
O introducere în analiza fișierelor jurnal SEO
Publicat: 2021-05-17Analiza jurnalelor este cea mai amănunțită modalitate de a analiza modul în care motoarele de căutare citesc site-urile noastre. În fiecare zi, SEO, marketerii digitale și specialiștii în analiză web folosesc instrumente care arată diagrame despre trafic, comportamentul utilizatorilor și conversii. SEO încearcă de obicei să înțeleagă cum își accesează Google site-ul cu crawlere prin Google Search Console.
Deci... de ce ar trebui un SEO să analizeze alte instrumente pentru a verifica dacă un motor de căutare citește corect site-ul? Ok, să începem cu elementele de bază.
Ce sunt fișierele jurnal?
Un fișier jurnal este un fișier în care web-ul serverului scrie un rând pentru fiecare resursă de pe site, care este solicitată de roboți sau utilizatori. Fiecare rând conține date despre cerere, care pot include:
IP apelant, data, resursa necesară (pagină, .css, .js, …), agent utilizator, timp de răspuns, …
Un rând va arăta cam așa:
66.249.**.** - - [13/Apr/2021:00:07:31 +0200] "GET /***/x_*** HTTP/1.1" 200 40960 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "www.***.it" "-"
Accesibilitate cu crawlere și actualizare
Fiecare pagină are trei stări SEO de bază:
- târâbil
- indexabile
- clasificabil
Din perspectiva analizei jurnalului, știm că o pagină, pentru a fi indexată, trebuie citită de un bot. Și, de asemenea, conținutul deja indexat de un motor de căutare trebuie să fie re-crawled pentru a fi actualizat în indexurile motorului de căutare.
Din păcate, în Google Search Console, nu avem acest nivel de detaliu: putem verifica de câte ori Googlebot a citit o pagină de pe site în ultimele trei luni și cât de repede a răspuns serverul web.
Cum putem verifica dacă un bot a citit o pagină? Desigur, prin utilizarea fișierelor jurnal și a unui analizor de fișiere jurnal.
De ce au nevoie SEO-urile să analizeze fișierele jurnal?
Analiza fișierelor jurnal permite SEO (și administratorilor de sistem, de asemenea) să înțeleagă:
- Exact ceea ce citește un bot
- Cât de des îl citește botul
- Cât costă accesările cu crawlere, în termeni de timp petrecut (ms)
Un instrument de analiză a jurnalelor permite analizarea jurnalelor prin gruparea informațiilor după „cale”, după tipul de fișier sau după timpul de răspuns. Un instrument excelent de analiză a jurnalelor ne permite, de asemenea, să unim informațiile obținute din fișierele jurnal cu alte surse de date precum Google Search Console (clicuri, afișări, poziții medii) sau Google Analytics.
Analizor de jurnal oncrawl
 Află mai multe
Află mai multeCe să cauți în fișierele jurnal?
Una dintre principalele informații importante din fișierele jurnal este ceea ce nu este în fișierele jurnal. Serios, nu glumesc. Primul pas pentru a înțelege de ce o pagină nu este indexată sau nu este actualizată la cea mai recentă versiune este să verificați dacă botul (de exemplu, Googlebot) a citit-o.
În continuare, dacă pagina este actualizată frecvent, poate fi important să verificați cât de des citește un bot pagina sau secțiunea site-ului.
Următorul pas este să verificați ce pagini sunt citite cel mai frecvent de către roboți. Urmărindu-le, puteți verifica dacă aceste pagini:
- merită să fie citit atât de des
- sau sunt citite atât de des pentru că ceva de pe pagină provoacă schimbări constante, scăpate de control
De exemplu, în urmă cu câteva luni, un site la care lucram avea o frecvență foarte mare de citiri de bot pe o adresă URL ciudată. Botul a dezvăluit că această pagină provine dintr-o adresă URL creată de un script JS și că această pagină a fost ștampilată cu niște valori de depanare care s-au schimbat de fiecare dată când pagina a fost încărcată... În urma acestei revelații, un SEO bun poate găsi cu siguranță soluția potrivită pentru a remedia acest lucru. crawl buget gaura.
