
As chaves para construir um Robots.txt que funcione
Publicados: 2020-02-18Bots, também conhecidos como Crawlers ou Spiders, são programas que “viajam” pela Web automaticamente de um site para outro usando os links como caminho. Embora sempre tenham apresentado certas curiosidades, os arquivos robot.txt podem ser ferramentas muito eficazes. Mecanismos de busca como Google e Bing usam bots para rastrear o conteúdo da web. O arquivo robots.txt fornece orientação aos diferentes bots sobre quais páginas eles não devem rastrear em seu site. Você também pode vincular seu sitemap XML a partir do robots.txt para que o bot tenha um mapa de todas as páginas que ele deve rastrear.
Por que o robots.txt é útil?
robots.txt limita a quantidade de páginas que um bot precisa rastrear e indexar no caso de bots de mecanismos de pesquisa. Se você quiser evitar que o Google rastreie páginas de administração, você pode bloqueá-las em seu robots.txt para tentar manter uma página fora dos servidores do Google.
Além de impedir que as páginas sejam indexadas, o robots.txt é ótimo para otimizar o orçamento de rastreamento. O orçamento de rastreamento é o número de páginas que o Google determinou que ele rastreará em seu site. Normalmente, sites com mais autoridade e mais páginas têm um orçamento de rastreamento maior do que sites com baixo número de páginas e baixa autoridade. Como não sabemos quanto orçamento de rastreamento é atribuído ao nosso site, queremos aproveitar ao máximo esse tempo permitindo que o Googlebot acesse as páginas mais importantes em vez de rastrear páginas que não queremos que sejam indexadas.
Um detalhe muito importante que você precisa saber sobre o robots.txt é que, embora o Google não rastreie as páginas bloqueadas pelo robots.txt, elas ainda podem ser indexadas se a página estiver vinculada a outro site. Para impedir adequadamente que suas páginas sejam indexadas e apareçam nos resultados da Pesquisa Google, você precisa proteger com senha os arquivos em seu servidor, usar a metatag noindex ou o cabeçalho de resposta ou remover a página completamente (responda com 404 ou 410). Para obter mais informações sobre rastreamento e controle de indexação, você pode ler o guia robots.txt do OnCrawl.
[Estudo de caso] Gerenciando o rastreamento de bot do Google
 Leia o estudo de caso
Leia o estudo de casoSintaxe correta do Robots.txt
A sintaxe do robots.txt às vezes pode ser um pouco complicada, pois diferentes rastreadores interpretam a sintaxe de maneira diferente. Além disso, alguns rastreadores não confiáveis veem as diretivas do robots.txt como sugestões e não como uma regra definitiva que eles precisam seguir. Se você tiver informações confidenciais em seu site, é importante usar proteção por senha além de bloquear rastreadores usando o robots.txt
Abaixo, listei algumas coisas que você precisa ter em mente ao trabalhar em seu robots.txt:
- O arquivo robots.txt precisa estar no domínio e não em um subdiretório. Os rastreadores não verificam arquivos robots.txt em subdiretórios.
