
Breadcrumb SEO, Python 3 și Oncrawl: pe drumul către automatizare!
Publicat: 2021-04-14Să învățăm cum să creăm automat o segmentare bazată pe breadcrumb cu OnCrawl și Python 3.
Ce este segmentarea în Oncrawl?
Oncrawl folosește segmentări pentru a împărți un set de pagini în grupuri. Acest lucru face foarte ușor să analizați datele din rapoartele de accesare cu crawlere, din analiza jurnalelor și din alte rapoarte de analiză încrucișată care combină datele de accesare cu crawlere cu Google Analytics, Google Search Console, AT Internet, Adobe Analytics sau Majestic pentru backlink.
De ce este important să creăm segmentări?
Odată ce accesarea cu crawlere este finalizată, crearea unei segmentări personalizate este cel mai important lucru de făcut. Acest lucru vă permite să citiți analizele din perspectiva care se potrivește cel mai bine site-ului dvs. și structurii acestuia.
Există multe modalități de a segmenta paginile site-ului dvs. și nu există o modalitate corectă sau greșită de a face acest lucru. De exemplu, este posibil să urmăriți structura site-ului dvs. pe baza structurii URL.
De exemplu, acest tip de adresă URL „ https://www.mydomain.com/news/canada/politics „, ar putea fi cu ușurință segmentată astfel:
- Un grup pentru a izola pagina de pornire
- Un grup pentru toate știrile
- Un subgrup pentru directorul Canada
- Un subgrup pentru directorul Politică
După cum puteți vedea, este posibil să creați până la 3 niveluri de adâncime pentru segmentările dvs. Acest lucru vă permite să vă concentrați pe anumite grupuri sau subgrupuri în analiza SEO, fără a fi nevoie să schimbați segmentele.
Cum creez o segmentare de bază?
Trebuie să știți că Oncrawl se ocupă de crearea primei segmentări, de la sine. Aceasta se bazează pe „Prima cale” sau pe primul director întâlnit în adresele URL.
Acest lucru vă permite să aveți o analiză disponibilă imediat ce accesarea cu crawlere este finalizată.
Este posibil ca această segmentare să nu reflecte structura site-ului dvs. sau să doriți să analizați lucrurile dintr-un unghi diferit.
Deci, veți crea o nouă segmentare folosind ceea ce numim OQL, care înseamnă Oncrawl Query Language. Este un fel ca SQL, doar că mult mai simplu și mai intuitiv: 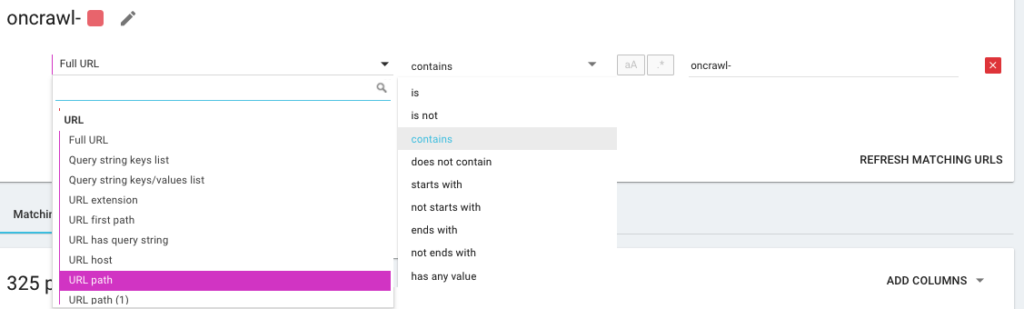
De asemenea, este posibil să folosiți operatori de condiție AND/OR pentru a fi cât mai precis posibil: 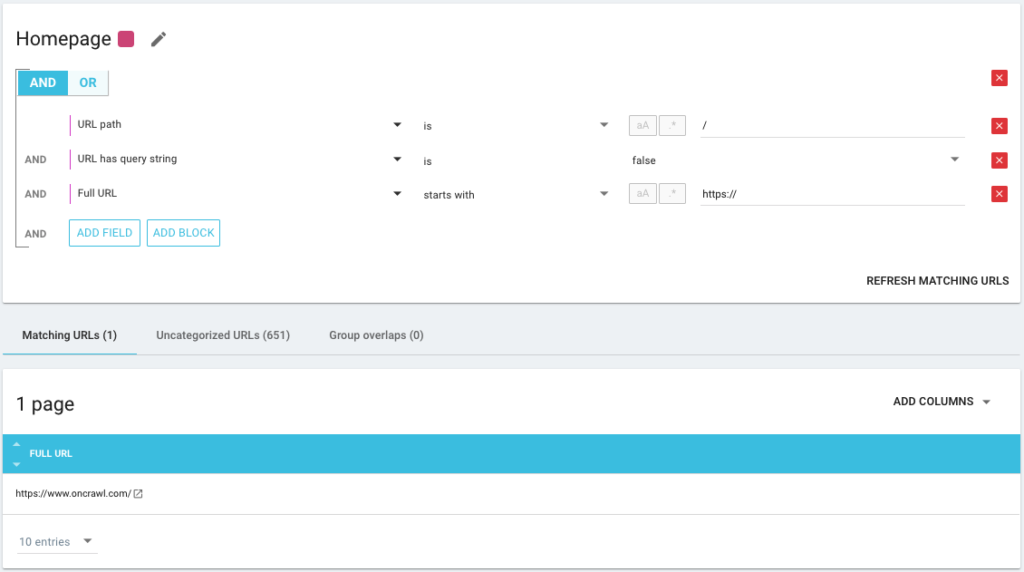
Segmentarea paginilor mele folosind diferite metode
Utilizarea altor KPI-uri
