
Ce ar trebui să știe orice scriitor de conținut despre SEO tehnic
Publicat: 2020-12-10Echipa dvs. de marketing de conținut are o responsabilitate principală: creați conținut care conduce la rezultate. Munca lor necesită un amestec de creativitate cu logică, găsirea cuvintelor potrivite pentru a vă educa și convinge publicul și utilizarea datelor potrivite pentru a optimiza conținutul pentru performanță.
În calitate de manager de marketing, ar fi greu să le ceri creatorilor de conținut să fie responsabili și pentru SEO tehnic. SEO tehnic necesită o înțelegere profundă a dezvoltării web, o abilitate complexă de stăpânit pe cont propriu.
Deși nu puteți cere creatorilor de conținut să vă optimizeze SEO tehnic, aceștia ar trebui să înțeleagă elementele de bază ale acestuia. Acest lucru face mult mai ușor pentru echipa de conținut să comunice cu dezvoltatorii dvs. web și să mărească performanța conținutului pe care îl produc.
Să aruncăm o privire la elementele de bază ale SEO tehnic pe care echipa ta de conținut ar trebui să le înțeleagă pentru a înțelege cum conținutul lor perfect scris poate câștiga și mai mulți cititori organici.
Ce este SEO tehnic?
În cei mai simpli termeni, SEO tehnic este partea tehnică a SEO - cuprinde fiecare sarcină care necesită cunoștințe despre dezvoltarea web, despre cum funcționează site-urile web și despre modul în care Google le accesează cu crawlere și le indexează.
Pentru a fi mai specific, SEO tehnic include orice optimizare pe care o faceți pentru a ajuta Google să acceseze cu crawlere și să indexeze corect paginile dvs. web.
Crawling și indexare
Toate paginile web care apar în rezultatele Google (cunoscute și sub numele de SERP-uri sau pagini cu rezultate ale motorului de căutare) trebuie să existe mai întâi în indexul Google. Acest index este „directorul” în care Google listează toate paginile pe care le analizează atunci când clasifică o listă de pagini pentru o interogare care este introdusă în caseta de căutare.
Înainte de a putea adăuga o pagină în indexul lor, roboții Google – algoritmii pe care îi folosesc pentru a scana o pagină web – trebuie să poată accesa ea. După cum explică suportul Google:
„Nu există un registru central al tuturor paginilor web, așa că Google trebuie să caute în mod constant pagini noi și să le adauge la lista de pagini cunoscute. Odată ce Google descoperă adresa URL a unei pagini, vizitează sau accesează cu crawlere pagina pentru a afla ce este pe ea.”
Cu alte cuvinte, crawling este atunci când roboții Google scanează o pagină. Rețineți că am spus „scanare” și nu „indexare”, deoarece accesarea cu crawlere se referă doar la capacitatea roboților Google de a scana o pagină; indexarea vine mai târziu.
Primul pas al unei implementări SEO tehnice corecte este să vă asigurați că site-ul dvs. poate fi accesat cu crawlere; adică Google ar trebui să poată accesa cu crawlere toate paginile site-ului dvs.
Există multe motive pentru care un site web sau o pagină nu ar putea fi accesată cu crawlere, inclusiv:
- Serverul este oprit
- URL-ul este rupt
- A apărut o problemă la încărcarea site-ului/paginii
- Nicio altă pagină nu are legătură cu acesta
Unele tipuri de probleme de crawling tind să fie rare, deoarece sunt relativ ușor de detectat. Totuși, nu ar trebui niciodată să reduceți accesul cu crawlere în analiza dvs.: alte probleme pot fi greu de găsit, cum ar fi paginile orfane pe care le-ați creat, dar Google nu le poate găsi, paginile care sunt redirecționate în cercuri sau părți ale unui site care pot crea un un număr infinit de pagini pe care Google le poate accesa cu crawlere, cum ar fi arhivele de ani de zile fără conținut.
Pentru a găsi probleme de accesare cu crawlere, puteți utiliza Google Search Console, care funcționează ca reprezentantul Google pentru site-ul dvs. web: orice probleme tehnice pe care le aveți, GSC (cum se numește) vă va ajuta.
