
Extrageți automat concepte și cuvinte cheie dintr-un text (Partea I: Metodele tradiționale)
Publicat: 2022-02-22La departamentul de cercetare și dezvoltare al Oncrawl, căutăm din ce în ce mai mult să îmbunătățim conținutul semantic al paginilor dvs. Web. Folosind modele de învățare automată pentru procesarea limbajului natural (NLP), putem compara conținutul paginilor dvs. în detaliu, putem crea rezumate automate, completăm sau corectăm etichetele articolelor dvs., putem optimiza conținutul în funcție de datele dvs. din Google Search Console etc.
Într-un articol anterior, am vorbit despre extragerea conținutului text din pagini HTML. De data aceasta, am vrea să vorbim despre extragerea automată a cuvintelor cheie dintr-un text. Acest subiect va fi împărțit în două postări:
- prima va acoperi contextul și așa-numitele metode „tradiționale” cu mai multe exemple concrete
- cel de-al doilea care va veni în curând se va ocupa de abordări mai semantice bazate pe transformatoare și metode de evaluare pentru a compara aceste metode diferite.
Context
Dincolo de un titlu sau un rezumat, ce modalitate mai bună de a identifica conținutul unui text, al unei lucrări științifice sau al unei pagini web decât cu câteva cuvinte cheie. Este o modalitate simplă și foarte eficientă de a identifica subiectul și conceptele unui text mult mai lung. De asemenea, poate fi o modalitate bună de a clasifica o serie de texte: identificați-le și grupați-le după cuvinte cheie. Site-urile care oferă articole științifice precum PubMed sau arxiv.org pot oferi categorii și recomandări bazate pe aceste cuvinte cheie.
Cuvintele cheie sunt de asemenea foarte utile pentru indexarea documentelor foarte mari și pentru regăsirea informațiilor, domeniu de expertiză bine cunoscut de motoarele de căutare
Lipsa cuvintelor cheie este o problemă recurentă în clasificarea automată a articolelor științifice [1]: multe articole nu au cuvinte cheie atribuite. Prin urmare, trebuie găsite metode pentru a extrage automat concepte și cuvinte cheie dintr-un text. Pentru a evalua relevanța unui set de cuvinte cheie extras automat, seturile de date compară adesea cuvintele cheie extrase de un algoritm cu cuvintele cheie extrase de mai mulți oameni.
După cum vă puteți imagina, aceasta este o problemă împărtășită de motoarele de căutare la clasificarea paginilor web. O mai bună înțelegere a proceselor automate de extragere a cuvintelor cheie permite să înțelegem mai bine de ce o pagină web este poziționată pentru un astfel de cuvânt cheie. De asemenea, poate dezvălui lacune semantice care îl împiedică să se claseze bine pentru cuvântul cheie pe care l-ați vizat.
Există, evident, mai multe moduri de a extrage cuvinte cheie dintr-un text sau dintr-un paragraf. În această primă postare, vom descrie așa-numitele abordări „clasice”.
[Ebook] Data SEO: următoarea mare aventură
 Citiți cartea electronică
Citiți cartea electronicăConstrângeri
Cu toate acestea, avem câteva limitări și premise în alegerea unui algoritm:
- Metoda trebuie să poată extrage cuvinte cheie dintr-un singur document. Unele metode necesită un corpus complet, adică câteva sute sau chiar mii de documente. Deși aceste metode pot fi folosite de motoarele de căutare, ele nu vor fi utile pentru un singur document.
- Ne aflăm într-un caz de învățare automată nesupravegheată. Nu avem la îndemână un set de date în franceză, engleză sau alte limbi cu date adnotate. Cu alte cuvinte, nu avem mii de documente cu cuvinte cheie deja extrase.
- Metoda trebuie să fie independentă de domeniul/câmpul lexical al documentului. Dorim să putem extrage cuvinte cheie din orice tip de document: articole de știri, pagini web etc. Rețineți că unele seturi de date care au deja cuvinte cheie extrase pentru fiecare document sunt adesea domeniului specific medicinei, informaticii etc.
