
7 falhas de SEO vistas na natureza (e como você pode evitá-las)
Publicados: 2022-06-12
Muitas vezes recebemos perguntas de pessoas que se perguntam por que seu site não está classificado ou por que não é indexado pelos mecanismos de pesquisa.
Recentemente, me deparei com vários sites com grandes erros que poderiam ser facilmente corrigidos, se apenas os proprietários soubessem olhar. Embora alguns erros de SEO sejam bastante complexos, aqui estão alguns dos erros de “bater a cabeça” frequentemente esquecidos.
Então confira esses erros de SEO – e como você pode evitar fazê-los você mesmo.
Falha de SEO nº 1: Problemas no Robots.txt
O arquivo robots.txt tem muito poder. Ele instrui os bots de mecanismos de pesquisa sobre o que excluir de seus índices.
No passado, eu vi sites esquecerem de remover uma única linha de código desse arquivo após uma reformulação do site e afundar o site inteiro nos resultados da pesquisa.
Assim, quando um site de flores destacava um problema, comecei com uma das primeiras verificações que sempre faço em um site — veja o arquivo robots.txt.
Eu queria saber se o robots.txt do site estava bloqueando os mecanismos de busca de indexar seu conteúdo. Mas em vez do arquivo de texto esperado, vi uma página oferecendo flores para Robots.Txt.
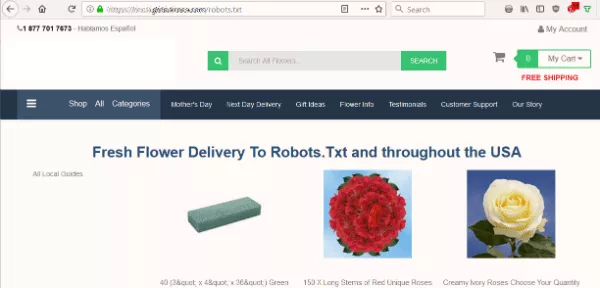
O site não tinha robots.txt, que é a primeira coisa que um bot procura ao rastrear um site. Esse foi o primeiro erro deles. Mas tomar esse arquivo como destino… sério?
Falha de SEO nº 2: autogeração enlouquecida
Em segundo lugar, o site estava gerando automaticamente conteúdo sem sentido. Provavelmente entregaria ao Papai Noel ou qualquer texto que eu colocasse na URL.
Eu executei uma ferramenta Check Server Page para ver qual status a página gerada automaticamente estava mostrando. Se fosse um 404 (não encontrado), os bots ignorariam a página como deveriam. No entanto, o cabeçalho do servidor da página deu um status 200 (OK). Como resultado, as páginas falsas estavam dando luz verde aos mecanismos de busca para serem indexados.
Os mecanismos de pesquisa desejam ver conteúdo exclusivo e significativo por página. Portanto, indexar essas não páginas pode prejudicar seu SEO.
Falha de SEO nº 3: Erros canônicos
Em seguida, verifiquei o que os mecanismos de pesquisa achavam deste site. Eles poderiam rastrear e indexar as páginas?
Olhando para o código-fonte de várias páginas, notei outro grande erro.
Cada página tinha um elemento de link canônico apontando para a página inicial:
<link rel=”canonical” href=”https://www.domain.com/” />
Em outras palavras, os mecanismos de busca estavam sendo informados de que cada página era na verdade uma cópia da página inicial. Com base nessa tag, os bots devem ignorar o restante das páginas desse domínio.
Felizmente, o Google é inteligente o suficiente para descobrir quando essas tags provavelmente são usadas por engano. Então ainda estava indexando algumas páginas do site. Mas esse pedido canônico universal não estava ajudando o SEO do site.
Como evitar essas falhas de SEO
Para os vários erros do site de flores, aqui estão as correções:
- Tenha um arquivo robots.txt válido para informar aos mecanismos de pesquisa como rastrear e indexar o site. Mesmo que seja um arquivo em branco, ele deve existir na raiz do seu domínio.
- Gere um elemento de link canônico adequado para cada página. E não aponte para fora de uma página que você deseja indexar.
- Exiba uma página 404 personalizada quando um URL de página não existir. Certifique-se de que ele retorne um código de servidor 404 para fornecer uma mensagem clara aos mecanismos de pesquisa.
- Tenha cuidado com páginas geradas automaticamente. Evite produzir páginas sem sentido ou duplicadas para mecanismos de busca e usuários.
Mesmo que você não esteja enfrentando um problema no site, esses são bons pontos para revisar periodicamente, apenas para garantir a segurança.
Ah, e nunca coloque uma tag canônica em sua página 404 , especialmente apontando para sua página inicial... apenas não coloque.
Falha de SEO nº 4: queda livre de classificações durante a noite
Às vezes, uma simples mudança pode ser um erro caro. Esta história vem de uma experiência com um de nossos clientes de SEO.
Quando a extensão .org de seu nome de domínio ficou disponível, eles a pegaram. Até agora tudo bem. Mas seu próximo passo levou ao desastre.
Eles imediatamente configuraram um redirecionamento 301 apontando o .org recém-adquirido para o site principal .com. O raciocínio deles fazia sentido – para capturar visitantes rebeldes que poderiam digitar a extensão errada.
Mas no dia seguinte, eles nos ligaram, desesperados. O tráfego do site deles era inexistente. Eles não tinham ideia do porquê.
Algumas verificações rápidas revelaram que seus rankings de busca haviam desaparecido do Google da noite para o dia. Não demorou muito Q&A para descobrir o que tinha acontecido.