Segmentările bazate pe URL-uri sunt bune, dar ar fi perfect dacă am putea combina și alți KPI-uri, cum ar fi gruparea URL-urilor care încep cu /car-rental/ și al căror H1 are expresia „ Agenții de închirieri auto ” și un alt grup în care H1 ar fi „ Agenții de închiriere de utilități ”, este posibil?
Da este posibil! În timpul creării segmentărilor dumneavoastră, aveți la dispoziție toți KPI-urile pe care le folosim, și nu doar pe cei de la crawler, ci și pe cei de la conectori. Acest lucru face ca crearea de segmentări să fie foarte puternică și vă permite să aveți unghiuri de analiză total diferite!
De exemplu, îmi place să creez o segmentare folosind poziția medie a adreselor URL datorită conectorului Google Search Console.
În acest fel, pot identifica cu ușurință adresele URL din adâncimea structurii mele care încă funcționează sau adresele URL apropiate de pagina mea de pornire care se află pe pagina 2 a Google.
Pot vedea dacă aceste pagini au conținut duplicat, o etichetă de titlu goală, dacă primesc suficiente link-uri... Pot vedea și cum se comportă Googlebot pe aceste pagini. Este frecvența de accesare cu crawlere bună sau rea? Pe scurt, mă ajută să prioritizez și să iau decizii care vor avea un impact real asupra SEO și rentabilitatea investiției mele.
Date oncrawl³
 Află mai multe
Află mai multeFolosind Data Ingest
Dacă nu sunteți familiarizat cu caracteristica noastră Data Ingest, vă invit să citiți mai întâi acest articol pe acest subiect. Acesta este un alt instrument foarte puternic care vă permite să adăugați surse de date externe la Oncrawl.
De exemplu, puteți adăuga date de la SEMrush, Ahrefs, Babbar.tech... Avantajul este că vă puteți grupa paginile în funcție de metrici preluate din aceste instrumente și puteți efectua analiza pe baza datelor care vă interesează, chiar dacă nu este nativ în Oncrawl.
Recent, am lucrat cu un grup hotelier global. Ei folosesc o metodă de punctare internă pentru a ști dacă înregistrările hotelului sunt completate corect, dacă au imagini, videoclipuri, conținut etc... Ei determină un procent de finalizare, pe care l-am folosit pentru a analiza încrucișat datele fișierelor de accesare cu crawlere și jurnal.
Rezultatul ne permite să știm dacă Googlebot petrece mai mult timp pe pagini care sunt completate corect, să știm dacă unele pagini cu un scor mai mare de 90% sunt prea adânci, nu primesc suficiente link-uri... Ne permite să arătăm că cu cât este mai mare scor, cu cât paginile primesc mai multe vizite, cu atât sunt mai explorate de Google și cu atât poziționarea lor în SERP Google este mai bună. Un argument de neoprit pentru a-i încuraja pe hotelieri să-și completeze lista de hoteluri!
