
O que são vetores de palavras e como a marcação estruturada os sobrecarrega
Publicados: 2021-07-28Como você define vetores de palavras? Neste post, apresentarei o conceito de vetores de palavras. Veremos diferentes tipos de incorporação de palavras e, mais importante, como os vetores de palavras funcionam. Assim, poderemos ver o impacto dos vetores de palavras em SEO, o que nos levará a entender como a marcação Schema.org para dados estruturados pode ajudá-lo a aproveitar os vetores de palavras em SEO.
Continue lendo este post se quiser saber mais sobre esses tópicos.
Vamos mergulhar direto.
O que são vetores de palavras?
Os vetores de palavras (também chamados de incorporação de palavras) são um tipo de representação de palavras que permite que palavras com significados semelhantes tenham uma representação igual.
Em termos simples: Um vetor de palavras é uma representação vetorial de uma determinada palavra.
Segundo a Wikipédia:
É uma técnica usada no processamento de linguagem natural (PLN) para representar palavras para análise de texto, normalmente como um vetor de valor real que codifica o significado da palavra de modo que as palavras que estão próximas no espaço vetorial provavelmente tenham significados semelhantes.
O exemplo a seguir nos ajudará a entender melhor:
Veja estas frases semelhantes:
Tenha um bom dia . e tenha um ótimo dia.
Eles mal têm um significado diferente. Se construirmos um vocabulário exaustivo (vamos chamá-lo de V), ele teria V = {Have, a, good, great, day} combinando todas as palavras. Poderíamos codificar a palavra da seguinte forma.
A representação vetorial de uma palavra pode ser um vetor codificado one-hot onde 1 representa a posição onde a palavra existe e 0 representa o resto
Ter = [1,0,0,0,0]
a=[0,1,0,0,0]
bom=[0,0,1,0,0]
ótimo=[0,0,0,1,0]
dia=[0,0,0,0,1]
Suponha que nosso vocabulário tenha apenas cinco palavras: Rei, Rainha, Homem, Mulher e Criança. Poderíamos codificar as palavras como:
Rei = [1,0,0,0,0]
Rainha = [0,1,0,0,0]
Homem = [0,0,1,00]
Mulher = [0,0,0,1,0]
Filho = [0,0,0,0,1]
Tipos de incorporação de palavras (vetores de palavras)
Word Embedding é uma dessas técnicas em que os vetores representam o texto. Aqui estão alguns dos tipos mais populares de incorporação de palavras:
- Incorporação baseada em frequência
- Incorporação baseada em previsão
Não nos aprofundaremos na incorporação baseada em frequência e na incorporação baseada em previsão aqui, mas você pode achar os seguintes guias úteis para entender ambos:
Uma compreensão intuitiva de incorporação de palavras e introdução rápida ao Bag-of-Words (BOW) e TF-IDF para criar recursos a partir de texto
Uma breve introdução ao WORD2Vec
Embora a incorporação baseada em frequência tenha ganhado popularidade, ainda há um vazio na compreensão do contexto das palavras e limitado em suas representações de palavras.
A incorporação baseada em previsão (WORD2Vec) foi criada, patenteada e apresentada à comunidade de PNL em 2013 por uma equipe de pesquisadores liderada por Tomas Mikolov no Google.
De acordo com a Wikipedia, o algoritmo word2vec usa um modelo de rede neural para aprender associações de palavras de um grande corpus de texto (conjunto de textos grande e estruturado).
Uma vez treinado, esse modelo pode detectar palavras sinônimas ou sugerir palavras adicionais para uma frase parcial. Por exemplo, com Word2Vec, você pode facilmente criar esses resultados: Rei – homem + mulher = Rainha, que foi considerado um resultado quase mágico.
