
Usando Python e Sitemaps para auditar estratégias de conteúdo
Publicados: 2020-10-08O interesse no que pode ser feito em prol do SEO com as Bibliotecas Python não é mais segredo. No entanto, a maioria das pessoas com pouca experiência em programação tem dificuldades em importar e usar um grande número de bibliotecas ou enviar resultados além do que qualquer rastreador comum ou ferramenta de SEO pode fazer.
É por isso que uma biblioteca Python criada especificamente para SEO, SEM, SMO, verificação de SERP e análise de conteúdo é útil para todos.
Neste artigo, veremos algumas das coisas que podem ser feitas com a Biblioteca Python da Advertools para SEO, criada e desenvolvida por Elias Dabbas, e para a qual vejo um grande potencial em SEO, PPC e recursos de codificação em muito pouco tempo. Além disso, usaremos scripts Python personalizados junto com outras bibliotecas Python de maneira educacional e adaptativa.
Vamos examinar o que pode ser aprendido para SEO a partir de um sitemap graças à função sitemap_to_df de Elias Dabbas, que ajuda no download e análise de sitemaps XML (Um sitemap é um documento em formato XML usado para relatar URLs rastreáveis e indexáveis para mecanismos de pesquisa.)
Este artigo mostrará como você pode escrever códigos Python personalizados para analisar diferentes sites de acordo com sua estrutura diferente, como interpretar dados em termos de SEO e como pensar como um mecanismo de pesquisa quando se trata de perfis de conteúdo, URLs e estruturas de sites .
Analisando a escala e a estratégia de conteúdo de um site com base em seu mapa do site
Um mapa do site é um componente de um site que pode capturar muitos tipos diferentes de dados, como a frequência com que um site publica conteúdo, categorias de conteúdo, datas de publicação, informações do autor, assunto do conteúdo…
Em condições normais, você pode raspar um mapa do site com scrapy, convertê-lo em um DataFrame com Pandas e interpretá-lo com muitas bibliotecas auxiliares diferentes, se desejar.
Mas neste artigo, usaremos apenas Advertools e alguns métodos e atributos da biblioteca Pandas. Algumas bibliotecas serão ativadas para visualizar os dados que adquirimos.
Vamos mergulhar direto e selecionar um site para usar seu mapa do site para concluir alguns insights importantes de SEO.
Extraindo e criando quadros de dados de Sitemaps com Advertools
No Advertools, você pode descobrir, navegar e combinar todos os mapas do site de um site com apenas uma linha de código.
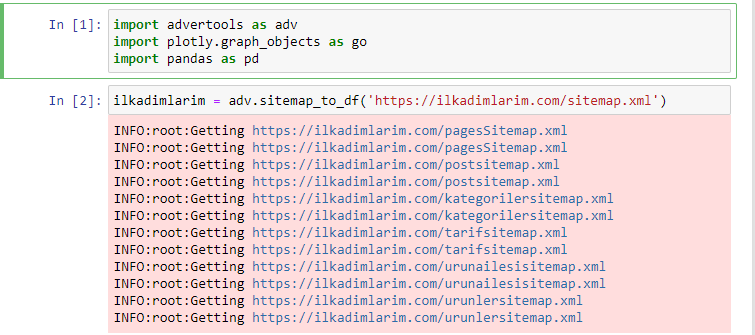
Adoro usar o Jupyter Notebook em vez de um editor de código ou IDE comum.
Na primeira célula importamos Pandas e Advertools para coleta e organização de dados e Plotly.graph_objects para visualização de dados.
O comando adv.sitemap_to_df('sitemap address') simplesmente coleta todos os sitemaps e os unifica como um DataFrame.
Se você fizer o mesmo usando Pandas e Advertools, poderá descobrir qual URL está disponível em qual mapa do site.
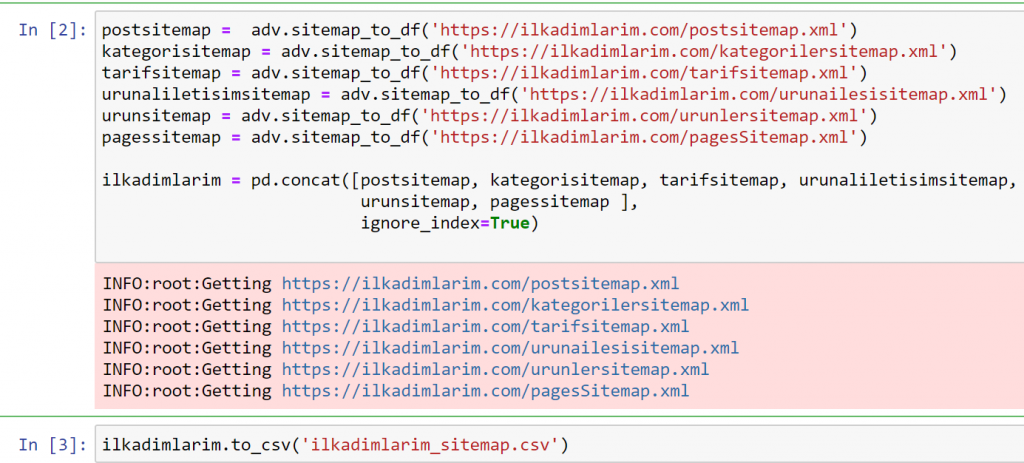
No exemplo acima, extraímos os mesmos sitemaps separadamente e os combinamos com o comando pd.concat e transferimos o resultado para o CSV. O exemplo anterior usou o arquivo de índice do sitemap, nesse caso a função vai para recuperar todos os outros sitemaps. Portanto, você tem a opção de selecionar mapas de site específicos, como fizemos aqui, se estiver interessado em uma seção específica do site.
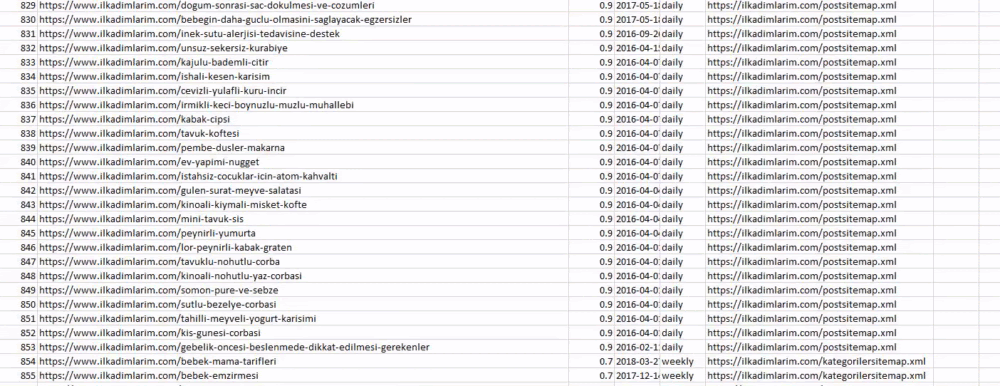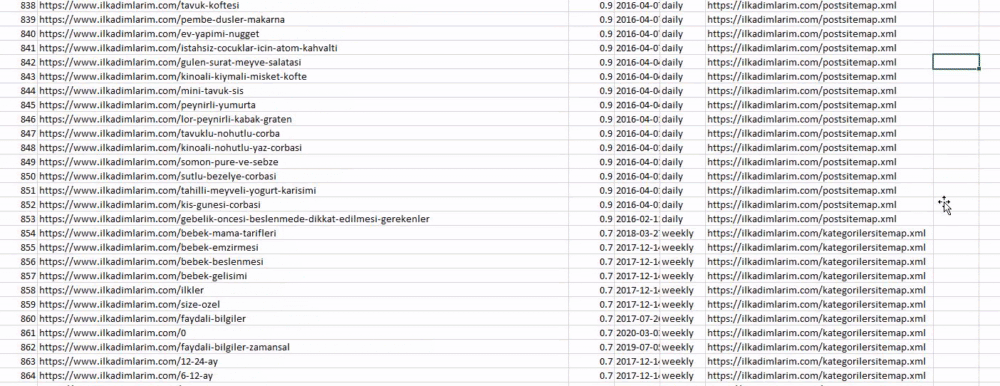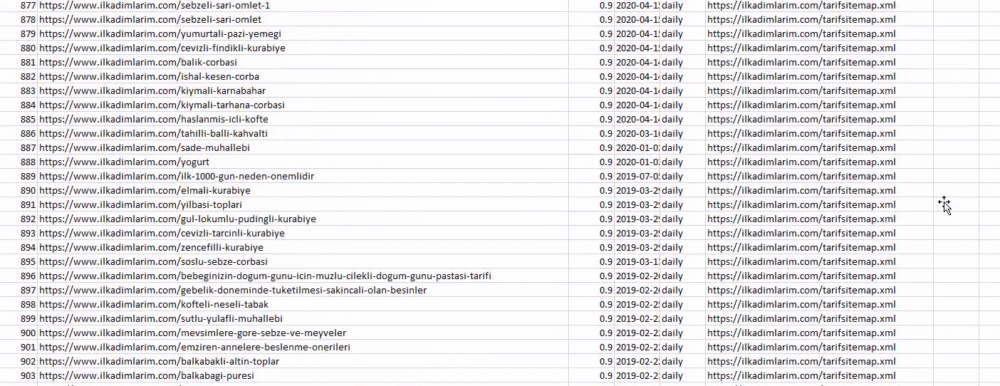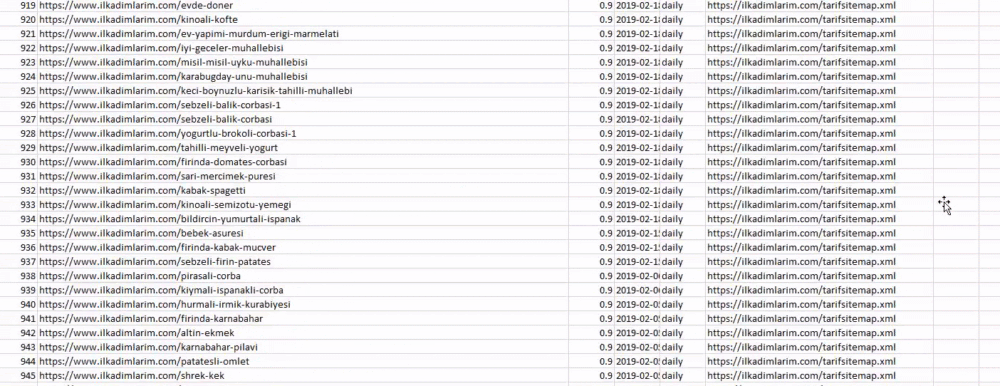
Você pode ver uma coluna com diferentes nomes de sitemaps acima. ignore_index=True seção é para a ordenação de números de índice de diferentes DataFrames, se você tiver mesclado vários.
Dados de rastreamento³
 Saber mais
Saber maisLimpando e preparando o quadro de dados do Sitemap para análise de conteúdo com Python
Para entender o perfil de conteúdo de um site por meio de um sitemap, precisamos prepará-lo para revisar o DataFrame obtido com o Advertools.
Usaremos alguns comandos básicos da biblioteca Pandas para moldar nossos dados:
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(columns = 'Sem nome: 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
“Ilkadimlarim” significa “meus primeiros passos” em turco e, como você pode imaginar, é um site para bebês, gravidez e maternidade.
Realizamos três operações com essas linhas.
- Sem nome: Removemos uma coluna vazia chamada 0 do DataFrame. Além disso, se você usar 'index = False “ com a função pd.to_csv() , você não verá esta coluna 'Unnamed 0' no início.
- Convertemos os dados na coluna Última modificação para Data e hora.
- Trouxemos a coluna “lastmod” para a posição do índice.
Abaixo você pode ver a versão final do DataFrame.
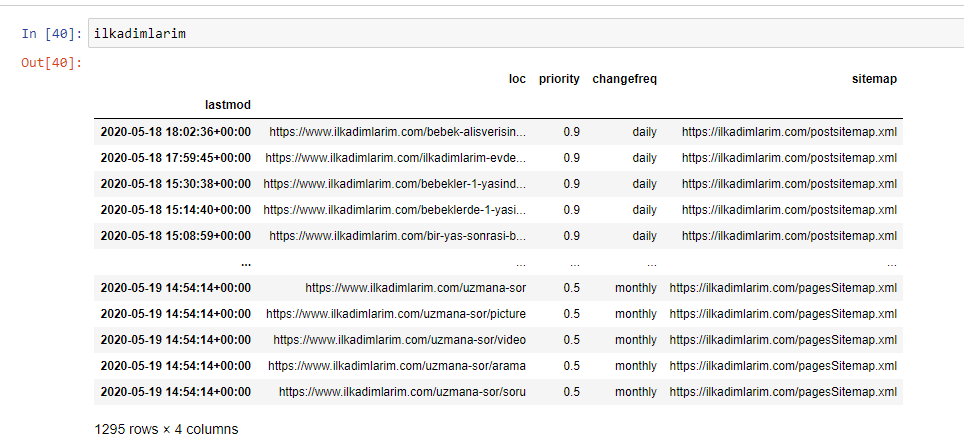
Sabemos que o Google não usa informações de prioridade e frequência de alteração de sitemaps. Eles chamam isso de “um saco de ruído”. Mas se você der importância ao desempenho do seu site para outros mecanismos de pesquisa, pode ser útil examiná-los também. Pessoalmente, não me importo muito com esses dados, mas ainda não preciso removê-los do DataFrame.
Precisamos de mais uma linha de código para categorizar os mapas do site em outra coluna.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
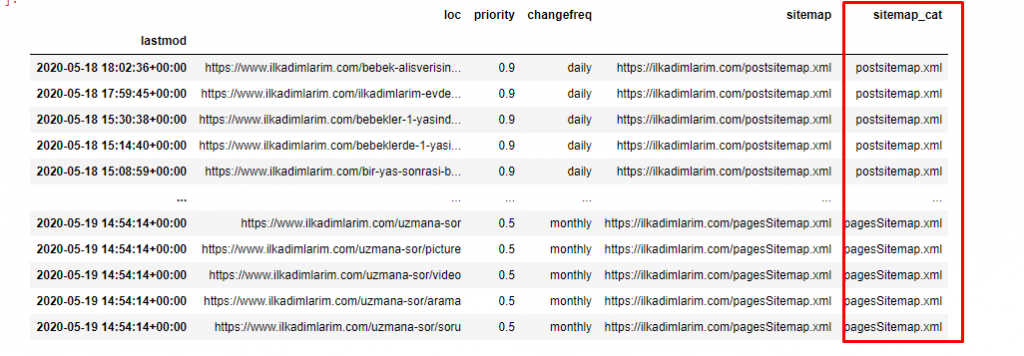
No Pandas, você pode adicionar novas colunas ou linhas a um DataFrame ou pode atualizá-las facilmente. Criamos uma nova coluna com o trecho de código DataFrame['new_columns'] . DataFrame['column_name'].str nos permite realizar diferentes operações alterando o tipo de dados em uma coluna. Dividimos os dados da string na coluna relacionada a .split ('/') pelo caractere / e colocamos em uma lista. Com .str [number] , criamos o conteúdo da nova coluna selecionando um determinado elemento nessa lista.
