
Hackeando o Topic Graph com a Wikipedia e a API de idiomas do Google
Publicados: 2019-08-27Um dos meus decks de slides favoritos dos últimos dez anos foi feito por Mark Johnstone em 2014, enquanto ele ainda estava com o Distilled. O deck se chamava Como produzir melhores ideias de conteúdo e eu o usei como minha bíblia por alguns anos enquanto montava equipes para fazer o trabalho duro de promoção de conteúdo.
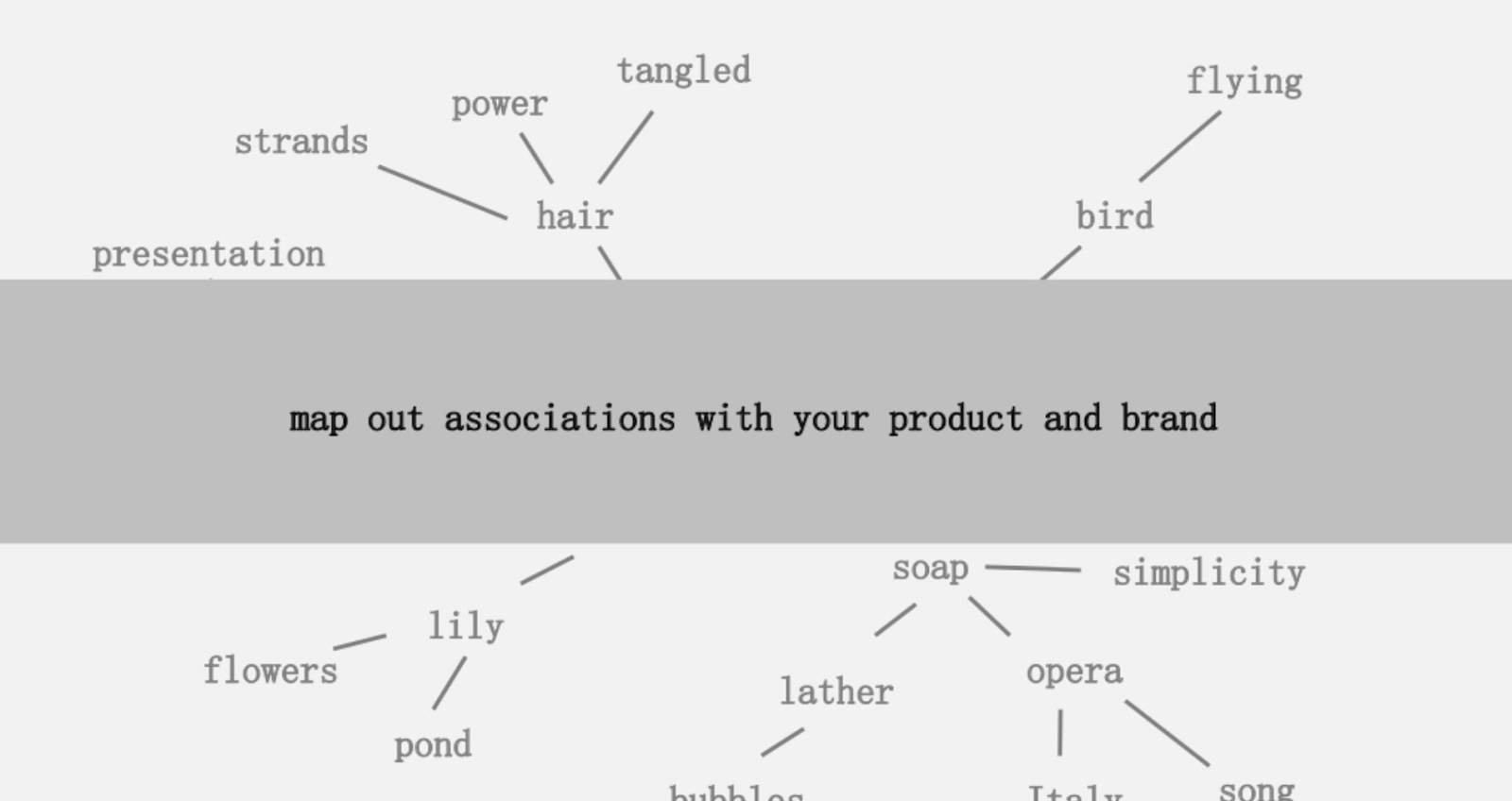
Uma das ideias oferecidas foi criar um mapeamento visual da conectividade das palavras associadas ao seu produto ou marca para que você possa se afastar e procurar maneiras de combinar as associações em algo interessante. O objetivo é a produção de ideias, que ele define como “ uma nova combinação de elementos previamente desconectados de uma forma que agrega valor”.