Creați o segmentare bazată pe traseul breadcrumb SEO
Acesta este subiectul acestui articol, așa că să trecem la miezul problemei. Este uneori dificil să segmentezi paginile site-ului tău, dacă structura URL-urilor nu atașează pagini la un anume director. Acesta este adesea cazul site-urilor de comerț electronic, unde paginile de produse sunt toate la rădăcină. Prin urmare, este imposibil să știi din URL cărui grup aparține o pagină.
Pentru a grupa paginile împreună, trebuie să găsim o modalitate de a identifica grupul din care aparțin. Ne-a avut așadar ideea de a prelua traseul seo de breadcrumb al fiecărei adrese URL și de a le clasifica pe baza valorilor din seo de breadcrumbs, folosind funcția Scraper oferită de Oncrawl.
Scraping pesmet SEO cu Oncrawl
După cum am văzut mai sus, vom configura o regulă de răzuire pentru a recupera traseul pesmet. De cele mai multe ori este destul de simplu, deoarece putem merge și prelua informațiile într-un div , apoi câmpurile fiecărui nivel sunt în
liste ul și li : 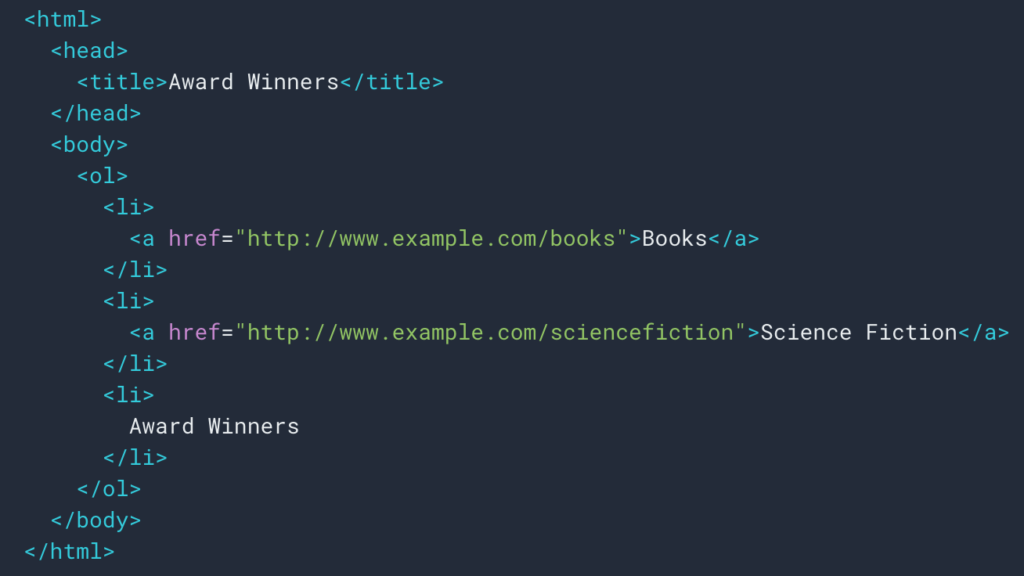
Uneori, de asemenea, putem prelua cu ușurință informațiile datorită tipului de date structurate Breadcrumb. Deci, va fi ușor să recuperați valoarea câmpului „nume” pentru fiecare poziție. 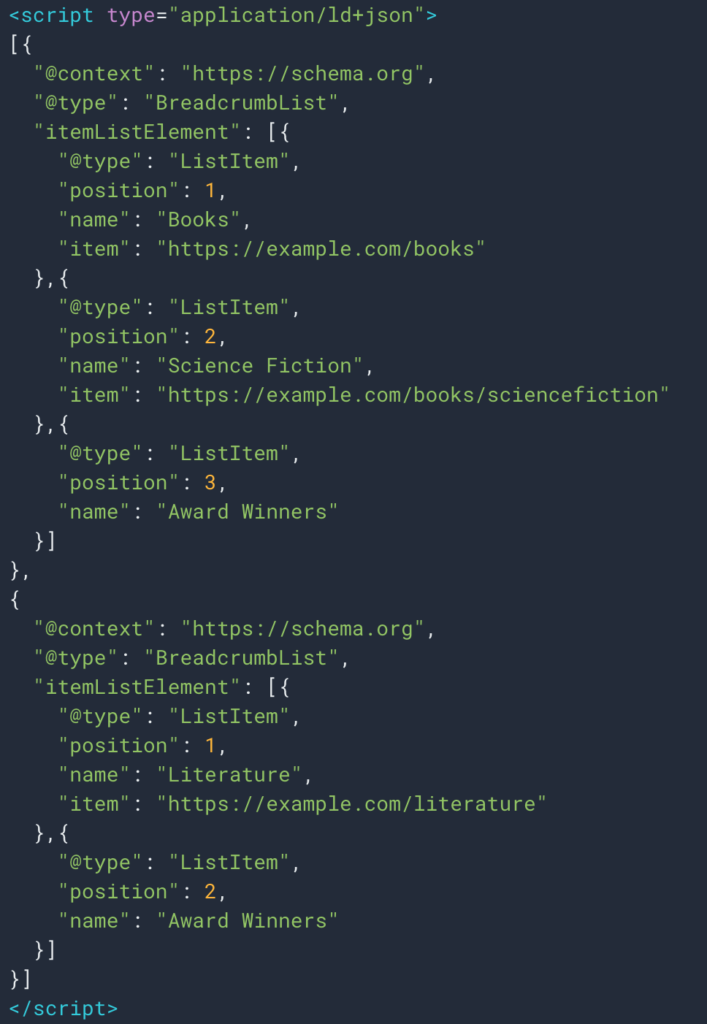
Iată un exemplu de regulă de răzuire pe care o folosesc: 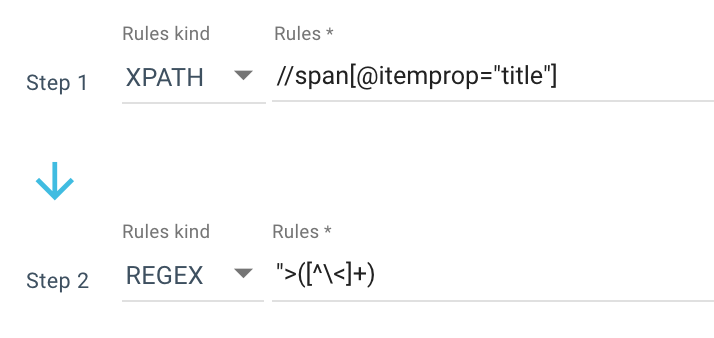
Sau această regulă: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()

