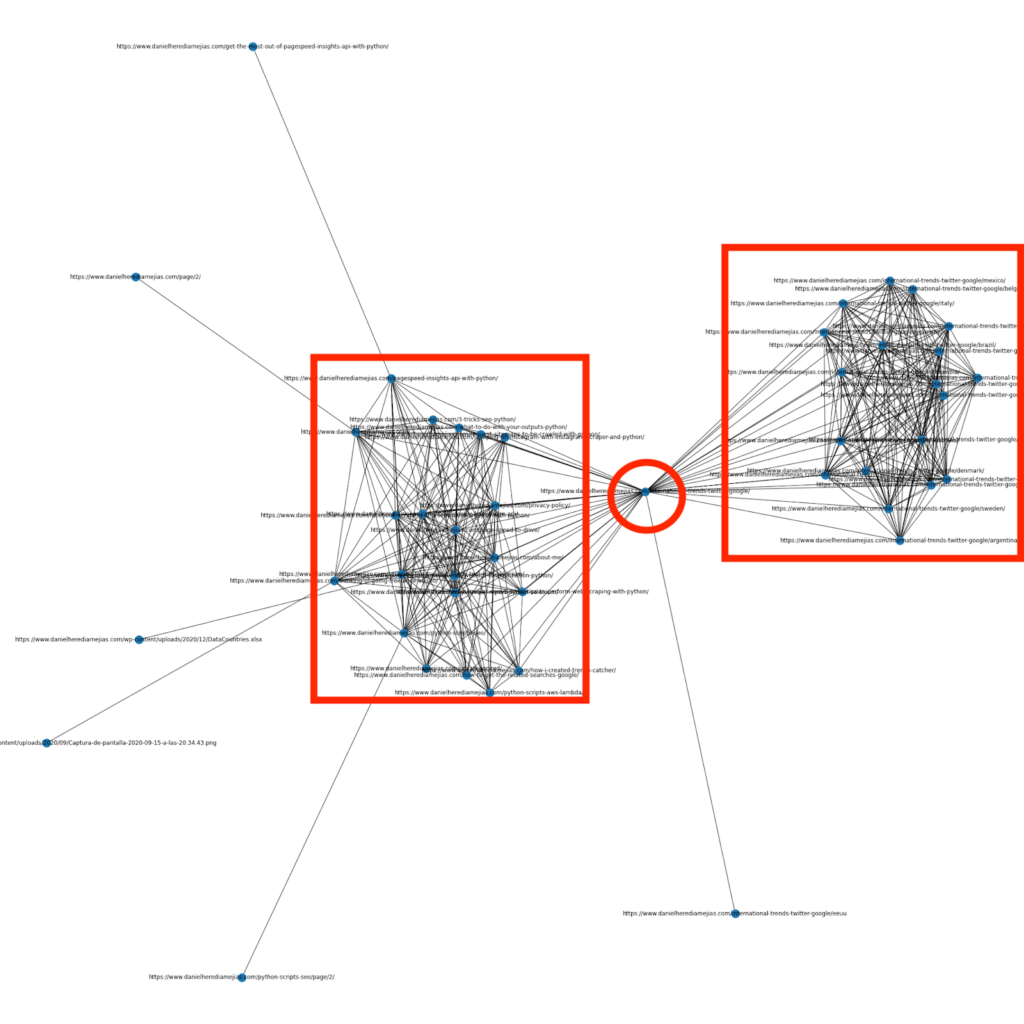
Acesta este ceva foarte asemănător cu ceea ce puteți obține de la Screaming Frog, dar avantajul utilizării Python pentru acest tip de analize este că, practic, puteți alege datele pe care doriți să le includeți în aceste grafice și să controlați majoritatea elementelor graficului, cum ar fi ca culori, dimensiuni ale nodurilor sau chiar paginile pe care doriți să le adăugați.
3.2. Găsirea de noi oportunități de conectare internă cu Python
Pe lângă analiza structurilor site-ului, puteți folosi și Python pentru a găsi noi oportunități de conectare internă, oferind un număr de cuvinte cheie și URL-uri și iterând peste acele URL-uri, căutând termenii furnizați în conținutul lor.
Acesta este ceva care poate funcționa foarte bine cu exporturile Semrush sau Ahrefs pentru a găsi legături interne contextuale puternice de la unele pagini care sunt deja clasate pentru cuvinte cheie și, prin urmare, care au deja un anumit tip de autoritate.
