
10 probleme tehnice comune SEO – și cum să le depistați
Publicat: 2019-06-04După ce ați prestat servicii SEO într-o gamă largă de industrii, uneori sunteți capabil să înțelegeți probleme comune, mai ales atunci când lucrați la un CMS obișnuit, cum ar fi WordPress, Shopify sau SquareSpace.
Aici am subliniat 10 probleme tehnice SEO destul de frecvente pe care le-ați putea întâlni atunci când optimizați un site web.
Nu spun că aceste probleme vor fi cu siguranță problematice pentru tine sau clientul tău – de foarte multe ori contextul este încă foarte important. Nu există întotdeauna o soluție universală, dar probabil că este totuși bine să fii atenți la scenariile prezentate mai jos.
1 – Fișierul Robots.txt care blochează accesul la Googlebot
Acest lucru nu este nimic nou pentru majoritatea SEO-urilor tehnice, dar este totuși foarte ușor să neglijezi să verifici fișierul roboților – și nu doar în momentul efectuării unui audit tehnic, ci ca o verificare recurentă.
Puteți folosi un instrument precum Search Console (versiunea veche) pentru a verifica dacă Google are probleme de acces sau puteți încerca doar să vă accesați cu crawlere site-ul ca Googlebot cu un instrument precum OnCrawl (doar selectați agentul utilizator). OnCrawl se va supune fișierului robots.txt, dacă nu spuneți altfel.
Exportați rezultatele accesării cu crawlere și comparați-le cu o listă cunoscută de pagini de pe site-ul dvs. și verificați că nu există puncte moarte ale crawlerului.
Pentru a arăta că acest lucru se întâmplă încă destul de des și pentru unele site-uri destul de mari, acum câteva săptămâni am observat că instrumentul de testare a vitezei de la Pingdom a fost blocat în Google.
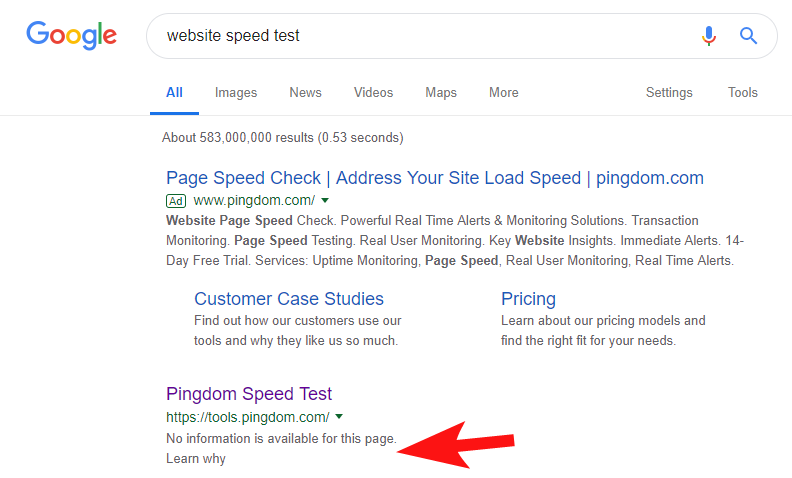
Privind fișierul roboților lor (și ulterior încercând să acceseze cu crawlere pagina lor din OnCrawl ca Googlebot) mi-a confirmat suspiciunile că blocau accesul la site-ul lor.
Fișierul robots.txt vinovat este afișat mai jos:

Le-am contactat cu un „FYI”, dar nu am primit niciun răspuns, dar câteva zile mai târziu am văzut că totul a revenit la normal. Puff – aș putea să dorm din nou ușor!
În cazul lor, se părea că ori de câte ori vă scanați site-ul ca parte a auditului lor de viteză, acesta crea o adresă URL care include acel caracter hashing evidențiat în fișierul roboți de mai sus.
Poate că acestea au fost accesate cu crawlere și chiar indexate cumva și au vrut să controleze asta (ceea ce ar fi foarte de înțeles). În acest caz, probabil că nu au testat pe deplin impactul potențial – care a fost probabil minim în cele din urmă.
Iată roboții lor actuali pentru oricine este interesat.

Este demn de remarcat faptul că, în unele cazuri, puteți accesa modificările istorice ale fișierului robots.txt folosind Internet Wayback Machine. Din experiența mea, acest lucru funcționează cel mai bine pe site-uri mai mari, așa cum vă puteți imagina – sunt mult mai des accesate cu crawlere de arhivatorul Wayback Machine.
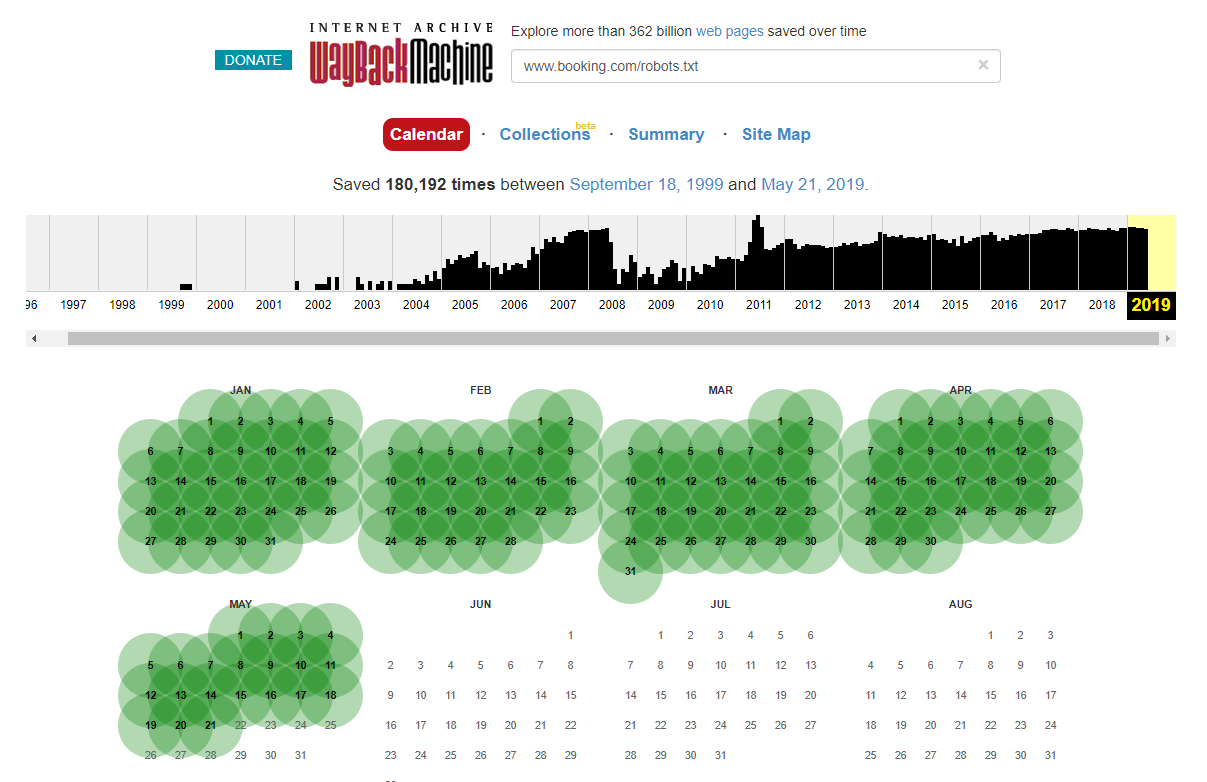
Nu este prima dată când văd un robots.txt live în sălbăticie provocând un pic de ravagii în SERPS. Și cu siguranță nu va fi ultimul – este un lucru atât de simplu de neglijat (în definitiv, este un fișier), dar verificarea acestuia ar trebui să facă parte din programul de lucru în curs de desfășurare al fiecărui SEO.
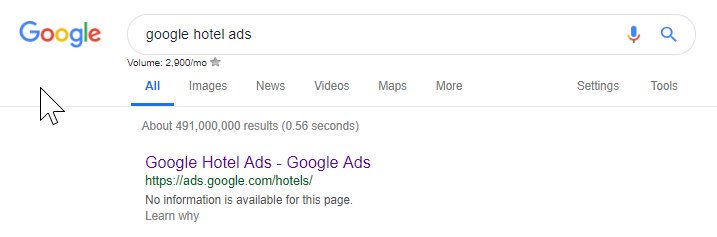
Din cele de mai sus puteți vedea că până și Google își încurcă uneori fișierul roboți, blocându-se să acceseze conținutul lor. Acest lucru ar fi putut fi intenționat, dar privind limba fișierului roboților lor de mai jos, mă îndoiesc cumva.
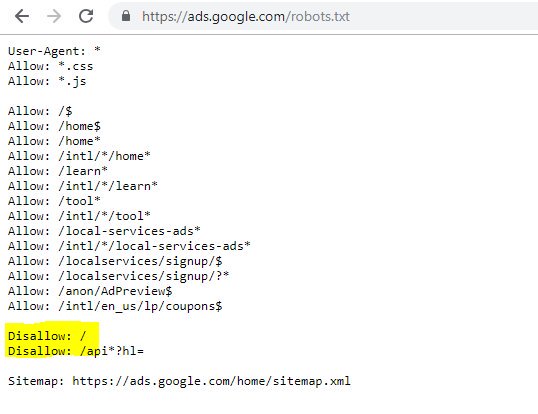
Evidențiat Disallow: / în acest caz a împiedicat accesul la orice căi URL; ar fi fost mai sigur să enumerați secțiunile specifice ale site-ului care nu ar trebui accesate cu crawlere.
2 – Probleme de configurare a domeniului la nivel DNS
Acesta este unul surprinzător de comun, dar de obicei este o soluție rapidă. Aceasta este una dintre acele modificări SEO cu cost redus, * potențial * cu mare impact, pe care SEO-ul tehnic le iubește.
