
[Webinar Digest] SEO em órbita: novas perspectivas sobre conteúdo duplicado
Publicados: 2019-11-20O webinar Novas perspectivas sobre conteúdo duplicado é o episódio final da série SEO in Orbit e foi ao ar em 24 de junho de 2019. Neste episódio, junte-se ao embaixador do OnCrawl Omi Sido e Alexis Sanders enquanto exploram a questão do conteúdo duplicado. Eles abordam questões como: Como os fatores de classificação e as tecnologias de pesquisa em evolução afetam a maneira como lidamos com conteúdo duplicado? E: O que o futuro reserva para conteúdo semelhante na web?
SEO in Orbit é a primeira série de webinars que envia SEO para o espaço. Ao longo da série, discutimos o presente e o futuro do SEO técnico com alguns dos melhores especialistas em SEO e enviamos suas principais dicas para o espaço em 27 de junho de 2019.
Assista a reprise aqui:
Apresentando Alexis Sanders
Alexis Sanders trabalha como gerente técnico de contas de SEO na Merkle. A equipe técnica de SEO garante a precisão, viabilidade e escalabilidade das recomendações técnicas da agência em todas as verticais. Ela é colaboradora do blog Moz e criadora do desafio TechnicalSEO.expert e do podcast SEO in the Lab.
Este episódio foi apresentado por Omi Sido. Omi é um palestrante internacional experiente e é conhecido na indústria por seu humor e capacidade de fornecer insights acionáveis que o público pode começar a usar imediatamente. Desde consultoria de SEO com algumas das maiores empresas de telecomunicações e viagens do mundo até o gerenciamento de SEO interno no HostelWorld e Daily Mail, Omi adora mergulhar em dados complexos e encontrar os pontos positivos. Atualmente, Omi é SEO Técnico Sênior na Canon Europe e Embaixador OnCrawl.
O que é conteúdo duplicado?
Omi fornece a seguinte definição de conteúdo duplicado:
Conteúdo duplicado que seja semelhante ou quase semelhante ao conteúdo que reside em um URL diferente no mesmo (ou em um site diferente).
O mito da penalidade por conteúdo duplicado
Não há penalidade de conteúdo duplicado.
Este é um problema de desempenho. Não queremos que um bot olhe para dois URLs específicos e pense que são dois conteúdos diferentes que podem ser classificados um ao lado do outro.
Alexis compara a compreensão de um bot do seu site com as fotos de Joey de 10 coisas que eu odeio em você: é impossível para um bot encontrar uma diferença material entre as duas versões.

Você quer evitar ter duas coisas exatamente iguais que precisam competir umas com as outras em uma situação de classificação de mecanismos de pesquisa. Em vez disso, você deseja ter uma experiência única e consolidada que possa classificar e ter desempenho nos mecanismos de pesquisa.
Diferença entre o que os usuários e os bots veem
Um usuário pode ver um único URL convincente, mas um bot ainda pode ver várias versões que parecem essencialmente iguais.
– Efeito no orçamento de rastreamento para sites muito grandes
Para sites muito grandes, como Zillow ou Walmart, o orçamento de rastreamento pode variar para páginas diferentes.
Como Alexis discutiu em um artigo de 2018 baseado em uma apresentação de Frederic Dubut na SMX East, os orçamentos são definidos em níveis variados – em níveis de subdomínio, em diferentes níveis de servidor. Os mecanismos de pesquisa, seja Google ou Bing, querem ser rastreadores educados; eles não querem diminuir o desempenho para usuários reais. Sempre que eles sentem uma mudança no desempenho, eles recuam. Isso pode ocorrer em diferentes níveis, não apenas no nível do site.
Se você tem um site enorme, quer ter certeza de que está oferecendo a experiência mais consolidada e relevante para seus usuários.
O conteúdo duplicado é um conteúdo ou um problema técnico?
Apesar da palavra “conteúdo” em “conteúdo duplicado”, é em parte um problema técnico.