Puteți citi mai multe despre această metodă aici.
4. Website Speed, 5xx și pagini de eroare soft
După cum se precizează de Google pe această pagină despre ce înseamnă bugetul de accesare cu crawlere pentru Google, accelerarea site-ului dvs. îmbunătățește experiența utilizatorului și crește rata de accesare cu crawlere. Pe de altă parte, există și alți factori care ar putea afecta bugetul de accesare cu crawlere, cum ar fi paginile de eroare soft, conținutul de calitate scăzută și conținutul duplicat de pe site.
4.1. Viteza paginii și Python
4.2.1 Analizarea vitezei site-ului dvs. cu Python
API-ul Page Speed Insights este foarte util pentru a analiza performanța site-ului dvs. în ceea ce privește viteza paginii și pentru a obține o mulțime de date despre multe valori diferite ale vitezei paginii (aproape 50) plus Core Web Vitals.
Lucrul cu Page Speed Insights cu Python este foarte simplu, sunt necesare doar o cheie API și solicitări pentru a o folosi. De exemplu:
import urllib.request, json url = „https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=ro&key=yourAPIKey” #Rețineți că puteți introduce adresa URL cu URL-ul parametrului și puteți modifica și parametrul dispozitivului dacă doriți să obțineți datele pentru desktop. răspuns = urllib.request.urlopen(url) date = json.loads(response.read())
În plus, puteți estima, de asemenea, cu ajutorul calculatorului Python și Lighthouse Scoring cât de mult s-ar îmbunătăți scorul dvs. general de performanță în cazul efectuării modificărilor solicitate pentru a îmbunătăți viteza paginii, așa cum este explicat în acest articol.
4.2.2 Optimizarea și redimensionarea imaginii cu Python
Legat de viteza site-ului web, Python poate fi folosit și pentru a optimiza, comprima și redimensiona imaginile, așa cum este explicat în aceste articole scrise de Koray Tugberk și Greg Bernhardt:
- Automatizați compresia imaginii cu Python prin FTP.
- Redimensionați imaginile cu Python în bloc.
- Optimizați imaginile prin Python pentru SEO și UX.
4.2. 5xx și alte erori de cod de răspuns extragerea cu Python
Erorile codului de răspuns 5xx ar putea indica faptul că serverul dvs. nu este suficient de rapid pentru a face față tuturor solicitărilor pe care le primește. Acest lucru poate avea un impact foarte negativ asupra ratei de accesare cu crawlere și, de asemenea, poate afecta experiența utilizatorului.
Pentru a vă asigura că site-ul dvs. funcționează conform așteptărilor, puteți automatiza descărcarea rapoartelor cu crawlere cu Python și Selenium și puteți urmări îndeaproape fișierele de jurnal.
4.3. Extragerea paginilor de eroare soft cu Python
Recent, Jose Luis Hernando a publicat un articol în onoarea lui Hamlet Batista despre cum puteți automatiza extragerea raportului de acoperire cu Node.js. Aceasta poate fi o soluție uimitoare pentru a extrage paginile de eroare soft și chiar erorile de răspuns 5xx care ar putea afecta negativ rata de accesare cu crawlere.
De asemenea, putem replica același proces cu Python pentru a compila într-o singură filă Excel toate URL-urile care sunt furnizate de Google Search Console ca fiind eronate, valabile cu avertismente, valide și excluse.
În primul rând, trebuie să ne conectăm la Google Search Console, așa cum sa explicat anterior în acest articol, cu Python cu Selenium. După aceea, vom selecta toate casetele de stare URL, vom adăuga până la 100 de rânduri pe pagină și vom începe să iterăm peste toate tipurile de adrese URL raportate de GSC și vom descărca fiecare fișier Excel.
