
Por que mudamos para a computação sem servidor para implantar compilações personalizadas
Publicados: 2018-11-22
Foto de panumas nikhomkhai do Pexels
Como parte de nosso compromisso de capacitar os profissionais de marketing de desempenho para fazer mais, com menos, sem preocupações , as equipes da TUNE estão sempre buscando novas maneiras de atender nossos clientes. Nesse caso, nossa equipe de Engenharia de Soluções descobriu uma tecnologia que simplifica a forma como eles implantam e dão suporte a construções personalizadas em nossa plataforma. Como resultado, eles agora podem gastar mais tempo (e menos dinheiro) trabalhando com mais clientes para criar as soluções de que precisam.
Na TUNE, nos orgulhamos de fornecer uma plataforma de marketing de desempenho flexível e abrangente que permite que redes e anunciantes gerenciem suas campanhas de marketing digital, relacionamentos com editores, pagamentos e muito mais - diretamente da caixa, sem ter que escrever uma única linha de código . Mas às vezes, como acontece com outros sistemas SaaS totalmente gerenciados, nossos clientes exigem configurações, funcionalidades ou integrações personalizadas que só podem ser alcançadas arregaçando as mangas e acionando o antigo editor de código. Recentemente, fizemos a transição para uma nova tecnologia que está mudando a maneira como criamos essas soluções: computação sem servidor.
Neste post, abordarei os problemas que encontramos com o desenvolvimento personalizado, as etapas que seguimos para configurar nosso processo de compilação sem servidor e como essa nova metodologia está resolvendo os desafios de custo e escala.
Desafio: acompanhar a demanda por soluções personalizadas
Quando começamos a equipe de engenharia de soluções na TUNE, tratamos cada versão personalizada do cliente como uma versão separada. A maioria dessas compilações tinha um componente de front-end, que geralmente era implantado como uma página personalizada em nossa plataforma, e um componente de back-end que consistia em um servidor, um banco de dados e qualquer outra infraestrutura necessária para manter os servidores atualizados. -data e operacional.
No início, essa metodologia funcionou para nós. Por ter uma equipe pequena e enxuta com algumas compilações personalizadas complexas, nosso método de provisionar e configurar um servidor diferente para cada compilação funcionou para nós. Isso nos permitiu criar experiências incríveis para nossos clientes.
Mas à medida que o número de compilações crescia, começamos a ter problemas:
- Muitos servidores! Como você pode imaginar, provisionar um mínimo de duas caixas por compilação nos levou a ter muitos servidores. O grande número de servidores e todas as dores que os acompanham (como atualizações de segurança e backups) estavam nos custando mais tempo do que gostaríamos de admitir.
- Mantenha esses servidores ativos. Com cada servidor sendo sua própria entidade, éramos responsáveis por garantir que cada servidor estivesse sempre ativo e operacional.
- PHP não é para mim. A maioria de nossas compilações são geradas a partir de uma imagem base do Docker PHP. Mas à medida que nossa equipe crescia, sabíamos que forçar as pessoas a escrever suas compilações de clientes em PHP 5.0 quando eram um assistente do Python não fazia sentido.
- Isso está ficando caro. Com todos os nossos servidores implantados em ec2/RDS, estávamos começando a ver um custo mensal significativo.
- Segurança primeiro. Como esses serviços lidavam com dados confidenciais de clientes, tivemos que fornecer um método de autenticação para nossos URLs públicos para garantir a segurança desses dados.
- Crons são difíceis. Muitos serviços de back-end consistiam em scripts cron e não tínhamos uma maneira eficiente de gerenciá-los.
Com esses desafios surgindo, sabíamos que precisávamos encontrar uma maneira mais simples e econômica de fornecer funcionalidade de back-end às compilações de nossos clientes. Mas depois de muito debate e nenhum candidato claro para uma solução, estávamos começando a ficar sem ideias. (Além disso, com a demanda por novas construções personalizadas crescendo loucamente, o tempo definitivamente não estava do nosso lado.)
Solução: Computação sem servidor para o resgate
Se você ainda não ouviu falar de computação sem servidor , pode estar se perguntando a mesma coisa que estávamos quando ouvimos falar sobre isso. Como você pode executar o código sem um servidor? (Não se preocupe; sua compreensão fundamental de programação ainda está correta e não, não abusamos do especial de happy hour antes de escrever isso.)
“Sem servidor” é um termo muito confuso para uma nova tecnologia, porque – não sejamos bobos – definitivamente ainda existe um servidor executando código. Então, o que exatamente é serverless?