Análise do perfil de conteúdo de acordo com a contagem e os tipos de sitemaps
Depois de colocar os sitemaps em uma coluna diferente de acordo com seus tipos, podemos verificar qual % do conteúdo está em cada sitemap. Assim, também podemos fazer uma inferência sobre qual parte do site é mais importante.
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name'] está selecionando a coluna que queremos transformar em um processo.
- value_counts() conta a frequência de valores na coluna.
- normalize=True leva a proporção de valores em decimal.
- Facilitamos a leitura tornando os números decimais maiores com *100.
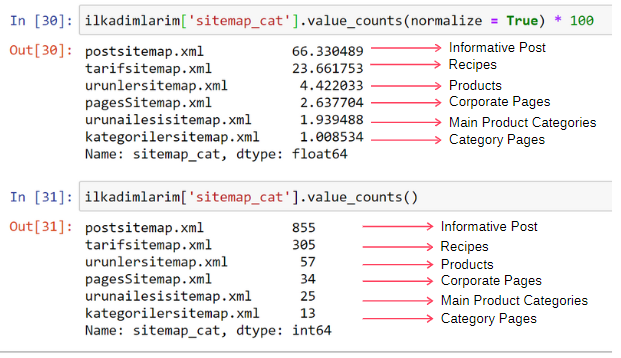
Vemos que 65% do conteúdo está no Sitemap de postagem e 23% no Sitemap de receita. O Sitemap do produto tem apenas 2% do conteúdo.
Isso mostra que temos um site que precisa criar conteúdo informativo para um público amplo para comercializar seus próprios produtos. Vamos verificar se nossa tese está correta.
Antes de prosseguir, precisamos alterar o nome da coluna ilkadimlarim['sitemap_cat'] para 'URL_Count' com o código abaixo:
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- A função rename() é útil para modificar o nome de suas colunas ou índices para conectar os dados e seu significado em um nível mais profundo.
- Alteramos o nome da coluna para ser permanente graças ao atributo 'inplace=True' .
- Você também pode alterar os estilos de letras de suas colunas e índices com ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) . Isso escreve apenas as primeiras letras maiúsculas de cada coluna em Ilkadimlarim.

Agora, podemos prosseguir.
Para ver essas informações em um único frame, você pode usar o código abaixo:
(ilkadimlarim['sitemap_cat']
.value_counts()
.enquadrar()
.assign(percentage=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', percent='{:.1%}'))))
- to_frame() é usado para enquadrar valores medidos por value_counts() na coluna selecionada.
- assign() é usado para adicionar certos valores ao quadro.
- lambda refere-se a funções anônimas em Python.
- Aqui, a função Lambda e os tipos de mapa do site são divididos pelo número total do mapa do site pelo método Pandas div() .
- style() determina como os valores finais especificados são escritos.
- Aqui, definimos quantos dígitos são escritos após o ponto com o método format() .
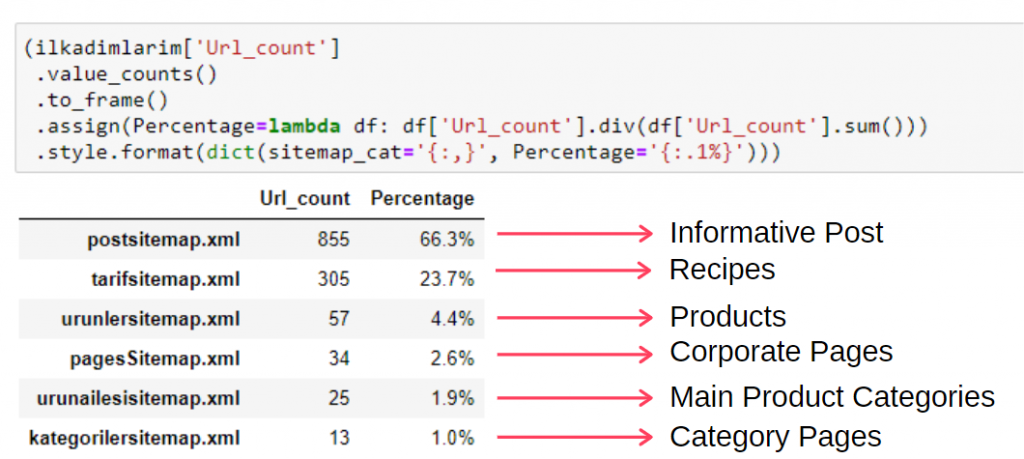
Assim, vemos a importância do marketing de conteúdo para este site. Também podemos verificar as tendências de publicação de artigos por ano com duas linhas únicas de código para examinar sua situação mais profundamente.
Examinando e visualizando tendências de publicação de conteúdo por ano via Sitemaps e Python
Fizemos a correspondência de conteúdo e intenção do site examinado de acordo com as categorias do mapa do site, mas ainda não fizemos uma classificação com base no tempo. Usaremos o método resample() para fazer isso.
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample é um método na biblioteca Pandas. resample('A') verifica a série de dados para um DataFrame anual. Por semanas, você pode usar 'W', por meses, você pode usar 'M'.
Loc aqui simboliza o índice; count significa que você deseja contar a soma dos exemplos de dados.
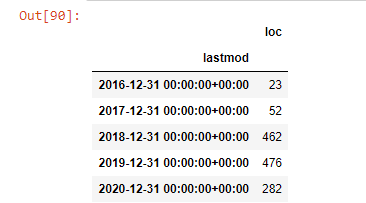
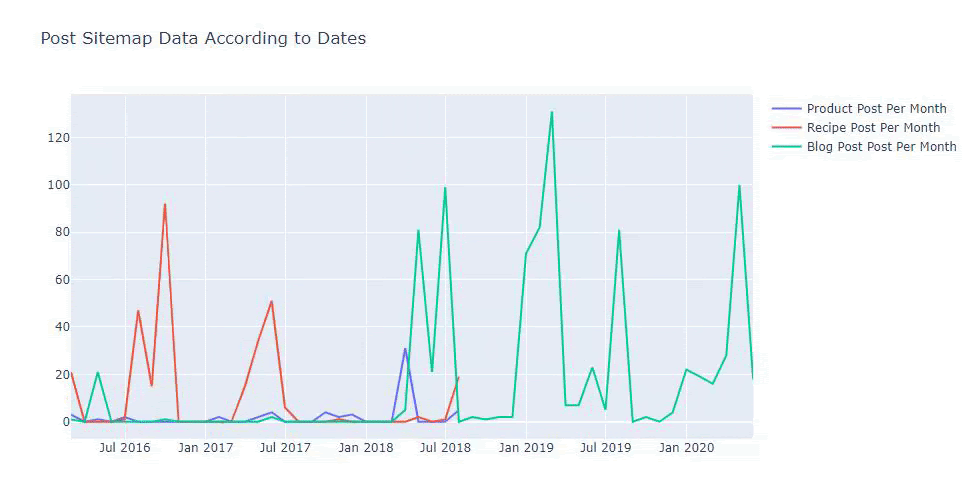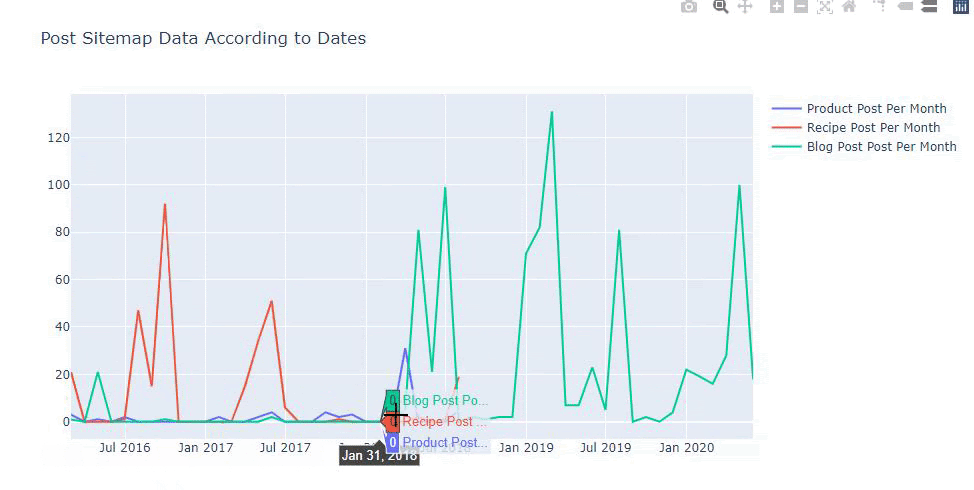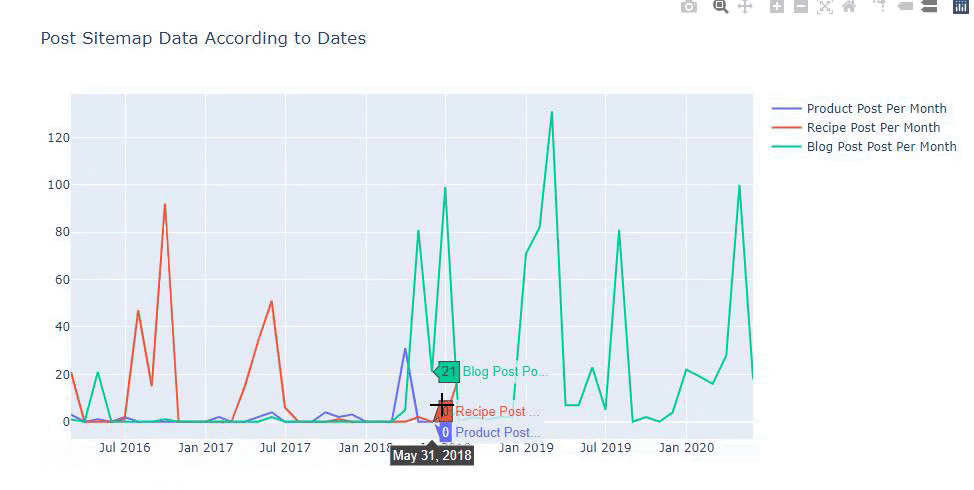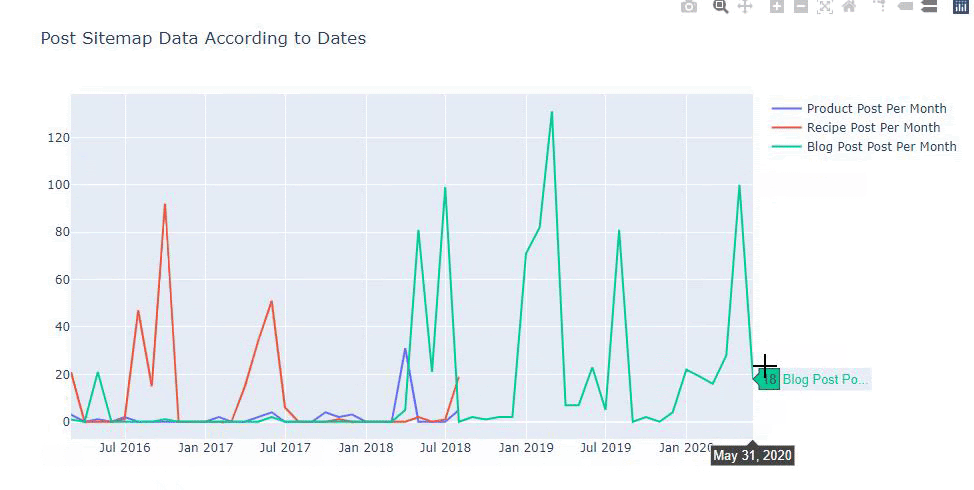
Vemos que eles começaram a publicar artigos em 2016, mas sua principal tendência de publicação aumentou após 2017. Também podemos colocar isso em um gráfico com a ajuda de Plotly Graph Objects.