- Unele metode se bazează pe modele de etichetare POS, adică capacitatea unui model NLP de a identifica cuvintele dintr-o propoziție după tipul lor gramatical: un verb, un substantiv, un determinant. Determinarea importanței unui cuvânt cheie care este mai degrabă un substantiv decât un determinant este în mod clar relevantă. Cu toate acestea, în funcție de limbă, modelele de etichetare POS sunt uneori de o calitate foarte neuniformă.
Despre metodele tradiționale
Facem diferența între așa-numitele metode „tradiționale” și cele mai recente care folosesc NLP – Natural Language Processing – tehnici precum încorporarea cuvintelor și încorporarea contextuală. Acest subiect va fi tratat într-o postare viitoare. Dar mai întâi, să ne întoarcem la abordările clasice, distingem două dintre ele:
- abordarea statisticii
- abordarea grafică
Abordarea statistică se va baza în principal pe frecvențele cuvintelor și pe co-apariția acestora. Începem cu ipoteze simple pentru a construi euristici și a extrage cuvinte importante: un cuvânt foarte frecvent, o serie de cuvinte consecutive care apar de mai multe ori etc. Metodele bazate pe grafice vor construi un grafic în care fiecărui nod îi poate corespunde un cuvânt, un grup de cuvinte sau propoziție. Apoi, fiecare arc poate reprezenta probabilitatea (sau frecvența) de a observa împreună aceste cuvinte.
Iată câteva metode:
- Bazat pe statistici
- TF-IDF
- grebla
- IAKE
- Pe baza de grafice
- TextRank
- TopicRank
- SingleRank
Toate exemplele oferite folosesc text preluat de pe această pagină web: Jazz au Tresor : John Coltrane – Impressions Graz 1962.
Abordarea statistică
Vă vom prezenta cele două metode Rake și Yake. Într-un context SEO, este posibil să fi auzit de metoda TF-IDF. Dar, deoarece necesită un corpus de documente, nu ne vom ocupa aici.
grebla
RAKE înseamnă Extragere automată rapidă a cuvintelor cheie. Există mai multe implementări ale acestei metode în Python, inclusiv rake-nltk. Scorul fiecărui cuvânt cheie, care se mai numește și frază cheie, deoarece conține mai multe cuvinte, se bazează pe două elemente: frecvența cuvintelor și suma apariției acestora. Constituția fiecărei fraze cheie este foarte simplă, constă din:
- tăiați textul în propoziții
- tăiați fiecare propoziție în fraze cheie
În următoarea propoziție, vom lua toate grupurile de cuvinte separate prin elemente de punctuație sau cuvinte oprite:
Chiar înainte, Coltrane conducea un cvintet, cu Eric Dolphy alături de el și Reggie Workman la contrabas.
Acest lucru ar putea avea ca rezultat următoarele expresii cheie:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
Rețineți că cuvintele oprite sunt o serie de cuvinte foarte frecvente, cum ar fi „ the ”, „ in ”, „și” or „ it ”. Deoarece metodele clasice se bazează adesea pe calcularea frecvenței de apariție a cuvintelor, este important să alegeți cu atenție cuvintele oprite. De cele mai multe ori, nu dorim să avem cuvinte precum >"to" , "the" or "of" în propunerile noastre de expresii cheie. Într-adevăr, aceste cuvinte oprite nu sunt asociate cu un anumit câmp lexical și, prin urmare, sunt mult mai puțin relevante decât cuvintele „ jazz ” sau „ saxophone ”, de exemplu.

Odată ce am izolat mai multe expresii cheie candidate, le acordăm un punctaj în funcție de frecvența cuvintelor și a aparițiilor concomitente. Cu cât scorul este mai mare, cu atât expresiile cheie ar trebui să fie mai relevante.
Să încercăm repede cu textul din articolul despre John Coltrane.