A computação sem servidor é um modelo de execução de computação em nuvem no qual o provedor de nuvem atua como servidor, gerenciando dinamicamente a alocação de recursos da máquina. – Wikipédia
As soluções em nuvem sem servidor permitem que você crie e execute aplicativos e serviços sem pensar nos aborrecimentos associados aos servidores. Essencialmente, a computação sem servidor permite que você faça o que faz melhor: escrever código.
O processo de configuração sem servidor
Para mostrar a você a essência de como a tecnologia sem servidor funciona, apresentarei as etapas que usamos para configurar essa funcionalidade.
Observação: existem muitos provedores de nuvem com funcionalidade sem servidor. Neste exemplo, usamos o AWS Lambda .

- Primeiro, crie uma nova função Lambda e selecione “ Blueprints ”. Em seguida, digite “ http ” no campo de palavra-chave e selecione Python ou Node microservice-http-endpoint. (Os blueprints são blocos de código pré-criados destinados a tornar o desenvolvimento mais rápido. Quão incrível é isso?) Depois de fazer uma seleção, clique em “ Configurar ”.
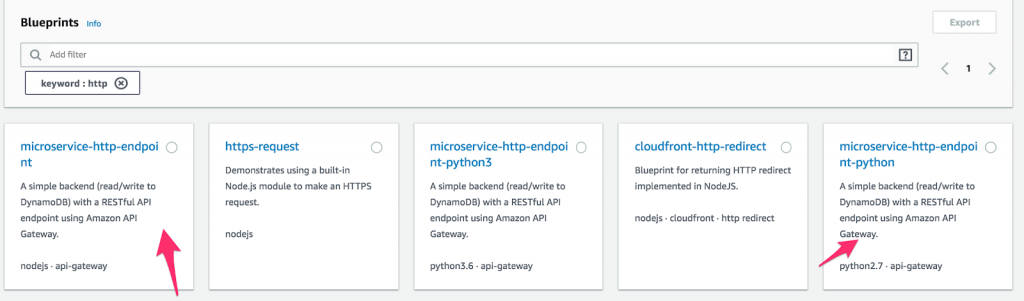
Como configurar uma função no AWS Lambda.
- Adicione um nome de função e uma função. Em seguida, selecione um gatilho do API Gateway com a opção de segurança “ Abrir com chave de API ”. Esse gateway de API fornecerá uma URL pública que acionará sua função Lambda. Adicionar a chave de API fornece um método de autenticação, que é altamente recomendado.
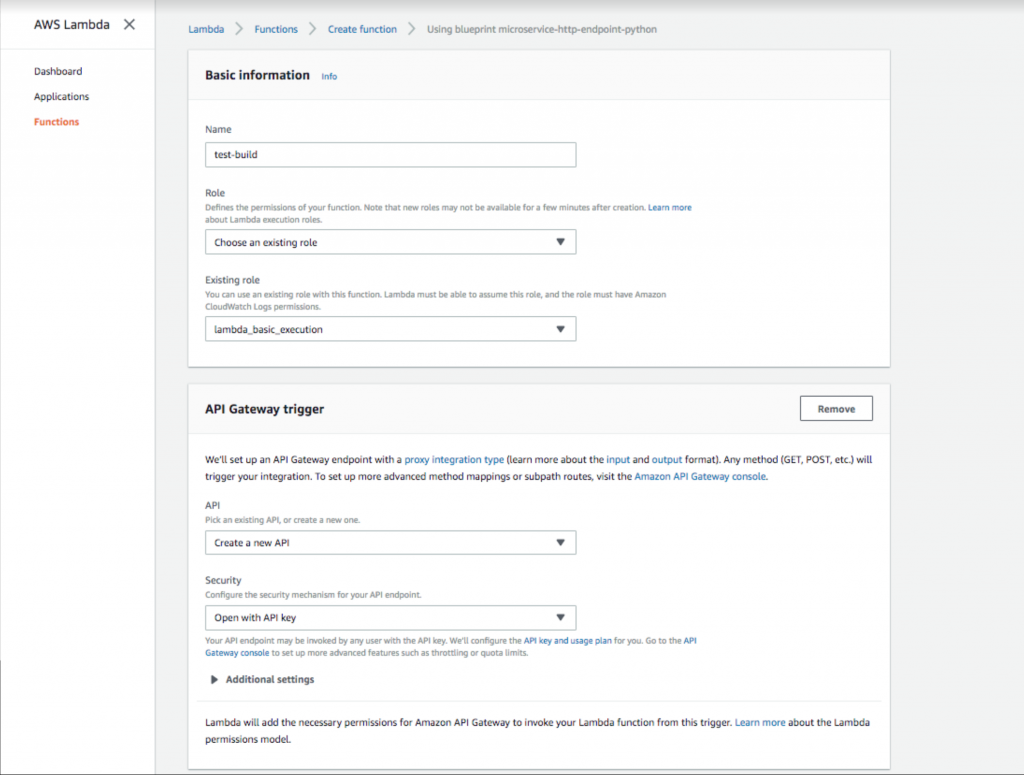
Configuração de uma chave de gateway de API aberta no AWS Lambda.