– Fontes de duplicação – [07:50]
Há muitos fatores que podem causar duplicação. Mesmo uma lista parcial pode parecer durar para sempre:
- Páginas repetitivas
- Sites de teste
- URLs HTTP vs HTTPS
- Diferentes subdomínios
- Casos diferentes
- Diferentes extensões de arquivo
- Barra final
- Páginas de índice
- Parâmetros de URL
- Facetas
- Classificações
- Versão para impressão
- Página de entrada
- Inventário
- Conteúdo distribuído
- Comunicados de relações públicas
- Republicação de conteúdo
- Conteúdo plagiado
- Conteúdo localizado
- Conteúdo fino
- Apenas imagens
- Pesquisa interna de sites
- Site móvel separado
- Conteúdo não exclusivo
- …
– Distribuição de questões entre SEO técnico e conteúdo
Na verdade, essas fontes de conteúdo duplicado podem ser divididas em fontes técnicas e de desenvolvimento e fontes baseadas em conteúdo, e algumas que se enquadram em uma zona de sobreposição entre as duas.
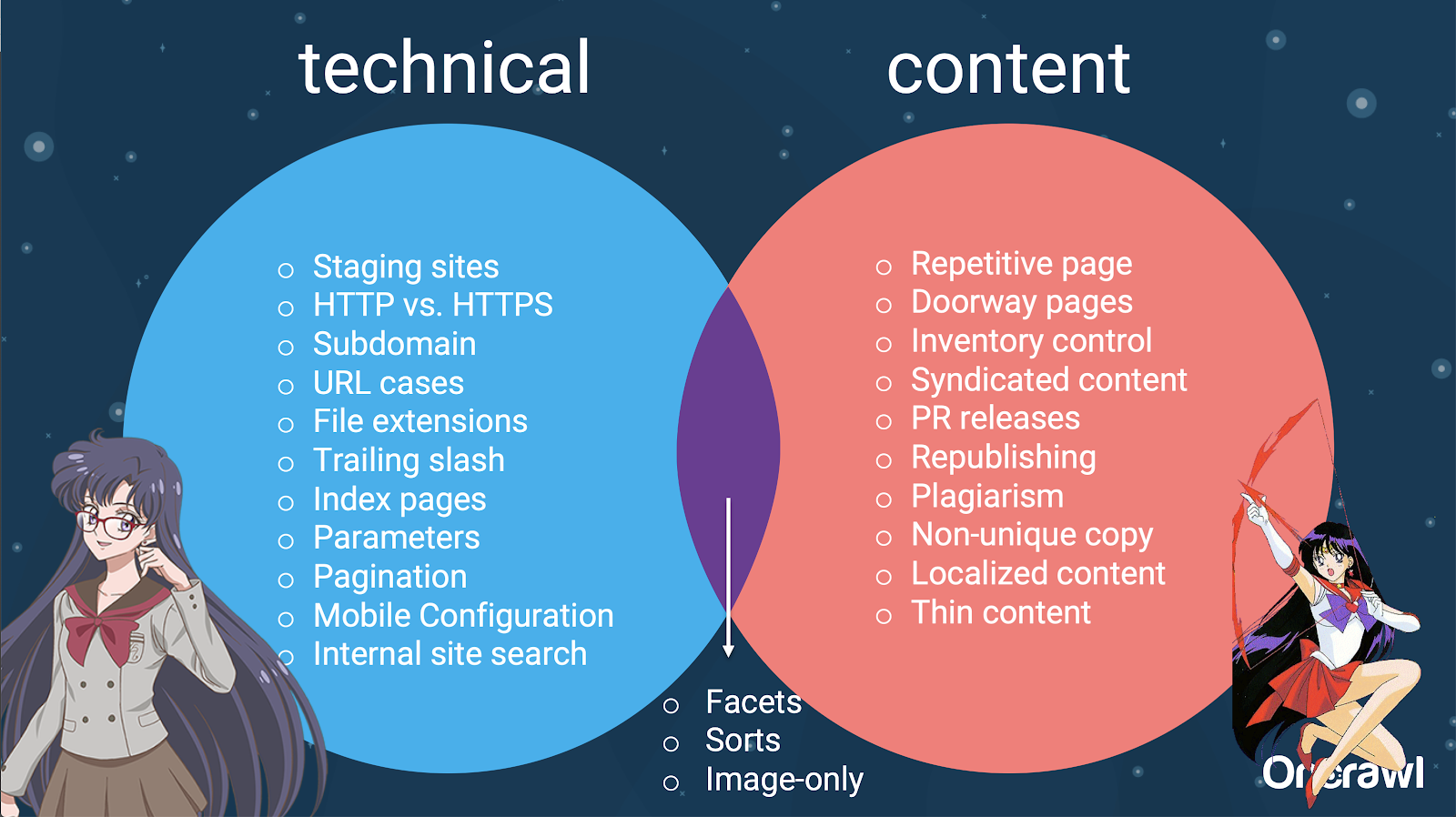
Isso torna o conteúdo duplicado um problema entre equipes, o que é parte do que o torna tão interessante.
