
Cum să răspunzi la întrebări complexe de date cu datele Oncrawl, în afara Oncrawl
Publicat: 2022-01-04Unul dintre avantajele Oncrawl pentru SEO pentru întreprinderi este acela de a avea acces deplin la datele dumneavoastră brute. Indiferent dacă vă conectați datele SEO la un flux de lucru BI sau știința datelor, efectuați propriile analize sau lucrați în conformitate cu liniile directoare de securitate a datelor pentru organizația dvs., datele brute SEO și auditul site-ului web pot servi în multe scopuri.
Astăzi vom analiza cum să folosiți datele Oncrawl pentru a răspunde la întrebări complexe despre date.
Ce este o întrebare complexă de date?
Întrebările complexe de date sunt întrebări la care nu se poate răspunde printr-o simplă căutare a bazei de date, dar necesită prelucrare a datelor pentru a obține răspunsul.
Iată câteva exemple comune de întrebări „complexe” de date pe care le au adesea SEO:
- Crearea unei liste cu toate linkurile care trimit către pagini care redirecționează către alte pagini cu starea 404
- Crearea unei liste a tuturor link-urilor și a textului lor de ancorare care indică paginile dintr-o segmentare bazată pe valori non-URL
Cum să răspunzi la întrebări complexe de date în Oncrawl
Structura de date a Oncrawl este construită pentru a permite aproape tuturor site-urilor să caute date aproape în timp real. Aceasta implică stocarea diferitelor tipuri de date în diferite seturi de date pentru a se asigura că timpul de căutare este menținut la minimum în interfață. De exemplu, stocăm toate datele asociate cu adresele URL într-un singur set de date: codul de răspuns, numărul de link-uri de ieșire, tipul de date structurate prezente, numărul de cuvinte, numărul de vizite organice... Și stocăm toate datele legate de link-uri într-un set de date separat: țintă link, origine link, text ancora…
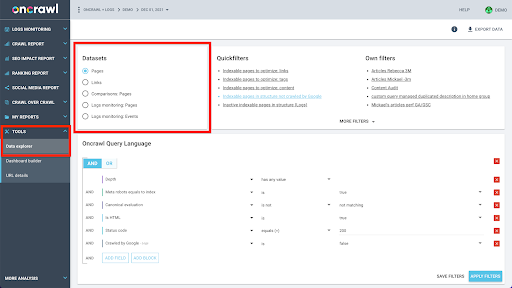
Alăturarea acestor seturi de date este complexă din punct de vedere computațional și nu este întotdeauna acceptată în interfața aplicației Oncrawl. Când sunteți interesat să căutați ceva care necesită filtrarea unui set de date pentru a căuta ceva în altul, vă recomandăm să manipulați datele brute pe cont propriu.
Deoarece toate datele Oncrawl sunt disponibile pentru dvs., există multe modalități de a vă alătura seturi de date și de a exprima interogări complexe.
În acest articol, ne vom uita la unul dintre ele, folosind Google Cloud și BigQuery, care este potrivit pentru seturi de date foarte mari, pe care le întâlnesc mulți dintre clienții noștri atunci când examinează datele pentru site-uri cu volume mari de pagini.
Ce vei avea nevoie
Pentru a urma metoda pe care o vom discuta în acest articol, veți avea nevoie de acces la următoarele instrumente:
- Oncrawl
- API-ul Oncrawl cu Big Data Export
- Google Cloud Storage
- BigQuery
- Un script Python pentru a transfera date de la Oncrawl la BigQuery (Vom construi acest lucru în timpul articolului.)
Înainte de a începe, va trebui să aveți acces la un raport de accesare cu crawlere finalizat în Oncrawl.
Cum să folosiți datele Oncrawl în Google BigQuery
Planul articolului de astăzi este următorul:
- În primul rând, ne vom asigura că Google Cloud Storage este configurat pentru a primi date de la Oncrawl.
- În continuare, vom folosi un script Python pentru a rula exporturile de date mari ale Oncrawl pentru a exporta datele dintr-un anumit acces cu crawlere într-un compartiment Google Cloud Storage. Vom exporta două seturi de date: pagini și link-uri.
- Când se face acest lucru, vom crea un set de date în Google BigQuery. Vom crea apoi un tabel din fiecare dintre cele două exporturi din setul de date BigQuery.
- În cele din urmă, vom experimenta cu interogarea seturilor de date individuale și apoi a ambelor seturi de date împreună pentru a găsi răspunsul la o întrebare complexă.
Configurarea în Google Cloud pentru a primi date Oncrawl
Pentru a rula acest ghid într-un mediu sandbox dedicat, vă recomandăm să creați un nou proiect Google Cloud pentru a-l izola de proiectele dvs. existente în desfășurare.
Să începem cu Google Cloud.
De pe pagina dvs. de pornire Google Cloud, aveți acces la multe lucruri în plus față de Cloud Storage. Suntem interesați de compartimentele de stocare în cloud, care sunt disponibile în nivelul de stocare în cloud al Google Cloud Platform: 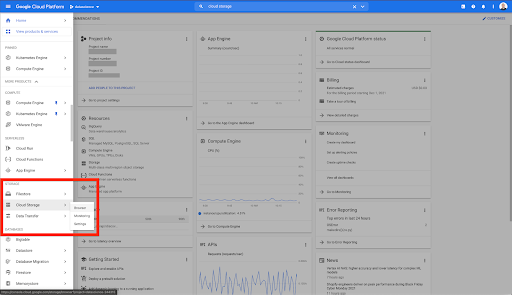
De asemenea, puteți accesa browserul Cloud Storage direct la https://console.cloud.google.com/storage/browser.
