
Compreendendo a IA: como ensinamos a linguagem natural aos computadores
Publicados: 2023-11-28A expressão “inteligência artificial” tem sido usada em relação aos computadores desde a década de 1950, mas até ao ano passado, a maioria das pessoas provavelmente pensava que a IA ainda era mais ficção científica do que realidade tecnológica.
A chegada do ChatGPT da OpenAI em novembro de 2022 mudou repentinamente a percepção das pessoas sobre o que o aprendizado de máquina era capaz – mas o que exatamente havia no ChatGPT que fez o mundo sentar e perceber que a inteligência artificial estava aqui em grande escala?
Em uma palavra, linguagem – a razão pela qual o ChatGPT pareceu um salto tão notável foi por causa de como ele parecia fluente em linguagem natural de uma forma que nenhum chatbot jamais foi antes.
Isto marca um novo estágio notável de “processamento de linguagem natural” (PNL), a capacidade dos computadores de interpretar a linguagem natural e produzir respostas convincentes. ChatGPT é construído em um “modelo de linguagem grande” (LLM), que é um tipo de rede neural que usa aprendizado profundo treinado em conjuntos de dados massivos que podem processar e gerar conteúdo.
“Como um programa de computador alcançou tal fluência linguística?”
Mas como chegamos aqui? Como um programa de computador alcançou tal fluência linguística? Como isso soa tão infalivelmente humano?
O ChatGPT não foi criado no vácuo – ele se baseou em inúmeras inovações e descobertas diferentes nas últimas décadas. A série de avanços que levaram ao ChatGPT foram marcos na ciência da computação, mas é possível vê-los como uma imitação dos estágios pelos quais os humanos adquirem a linguagem.
Como aprendemos a língua?
Para compreender como a IA atingiu esta fase, vale a pena considerar a natureza da aprendizagem de línguas em si – começamos com palavras isoladas e depois começamos a combiná-las em sequências mais longas até conseguirmos comunicar conceitos, ideias e instruções complexas.
Por exemplo, alguns estágios comuns de aquisição da linguagem em crianças são:
- Estágio holofrástico: Entre 9 e 18 meses, as crianças aprendem a usar palavras únicas que descrevem suas necessidades ou desejos básicos. Comunicar-se com uma única palavra significa que há ênfase na clareza em vez da integridade conceitual. Se uma criança estiver com fome, ela não dirá “quero comida” ou “estou com fome”, mas simplesmente dirá “comida” ou “leite”.
- Estágio de duas palavras: Durante os 18-24 meses, as crianças começam a usar agrupamentos simples de duas palavras para aprimorar suas habilidades de comunicação. Agora eles podem comunicar seus sentimentos e necessidades com expressões como “mais comida” ou “ler livro”.
- Estágio telegráfico: Entre 24 e 30 meses, as crianças começam a encadear várias palavras para formar frases e sentenças mais complexas. O número de palavras utilizadas ainda é pequeno, mas a ordem correta das palavras e mais complexidade começam a aparecer. As crianças começam a aprender a construção básica de frases, como “eu quero mostrar para a mamãe”.
- Estágio de múltiplas palavras: Após 30 meses, as crianças começam a transição para o estágio de múltiplas palavras. Nesta fase, as crianças começam a usar frases gramaticalmente mais corretas e complexas e com várias orações. Este é o estágio final da aquisição da linguagem e as crianças eventualmente se comunicam com frases complexas como “Se chover, quero ficar em casa e jogar”.
Um dos primeiros estágios importantes na aquisição da linguagem é a capacidade de começar a usar palavras isoladas de uma forma muito simples. Portanto, o primeiro obstáculo que os pesquisadores de IA precisaram superar foi como treinar modelos para aprender associações simples de palavras.
Modelo 1 – Aprendendo palavras únicas com Word2Vec (artigo 1 e artigo 2)
Um dos primeiros modelos de redes neurais que tentou aprender associações de palavras dessa forma foi o Word2Vec, desenvolvido por Tomaš Mikolov e um grupo de pesquisadores do Google. Foi publicado em dois artigos em 2013 (o que mostra a rapidez com que as coisas se desenvolveram neste campo).
Esses modelos foram treinados aprendendo a associar palavras que eram comumente usadas juntas. Esta abordagem baseou-se na intuição dos primeiros pioneiros linguísticos, como John R. Firth, que observou que o significado poderia ser derivado da associação de palavras: “Você conhecerá uma palavra pela companhia que ela mantém”.
A ideia é que palavras que compartilham um significado semântico semelhante tendem a ocorrer juntas com mais frequência. As palavras “gatos” e “cães” geralmente ocorrem juntas com mais frequência do que com palavras como “maçãs” ou “computadores”. Em outras palavras, a palavra “gato” deveria ser mais parecida com a palavra “cachorro” do que “gato” seria com “maçã” ou “computador”.