# python fragment pentru rake din rake_nltk import Rake # să presupunem că aveți deja articolul în variabila „text”. rake = Rake(stopwords=FRENCH_STOPWORDS, max_length=4) rake.extract_keywords_from_text(text) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
Iată primele 5 fraze cheie:
„radio public național austriac”, „vârfurile lirice mai cerești”, „grazul are două particularități”, „saxofon tenor john coltrane”, „numai versiune înregistrată”
Există câteva dezavantaje ale acestei metode. Prima este importanța alegerii cuvintelor oprite, deoarece acestea sunt folosite pentru a împărți o propoziție în fraze cheie candidate. Al doilea este că atunci când frazele cheie sunt prea lungi, ele vor avea adesea un scor mai mare din cauza co-apariției cuvintelor prezente. Pentru a limita lungimea frazelor cheie, am setat metoda cu max_length=4 .
IAKE
YAKE înseamnă Yet Another Keyword Extractor. Această metodă se bazează pe următorul articol YAKE! Extragerea cuvintelor cheie din documente individuale folosind mai multe caracteristici locale care datează din 2020. Este o metodă mai recentă decât RAKE ai cărui autori au propus o implementare Python disponibilă pe Github.
Ne vom baza, ca și în cazul RAKE, pe frecvența cuvintelor și pe co-apariția. Autorii vor adăuga, de asemenea, câteva euristici interesante:
- vom face distincția între cuvintele cu litere mici și cuvintele cu litere mari (fie prima literă, fie întregul cuvânt). Vom presupune aici că cuvintele care încep cu majusculă (cu excepția începutului unei propoziții) sunt mai relevante decât altele: nume de oameni, orașe, țări, mărci. Acesta este același principiu pentru toate cuvintele cu majuscule.
- scorul fiecărei expresii cheie candidat va depinde de poziția sa în text. Dacă frazele cheie candidate apar la începutul textului, vor avea un scor mai mare decât dacă apar la sfârșit. De exemplu, articolele de știri menționează adesea concepte importante la începutul articolului.
# python fragment pentru yake din yake import KeywordExtractor ca Yake yake = Yake(lan="fr", stopwords=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(text)
La fel ca RAKE, iată primele 5 rezultate:
„Treasure Jazz”, „John Coltrane”, „Impressions Graz”, „Graz”, „Coltrane”
În ciuda unor dublări ale anumitor cuvinte în unele fraze cheie, această metodă pare destul de interesantă.
Abordarea grafică
Acest tip de abordare nu este prea departe de abordarea statistică în sensul că vom calcula și co-ocurențe de cuvinte. Sufixul Rank asociat cu unele nume de metode, cum ar fi TextRank , se bazează pe principiul algorului PageRank pentru a calcula popularitatea fiecărei pagini pe baza linkurilor sale de intrare și de ieșire.
[Ebook] Automatizarea SEO cu Oncrawl
 Citiți cartea electronică
Citiți cartea electronicăTextRank
Acest algoritm provine din lucrarea TextRank: Bringing Order into Texts din 2004 și se bazează pe aceleași principii ca și algoritmul PageRank . Cu toate acestea, în loc să construim un grafic cu pagini și link-uri, vom construi un grafic cu cuvinte. Fiecare cuvânt va fi legat de alte cuvinte în funcție de co-apariția lor.
Există mai multe implementări în Python. În acest articol, voi prezenta pytextrank. Vom depăși una dintre constrângerile noastre legate de etichetarea POS. Într-adevăr, atunci când construim graficul, nu vom include toate cuvintele ca noduri. Vor fi luate în considerare doar verbele și substantivele. La fel ca metodele anterioare care folosesc cuvinte oprite pentru a filtra candidații irelevanți, algo-ul TextRank folosește tipul gramatical de cuvinte.