Como encontrar conteúdo duplicado
A maioria dos conteúdos duplicados não é intencional. Para a Omi, isso indica que há uma responsabilidade compartilhada entre o conteúdo e as equipes técnicas para encontrar e corrigir conteúdo duplicado.
– A ferramenta favorita de Omi: Grammarly
Grammarly é a ferramenta favorita do Omi para encontrar conteúdo duplicado – e nem é uma ferramenta de SEO. Ele usa o verificador de plágio. Ele pede ao editor de conteúdo para verificar se um novo conteúdo já foi publicado em outro lugar.
– Volume de conteúdo duplicado não intencional
O problema do conteúdo duplicado não intencional é um problema com o qual os engenheiros estão muito familiarizados. Em um livro chamado Introduction to Information Retrieval (2008), que está claramente desatualizado, eles estimaram que cerca de 40% da web da época estava duplicada.

– Priorizando estratégias para lidar com conteúdo duplicado
Para lidar com conteúdo duplicado, você deve:
- Comece conhecendo a jornada do usuário, o que ajudará você a entender onde cada parte do conteúdo se encaixa. Isso pode ser extremamente difícil de fazer, principalmente quando os sites foram criados há 20 anos, quando não sabíamos o quão grande eles se tornariam ou como eles escalariam. Saber onde seu usuário está em um determinado ponto da jornada o ajudará a priorizar algumas das próximas etapas.