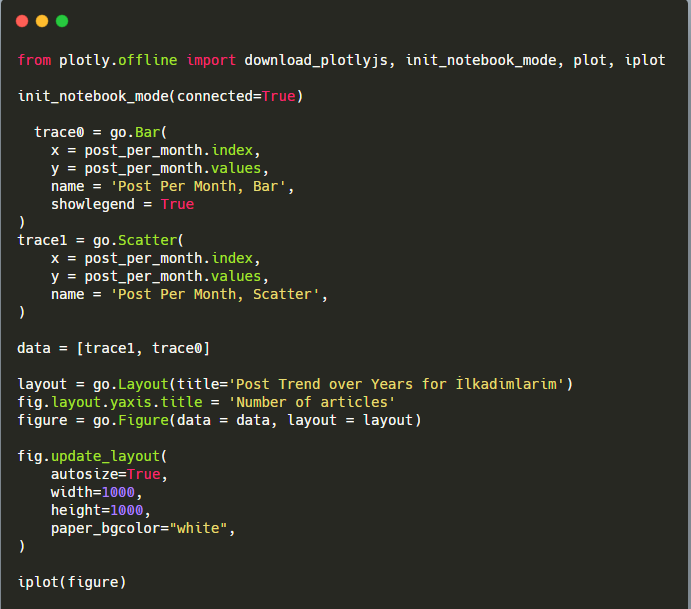
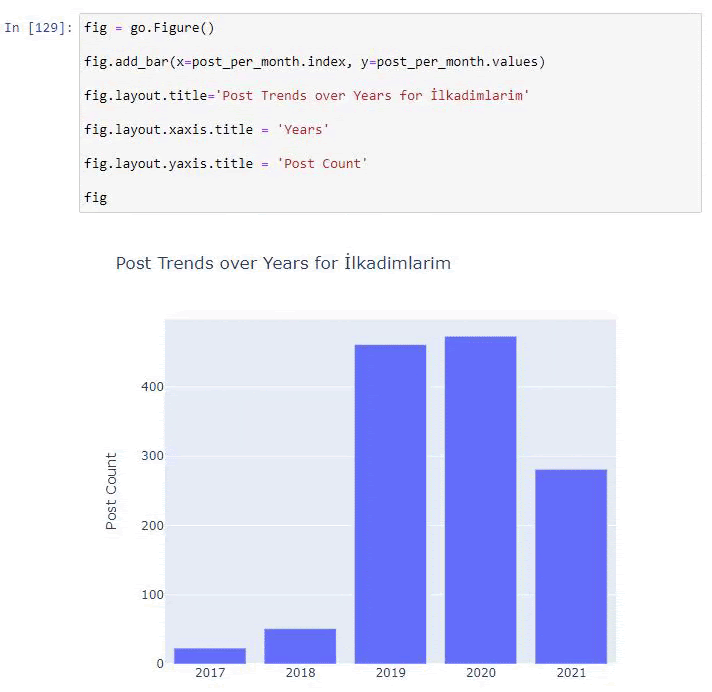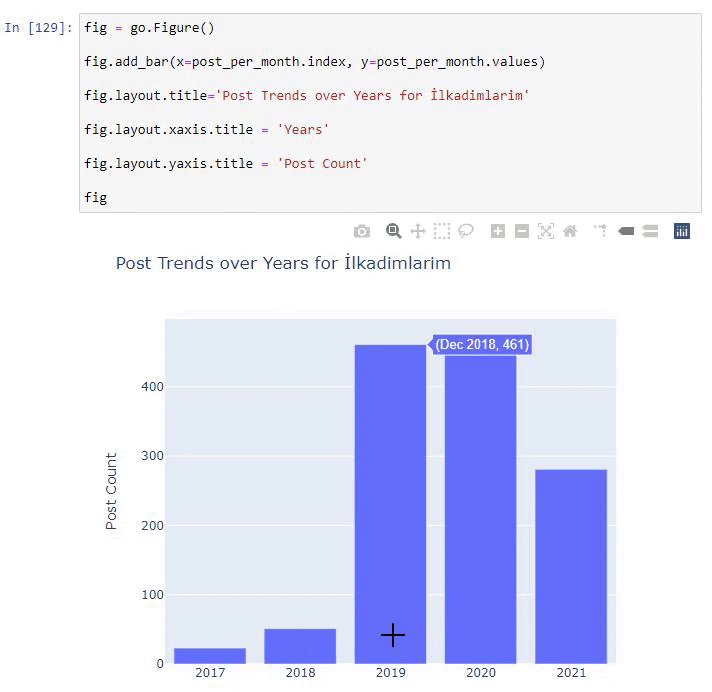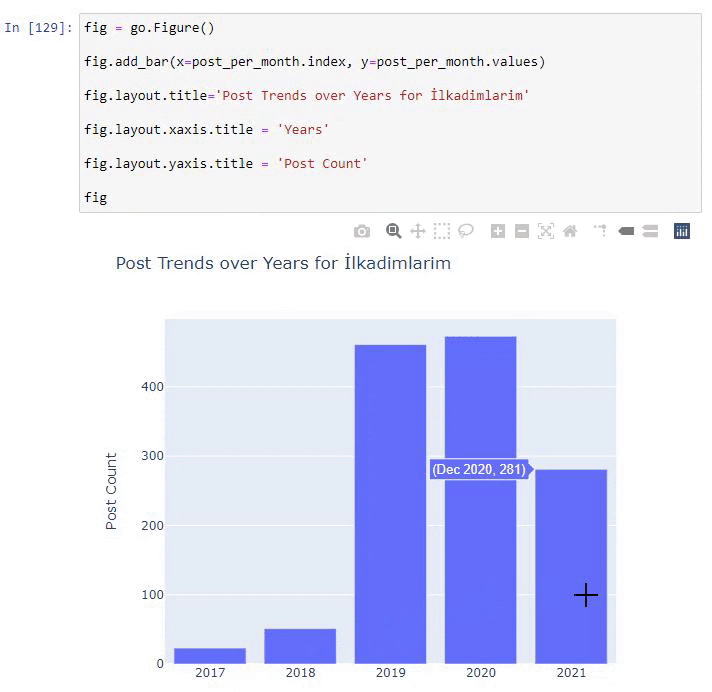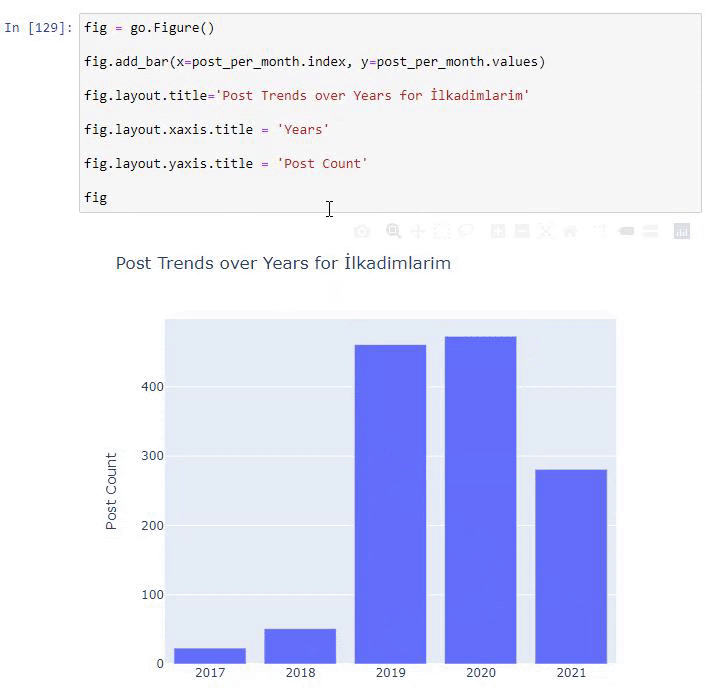
Explicação deste trecho de código Plotly Bar Plot:
- fig = go.Figure() é para criar uma figura.
- fig.add_bar() é para adicionar um gráfico de barras na figura. Também determinamos quais eixos X e Y estarão dentro dos parênteses.
- Fig.layout é para criar um título geral para a figura e eixos.
- Na última linha estamos chamando o gráfico que criamos com o comando fig que é igual a go.Figure()
Abaixo, você encontrará os mesmos dados por mês, com gráfico de dispersão e gráfico de barras:
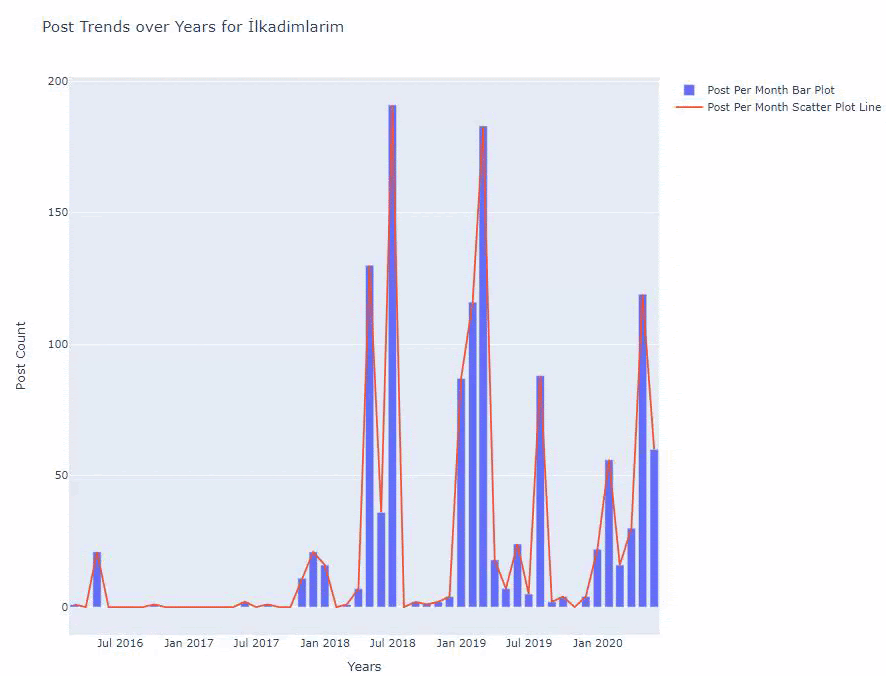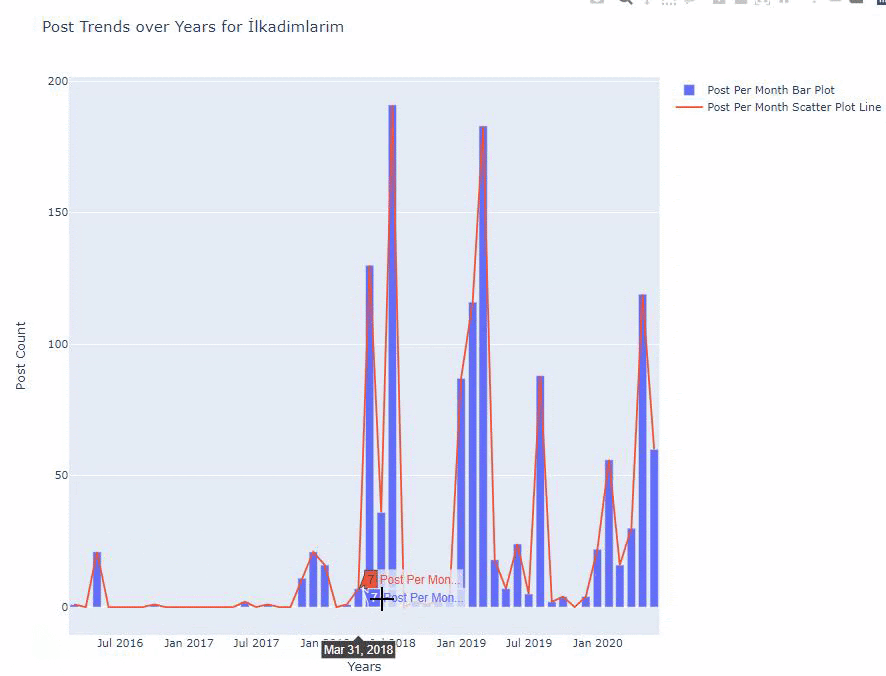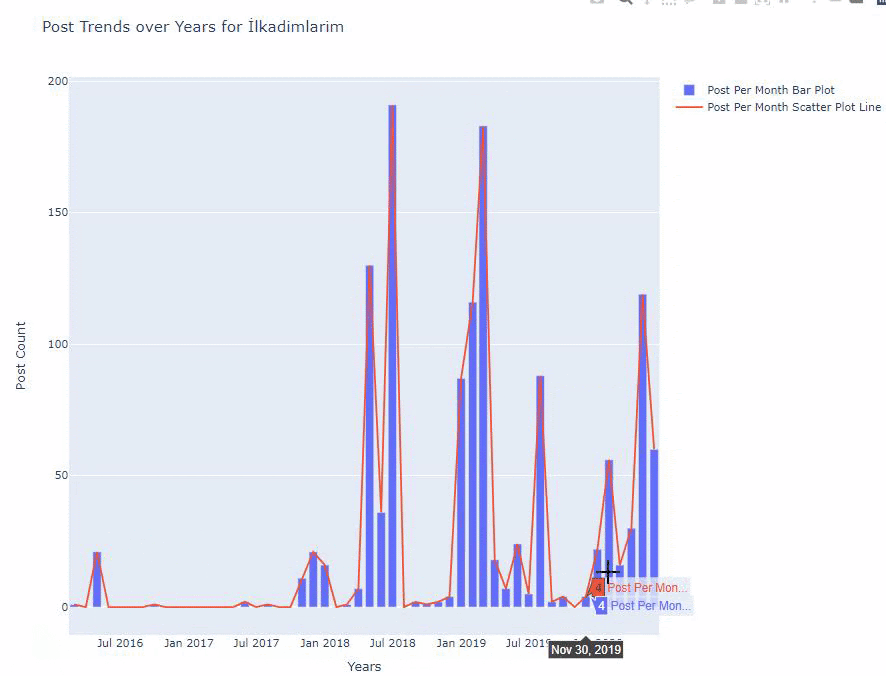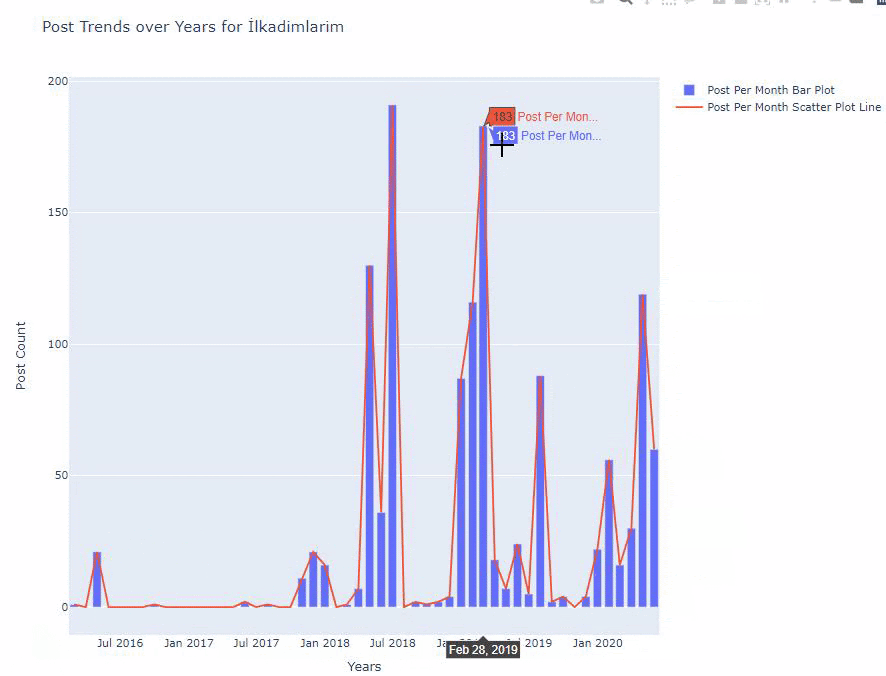
Aqui estão os códigos para criar esta figura:
Adicionamos um segundo gráfico com fig.add_scatter() e também alteramos os nomes usando o atributo name. fig.update_layout() é para alterar o tamanho e a cor de fundo do gráfico.
Você também pode alterar o modo de foco, a distância entre as barras e muito mais. Acho que é suficiente apenas compartilhar os códigos, pois explicar cada código aqui separadamente pode nos afastar do assunto principal.