În GSC, accesați „Raport de acoperire” și verificați coloana Erori.
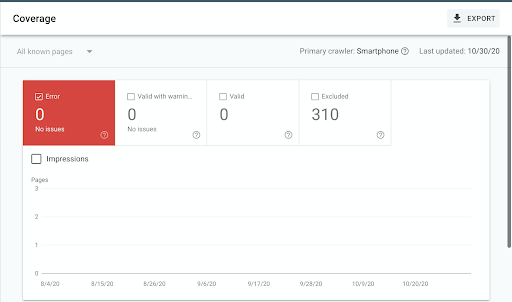
Puteți verifica din nou orice problemă de crawling utilizând un instrument SEO care include un crawler SEO, cum ar fi Oncrawl. Crawlerele SEO vă vor spune când găsesc probleme 5xx sau 4xx (aceste numere ciudate se referă la codul lor de stare - de exemplu, o eroare 404 apare atunci când o pagină nu poate fi accesată sau găsită).
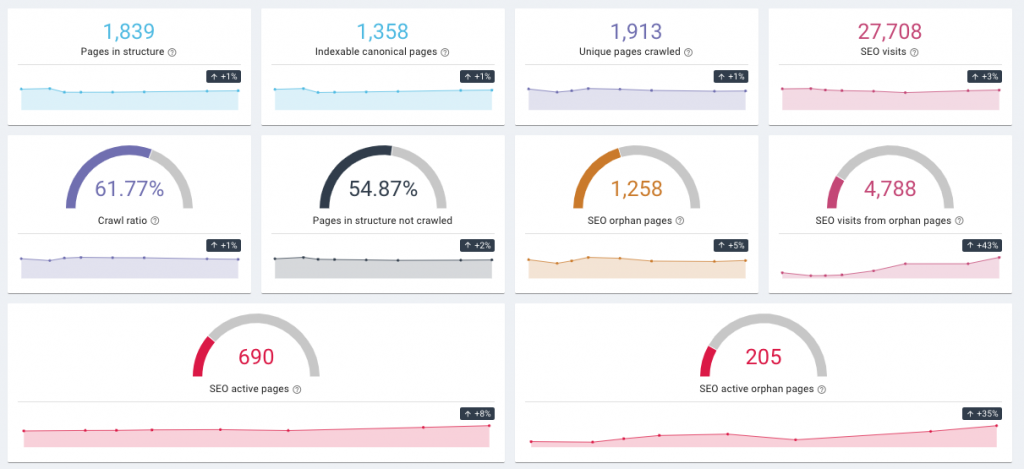 Raport de impact SEO Oncrawl
Raport de impact SEO Oncrawl 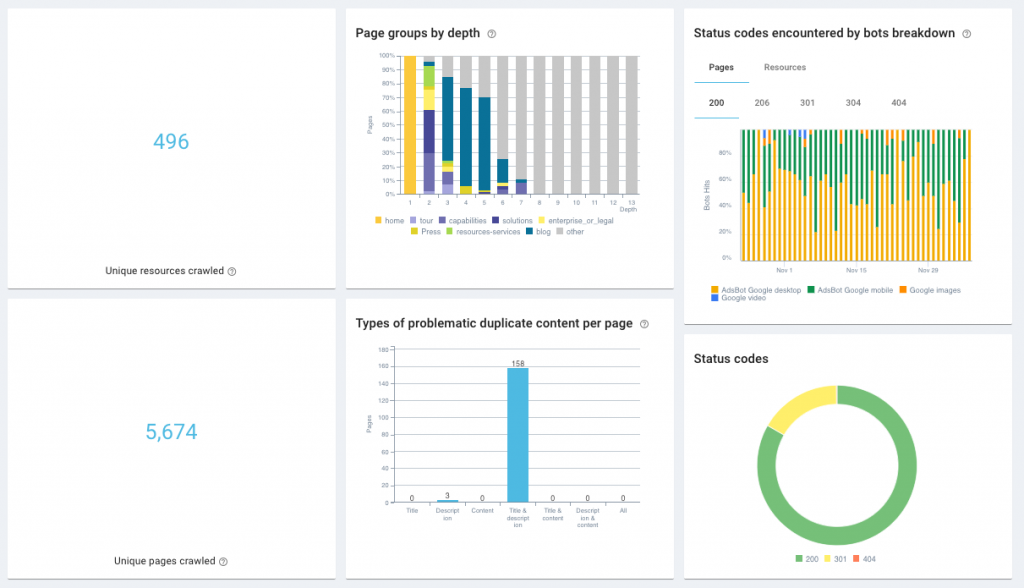 Tabloul de bord Oncrawl Health
Tabloul de bord Oncrawl Health
După ce Google accesează cu crawlere o pagină, nu o indexează imediat. Indexarea are loc atunci când Google decide să adauge o pagină la indexul lor, același index pe care îl consultă atunci când clasifică o pagină pentru SERP-uri. După cum afirmă:
„Google analizează conținutul paginii, cataloghează imaginile și fișierele video încorporate în pagină și, altfel, încearcă să înțeleagă pagina. Aceste informații sunt stocate în indexul Google, o bază de date uriașă stocată în multe, multe (multe!) computere.”
Pentru a fi clar: orice pagină pe care roboții Google o pot accesa cu crawlere va fi accesată cu crawlere, în timp ce noi nu putem spune același lucru despre indexare. Pentru a indexa o pagină, trebuie să clarificați că Google ar trebui să facă acest lucru. Iată cum:
- Evitați orice eroare de server . Cel mai bun mod de a avea o pagină indexată este să vă asigurați că este accesată cu crawlere în primul rând. Evitarea erorilor de server este cea mai bună modalitate de a face acest lucru. Verificați raportul de acoperire al GSC, așa cum a fost arătat anterior.
- Adăugați linkuri interne . Toate paginile dvs. ar trebui să fie conectate între ele cel puțin o dată. Folosiți textul de ancorare relevant, care descrie în mod corespunzător conținutul paginii (de exemplu, dacă aș trimite la această postare, aș folosi textul de ancorare tehnic SEO).
- Creați și încărcați un sitemap XML . Sunt ca niște broșuri pe care le folosiți pentru a prezenta paginile site-ului dvs. roboților Google. Potrivit unui inginer Google, sitemap-urile XML sunt „a doua cea mai importantă sursă” pentru găsirea adreselor URL – linkurile interne par a fi prima.
- Evitați indicațiile că Google ar trebui să stea departe de pagină . Acestea pot include instrucțiuni pentru a nu accesa pagina cu crawlere în ghidul site-ului pentru roboți, fișierul robots.txt sau atributele „nofollow” pe linkurile care indică către pagină.
- Asigurați-vă că nu îi spuneți Google să indexeze o altă pagină . Paginile pot sugera lui Google că o altă pagină ar fi o alegere mai bună pentru a indexa același conținut, așa cum vom vedea mai târziu. Poate trimite Google către o altă pagină cu o redirecționare sau poate spune direct Google să nu o indexeze cu o etichetă „noindex”. Paginile care fac oricare dintre acestea nu sunt considerate indexabile.