- Você precisará de uma hierarquia que funcione para fornecer um local para cada tipo de conteúdo. Compreender sua arquitetura de informações é realmente uma etapa importante para lidar com conteúdo duplicado.
- Priorize o conteúdo duplicado que afeta o desempenho. A lista parcial de fontes acima é muito longa para ser algo que você possa atacar realisticamente de uma só vez.
- Lidar com 100% de duplicação
- Conteúdo duplicado do sinal
- Faça escolhas estratégicas sobre como lidar com a duplicação: consolidar, criar, excluir, otimizar
- Lidar com conteúdo roubado

– Ferramentas: Usando segmentação no OnCrawl
Alexis realmente gosta da capacidade de segmentar seu site no OnCrawl, o que permite mergulhar em coisas que são significativas para você.
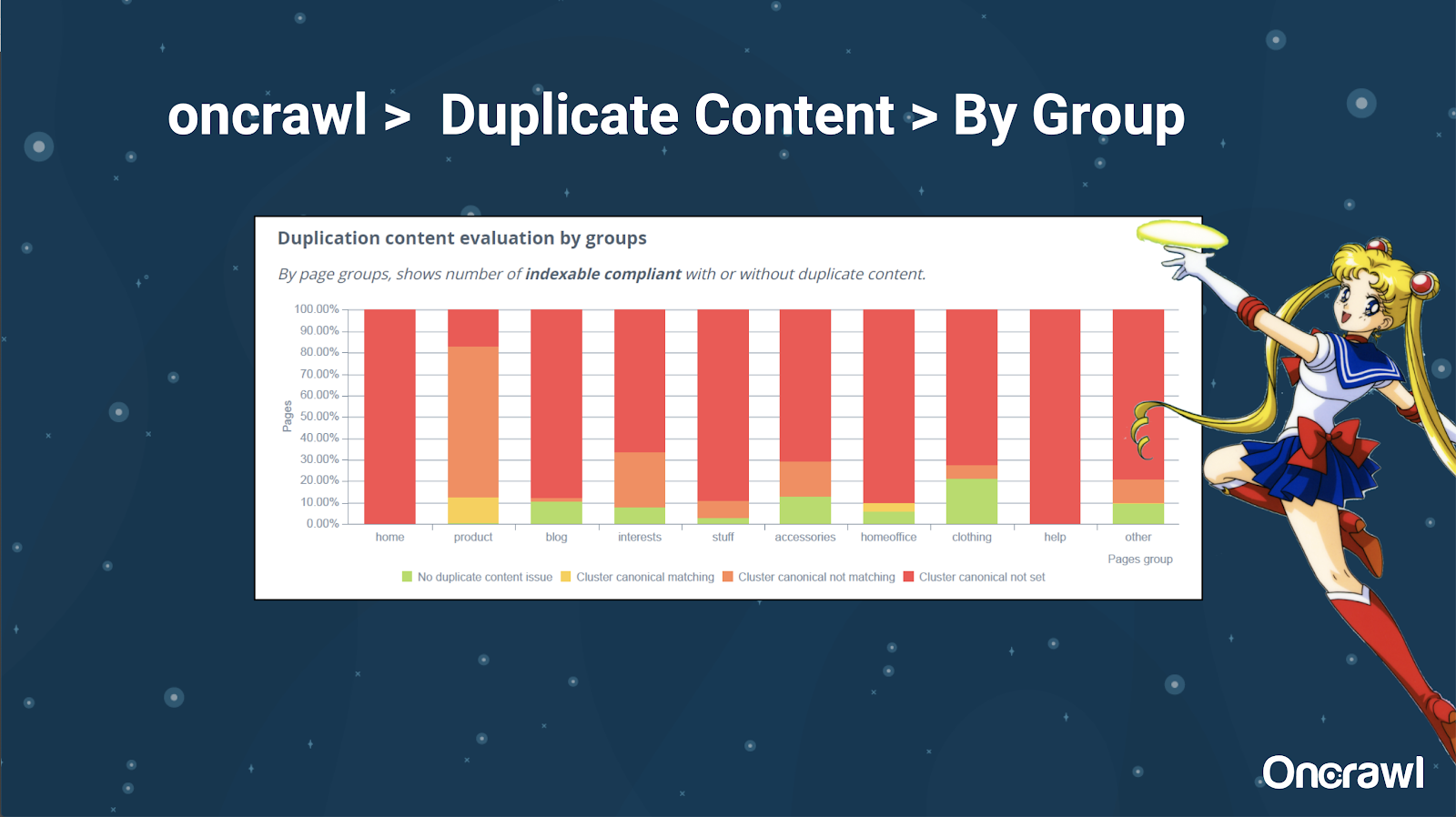
Diferentes tipos de páginas têm diferentes quantidades de duplicação; isso permite obter uma visão das seções que têm mais problemas. No exemplo acima, o site precisa de muita atenção.
– Ferramentas: Pesquisa Google e GSC
Você também pode verificar se há conteúdo duplicado usando o próprio mecanismo de pesquisa. No Google você pode:
- Use citações diretas
- Usar site: pesquisas
- Usando operadores adicionais como inurl:, intitle: ou filetype:

O Google Search Console também adicionou um relatório de conteúdo duplicado, que é muito útil para identificar o que o Google acredita ser conteúdo duplicado do lado deles.