Adesea, cu implementările SSL, nu reușesc să văd versiunea de domeniu non-WWW configurată corect, cum ar fi 302 redirecționând la următoarea adresă URL și formând un lanț sau, în cel mai rău caz, nu se încarcă deloc.
Un exemplu bun aici este cel al site-ului Hotel Football.
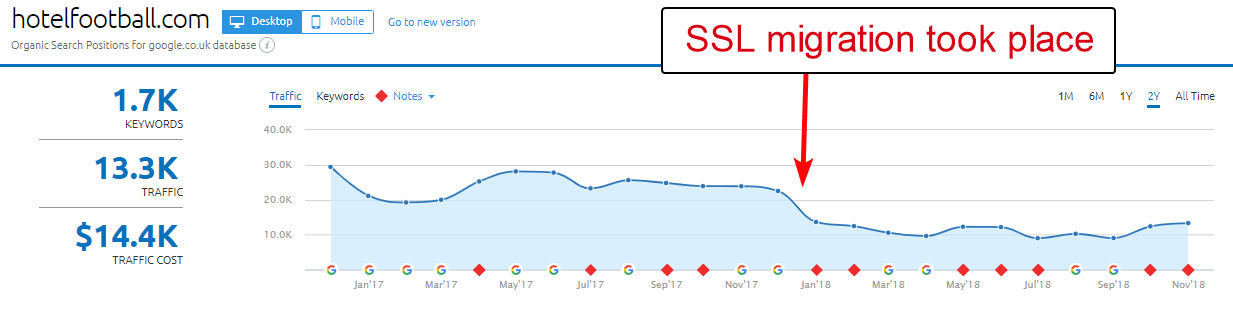
Ei au suferit o migrare SSL la începutul anului trecut, ceea ce nu le-a ieșit atât de bine, judecând după raportul de prezentare generală a domeniului SEMRush de mai sus.
L-am observat pe acesta cu ceva vreme în urmă, deoarece am lucrat mult în industria turismului și ospitalității – și cu o mare dragoste pentru fotbal, eram interesat să văd cum era site-ul lor (plus cum mergea organic, desigur! ).
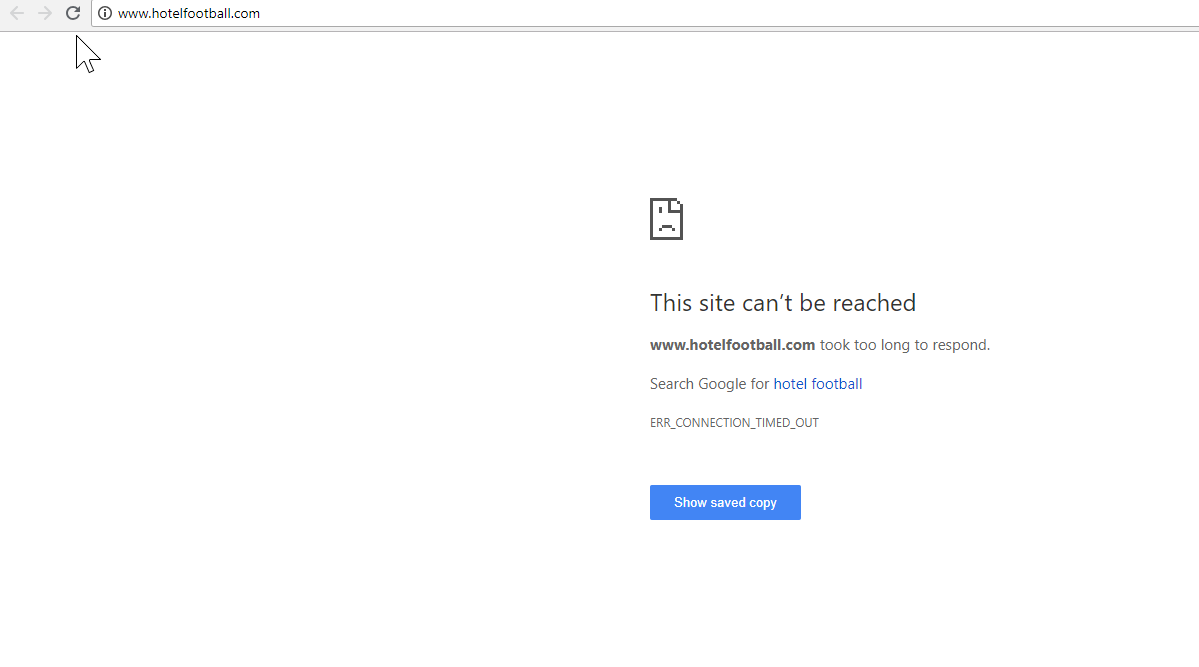
Acest lucru a fost de fapt foarte ușor de diagnosticat – site-ul avea o mulțime de backlink-uri extrem de bune, toate indicând domeniul non-SSL, WWW la http://www.hotelfootball.com/
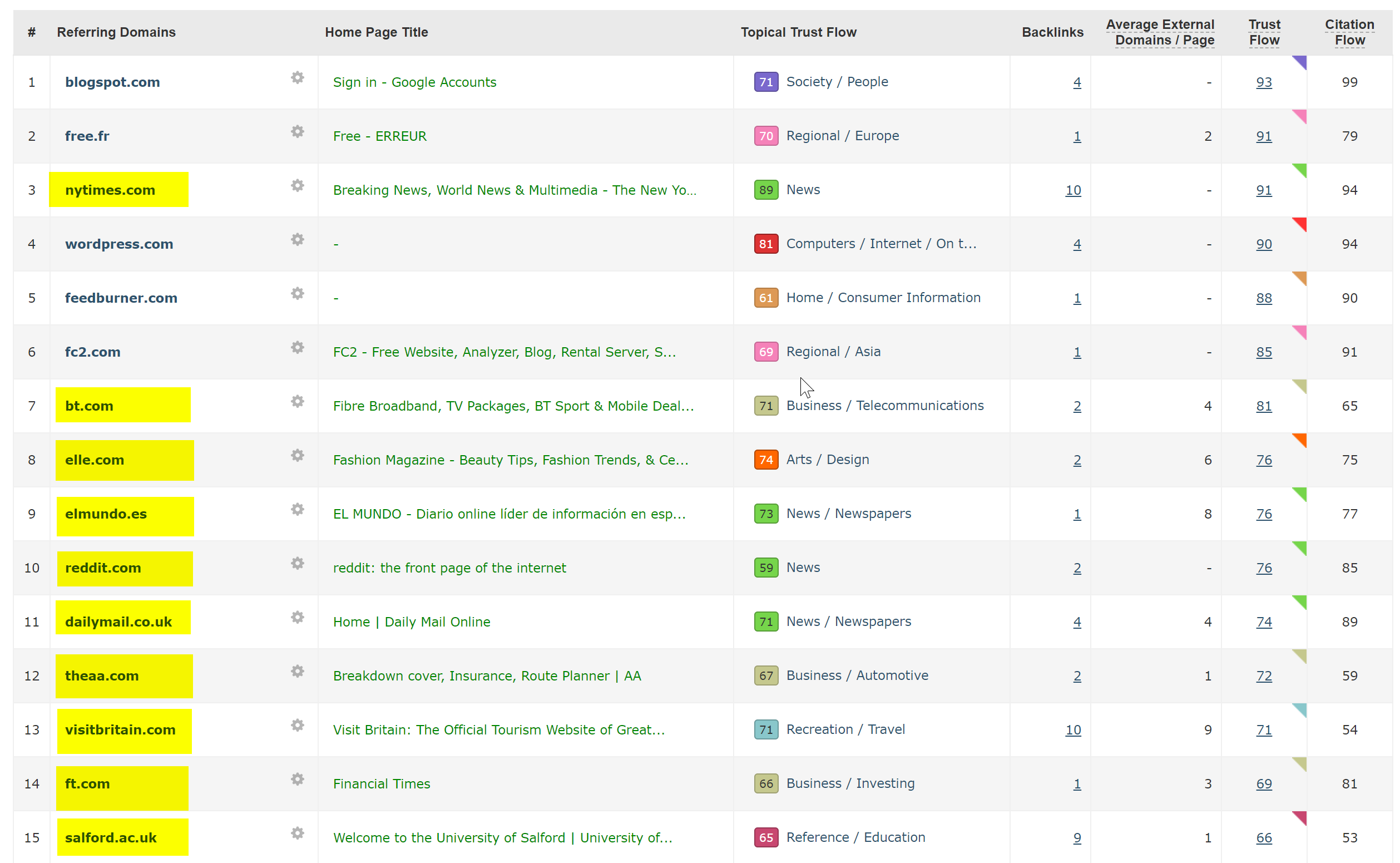
Dacă încercați să accesați acea adresă URL de mai sus, nu se încarcă. Hopa! Și așa e de vreo 18 luni acum, cel puțin. Am contactat agenția care gestionează site-ul prin Twitter pentru a le informa despre asta, dar nu am primit niciun răspuns.
Cu aceasta, tot ce trebuie să facă este să se asigure că setările zonei DNS sunt corecte, cu o înregistrare „A” în loc pentru versiunea „WWW” a domeniului, care indică adresa IP corectă (un CNAME ar funcționa și el). Acest lucru va preveni ca domeniul să nu se rezolve.
Singurul dezavantaj, sau motivul pentru care acesta durează atât de mult să se rezolve, este că poate fi dificil să obții acces la panoul de gestionare a domeniului unui site sau chiar că parolele s-au pierdut sau nu este văzut ca o prioritate ridicată.
Nici să trimiți instrucțiuni pentru a remedia unei persoane non-tehnologice care deține cheile numelui de domeniu nu este întotdeauna o idee grozavă.