Buget de accesare cu crawlere
Buget de accesare cu crawlere? Ce este? Fiecare site are bugetul său metaforic legat de motoarele de căutare și botul lor. Da: Google stabilește un fel de buget pentru site-ul tău. Acest lucru nu este înregistrat nicăieri, dar îl puteți „calcula” în două moduri:
- verificând raportul privind statisticile de accesare cu crawlere Google Search Console
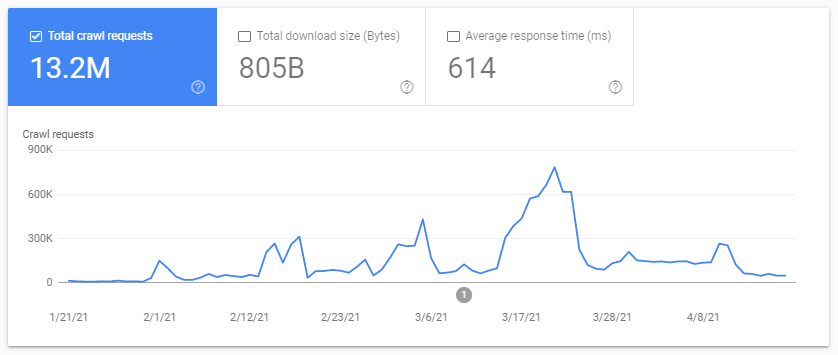
- verificarea fișierelor jurnal, filtrarea lor de către agentul de utilizator care conține „Googlebot” ( veți obține cele mai bune rezultate dacă vă asigurați că acești agenți de utilizator se potrivesc cu IP-urile Google corecte... )
Bugetul de accesare cu crawlere crește atunci când site-ul este actualizat cu conținut interesant, sau când actualizează în mod regulat conținut sau când site-ul primește backlink-uri bune.
Modul în care este cheltuit bugetul de accesare cu crawlere pe site-ul dvs. poate fi gestionat de:
- link-uri interne (follow / nofollow de asemenea!)
- noindex / canonical
- robots.txt (atenție: acest lucru „blochează” user-agent)
Pagini de zombi
Pentru mine, „pagini zombie” sunt toate paginile care nu au avut trafic organic sau vizite bot pentru o perioadă considerabilă de timp, dar au link-uri interne care indică spre ele.
Acest tip de pagină poate folosi prea mult buget de accesare cu crawlere și poate primi în mod inutil rangul paginii din cauza linkurilor interne. Această situație poate fi rezolvată:
- Dacă aceste pagini sunt utile pentru utilizatorii care vin pe site, le putem seta la noindex și le putem seta link-urile interne la ele ca nofollow ( sau folosim disallow robots.txt, dar aveți grijă cu asta... )
- În cazul în care aceste pagini nu sunt utile utilizatorilor care urmează să vină pe site, le putem elimina (și returna un cod de stare 410 sau 404) și eliminăm toate link-urile interne.