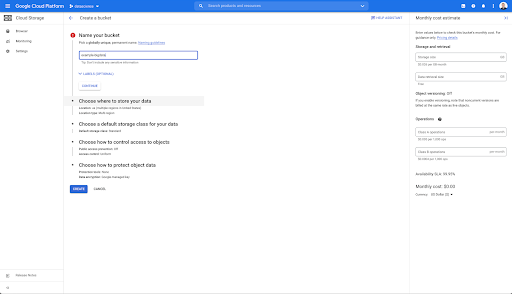
Apoi, trebuie să creați un compartiment de stocare în cloud și să acordați permisiunile corecte, astfel încât Contul de serviciu al Oncrawl să aibă permisiunea de a scrie în el, sub prefixul ales de dvs.
Bucheta Google Cloud Storage va servi ca stocare temporară pentru a păstra exporturile de date mari de la Oncrawl înainte de a le încărca în Google BigQuery.
În această găleată, am creat și două foldere: „link-uri” și „pagini”: 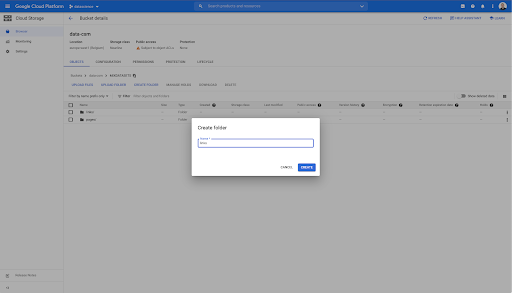
Exportarea seturilor de date din Oncrawl
Acum că am configurat spațiul în care dorim să salvăm datele, trebuie să le exportăm din Oncrawl. Exportul într-un compartiment Google Cloud Storage cu Oncrawl este deosebit de ușor, deoarece putem exporta date în formatul potrivit și le putem salva direct în compartiment. Acest lucru elimină orice pași suplimentari.
Crearea unei chei API
Exportarea datelor din Oncrawl în formatul Parquet pentru BigQuery va necesita utilizarea unei chei API pentru a acționa programatic asupra API, în numele proprietarului contului Oncrawl. Aplicația Oncrawl permite utilizatorilor să creeze chei API numite, astfel încât contul dvs. să fie întotdeauna bine organizat și curat. Cheile API sunt, de asemenea, asociate cu diferite permisiuni (sfere), astfel încât să puteți gestiona cheile și scopurile acestora.
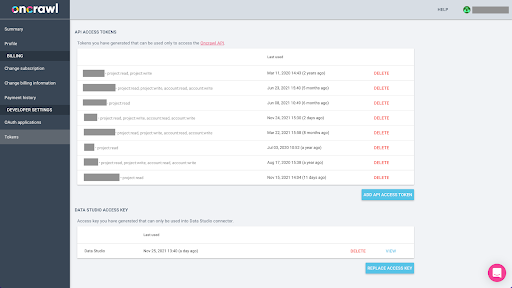
Să denumim noua noastră cheie „Cheia sesiunii de cunoștințe”. Funcția de export Big Data necesită permisiuni de scriere în cont, deoarece noi creăm exporturile de date. Pentru a realiza acest lucru, trebuie să avem acces de citire pe proiect și acces de citire și scriere pe cont.
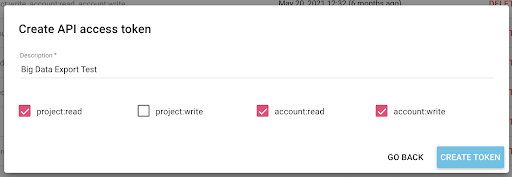
Acum avem o nouă cheie API, pe care o voi copia în clipboard.
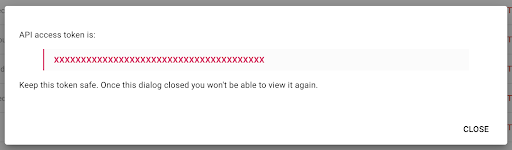
Rețineți că, din motive de securitate, aveți posibilitatea de a copia cheia o singură dată . Dacă uitați să copiați cheia, va trebui să ștergeți cheia și să creați una nouă.
Crearea scriptului dvs. Python
Am construit un blocnotes Google Colab pentru asta, dar voi împărtăși codul de mai jos, astfel încât să vă puteți crea propriile instrumente sau propriul blocnotes.
1. Stocați cheia API într-o variabilă globală
Mai întâi, pornim mediul și declarăm cheia API într-o variabilă globală numită „Oncrawl Token”. Apoi, ne pregătim pentru restul experimentului:
#@title Accesați API-ul Oncrawl
#@markdown Furnizați indicativul API de mai jos pentru a permite acestui blocnotes să vă acceseze datele Oncrawl:
# TOKENUL DVS. PENTRU API-UL ONCrawL
ONCRAWL_TOKEN = "" #@param {tip:"șir"}
!pip instalează închisoare
din IPython.display import clear_output
clear_output()
print('Toate încărcate.') 
2. Creați o listă derulantă pentru a alege proiectul Oncrawl cu care doriți să lucrați
Apoi, folosind acea cheie, dorim să putem alege proiectul cu care vrem să ne jucăm, obținând lista proiectelor și creând un widget drop-down din acea listă. Prin rularea celui de-al doilea bloc de cod, efectuați următorii pași:
- Vom apela API-ul Oncrawl pentru a obține lista proiectelor din cont folosind cheia API care tocmai a fost trimisă.
- Odată ce avem lista proiectului din răspunsul API, o formatăm ca o listă folosind numele proiectului, precum și URL-ul de pornire al proiectului.
- Stocăm ID-ul proiectului care a fost furnizat în răspuns.
- Construim un meniu derulant și îl arătăm sub blocul de cod.