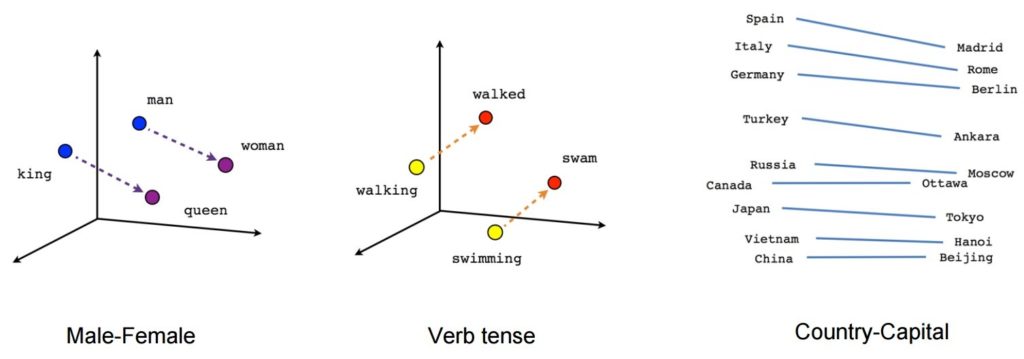 Fonte da imagem: Tensorflow
Fonte da imagem: Tensorflow
- [rei] – [homem] + [mulher] ~= [rainha] (outra maneira de pensar sobre isso é que [rei] – [rainha] está codificando apenas a parte de gênero de [monarca])
- [andar] – [nadar] + [nadar] ~= [andar] (ou [nadar] – [nadar] está codificando apenas o “passado” do verbo)
- [madrid] – [spain] + [france] ~= [paris] (ou [madrid] – [spain] ~= [paris] – [france] que é presumivelmente mais ou menos “capital”)
Fonte: Brainslab Digital
Eu sei que isso é um pouco técnico, mas o Stitch Fix montou um post fantástico sobre relacionamentos semânticos e vetores de palavras.
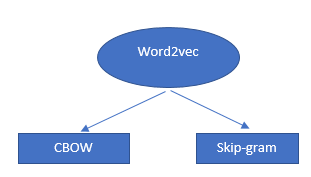
O algoritmo Word2Vec não é um algoritmo único, mas uma combinação de duas técnicas que usa alguns métodos de IA para unir a compreensão humana e a compreensão da máquina. Essa técnica é essencial para resolver muitos PNL problemas.
Essas duas técnicas são:
- – CBOW (contínuo saco de palavras) ou modelo CBOW
- – Modelo Skip-gram.
Ambos são redes neurais superficiais que fornecem probabilidades de palavras e se mostraram úteis em tarefas como comparação de palavras e analogia de palavras.
Como funcionam os vetores de palavras e o word2vecs
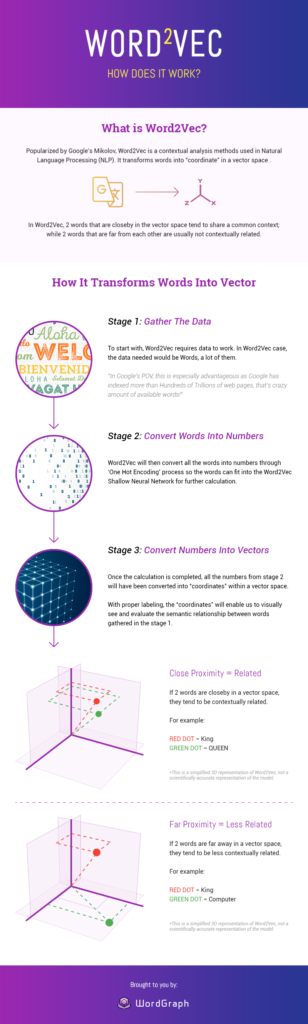
Word Vector é um modelo de IA desenvolvido pelo Google e nos ajuda a resolver tarefas de PNL muito complexas.
“Os modelos Word Vector têm um objetivo central que você deve saber:
É um algoritmo que ajuda o Google a detectar relações semânticas entre palavras.”