Așa că primesc tot span itemprop=”title” cu Xpath, apoi folosesc o expresie obișnuită pentru a extrage totul după “> care nu este un > caracter. Dacă doriți să aflați mai multe despre Regex, vă sugerez să citiți acest articol pe acest subiect și Cheat sheet despre Regex.
Obțin mai multe valori ca aceasta ca rezultat: 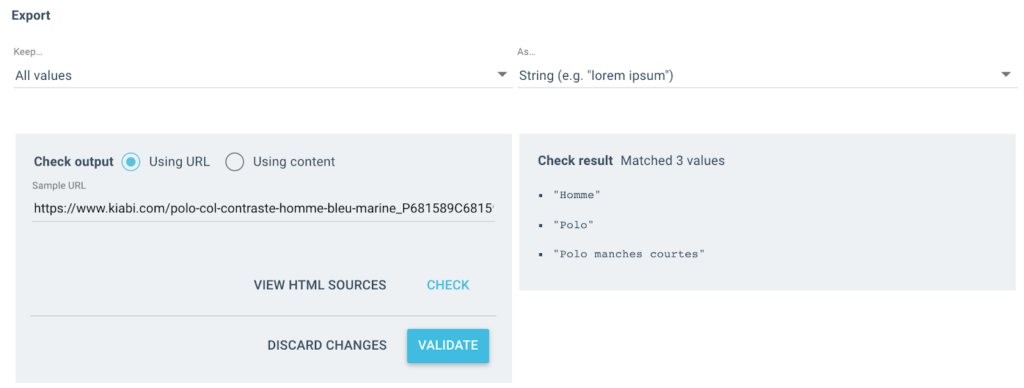
Pentru URL-ul testat, voi avea un câmp „Breadcrumb” cu 3 valori:
- Om
- maiou Polo
- Polo cu mânecă scurtă
import json
import aleatoriu
cereri de import
# Autentic
# Două moduri, cu x-oncrawl-token decât le puteți obține în anteturile solicitărilor din browser
# sau cu un token api aici: https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# Setați ID-ul de accesare cu crawlere acolo unde există un câmp personalizat pe firul de navigare
CRAWL_
# Actualizați articolele interzise pe care nu doriți să le obțineți în segmentare
FORBIDDEN_BREADCRUMB_ITEMS = ('Accueil',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip()
pentru v în FORBIDDEN_BREADCRUMB_ITEMS.split(',')
]
def culoarea_aleatorie():
random_number = random.randint(0, 16777215)
hex_number = str(hex(număr_aleatoriu))
hex_number = hex_number[2:].ljust(6, '0')
returnează f'#{hex_number}'
def value_to_group(valoare):
întoarcere {
„culoare”: random_color(),
„nume”: valoare,
'oql': {'sau': [{'câmp': ['custom_Breadcrumb', 'equals', value]}]}
}
def walk_dict(dicționar, nivel=0):
ret = {
"icoana": "tabloul de bord",
„transposabil”: fals,
"name": "Pesmet"
}Acum că regula este definită, îmi pot lansa accesul cu crawlere, iar Oncrawl va prelua automat valorile de breadcrumb și le va asocia cu fiecare adresă URL accesată cu crawlere.