Neste artigo, adotamos uma abordagem muito mais voltada para o lado esquerdo do cérebro, usando Python, a API de linguagem do Google, juntamente com a Wikipedia, para explorar associações de entidades que existem a partir de um tópico semente. O objetivo é uma visão de alto nível dos relacionamentos de entidade ao longo do gráfico de tópicos. Este artigo não é para o leitor médio. Os leitores que estão familiarizados com Python e têm pelo menos um nível básico de habilidade de codificação acharão muito mais instrutivo.
A ideia
Seguindo a ideia de mapeamento de Mark Johnstone, pensei que seria interessante deixar o Google e a Wikipedia definirem uma estrutura de tópicos a partir de um tópico inicial ou página da web. O objetivo é construir o mapeamento de relacionamentos com o tópico principal visualmente, em um gráfico em forma de árvore que pode ser revisado para procurar conexões e possivelmente gerar ideias de conteúdo. A imagem a seguir representa a ideia inicial do design.
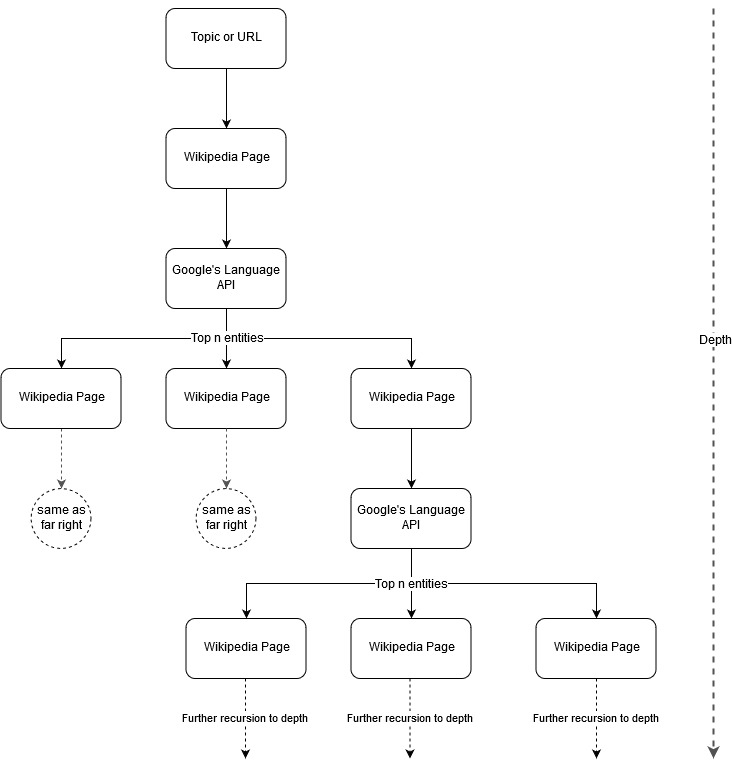
Essencialmente, damos à ferramenta um tópico ou URL e permitimos que a API de idiomas do Google selecione as principais n (3 em nossos exemplos) entidades (que incluem URLs da Wikipedia) para cada página de entidade e continuamos a construir recursivamente um gráfico de rede para cada entidade encontrada até uma profundidade máxima.