#@title Selectați site-ul web de analizat alegând proiectul Oncrawl corespunzător
cereri de import
închisoare de import
importa ipywidgets ca widget-uri
import json
# Obțineți lista de proiecte
răspuns = requests.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
limita=1000,
sort='nume:asc'
),
headers={ 'Autorizare': 'Purtător '+ONCRAWL_TOKEN }
)
json_res = response.json()
meniu drop-down #prepare pentru a permite utilizatorului să selecteze un proiect
proiecte = []
pentru element în json_res['proiecte']:
projects.append(('{} - {}'.format(element['nume'], element['start_url']), item['id']))
output = widgets.Output()
dropdown_purpose = widgets.Dropdown(opțiuni = proiecte, description="Proiect: ")
def dropdown_project_eventhandler(modificare):
output.clear_output()
cu iesire:
afișare (proiecte)
dropdown_purpose.observe(dropdown_project_eventhandler, names='valoare')
afișare (dropdown_purpose) Din meniul derulant pe care îl creează, puteți vedea lista completă a proiectului la care are acces cheia API. 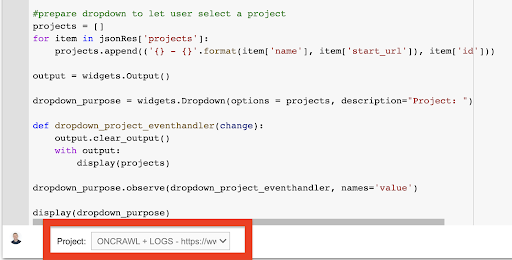
În scopul demonstrației de astăzi, folosim un proiect demonstrativ bazat pe site-ul web Oncrawl.
3. Creați o listă derulantă pentru a alege profilul de accesare cu crawlere din cadrul proiectului cu care doriți să lucrați
În continuare, vom decide ce profil de accesare cu crawlere să folosim. Dorim să alegem un profil de accesare cu crawlere în cadrul acestui proiect. Proiectul demonstrativ are o mulțime de configurații diferite de accesare cu crawlere: 
În acest caz, ne uităm la un proiect pe care echipele Oncrawl îl folosesc adesea pentru experimente, așa că voi alege profilul de accesare cu crawlere folosit de echipa de marketing pentru a monitoriza performanța site-ului Oncrawl. Deoarece acesta ar trebui să fie cel mai stabil profil de accesare cu crawlere, este o alegere bună pentru experimentul de astăzi.
Pentru a obține profilul de accesare cu crawlere, vom folosi API-ul Oncrawl, pentru a solicita ultima accesare cu crawlere din fiecare profil de accesare cu crawlere din proiect:
- Ne pregătim să interogăm API-ul Oncrawl pentru proiectul dat.
- Vom cere toate accesările cu crawlere returnate în ordine descrescătoare în funcție de data „creat la”.
cereri de import
import json
importa ipywidgets ca widget-uri
project_id = dropdown_purpose.value
# Obțineți detalii despre proiecte (includeți toate accesările cu crawlere din proiect)
proiect = requests.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ „Autorizare”: „Purtător „+ONCRAWL_TOKEN }).json()
# Grupați accesările cu crawlere în funcție de profilul de accesare cu crawlere (numele accesării cu crawlere)
crawls_by_config = {}
încerca:
pentru crawl în project['crawls']:
dacă crawl['status'] în [„terminat”]:
dacă crawl['crawl_config']['name'] nu este în crawls_by_config.keys():
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids': [], 'is_crawl_archived': False}
dacă len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
if crawl['status'] == „arhivat”:
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = Adevărat
cu excepția excepției ca e:
ridică excepție ("eroare {} , {}".format(e, proiect))
# Construiți lista pentru selectarea drop-down
list = [("{} ({})).format(k, len(v['crawl_ids'])), k) pentru k, v în crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list, description="Crawl configs: ")
def dropdown_cc_eventhandler(modificare):
output.clear_output()
cu iesire:
afișare(crawls_by_config)
dacă len(crawls_by_config.values()) == 0:
print('Nu s-a găsit niciun acces cu crawlere live în acest proiect')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='value')
afișare(dropdown_crawl_configs)Când acest cod este rulat, API-ul Oncrawl ne va răspunde cu lista de accesări cu crawlere prin proprietatea descendentă „creat la”.
Apoi, din moment ce vrem să ne concentrăm doar pe crawlerile care s-au terminat, vom parcurge lista cu crawleri. Pentru fiecare accesare cu crawlere cu starea „terminat”, vom salva numele profilului de accesare cu crawlere și vom stoca ID-ul accesării cu crawlere.
Vom păstra cel mult un acces cu crawlere după profil, astfel încât să nu dorim să expunem prea multe accesări cu crawlere.
Rezultatul este acest nou meniu derulant creat din lista de profiluri de accesare cu crawlere din proiect. O vom alege pe cea pe care o dorim. Aceasta va dura ultima accesare cu crawlere efectuată de echipa de marketing: 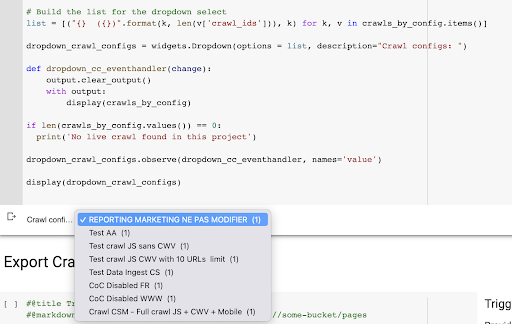
4. Identificați ultimul acces cu crawlere cu profilul pe care vrem să-l folosim
Avem deja ID-ul de accesare cu crawlere asociat cu ultima accesare cu crawlere din profilul ales. Este ascuns în dicționarul de obiecte „crawl_by_config”. 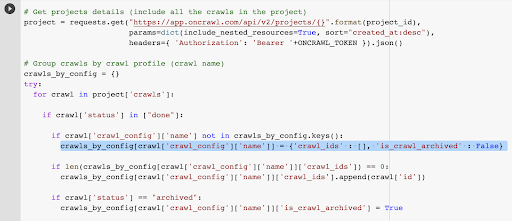
Puteți verifica acest lucru cu ușurință în interfață: Găsiți ultima accesare cu crawlere finalizată în această analiză a profilului. 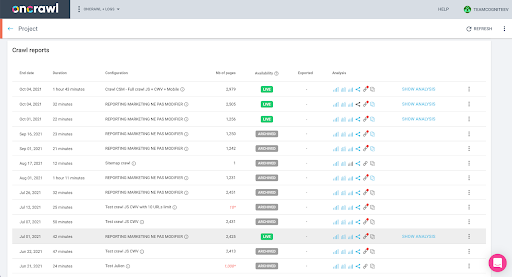
Dacă facem clic pentru a vizualiza analiza, vom vedea că ID-ul de accesare cu crawlere se termină cu E617. 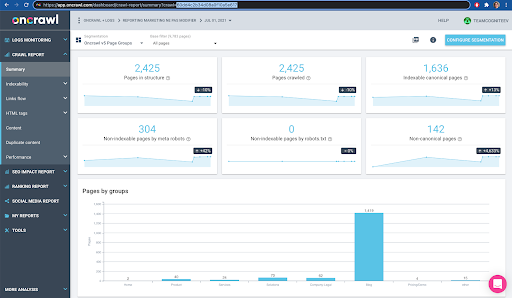
Să luăm doar notă de ID-ul de accesare cu crawlere în scopul demonstrației de astăzi.