Aș fi foarte dornic să văd impactul organic dacă/când vor fi capabili să facă ajustările de mai sus – mai ales având în vedere toate backlink-urile pe care domeniul non-WWW le-a creat de când hotelul a fost lansat de foștii fotbaliști Manchester United Gary Neville, Ryan Giggs si companie.
Deși ocupă locul 1 în Google pentru numele hotelului lor (după cum v-ați imagina), ei nu par să aibă deloc clasamente bune pentru niciunul dintre termenii lor de căutare fără marcă mai competitivi (în prezent se află pe poziția 10). pe Google pentru „hotel lângă Old Trafford”).
Ei au marcat un pic de autogol cu cele de mai sus - dar rezolvarea acestei probleme ar putea ajuta cel puțin într-un fel să rezolve asta.
Oncrawl SEO Crawler
 Află mai multe
Află mai multe3 – Pagini necinstite din Sitemap XML
Din nou, aceasta este una destul de simplă, dar este ciudat de obișnuită – la examinarea unei hărți XML a site-urilor (care este aproape întotdeauna fie la domain.com/sitemap.xml, fie la domain.com/sitemap_index.xml, pot exista pagini enumerate aici care într-adevăr nu nu trebuie să fie indexat.
Vinovații tipici includ pagini de mulțumire ascunse (mulțumim pentru trimiterea unui formular de contact), pagini de destinație PPC care pot cauza probleme de conținut duplicat sau alte forme de pagini/postări/taxonomii pe care nu le-ați indexat deja în altă parte.
Includerea lor din nou în harta site-ului XML poate trimite semnale conflictuale către motoarele de căutare – într-adevăr ar trebui să enumerați doar paginile pe care doriți să le găsească și să le indexeze, ceea ce este în principal punctul de vedere al hărții site-ului.
Acum puteți utiliza raportul la îndemână din Search Console pentru a afla dacă paginile au fost sau nu incluse într-o hartă de site XML a site-urilor, prin opțiunea Inspectați URL.
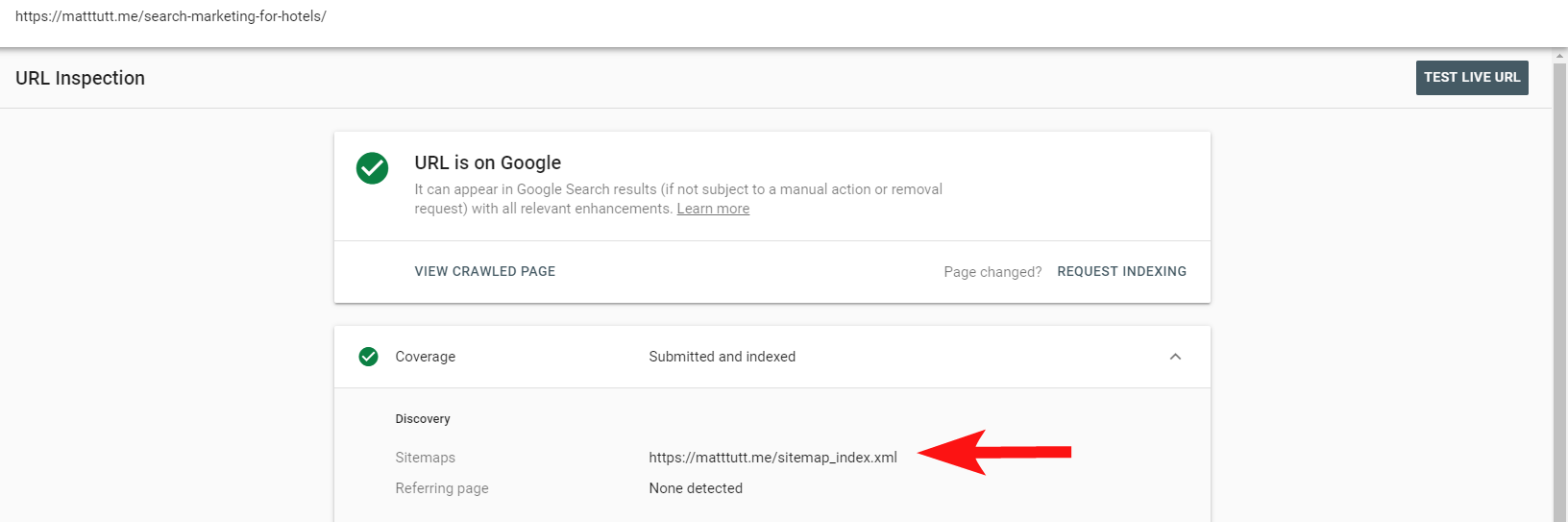
Dacă aveți un site destul de mic, probabil că puteți revizui manual harta site-ului dvs. XML în browser - în caz contrar, descărcați-l și comparați-l cu un acces cu crawlere complet al adreselor URL indexabile.
Adesea, puteți găsi acest tip de conținut de calitate scăzută, neprețuit, făcând o căutare site:domain.com în Google pentru a returna tot ceea ce a fost indexat.
Merită remarcat aici că acesta poate conține conținut vechi și nu ar trebui să se bazeze pe acesta pentru a fi 100% actualizat, dar este o verificare ușoară pentru a vă asigura că nu există o mulțime de conținut care să vă umfle eforturile SEO și să consume bugetele de accesare cu crawlere.
4 – Probleme cu Googlebot care redă conținutul dvs
Acesta este demn de un articol întreg dedicat acestuia și, personal, simt că mi-am petrecut o viață întreagă jucându-se cu instrumentul de preluare și redare de la Google.
S-au spus multe despre acest lucru (și despre JavaScript) deja de către unii SEO foarte capabili, așa că nu voi aprofunda acest lucru, dar verificarea modului în care Googlebot redă site-ul tău va fi întotdeauna demn de timpul tău.
Executarea câtorva verificări prin instrumente online poate ajuta la descoperirea punctelor nevăzute ale Googlebot (zonele de pe site pe care nu le pot accesa), probleme cu mediul dvs. de găzduire, resurse problematice de ardere JavaScript și chiar probleme de scalare a ecranului.
În mod normal, aceste instrumente terță parte sunt destul de utile la diagnosticarea problemei (Google chiar vă spune când o resursă este blocată din cauza fișierului dvs. roboți, de exemplu), dar uneori vă puteți găsi în cerc.
Pentru a arăta un exemplu real de site problematic, o să mă împușc în picior și o să fac referire la propriul meu site web – și la o temă WordPress deosebit de frustrantă pe care o folosesc.
Uneori, când execut o inspecție URL din Search Console, primesc avertismentul „Pagina nu este adaptată pentru dispozitive mobile” (vezi mai jos).
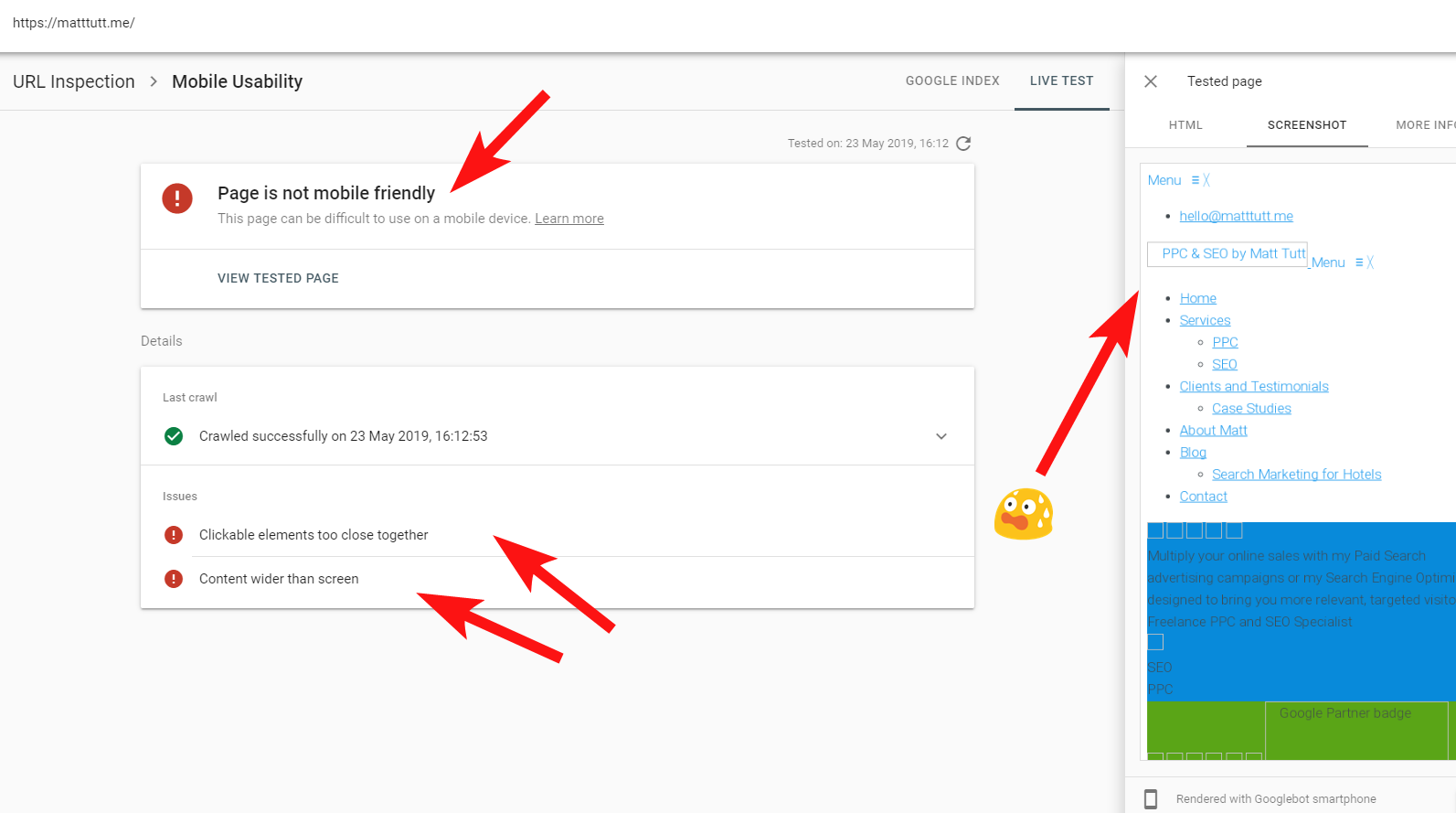
Făcând clic pe fila Mai multe informații (dreapta sus), oferă o listă de resurse care nu au putut fi accesate atunci de Googlebot, care este în principal CSS și fișiere imagine.