O interessante do Word2Vec é como ele foi treinado para aprender estas associações de palavras:
- Adivinhe a palavra-alvo: o modelo recebe um número fixo de palavras como entrada, sem a palavra-alvo e precisa adivinhar a palavra-alvo que falta. Isso é conhecido como Saco Contínuo de Palavras (CBOW).
- Adivinhe as palavras ao redor: O modelo recebe uma única palavra e então é encarregado de adivinhar as palavras ao redor. Isso é conhecido como Skip-Gram e é a abordagem oposta ao CBOW, pois prevemos as palavras ao redor.
Uma vantagem dessas abordagens é que você não precisa ter nenhum dado rotulado para treinar o modelo – rotular dados, por exemplo, descrever o texto como “positivo” ou “negativo” para ensinar análise de sentimento, é um trabalho lento e trabalhoso, afinal.
Uma das coisas mais surpreendentes sobre o Word2Vec foram as complexas relações semânticas que ele capturou com uma abordagem de treinamento relativamente simples. Word2Vec gera vetores que representam a palavra de entrada. Ao realizar operações matemáticas nesses vetores, os autores conseguiram mostrar que os vetores de palavras não capturavam apenas elementos sintaticamente semelhantes, mas também relações semânticas complexas.
Essas relações estão relacionadas à forma como as palavras são usadas. O exemplo que os autores observaram foi a relação entre palavras como “Rei” e “Rainha” e “Homem” e “Mulher”.
Mas embora tenha sido um avanço, o Word2Vec tinha limites. Tinha apenas uma definição por palavra – por exemplo, todos nós sabemos que “banco” pode significar coisas diferentes dependendo se você planeja segurar um ou pescar em um. O Word2Vec não se importava, ele apenas tinha uma definição para a palavra “banco” e a usaria em todos os contextos.
Acima de tudo, o Word2Vec não conseguia processar instruções ou mesmo frases. Ele só poderia pegar uma palavra como entrada e gerar uma “incorporação de palavras”, ou representação vetorial, que havia aprendido para essa palavra. Para desenvolver essa base de palavra única, os pesquisadores precisavam encontrar uma maneira de encadear duas ou mais palavras em uma sequência. Podemos imaginar isso como sendo semelhante ao estágio de aquisição da linguagem de duas palavras.
Modelo 2 – Aprendendo sequências de palavras com RNNs e sequências de texto