Desigur, dacă știți deja ce faceți, puteți sări peste pașii pe care tocmai i-am parcurs pentru a apela API-ul Oncrawl pentru a obține lista de proiecte și lista de accesări cu crawlere după profilul de crawlere: aveți deja ID-ul de accesare cu crawlere din interfață, iar acest ID este tot ce aveți nevoie pentru a rula exportul.
Pașii pe care i-am parcurs până acum sunt pur și simplu pentru a ușura procesul de obținere a ultimei accesări cu crawlere a profilului de accesare cu crawlere dat al proiectului dat, având în vedere la ce are acces cheia API. Acest lucru poate fi util dacă oferiți această soluție altor utilizatori sau dacă doriți să o automatizați.
5. Exportați rezultatele accesării cu crawlere
Acum, ne vom uita la comanda de export:
#@title Declanșează exportul de date mari
#@markdown Furnizați secțiunea dvs. GCS și prefixul gs://some-bucket/pages
# GALEȚA DVS. GCS
gcs_bucket = #@param {type:"șir"}
gcs_prefix = #@param {type:"șir"}
# Obțineți ultimul ID de accesare cu crawlere de la proiectul/profilul de accesare cu crawlere dat
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Sarcină utilă a șablonului pentru interogarea exportului de date
sarcina utila = {
"data_export": {
„data_type”: „pagină”,
„resource_id”: last_crawl_id,
„output_format”: „parchet”,
„țintă”: „gcs”,
„target_parameters”: {
„gcs_bucket”: gcs_bucket,
„gcs_prefix”: gcs_prefix
}
}
}
# Declanșează exportul
export = requests.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
# Afișează răspunsul API
afișare (exportare)
# Stocați ID-ul de export pentru utilizare ulterioară
export_id = export['data_export']['id']Dorim să exportăm în compartimentul Cloud Storage pe care l-am configurat mai devreme.
În acest sens, vom exporta paginile pentru ultimul ID de accesare cu crawlere:
- Ultimul ID de accesare cu crawlere este obținut din lista de ID-uri de accesare cu crawlere, care este stocată undeva în dicționarul „crawls_by_config”, care a fost creat la pasul 3.
- Dorim să-l alegem pe cel corespunzător meniului drop-down la pasul 4, așa că folosim atributul value al meniului drop-down.
- Apoi, extragem atributul crawl_ID. Aceasta este o listă. Vom păstra primele 50 de articole din listă. Trebuie să facem acest lucru deoarece la pasul 2, după cum vă veți aminti, când am creat dicționarul crawls_by_config, am stocat doar un ID de accesare cu crawlere pentru fiecare nume de configurație.
Am configurat câmpuri de introducere pentru a facilita furnizarea compartimentului Google Cloud Storage și a prefixului, sau a folderului, unde vrem să trimitem exportul. 
În scopul demonstrației, astăzi, vom scrie în folderul „mixed dataset”, într-unul dintre folderele pe care le-am configurat deja. Când ne-am configurat găleata în Google Cloud Storage, vă veți aminti că am pregătit dosare pentru exportul „link-urilor” și pentru exportul „paginilor”.
Pentru primul export, vom dori să exportăm paginile în folderul „pagini” pentru ultimul ID de accesare cu crawlere utilizând formatul de fișier Parquet. 
În rezultatele de mai jos, veți vedea sarcina utilă care urmează să fie trimisă la punctul final de export de date, care este punctul final pentru a solicita un export de Big Data folosind o cheie API:
# Sarcină utilă a șablonului pentru interogarea exportului de date
sarcina utila = {
"data_export": {
„data_type”: „pagină”,
„resource_id”: last_crawl_id,
„output_format”: „parchet”,
„țintă”: „gcs”,
„target_parameters”: {
„gcs_bucket”: gcs_bucket,
„gcs_prefix”: gcs_prefix
}
}
}
Acesta conține mai multe elemente, inclusiv tipul setului de date pe care doriți să-l exportați. Puteți exporta setul de date de pagină, setul de date link, setul de date cluster sau setul de date structurate. Dacă nu știți ce se poate face, puteți introduce o eroare aici, iar când apelați API-ul veți primi un mesaj care spune că alegerea pentru tipul de date trebuie să fie fie pagină, fie link, fie cluster sau date structurate. Mesajul arata asa:

{'fields': [{'message': 'Nu este o alegere validă. Trebuie să fie unul dintre „pagină”, „link”, „cluster”, „date_structurate”.',
„nume”: „tip_date”,
„tip”: „alegere_invalidă”}],
„type”: „invalid_request_parameters”}
În scopul experimentului de astăzi, vom exporta setul de date de pagină și setul de date de link în exporturi separate.