Cu Oncrawl putem crea un „raport zombi” bazat pe:
- impresii GSC
- GSC face clicuri
- Sesiuni GA
De asemenea, putem folosi evenimente de jurnal pentru a descoperi pagini zombie: putem defini un filtru de evenimente 0, de exemplu. Una dintre cele mai simple moduri de a face acest lucru este crearea unei Segmentări. În exemplul de mai jos, filtrez toate paginile cu următoarele criterii: fără accesări Googlebot, dar cu un Inrank (asta înseamnă că aceste pagini au link-uri interne care indică către ele). 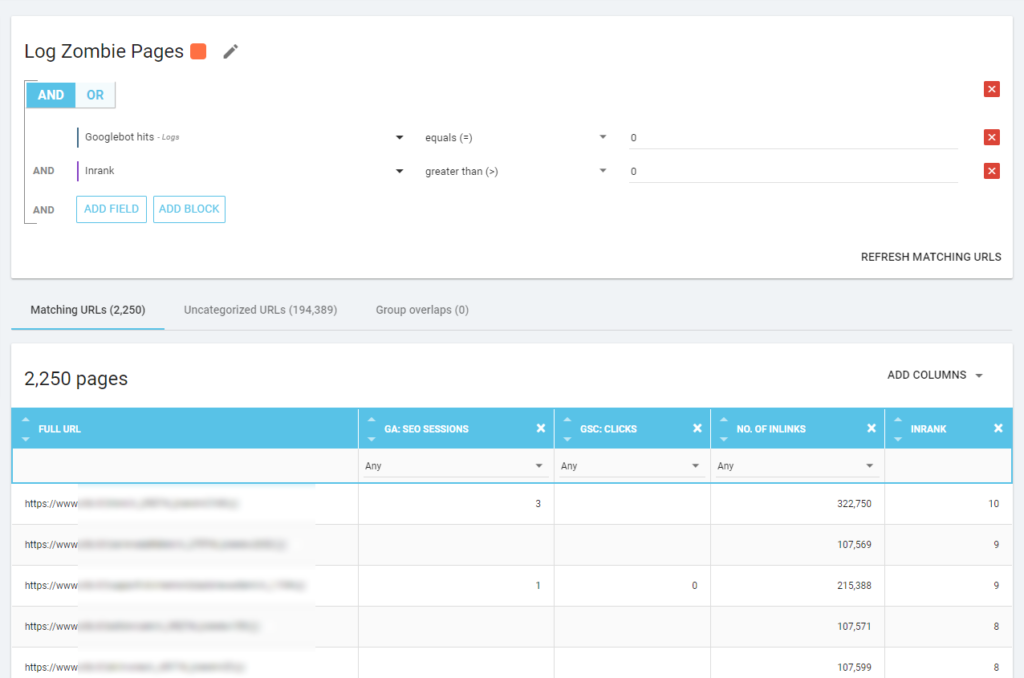
Deci acum putem folosi această segmentare în toate rapoartele Oncrawl. Acest lucru ne permite să obținem informații din orice grafic, de exemplu: câte „pagini zombie de jurnal” returnează un cod de stare de 200? 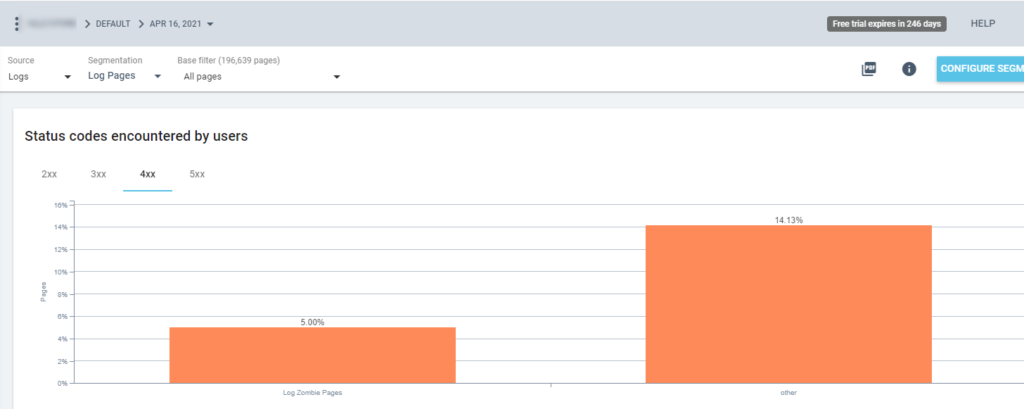
Pagini orfane
Pentru mine, „paginile orfane” care merită să fie analizate cu atenție sunt toate paginile care au valoare mare pentru valori importante (sesiune GA, impresie GSC, accesări în jurnal, …) care nu au nicio legătură internă care să trimită către ele pentru a partaja rangul paginii și indicați importanța paginii.