Acest lucru este probabil deoarece Googlebot nu poate oferi întotdeauna „energie” completă în redarea paginii - uneori, pentru că Google se teme să-mi blocheze site-ul (care este un fel de ele), iar alteori s-ar putea să fiu limitat deoarece au folosit-o. o mulțime de resurse pentru a prelua și reda site-ul meu deja.
Uneori, din cauza celor de mai sus, merită să rulați aceste teste de câteva ori la intervale extinse pentru a obține o poveste mai adevărată. De asemenea, vă recomand să verificați jurnalele serverului, dacă puteți, pentru a verifica cum Googlebot a accesat (sau nu a accesat) conținutul site-ului dvs.
404 sau alte stări proaste pentru aceste resurse ar fi în mod clar un semn rău, mai ales dacă este consecvent.
În cazul meu, Google reclamă site-ul pentru că nu este prietenos cu dispozitivele mobile, ceea ce este în principal rezultatul eșecului anumitor fișiere în stil CSS în timpul redării, ceea ce poate suna pe bună dreptate semnale de alarmă.
Pentru a face lucrurile mai confuze, atunci când rulați Testul de compatibilitate cu dispozitivele mobile de la Google sau când utilizați orice alt instrument terță parte, nu sunt detectate probleme: site-ul este prietenos cu dispozitivele mobile.
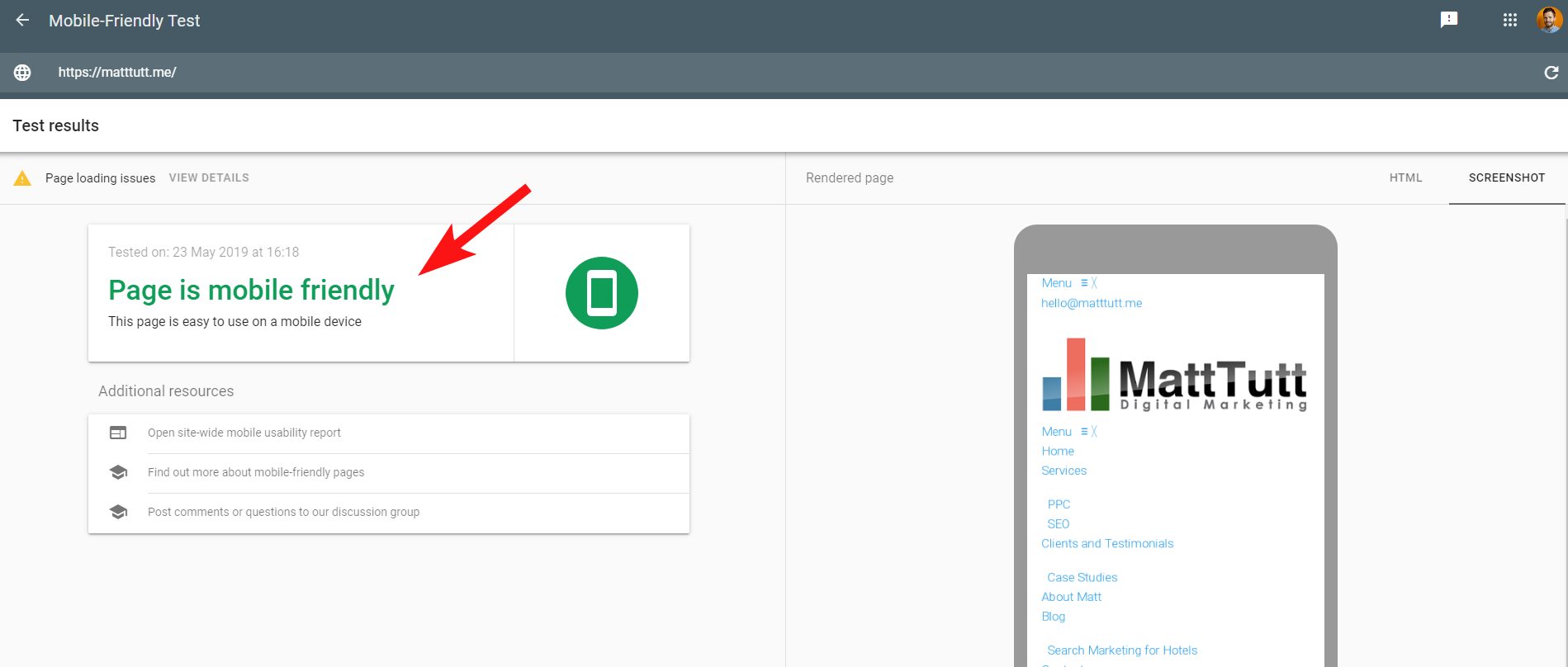
Aceste mesaje conflictuale de la Google pot fi dificil de decodat pentru SEO și dezvoltatorii web. Pentru a înțelege mai mult, am luat legătura cu John Mueller, care mi-a sugerat să-mi verific gazda web (fără probleme) și că fișierul CSS poate fi într-adevăr stocat în cache de Google.
Search Console folosește un serviciu Web Rendering (WRS) mai vechi în comparație cu Instrumentul Mobile-Friendly, așa că în prezent tind să acord mai multă ponderare acestuia din urmă.
Odată ce Google a anunțat un Googlebot mai nou, cu cele mai recente capacități de randare, toate acestea ar putea fi setate să se schimbe, așa că merită să fiți la curent cu ce instrumente sunt cele mai bune de utilizat pentru verificările de randare.
Un alt sfat aici - dacă doriți să vedeți o redare completă derulabilă a unei pagini, puteți comuta la fila HTML din instrumentul de testare mobil Google, apăsați CTRL+A pentru a evidenția tot codul HTML redat, apoi copiați și inserați într-un editor de text și salvați ca fișier HTML.
Deschiderea acestuia în browser (degetele încrucișate, uneori depinde de CMS-ul folosit!) vă va oferi o randare care poate fi derulată. Și avantajul acestui lucru este că puteți verifica cum se redă orice site - nu aveți nevoie de acces Search Console.
5 – Site-uri piratate și backlink-uri spam
Acesta este unul destul de distractiv de prins și se poate strecura adesea pe site-uri care rulează pe versiuni mai vechi de WordPress sau alte platforme CMS care necesită actualizări regulate de securitate.
Cu acest client (un centru de înfrumusețare), am observat niște termeni ciudați de căutare care apar în Search Console.
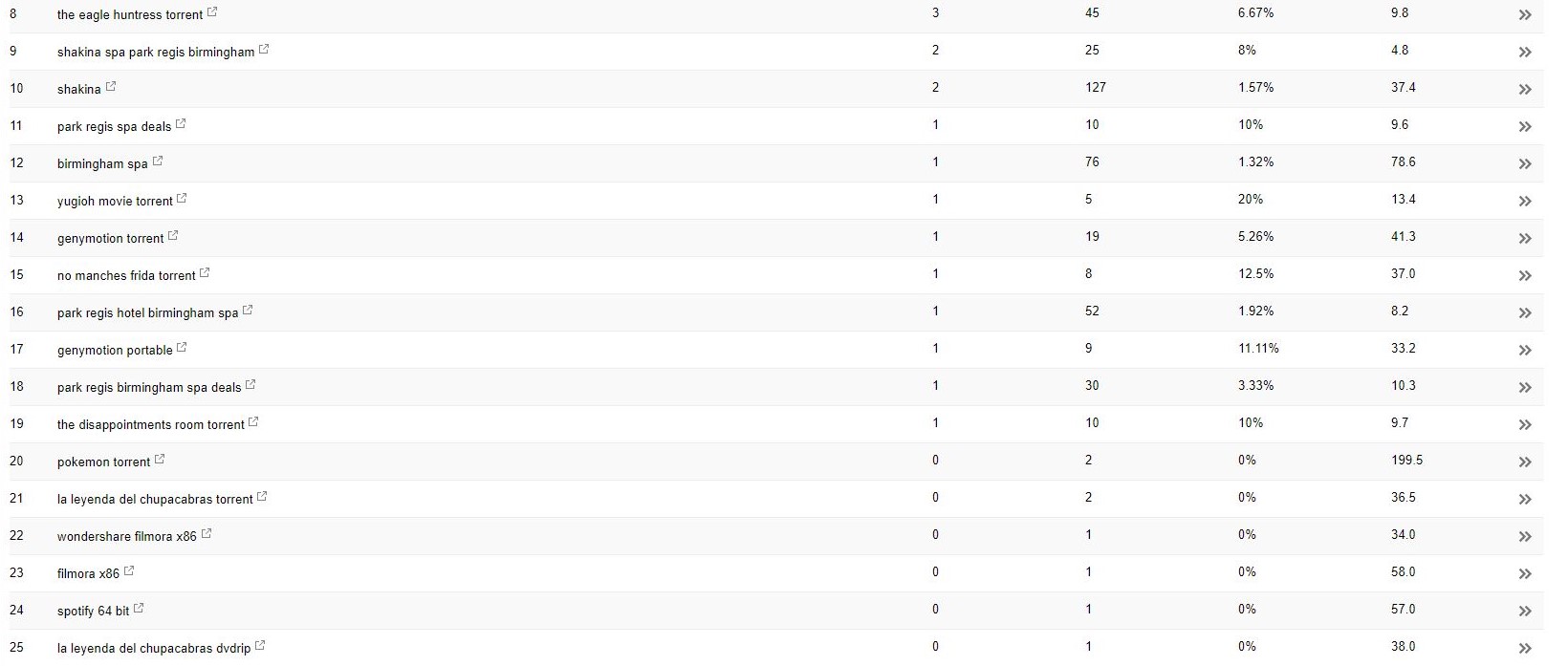
În mod surprinzător, nu numai că au avut afișări în Search Console, ci și clicuri, ceea ce înseamnă că ceva trebuie să fi fost indexat pe domeniu.