Histórico das ferramentas usadas
API de idiomas do Google
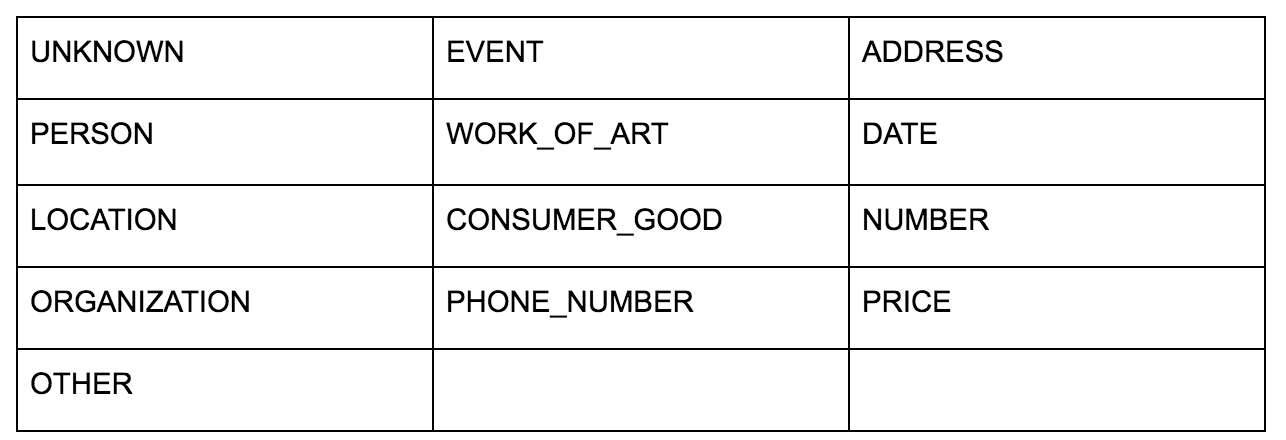
A API de idiomas do Google permite que você transmita texto simples ou HTML e retorna magicamente todas as várias entidades associadas ao conteúdo. A API faz mais do que isso, mas para esta análise, focaremos apenas nesta parte. Aqui está uma lista dos tipos de entidades que ele retorna:
A identificação de entidades tem sido uma parte fundamental do Processamento de Linguagem Natural (PLN) há muito tempo e a terminologia correta para a tarefa é Reconhecimento de Entidades Nomeadas (NER). O NER é uma tarefa difícil porque muitas palavras têm significados diferentes com base no contexto usado, portanto, as ferramentas ou APIs de PNL precisam entender todo o contexto em torno dos termos para poder identificá-los adequadamente como uma entidade específica.
Eu dei uma visão bem detalhada desta API, e entidades em particular, em um artigo em opensource.com se você quiser se atualizar em algum contexto antes de terminar este artigo.
Um recurso interessante da API de idiomas do Google é que, além de encontrar entidades relevantes, ela também marca o quanto elas estão relacionadas ao documento geral (saliência) e, para alguns, fornece um artigo relacionado da Wikipedia (gráfico de conhecimento) que representa a entidade.
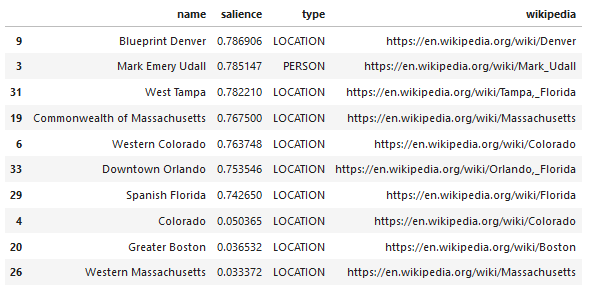
Aqui está um exemplo de saída do que a API retorna (classificada por saliência):
Desenvolvedor Oncrawl
 Saber mais
Saber maisPitão
Python é uma linguagem de software que se tornou popular no espaço da ciência de dados devido a um grande e crescente conjunto de bibliotecas que facilitam a ingestão, limpeza, manipulação e análise de grandes conjuntos de dados. Ele também se beneficia de um ambiente colaborativo chamado notebooks Jupyter, que permite que os usuários testem e anotem facilmente seu código sem esforço.