Também podemos comparar as tendências de publicação de conteúdo dos concorrentes de acordo com categorias como abaixo:
Este gráfico foi criado com o segundo método, como você pode ver, não há diferença, mas um deles é bastante simples.
Para traçar a frequência e a tendência de publicação de conteúdo de três sitemaps separados, devemos colocar o sitemap, que tem o intervalo mais longo, no eixo X. Assim, podemos comparar a frequência com que o site que estamos examinando publica cada tipo diferente de conteúdo para diferentes intenções de pesquisa.
Ao examinar os códigos relevantes abaixo, você verá que não é muito diferente do acima.
Para criar um gráfico de dispersão com vários eixos Y, você pode usar o código abaixo.
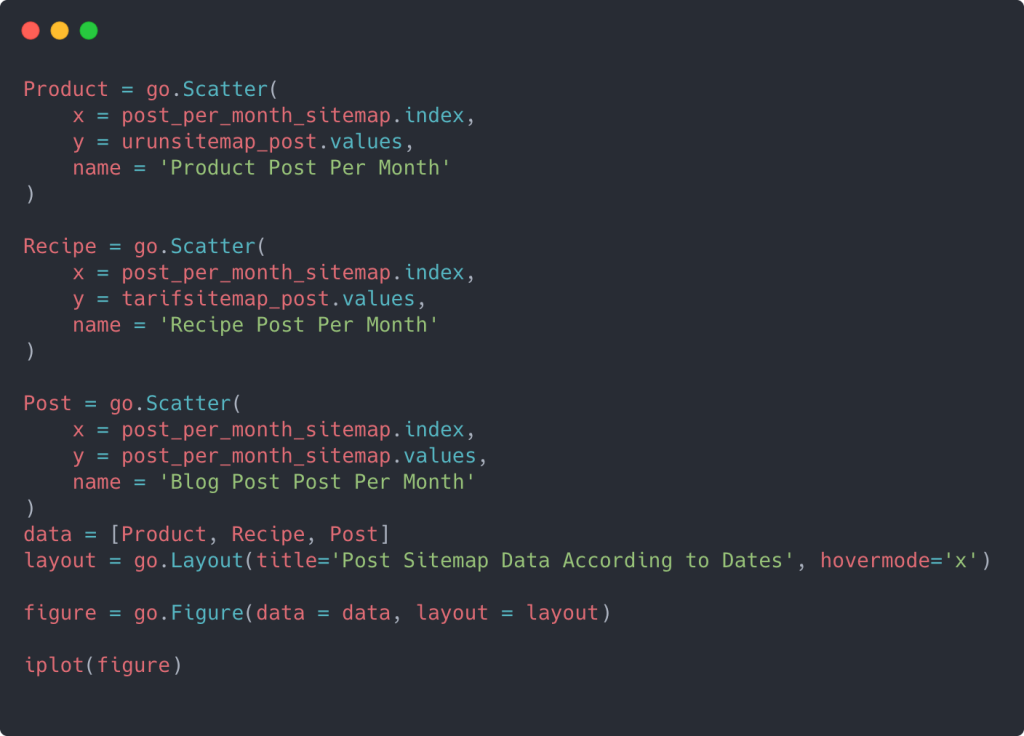
Existem outros métodos, como unificar diferentes sitemaps e usar um loop for para as colunas usarem vários eixos Y no gráfico de dispersão, mas para um site tão pequeno não precisamos disso. Na maioria das vezes, seria mais lógico usar esse método em sites com centenas de sitemaps.
Além disso, como o site é pequeno, o gráfico pode parecer superficial, mas, como você verá mais adiante no artigo em um site com milhões de URLs, esses gráficos são uma ótima maneira de comparar sites diferentes, bem como comparar diferentes categorias do mesmo site.
Examinando e visualizando categorias de conteúdo, intenção e tendências de publicação com Sitemaps e Python
Nesta seção, verificaremos se eles escreveram um grande número de conteúdo em um domínio de conhecimento específico para comercializar um pequeno número de produtos, o que dissemos no início do artigo. Graças a isso, podemos ver se eles têm uma parceria de conteúdo com outras marcas ou não.
Para mostrar o que mais pode ser encontrado nos mapas do site, continuaremos cavando um pouco mais. Também podemos obter algumas informações da parte 'loc' do mapa do site, como outras.
Não há divisão de categoria nas URLs de Ilkadimlarim. Se um site tiver uma divisão de categorias em seus URLs, podemos aprender muito mais sobre distribuição de conteúdo. Caso contrário, podemos acessar os mesmos dados escrevendo código adicional, mas apenas com menos certeza.
Nesse ponto, você pode imaginar o quanto os detalhamentos de URL são menos dispendiosos para os mecanismos de pesquisa que rastreiam bilhões de sites para entender seu site.
a = ilkadimlarim['loc'].str.contains(“bebek|hamile|haftalik”)
Bebe: bebê
Hamile: grávida
Haftalik: semanal ou “semanas de gravidez”
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
O método str() aqui novamente nos permite definir a coluna onde selecionamos certas operações.
Com o método contains() , determinamos os dados para verificar se estão incluídos nos dados convertidos em uma string.
Aqui, “|” entre os termos significa "ou" .
Em seguida, atribuímos os dados filtrados a uma variável e usamos o método resample() que usamos anteriormente.
O método count , por outro lado, mede quais dados são usados e quantas vezes.
O resultado obtido com count() é novamente incluído com to_frame() .
Além disso, str.contains() aceita valores Regex por padrão, o que significa que você pode criar condições de filtragem mais complicadas com menos código.
Em outras palavras, neste momento, atribuímos as URLs contendo as palavras “baby”, “weekly”, “pregnant” a uma variável em ilkadimlarim , e então colocamos a data de publicação das URLs nas condições apropriadas para este filtro que criado em um quadro.
Em seguida, fazemos o mesmo para URLs contendo a palavra 'aptamil'. Aptamil é o nome de um produto de nutrição infantil introduzido pela Ilkadimlarim. Portanto, também podemos atentar para a densidade de transmissão de conteúdos informativos e comerciais.
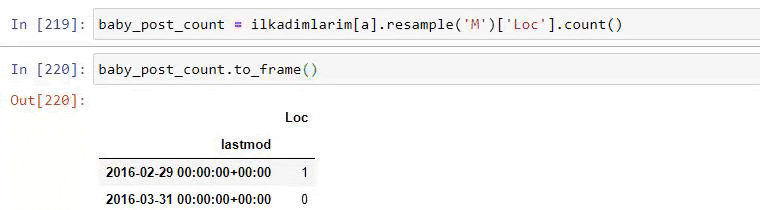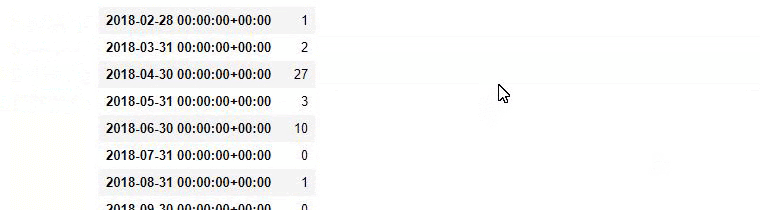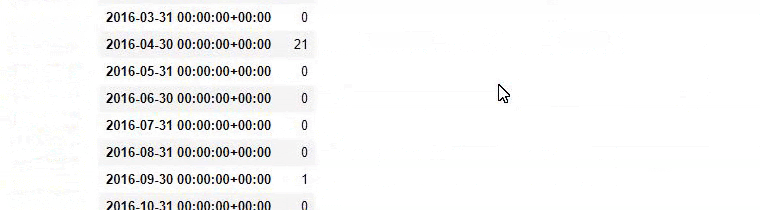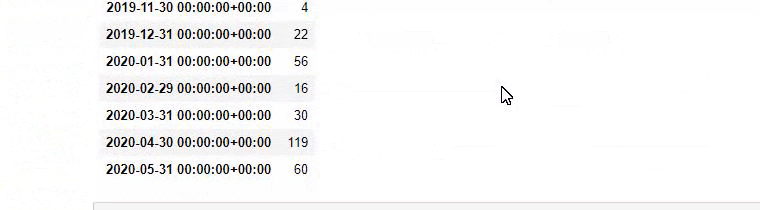
E você pode ver os dois diferentes grupos de conteúdo publicando agendas ao longo dos anos para diferentes intenções de pesquisa com mais certeza e informações precisas de URLs.
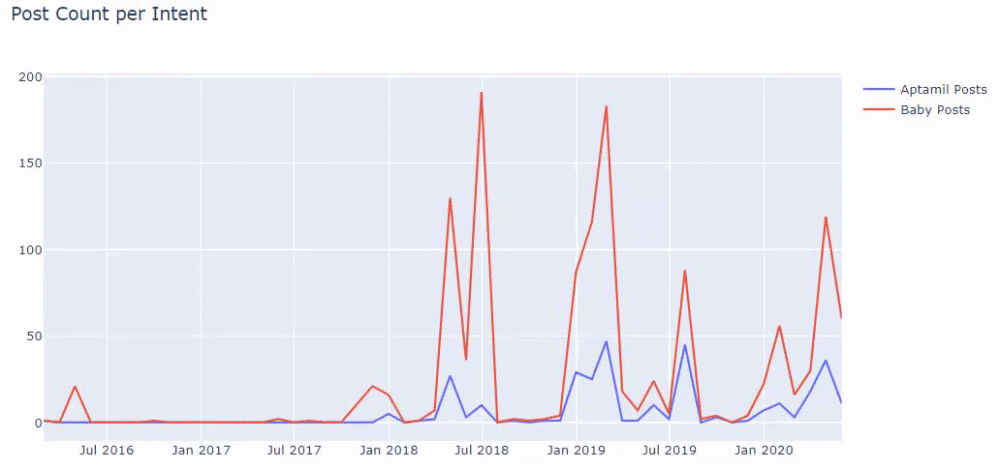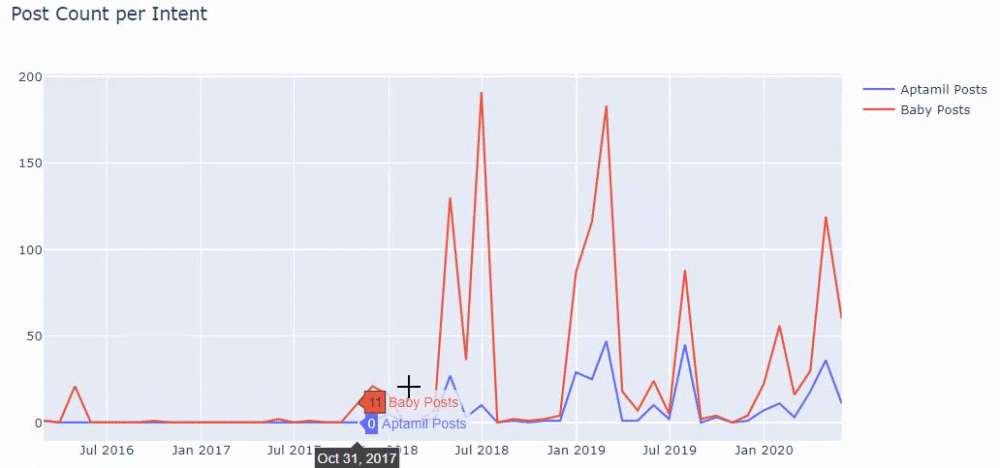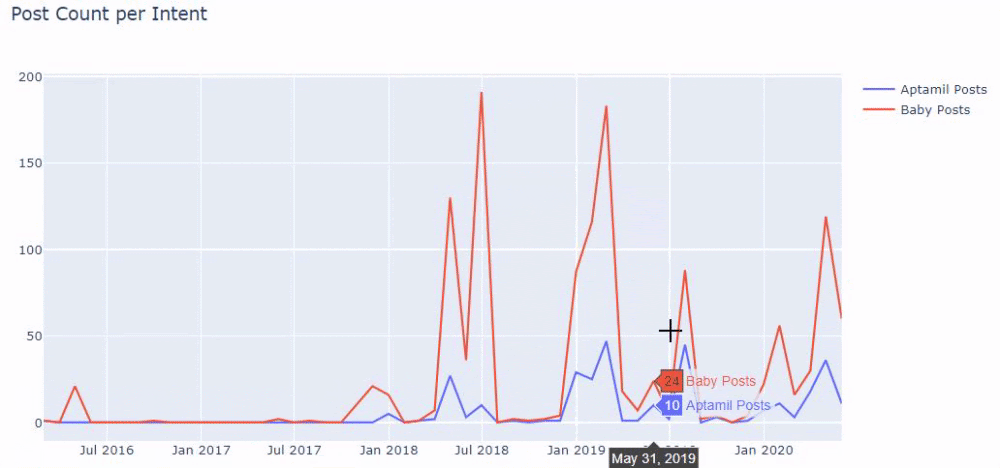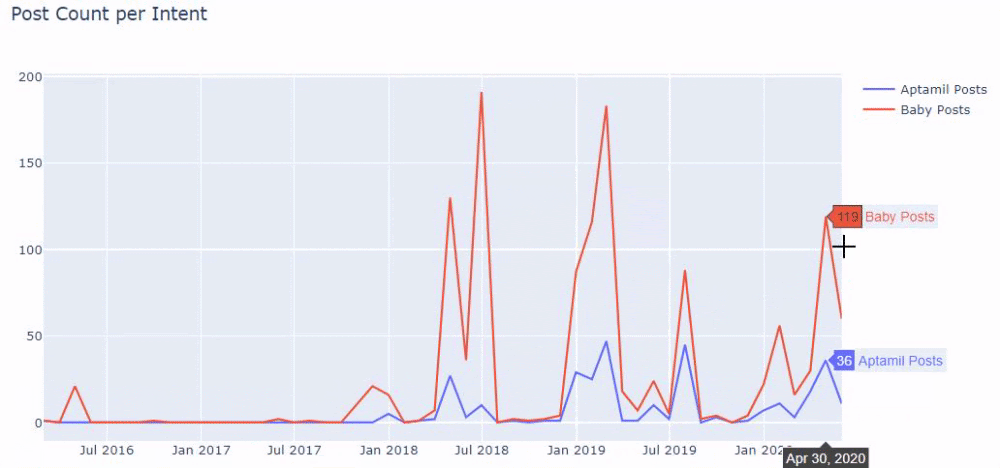
O código para produzir este gráfico não foi compartilhado, pois é o mesmo usado para o gráfico anterior
Com a ajuda de operadores de busca no Google, recebo 38 resultados quando quero as páginas onde a palavra Aptamil é usada no texto âncora em Ilkadimlarim.com. Um número importante dessas páginas são informativos e vinculam conteúdo comercial.
