
Noções básicas sobre o relatório de cobertura do Search Console
Publicados: 2019-08-15Introdução ao relatório de cobertura e como interpretar os dados
O Relatório de cobertura do Search Console fornece informações sobre quais páginas do seu site foram indexadas e lista os URLs que apresentaram problemas enquanto o Googlebot tenta rastreá-los e indexá-los.
A página principal do relatório de cobertura mostra os URLs do seu site agrupados por status:
- Erro: a página não está indexada. Existem várias razões para isso, páginas respondendo com 404, páginas suaves 404, entre outras coisas.
- Válido com avisos: a página está indexada mas apresenta problemas.
- Válido: a página está indexada.
- Excluído: a página não está indexada, o Google está seguindo regras no site, como tags noindex em robots.txt ou metatags, tags canônicas etc. que impedem que as páginas sejam indexadas.
Este relatório de cobertura fornece muito mais informações do que o antigo console de pesquisa do Google. O Google realmente melhorou os dados que compartilha, mas ainda há algumas coisas que precisam ser melhoradas.
Como você pode ver abaixo, o Google mostra um gráfico com o número de URLs em cada categoria. Se houver um aumento repentino de erros, você poderá ver as barras e até correlacionar isso com as impressões para determinar se um aumento nos URLs com erros ou avisos pode diminuir as impressões.

Após o lançamento de um site ou a criação de novas seções, você deseja ver uma contagem crescente de páginas indexadas válidas. Leva alguns dias para o Google indexar novas páginas, mas você pode usar a ferramenta de inspeção de URL para solicitar indexação e reduzir o tempo para o Google encontrar sua nova página.

No entanto, se você observar um número decrescente de URLs válidos ou picos repentinos, é importante trabalhar para identificar os URLs na seção Erros e corrigir os problemas listados no relatório. O Google fornece um bom resumo dos itens de ação a serem executados quando há aumento de erros ou avisos.
O Google fornece informações sobre quais são os erros e quantos URLs têm esse problema:

Lembre-se de que o Google Search Console não mostra informações 100% precisas. Na verdade, houve vários relatórios sobre bugs e anomalias de dados. Além disso, o console de pesquisa do Google leva tempo para atualizar, sabe-se que os dados estão 16 dias a 20 dias atrasados. Além disso, o relatório mostrará, às vezes, listar mais de 1.000 páginas em categorias de erros ou avisos, como você pode ver na imagem acima, mas só permite que você veja e baixe uma amostra de 1.000 URLs para você auditar e verificar.
No entanto, esta é uma ótima ferramenta para encontrar problemas de indexação em seu site:
Ao clicar em um erro específico, você poderá ver a página de detalhes que lista exemplos de URLs:

Como você pode ver na imagem acima, esta é a página de detalhes de todos os URLs que responderam com 404. Cada relatório tem um link "Saiba mais" que leva você a uma página de documentação do Google que fornece detalhes sobre esse erro específico. O Google também fornece um gráfico que mostra a contagem de páginas afetadas ao longo do tempo.
Você pode clicar em cada URL para inspecionar o URL que é semelhante ao antigo recurso “buscar como Googlebot” do antigo Google Search Console. Você também pode testar se a página está bloqueada pelo seu robots.txt
Depois de corrigir os URLs, você pode solicitar que o Google os valide para que o erro desapareça do seu relatório. Você deve priorizar a correção de problemas que estão no estado de validação “falhou” ou “não iniciado”.
É importante mencionar que você não deve esperar que todos os URLs do seu site sejam indexados. O Google afirma que o objetivo do webmaster deve ser indexar todos os URLs canônicos. Páginas duplicadas ou alternativas serão categorizadas como excluídas, pois possuem conteúdo semelhante à página canônica.