Să începem cu setul de date de pagină. Când rulez acest bloc de cod, am tipărit rezultatul apelului API, care arată astfel:
{'data_export': {'data_type': 'pagina',
„export_failure_reason”: niciunul,
„id”: „XXXXXXXXXXXXXXX”,
'output_format': 'parchet',
„output_format_parameters”: niciunul,
'output_row_count': niciunul,
'dimensiunea_ieșirii_în_octeți: 1634460016000,
„resource_id”: „60dd4c2b34d08a0f10a5e617”,
„stare”: „SOLICIT”,
„țintă”: „gcs”,
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pages/'}}}
Acest lucru îmi permite să văd că exportul a fost solicitat.
Dacă vrem să verificăm starea exportului, este foarte simplu. Folosind ID-ul de export pe care l-am salvat la sfârșitul acestui bloc de cod, putem solicita oricând starea exportului cu următorul apel API:
# STAREA EXPORTULUI
export_status = requests.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json ()
afișare(stare_export)
Aceasta va indica o stare ca parte a obiectului JSON returnat:
{'data_export': {'data_type': 'pagina',
„export_failure_reason”: niciunul,
„id”: „XXXXXXXXXXXXXXX”,
'output_format': 'parchet',
„output_format_parameters”: niciunul,
'output_row_count': niciunul,
'output_size_in_bytes': niciunul,
„requested_at”: 1638350549000,
„resource_id”: „60dd4c2b34d08a0f10a5e617”,
„stare”: „EXPORTARE”,
„țintă”: „gcs”,
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/pages/'}}} Când exportul este finalizat ( 'status': 'DONE' ), putem reveni la Google Cloud Storage.
Dacă ne uităm în găleată și intrăm în folderul „linkuri”, nu există încă nimic aici pentru că am exportat paginile. 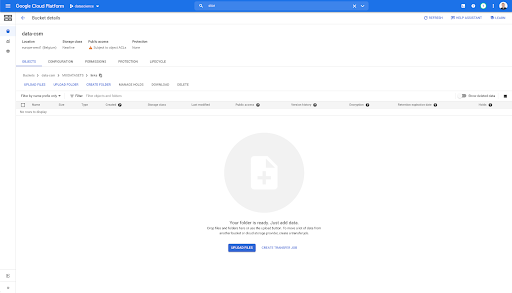
Cu toate acestea, când ne uităm în folderul „pagini”, putem vedea că exportul a reușit. Avem un dosar Parquet: 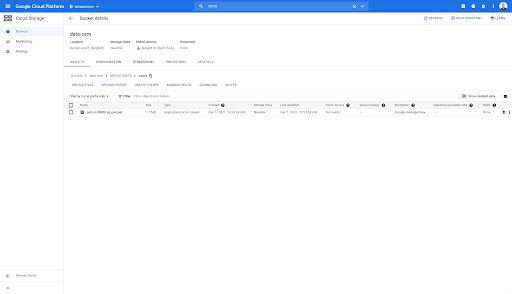
În această etapă, setul de date de pagini este gata pentru import în BigQuery, dar mai întâi vom repeta pașii de mai sus pentru a obține fișierul Parquet pentru link-uri:
- Asigurați-vă că setați prefixul de linkuri.
- Alegeți tipul de date „link”.
- Rulați din nou acest bloc de cod pentru a solicita al doilea export.

Acest lucru va produce un fișier Parquet în folderul „link-uri”.
Crearea seturi de date BigQuery
În timp ce exportul se execută, putem avansa și începe să creăm seturi de date în BigQuery și să importam fișierele Parquet în tabele separate. Apoi vom uni mesele împreună.
Ceea ce vrem să facem acum este să ne jucăm cu Google Big Query, care este ceva disponibil ca parte a platformei Google Cloud. Puteți utiliza bara de căutare din partea de sus a ecranului sau puteți accesa direct https://console.cloud.google.com/bigquery.
Crearea unui set de date pentru munca dvs
Va trebui să creăm un set de date în Google BigQuery: 
Va trebui să furnizați setului de date un nume și să alegeți locația în care vor fi stocate datele. Acest lucru este important deoarece va condiționa locul în care sunt prelucrate datele și nu poate fi schimbat. Acest lucru poate avea un impact dacă datele dvs. includ informații care sunt acoperite de GDPR sau de alte legi privind confidențialitatea. 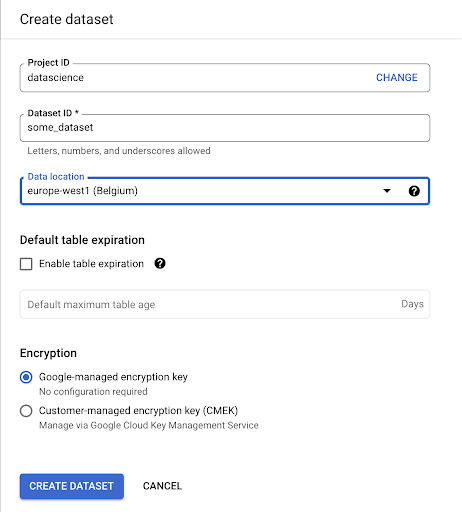
Acest set de date este inițial gol. Când îl deschideți, veți putea crea un tabel, partajați setul de date, copiați, ștergeți și așa mai departe.