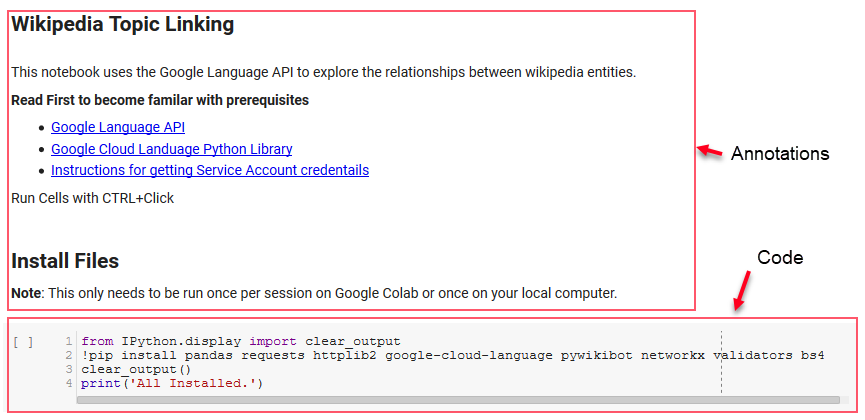
Para esta revisão, usaremos algumas bibliotecas importantes que nos permitirão fazer algumas coisas interessantes com os dados de PNL do Google.
- Pandas: Pense em ser capaz de criar scripts no Microsoft Excel para ler, salvar, analisar ou reorganizar planilhas e você terá uma ideia do que o Pandas faz. Pandas é incrível. (link)
- Networkx: Networkx é uma ferramenta para construção de grafos de nós e arestas que definem as relações entre os nós. Ele também possui suporte embutido para plotar os gráficos para que sejam fáceis de visualizar. (link)
- Pywikibot: Pywikibot é uma biblioteca que permite interagir com a Wikipédia para pesquisar, editar, encontrar relacionamentos, etc., com todo o conteúdo de cada site da Wikipédia. (link)
O processo
Estamos compartilhando aqui um bloco de anotações do Google Colab que pode ser usado para acompanhar. (Agradecimentos especiais a Tyler Reardon por uma verificação de sanidade no artigo e neste caderno.)
Configurando
As primeiras células do notebook lidam com a instalação de algumas bibliotecas, disponibilizando essas bibliotecas para o Python e fornecendo credenciais e arquivo de configuração para a API de linguagem do Google e o Pywikibot, respectivamente. Aqui estão todas as bibliotecas que precisamos instalar para garantir que a ferramenta possa ser executada:
- pandas
- solicitações de
- httplib2
- google-cloud-language
- pywikibot
- rede x
- validadores
- Bs4
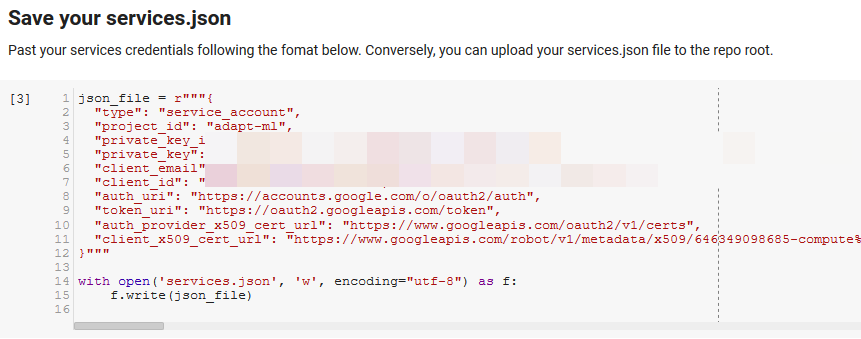
Observação: a parte mais difícil de executar este notebook é obter credenciais do Google para acessar suas APIs. Para aqueles inexperientes com isso, isso levará uma hora ou mais para descobrir. Vinculamos as Instruções para obter as credenciais da conta de serviço na parte superior do notebook para ajudá-lo. Abaixo está um exemplo de como incluímos o nosso.