Cada palavra é codificada em um vetor (como um número representado em várias dimensões) para corresponder a vetores de palavras que aparecem em um contexto semelhante. Assim, um vetor denso é formado para o texto.
Esses modelos vetoriais mapeiam frases semanticamente semelhantes para pontos próximos com base na equivalência, semelhanças ou relação de ideias e linguagem
[Estudo de caso] Impulsionando o crescimento em novos mercados com SEO na página
 Leia o estudo de caso
Leia o estudo de casoWord2Vec- Como funciona?
Fonte da imagem: Seopressor
Prós e contras do Word2Vec
Vimos que o Word2vec é uma técnica muito eficaz para gerar similaridade de distribuição. Eu listei algumas de suas outras vantagens aqui:
- Não há dificuldade em entender os conceitos do Word2vec. Word2Vec não é tão complexo que você não saiba o que está acontecendo nos bastidores.
- A arquitetura do Word2Vec é muito poderosa e fácil de usar. Comparado com outras técnicas, é rápido de treinar.
- O treinamento é quase totalmente automatizado aqui, portanto, os dados marcados por humanos não são mais necessários.
- Essa técnica funciona para conjuntos de dados pequenos e grandes. Como resultado, é um modelo fácil de dimensionar.
- Se você conhece os conceitos, pode facilmente replicar todo o conceito e algoritmo.
- Ele captura a semelhança semântica excepcionalmente bem.
- Preciso e computacionalmente eficiente
- Como essa abordagem não é supervisionada, economiza muito tempo em termos de esforço.
Desafios do Word2Vec
O conceito Word2vec é muito eficiente, mas você pode achar alguns pontos um pouco desafiadores. Aqui estão alguns dos desafios mais comuns.
- Ao desenvolver um modelo word2vec para seu conjunto de dados, a depuração pode ser um grande desafio, pois o modelo word2vec é fácil de desenvolver, mas difícil de depurar.
- Não lida com ambiguidades. Assim, no caso de palavras com múltiplos significados, a incorporação refletirá a média desses significados no espaço vetorial.
- Incapaz de lidar com palavras desconhecidas ou OOV: O maior problema com o word2vec é a incapacidade de lidar com palavras desconhecidas ou fora do vocabulário (OOV).
Word Vector: Um divisor de águas em Search Engine Optimization?
Muitos especialistas em SEO acreditam que o Word Vector afeta a classificação de um site nos resultados dos mecanismos de pesquisa.
Nos últimos cinco anos, o Google introduziu duas atualizações de algoritmo que colocam um foco claro na qualidade do conteúdo e na abrangência do idioma.
Vamos dar um passo atrás e falar sobre as atualizações:
beija Flor
Em 2013, o Hummingbird deu aos mecanismos de busca a capacidade de análise semântica. Ao utilizar e incorporar a teoria da semântica em seus algoritmos, eles abriram um novo caminho para o mundo da busca.
O Google Hummingbird foi a maior mudança no mecanismo de busca desde Caffeine em 2010. Recebe o nome por ser “preciso e rápido”.
De acordo com o Search Engine Land, o Hummingbird presta mais atenção a cada palavra em uma consulta, garantindo que toda a consulta seja considerada, em vez de apenas palavras específicas.

O principal objetivo do Hummingbird era fornecer melhores resultados por meio da compreensão do contexto da consulta, em vez de retornar resultados para palavras-chave específicas.
“O Google Hummingbird foi lançado em setembro de 2013.”
RankBrain
Em 2015, o Google anunciou o RankBrain, uma estratégia que incorporou inteligência artificial (IA).
RankBrain é um algoritmo que ajuda o Google a dividir consultas de pesquisa complexas em outras mais simples. O RankBrain converte as consultas de pesquisa do idioma “humano” em um idioma que o Google pode entender facilmente.
O Google confirmou o uso do RankBrain em 26 de outubro de 2015 em um artigo publicado pela Bloomberg.