Crearea de tabele pentru datele dvs
Vom crea un tabel în acest set de date. 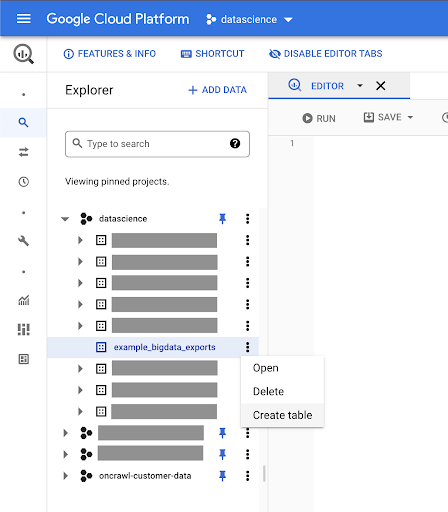
Puteți fie să creați un tabel gol și apoi să furnizați schema. Schema este definiția coloanelor din tabel. Puteți fie să vă definiți propria, fie să răsfoiți Google Cloud Storage pentru a alege o schemă dintr-un fișier.
Vom folosi această ultimă opțiune. Vom naviga la găleata noastră, apoi la folderul „pagini”. Să alegem fișierul pagini. Există un singur fișier, așa că putem selecta doar unul, dar dacă exportul ar fi generat mai multe fișiere, le-am fi putut alege pe toate. 
Când selectăm fișierul, acesta detectează automat că este în format de fișier Parquet. Dorim să creăm un tabel numit „pagini”, iar schema va fi definită de fișierul sursă. 
Când încărcăm un fișier Parquet, acesta încorporează o schemă. Cu alte cuvinte, definiția coloanelor tabelului pe care îl creăm va fi dedusă din schema care există deja în fișierul Parquet. Aici se întâmplă de fapt o parte din magie.
Să mergem înainte și să creăm pur și simplu tabelul din fișierul Parquet. 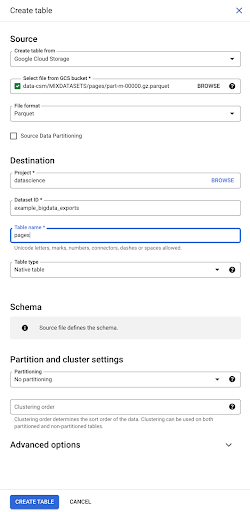
În bara laterală din stânga, putem vedea acum că în setul nostru de date a apărut un tabel, care este exact ceea ce ne dorim:
Deci, acum avem schema tabelului de pagini cu toate câmpurile care au fost deduse automat din fișierul Parquet. Avem Inrank, adâncimea paginii, dacă pagina este o redirecționare și așa mai departe și așa mai departe: 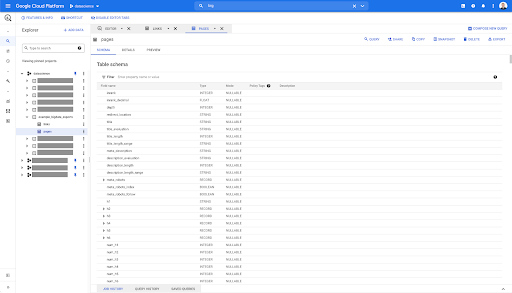
Cele mai multe dintre aceste câmpuri sunt aceleași cu cele puse la dispoziție în Data Studio prin conectorul Oncrawl Data Studio și aceleași cu cele pe care le vedeți în Data Explorer în interfața Oncrawl. 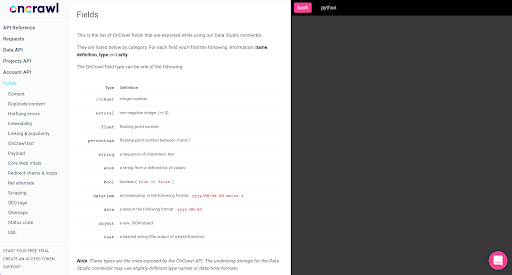
Cu toate acestea, există unele diferențe. Când ne jucăm cu exportul brut de date mari, aveți toate datele brute.
- În Data Studio, unele câmpuri sunt redenumite, altele sunt ascunse și unele câmpuri sunt adăugate, cum ar fi starea.
- În Data Explorer, unele câmpuri sunt ceea ce numim „câmpuri virtuale”, ceea ce înseamnă că pot fi un fel de comandă rapidă către un câmp de bază. Aceste câmpuri virtuale disponibile în Data Explorer nu vor fi listate în schemă, dar pot fi recreate pe baza a ceea ce este disponibil în fișierul Parquet.
Să închidem acum acest tabel și să o facem din nou pentru legături.
Pentru tabelul de linkuri, schema este puțin mai mică. 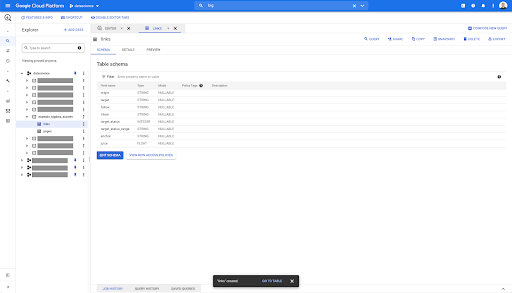
Acesta conține doar următoarele câmpuri:
- Originea link-ului,
- Ținta linkului,
- Următoarea proprietate,
- Proprietatea internă,
- Starea țintă,
- Intervalul stării țintă,
- Textul ancoră și
- Sucul sau capitalul propriu cumpărat prin link.
Pe orice tabel din BigQuery, când dați clic pe fila de previzualizare, aveți o previzualizare a tabelului fără a interoga baza de date: 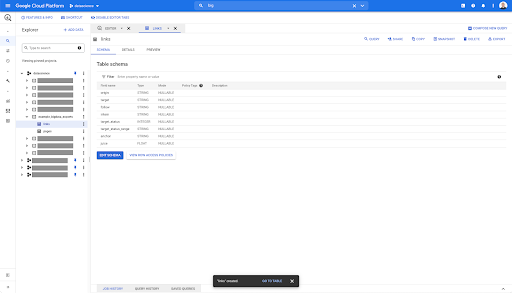
Acest lucru vă oferă o vedere rapidă a ceea ce este disponibil în el. În previzualizarea pentru tabelul de linkuri de mai sus, aveți o previzualizare a fiecărui rând și a tuturor coloanelor.