Pentru a vă asigura indexabilitatea paginii dvs., utilizați instrumentul de inspecție URL al GSC:
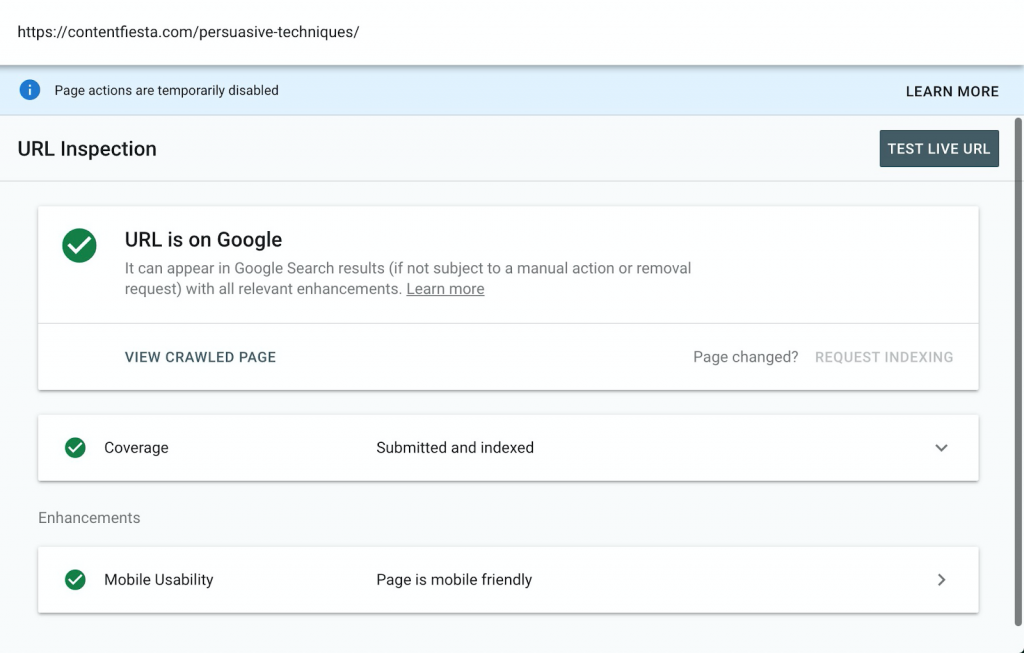
Odată ce Google indexează o pagină pe care doriți să o clasați în mod activ, sunteți gata. Dar există multe cazuri în care nu ați dori ca Google să vă indexeze paginile.
- Aveți informații sensibile pe care nimeni din afara companiei dvs. nu ar trebui să le vadă
- Aveți mai multe versiuni ale unei pagini pe care doriți să le ignore Google (mai târziu, veți vedea cum arată aceasta când vorbim despre „URL-uri canonice”)
- Nu doriți să vă diluați autoritatea domeniului indexând pagini irelevante, de exemplu, termenii dvs. de confidențialitate
Când de-indexați o pagină în mod intenționat, folosiți puterea puternică a Google pentru totdeauna. Fă-o inconștient și vei afecta semnificativ performanța site-ului tău.
Restul acestui ghid va acoperi trei subiecte care afectează direct sau indirect accesarea cu crawlere și indexarea site-ului dvs.
Structura site-ului
Structura site-ului dvs. se referă la modul în care vă planificați și vă organizați paginile. Totuși, nu vorbim despre meniurile tale, ci mai degrabă de structura creată de link-uri de la o pagină la alta. SEO numesc adesea structura site-ului „arhitectura site-ului”, deoarece definiți aspectul diferitelor părți ale site-ului dvs., modul în care acestea se relaționează între ele și modul în care toate vă susțin site-ul.
Multe probleme de crawling și indexare apar atunci când Google nu poate accesa sau indexa o pagină din cauza unei structuri ineficiente a site-ului; site-uri în care diferite părți sunt încurcate în moduri incoerente și complicate. Pentru a remedia această problemă, o teorie a arhitecturii site-ului SEO folosește următoarea regulă generală: un site nu trebuie să aibă mai mult de trei până la patru straturi.

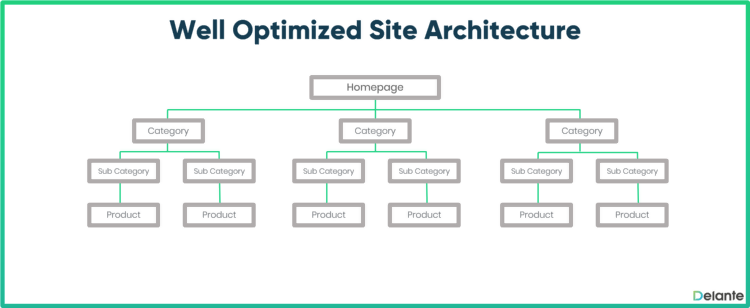
Sursă
O structură atât de simplă a site-ului ar însemna că de pe pagina dvs. de pornire, puteți face clic pe o pagină de blog de pe pagina dvs. de pornire și apoi pe o postare de blog scrisă de echipa de conținut. Puteți face clic pe alte postări sau pagini (de exemplu, pagina dvs. de contact), dar toate ar putea fi accesate alternativ în mai puțin de trei sau patru clicuri când porniți de la pagina de pornire. Ca alternativă, un site de comerț electronic ar putea avea o pagină de pornire, o pagină de categorie și o pagină de produs (coșurile de casă nu sunt indexate, deci nu sunt luate în considerare).