- Depois de criar a função, agora você pode fazer configurações em seu código. Como você pode ver, o blueprint já forneceu um gancho de ponto de entrada legal que permite que você interaja com uma tabela do Dynamo (se você deseja adicionar um banco de dados). O que estiver sob o lambda_handler será executado quando a URL pública for carregada. Como também estamos adicionando um banco de dados, vamos ao Dynamo e criemos um.
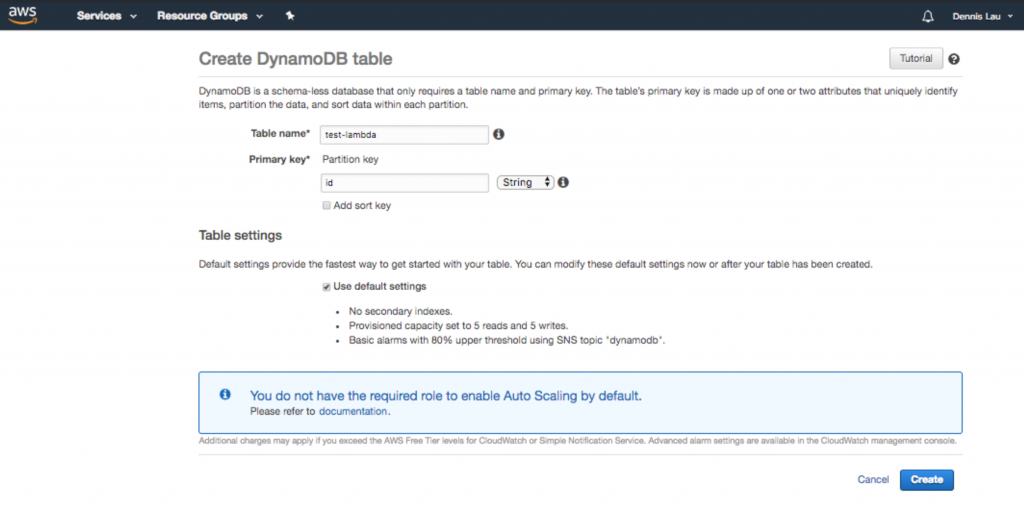
Criando uma tabela de banco de dados do Dynamo no AWS Lambda.
- Depois que a tabela do Dynamo for criada, faremos uma chamada para essa função do Lambda a partir de uma URL pública. Volte para sua função e clique no ícone “ API Gateway ” na parte superior. Você deve ver que o endpoint e a chave de API já foram criados para você.