În unele seturi de date Oncrawl, este posibil să vedeți câteva rânduri care se întind pe mai multe rânduri. Nu am un exemplu pentru tine, dar dacă acesta este cazul, este pentru că unele câmpuri conțin o listă de valori. De exemplu, în lista de titluri h2 dintr-o pagină, un singur rând va cuprinde mai multe rânduri în Big Query. Ne vom uita la asta mai târziu dacă vedem un exemplu.
Crearea interogării dvs
Dacă nu ați creat niciodată o interogare în BigQuery, acum este momentul să vă jucați cu ea pentru a vă familiariza cu modul în care funcționează. BigQuery folosește SQL pentru a căuta date.
Cum funcționează interogările
De exemplu, să ne uităm la toate adresele URL și la rangul lor...
SELECTAȚI adresa URL, inrank...
din setul de date pagini...
SELECTAȚI adresa URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages`...
unde codul de stare al paginii este 200...
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ...
și păstrează doar primele 10 rezultate:
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
Când rulăm această interogare, vom obține primele 10 rânduri ale listei de pagini în care codul de stare este 200.
Oricare dintre aceste proprietăți poate fi modificată. Dacă vreau 1000 de rânduri în loc de 10, pot seta 1000 de rânduri:
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
Dacă vreau să sortez, pot face asta cu „order-by”: acest lucru îmi va oferi toate rândurile ordonate în ordinea descendentă a Inrank.
SELECTAȚI adresa URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
Aceasta este prima mea întrebare. O pot salva dacă vreau, ceea ce îmi va oferi posibilitatea de a reutiliza această interogare mai târziu dacă vreau: 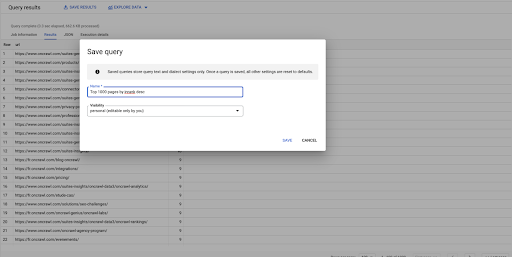
Utilizarea interogărilor pentru a răspunde la întrebări simple: Listarea tuturor linkurilor interne către pagini cu starea 301
Acum că știm cum să compunem o interogare, să ne întoarcem la problema noastră inițială.
Am vrut să răspundem la întrebările de date, fie ele simple sau complexe. Să începem cu o întrebare simplă, cum ar fi „care sunt toate linkurile interne care indică paginile cu starea 301 (redirecționată) și unde le pot găsi?”
Crearea unei noi interogări
Vom începe prin a explora modul în care funcționează.
O să vreau coloane pentru următoarele elemente din baza de date „linkuri”:
- Origine
- Ţintă
- Codul de stare țintă
SELECTAȚI origine, țintă, stare_țintă FROM `datascience-oncrawl.example_bigdata_exports.links`
Vreau să le limitez doar la link-uri interne, dar să ne imaginăm că nu-mi amintesc numele coloanei sau valoarea care indică dacă linkul este intern sau extern. Pot merge la schema pentru a o căuta și pot folosi previzualizarea pentru a vedea valoarea: 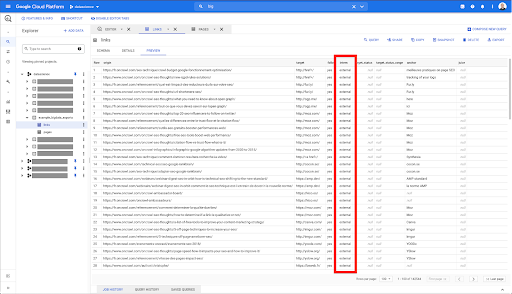
Acest lucru îmi spune că coloana este numită „intern”, iar intervalul posibil de valori este „extern” sau „intern”.
În interogarea mea, vreau să specific „unde este intern intern” și să limitez rezultatele la primele 100 pentru moment:
SELECTAȚI origine, țintă, stare_țintă FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'intern' LIMIT 100
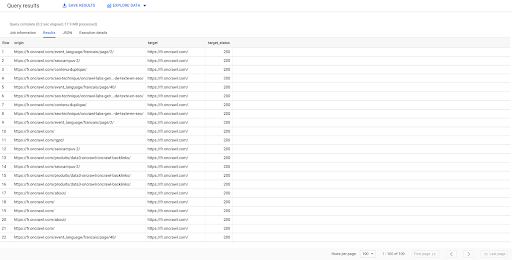
Rezultatul de mai sus arată lista de link-uri cu starea lor țintă. Avem doar link-uri interne și avem 100 dintre ele, așa cum este specificat în interogare.
Dacă vrem să avem doar linkuri interne către paginile redirecționate, am putea spune „unde intern, cum ar fi starea internă și țintă, este egală cu 301”:
SELECTAȚI origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' AND target_status = 301
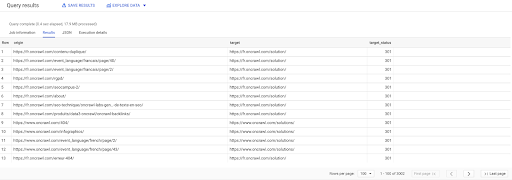
Dacă nu știm câte dintre ele există, putem rula această nouă interogare și vom vedea că există 3002 link-uri interne cu o stare țintă de 301.
Alăturarea tabelelor: găsirea codurilor de stare finale ale linkurilor care indică paginile redirecționate
Pe un site web, aveți adesea link-uri către pagini care sunt redirecționate. Dorim să știm codul de stare al paginii către care sunt redirecționați (sau adresa URL țintă finală).