Depois que as crianças começam a dominar o uso de palavras isoladas, elas tentam juntar palavras para expressar pensamentos e sentimentos mais complexos. Da mesma forma, o próximo passo no desenvolvimento da PNL foi desenvolver a capacidade de processar sequências de palavras. O problema com o processamento de sequências de texto é que elas não têm comprimento fixo. Uma frase pode variar em comprimento, desde algumas palavras até um longo parágrafo. Nem toda a sequência será importante para o significado e contexto geral. Mas precisamos ser capazes de processar toda a sequência para saber quais partes são mais relevantes.
Foi aí que surgiram as Redes Neurais Recorrentes (RNNs).
Desenvolvido na década de 1990, um RNN funciona processando sua entrada em um loop onde a saída das etapas anteriores é transportada pela rede à medida que ela itera em cada etapa da sequência.
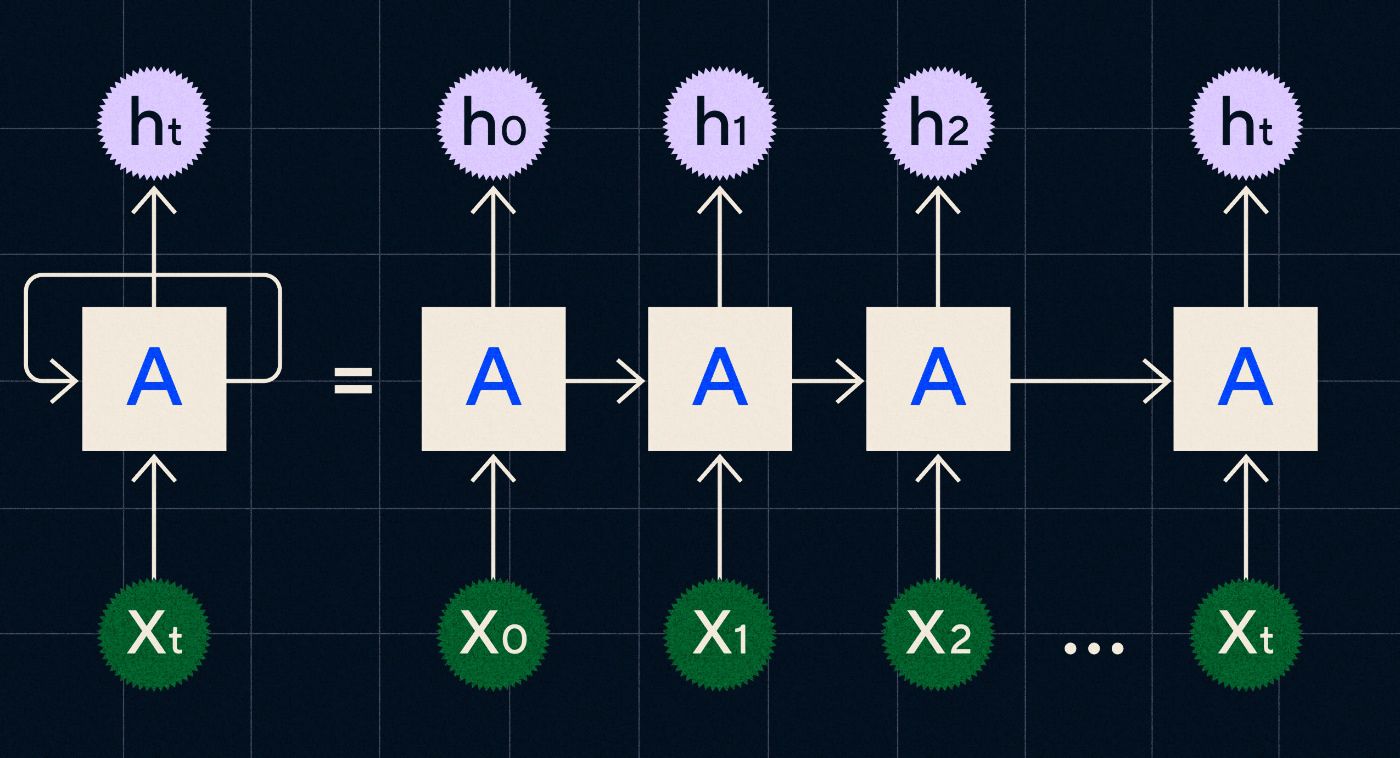
Fonte: postagem do blog de Christopher Olah sobre RNNs
O diagrama acima mostra como imaginar um RNN como uma série de redes neurais (A) onde a saída da etapa anterior (h0, h1, h2…ht) é transportada para a próxima etapa. Em cada etapa uma nova entrada (X0, X1, X2…Xt) também é processada pela rede.
RNNs (e especificamente redes de Long Short Term Memory, ou LSTMs, um tipo especial de RNN introduzido por Sepp Hochreiter e Jurgen Schmidhuber em 1997) nos permitiram criar arquiteturas de redes neurais que poderiam executar tarefas mais complexas, como tradução.
Em 2014, um artigo foi publicado por Ilya Sutskever (cofundador da OpenAI), Oriol Vinyals e Quoc V Le no Google, que descreveu modelos Sequence to Sequence (Seq2Seq). Este artigo mostrou como você pode treinar uma rede neural para pegar um texto de entrada e retornar uma tradução desse texto. Você pode pensar nisso como um dos primeiros exemplos de rede neural generativa, onde você dá um prompt e ela retorna uma resposta. No entanto, a tarefa foi corrigida, portanto, se ela fosse treinada em tradução, você não poderia “solicitá-la” a fazer mais nada.
Lembre-se que o modelo anterior, Word2Vec, só conseguia processar palavras isoladas. Então, se você passasse uma frase como “o dentista arrancou meu dente”, simplesmente geraria um vetor para cada palavra como se elas não estivessem relacionadas.
No entanto, a ordem e o contexto são importantes para tarefas como a tradução. Você não pode simplesmente traduzir palavras individuais, você precisa analisar sequências de palavras e então gerar o resultado. Foi aqui que os RNNs permitiram que os modelos Seq2Seq processassem palavras dessa maneira.