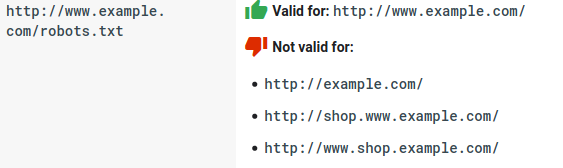
- Cada subdomínio precisa de seu próprio arquivo robots.txt:
- Robots.txt diferencia maiúsculas de minúsculas:
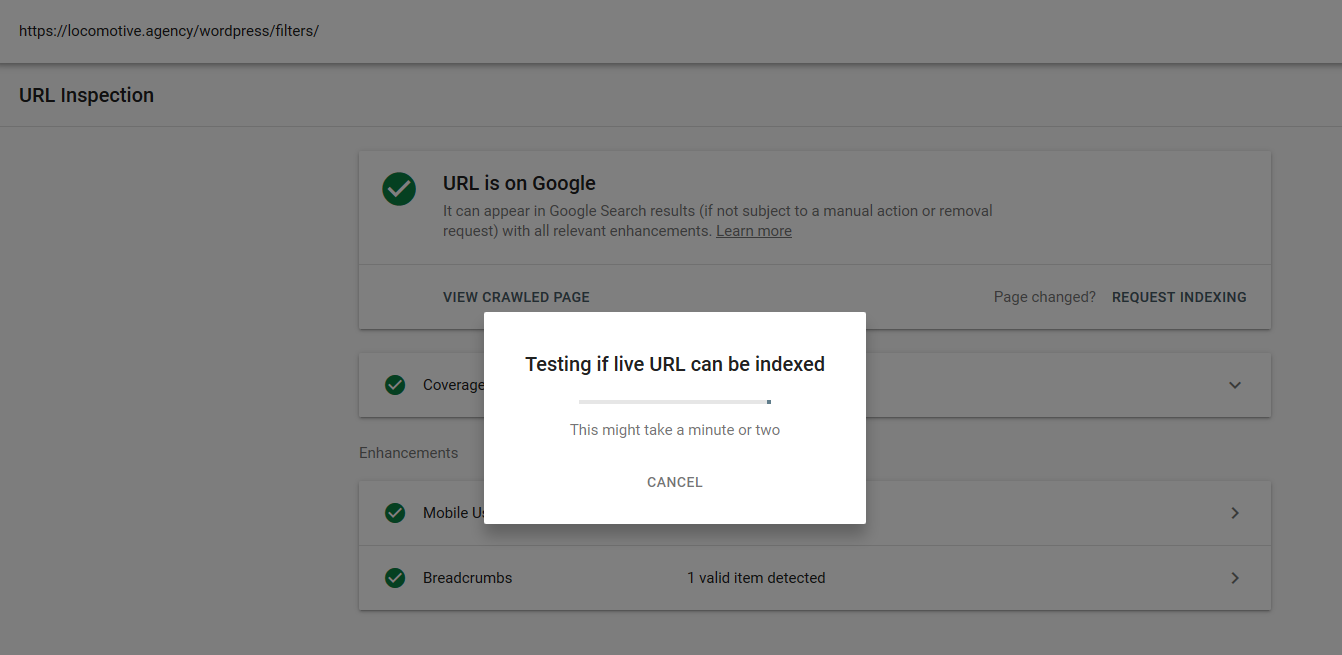
- A diretiva noindex: Quando você usa noindex no robots.txt, ele funcionará da mesma forma que disallow. O Google deixará de rastrear a página, mas a manterá em seu índice. @jroakes e eu criamos um teste onde usamos a diretiva Noindex no artigo /wordpress/filters/ e submetemos a página no Google. Você pode ver na captura de tela abaixo que mostra que o URL foi bloqueado:
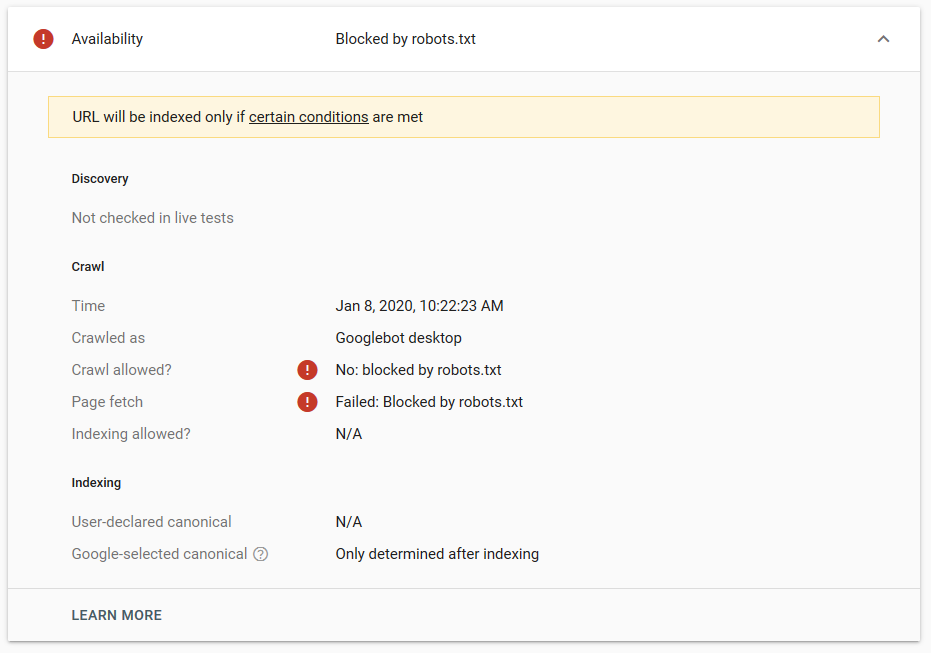