Ca și în cazul „paginilor zombie”, pentru a crea un raport bazat pe jurnal, cea mai bună modalitate este de a crea o nouă segmentare. 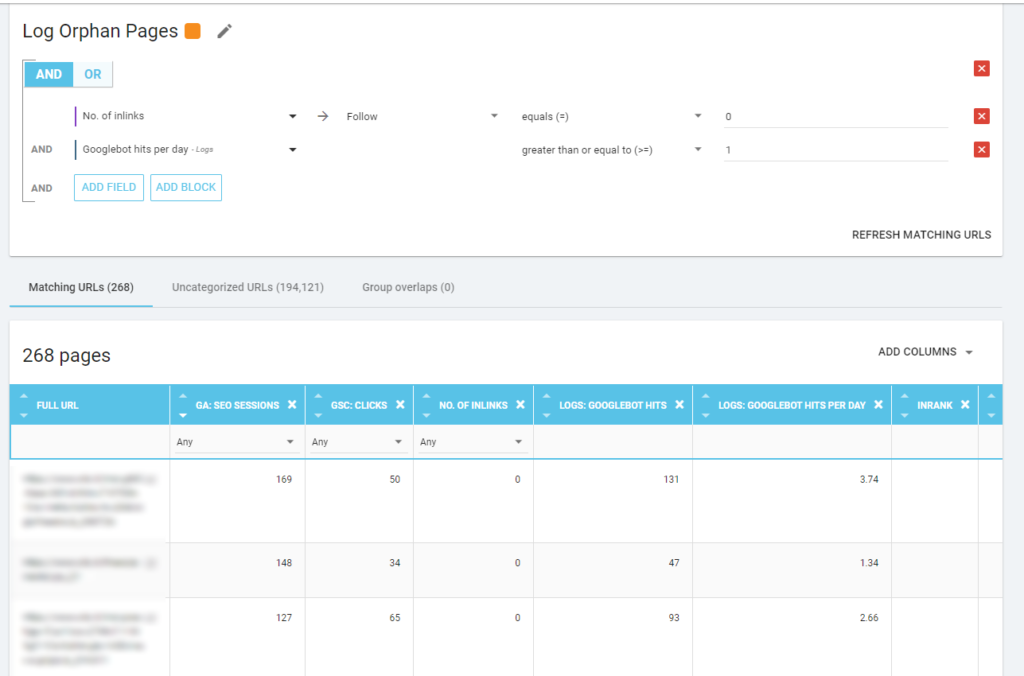
WOW, ce multe pagini cu sesiuni și hit-uri și fără inlink-uri!
Când verificați un raport bazat pe „Zero Follow Inlinks”, vă rugăm să acordați atenție stării de accesare cu crawlere: a reușit Oncrawl să acceseze cu crawlere tot site-ul sau doar câteva pagini? Puteți vedea asta pe pagina principală a proiectului: 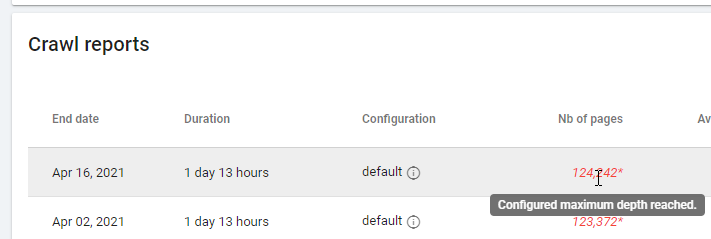
Dacă a fost atinsă adâncimea maximă:

- Verificați configurația accesului cu crawlere
- Verificați structura site-ului dvs
Fișiere jurnal și Oncrawl
Ce oferă Oncrawl în tablourile de bord implicite?
Jurnal live
Acest tablou de bord este util pentru verificarea informațiilor cheie despre modul în care roboții vă citesc site-urile, de îndată ce roboții vizitează site-ul și înainte ca informațiile din fișierele jurnal să fie complet procesate. Pentru a profita la maximum, recomand să încărcați frecvent fișierele jurnal: o puteți face prin FTP, prin conectori precum cel pentru Amazon S3, sau o puteți face manual prin interfața web.