Funções para a vitória
Na célula indicada por “Definir algumas funções para o Google NLP”, desenvolvemos oito funções que lidam com coisas como consultar a API de linguagem, interagir com a Wikipedia, extrair texto de página da Web e construir e plotar gráficos. As funções são essencialmente pequenas unidades de código que recebem alguns dados de configuração, fazem algum trabalho e produzem algo. Todas as funções são comentadas para informar as variáveis que elas recebem e o que elas produzem.

Testando a API
As duas células a seguir pegam um URL, extraem o texto do URL e extraem as entidades da API de idiomas do Google. Um puxa apenas entidades que têm URLs da Wikipedia e o outro puxa todas as entidades dessa página.
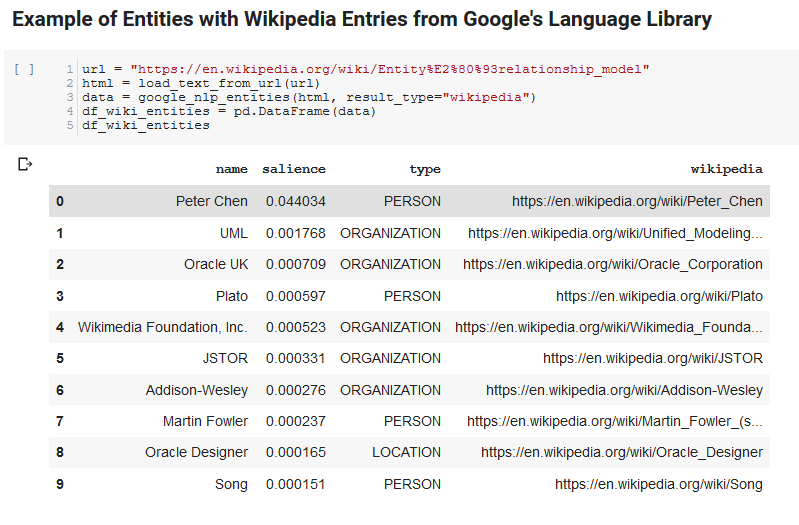
Este foi um primeiro passo importante apenas para obter a parte de extração de conteúdo correta e entender como a API de idioma funcionava e retornava os dados.
Redex
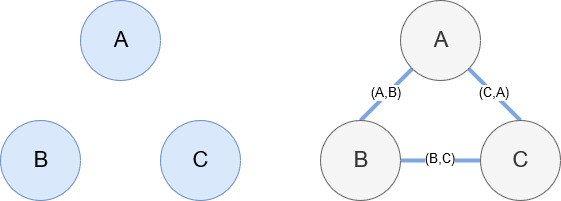
Networkx, como mencionado anteriormente, é uma biblioteca maravilhosa que é bastante intuitiva para brincar. Essencialmente, você precisa dizer quais são seus nós e como os nós estão conectados. Por exemplo, na imagem abaixo, damos ao Networkx três nós (A,B,C). Em seguida, informamos ao Networkx que eles estão conectados por arestas (A,B), (B,C), (C,A) definindo os relacionamentos entre os nós. Para nosso uso, as entidades com URLs da Wikipedia serão os nós e as bordas são definidas por novas entidades encontradas em uma página de entidade atual. Então, se estivermos revisando a página da Wikipédia para a Entidade A, e nessa página a Entidade B for descoberta, então essa é uma borda entre a Entidade A e a Entidade B.