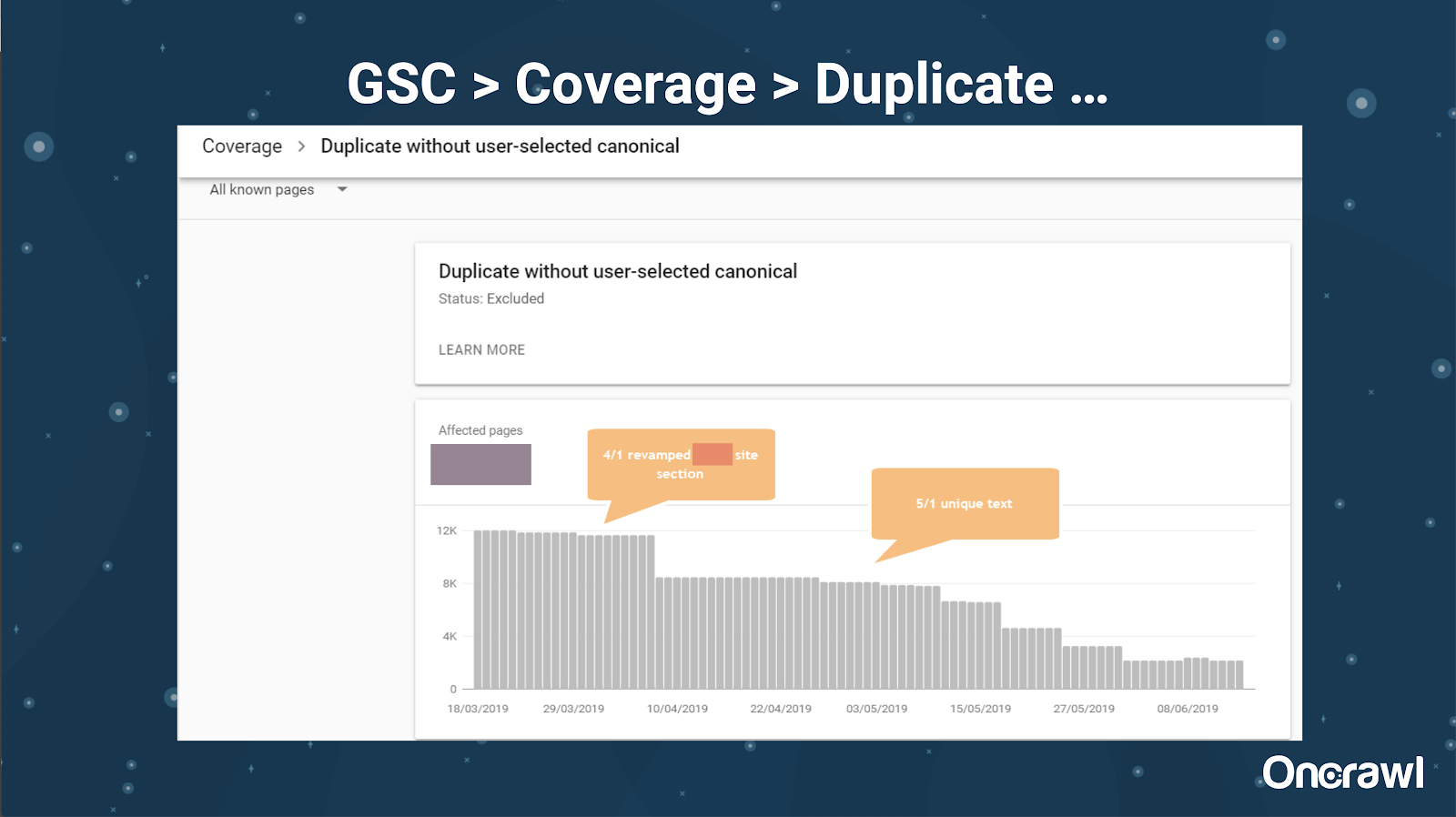
– Ferramentas: ferramentas de plágio
Assim como Omi, Alexis também usa diferentes ferramentas de plágio:
Quetexto
Noplag
PaperRater
Gramaticalmente
CopyScape
Você quer ter certeza de que seu conteúdo não é apenas original, mas também da perspectiva de um bot, que não está sendo percebido como extraído de outra fonte.
Isso também pode ajudá-lo a encontrar segmentos em um artigo que possam ser semelhantes ao conteúdo de outros lugares na Internet.
Alexis adora como temos essas ferramentas que nos permitem ser “empáticos com os robôs dos mecanismos de busca”, já que nenhum de nós é robô. Quando as ferramentas nos dão sinais de que o conteúdo é muito semelhante, mesmo que saibamos que há uma diferença, isso é um bom sinal de que há algo para investigar.

– Ferramentas: ferramentas de densidade de palavras-chave
Dois exemplos de ferramentas de densidade de palavras-chave que Alexis usa são:
TagMultidão
SEObook
Problemas dependentes do tipo de site
A resolução de conteúdo duplicado realmente depende do tipo de conteúdo que você está publicando e do tipo de problema que está enfrentando. Os blogs não enfrentam os mesmos casos de conteúdo duplicado que os sites de comércio eletrônico, por exemplo.