É normal que os sites tenham várias páginas incluídas na categoria excluída. A maioria dos sites terá várias páginas sem meta tags de índice ou bloqueadas pelo robots.txt. Quando o Google identifica uma página duplicada ou alternativa, certifique-se de que essas páginas tenham uma tag canônica apontando para o URL correto e tente encontrar o equivalente canônico na categoria válida.
O Google incluiu um filtro suspenso no canto superior esquerdo do relatório para que você possa filtrar o relatório por todas as páginas conhecidas, todas as páginas enviadas ou URLs em um sitemap específico. O relatório padrão inclui todas as páginas conhecidas, incluindo todos os URLs descobertos pelo Google. Todas as páginas enviadas incluem todos os URLs que você denunciou por meio de um mapa do site. Se você enviou vários sitemaps, pode filtrar por URLs em cada sitemap.
[Estudo de caso] Aumente o orçamento de rastreamento em páginas estratégicas
 Leia o estudo de caso
Leia o estudo de casoErros, avisos, URLs válidos e excluídos
Erro
- Erro do servidor (5xx): o servidor retornou um erro 500 quando o Googlebot tentou rastrear a página.
- Erro de redirecionamento: quando o Googlebot rastreou o URL, houve um erro de redirecionamento, porque a cadeia era muito longa, havia um loop de redirecionamento, o URL excedeu o comprimento máximo do URL ou havia um URL incorreto ou vazio na cadeia de redirecionamento.
- URL enviado bloqueado por robots.txt: os URLs nesta lista estão bloqueados pelo seu arquivo robts.txt.
- URL enviado marcado como 'noindex': os URLs nesta lista têm uma tag meta robots 'noindex' ou um cabeçalho http.
- O URL enviado parece ser um Soft 404: um erro soft 404 ocorre quando uma página que não existe (foi removida ou redirecionada) exibe uma mensagem 'página não encontrada' para o usuário, mas não retorna um código de status HTTP 404. Soft 404s também acontecem quando as páginas são redirecionadas para páginas não relevantes, por exemplo, uma página redirecionando para a página inicial em vez de retornar um código de status 404 ou redirecionar para uma página relevante.
- URL enviado retorna solicitação não autorizada (401): a página enviada para indexação está retornando uma resposta HTTP 401 não autorizada.
- URL enviado não encontrado (404): a página respondeu com um erro 404 Not Found quando o Googlebot tentou rastrear a página.
- O URL enviado tem um problema de rastreamento: o Googlebot detectou um erro de rastreamento ao rastrear essas páginas que não se enquadram em nenhuma das outras categorias. Você terá que verificar cada URL e determinar qual poderia ter sido o problema.
Aviso
- Indexada, embora bloqueada por robots.txt: a página foi indexada porque o Googlebot a acessou por meio de links externos que apontam para a página, mas a página está bloqueada por seu robots.txt. O Google marca esses URLs como avisos porque não tem certeza se a página deve realmente ser impedida de aparecer nos resultados de pesquisa. Se você deseja bloquear uma página, deve usar uma metatag 'noindex' ou usar um cabeçalho de resposta HTTP noindex.
Se o Google estiver correto e o URL tiver sido bloqueado incorretamente, atualize seu arquivo robots.txt para permitir que o Google rastreie a página.
Válido
- Enviados e indexados: URLs que você enviou ao Google por meio do sitemap.xml para indexação e foram indexados.
- Indexado, não enviado no mapa do site: o URL foi descoberto pelo Google e indexado, mas não foi incluído no mapa do site. É recomendável atualizar seu mapa do site e incluir todas as páginas que você deseja que o Google rastreie e indexe.
Excluído
- Excluído pela tag 'noindex': quando o Google tentou indexar a página, encontrou uma meta tag robots 'noindex' ou um cabeçalho HTTP.
- Bloqueado pela ferramenta de remoção de página: alguém enviou uma solicitação ao Google para não indexar esta página usando a solicitação de remoção de URL no Google Search Console. Se você deseja que esta página seja indexada, faça login no Search Console do Google e remova-a da lista de páginas removidas.