Juntando tudo
A próxima seção do bloco de anotações é chamada de Ramificação de tópicos da Wikipedia por URL. É aqui que a mágica acontece. Havíamos definido uma função especial (recurse_entities) anteriormente que se repete através de páginas na Wikipedia seguindo novas entidades definidas pela API de linguagem do Google. Também adicionamos uma função realmente difícil de entender (hierarchy_pos) que tiramos do Stack Overflow que faz um bom trabalho ao apresentar um gráfico semelhante a uma árvore com muitos nós. Na célula abaixo, definimos a entrada como “Search Engine Optimization” e especificamos uma profundidade de 3 (é quantas páginas ele segue recursivamente) e um limite de 3 (é quantas entidades ele puxa por página).
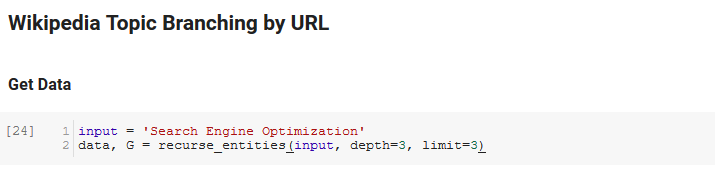
Executando-o para o termo “Search Engine Optimization” podemos ver o seguinte caminho que a ferramenta percorreu, iniciando na página Search Engine Optimization da Wikipedia (Nível 0) e seguindo, recursivamente, as páginas até a profundidade máxima especificada (3).

Em seguida, pegamos todas as entidades encontradas e as adicionamos a um Pandas DataFrame, o que torna muito fácil salvar como um CSV. Classificamos esses dados por saliência (que é a importância da entidade para a página em que foi encontrada), mas essa pontuação é um pouco enganosa nesse contexto porque não informa o quanto a entidade está relacionada ao seu termo original (“ Motor de Otimização de Busca"). Deixaremos esse trabalho adicional para o leitor.