Primul grafic arată cât de des este citit site-ul dvs. și de ce bot. În exemplul pe care îl puteți vedea mai jos, putem verifica accesul desktop vs mobil. În acest caz, am trimis către Oncrawl fișierele jurnal filtrate numai pentru Googlebot: 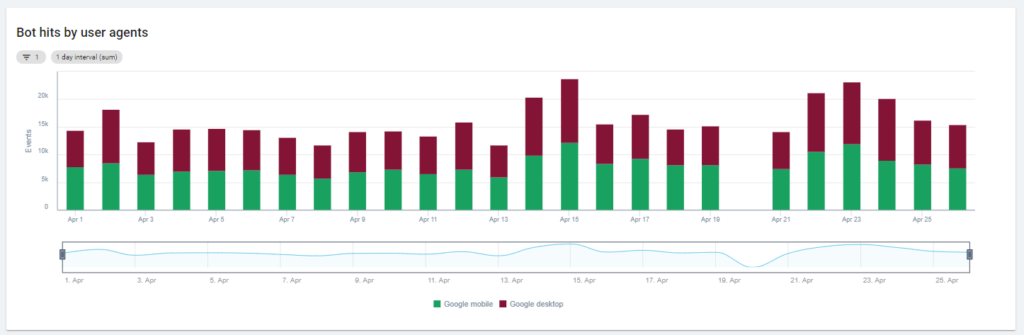
Este interesant de văzut cum cantitatea de citiri mobile este încă foarte mare: este normal? Depinde... Site-ul pe care îl analizăm este încă în „indexul pe mobil”, dar nu este un site complet responsive: este un site web de difuzare dinamică (cum îl numește Google) și Google încă verifică ambele versiuni!
O altă diagramă interesantă este „Accesările botului în funcție de grupul de pagini”. În mod implicit, Oncrawl creează grupuri pe baza căilor URL. Dar putem seta grupuri manual pentru a grupa adresele URL care au cel mai mult sens să le analizăm împreună. 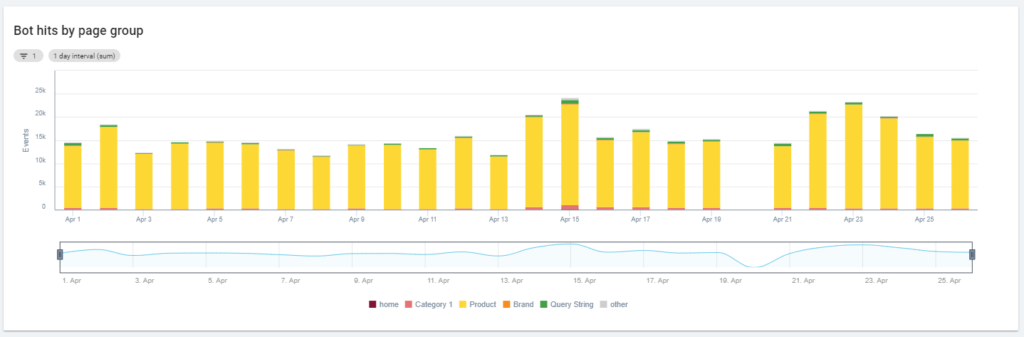
După cum puteți vedea, galbenul câștigă! Reprezintă adrese URL cu o cale de produs, așa că este normal ca acesta să aibă un impact atât de mare, mai ales că avem campanii Google pentru Cumpărături plătite.
Și... da, tocmai am confirmat că Google utilizează Googlebot standard pentru a verifica starea produsului legată de feedul comerciantului!
Comportamentul de crawler
Acest tablou de bord afișează informații similare cu „Jurnal live”, dar aceste informații au fost procesate integral și sunt agregate pe zi, săptămână sau lună. Aici puteți seta o perioadă de dată (început/sfârșit), care se poate întoarce în timp cât doriți. Există două diagrame noi pentru analizarea jurnalelor:
- Comportamentul accesării cu crawlere: pentru a verifica raportul dintre paginile accesate cu crawlere și paginile nou accesate cu crawlere
- Frecvența de accesare cu crawlere pe zi
Cel mai bun mod de a citi aceste diagrame este să conectați rezultatele la acțiunile site-ului:
- Ai mutat paginile?
- Ai actualizat unele secțiuni?
- Ați publicat conținut nou?