Astfel de structuri simple de site sunt numite „plate” datorită aspectului lor, așa cum ați văzut în imaginea de mai sus. Indiferent dacă site-ul dvs. are două, trei sau patru straturi, doriți să aveți un site web ușor de navigat, atât pentru vizitatori, cât și pentru botul Google.
Potrivit Google, „Navigarea unui site web este importantă pentru a ajuta vizitatorii să găsească rapid conținutul pe care îl doresc. De asemenea, poate ajuta motoarele de căutare să înțeleagă ce conținut consideră că webmasterul este important.”
 Sursă
Sursă
Pentru a vă face o idee despre structura site-ului dvs., efectuați un audit al site-ului cu Screaming Frog sau Oncrawl.
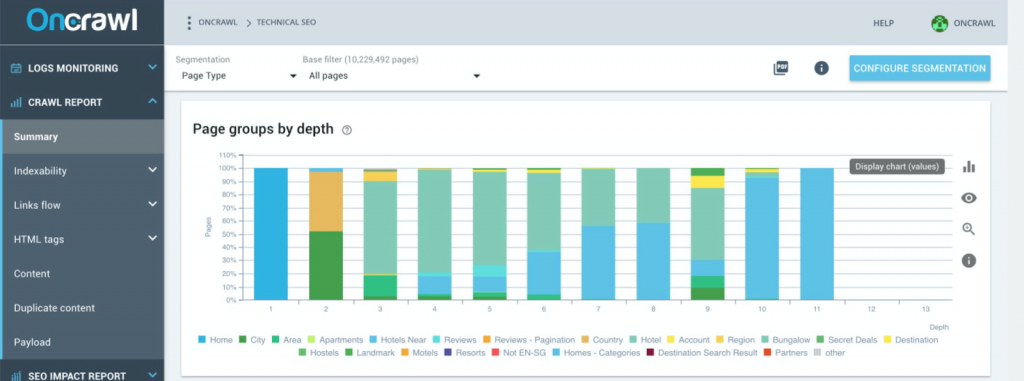
Sursă
Dacă descoperiți că structura site-ului dvs. are prea multe straturi și secțiuni confuze, trebuie să vă regândiți structura cu ajutorul echipei de dezvoltatori și al experților profesioniști în SEO. Este posibil ca creatorii dvs. de conținut să nu fie nevoie să participe la discuție, dar este important să știe de ce contează acest subiect: dacă conținutul pe care îl creează este prea jos în arhitectură sau nu face parte deloc din el, nu va fi indexate.
[Ebook] SEO tehnic pentru gânditori non-tehnici
 Lire l'ebook
Lire l'ebookOptimizarea vitezei
Viteza este unul dintre cei mai critici factori care afectează experiența utilizatorului (UX) și clasamentele. Prin „viteză”, mă refer la timpul necesar unui browser pentru a prelua datele unui site de pe un server, a crea pagina și a o afișa.
Fiecare pagină are zeci, dacă nu sute de elemente pe care un browser trebuie să le preia pentru a încărca o pagină. Modul în care un browser încarcă aceste elemente va defini viteza site-ului dvs.; cu cât durează mai mult pentru a încărca elementele site-ului dvs., cu atât viteza paginii dvs. este mai mică.