Por fim, traçamos o gráfico construído pela ferramenta para mostrar a conectividade de todas as entidades. Na célula abaixo, os parâmetros que você pode passar para a função são: ( G : o gráfico construído anteriormente pela função recurse_entities, w: a largura do gráfico, h: a altura do gráfico, c: a porcentagem circular da plot e nome do arquivo: o arquivo PNG que é salvo na pasta de imagens.)

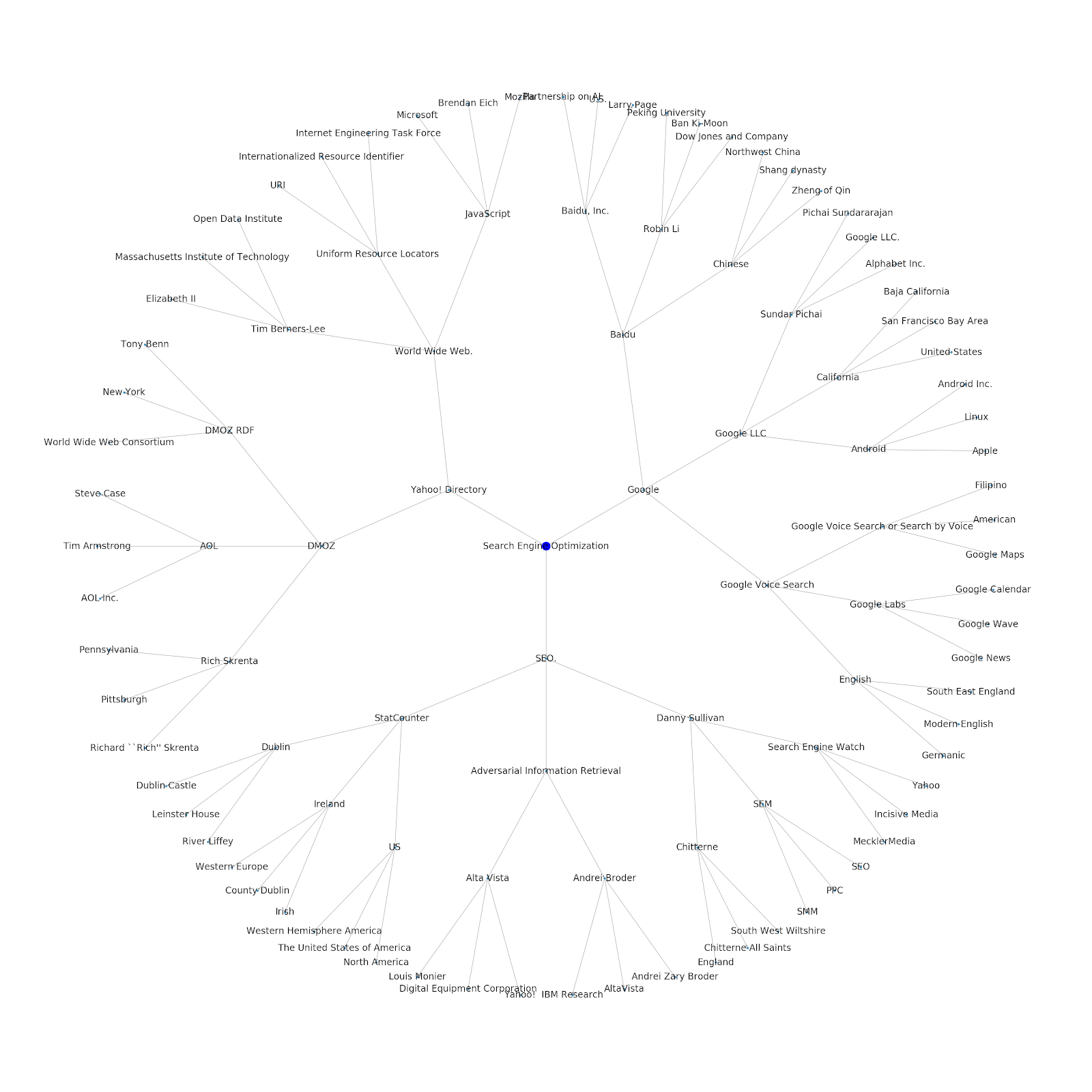
Adicionamos a capacidade de fornecer um tópico de semente ou um URL de semente. Nesse caso, analisamos as entidades associadas ao artigo Os problemas de indexação do Google continuam, mas este é diferente
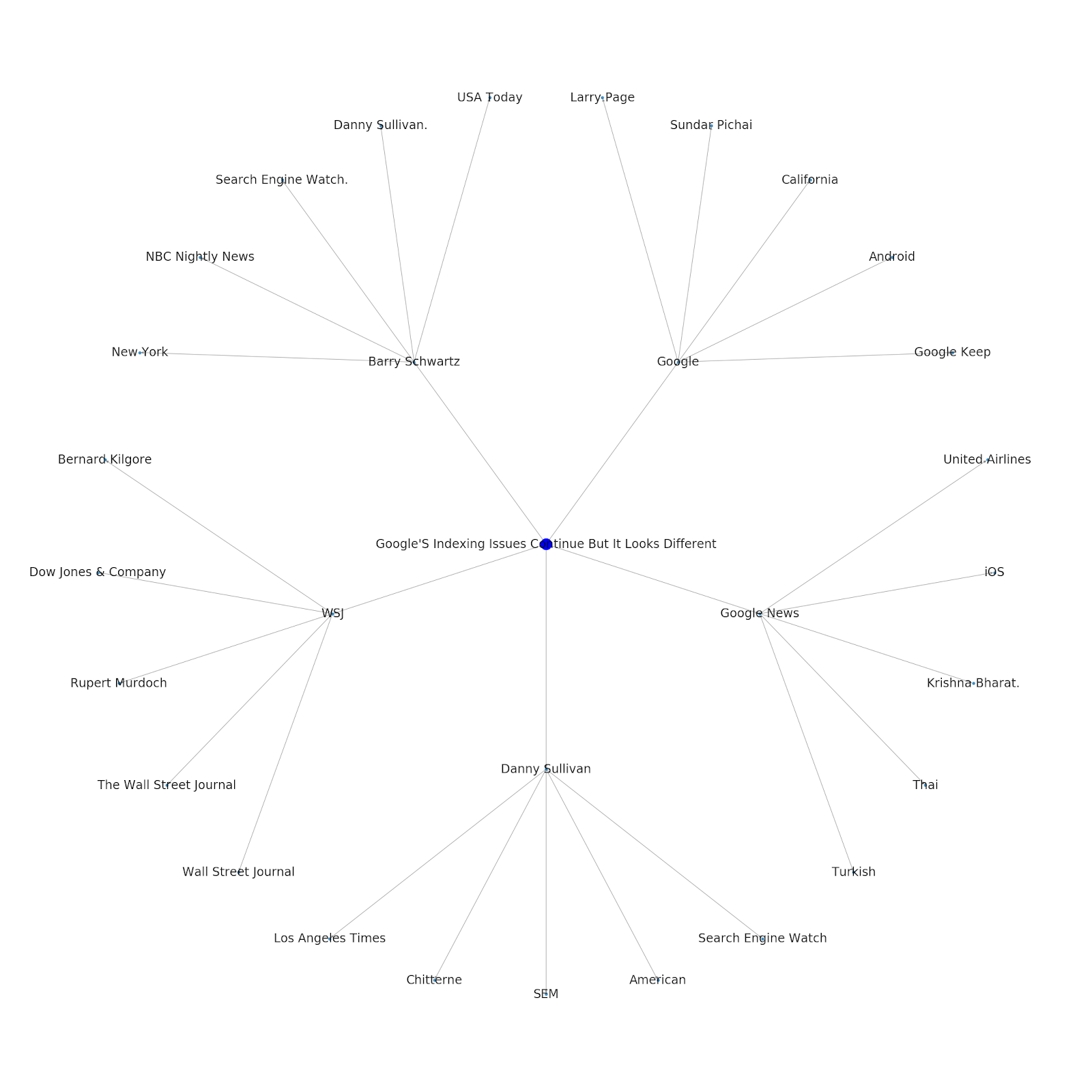
Aqui está o gráfico de entidade do Google/Wikipedia para Python.
O que isto significa
Compreender a camada de tópicos da internet é interessante do ponto de vista de SEO porque força você a pensar em termos de como as coisas estão conectadas e não apenas em consultas individuais. Como o Google está usando essa camada para combinar afinidades de usuários individuais com tópicos, conforme mencionado na reintrodução do Google Discover, ela pode se tornar um fluxo de trabalho mais importante para SEOs focados em dados. No gráfico “Python” acima, pode-se inferir que a familiaridade de um usuário com os tópicos relacionados a um tópico semente pode ser uma medida razoável de seu nível de conhecimento com o tópico semente.