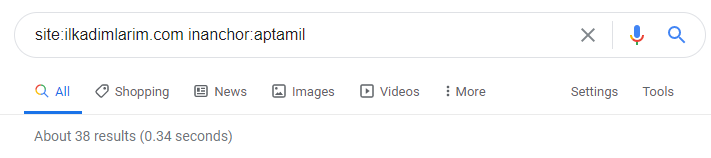
Nossa tese foi comprovada.
“Meus Primeiros Passos” utiliza centenas de conteúdos informativos sobre maternidade, cuidados com o bebê e gravidez para atingir seu público-alvo. “Ilkadimlarim” vincula as páginas que contêm produtos Aptamil a partir deste conteúdo e direciona os usuários para lá.
Criação de perfil de conteúdo comparativo e análise de estratégia de conteúdo via Sitemaps com Python
Agora, se você quiser, vamos fazer o mesmo para uma empresa do mesmo setor e fazer uma comparação para entender o aspecto geral desse setor e as diferenças de estratégia entre essas duas marcas.

Como segundo exemplo, escolhi Prima.com.tr, que é Pampers, mas usa a marca Prima na Turquia. Como o Prima tem um único sitemap, não poderemos classificar por sitemaps, mas pelo menos eles têm quebras diferentes em seus URLs. Então temos muita sorte: teremos que escrever menos código.
Imagine o quanto mais caros são os algoritmos que o Google tem que executar para você quando você cria um site difícil de entender! Isso pode ajudar a tornar o cálculo de custo de rastreamento mais tangível em sua mente, mesmo apenas em relação à estrutura de URL.
Para não aumentar ainda mais o volume do artigo, não colocamos os códigos dos processos semelhantes aos que já fizemos.
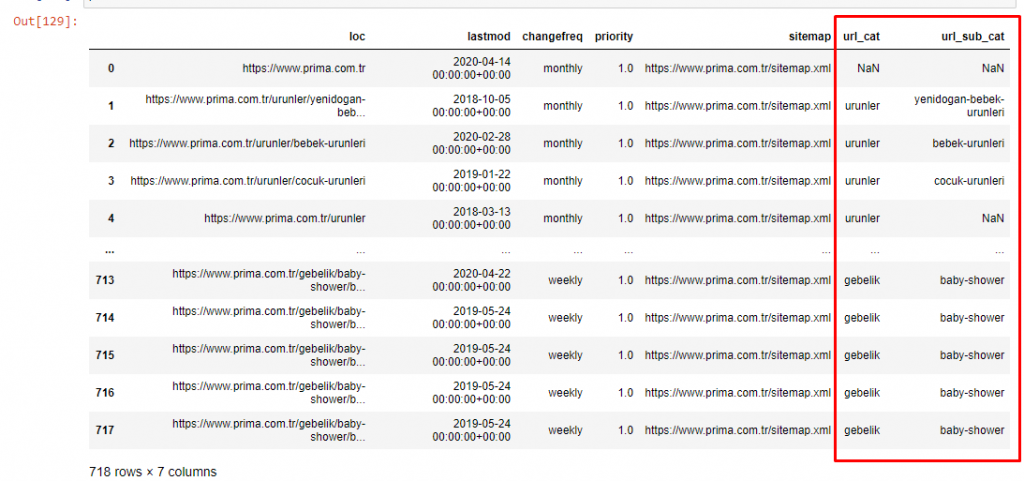
Agora, podemos examinar a distribuição da categoria de conteúdo por categorias de URL e subcategorias de URL. Vemos que eles têm uma quantidade excessiva de páginas da web corporativas. Essas páginas da web corporativas são colocadas na seção “prima-hakkinda” (“Sobre a Prima”). Mas quando eu os verifico com o Python, vejo que eles unificaram seus produtos e páginas da web corporativas em uma categoria. Você pode ver sua distribuição de conteúdo abaixo:

Podemos fazer o mesmo para as seguintes subcategorias.
É interessante notar que Prima usa “gebelik” (gravidez em turco) que é uma variante de “hamilelik” (gravidez em árabe), e ambos significam período de gravidez.

Agora vemos uma categorização mais profunda em seu conteúdo. 9,2% do conteúdo é sobre gravidez saudável, 7,3% é sobre o processo de crescimento dos bebês, 8,3% do conteúdo é sobre atividades que podem ser feitas com bebês, 0,7% é sobre a ordem de sono dos bebês. Há ainda tópicos como dentição com 3,9%, segurança do bebê com 1,9% e revelação de uma gravidez para a família com 1,4%. Como você pode ver, você pode conhecer um setor apenas com URLs e sua porcentagem de distribuição.
Esta não é a categorização perfeita, mas pelo menos podemos ver a mentalidade e as tendências de marketing de conteúdo de nossos concorrentes e o conteúdo de seu site de acordo com as categorias. Agora vamos verificar a frequência de publicação de conteúdo por mês.
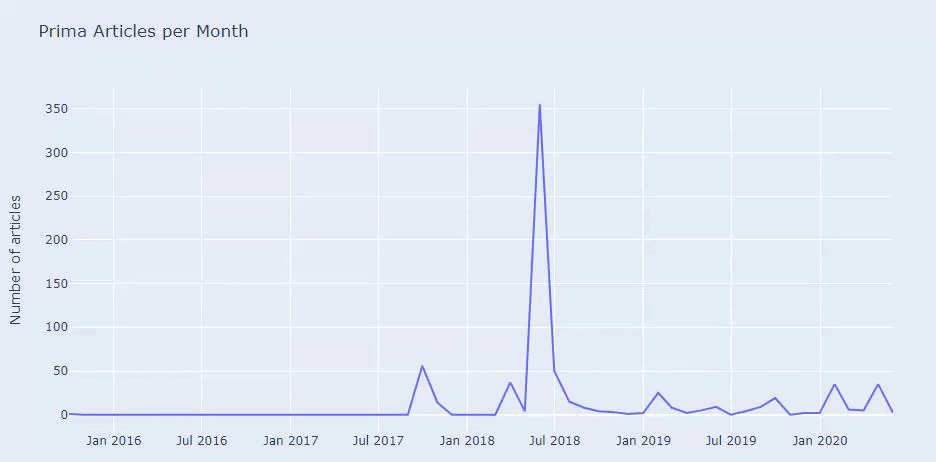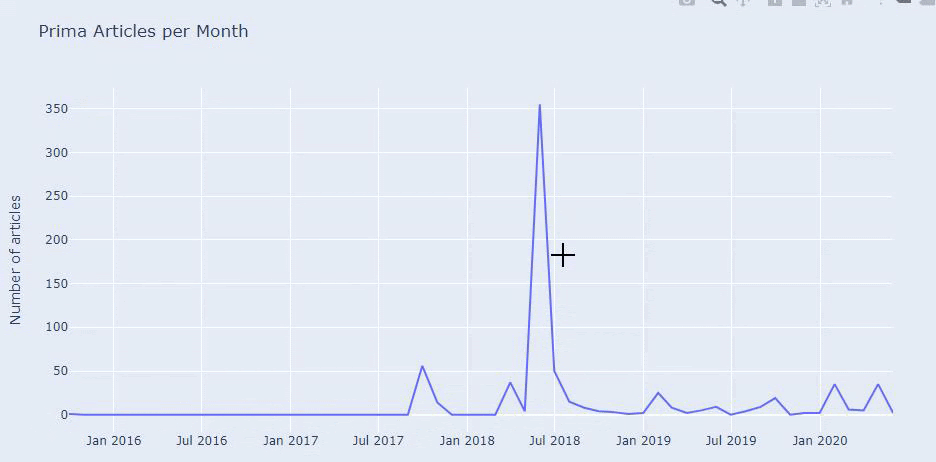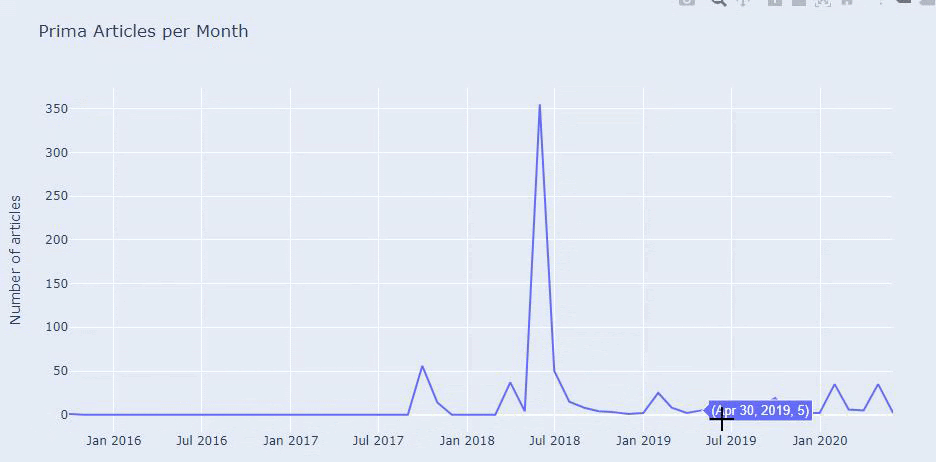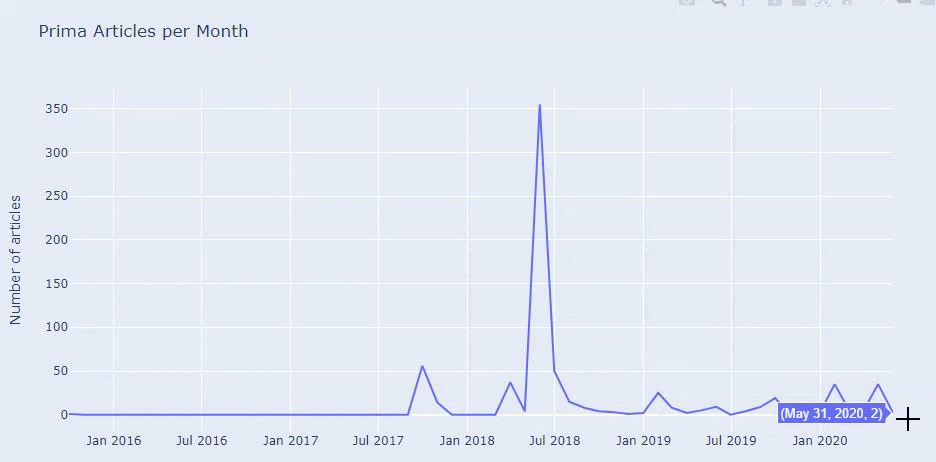
Vemos que eles publicaram 355 artigos em julho de 2018 e, de acordo com o Sitemap, seus conteúdos não são atualizados desde então. Também podemos comparar suas tendências de publicação de conteúdo de acordo com as categorias ao longo dos anos. Como você pode ver, seu conteúdo está localizado principalmente em quatro categorias diferentes e a maioria deles é publicada no mesmo mês.
Antes de prosseguir, devo dizer que os dados do mapa do site nem sempre estão corretos. Por exemplo, os dados do Lastmod podem ter sido atualizados para todos os URLs porque eles renovaram todos os sitemaps nesta data. Para contornar isso, também podemos verificar se eles não alteraram seu conteúdo desde então usando o Wayback Machine.
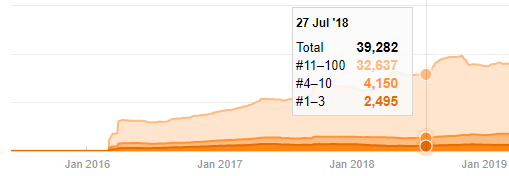
Mesmo que pareça suspeito, esses dados podem ser reais. Muitas empresas na Turquia tendem a dar um grande número de pedidos e publicar conteúdo um pouco antes. Quando verifico a contagem de palavras-chave, vejo um salto nesse período. Portanto, se você estiver realizando um perfil de conteúdo comparativo e uma análise de estratégia, também deve pensar nessas questões.