Impact SEO
Pentru SEO, este important să monitorizați dacă paginile optimizate sunt citite de boți sau nu. Așa cum am scris despre „paginile orfane”, este important să ne asigurăm că cele mai importante/actualizate pagini sunt citite de roboți, astfel încât cele mai actualizate informații să fie disponibile pentru motoarele de căutare pentru a putea fi clasate.
Oncrawl folosește conceptul de „Pagini active” pentru a indica paginile care primesc trafic organic de la motoarele de căutare. Pornind de la acest concept, arată câteva numere de bază, cum ar fi:
- Vizite SEO
- Pagini active SEO
- Raportul activ SEO (proporția de pagini active dintre toate paginile accesate cu crawlere)
- Clasament proaspăt (timpul mediu care trece între momentul când botul citește prima pagină și prima vizită organică)
- Paginile active nu au fost accesate cu crawlere
- Pagini nou active
- Frecvența accesării cu crawlere pe zi a paginilor active
Așa cum este filosofia lui Oncrawl, cu un singur clic, putem pătrunde adânc în lacul de informații, filtrate după metrica pe care am dat clic! De exemplu: care sunt paginile active care nu sunt accesate cu crawlere? Un click… 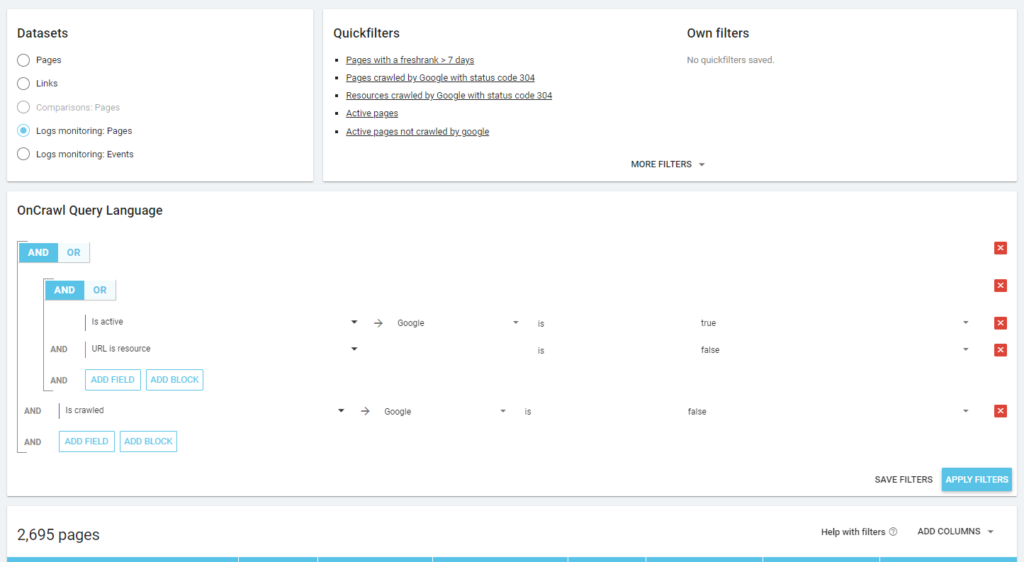
Explorare minte
Acest ultim tablou de bord ne permite să verificăm calitatea crawling-ului bo-ului sau, mai precis, cât de bine se prezintă site-ul motoarele de căutare:
- Analiza codului de stare
- Analiza codului de stare pe zi
- Analiza codului de stare pe grup de pagini
- Analiza timpului de raspuns
Pentru o bună activitate SEO, este obligatoriu să:
- reduceți numărul de 301 răspunsuri de la legăturile interne
- eliminați răspunsurile 404/410 din linkurile interne
- optimizați timpul de răspuns, deoarece calitatea accesului cu crawlere Googlebot este direct legată de timpul de răspuns: încercați să reduceți timpul de răspuns pe site-ul dvs. la jumătate și veți vedea (în câteva zile) că cantitatea de pagini accesate cu crawlere se va dubla.
Știința analizei jurnalului și a exploratorului de date Oncrawl
Până acum am văzut rapoartele Oncrawl standard și cum să le folosim pentru a obține informații personalizate prin segmentări și grupuri de pagini.