Judecând după interogări, în mod clar a fost foarte spam și nu ceva cu care clientul ar dori ca afacerea sa să fie asociată.
Făcând o simplă căutare „site:domain.com” în Google, a scos la iveală sute de pagini de presupuse torrente pe care se presupune că clientul le găzduia pe site-ul lor.
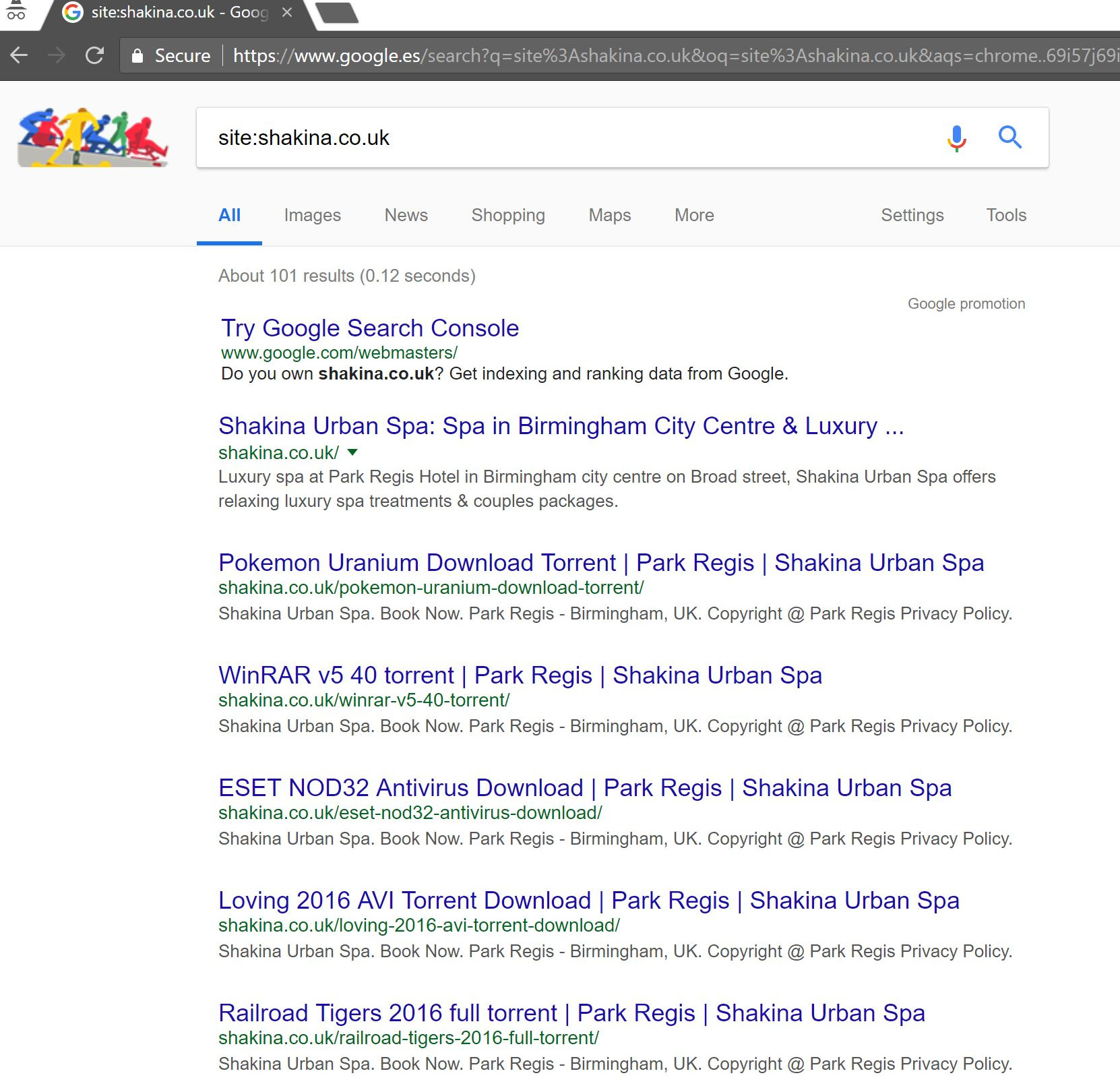
Vizitarea oricăreia dintre acele URL-uri a dus, de fapt, la un 404 – totuși, ele erau încă indexate (am verificat și diverși agenți de utilizator și toți au primit aceeași eroare 404).
Apoi am rulat domeniul prin verificatorul de backlink al Majestic și a oferit o listă lungă de backlink-uri de foarte slabă calitate care indică aceste pagini de pe site-urile clienților – ceea ce probabil a ajutat la indexarea lor.
Privind la Anchor Cloud de la Majestic al backlink-urilor a arătat cu adevărat amploarea problemei.


Singura soluție aici a fost să dezavuezi toate acele backlink-uri în funcție de domeniu și apoi să rulezi o analiză curată a instalării WordPress în speranța de a curăța orice injecție de cod sau să instalezi o copie nouă a WordPress.
Dacă sunteți într-adevăr îngrijorat de conținutul indexat în cazuri precum cel de mai sus, puteți furniza și un cod de stare 410 pentru a clarifica cu adevărat lucrurile cu crawlerele de căutare.
Cele de mai sus s-ar potrivi acelor site-uri care au primit avertismente legale din cauza revendicărilor de drepturi de autor din partea producătorilor de film – ceea ce poate apărea uneori în situații ca aceasta dacă problema nu este rezolvată rapid.
6 – Configurații SEO internaționale proaste
Fiind stabilit în Spania, dar navigând pe internet în limba mea maternă engleză, mă voi trezi adesea redirecționat automat către o versiune spaniolă a unui site web.
Deși înțeleg logica (sunt cu sediul în Spania, prin urmare vreau să răsfoiesc site-ul în spaniolă), este destul de enervant din perspectiva experienței utilizatorului și, dacă nu este făcut corect, poate provoca, de asemenea, un pic de haos cu SEO internațional.
Site-uri precum Google Ads duc acest lucru la un alt nivel – utilizând JavaScript Angular pentru a genera în mod dinamic conținut pe baza locației mele, nici măcar nu trec printr-o redirecționare a paginii de orice fel și nu încarcă conținutul chiar în DOM.
Metoda mea preferată de alegere atunci când sunt disponibile mai multe limbi este să redirecționez 302 un utilizator către o limbă pe baza setărilor browserului său de Internet.
Prin urmare, dacă cineva are limba germană ca limbă implicită în Google Chrome, probabil că este confortabil să citească site-ul în germană, indiferent de locația sa fizică.
Acest lucru ajută și la rezolvarea dificultăților atunci când cineva se află într-o regiune în care se vorbesc diferite limbi, cum ar fi în Elveția, unde sunt folosite franceză, italiană, germană și romanșă.
Este, de asemenea, esențial, în scopuri de utilizare, să vă asigurați că există o opțiune de a schimba limbile în funcție de preferințele dvs. - doar în cazul în care doresc să schimbe.
Într-un caz, am lucrat cu un hotel din Barcelona, unde un script de redirecționare a limbajului JavaScript a fost adăugat la un site fără a lua în considerare impactul SEO.
Acest script a redirecționat utilizatorii pe baza setării de limbă a browserului (ceea ce nu este prea rău în sine) printr-o redirecționare JavaScript pe partea clientului.
Din păcate, în acest caz, scriptul nu a fost configurat corect din cauza unei configurații ciudate a permalink-urilor site-urilor, iar atunci când este combinat cu faptul că eticheta HTML lang lipsea din toate paginile de pe site, Googlebot a devenit puțin nebun...