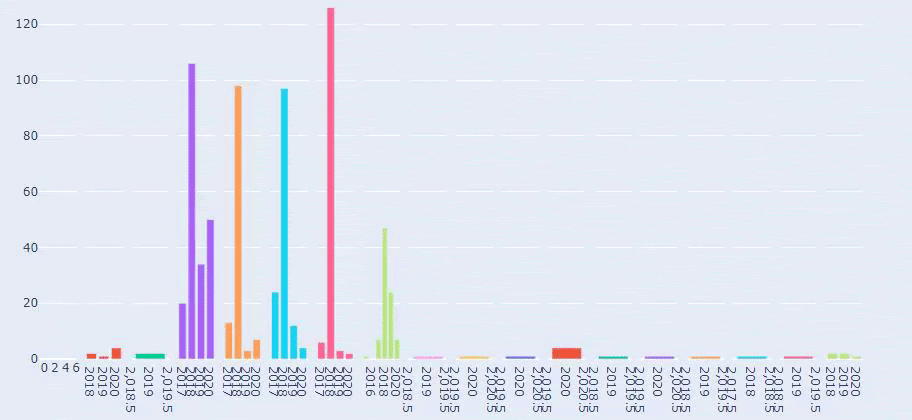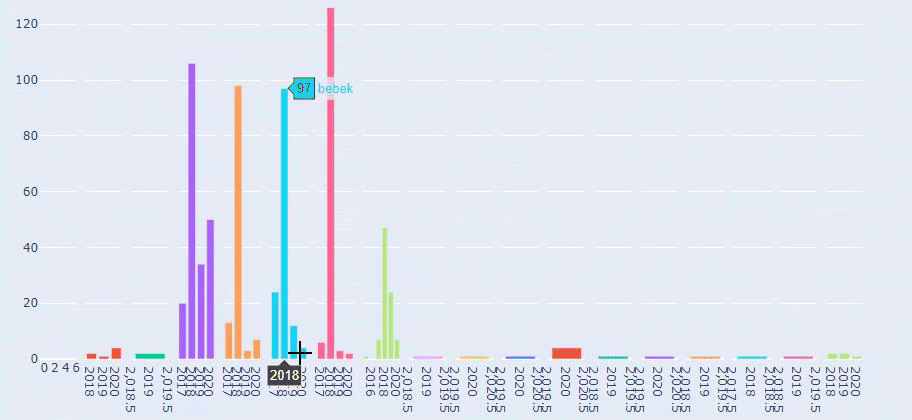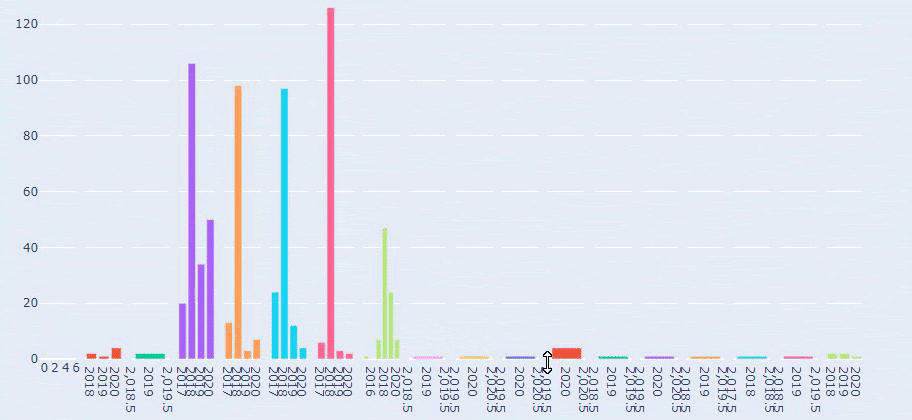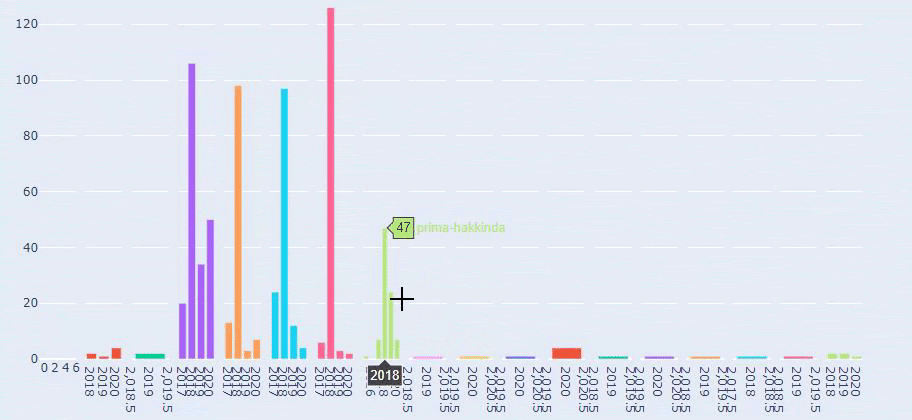
Esta é uma comparação entre a tendência de publicação de conteúdo de todas as categorias ao longo dos anos para Prima.com.tr
Agora, podemos comparar as categorias de conteúdo dos dois sites diferentes e suas tendências de publicação.
Quando olhamos para a frequência de publicação de artigos da Prima sobre crescimento do bebê, gravidez e maternidade, vemos uma semelhança com Ilkadimlarim:
- A maioria dos artigos foi publicada em um determinado momento.
- Fazia muito tempo que não eram atualizados.
- O número de produtos e páginas foi muito baixo em comparação com o número de páginas de conteúdo informativo.
- Recentemente, eles acabaram de adicionar novos produtos aos seus sites.
Podemos considerar esses quatro recursos como a mentalidade padrão do setor e podemos usar esses pontos fracos a favor de nossa campanha. Afinal, qualidade exige frescor (como afirma Amit Singhal, Google Fellow).
Neste ponto, também vemos que a indústria não está familiarizada com o comportamento do Googlebot. Em vez de carregar 250 peças de conteúdo em um dia e não fazer alterações por um ano, é melhor adicionar periodicamente novos conteúdos e atualizar o conteúdo antigo regularmente. Assim, você consegue manter a qualidade do conteúdo, o Googlebot consegue entender seu site com mais facilidade, e seus valores de frequência de demanda de rastreamento serão maiores que seus concorrentes.
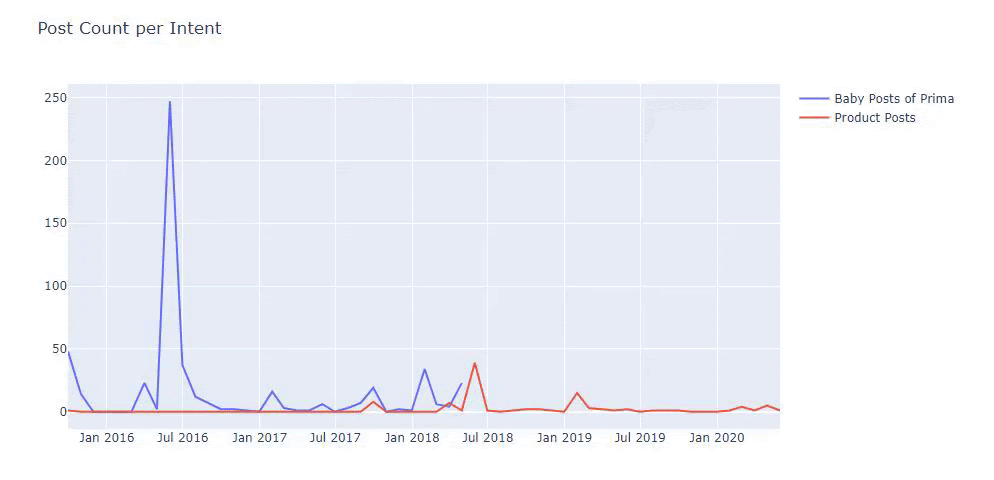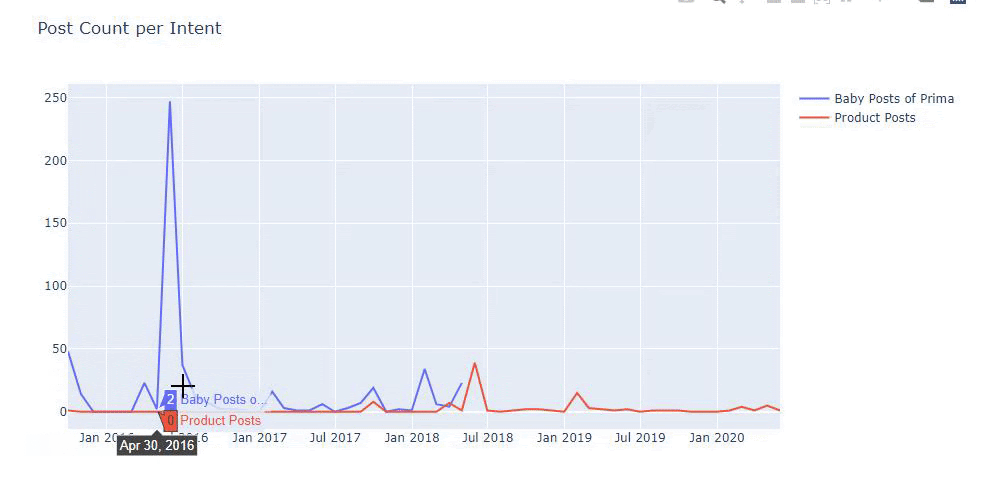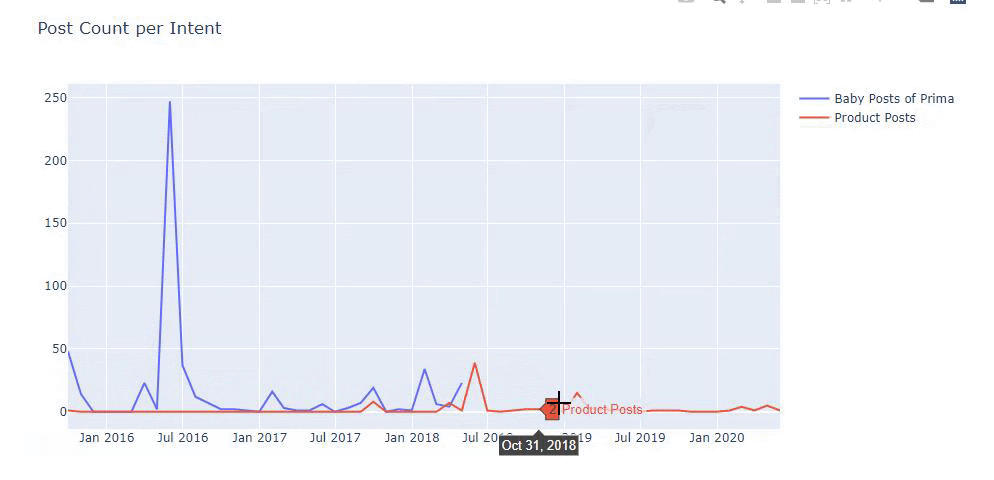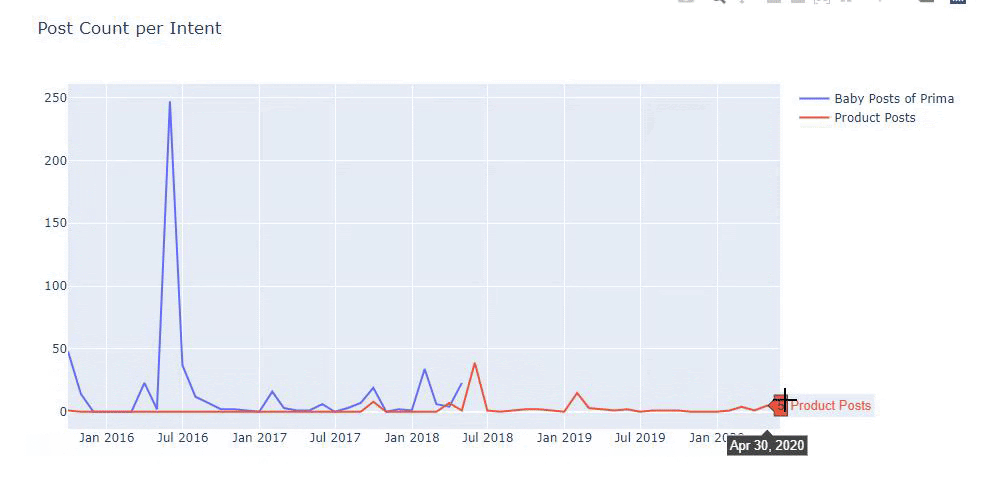
Usei os métodos anteriores para distinguir entre páginas de conteúdo de produtos e informativos e criei o perfil das palavras mais usadas nas URLs. Baby Posts aqui significa que são conteúdos informativos.
Como você pode ver, eles adicionaram 247 conteúdos em um dia. Além disso, eles não publicaram ou atualizaram o conteúdo informativo em mais de um ano e, ocasionalmente, adicionaram algumas novas páginas de produtos.
Agora vamos comparar suas tendências de publicação em uma única figura, mas com dois gráficos diferentes. Eu usei os códigos abaixo para criar esta figura:
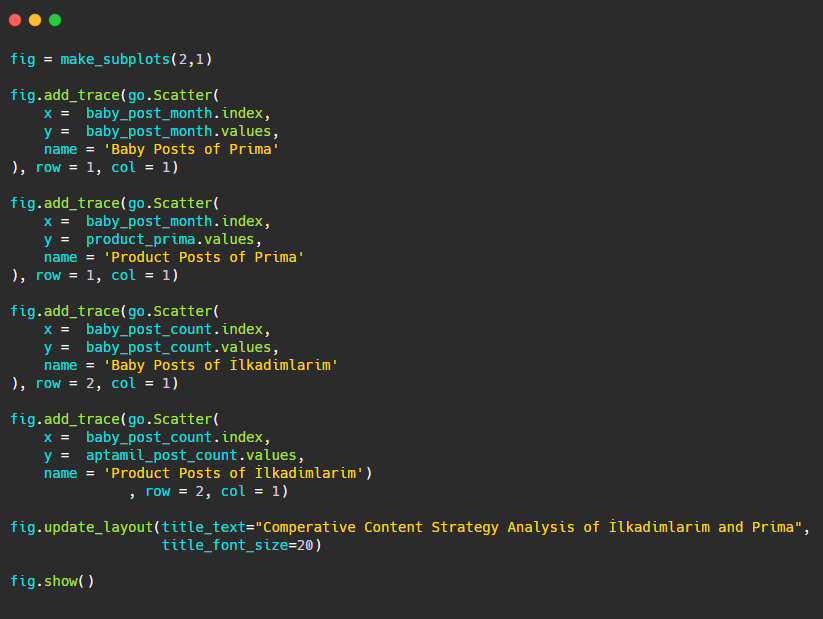
Como este gráfico é diferente dos anteriores, eu queria mostrar o código. Aqui, dois gráficos separados são colocados na mesma figura. Para isso, o método make_subplots foi chamado com o comando de plotly.subplots import make_subplots.
Ele foi criado como uma figura de duas linhas e uma coluna com make_subplots (2,1) .
Portanto, col e row são escritos no final dos traços e suas posições são especificadas. É um sistema que qualquer pessoa familiarizada com o sistema de grade em CSS pode reconhecer facilmente.