Automatizați crearea segmentării pe mai multe niveluri cu Python
Acum că am toate valorile de breadcrumb SEO pentru fiecare adresă URL, vom folosi un script python de automatizare seo într-un Google Colab pentru a crea automat o segmentare compatibilă cu Oncrawl.
Pentru scriptul în sine, folosim 3 biblioteci care sunt:
- json (Pentru a genera segmentarea noastră scrisă în Json)
- csv
- aleatoriu (Pentru a genera coduri de culoare hexazecimale pentru fiecare grup)
Odată lansat scriptul, acesta se ocupă automat de crearea segmentării în proiectul tău! 
Previzualizarea datelor în analize
Acum că segmentarea noastră este creată, este posibil să am acces la diferite analize cu o vizualizare segmentată bazată pe traseul meu breadcrumb. 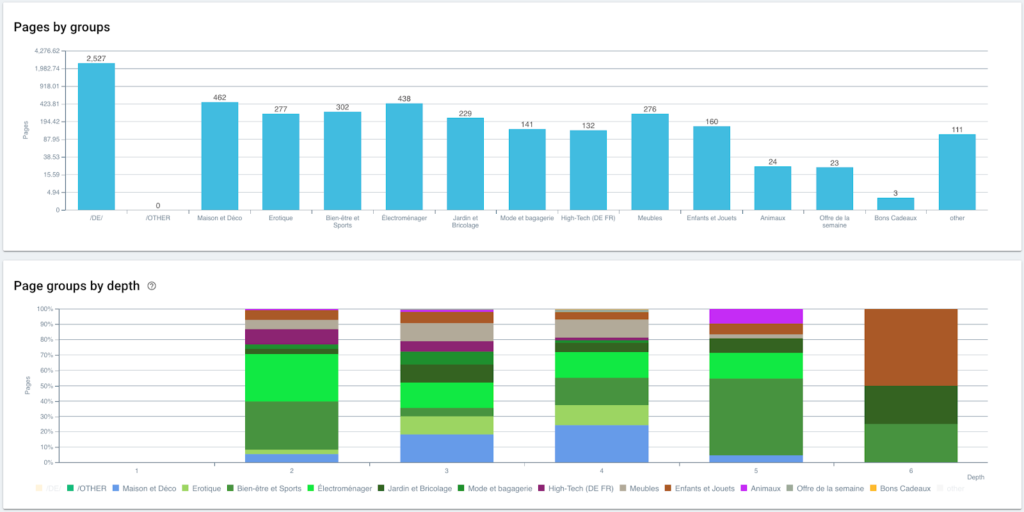
Distribuția paginilor pe grupe și după profunzime
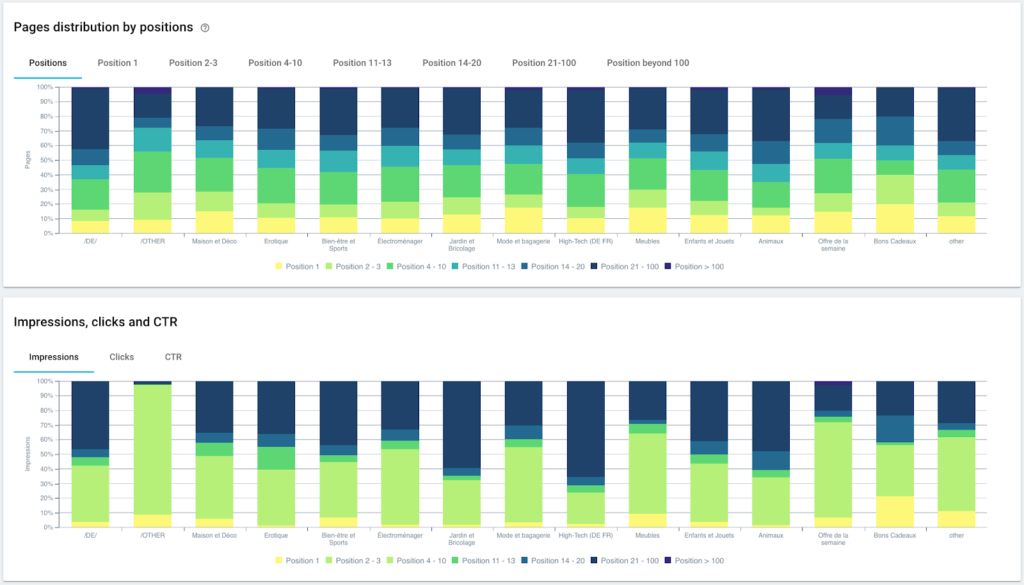