A chave para os modelos Seq2Seq foi o projeto da rede neural, que usava dois RNNs consecutivos. Um era um codificador que transformava a entrada do texto em uma incorporação, e o outro era um decodificador que tomava como entrada as incorporações emitidas pelo codificador:
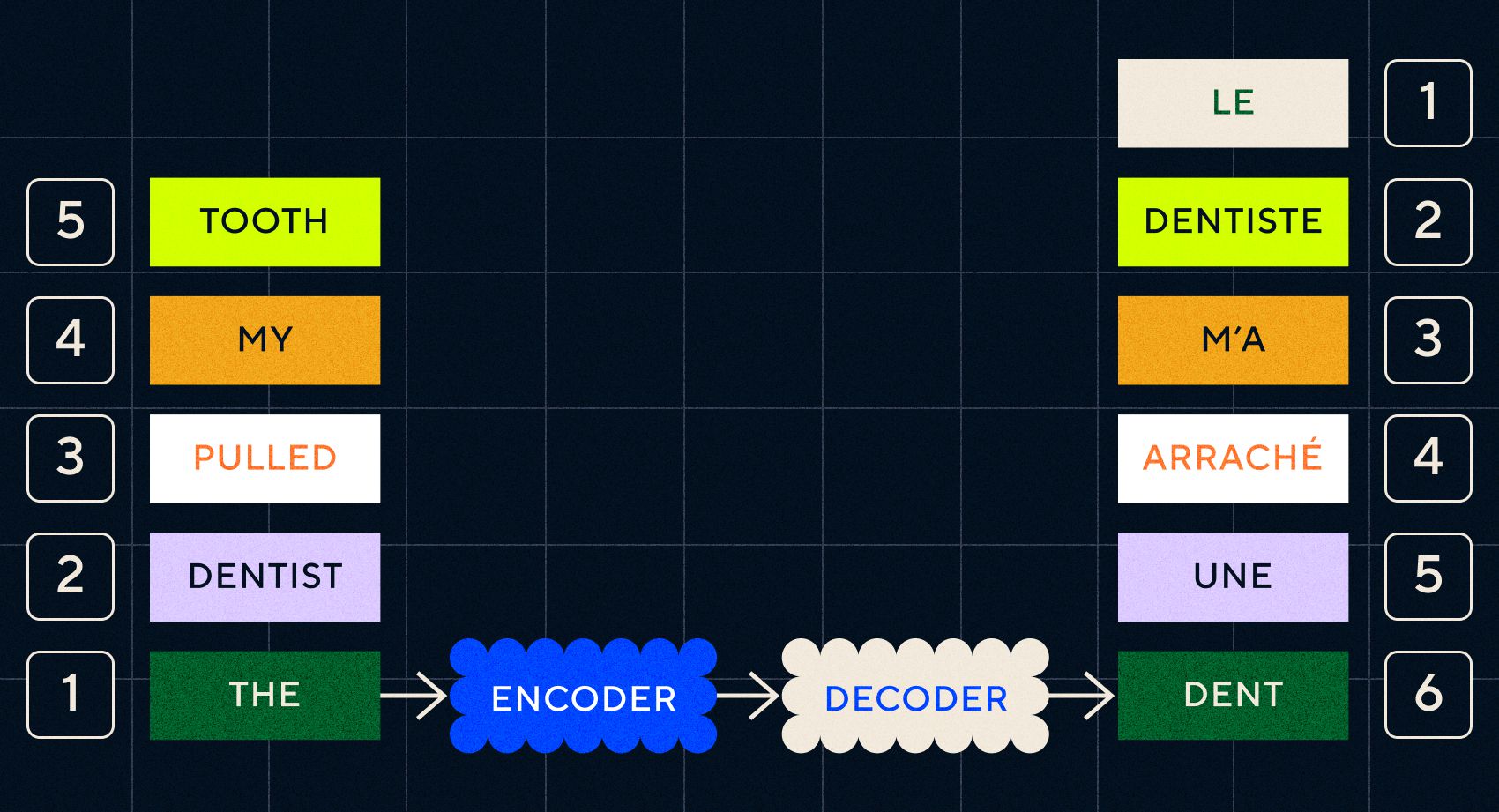
Depois que o codificador processa as entradas em cada etapa, ele começa a passar a saída para o decodificador, que transforma as incorporações em um texto traduzido.
Podemos perceber com a evolução desses modelos que eles estão começando a se assemelhar, de alguma forma simples, ao que vemos hoje com o ChatGPT. No entanto, também podemos ver quão limitados estes modelos eram em comparação. Tal como acontece com o nosso próprio desenvolvimento linguístico, para realmente melhorar as habilidades linguísticas, precisamos saber exatamente no que prestar atenção para criar frases e sentenças mais complexas.
Modelo 3 – Aprendizagem por atenção e escalonamento com Transformers
Observamos anteriormente que os estágios telegráficos eram onde as crianças começavam a criar frases curtas com duas ou mais palavras. Um aspecto fundamental desta fase de aquisição da linguagem é que as crianças estão começando a aprender como construir frases adequadas.
Os modelos RNNs e Seq2Seq ajudaram os modelos de linguagem a processar múltiplas sequências de palavras, mas ainda eram limitados no comprimento das frases que podiam processar. À medida que o comprimento da frase aumenta, precisamos prestar atenção à maioria das coisas na frase.
Por exemplo, tome a seguinte frase “Havia tanta tensão na sala que você poderia cortá-la com uma faca”. Há muita coisa acontecendo lá. Para saber que não estamos literalmente cortando algo com uma faca, precisamos vincular “cortar” com “tensão” no início da frase.