- Bloqueado por robots.txt: o arquivo robots.txt tem uma linha que exclui o rastreamento do URL. Você pode verificar qual linha está fazendo isso usando o testador robots.txt.
- Bloqueado devido a solicitação não autorizada (401): Igual à categoria Erro, as páginas aqui estão retornando com um cabeçalho HTTP 401.
- Anomalia de rastreamento: essa é uma categoria abrangente, os URLs aqui respondem com códigos de resposta de nível 4xx ou 5xx; Esses códigos de resposta impedem a indexação da página.
- Rastreado – atualmente não indexado: o Google não fornece um motivo pelo qual o URL não foi indexado. Eles sugerem reenviar o URL para indexação. No entanto, é importante verificar se a página tem conteúdo pequeno ou duplicado, se está canonizada para uma página diferente, se tem uma diretiva noindex, se as métricas mostram uma experiência ruim do usuário, tempo de carregamento de página alto etc. Pode haver vários motivos para que o Google não quer indexar a página.
- Descoberta – atualmente não indexada: a página foi encontrada, mas o Google não a incluiu em seu índice. Você pode enviar o URL para indexação para acelerar o processo, como mencionamos acima. O Google afirma que o motivo típico para isso acontecer é que o site estava sobrecarregado e o Google reagendou o rastreamento.
- Página alternativa com tag canônica adequada: o Google não indexou esta página porque ela tem uma tag canônica apontando para um URL diferente. O Google seguiu a regra canônica e indexou corretamente o URL canônico. Se você pretendia que esta página não fosse indexada, então não há nada para corrigir aqui.
- Duplicar sem canônica selecionada pelo usuário: o Google encontrou duplicatas para as páginas listadas nesta categoria e nenhuma faz uso de tags canônicas. O Google selecionou uma versão diferente como uma tag canônica. Você precisa revisar essas páginas e adicionar uma tag canônica apontando para o URL correto.
- Duplicado, o Google escolheu um canônico diferente do usuário: URLs nesta categoria foram descobertos pelo Google sem uma solicitação de rastreamento explícita. O Google os encontrou por meio de links externos e determinou que existe outra página que torna um canônico melhor. O Google não indexou essas páginas por esse motivo. O Google recomenda marcar esses URLs como duplicatas do canônico.
- Não encontrado (404): quando o Googlebot tenta acessar essas páginas, ele responde com um erro 404. O Google afirma que esses URLs não foram enviados, esses URLs foram encontrados por meio de links externos que apontam para esses URLs. É uma boa ideia redirecionar esses URLs para páginas semelhantes para aproveitar o valor do link e também garantir que os usuários acessem uma página relevante.
- Página removida devido a uma reclamação legal: alguém reclamou sobre essas páginas devido a questões legais, como uma violação de direitos autorais. Você pode apelar da reclamação legal enviada aqui.
- Página com redirecionamento: esses URLs estão redirecionando, portanto, são excluídos.
- Soft 404: Como explicado acima, esses URLs são excluídos porque deveriam estar respondendo com um 404. Verifique as páginas e certifique-se de que, se houver uma mensagem 'não encontrada', responda com um cabeçalho HTTP 404.
- URL enviado duplicado não selecionado como canônico: semelhante a "O Google escolheu um canônico diferente do usuário", no entanto, os URLs nesta categoria foram enviados por você. É uma boa ideia verificar seus sitemaps e certificar-se de que não há páginas duplicadas sendo incluídas.
Como usar os dados e itens de ação para melhorar o site
Trabalhando em uma agência, tenho acesso a vários sites diferentes e seus relatórios de cobertura. Passei um tempo analisando os erros que o Google relata nas diferentes categorias.