Fizemos vários testes no Google e a página nunca foi removida do índice:

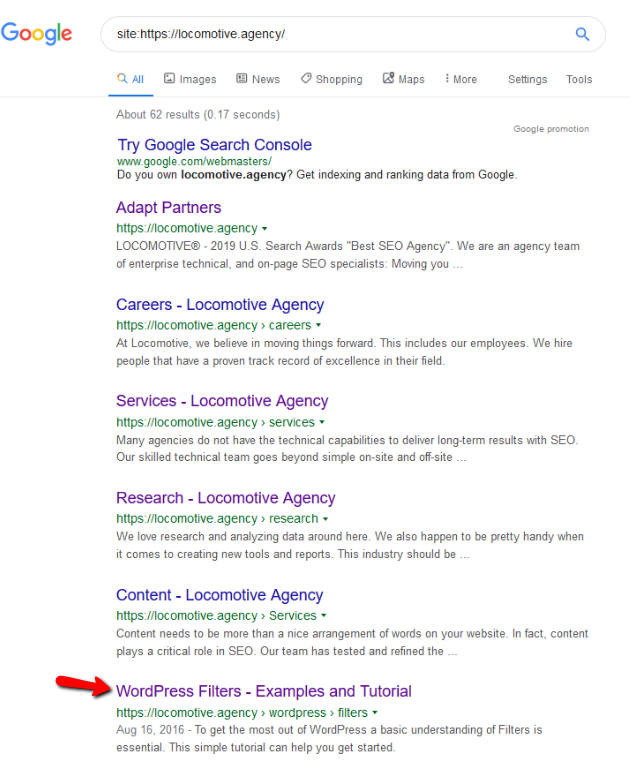
Houve uma discussão no ano passado sobre a diretiva noindex trabalhando no robots.txt, removendo páginas menos o Google. Aqui está um tópico onde Gary Illyes afirmou que estava indo embora. Neste teste podemos ver que a solução do Google está em vigor, pois a diretiva noindex não removeu a página dos resultados da pesquisa.
Recentemente, surgiu outro tópico interessante no twitter de Christian Oliveira, onde ele compartilhou vários detalhes a serem levados em consideração ao trabalhar em seu robots.txt.