À medida que o comprimento da frase aumenta, torna-se mais difícil saber quais palavras se referem a quais, a fim de inferir o significado adequado. Foi aqui que as RNNs começaram a encontrar limites e precisávamos de um novo modelo para passar para o próximo estágio de aquisição da linguagem.
“Pense em tentar resumir uma conversa à medida que ela fica cada vez mais longa, com um limite fixo de palavras. A cada passo você começa a perder mais e mais informações”
Em 2017, um grupo de pesquisadores do Google publicou um artigo que propunha uma técnica para melhor permitir que os modelos prestassem atenção ao contexto importante em um trecho de texto.
O que eles desenvolveram foi uma maneira de os modelos de linguagem procurarem com mais facilidade o contexto de que precisavam enquanto processavam uma sequência de entrada de texto. Eles chamaram essa abordagem de “arquitetura de transformador” e representou o maior avanço no processamento de linguagem natural até o momento.
Esse mecanismo de pesquisa torna mais fácil para o modelo identificar quais das palavras anteriores forneceram mais contexto para a palavra atual que está sendo processada. As RNNs tentam fornecer contexto passando um estado agregado de todas as palavras que já foram processadas em cada etapa. Pense em tentar resumir uma conversa à medida que ela fica cada vez mais longa, com um limite fixo de palavras. A cada passo você começa a perder mais e mais informações. Em vez disso, os transformadores ponderaram palavras (ou tokens, que não são palavras inteiras, mas partes de palavras) com base em sua importância para a palavra atual em termos de seu contexto. Isso tornou mais fácil processar sequências cada vez mais longas de palavras sem o gargalo visto nas RNNs. Este novo mecanismo de atenção também permitiu que o texto fosse processado em paralelo, em vez de sequencialmente, como um RNN.
Então imagine uma frase como “O animal não atravessou a rua porque estava muito cansado”. Para um RNN seria necessário representar todas as palavras anteriores em cada etapa. À medida que aumenta o número de palavras entre “isso” e “animal”, torna-se mais difícil para a RNN identificar o contexto adequado.

Com a arquitetura do transformador, o modelo agora tem a capacidade de procurar a palavra que tem maior probabilidade de se referir a “isso”. O diagrama abaixo mostra como os modelos transformadores são capazes de focar na parte “animal” do texto enquanto tentam processar uma frase.
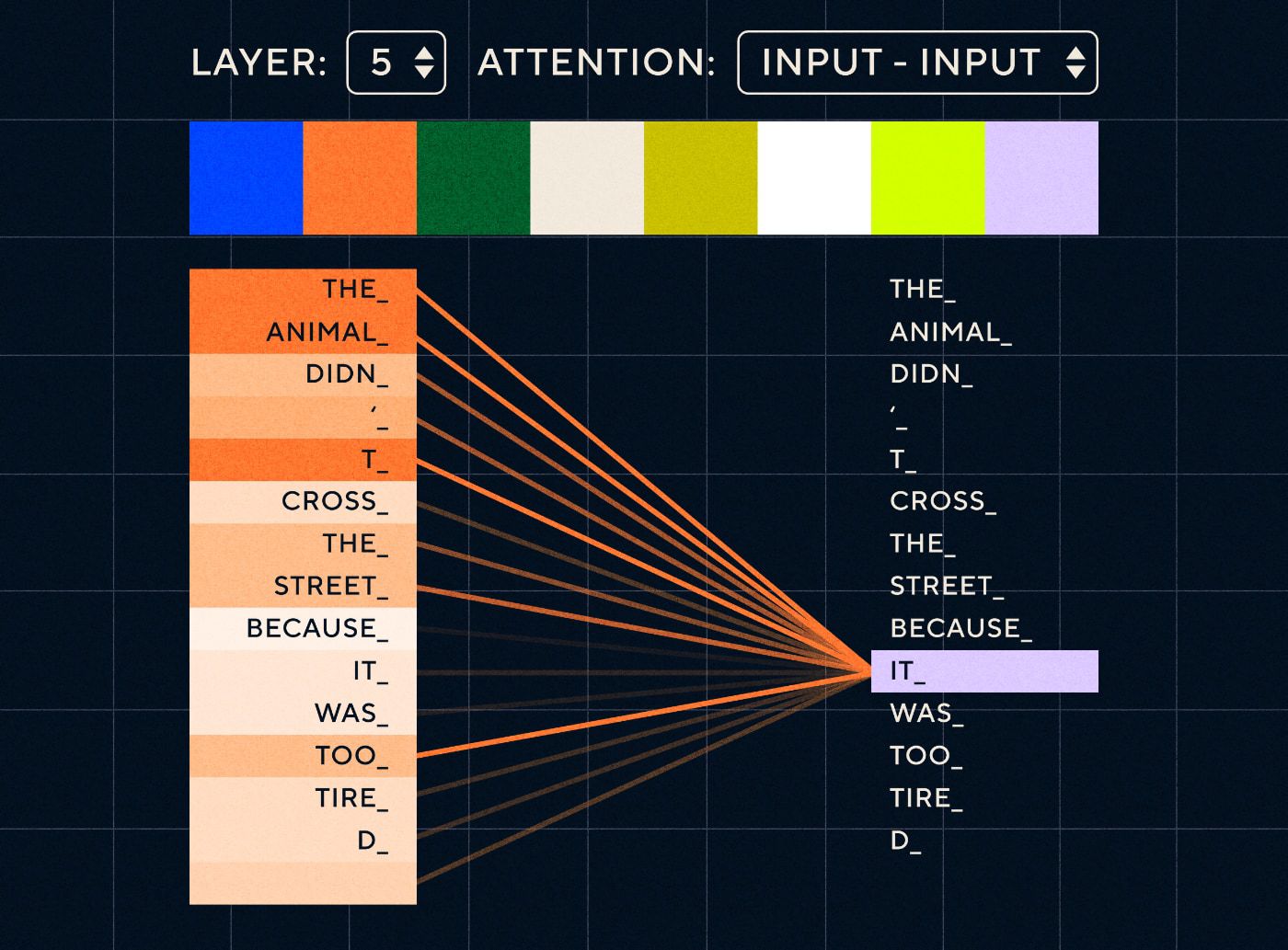
Fonte: O Transformador Ilustrado
O diagrama acima mostra a atenção na camada 5 da rede. Em cada camada, o modelo constrói a sua compreensão da frase e “presta atenção a” uma parte específica da entrada que considera mais relevante para a etapa que está processando naquele momento, ou seja, está colocando mais atenção “no animal” para o “isso” nesta camada. Fonte: O Transformador ilustrado
Pense nisso como um banco de dados onde é possível recuperar a palavra com a pontuação mais alta que provavelmente está relacionada a “isso”.
Com este desenvolvimento, os modelos de linguagem não se limitaram a analisar sequências textuais curtas. Em vez disso, você poderia usar sequências de texto mais longas como entradas. Sabemos que expor as crianças a mais palavras através de “conversas envolventes” ajuda a melhorar o seu desenvolvimento linguístico.
Da mesma forma, com o novo mecanismo de atenção, os modelos de linguagem foram capazes de analisar mais e mais variados tipos de dados de treinamento textual. Isso incluía artigos da Wikipédia, fóruns online, Twitter e quaisquer outros dados de texto que você pudesse analisar. Tal como acontece com o desenvolvimento infantil, a exposição a todas estas palavras e a sua utilização em diferentes contextos ajudou os modelos linguísticos a desenvolver capacidades linguísticas novas e mais complicadas.
Foi nesta fase que começamos a ver uma corrida em escala onde as pessoas lançavam cada vez mais dados nestes modelos para ver o que podiam aprender. Esses dados não precisavam ser rotulados por humanos – os pesquisadores poderiam simplesmente vasculhar a Internet e alimentá-los no modelo e ver o que ele aprendia.
“Modelos como o BERT quebraram todos os recordes de processamento de linguagem natural disponíveis. Na verdade, os conjuntos de dados de teste usados para essas tarefas eram simples demais para esses modelos de transformadores”.
O modelo BERT (Bidirecional Encoder Representations from Transformers) merece menção especial por alguns motivos. Foi um dos primeiros modelos a utilizar o recurso de atenção que é o núcleo da arquitetura do Transformer. Em primeiro lugar, o BERT era bidirecional, pois podia visualizar o texto à esquerda e à direita da entrada atual. Isso era diferente dos RNNs, que só podiam processar texto sequencialmente da esquerda para a direita. Em segundo lugar, o BERT também utilizou uma nova técnica de treinamento chamada “mascaramento” que, de certa forma, forçou o modelo a aprender o significado de diferentes entradas “ocultando” ou “mascarando” tokens aleatórios para garantir que o modelo não pudesse “trapacear” e concentre-se em um único token em cada iteração. E, finalmente, o BERT pode ser ajustado para realizar diferentes tarefas de PNL. Não precisou ser treinado do zero para essas tarefas.
Os resultados foram surpreendentes. Modelos como o BERT quebraram todos os recordes de processamento de linguagem natural disponíveis. Na verdade, os conjuntos de dados de teste usados para essas tarefas eram simples demais para esses modelos de transformadores.
Agora tínhamos a capacidade de treinar grandes modelos de linguagem que serviam como modelos básicos para novas tarefas de processamento de linguagem natural. Anteriormente, as pessoas treinavam seus modelos do zero. Mas agora os modelos pré-treinados como o BERT e os primeiros modelos GPT eram tão bons que não fazia sentido fazer você mesmo. Na verdade, esses modelos eram tão bons que as pessoas descobriram que podiam realizar novas tarefas com relativamente poucos exemplos – eles foram descritos como “alunos de poucas tentativas”, semelhante ao modo como a maioria das pessoas não precisa de muitos exemplos para compreender novos conceitos.
Este foi um enorme ponto de inflexão no desenvolvimento destes modelos e das suas capacidades linguísticas. Agora só precisávamos melhorar a elaboração de instruções.
Modelo 4 – Instruções de aprendizagem com InstructGPT
Uma das coisas que as crianças aprendem no estágio final da aquisição da linguagem, o estágio de múltiplas palavras, é a capacidade de usar palavras funcionais para conectar os elementos que transportam informações em uma frase. Palavras funcionais nos falam sobre a relação entre diferentes palavras em uma frase. Se quisermos criar instruções, os modelos de linguagem precisarão ser capazes de criar frases com palavras de conteúdo e palavras funcionais que capturem relacionamentos complexos. Por exemplo, a instrução a seguir tem as palavras de função destacadas em negrito:
- “ Quero que você escreva uma carta…”
- “Diga -me o que você pensa sobre o texto acima ”
Mas antes que pudéssemos tentar treinar modelos de linguagem para seguir instruções, precisávamos entender exatamente o que eles já sabiam sobre instruções.
O GPT-3 da OpenAI foi lançado em 2020. Foi um vislumbre do que esses modelos eram capazes, mas ainda precisávamos entender como desbloquear os recursos subjacentes desses modelos. Como poderíamos interagir com esses modelos para fazê-los executar tarefas diferentes?
Por exemplo, o GPT-3 mostrou que o aumento do tamanho do modelo e dos dados de treinamento permitiu o que os autores chamaram de “meta-aprendizagem” – é aqui que o modelo de linguagem desenvolve um amplo conjunto de habilidades linguísticas, muitas das quais eram inesperadas, e pode usar essas habilidades. habilidades para compreender uma determinada tarefa.
“O modelo seria capaz de compreender a intenção da instrução e executar a tarefa, em vez de simplesmente prever a próxima palavra?”
Lembre-se de que os modelos de linguagem GPT-3 e anteriores não foram projetados para desenvolver essas habilidades – eles foram treinados principalmente para apenas prever a próxima palavra em uma sequência de texto. Mas, através de avanços com RNNs, Seq2Seq e redes de atenção, estes modelos foram capazes de processar mais texto, em sequências mais longas e focar melhor no contexto relevante.
Você pode pensar no GPT-3 como um teste para ver até onde poderíamos ir. Quão grande poderíamos fazer os modelos e quanto texto poderíamos alimentá-los? Depois de fazer isso, em vez de apenas alimentar o modelo com algum texto de entrada para que ele seja concluído, poderíamos usar o texto de entrada como uma instrução. O modelo seria capaz de compreender a intenção da instrução e executar a tarefa, em vez de simplesmente prever a próxima palavra? De certa forma, foi como tentar entender em que estágio de aquisição da linguagem esses modelos haviam atingido.
Agora descrevemos isso como “promover”, mas em 2020, na época em que o artigo foi publicado, esse era um conceito muito novo.
Alucinações e alinhamento
O problema com o GPT-3, como sabemos agora, era que ele não era muito bom em seguir as instruções do texto de entrada. GPT-3 pode seguir instruções, mas perde a atenção facilmente, só consegue entender instruções simples e tende a inventar coisas. Em outras palavras, os modelos não estão “alinhados” com as nossas intenções. Portanto, o problema agora não é tanto melhorar a capacidade linguística dos modelos, mas sim a sua capacidade de seguir instruções.
É importante notar que o GPT-3 nunca foi realmente treinado com base em instruções. Não foi dito o que era uma instrução, ou como ela diferia de outro texto, ou como deveria seguir as instruções. De certa forma, ele foi “enganado” para seguir instruções, fazendo com que “completasse” um prompt como outras sequências de texto. Como resultado, a OpenAI precisava treinar um modelo que fosse mais capaz de seguir instruções como um ser humano. E eles fizeram isso em um artigo apropriadamente intitulado Treinamento de modelos de linguagem para seguir instruções com feedback humano publicado no início de 2022. O InstructGPT provaria ser um precursor do ChatGPT no final daquele mesmo ano.
As etapas descritas nesse artigo também foram usadas para treinar o ChatGPT. O treinamento de instrução seguiu 3 etapas principais:
- Etapa 1 – Ajuste fino do GPT-3: Como o GPT-3 parecia funcionar tão bem com o aprendizado de poucas tentativas, o pensamento era que seria melhor se fosse ajustado com exemplos de instrução de alta qualidade. O objetivo era facilitar o alinhamento da intenção da instrução com a resposta gerada. Para fazer isso, a OpenAI fez com que rotuladores humanos criassem respostas a alguns prompts enviados por pessoas que usavam GPT-3. Ao usar instruções reais, os autores esperavam capturar uma “distribuição” realista de tarefas que os usuários estavam tentando fazer com que o GPT-3 executasse. Elas foram usadas para ajustar o GPT-3 para ajudá-lo a melhorar sua capacidade de resposta imediata.
- Etapa 2 - Faça com que os humanos classifiquem o novo e aprimorado GPT-3: Para avaliar o novo GPT-3 ajustado com instruções, os rotuladores agora avaliaram o desempenho dos modelos em diferentes prompts, sem resposta predefinida. A classificação foi relacionada a importantes fatores de alinhamento, como ser útil, verdadeiro e não tóxico, tendencioso ou prejudicial. Portanto, atribua uma tarefa ao modelo e avalie seu desempenho com base nessas métricas. O resultado deste exercício de classificação foi então usado para treinar um modelo separado para prever quais resultados os rotuladores provavelmente prefeririam. Este modelo é conhecido como modelo de recompensa (RM).
- Passo 3 – Use o RM para treinar em mais exemplos: Finalmente, o RM foi usado para treinar o novo modelo de instrução para gerar melhor respostas que estejam alinhadas com as preferências humanas.
É complicado compreender completamente o que está acontecendo aqui com o Aprendizado por Reforço com Feedback Humano (RLHF), modelos de recompensa, atualizações de políticas e assim por diante.
Uma maneira simples de pensar nisso é que se trata apenas de uma forma de permitir que os humanos gerem melhores exemplos de como seguir instruções. Por exemplo, pense em como você tentaria ensinar uma criança a agradecer:
- Pai: “Quando alguém te dá X, você agradece”. Esta é a etapa 1, um exemplo de conjunto de dados de prompts e respostas apropriadas
- Pai: “Agora, o que você diz para Y aqui?”. Esta é a etapa 2, onde pedimos à criança que gere uma resposta e então os pais avaliarão isso. “Sim, isso é bom.”
- Finalmente, em encontros subsequentes, os pais recompensarão a criança com base em bons ou maus exemplos de respostas em cenários semelhantes no futuro. Esta é a etapa 3, onde ocorre o comportamento de reforço.
Por sua vez, a OpenAI afirma que tudo o que faz é simplesmente desbloquear capacidades que já estavam presentes em modelos como o GPT-3, “mas eram difíceis de obter apenas através da engenharia imediata”, como afirma o documento.
Em outras palavras, o ChatGPT não está realmente aprendendo “ novos ” recursos, mas simplesmente aprendendo uma “ interface ” linguística melhor para utilizá-los.
A magia da linguagem
ChatGPT parece um salto mágico, mas na verdade é o resultado de um meticuloso progresso tecnológico ao longo de décadas.
Ao observar alguns dos principais desenvolvimentos no campo da IA e da PNL na última década, podemos ver como o ChatGPT está “sobre os ombros de gigantes”. Os modelos anteriores aprenderam pela primeira vez a identificar o significado das palavras. Em seguida, os modelos subsequentes juntaram essas palavras e poderíamos treiná-las para realizar tarefas como tradução. Assim que conseguiram processar frases, desenvolvemos técnicas que permitiram a estes modelos de linguagem processar cada vez mais texto e desenvolver a capacidade de aplicar estas aprendizagens a tarefas novas e imprevistas. E então, com o ChatGPT finalmente desenvolvemos a capacidade de interagir melhor com esses modelos, especificando nossas instruções em formato de linguagem natural.
“Como a linguagem é o veículo para nossos pensamentos, será que ensinar aos computadores todo o poder da linguagem levará a, bem, uma inteligência artificial independente?”
No entanto, a evolução da PNL revela uma magia mais profunda para a qual normalmente somos cegos – a magia da própria linguagem e como nós, como humanos, a adquirimos.
Ainda existem muitas questões em aberto e controvérsias sobre como as crianças aprendem a língua. Também há dúvidas sobre se existe uma estrutura subjacente comum a todas as línguas. Os humanos evoluíram para usar a linguagem ou foi o contrário?
O curioso é que, à medida que o ChatGPT e seus descendentes melhoram o seu desenvolvimento linguístico, estes modelos podem ajudar a responder algumas destas importantes questões.
Finalmente, como a linguagem é o veículo para os nossos pensamentos, será que ensinar aos computadores todo o poder da linguagem levará a, bem, uma inteligência artificial independente? Como sempre na vida, ainda há muito para aprender.