Foi útil encontrar problemas com canonização e conteúdo duplicado, mas às vezes você encontra discrepâncias como a relatada por @jroakes:

Parece que o Google Search Console > Inspeção de URL > Teste ao vivo relata incorretamente todos os arquivos JS e CSS como Rastreamento permitido: Não: bloqueado por robots.txt. Teste cerca de 20 arquivos em 3 domínios. pic.twitter.com/fM3WAcvK8q
— JR%20Oakes ???? (@jroakes) 16 de julho de 2019
AJ Koh, escreveu um ótimo artigo logo após a disponibilização do novo Google Search Console, onde ele explica que o valor real dos dados é usá-los para pintar uma imagem de saúde para cada tipo de conteúdo em seu site:
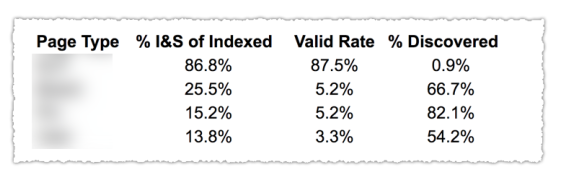
Como você pode ver na imagem acima, os URLs das diferentes categorias do relatório de cobertura foram classificados por template de página como blog, página de serviço, etc. Usar vários sitemaps para diferentes tipos de URLs pode ajudar nessa tarefa, pois o Google permite que você filtre as informações de cobertura por mapa do site. Em seguida, ele incluiu três colunas com as seguintes informações % de páginas indexadas e enviadas, taxa válida e % de descobertas.
Esta tabela realmente oferece uma ótima visão geral da integridade do seu site. Agora, se você quiser se aprofundar nas diferentes seções, recomendo revisar os relatórios e verificar novamente os erros que o Google apresenta.
Você pode baixar todas as URLs apresentadas em diferentes categorias e usar o OnCrawl para verificar seu status HTTP, tags canônicas, etc. e criar uma planilha como esta:
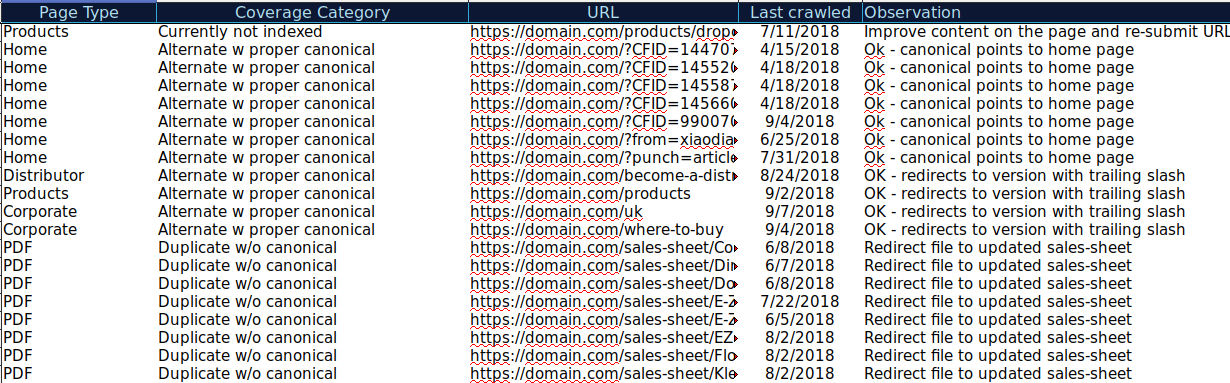
Organizar seus dados dessa forma pode ajudar a acompanhar os problemas, bem como adicionar itens de ação para URLs que precisam ser melhorados ou corrigidos. Além disso, você pode marcar os URLs que estão corretos e nenhum item de ação é necessário no caso desses URLs com parâmetros com implementação de tag canônica corretamente.
Comece seu teste gratuito de 14 dias
 Comece seu teste
Comece seu testeVocê pode até adicionar mais informações a esta planilha de outras fontes, como ahrefs, Majestic e Google Analytics com integrações OnCrawl. Isso permitiria extrair dados de links, bem como dados de tráfego e conversão para cada um dos URLs no Google Search Console. