
Clustering de palavras-chave semânticas em Python
Publicados: 2021-04-19Em um mundo cheio de mitos do marketing digital, acreditamos que encontrar soluções práticas para os problemas do dia a dia é o que precisamos.
Na PEMAVOR, sempre compartilhamos nossa experiência e conhecimento para atender às necessidades dos entusiastas do marketing digital. Por isso, muitas vezes publicamos scripts Python gratuitos para ajudá-lo a aumentar seu ROI.
Nosso agrupamento de palavras-chave de SEO com Python abriu o caminho para obter novos insights para grandes projetos de SEO, com apenas menos de 50 linhas de códigos Python.
A ideia por trás desse script era permitir que você agrupasse palavras-chave sem pagar 'taxas exageradas' para… bem, nós sabemos quem…
Mas percebemos que esse script não é suficiente por si só. Há a necessidade de outro script, para que vocês possam aprofundar sua compreensão de suas palavras-chave: você precisa ser capaz de “ agrupar palavras-chave por significado e relações semânticas. ”
Agora, é hora de levar o Python para SEO um passo adiante.
Dados de rastreamento³
 Saber mais
Saber maisA maneira tradicional de agrupamento semântico
Como você sabe, o método tradicional para semântica é construir modelos word2vec e , em seguida, agrupar palavras-chave com a distância do Word Mover .
Mas esses modelos levam muito tempo e esforço para serem construídos e treinados. Assim, gostaríamos de lhe oferecer uma solução mais simples. 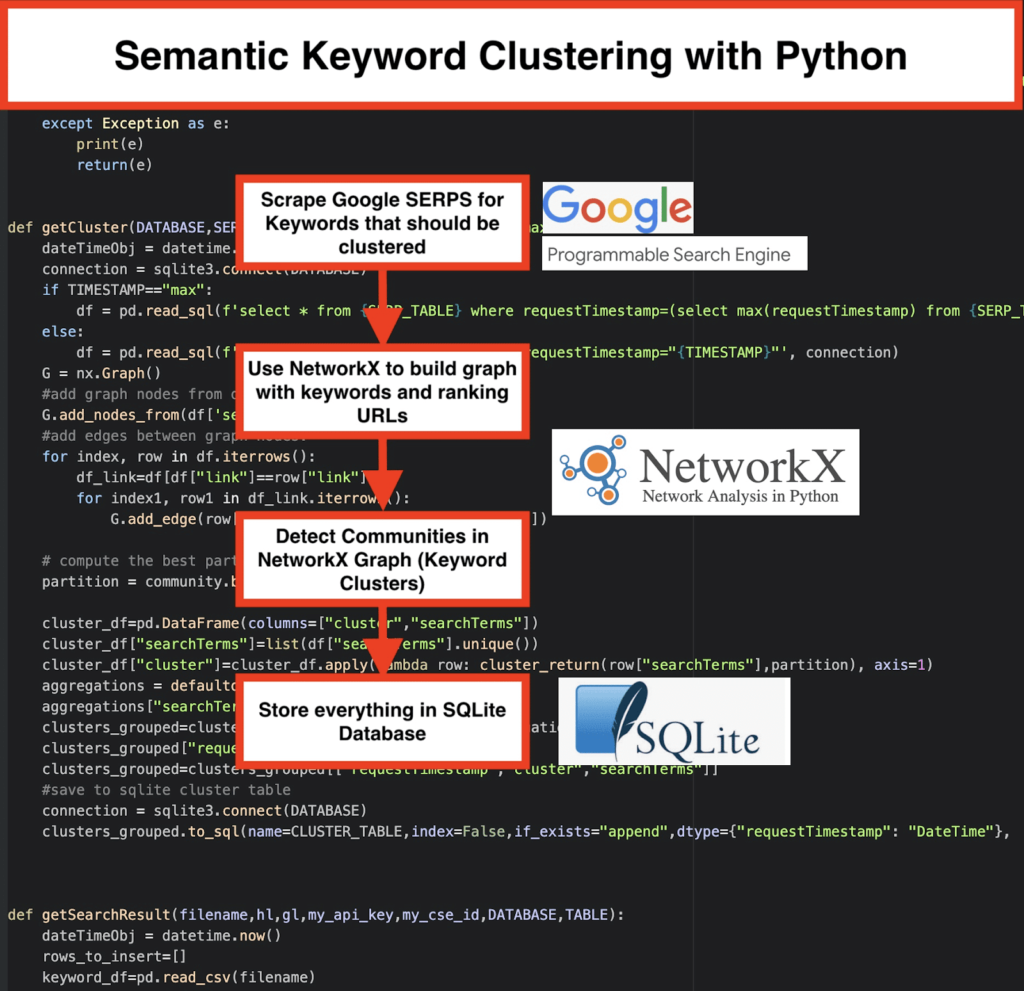
Resultados do Google SERP e descoberta de semântica
O Google faz uso de modelos de PNL para oferecer os melhores resultados de pesquisa. É como abrir a caixa de Pandora, e não sabemos exatamente.
No entanto, em vez de construir nossos modelos, podemos usar esta caixa para agrupar palavras-chave por sua semântica e significado.
Aqui está como fazemos isso:
️ Primeiro, crie uma lista de palavras-chave para um tópico.
️ Em seguida, raspe os dados SERP para cada palavra-chave.
️ Em seguida, é criado um gráfico com a relação entre as páginas de classificação e as palavras-chave.
️ Desde que as mesmas páginas sejam classificadas para palavras-chave diferentes, isso significa que elas estão relacionadas entre si. Este é o princípio básico por trás da criação de clusters de palavras-chave semânticas.
Hora de juntar tudo em Python
O Python Script oferece as funções abaixo:
- Usando o mecanismo de pesquisa personalizado do Google, baixe as SERPs para a lista de palavras-chave. Os dados são salvos em um banco de dados SQLite . Aqui, você deve configurar uma API de pesquisa personalizada.
- Em seguida, faça uso da cota gratuita de 100 solicitações diárias. Mas eles também oferecem um plano pago por US$ 5 por 1000 missões, se você não quiser esperar ou se tiver grandes conjuntos de dados.
- É melhor usar as soluções SQLite se você não estiver com pressa – os resultados SERP serão anexados à tabela em cada execução. (Basta fazer uma nova série de 100 palavras-chave quando tiver cota novamente no dia seguinte.)
- Enquanto isso, você precisa configurar essas variáveis no Python Script .
- CSV_FILE=”keywords.csv” => armazene suas palavras-chave aqui
- IDIOMA = “pt”
- PAÍS = “pt”
- API_KEY=" xxxxxxx"
- CSE_ID=”xxxxxxx”
- A execução
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)os resultados SERP no banco de dados. - O Clustering é feito pelo networkx e pelo módulo de detecção de comunidade. Os dados são buscados no banco de dados SQLite – o clustering é chamado com
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - Os resultados do Clustering podem ser encontrados na tabela SQLite – contanto que você não altere, o nome é “keyword_clusters” por padrão.
Abaixo, você verá o código completo:
# Agrupamento de palavras-chave semânticas por Pemavor.com # Autor: Stefan Neefischer ([email protected]) da compilação de importação do googleapiclient.discovery importar pandas como pd importar Levenshtein de datetime importação datetime de fuzzywuzzy importar fuzz de urllib.parse importar urlparse de tld importar get_tld importar langid importar json importar pandas como pd importar numpy como np importar networkx como nx comunidade de importação importar sqlite3 importar matemática importar io de coleções import defaultdict def cluster_return(searchTerm,partição): partição de retorno[searchTerm] def language_detection(str_lan): lan=langid.classify(str_lan) retornar lan[0] def extract_domain(url, remove_http=True): uri = urlparse(url) se remover_http: domain_name = f"{uri.netloc}" senão: domain_name = f"{uri.netloc}://{uri.netloc}" retornar nome_dominio def extract_mainDomain(url): res = get_tld(url, as_object=True) retornar res.fld def fuzzy_ratio(str1,str2): return fuzz.ratio(str1,str2) def fuzzy_token_set_ratio(str1,str2): return fuzz.token_set_ratio(str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): tentar: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() retorno res exceto Exceção como e: imprimir(e) retorno (e) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): tentar: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() retorno res exceto Exceção como e: imprimir(e) retorno (e) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"): dateTimeObj = datetime.now() conexão = sqlite3.connect(DATABASE) se TIMESTAMP=="max": df = pd.read_sql(f'select * from {SERP_TABLE} onde requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', conexão) senão: df = pd.read_sql(f'select * from {SERP_TABLE} onde requestTimestamp="{TIMESTAMP}"', conexão) G = nx.Gráfico() #adicionar nós de gráfico da coluna de dataframe G.add_nodes_from(df['searchTerms']) #add arestas entre os nós do gráfico: para índice, linha em df.iterrows(): df_link=df[df["link"]==linha["link"]] para index1, row1 em df_link.iterrows(): G.add_edge(row["searchTerms"], row1['searchTerms']) # calcula a melhor partição para a comunidade (clusters) partição = community.best_partition(G) cluster_df=pd.DataFrame(columns=["cluster","searchTerms"]) cluster_df["searchTerms"]=list(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(lambda row: cluster_return(row["searchTerms"],partição), axis=1) agregações = defaultdict() agregações["searchTerms"]=' | '.Junte clusters_grouped=cluster_df.groupby("cluster").agg(aggregations).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #save na tabela de cluster sqlite conexão = sqlite3.connect(DATABASE) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) def getSearchResult(filename,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE): dateTimeObj = datetime.now() rows_to_insert=[] keyword_df=pd.read_csv(nome do arquivo) keywords=keyword_df.iloc[:,0].tolist() para consulta em palavras-chave: if hl=="padrão": resultado = google_search_default_language(consulta, my_api_key, my_cse_id,gl) senão: resultado = google_search(consulta, my_api_key, my_cse_id,hl,gl) if "itens" no resultado e "consultas" no resultado: for position in range(0,len(result["items"])): resultado["itens"][posição]["posição"]=posição+1 result["items"][position]["main_domain"]= extract_mainDomain(result["items"][position]["link"]) result["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],consulta) result["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],consulta) result["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],consulta) result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query) result["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"]) for position in range(0,len(result["items"])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"], "displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"], "position":result["items"][position]["position"],"snippet":result["items"][position]["snippet"], "snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"], "title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"], }) df=pd.DataFrame(rows_to_insert) #salvar resultados do serp no banco de dados sqlite conexão = sqlite3.connect(DATABASE) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) ################################################# ################################################# ######################################### #Leia-me: # ################################################# ################################################# ######################################### #1- Você precisa configurar um mecanismo de pesquisa personalizado do Google. # # Forneça a chave de API e o SearchId. # # Defina também seu país e idioma onde deseja monitorar os resultados da SERP. # # Se você ainda não tem uma chave de API e um ID de pesquisa, # # você pode seguir as etapas na seção Pré-requisitos nesta página https://developers.google.com/custom-search/v1/overview#prerequisites # ## #2- Você também precisa inserir os nomes do banco de dados, da tabela serp e da tabela de cluster a serem usados para salvar os resultados. # ## #3- digite o nome do arquivo csv ou o caminho completo que contém palavras-chave que serão usadas para serp # ## #4- Para clustering de palavras-chave, insira o timestamp para resultados de serp que serão usados para clustering. # # Se você precisar agrupar os últimos resultados de serp, digite "max" para timestamp. # # ou você pode inserir um carimbo de data/hora específico como "2021-02-18 17:18:05.195321" # ## #5- Navegue pelos resultados através do navegador DB para o programa SQLite # ################################################# ################################################# ######################################### #csv nome do arquivo que tem palavras-chave para serp CSV_FILE="palavras-chave.csv" # determina o idioma IDIOMA = "pt" #determine cidade PAÍS = "pt" #chave de API json de pesquisa personalizada do google API_KEY="INSIRA A CHAVE AQUI" #ID do mecanismo de pesquisa CSE_ #sqlite nome do banco de dados DATABASE="palavras-chave.db" #nome da tabela para salvar os resultados da serp nela SERP_TABLE="keywords_serps" # executa serp para palavras-chave getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) #table nome que os resultados do cluster salvarão nele. CLUSTER_TABLE="keyword_clusters" #Insira o carimbo de data/hora, se quiser criar clusters para um carimbo de data/hora específico #Se você precisar fazer clusters para o último resultado da serp, envie-o com o valor "max" #TIMESTAMP="2021-02-18 17:18:05.195321" TIMESTAMP="máximo" #executar clusters de palavras-chave de acordo com algoritmos de redes e comunidades getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Resultados do Google SERP e descoberta de semântica
Esperamos que você tenha gostado deste script com seu atalho para agrupar suas palavras-chave em clusters semânticos sem depender de modelos semânticos. Como esses modelos geralmente são complexos e caros, é importante procurar outras maneiras de identificar palavras-chave que compartilham propriedades semânticas.
Ao tratar palavras-chave semanticamente relacionadas juntas, você pode cobrir melhor um assunto, vincular melhor os artigos do seu site uns aos outros e aumentar a classificação do seu site para um determinado tópico.