Casos memoráveis
Alexis compartilha casos recentes de clientes em que encontrou problemas memoráveis de conteúdo duplicado.
– Site massivamente grande: resultados após a adição de conteúdo exclusivo
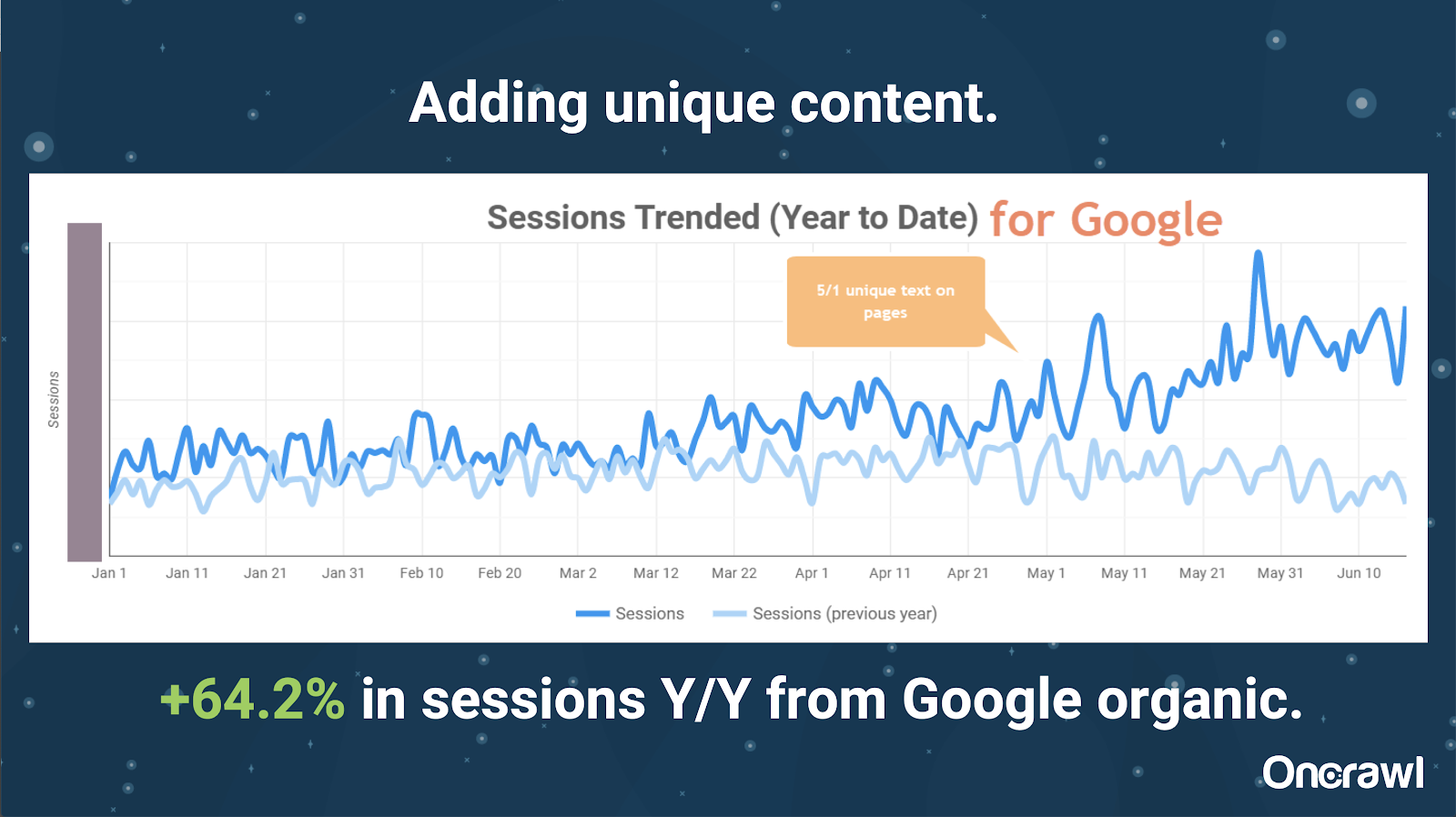
Este site era enormemente grande e enfrenta problemas de orçamento de rastreamento. Possui 86 milhões de páginas que ainda não foram indexadas e apenas cerca de 1% de suas páginas foram indexadas.