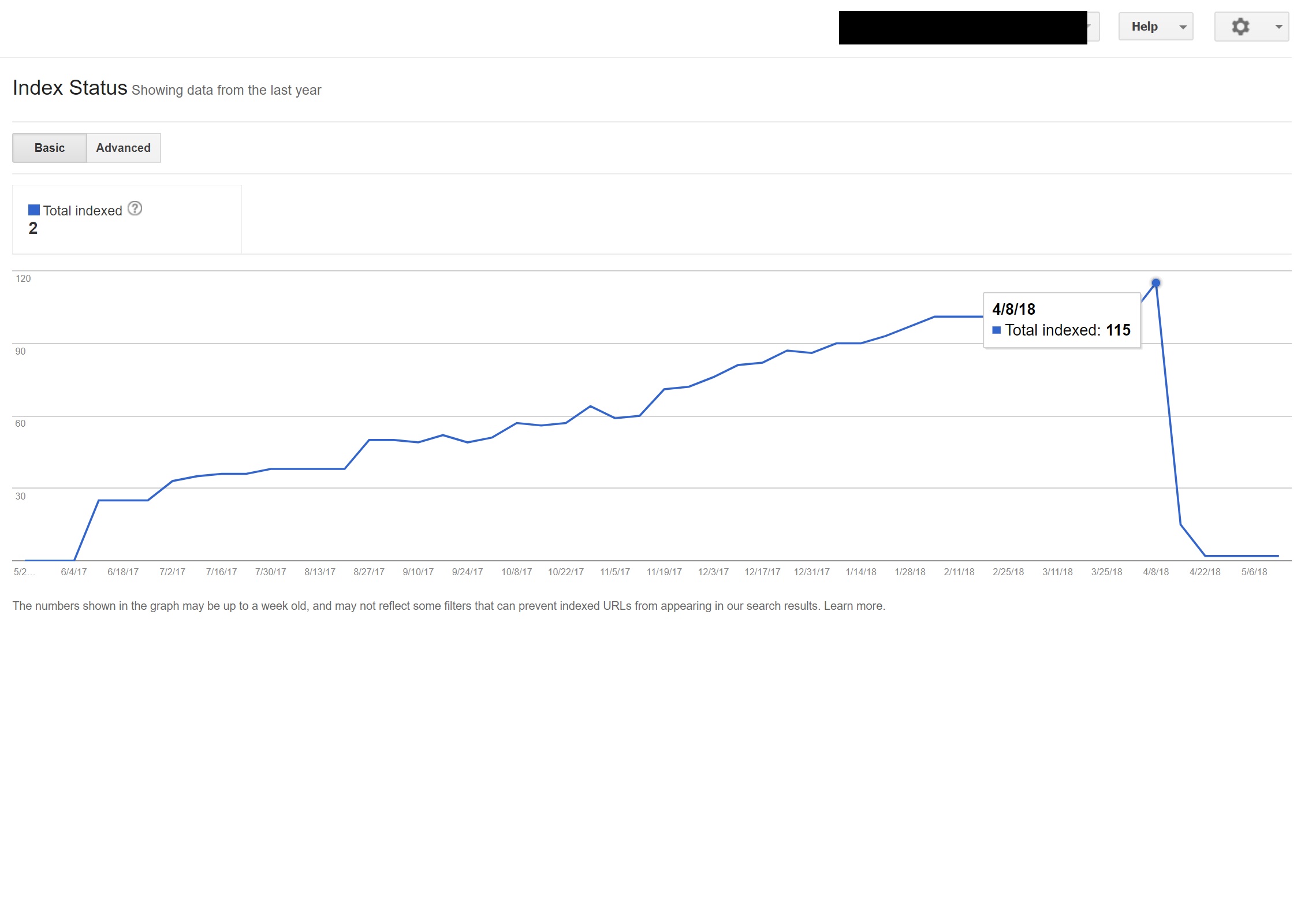
În acest exemplu, aproape tot conținutul care nu era în limba engleză de pe site a fost de-indexat de Google, deoarece era redirecționat către pagini care nu existau, oferind astfel mai multe erori 404.
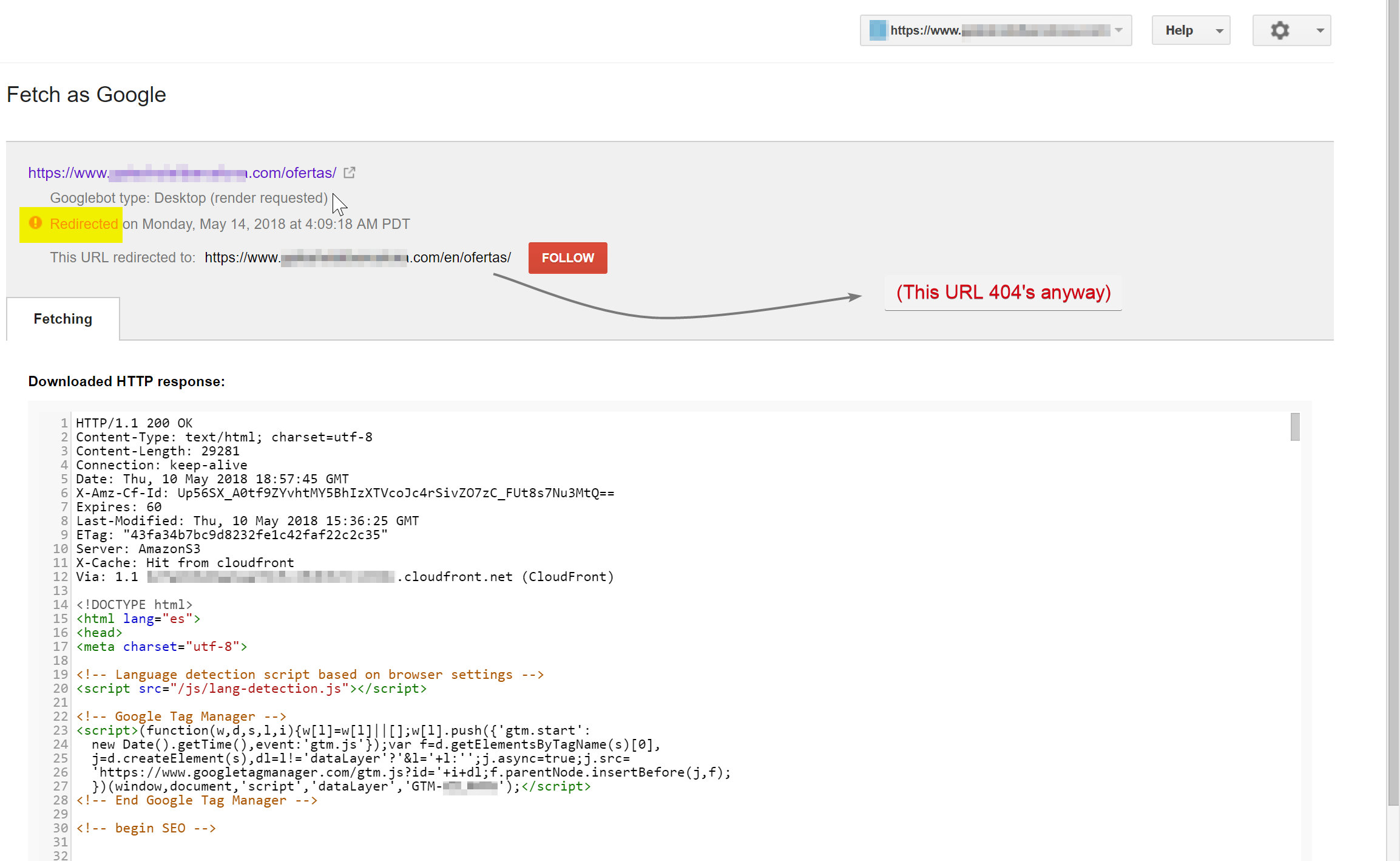
Googlebot încerca să acceseze cu crawlere conținutul spaniol (care exista la hotelname.com/ofertas) și era redirecționat către hotelname.com/en/ofertas – o adresă URL inexistentă.
În mod surprinzător, în acest caz, Googlebot urmărea toate aceste redirecționări JavaScript și, deoarece nu a putut găsi aceste adrese URL, a fost forțat să le elimine din indexul său.
În cazul de mai sus, am putut să confirm acest lucru accesând jurnalele de server ale site-ului, filtrăndu-mă la Googlebot și verificând unde a fost deservit 404.
Eliminarea scriptului de redirecționare JavaScript defect a rezolvat problema și, din fericire, paginile traduse nu au fost de-indexate mult timp.
Este întotdeauna o idee bună să testați lucrurile pe deplin – investiția într-un VPN vă poate ajuta să diagnosticați aceste tipuri de scenarii sau chiar să vă schimbați locația și/sau limba în browserul Chrome.
[Studiu de caz] Gestionarea mai multor audituri ale site-urilor
 Citiți studiul de caz
Citiți studiul de caz7 – Conținut duplicat
Conținutul duplicat este o problemă destul de comună și bine discutată și există multe moduri în care puteți verifica conținutul duplicat pe site-ul dvs. - Richard Baxter a scris recent un articol grozav pe această temă.
În cazul meu, problema este probabil un pic mai simplă. Am văzut în mod regulat site-uri publicând conținut grozav, adesea ca postare pe blog, dar apoi partajând aproape instantaneu acel conținut pe un site web terță parte, cum ar fi Medium.com.
Medium este un site grozav pentru reutilizarea conținutului existent pentru a ajunge la un public mai larg, dar ar trebui să aveți grijă cum este abordat acest lucru.
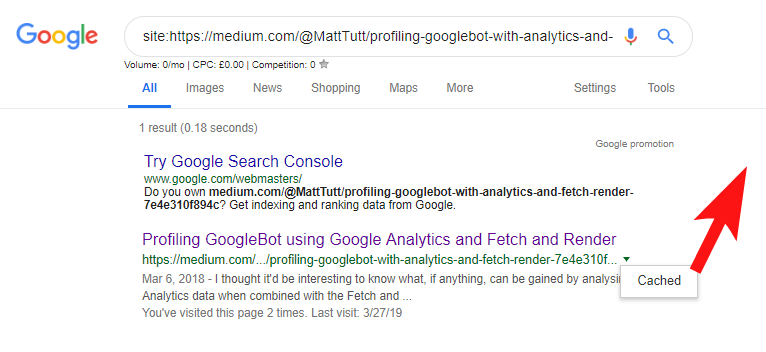
Când importați conținut din WordPress pe Medium, în timpul acestui proces Medium va folosi adresa URL a site-ului dvs. ca etichetă canonică. Deci, teoretic, ar trebui să ajute să acordați site-ului dvs. credit pentru conținut, ca sursă originală.
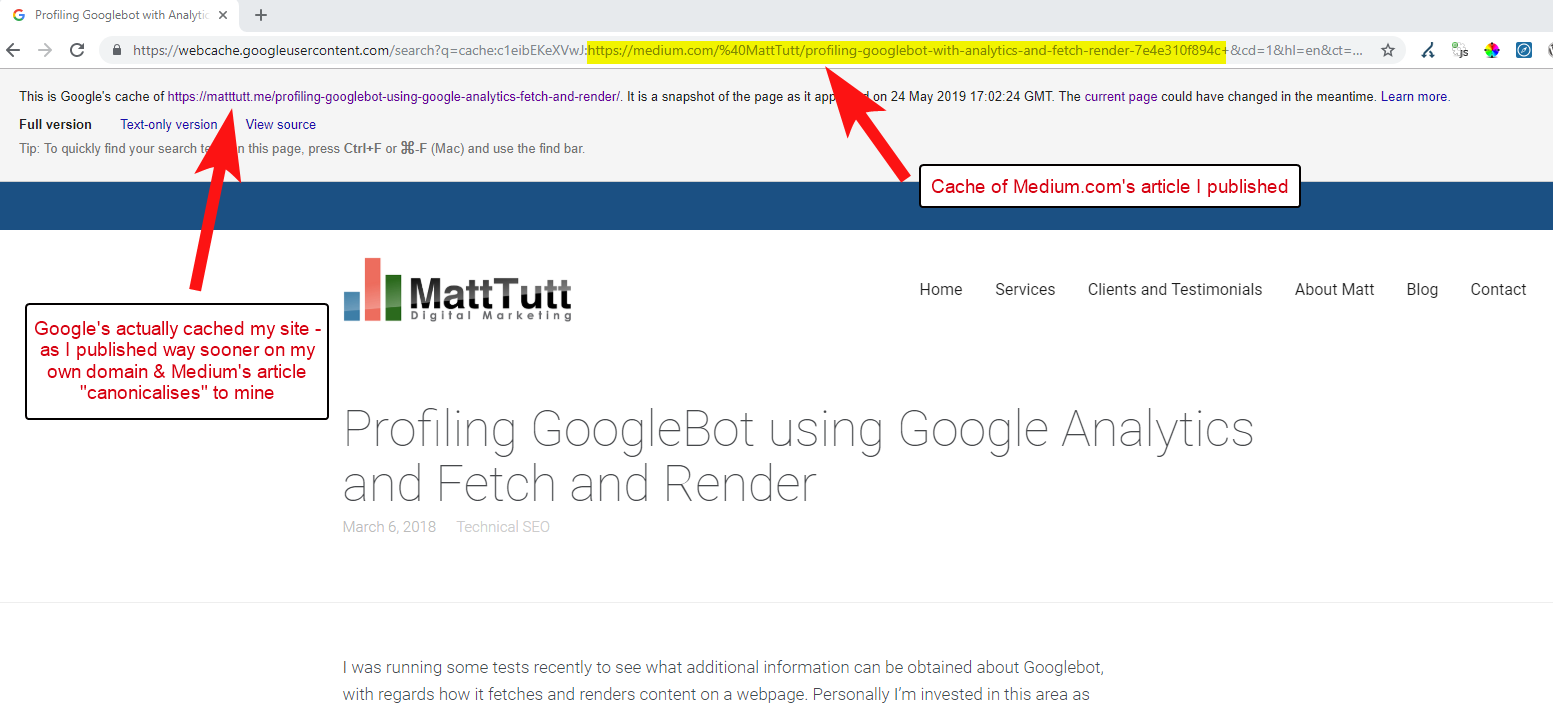
Din unele dintre analizele mele, deși nu funcționează întotdeauna așa.
Cred că acesta este cazul, deoarece atunci când un articol este publicat pe Medium fără a permite mai întâi Google timp să acceseze cu crawlere și să indexeze articolul pe domeniul dvs., dacă articolul merge bine pe Medium (care este puțin lovit sau ratat), conținutul dvs. devine indexate și asociate cu site-ul Medium, în ciuda faptului că ei indică canonic către al tău.
Odată ce conținutul este adăugat la Medium (și mai ales dacă este popular), puteți garanta aproape că piesa va fi răzuită și republicată pe web în altă parte aproape instantaneu - așa că din nou conținutul dvs. este duplicat în altă parte.
În timp ce toate acestea se întâmplă, sunt șanse ca, dacă domeniul dvs. este destul de mic în ceea ce privește autoritatea, este posibil ca Google să nu aibă nici măcar șansa de a accesa cu crawlere și de a indexa conținutul pe care l-ați publicat - și chiar s-ar putea întâmpla ca elementul de randare al accesarea cu crawlere/indexarea nu a fost încă finalizată sau există JavaScript grele care provoacă un decalaj mare între accesarea cu crawlere, redare și indexare a conținutului respectiv.
Am văzut situații în care o companie mare publică un articol grozav, dar a doua zi îl publică ca un articol de gândire pe un blog masiv de știri din industrie. În plus, site-ul lor a avut o problemă în care conținutul a fost duplicat (și indexat) la https://domain.com și https://www.domain.com.
La câteva zile după publicare, la căutarea unei fraze exacte a articolului între ghilimele în cadrul Google, site-ul companiei nu era de văzut nicăieri. În schimb, blogul autoritar din industrie a fost pe primul loc, iar alți re-editori ocupau următoarele poziții.
În acest caz, conținutul a fost asociat cu blogul din industrie și, prin urmare, orice linkuri pe care le câștigă piesa va beneficia site-ul respectiv - nu editorul original.
Dacă aveți de gând să reutilizați conținut oriunde pe web, este probabil să fie indexat, ar trebui să așteptați până când sunteți complet sigur că a fost indexat de Google pe propriul domeniu.
Probabil că munciți din greu pentru a vă crea și crea conținutul – nu le aruncați pe toate, fiind prea dornici să republicați în altă parte!
8 – Configurație AMP greșită (declarația URL AMP lipsește)
Doar câțiva dintre clienții pe care i-am asistat au ales să dea o încercare AMP, probabil pe baza unora dintre numeroasele studii de caz finanțate de Google cu privire la utilizarea acestuia.
Uneori nici măcar nu știam că un client avea o versiune AMP a site-ului său – a apărut un trafic ciudat în rapoartele de recomandare Google Analytics – unde versiunea AMP a site-ului trimitea înapoi la versiunea site-ului non-AMP.
În acest caz, versiunile paginilor AMP nu au fost configurate corect, deoarece nu a existat nicio referință URL de la capul paginilor non-AMP.

Fără să le spunem motoarelor de căutare că o pagină AMP există la o anumită adresă URL, nu are deloc rost să configurați AMP – ideea este că aceasta este indexată și returnată în SERPS pentru utilizatorii de telefonie mobilă.
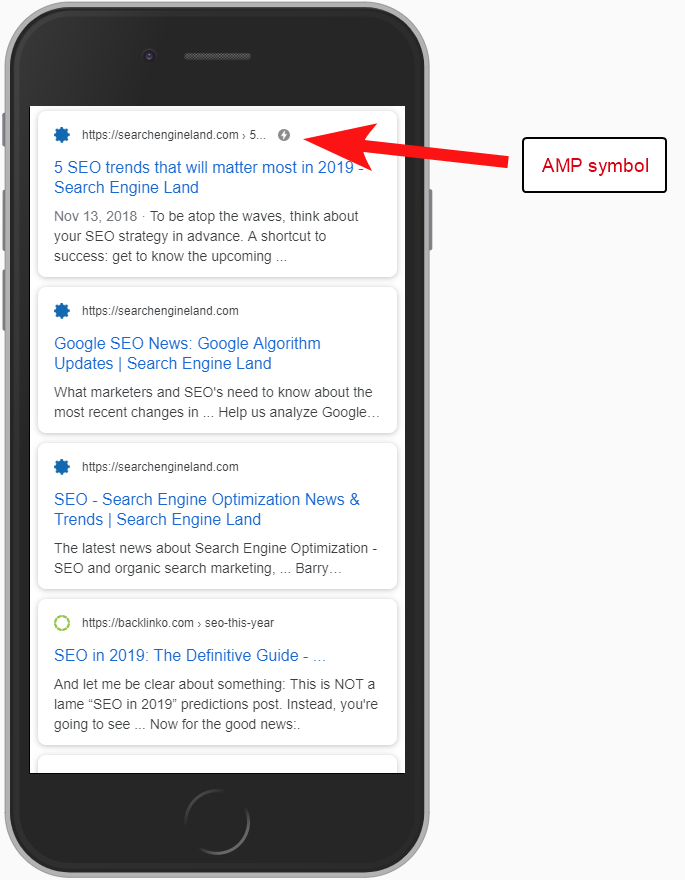
Adăugarea referinței la pagina dvs. non-AMP este o modalitate importantă de a spune Google despre pagina AMP și este important să rețineți că etichetele canonice de pe paginile AMP nu ar trebui să se auto-referenți: ele trimite înapoi la pagina non-AMP.
Și, deși nu este cu adevărat o considerație tehnică SEO, merită remarcat faptul că trebuie să includeți în continuare codul de urmărire pe paginile AMP dacă doriți să puteți raporta orice informații despre trafic și comportamentul utilizatorilor.
În mod obișnuit, ca parte a auditurilor mele SEO, îmi place să efectuez și câteva verificări de bază ale implementării analizei – altfel datele pe care le-ați furnizat ar putea să nu fie chiar atât de utile, mai ales dacă a existat o configurație de analiză anticipată.
9 – Domenii vechi care 302 redirecționează sau formează un lanț de redirecționări
Când lucrați cu o marcă hotelieră independentă mare din SUA, care a suferit mai multe rebranduri în ultimii ani (destul de frecvente în industria ospitalității), este important să monitorizați cum se comportă cererile anterioare de nume de domeniu.