Optimizarea vitezei site-ului dvs. este una dintre cele mai importante modificări tehnice SEO pe care le puteți face. Cele mai comune și, cel mai adesea, eficiente modificări de optimizare a vitezei pe care le puteți face sunt:
- Comprimarea și reducerea fișierelor HTML, CSS și JS
- Optimizarea dimensiunii și a calității compresiei imaginilor dvs
- Configurarea memoriei cache a browserului
- Configurarea unui CDN
Potrivit unui studiu Backlinko, dimensiunea totală a unei pagini are cea mai mare corelație cu timpul de încărcare, mai presus de toți ceilalți factori.
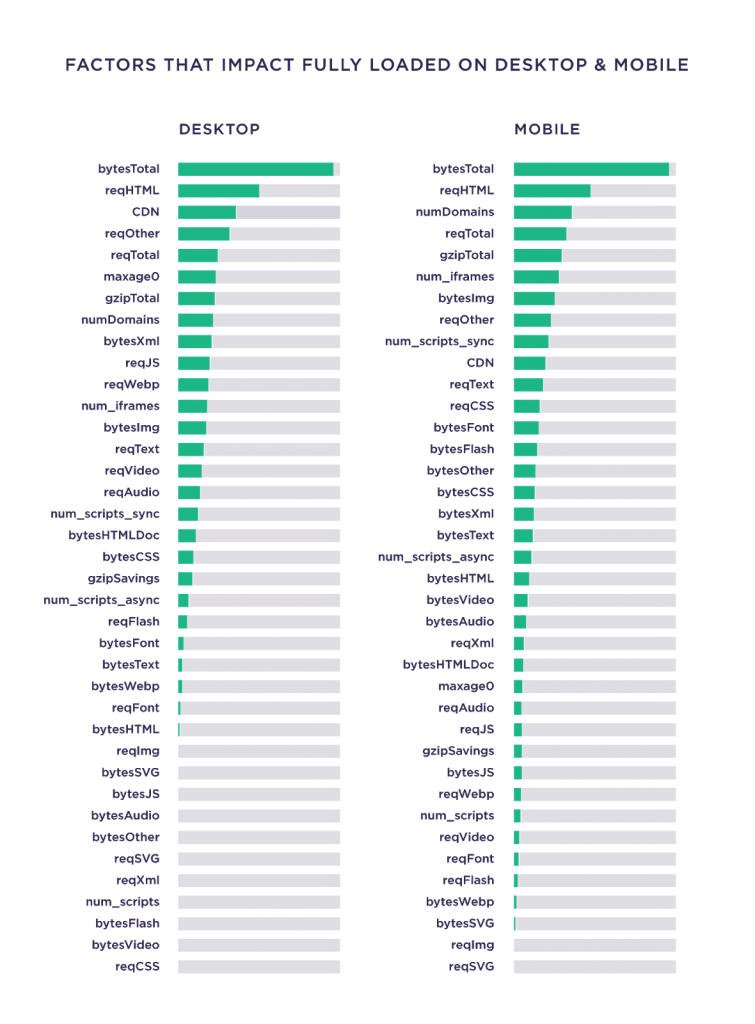
Pentru un creator de conținut, optimizarea vitezei este adesea în afara domeniului lor de aplicare, deoarece necesită abilități extrem de tehnice și pe partea de server, de exemplu, utilizarea RegEx, Apache HTTP Server etc. Cu toate acestea, există două aspecte de care orice marketer de conținut poate fi responsabil:
- Utilizarea pluginurilor: Instalarea pluginurilor WordPress nu este doar ușoară, ci și utilă. Problema este că pot reduce viteza unui site, așa că ori de câte ori un marketer de conținut decide să instaleze un plugin, ar trebui să discute despre implicația vitezei în mod corespunzător cu un SEO și un dezvoltator web.
- Optimizarea imaginii : Imaginile tind să fie cele mai grele elemente pe care le are o pagină. Pentru a depăși această problemă, utilizați formatul JPG, comprimați-vă imaginile și, ori de câte ori este posibil, reduceți dimensiunile acestora.