Performanța clasamentului (GSC)
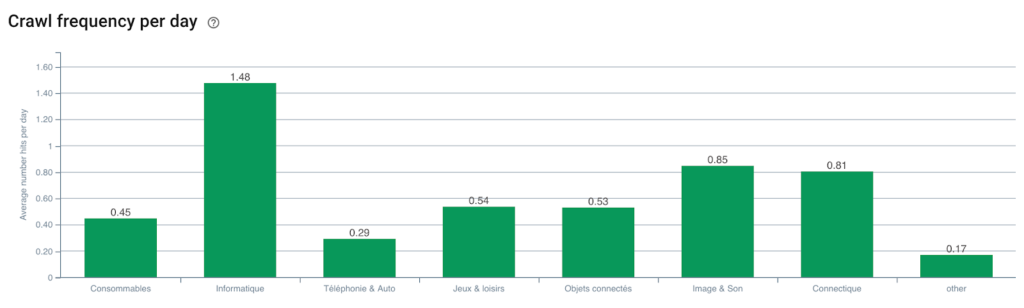
Frecvența de accesare cu crawlere Googlebot
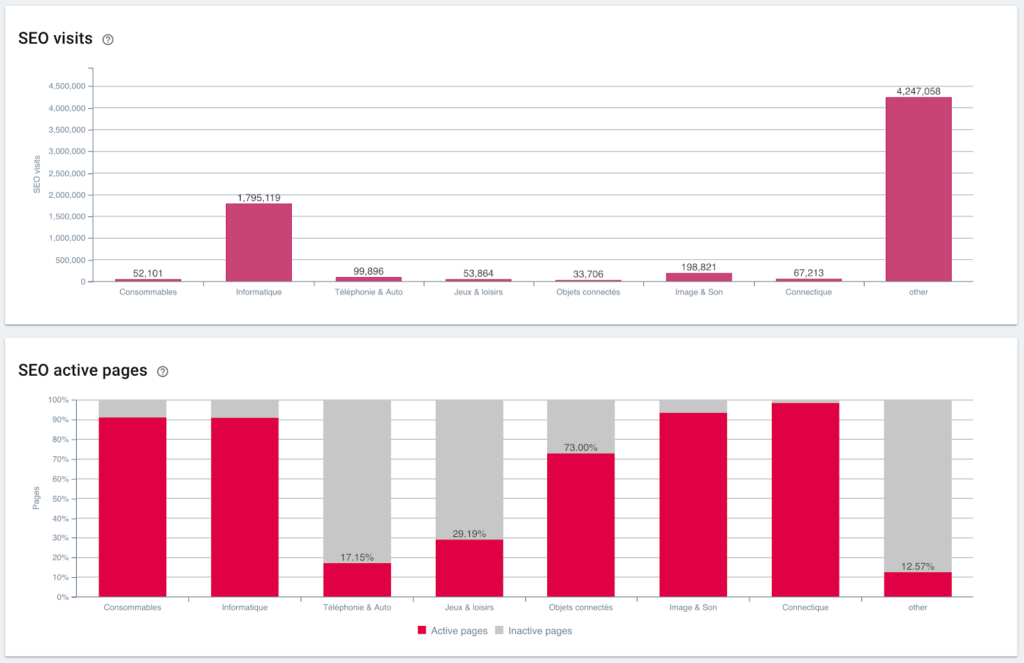
Vizite SEO și raportul paginii active
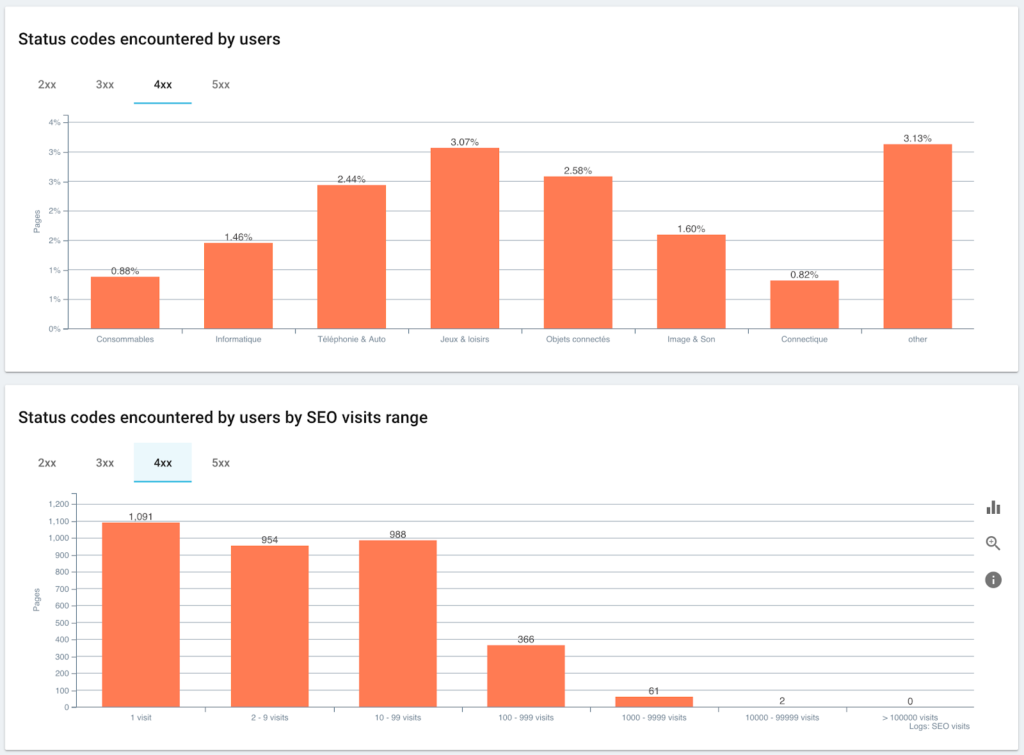
Codurile de stare întâlnite de utilizatori vs. sesiuni SEO
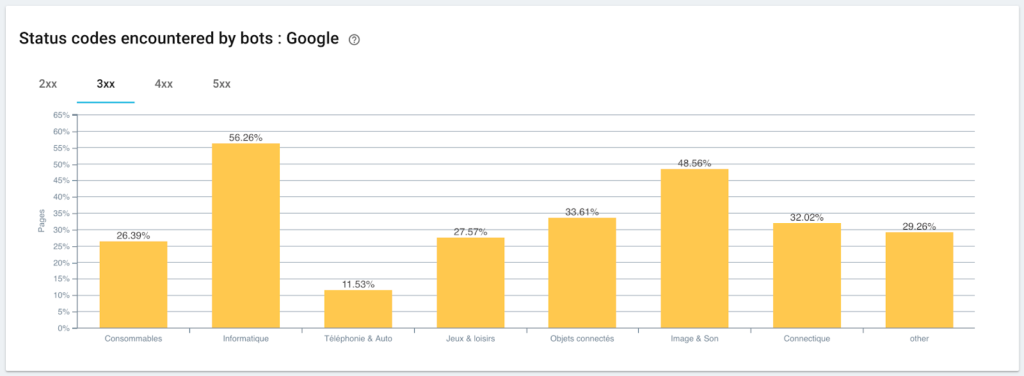
Monitorizarea codurilor de stare întâlnite de Googlebot
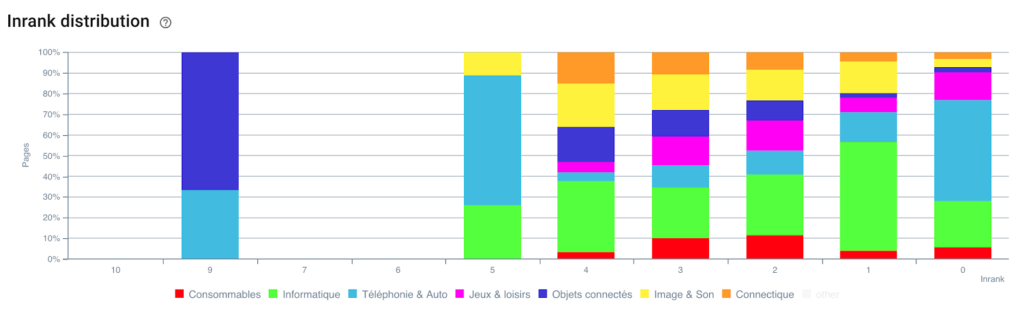
Distribuția Inrank-ului
Și iată-ne, tocmai am creat o segmentare automată datorită unui script folosind Python și OnCrawl. Toate paginile sunt acum grupate în funcție de traseul breadcrumb și aceasta pe 3 niveluri de adâncime: 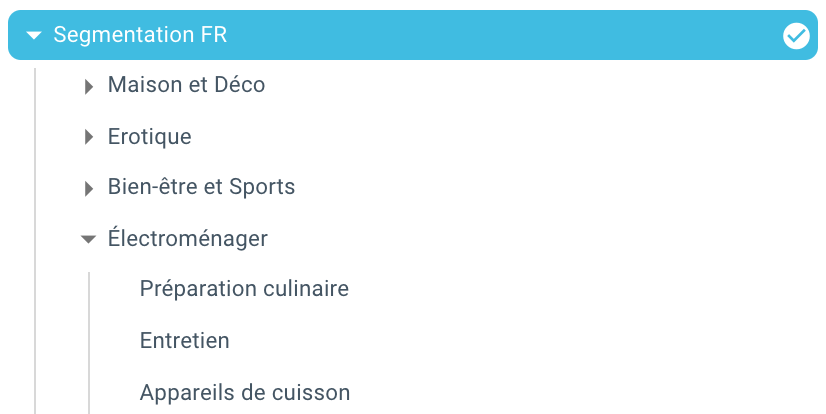
Avantajul este că acum putem monitoriza diferiții KPI (Crawl, profunzime, link-uri interne, buget de crawl, sesiuni SEO, vizite SEO, performanțe de clasare, timp de încărcare) pentru fiecare grup și subgrup de pagini.