Este é um site imobiliário, muito do conteúdo não é particularmente exclusivo e muitas de suas páginas são muito, muito semelhantes. Alexis acabou adicionando conteúdo à página para adicionar informações específicas do local para diferenciar as páginas. Foi surpreendente a rapidez com que isso produziu resultados. (Estes são apenas dados orgânicos do Google.)
Para Alexis, este é um estudo de caso bastante genérico. Por mais que falemos sobre EAT e coisas semelhantes hoje, isso demonstra que assim que os mecanismos de busca veem o conteúdo como único e valioso, isso ainda está sendo recompensado.

Neste site, um problema acidental de tag canônica fez com que cerca de 250 páginas fossem enviadas para o protocolo errado.
Este é um caso em que as tags canônicas indicaram a página principal errada, empurrando as páginas HTTP no lugar da página HTTPS.
Mudanças nos últimos 18 meses
Alexis escreveu um artigo muito completo, Duplicate content and Strategic Resolution, cerca de 18 meses antes deste webinar. O SEO muda rapidamente e você precisa constantemente renovar e reavaliar seu conhecimento.
Para Alexis, a maior parte do que é mencionado no artigo ainda é relevante hoje, com exceção de rel=next/prev. Ela espera que deixe de ser relevante nos próximos cinco a dez anos, no entanto.
Problemas técnicos tratados pelos desenvolvedores: muito manual
Muitos dos problemas relacionados ao conteúdo duplicado que são tratados pelos desenvolvedores são muito manuais. Alexis acredita que eles deveriam ser tratados por CMSs e Adobe. Por exemplo, você não deveria ter que passar manualmente e certificar-se de que todos os canônicos estão definidos e coerentes.
– Oportunidades de automação/notificação
Há muitas oportunidades de automação na área de problemas técnicos com conteúdo duplicado. Para dar um exemplo: devemos ser capazes de detectar imediatamente se algum link está indo para HTTP quando deveria estar indo para HTTPS e corrigi-lo.
– Idade do site e infraestrutura legada como um obstáculo
Alguns sistemas de back-end são muito antigos para suportar certas mudanças e automações. É extremamente difícil migrar um CMS antigo para um novo. Omi dá o exemplo da migração dos sites da Canon para um novo CMS personalizado. Não foi apenas caro, mas levou 12 meses.
Rel anterior/próximo e comunicação do Google
Às vezes, a comunicação do Google é um pouco confusa. Omi cita um exemplo em que, ao aplicar rel=prev/next, seu cliente viu um aumento significativo no desempenho em 2018, apesar do anúncio do Google em 2019 de que essas tags não eram usadas há anos.
– Falta de soluções únicas
A dificuldade com SEO é que o que uma pessoa observa acontecendo em seu site não é necessariamente o mesmo que outro SEO vê em seu próprio site; não existe um SEO de tamanho único.
A capacidade do Google de fazer anúncios pertinentes a todos os SEOs deve ser reconhecida como uma grande façanha, até mesmo algumas de suas declarações são um erro, como no caso de rel=next/prev.
Esperanças para o futuro do gerenciamento de conteúdo duplicado
As esperanças de Alexis para o futuro:
- Menos conteúdo duplicado com base técnica (como os CMSs ficam sabendo).
- Mais automação (testes unitários e testes externos). Por exemplo, ferramentas como o OnCrawl podem rastrear regularmente seu site e notificá-lo assim que perceberem determinados erros.
- Detecte automaticamente páginas e tipos de página de alta similaridade para escritores e gerenciadores de conteúdo. Isso automatizaria algumas das verificações que atualmente são feitas manualmente em ferramentas como o Grammarly: quando alguém tenta publicar, o CMS deve dizer “isso é meio semelhante – você tem certeza de que deseja publicar isso?” Há muito valor em olhar para sites únicos, bem como em comparação entre sites.
- O Google continua aprimorando seus sistemas e detecção existentes.