Într-un set de date, aveți informațiile despre linkuri: pagina de origine, pagina țintă și codul său de stare (cum ar fi 301), dar nu adresa URL la care indică o pagină redirecționată. Și în celălalt, aveți informațiile despre redirecționări și țintele lor finale, dar nu pagina originală unde a fost găsit linkul către acestea.
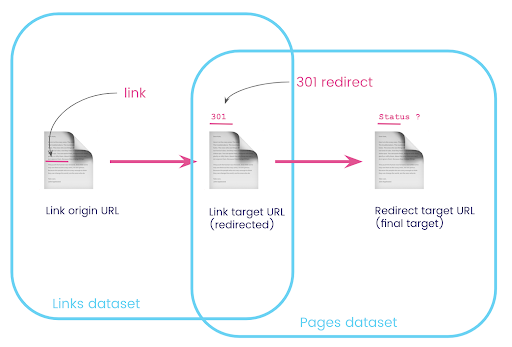
Să descompunem asta:
În primul rând, vrem link-uri către redirecționări. Să scriem asta. Noi vrem:
- Originea.
- Ținta. Ținta trebuie să aibă un cod de stare 301.
- Ținta finală a redirecționării.
Cu alte cuvinte, în setul de date linkuri, dorim:
- Originea legăturii
- Ținta linkului
În setul de date de pagini, dorim:
- Toate țintele care sunt redirecționate
- Ținta finală a redirecționării
Acest lucru ne va oferi o interogare de genul:
SELECTAȚI url, final_redirect_location, final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` AS pagini WHERE status_code = 301 SAU status_code = 302
Asta ar trebui să-mi dea prima parte a ecuației.
Acum am nevoie de toate linkurile care leagă la pagină care sunt rezultatele interogării pe care tocmai am creat-o, folosind aliasuri pentru seturile mele de date și unindu-le pe adresa URL țintă a linkului și adresa URL a paginii. Aceasta corespunde zonei de suprapunere a celor două seturi de date din diagrama de la începutul acestei secțiuni.
SELECTAȚI links.origin, pages.url, pages.final_redirect_location, pagini.starea_finală_redirecționării DIN Pagini AS `datascience-oncrawl.example_bigdata_exports.pages` A TE ALATURA Legături AS `datascience-oncrawl.example_bigdata_exports.links` PE links.target = pages.url UNDE pages.status_code = 301 SAU pages.status_code = 302 COMANDA PENTRU origine ASC
În rezultatele Interogării, pot redenumi coloanele pentru a clarifica lucrurile, dar văd deja că am un link de la o pagină din prima coloană, care merge la pagina din a doua coloană, care este la rândul său redirecționată către pagina din a treia coloană. În a patra coloană, am codul de stare al țintei finale: 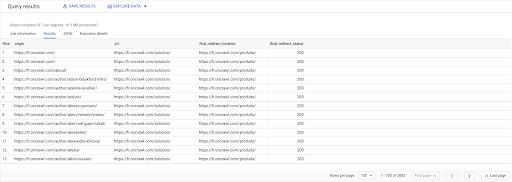
Acum pot spune ce linkuri indică pagini redirecționate care nu se rezolvă la 200 de pagini. Poate că sunt 404, de exemplu, ceea ce îmi oferă o listă prioritară de link-uri de corectat.
Am văzut mai devreme cum să salvăm o interogare. De asemenea, putem salva rezultatele, pentru până la 16000 de linii de rezultate: 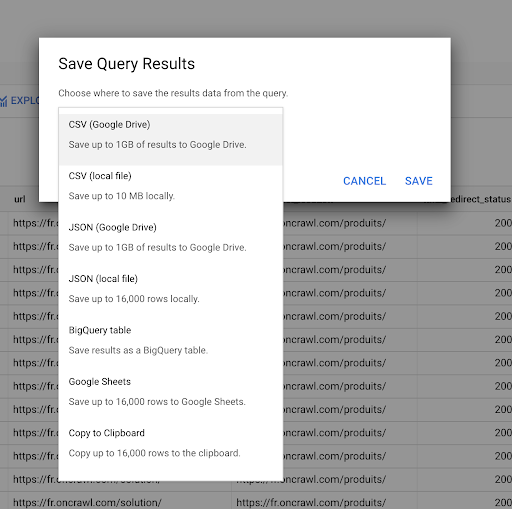
Apoi putem folosi aceste rezultate în multe moduri diferite. Iată câteva exemple:
- Putem salva acest lucru local ca fișier CSV sau JSON.
- Îl putem salva ca foaie de calcul Google Sheets și îl putem partaja cu restul echipei.
- De asemenea, îl putem exporta direct în Data Studio.
Datele ca avantaj strategic
Cu toate aceste posibilități, utilizarea strategică a răspunsurilor la întrebările dumneavoastră complexe este ușoară. Este posibil să aveți deja experiență în conectarea rezultatelor BigQuery la Data Studio sau la alte platforme de vizualizare a datelor sau este posibil să aveți deja un proces care transmite informații către o echipă de inginerie sau chiar într-un flux de lucru de business intelligence sau de analiză a datelor.
Dacă ați inclus pașii din acest articol ca parte a unui proces, rețineți că puteți automatiza toți pașii din BigQuery: toate acțiunile pe care le-am efectuat în acest articol sunt accesibile și prin intermediul API-ului BigQuery. Aceasta înseamnă că pot fi executate programatic ca parte a unui script sau a unui instrument personalizat.
Oricare ar fi următorii pași, primul pas este întotdeauna accesul la datele brute SEO și site-ul web. Credem că acest acces la date este una dintre cele mai importante părți ale analizei tehnice: cu Oncrawl, veți avea întotdeauna acces complet la datele dumneavoastră brute.
Accesul la date înseamnă, de asemenea, că puteți depăși ceea ce este posibil în interfața Oncrawl și puteți explora toate relațiile dintre datele dvs., indiferent cât de complexe sunt întrebările pe care le puneți.