Dar miezul analizei jurnalelor este de a înțelege cum să găsiți ceva greșit. De obicei, punctul de pornire al analizei este să verifici vârfurile și să le compari cu traficul și cu obiectivele tale:
- cele mai multe pagini accesate cu crawlere
- paginile cel mai puțin accesate cu crawlere
- cele mai accesate resurse (nu pagini)
- frecvențele de accesare cu crawlere în funcție de tipul de fișier
- impactul codurilor de stare 3xx / 4xx
- impactul codurilor de stare 5xx
- pagini cu crawlere mai lente
- …
Vrei să mergi mai adânc? Bine... trebuie să adăugați date. Și Oncrawl oferă un instrument foarte puternic, cum ar fi Data Explorer.
După cum puteți vedea într-o captură de ecran anterioară (paginile active nu au fost accesate cu crawlere), puteți crea toate rapoartele dorite pe baza cadrului de analiză.
De exemplu:
- cele mai proaste pagini de trafic organic cu mult acces cu crawlere de către roboți
- cele mai bune pagini de trafic organic cu prea mult acces cu crawlere de către roboți
- pagini mai lente, cu multe afișări SERP
- …
Mai jos puteți vedea cum am verificat care sunt paginile cele mai accesate cu crawlere legate de numărul lor de sesiuni SEO: 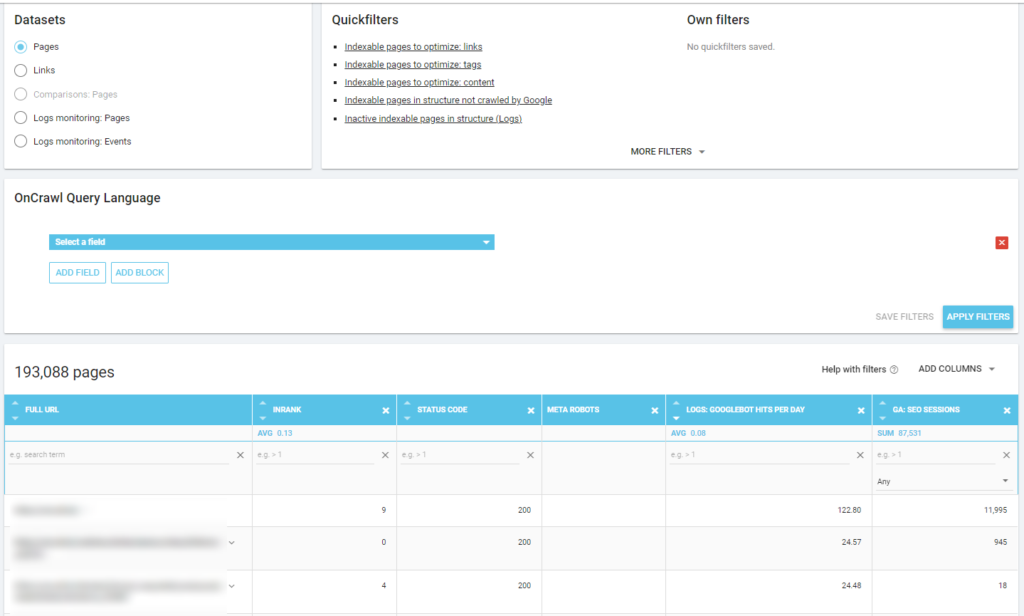
Concluzii
Analiza jurnalului nu este strict tehnică: pentru a o face în cel mai bun mod posibil trebuie să combinăm abilitățile tehnice, abilitățile SEO și abilitățile de marketing.
Prea des, o analiză este exclusă dintr-o „listă de verificare SEO” deoarece clientul nostru nu are acces la fișierele jurnal sau pentru că poate fi o analiză costisitoare.
Realitatea este că jurnalele sunt singurele surse pentru a verifica cu adevărat unde merg roboții pe site-urile noastre și pentru a ști cum răspund serverele noastre la ele.
Un instrument precum Oncrawl poate reduce foarte mult cerințele tehnice: trebuie doar să încărcați fișierele jurnal și să începeți să le analizați!