- Talvez um sistema de alerta para escalar o problema do Google não usar o canônico correto. Seria útil poder alertar o Google sobre o problema e resolvê-lo.
Precisamos de ferramentas melhores, ferramentas internas melhores, mas esperamos que, à medida que o Google desenvolva seus sistemas, eles adicionem elementos para nos ajudar um pouco.
Os truques técnicos favoritos de Alexis
Alexis tem vários truques técnicos favoritos:
- Instância de computador remoto do EC2. Esta é uma ótima maneira de acessar um computador real para rastreamentos muito grandes ou qualquer coisa que exija muito poder de computação. É extremamente rápido depois de configurá-lo. Apenas certifique-se de encerrá-lo quando terminar, pois isso custa dinheiro.
- Verifique a primeira ferramenta de teste móvel. O Google mencionou que esta é a imagem mais precisa do que eles estão vendo. Ele olha para o DOM.
- Mude o agente do usuário para o Googlebot. Isso lhe dará uma ideia do que os Googlebots estão realmente vendo.
- Usando a ferramenta robots.txt do TechnicalSEO.com. Esta é uma das ferramentas de Merkle, mas Alexis realmente adora porque robots.txt pode ser muito confuso às vezes.
- Use um analisador de log.
- Feito com o verificador htaccess do Love.
- Usar o Google Data Studio para gerar relatórios sobre alterações (sincronizar Planilhas com atualizações, filtrar cada página por atualizações relevantes).
Dificuldades técnicas de SEO: robots.txt
Robots.txt é realmente confuso.
É um arquivo arcaico que parece ser capaz de suportar RegEx, mas não suporta.
Ele tem regras de precedência diferentes para regras de não permissão e permissão, o que pode ficar confuso.
Bots diferentes podem ignorar coisas diferentes, mesmo que não devam.
Suas suposições sobre o que é certo nem sempre estão certas.

Perguntas e respostas
– HSTS: é necessário o protocolo split?
Você precisa ter todos os HTTPS para conteúdo duplicado se tiver HSTS.
– O conteúdo traduzido é duplicado?
Muitas vezes, quando você está usando hreflang, você o está usando para desambiguar entre versões localizadas no mesmo idioma, como uma página em inglês dos EUA e da Irlanda. Alexis não consideraria esse conteúdo duplicado, mas ela definitivamente recomendaria garantir que você tenha suas tags hreflang configuradas corretamente para indicar que esta é a mesma experiência, otimizada para diferentes públicos.
– Você pode usar tags canônicas em vez de redirecionamentos 301 para uma migração HTTP/HTTPS?
Seria útil verificar o que realmente está acontecendo nos SERPs. O instinto de Alexis é dizer que tudo bem, mas depende de como o Google está realmente se comportando. Idealmente, se estas forem exatamente a mesma página, você desejará usar um 301, mas ela já viu as tags canônicas funcionarem no passado para esse tipo de migração. Na verdade, ela até viu isso acontecer acidentalmente.
Na experiência de Omi, ele sugere fortemente o uso de 301s para evitar problemas: se você estiver migrando o site, também poderá migrá-lo corretamente para evitar erros atuais e futuros.
– Efeito de títulos de página duplicados
Digamos que você tenha um título muito semelhante para locais diferentes, mas o conteúdo é muito diferente. Embora isso não seja conteúdo duplicado para Alexis, ela vê os mecanismos de pesquisa tratando isso como uma coisa do tipo “geral”, e os títulos são algo que pode ser usado para identificar áreas com possíveis problemas.
É aqui que você pode usar uma pesquisa [site: + intitle: ].
No entanto, só porque você tem a mesma tag de título, isso não causará um problema de conteúdo duplicado.
Você ainda deve buscar títulos exclusivos e meta descrições, mesmo em páginas paginadas ou outras muito semelhantes. Isso não se deve ao conteúdo duplicado, mas sim à maneira de querer otimizar a forma como você apresenta suas páginas nas SERPs.
Melhor dica
“Conteúdo duplicado é um desafio técnico e de marketing de conteúdo.”
SEO em órbita foi para o espaço
Se você perdeu nossa viagem ao espaço no dia 27 de junho, assista aqui e descubra todas as dicas que enviamos ao espaço.