Viitorul SEO cu Oncrawl
Probabil că te gândești că este grozav să ai această capacitate „din cutie”, dar nu ai neapărat timp să faci totul. Vestea bună este că lucrăm pentru ca această caracteristică să fie integrată direct în viitorul apropiat.
Aceasta înseamnă că în curând veți putea crea automat o segmentare pe orice câmp sau câmp abandonat din Data Ingest cu un simplu clic. Și asta vă va economisi o mulțime de timp, permițându-vă în același timp să efectuați analize SEO transversale incredibile.
Imaginați-vă că puteți elimina orice date din codul sursă al paginilor dvs. sau puteți integra orice KPI pentru fiecare adresă URL. Singura limită este imaginația ta!
De exemplu, puteți prelua prețul de vânzare al produselor și puteți vedea profunzimea, Inrank-ul, backlink-urile, bugetul de crawl în funcție de preț.
Dar putem, de asemenea, să preluăm numele autorilor articolelor dvs. media și să vedem cine are cele mai bune performanțe și să aplicăm metodele de scriere care funcționează cel mai bine.
Putem prelua recenziile și evaluările produselor dvs. și să vedem dacă cele mai bune produse sunt accesibile cu un minim de clicuri, primim suficiente link-uri, au backlink-uri, sunt bine accesate cu crawlere de Googlebot etc...
Vă putem integra datele companiei, cum ar fi cifra de afaceri, marja, rata de conversie, cheltuielile dvs. Google Ads.
Acum rămâne la latitudinea dvs. să vă imaginați cum puteți face referințe încrucișate la datele pentru a vă extinde analiza și a lua deciziile SEO potrivite.
Doriți să testați segmentarea automată pe traseul breadcrumb? Contactați-ne prin intermediul casetei de chat direct din Oncrawl.
Bucură-te de târâtul tău!