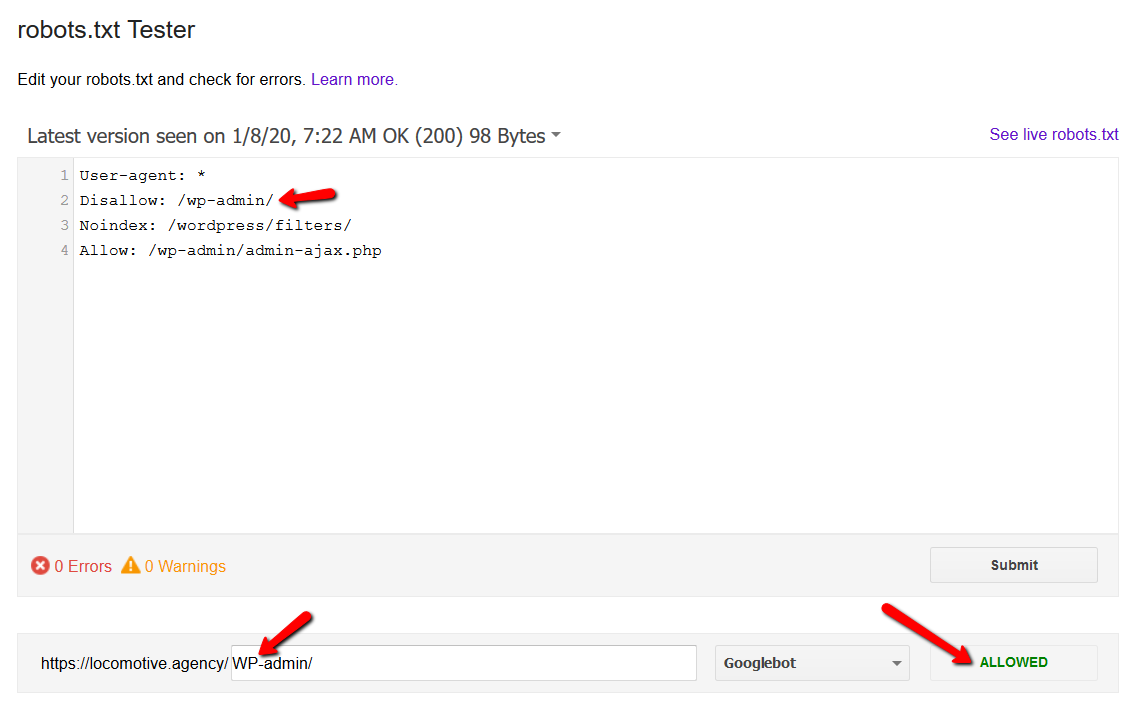
- Se quisermos ter regras genéricas e regras apenas para o Googlebot, precisamos duplicar todas as regras genéricas no conjunto de regras User-agent: Google bot. Se eles não forem incluídos, o Googlebot ignorará todas as regras:

- Outro comportamento confuso é que a prioridade das regras (dentro do mesmo grupo User-agent) não é determinada por sua ordem, mas pelo comprimento da regra.