Iată un exemplu de parte a graficului care va fi construită de algo: 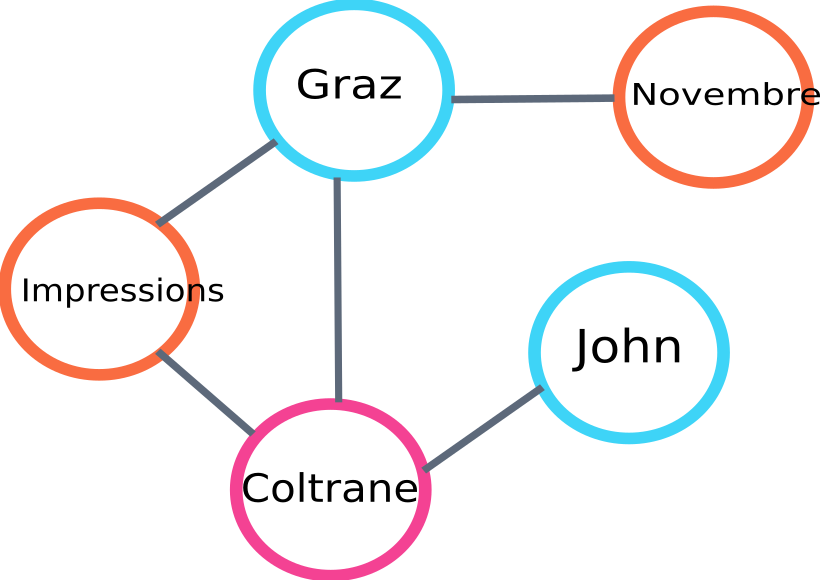
exemplu de grafic de rang de text
Iată un exemplu de utilizare în Python. Rețineți că această implementare folosește mecanismul pipeline al bibliotecii spaCy. Această bibliotecă este capabilă să facă etichetare POS.
# python snippet pentru pytextrank
import spacy
import pytextrank
# încărcați un model francez
nlp = spacy.load("fr_core_news_sm")
# adăugați pytextrank la conductă
nlp.add_pipe("textrank")
doc = nlp(text)
textrank_keyphrases = doc._.phrases
Iată primele 5 rezultate:
„Copenhaga”, „noiembrie”, „Impressions Graz”, „Graz”, „John Coltrane”
Pe lângă extragerea frazelor cheie, TextRank extrage și propoziții. Acest lucru poate fi foarte util pentru realizarea așa-numitelor „rezumate extractive” – acest aspect nu va fi tratat în acest articol.
Concluzii
Dintre cele trei metode testate aici, ultimele două ni se par a fi destul de relevante pentru subiectul textului. Pentru a compara mai bine aceste abordări, ar trebui evident să evaluăm aceste modele diferite pe un număr mai mare de exemple. Există într-adevăr valori pentru a măsura relevanța acestor modele de extragere a cuvintelor cheie.
Listele de cuvinte cheie produse de aceste așa-numite modele tradiționale oferă o bază excelentă pentru a verifica dacă paginile dvs. sunt bine vizate. În plus, ele oferă o primă aproximare a modului în care un motor de căutare ar putea înțelege și clasifica conținutul.
Pe de altă parte, alte metode care utilizează modele NLP pre-antrenate, cum ar fi BERT, pot fi, de asemenea, utilizate pentru a extrage concepte dintr-un document. Spre deosebire de așa-numita abordare clasică, aceste metode permit de obicei o mai bună captare a semanticii.
Diferitele metode de evaluare, înglobări contextuale și transformatoare vor fi prezentate într-un al doilea articol care urmează să vină pe subiect!
Iată lista de cuvinte cheie extrase din acest articol cu una dintre cele trei metode menționate:
„metode”, „cuvinte cheie”, „expresii cheie”, „text”, „cuvinte cheie extrase”, „Procesarea limbajului natural”
Referințe bibliografice
- [1] Extragerea automată a cuvintelor cheie îmbunătățită, având în vedere mai multe cunoștințe lingvistice, Anette Hulth, 2003
- [2] Extragerea automată a cuvintelor cheie din documente individuale, Stuart Rose et. al, 2010
- [3] JAKE! Extragerea cuvintelor cheie din documente individuale folosind mai multe caracteristici locale, Ricardo Campos et. al, 2020
- [4] TextRank: Bringing Order into Texts, Rada Mihalcea et. al, 2004
Începeți perioada de încercare gratuită de 14 zile
 Începeți procesul
Începeți procesul