O exemplo abaixo mostra dois usuários com destaques verdes mostrando seu interesse histórico ou afinidade com tópicos relacionados. O usuário à esquerda, entendendo o que é um IDE e entendendo o que PyPy e CPython significam, seria um usuário muito mais experiente com Python do que alguém que sabe que é uma linguagem, mas não muito mais. Isso seria fácil de transformar em pontuações numéricas para cada tópico, para cada usuário.

Conclusão
Meu objetivo hoje era compartilhar o que é um processo bastante padrão pelo qual passo para testar e revisar a eficácia de várias ferramentas ou APIs usando Jupyter Notebooks. Explorar o gráfico de tópicos é incrivelmente interessante e esperamos que você ache que as ferramentas compartilhadas lhe dão a vantagem necessária para começar a explorar por si mesmo. Com essas ferramentas, você pode criar gráficos de tópicos que exploram muitos níveis de relacionamento, limitados apenas à extensão da cota da API de idiomas do Google (que é de 800.000 por dia). (Atualização: o preço é baseado em unidades de 1.000 caracteres unicode enviados para a API e é gratuito até 5k unidades. Como os artigos da Wikipedia podem ficar longos, você deve observar seus gastos. Dica de chapéu para John Murch por apontar isso.) Se você aprimorar o notebook ou encontrar casos interessantes, espero que me avise. Você pode me encontrar em @jroakes no Twitter.