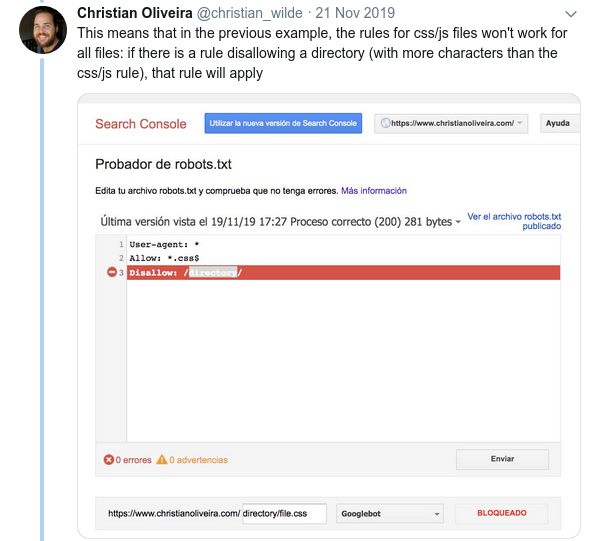
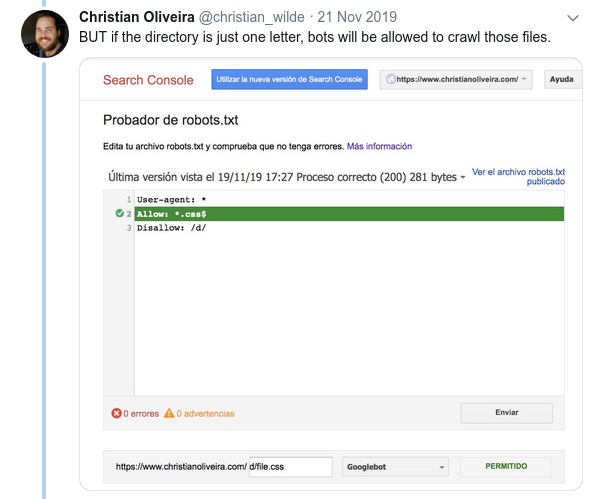
- Agora, quando você tem duas regras, com o mesmo tamanho e comportamento oposto (uma permitindo o rastreamento e outra não permitindo), a regra menos restritiva se aplica:
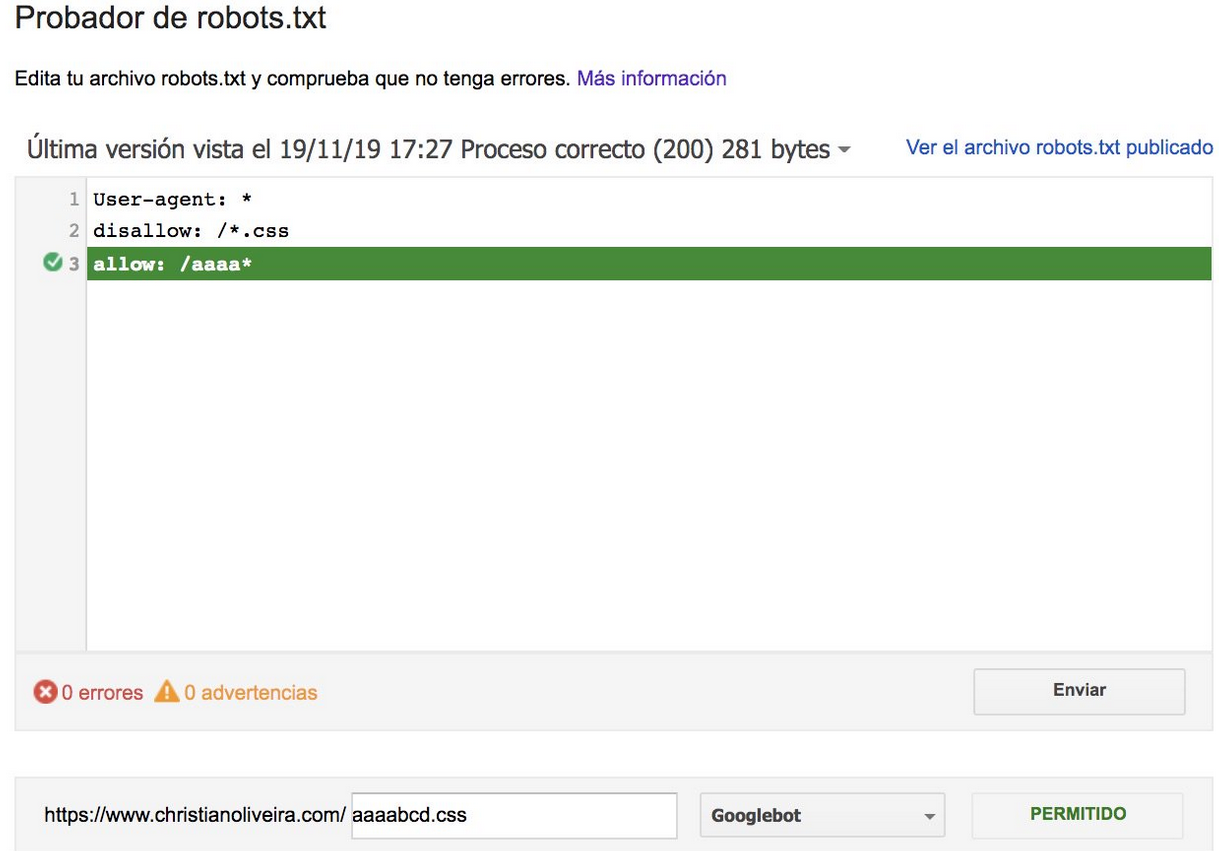
Para mais exemplos, leia as especificações do robots.txt fornecidas pelo Google.