BERT
Em 21 de outubro de 2019, o BERT começou a ser lançado no sistema de pesquisa do Google
BERT significa Bidirectional Encoder Representations from Transformers, uma técnica baseada em rede neural usada pelo Google para pré-treinamento em processamento de linguagem natural (NLP).
Em suma, o BERT ajuda os computadores a entender a linguagem mais como os humanos, e é a maior mudança na pesquisa desde que o Google introduziu o RankBrain.
Não é um substituto para o RankBrain, mas sim um método adicional para entender o conteúdo e as consultas.
O Google usa o BERT em seu sistema de classificação como um complemento. O algoritmo RankBrain ainda existe para algumas consultas e continuará existindo. Mas quando o Google achar que o BERT pode entender melhor uma consulta, eles usarão isso.
Para mais informações sobre o BERT, confira este post de Barry Schwartz, bem como o mergulho aprofundado de Dawn Anderson.
Classifique seu site com vetores do Word
Presumo que você já tenha criado e publicado conteúdo exclusivo e, mesmo depois de poli-lo repetidamente, isso não melhora sua classificação ou tráfego.
Você se pergunta por que isso está acontecendo com você?
Pode ser porque você não incluiu o Word Vector: o modelo de IA do Google.
- O primeiro passo é identificar os vetores de palavras dos 10 principais rankings SERP para o seu nicho.
- Saiba quais palavras-chave seus concorrentes estão usando e o que você pode estar ignorando.
Ao aplicar o Word2Vec, que aproveita as técnicas avançadas de processamento de linguagem natural e a estrutura de aprendizado de máquina, você poderá ver tudo em detalhes.
Mas isso é possível se você conhece as técnicas de aprendizado de máquina e PNL, mas podemos aplicar vetores de palavras no conteúdo usando a seguinte ferramenta:
WordGraph, a primeira ferramenta de vetor de palavras do mundo
Esta ferramenta de inteligência artificial é criada com Redes Neurais para Processamento de Linguagem Natural e treinada com Aprendizado de Máquina.
Com base em Inteligência Artificial, o WordGraph analisa seu conteúdo e ajuda você a melhorar sua relevância para os 10 principais sites do ranking.
Ele sugere palavras-chave matematicamente e contextualmente relacionadas à sua palavra-chave principal.
Pessoalmente, combino com o BIQ, uma poderosa ferramenta de SEO que funciona bem com o WordGraph.
Adicione seu conteúdo à ferramenta de inteligência de conteúdo integrada ao Biq. Ele mostrará uma lista completa de dicas de SEO na página que você pode adicionar se quiser classificar na primeira posição.
Você pode ver como a inteligência de conteúdo funciona neste exemplo. As listas ajudarão você a dominar o SEO na página e a classificar usando métodos acionáveis!
Como turbinar vetores do Word: usando marcação de dados estruturados
Marcação de esquema, ou dados estruturados, é um tipo de código (escrito em JSON, Java-Script Object Notation) criado usando o vocabulário schema.org que ajuda os mecanismos de pesquisa a rastrear, organizar e exibir seu conteúdo.
Como adicionar dados estruturados
Dados estruturados podem ser facilmente adicionados ao seu site adicionando um script embutido em seu html
Um exemplo abaixo mostra como definir os dados estruturados da sua organização no formato mais simples possível.
Para gerar o Schema Markup, utilizo este Schema Markup Generator (JSON-LD).
Aqui está o exemplo ao vivo de marcação de esquema para https://www.telecloudvoip.com/. Verifique o código-fonte e procure por JSON.