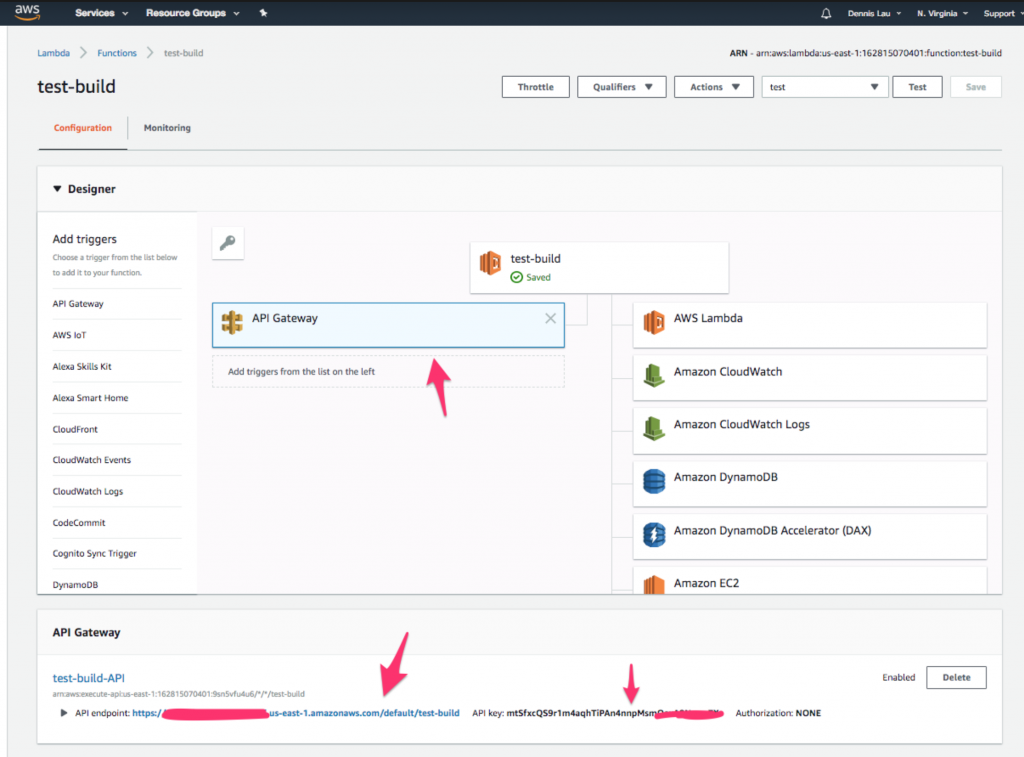
Onde encontrar o ícone do API Gateway nas funções do AWS Lambda.
- Agora abra o terminal e adicione a chave da API no cabeçalho “ x-api-key” e, em seguida, adicione o nome da tabela que você criou no parâmetro de string de consulta TableName .

Digite sua chave e nome do banco de dados no terminal para finalizar.
- Primeiro, crie uma nova função Lambda e selecione “ Blueprints ”. Em seguida, digite “ http ” no campo de palavra-chave e selecione Python ou Node microservice-http-endpoint. (Os blueprints são blocos de código pré-criados destinados a tornar o desenvolvimento mais rápido. Quão incrível é isso?) Depois de fazer uma seleção, clique em “ Configurar ”.
É isso! Agora você tem um back-end seguro e funcional conectado a um banco de dados. Bastou cinco passos fáceis.
Como a computação sem servidor abordou nossos desafios
Agora que mostramos como configurar compilações sem servidor, vamos dar uma olhada e ver como esse modelo baseado em nuvem se sai em relação à nossa lista de problemas.
- Muitos servidores! Sem servidor... o que significa que não há mais servidores, certo?
- Mantenha esses servidores ativos. Como a computação sem servidor é gerenciada pelo provedor de nuvem, você obtém o benefício de ter esses provedores (junto com seus métodos comprovados e robustos) para monitorar seus servidores. Para aqueles que querem jogar Sherlock Holmes, também podem ver todos os logs do servidor gerados por sua função no Cloudwatch .
- PHP não é para mim. Modelos sem servidor permitem que você escreva em C#, Python, NodeJS, Go e até Java.
- Isso está ficando caro. Com soluções sem servidor, os custos são medidos com base no tempo de execução (por 100 milissegundos) e na quantidade de dados transferidos. Ao contrário de pagar por mês, que inclui o tempo que seus servidores ficam ociosos, você está pagando apenas pelo que usa. Com custos tão baixos quanto $ 0,000000208 por 100 ms de execução, a computação sem servidor pode economizar uma quantia significativa de dinheiro.
- Segurança primeiro. O serverless é seguro? Com um sistema de autenticação de chave de API integrado, pode apostar que sim.
- Crons são difíceis. Com um sistema de gerenciamento cron construído nativamente no Cloudwatch, basta definir uma janela de tempo e esquecê-la. Cloudwatch lida com todo o registro e execução.
Pensamentos finais
Para a equipe de Engenharia de Soluções aqui da TUNE, mudar para a computação sem servidor foi um divisor de águas. Sua facilidade de uso, economia de custos e recursos ágeis mudaram a maneira como lidamos com todas as novas compilações de clientes. As soluções baseadas em nuvem sem servidor estão definidas para mudar o mundo da computação do lado do servidor. Não sei vocês, mas uma coisa é certa: a equipe de Engenharia de Soluções da TUNE está pronta.
Para saber mais sobre a plataforma TUNE e os serviços de desenvolvimento personalizados que fornecemos, visite nossa página de Serviços Profissionais .