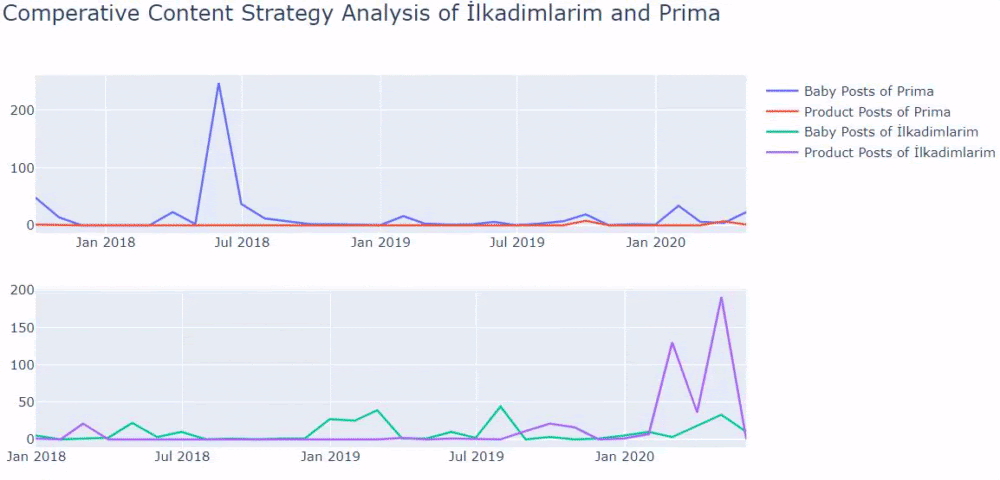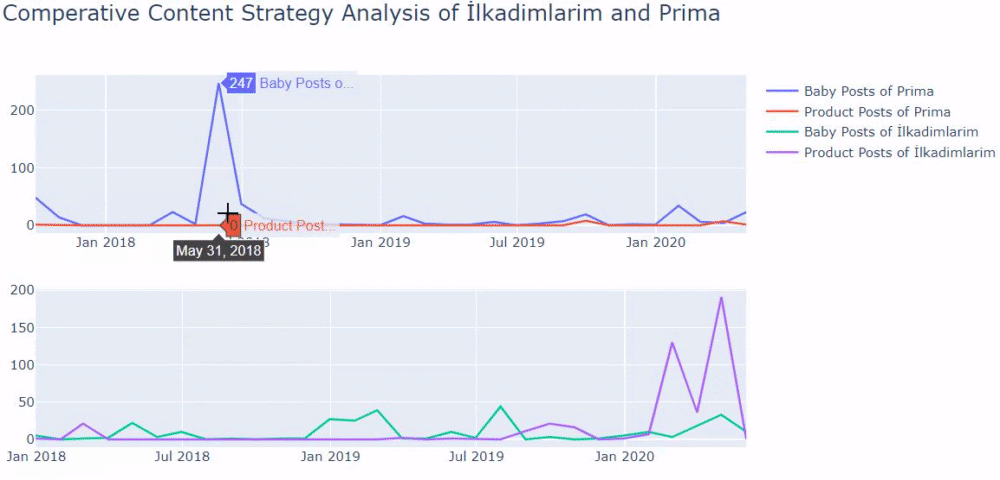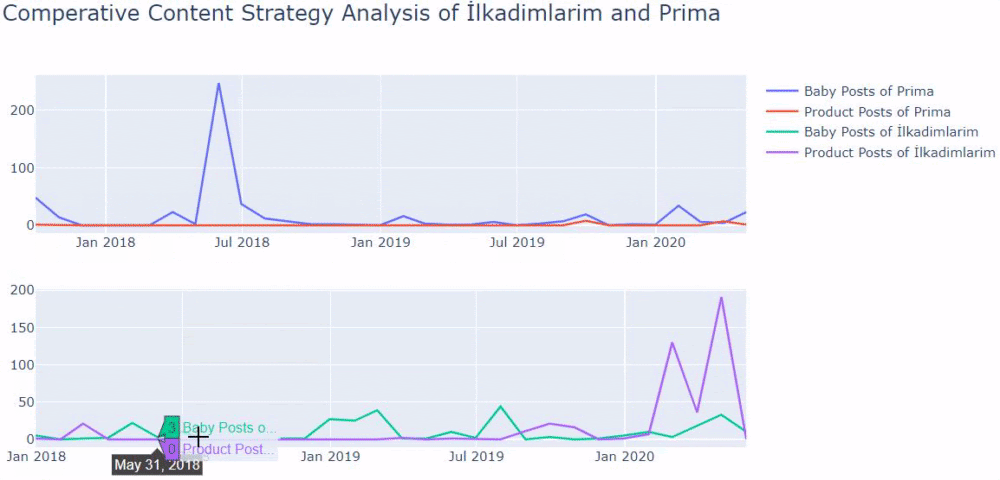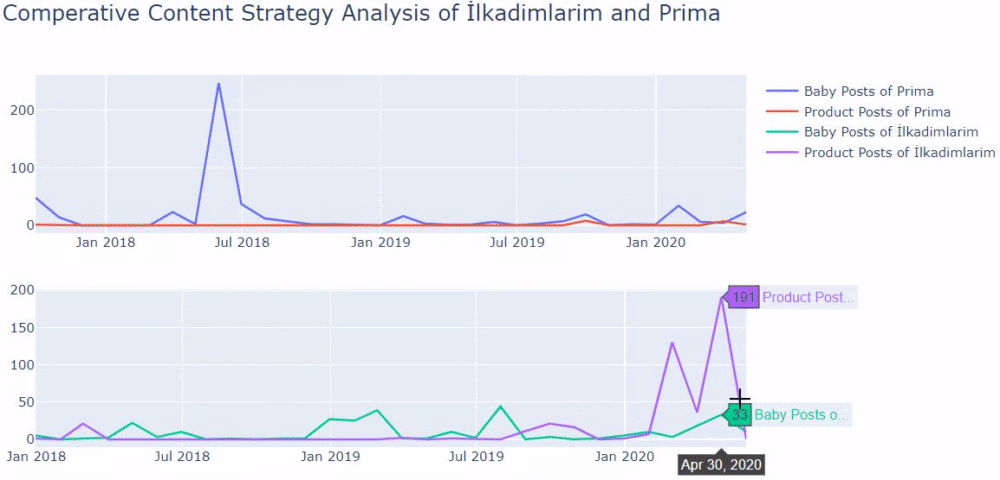
Se você tem um cliente no mesmo setor, pode usar esses dados para criar uma estratégia de conteúdo, para ver os pontos fracos de seus concorrentes e sua rede de consultas/páginas de destino na SERP. Além disso, você pode entender a quantidade de conteúdo que deve publicar no mesmo domínio de conhecimento ou para a mesma intenção do usuário.
Antes de encerrar com o que podemos aprender com os mapas do site como parte de uma análise de estratégia de conteúdo, podemos examinar um último site com uma contagem de URL muito maior de outro setor.
Análise de Estratégia de Conteúdo de Entidades da Web de Notícias sobre Moedas com Python e Sitemaps
Nesta seção, usaremos o gráfico de mapa de calor do Seaborn e também alguns métodos mais sofisticados de enquadramento e extração de dados.

Elias Dabbas tem um Kaggle Archive interessante e muito útil em termos de Data Science e SEO. Este mês, ele abriu uma nova seção Kaggle Dataset para sites de notícias turcos para eu escrever os códigos necessários e realizar uma análise de estratégia de conteúdo com Advertools via sitemaps.
Antes de começar a usar essas técnicas no Kaggle, gostaria de mostrar alguns exemplos do que aconteceria se usássemos as mesmas técnicas em entidades da Web maiores neste artigo.
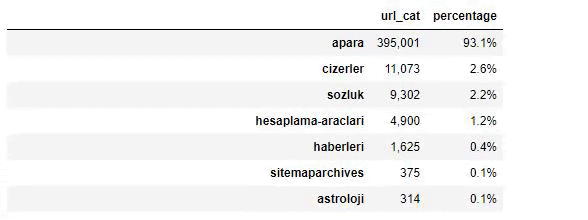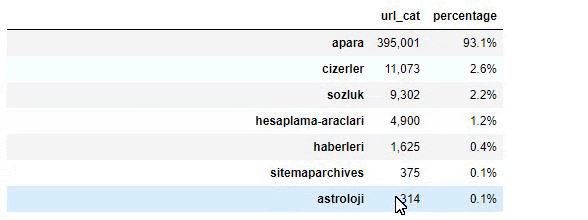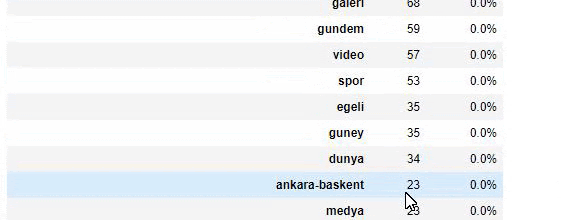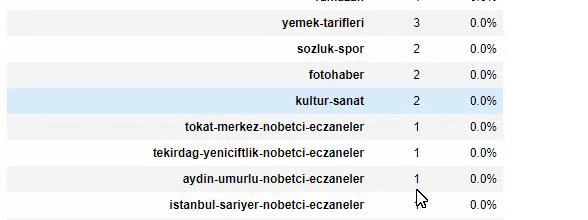
Quando analisamos o conteúdo do Jornal Sabah, vemos que parte significativa de seu conteúdo (81%) está em uma categoria denominada “apara”. Além disso, eles têm algumas grandes categorias para Astrologia, Cálculo, Dicionário, Tempo e Notícias do mundo. (Para significa o dinheiro em turco)
Para o Sabah Newspaper, também podemos analisar o conteúdo com sitemaps que coletamos apenas com o Advertools, mas como o jornal em questão é muito grande, não o preferi devido ao alto número de sitemaps e ao conteúdo de diferentes sitemaps contendo a mesma URL Categoria.
Abaixo você também pode ver o excesso de sitemaps com Advertools.
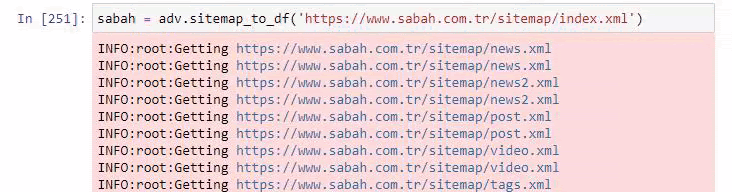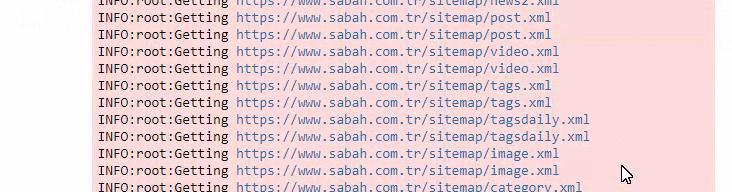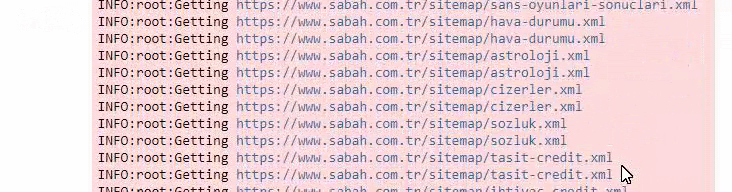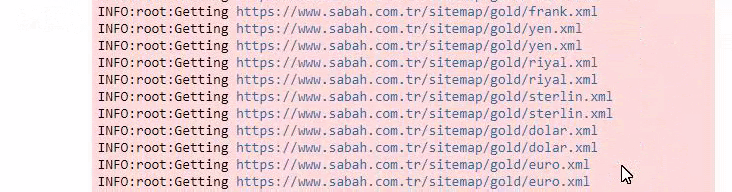
Podemos ver que eles têm diferentes sitemaps para as mesmas categorias de URL, como Ouro, Crédito, Moedas, Tags, Horários de Oração e Horário de Trabalho da Farmácia, etc…
Em suma, podemos obter esses detalhes focando em subcategorias de URLs. Em vez de unificar diferentes sitemaps por meio de variáveis. Então, eu unifiquei todos os sitemaps com o método sitemap_to_df() do Advertools como no início do artigo.
Também podemos usar outro conjunto de funções criadas por Elias Dabbas para criar melhores quadros de dados. Se você verificar as funções dataset_utitilites, poderá ver alguns exemplos. O código abaixo fornece o total e a porcentagem de um regex de URL especificado junto com a soma cumulativa por estilização.
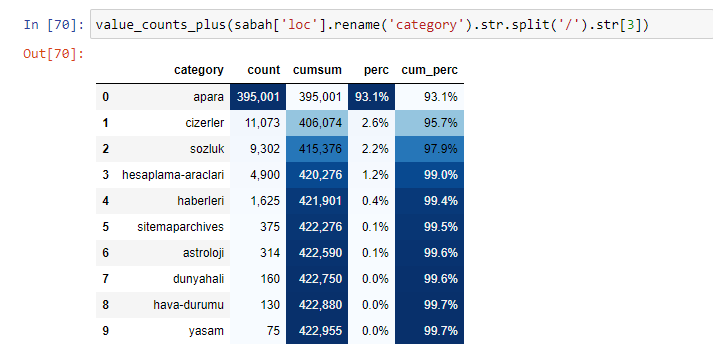
Se fizermos o mesmo com um detalhamento de sub-URL do jornal Sabah, obteremos o seguinte resultado.
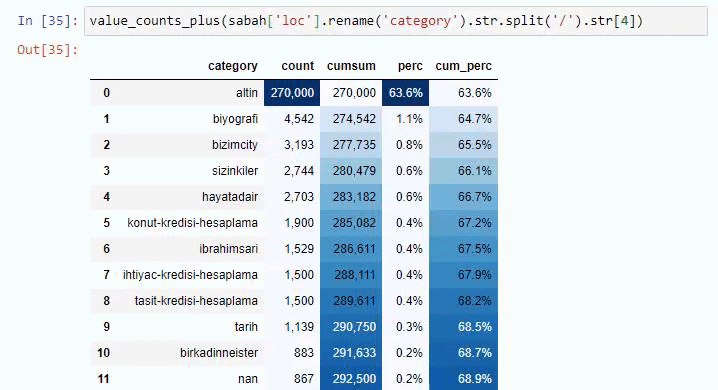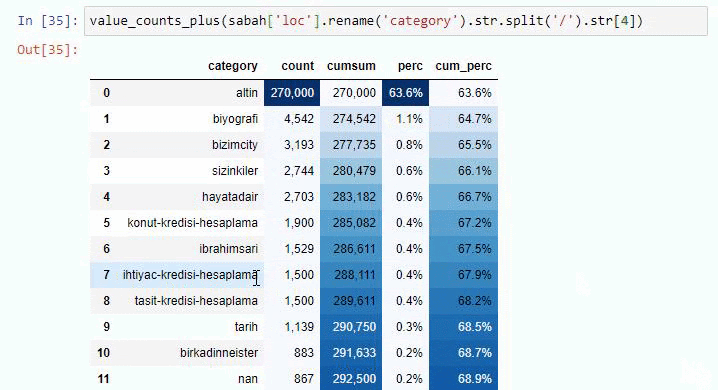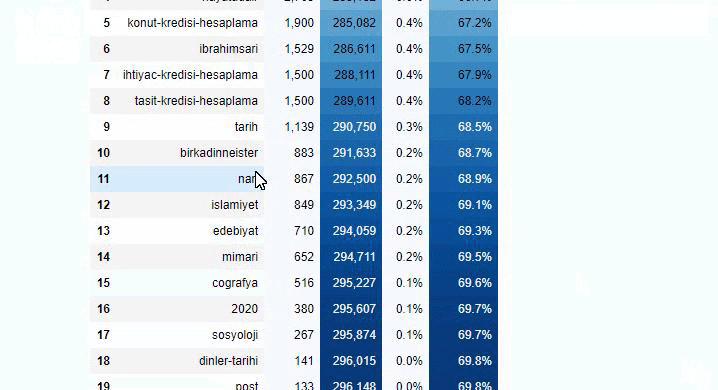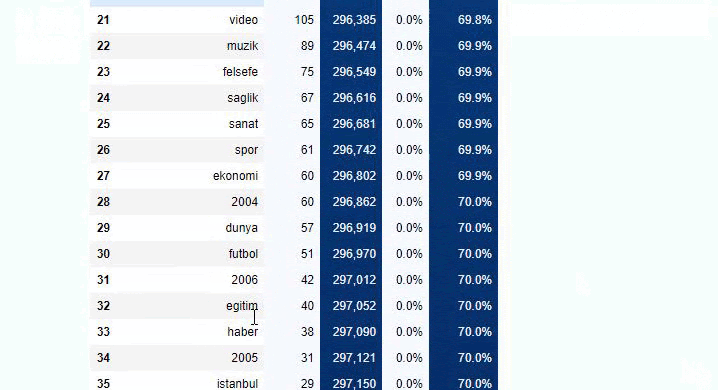
Você pode aumentar o número de linhas que a função em questão produzirá alterando a linha abaixo. Além disso, se você examinar o conteúdo da função, verá que ela é semelhante às que usamos antes.