Eles colocam o redirecionamento sem considerar o risco. Fizemos algumas pesquisas e descobrimos que o .org teve um passado sórdido.

O proprietário anterior do site .org o usou para spam. Com o redirecionamento, o Google estava atribuindo todo aquele veneno ao site principal da empresa! Levamos apenas dois dias para restaurar a posição do site no Google.
Como evitar essa falha de SEO
Sempre pesquise o perfil do link e o histórico de qualquer nome de domínio sob o qual você se registre.
Um consultor de SEO qualificado pode fazer isso. Há também ferramentas que você pode usar para ver quais esqueletos podem estar no armário do site.
Sempre que pego um novo domínio, gosto de deixá-lo inativo por seis meses a um ano, pelo menos, antes de tentar fazer qualquer coisa com ele. Eu quero que os mecanismos de busca diferenciem claramente a nova encarnação do meu site de sua vida passada. É uma precaução extra para proteger seu investimento.
Falha de SEO nº 5: páginas que não vão embora
Às vezes, os sites podem ter um problema diferente – muitas páginas no índice de pesquisa.
Os mecanismos de pesquisa às vezes retêm páginas que não são mais válidas. Se as pessoas chegarem a páginas de erro quando vierem dos resultados da pesquisa, é uma experiência ruim para o usuário.
Alguns proprietários de sites, frustrados, listam os URLs individuais no arquivo robots.txt. Eles esperam que o Google entenda a dica e pare de indexá-los.
Mas esta abordagem falha! Se o Google respeitar o robots.txt, ele não rastreará essas páginas. Portanto, o Google nunca verá o status 404 e não descobrirá que as páginas são inválidas.
Como evitar esse erro de SEO
A primeira parte da correção é não permitir esses URLs em robots.txt. Você QUER que os bots rastreiem e saibam quais URLs devem ser removidas do índice de pesquisa.
Depois disso, configure um redirecionamento 301 na URL antiga. Envie o visitante (e os mecanismos de pesquisa) para a página de substituição mais próxima no site. Isso cuida de seus visitantes, sejam eles provenientes de pesquisa ou de um link direto.
Falha de SEO nº 6: Equidade de links perdidos
Segui um link de um site da universidade e fui recebido com um erro 404 (não encontrado).
Isso não é incomum, exceto que o link era para /home.html — o antigo URL da página inicial do site.
Em algum momento, eles devem ter mudado a arquitetura do site e excluído o /home.html de estilo antigo, perdendo o redirecionamento no shuffle.
Ironicamente, a página 404 deles diz que você pode começar de novo na página inicial, que é o que eu estava tentando alcançar em primeiro lugar.
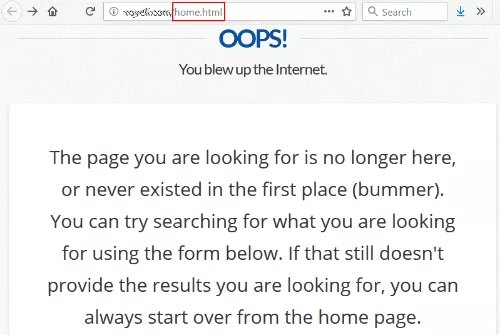
É uma aposta bastante segura que este site adoraria ter um bom link de uma universidade respeitada indo para sua página inicial. E conseguir isso está inteiramente sob seu controle. Eles nem precisam entrar em contato com o site de vinculação.
Como corrigir esta falha
Para corrigir esse link, eles só precisam colocar um redirecionamento 301 apontando /home.html para a página inicial atual. (Consulte nosso artigo sobre como configurar um redirecionamento 301 para obter instruções.)
Para crédito extra, acesse o Google Search Console e revise o Relatório de status de cobertura do índice. Observe todas as páginas relatadas como retornando um erro 404 e trabalhe para corrigir o maior número possível de erros aqui.
Falha de SEO nº 7: a falha de copiar/colar
A reformulação do site é iniciada, as tags canônicas estão em vigor e o novo Gerenciador de tags do Google está instalado. No entanto, ainda há problemas de classificação. Na verdade, uma nova página de destino não está mostrando nenhum visitante no Google Analytics.
A equipe de desenvolvimento responde que eles fizeram tudo de acordo com as regras e seguiram os exemplos ao pé da letra.
Eles estão exatamente certos. Eles seguiram os exemplos — inclusive deixando o código de exemplo! Depois de copiar e colar, os desenvolvedores esqueceram de inserir suas próprias informações do site de destino.
Aqui estão três exemplos que nossos analistas encontraram no código do site:
- <link rel=”canonical” href=”http://example.com/”>
- 'analyticsAccountNumber': 'UA-123456-1'
- _gaq.push(['_setAccount', 'UA-000000-1']);
Como evitar essa falha de SEO
Quando as coisas não funcionam direito, olhe além de apenas “este elemento está no código-fonte?” Pode ser que os códigos de validação adequados, números de conta e URLs nunca tenham sido especificados em seu código HTML.
Erros acontecem, e as pessoas são apenas humanas. Espero que esses exemplos o ajudem a evitar erros de SEO semelhantes. Para seu benefício, criamos um guia de SEO detalhado, descrevendo dicas e práticas recomendadas de SEO.
Mas alguns problemas de SEO são mais complexos do que você pensa. Se você tiver problemas de indexação, estamos aqui para ajudar. Ligue para nós ou preencha nosso formulário de solicitação e entraremos em contato.
Gostou desta postagem? Por favor, assine nosso blog para receber novos posts em sua caixa de entrada.