Dacă optimizați o pagină, aceasta se află deja pe poziții ridicate, dar nu pe aceleași primele poziții și ați văzut că este deja optimizată corespunzător pentru SEO pe pagină, verificați-i viteza. Adăugați pagina dvs. în instrumentul Google PageSpeed Insights sau, alternativ, în raportul Oncrawl Sarcina utilă și optimizați-o pe baza sugestiilor sale. Dacă aceste sugestii sunt în afara domeniului dvs. de aplicare, discutați-le cu echipa SEO și dezvoltatorii responsabili de gestionarea site-ului dvs.
Optimizarea conținutului
Când un scriitor de conținut creează o nouă piesă de conținut, scopul său principal este de a educa cititorul. La scurt timp după publicarea conținutului, poate apărea o problemă tehnică, care poate ruina funcționarea conținutului.
Vorbesc despre conținut duplicat , o problemă care se întâmplă atunci când Google indexează mai multe versiuni ale unei pagini. Site-urile de comerț electronic tind să aibă conținut duplicat, ceea ce duce la indexarea paginilor variante, cum ar fi:
- http://www.domain.com/product-list.html
- http://www.domain.com/product-list.html?sort=color
- http://www.domain.com/product-list.html?sort=price
Aceste greșeli se întâmplă neintenționat și discret. Scopul dvs. este să evitați indexarea paginilor duplicate. Pentru a începe, auditați-vă site-ul cu ajutorul detectorului de aproape duplicat al Oncrawl.
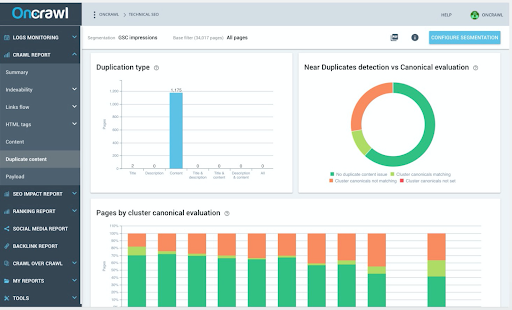
Există mai multe soluții pentru a remedia conținutul duplicat:
- Deindexați-l : adăugați eticheta „noindex” la pagina dvs. duplicată, astfel încât Google să o elimine din indexul lor.
- Adăugați eticheta canonică : adăugați eticheta rel=“canonic” la pagina duplicată și indicați versiunea reală (sau „canonică”) a paginii. Acest lucru nu îl va deindexa, dar îi va spune Google ce pagină ar trebui să folosească în SERP-uri.
- Redirecționați-l : utilizați o redirecționare 301 sau la nivel HTTP pentru a duce vizitatorii și roboții din pagina duplicată (http://www.domain.com/product-list.html?sort=color din exemplul de mai sus) la cea corectă .
- Eliminați-o : în unele cazuri, pagina duplicată are un fișier separat pe serverul dvs. sau pe CMS. În acest caz, eliminați pagina duplicată și redirecționați adresa URL a acesteia.
- Rescrieți-l : dacă se întâmplă să aveți mai multe pagini similare una cu cealaltă, puteți modifica conținutul acestora pentru a vă asigura că sunt recunoscute ca pagini separate.
Conținutul duplicat nu este o problemă mică de ignorat, așa că asigurați-vă că auditați site-ul în mod corespunzător și remediați orice situație a acestei probleme.
În concluzie
Sfatul prezentat aici este doar vârful aisbergului. SEO tehnic poate fi o sarcină copleșitoare pentru orice scriitor de conținut non-tehnic, așa că un dezvoltator ar trebui să facă cele mai complexe modificări.
Cu toate acestea, niciun creator de conținut nu ar trebui să ignore elementele de bază ale SEO tehnic, deoarece acestea sunt esențiale pentru a se asigura că conținutul funcționează conform așteptărilor. Orice problemă care poate provoca o accesare cu crawlere și o indexare incorectă de la Google poate ajunge să provoace probleme grave întregii operațiuni de marketing de conținut.
Ce altceva crezi că ar trebui să știe un marketer de conținut despre SEO tehnic?