timpul de import
de la selenium import webdriver
din webdriver_manager.chrome import ChromeDriverManager
din selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=40740871819google.contents.google.com .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
timp.somn(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys(„<adresa ta de email>”)
searchBox.send_keys(Keys.ENTER)
timp.somn(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
searchBox.send_keys("<parola ta>")
searchBox.send_keys(Keys.ENTER)
timp.somn(5)
yourdomain = str(input("Inserați aici proprietatea sau domeniul dvs. http. Dacă este un domeniu includeți: 'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] pentru i în interval(len(df1["URL"]))]
df1['Type'] = listvalues
list_results = df1.values.tolist()
altceva:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Acoperire-Drilldown-" + astăzi + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] pentru i în interval(len(df2["URL"]))]
df2['Type'] = listvalues
list_results = list_results + df2.values.tolist()
df = pd.DataFrame(list_results, columns= ["URL","TimeStamp", "Type"])
df.to_csv('<nume fișier>.csv', antet=Adevărat, index=Fals, codificare = "utf-8")
Rezultatul final arată astfel: 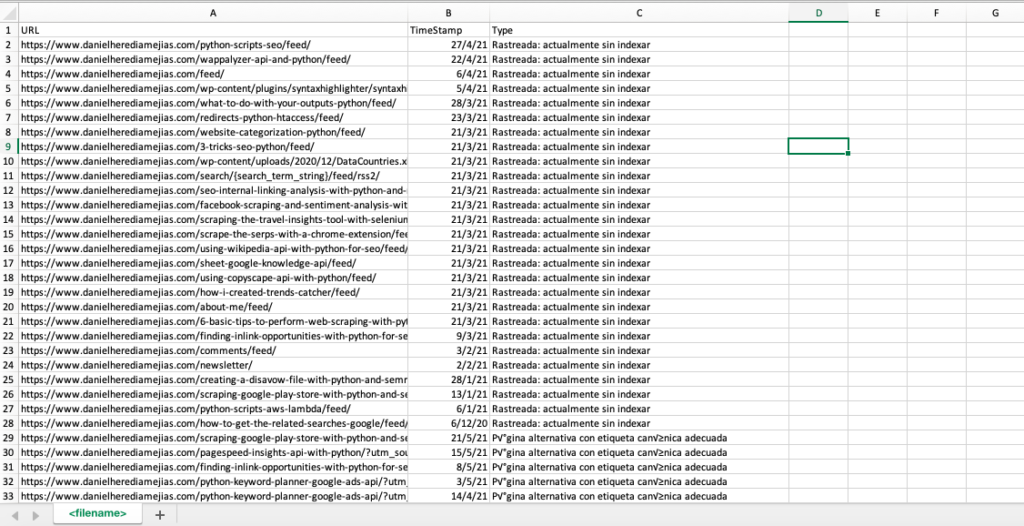
4.4. Analiza fișierelor jurnal cu Python
Pe lângă datele disponibile în raportul de statistici de accesare cu crawlere din Google Search Console, vă puteți analiza propriile fișiere folosind Python pentru a obține mult mai multe informații despre modul în care roboții motoarelor de căutare accesează cu crawlere site-ul dvs. Dacă nu utilizați deja un analizor de jurnal pentru SEO, puteți citi acest articol din SEO Garden, unde este explicată analiza jurnalelor cu Python.
[Ebook] Patru cazuri de utilizare pentru a utiliza analiza jurnalelor SEO
Descarcă gratis5. Concluzii finale
Am văzut că Python poate fi un atu excelent pentru a analiza și îmbunătăți accesarea cu crawlere și indexarea site-urilor noastre web în multe moduri diferite. De asemenea, am văzut cum să facem viața mult mai ușoară prin automatizarea majorității sarcinilor obositoare și manuale care ar necesita mii de ore din timpul tău.
Trebuie să spun că, din păcate, nu sunt pe deplin convins de soluțiile care sunt oferite în acest moment de Google pentru a solicita indexarea unui număr mare de URL-uri, deși pot înțelege într-o oarecare măsură teama acesteia de a oferi o soluție mai bună: mulți SEO-uri ar putea tinde a-l folosi excesiv.
Spre deosebire de asta, există Bing, care oferă soluții excepționale și convenabile pentru a solicita indexarea URL-ului prin API și chiar prin interfața normală din Bing Webmaster Tools.
Datorită faptului că API-ul de indexare Google are loc de îmbunătățire, alte elemente, cum ar fi o hartă a site-ului accesibilă și actualizată, conectarea internă, viteza paginii, paginile de eroare soft și conținutul duplicat și de calitate scăzută devin și mai importante pentru a vă asigura că site-ul dvs. este accesat cu crawlere în mod corespunzător și că cele mai importante pagini sunt indexate.