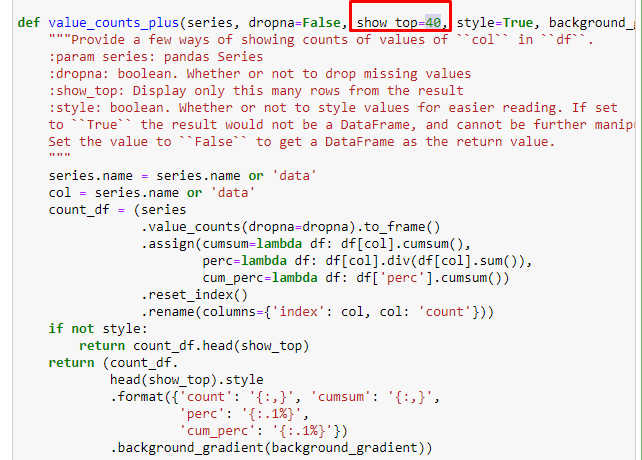
Em sub-quebras, vemos diferentes divisões, como “História da Religião”, “Biografia”, “Nomes de Cidades”, “Futebol”, “Bizimcity (Caricatura)”, “Crédito Hipotecário”. O maior detalhamento está na categoria “Ouro”.
Então, como um jornal pode ter 295.000 URLs para preços de ouro?
Em primeiro lugar, eu coloco todos os URLs que contêm o “apara” no primeiro detalhamento de URL do Sabah Newspaper em uma variável.
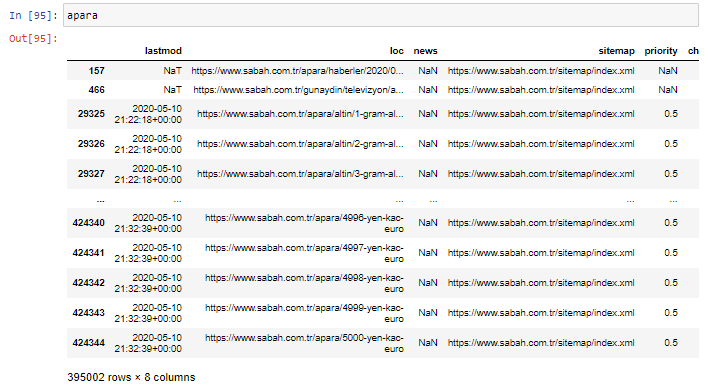
apara = sabah[sabah['loc'].str.contains('apara')]
Aqui está o resultado:
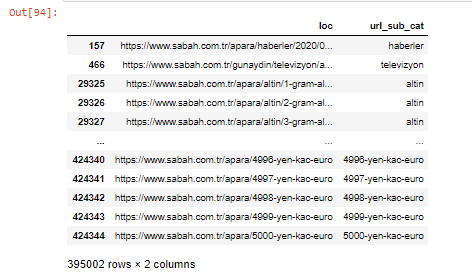
Também podemos filtrar as colunas com o método .filter():
Agora, podemos ver na parte inferior do DataFrame porque o Sabah Newspaper tem uma quantidade excessiva de URLs Apara porque eles abriram diferentes páginas da web para cada valor de cálculo de moeda, como 5000 Euros, 4999 Euros, 4998 Euros e muito mais…
Mas, antes de qualquer conclusão, precisamos ter certeza porque mais de 250.000 dessas URLs pertencem à categoria 'altin (ouro)'.
apara.filter(['loc', 'url_sub_cat' ]).tail(60) nos mostrará as últimas 60 linhas deste Data Frame:

Podemos fazer o mesmo para o detalhamento do URL de ouro no grupo Apara.
ouro = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
Neste ponto, vemos que o Sabah Newspaper abriu 5.000 páginas diferentes para converter cada moeda em Dólar, Euro, Ouro e TL (Liras Turcas). Há uma página de cálculo separada para cada unidade de dinheiro entre 1 e 5000. Você pode ver o exemplo das primeiras 85 e últimas 85 linhas do grupo ouro abaixo. Uma página separada foi aberta para cada grama de preço de ouro.


Não temos dúvidas de que essas páginas são desnecessárias, com muito conteúdo duplicado e excessivamente grandes, mas o Sabah Newspaper é um site tão forte que o Google continua a mostrá-lo em quase todas as consultas, no topo do ranking.
Neste ponto, também podemos ver que a tolerância ao custo de rastreamento é alta para um site de notícias antigo com alta autoridade.
No entanto, isso não explica por que a categoria ouro tem mais URLs do que outras.
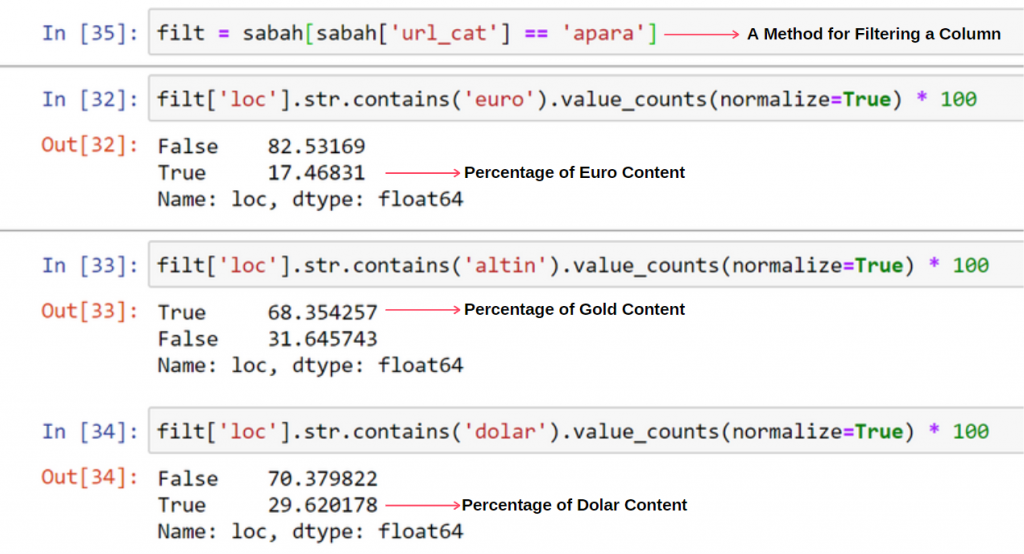
Não vejo nada de estranho em valores sobrepostos somando mais de 100%.
A menos que eu esteja perdendo alguma coisa?
Como você notará, quando somamos todos os True Values, obtemos o resultado de 115,16%. A razão para isso está abaixo.
Mesmo o grupo principal tem uma interseção entre si assim. Poderíamos também analisar essas interseções, mas isso poderia ser assunto para outro artigo.
Vemos que 68% do conteúdo do grupo Apara URL está relacionado ao GOLD.
Para entender melhor essa situação, a primeira coisa que precisamos fazer é escanear as URLs na refração de ouro.
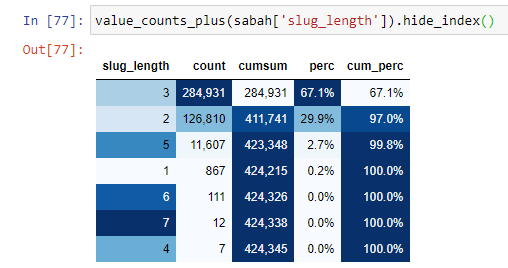
Quando classificamos as URLs de acordo com a quantidade de '/' que possuem desde a seção raiz, vemos que o número de URLs com no máximo 3 quebras é alto. Quando analisamos esses URLs, vemos que 270.000 dos 3 URLs slug_length estão na categoria Gold.
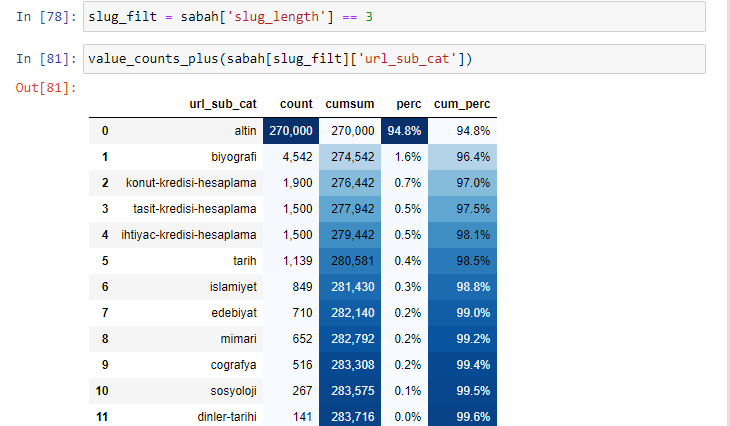
morning_filt = morning ['slug_length'] == 3 Isso significa que você só obtém os que são iguais a 3 do grupo de dados do tipo de dados int em uma determinada coluna de um determinado quadro de dados. Em seguida, com base nessas informações, enquadramos as URLs que são convenientes para a condição com a contagem, somas e taxas de agregação com soma cumulativa.
Quando extraímos as palavras mais utilizadas nas URLs gold, encontramos palavras que representam “full”, “republic”, “quarter”, “gram”, “half”, “ancestor”. Os tipos de ouro Ata e Republic são exclusivos da Turquia. Um deles representa a Soberania Turca e o outro é o Fundador da República, Kemal Ataturk. É por isso que seus volumes de pesquisa de consulta são altos.
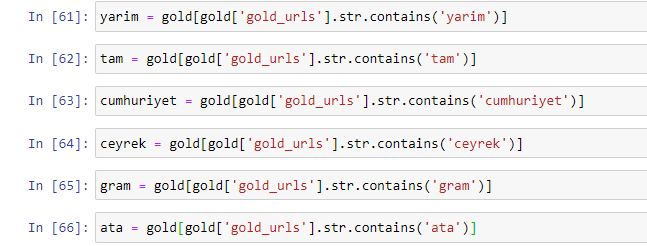
Em primeiro lugar, removemos as palavras comuns encontradas nos URLs e as atribuímos a variáveis separadas. Em seguida, usaremos essas variáveis no Gold DataFrame para criar colunas específicas para seus tipos.
Após criar novas colunas através de variáveis, devemos filtrá-las juntamente com valores booleanos.
Como você pode ver, conseguimos categorizar todos os URLs de ouro com 270.000 linhas e 6 colunas. A principal razão para o alto número de páginas específicas de ouro é que o dólar ou o euro não têm tipos separados, enquanto o ouro tem tipos separados. Ao mesmo tempo, a diversidade de páginas cruzadas entre ouro e moedas diferentes é maior do que outras moedas devido à confiança tradicional no povo turco.
Na minha opinião, todos os tipos de páginas douradas devem ser distribuídos igualmente, certo?
Podemos testar isso facilmente com o recurso Heatmap do Seaborn.
importar seaborn como sns
importar matplotlib.pyplot como plt
plt.figura(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
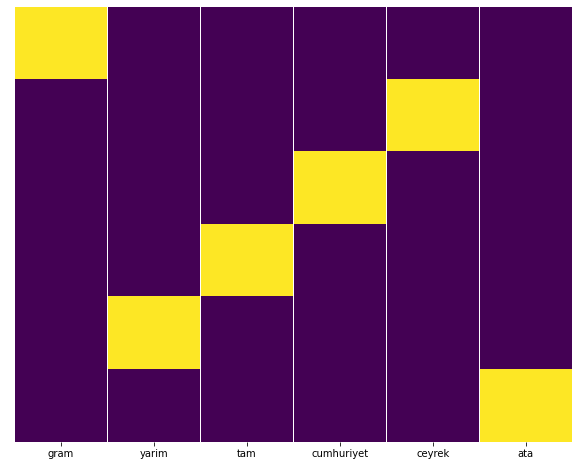
Aqui no Heat Map, os Trues em cada coluna são simplesmente marcados. Como pode ser visto, o tamanho de cada um é simétrico entre si e está bem organizado no mapa.
Assim, adotamos uma perspectiva ampla sobre a política de conteúdo do Jornal Sabah.com.tr sobre Moedas e Cálculo de Moedas.
No futuro, escreverei sites de notícias turcos e suas estratégias de conteúdo com base no Sitemaps Kaggle, lançado por Elias Dabbas, mas neste artigo, falamos o suficiente sobre o que pode ser descoberto em sites grandes e pequenos com sitemaps .
Conclusão e conclusões
Acho que vimos como é fácil entender um site, graças a uma estrutura de URL suave e semântica. Também devemos lembrar o quão valiosa uma estrutura de URL adequada pode ser para o Google.
No futuro, veremos muitos SEOs cada vez mais familiarizados com ciência de dados, visualização de dados, programação front-end e muito mais… Vejo esse processo como o início de uma mudança inevitável: a lacuna entre SEOs e desenvolvedores será fechada completamente em poucos anos.
Com o Python, você pode levar esse tipo de análise ainda mais longe: é possível obter dados desde a compreensão das visões políticas de um site de notícias, até quem escreve sobre o quê, com que frequência e com quais sentimentos. Prefiro não entrar nisso aqui, pois esses processos são mais sobre ciência de dados pura do que SEO (e este artigo já é bastante longo).
Mas se você estiver interessado, existem muitos outros tipos de auditorias que podem ser realizadas por meio de Sitemaps e Python, como verificar os códigos de status de URLs em um sitemap.
Estou ansioso para experimentar e compartilhar outras tarefas de SEO que você pode fazer com Python e Advertools.