Acest lucru este ușor de uitat, dar ar putea fi o simplă verificare semi-regulată a încercării de a accesa cu crawlere vechiul lor site folosind un instrument precum OnCrawl sau chiar un site terță parte care verifică codurile de stare și redirecționările.
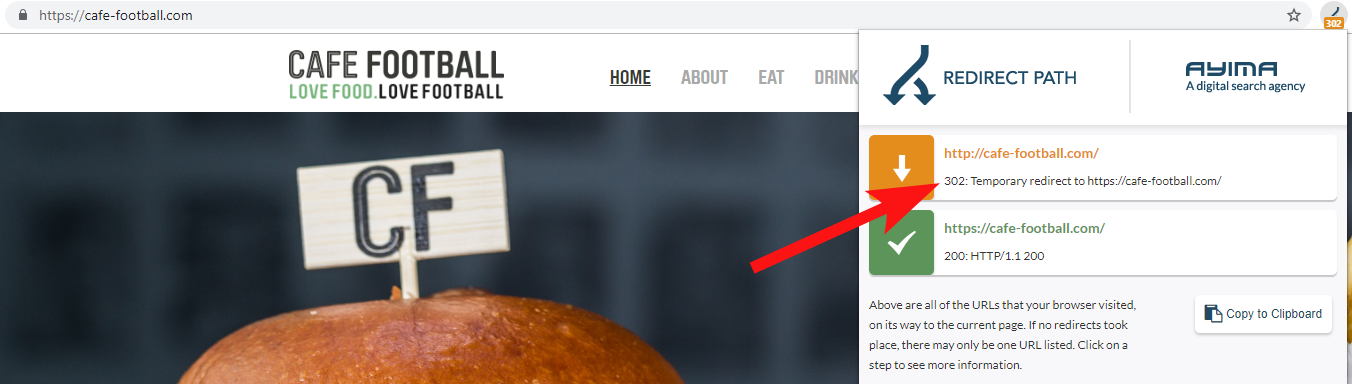
De cele mai multe ori, veți găsi redirecționările domeniului 302 către destinația finală (301 este întotdeauna cel mai bun pariu aici) sau 302 este către o versiune non-WWW a adresei URL înainte de a trece prin mai multe redirecționări înainte de a atinge adresa URL finală.
John Mueller de la Google a declarat anterior că urmăresc doar 5 redirecționări înainte de a renunța, în timp ce se știe, de asemenea, că pentru fiecare redirecționare trecută o parte din valoarea link-ului se pierde. Din aceste motive, prefer să rămân la redirecționări 301 cât mai curate posibil.
Calea de redirecționare de la Ayima este o extensie excelentă de browser Chrome care vă va arăta stările de redirecționare în timp ce navigați pe web.
Un alt mod în care am detectat nume vechi de domenii aparținând unui client este căutând pe Google numărul de telefon al acestuia, folosind ghilimele cu potrivire exactă sau părți din adresa lor.
O afacere precum un hotel nu își schimbă adesea adresa (oricum cel puțin o parte din ea) și este posibil să găsiți directoare/profiluri de afaceri vechi care se leagă la un domeniu vechi.
Utilizarea unui instrument de backlink precum Majestic sau Ahrefs ar putea afișa, de asemenea, unele link-uri vechi din domeniile anterioare, așa că acesta este și un bun port de apel - mai ales dacă nu sunteți în contact direct cu clientul.
10 – Gestionați prost conținutul căutării interne
Acesta este de fapt un subiect despre care am mai scris aici la OnCrawl – dar îl includ din nou pentru că încă văd conținut intern problematic care se întâmplă foarte des „în sălbăticie”.
Am început acest articol vorbind despre problema directivei robots.txt a lui Pingdom, care din exteriorul meu părea a fi o remediere pentru a preveni accesarea cu crawlere și indexarea conținutului pe care îl trimiteau.
Orice site care furnizează rezultate de căutare interne către Google ca conținut sau care produce o mulțime de conținut generat de utilizatori, trebuie să fie foarte atent la modul în care fac acest lucru.
Dacă un site furnizează rezultate de căutare interne către Google într-un mod foarte direct, acest lucru poate duce la o sancțiune manuală de vreun fel. Google ar vedea probabil asta ca pe o experiență proastă pentru utilizator - caută X, apoi ajung pe un site unde trebuie apoi să filtreze manual ceea ce își dorește.
În unele cazuri, cred că poate fi bine să difuzați conținut intern, depinde doar de context și circumstanțe. Un site de locuri de muncă, de exemplu, ar putea dori să ofere cele mai recente rezultate ale locurilor de muncă, care se actualizează aproape zilnic – așa că aproape că trebuie să se ocupe de asta.
Într-adevăr, este un exemplu celebru de site de locuri de muncă care poate duce acest lucru prea departe, generând tot felul de conținut bazat pe interogări de căutare populare (vedeți mai jos ce se poate întâmpla dacă utilizați această tactică).
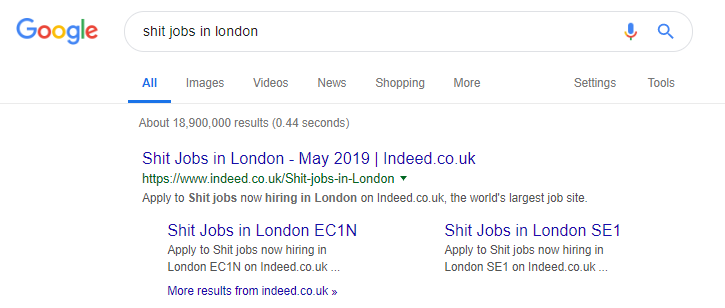
În ciuda acestui fapt, deși, conform datelor SEMRush, traficul lor organic se descurcă grozav – dar acestea sunt linii fine, iar comportamentul astfel vă expune un risc ridicat de a fi penalizat de Google.
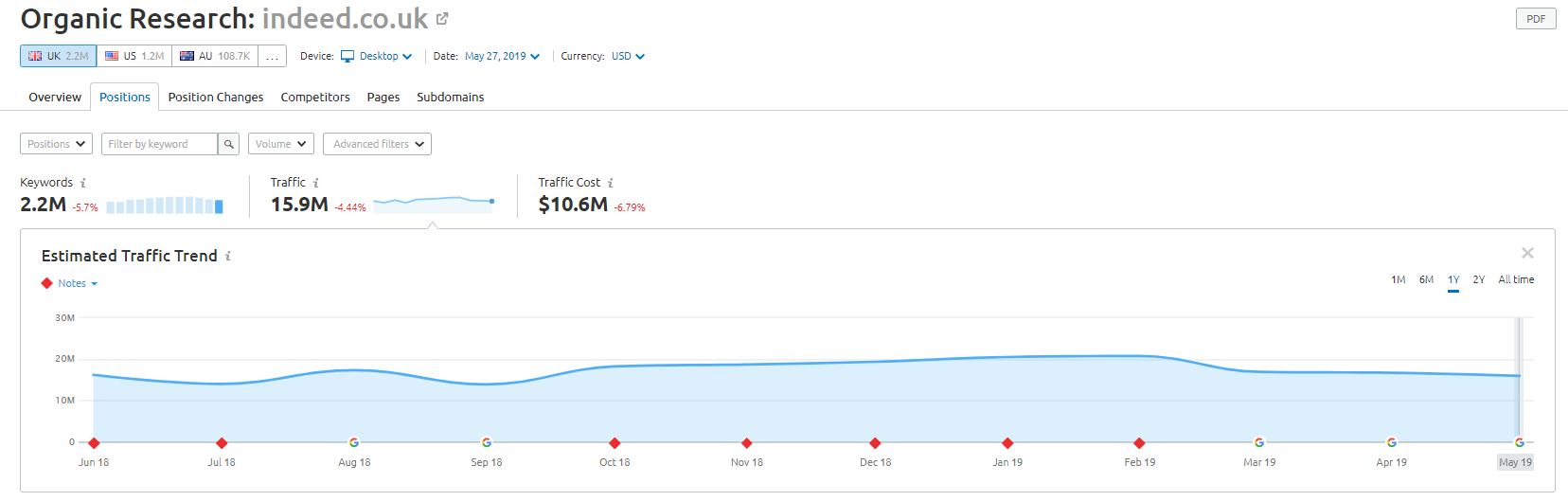
Retailerul online Wayfair.com este un alt brand căruia îi place să navigheze aproape de vânt. Cu milioane de adrese URL indexate (și o mulțime de adrese URL de cuvinte cheie generate automat), aceștia se descurcă grozav în ceea ce privește traficul organic – dar riscă să fie penalizați pentru difuzarea conținutului în acest mod către motoarele de căutare.
Prin implementarea unei structuri adecvate a site-ului, care implică clasificarea întregului conținut, construirea diferitelor ierarhii părinte/copil, chiar și folosind etichete sau alte taxonomii personalizate, ați putea ajuta la navigarea cu crawlerul de căutare și de clienți.
Folosirea trucurilor ca cele de mai sus ar putea câștiga pe termen scurt, dar este puțin probabil să aducă multe pentru tine pe termen lung. Acest lucru face ca este esențial să obțineți structura site-ului chiar de la început sau cel puțin să o planificați corect în avans.
Încheierea
Cele 10 erori discutate în acest articol sunt unele dintre cele mai frecvente probleme tehnice pe care le întâmpin în timpul auditurilor de șantier.
Corectarea acestor erori pe site-ul dvs. este un prim pas pentru a vă asigura că site-ul dvs. este sănătos din punct de vedere tehnic. Odată ce aceste probleme sunt corectate, auditurile tehnice se pot concentra asupra problemelor specifice site-ului dvs.