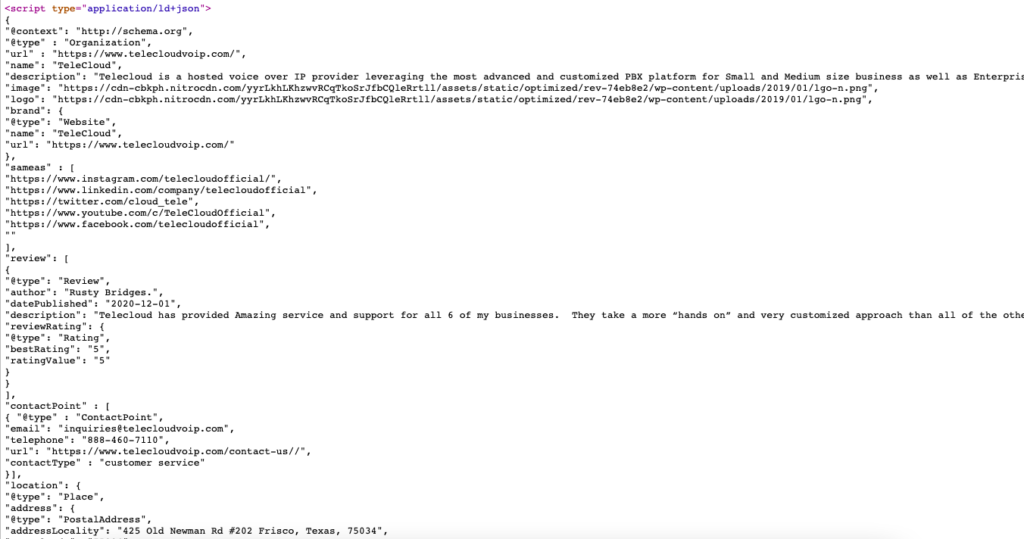
Depois que o código de marcação do esquema for criado, use o teste de pesquisa aprimorada do Google para ver se a página é compatível com pesquisas aprimoradas.
Você também pode usar a ferramenta Semrush Site Audit para explorar itens de Dados Estruturados para cada URL e identificar quais páginas são elegíveis para serem incluídas em Rich Results. 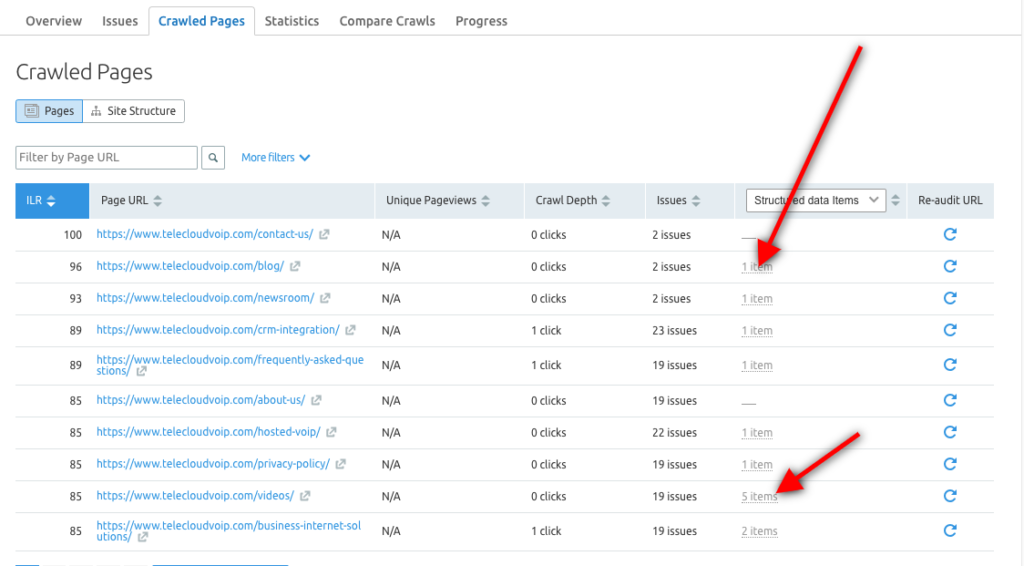
Por que os dados estruturados são importantes para SEO?