Ferramentas para testar seu Robots.txt
Se você quiser testar seu arquivo robots.txt, existem várias ferramentas que podem ajudá-lo e também alguns repositórios do github se você quiser fazer o seu próprio:
- Destilado
- O Google deixou a ferramenta de teste robots.txt do antigo Google Search Console aqui
- Em Python
- Em C++
Resultados da amostra: uso eficaz de um Robots.txt para comércio eletrônico
Abaixo, incluí um caso em que estávamos trabalhando com um site Magento que não tinha um arquivo robots.txt. Magento, assim como outros CMS, têm páginas de administração e diretórios com arquivos que não queremos que o Google rastreie. Abaixo, incluímos um exemplo de alguns dos diretórios que incluímos no robots.txt:
# # Diretórios gerais do Magento Não permitir: /aplicativo/ Não permitir: / downloader / Não permitir: / erros / Não permitir: / inclui / Não permitir: /lib/ Não permitir: /pkginfo / Não permitir: / shell / Não permitir: /var/ # # Não indexe a página de pesquisa e categorias de links não otimizadas Não permitir: /catalog/product_compare/ Não permitir: /catalog/category/view/ Não permitir: /catalog/product/view/ Não permitir: /catalog/product/gallery/ Não permitir: /catalogsearch/
A enorme quantidade de páginas que não deveriam ser rastreadas estava afetando o orçamento de rastreamento e o Googlebot não conseguia rastrear todas as páginas de produtos no site.
Você pode ver na imagem abaixo como as páginas indexadas aumentaram após 25 de outubro, quando o robots.txt foi implementado:
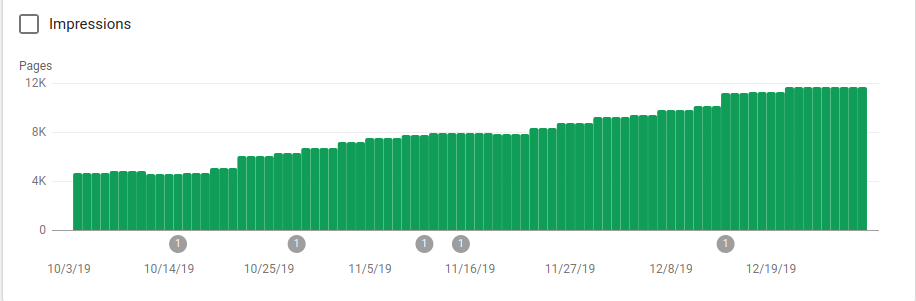
Além de bloquear vários diretórios que não deveriam ser rastreados, os robôs incluíam um link para os mapas do site. Na captura de tela abaixo você pode ver como o número de páginas indexadas aumentou em comparação com as páginas excluídas:
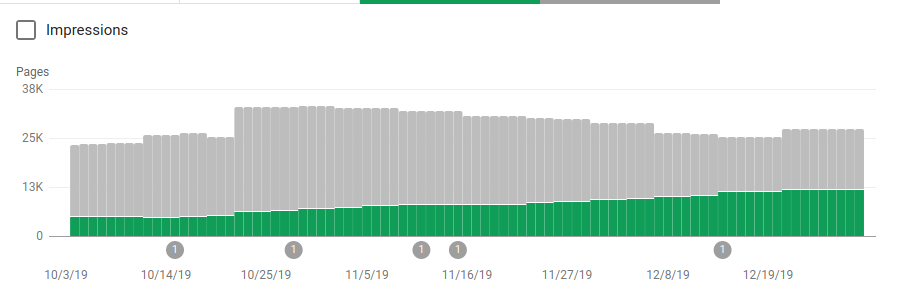
Há uma tendência positiva nas páginas válidas indexadas conforme mostrado pelas barras verdes e uma tendência negativa nas páginas excluídas representadas pelas barras cinzas.
Empacotando
A importância do robots.txt às vezes pode ser subestimada e, como você pode ver neste post, há muitos detalhes que precisam ser considerados ao criar um. Mas o trabalho compensa: mostrei alguns dos resultados positivos que você pode obter ao configurar um robots.txt corretamente.