Os Dados Estruturados são importantes para SEO porque ajudam o Google a entender sobre o que é seu site e suas páginas, resultando em uma classificação mais precisa do seu conteúdo.
Os Dados Estruturados melhoram tanto a experiência do Search Bot quanto a experiência do usuário, melhorando a SERP (páginas de resultados do mecanismo de pesquisa) com mais informações e precisão.
Para ver o impacto na pesquisa do Google, acesse Search Console e, em Desempenho > Resultado da pesquisa > Aparência da pesquisa, você pode ver um detalhamento de todos os tipos de pesquisa aprimorada, como "vídeos" e "Perguntas frequentes", e ver as impressões orgânicas e os cliques que eles geraram para o seu conteúdo.
A seguir estão algumas vantagens dos dados estruturados:
- Dados estruturados suportam pesquisa semântica
- Ele também suporta seu E-AT (experiência, autoridade e confiança)
- Ter dados estruturados também pode aumentar as taxas de conversão, pois mais pessoas verão suas listagens, o que aumenta a probabilidade de comprarem de você.
- Usando dados estruturados, os mecanismos de pesquisa são mais capazes de entender sua marca, seu site e seu conteúdo.
- Será mais fácil para os mecanismos de pesquisa distinguir entre páginas de contato, descrições de produtos, páginas de receitas, páginas de eventos e avaliações de clientes.
- Com a ajuda de dados estruturados, o Google cria um gráfico de conhecimento e um painel de conhecimento melhores e mais precisos sobre sua marca.
- Essas melhorias podem resultar em mais impressões orgânicas e cliques orgânicos.
Atualmente, os dados estruturados são usados pelo Google para aprimorar os resultados da pesquisa. Quando as pessoas pesquisam suas páginas da Web usando palavras-chave, os dados estruturados podem ajudar você a obter melhores resultados. Os mecanismos de pesquisa notarão seu conteúdo mais se adicionarmos a marcação Schema.
Você pode implementar a marcação de esquema em vários itens diferentes. Abaixo estão listadas algumas áreas onde o esquema pode ser aplicado:
- Artigos
- Postagens no blog
- Novos artigos
- Eventos
- Produtos
- Vídeos
- Serviços
- Avaliações
- Classificações agregadas
- Restaurantes
- Negócio local
Aqui está uma lista completa dos itens que você pode marcar com o esquema.
Dados estruturados com incorporações de entidade
O termo “entidade” refere-se a uma representação de qualquer tipo de objeto, conceito ou assunto. Uma entidade pode ser uma pessoa, filme, livro, ideia, lugar, empresa ou evento.
Enquanto as máquinas não podem realmente entender palavras, com incorporação de entidades, elas são capazes de entender facilmente a relação entre rei – rainha = marido – esposa
As incorporações de entidades têm um desempenho melhor do que as codificações one-hot
O algoritmo de vetor de palavras é usado pelo Google para descobrir relações semânticas entre palavras e, quando combinado com dados estruturados, acabamos com uma web semanticamente aprimorada.
Ao usar dados estruturados, você está contribuindo para uma web mais semântica. Esta é uma web aprimorada onde descrevemos os dados em um formato legível por máquina.
Dados semânticos estruturados em seu site ajudam os mecanismos de pesquisa a combinar seu conteúdo com o público certo. O uso de NLP, Machine Learning e Deep Learning ajuda a reduzir a lacuna entre o que as pessoas pesquisam e quais títulos estão disponíveis.
Pensamentos finais
Agora que você entende o conceito de vetores de palavras e sua importância, pode tornar sua estratégia de pesquisa orgânica mais eficaz e eficiente utilizando vetores de palavras, incorporações de entidades e dados semânticos estruturados.
Para alcançar a classificação, o tráfego e as conversões mais altos, você deve usar vetores de palavras, incorporações de entidades e dados semânticos estruturados para demonstrar ao Google que o conteúdo da sua página da Web é preciso, preciso e confiável.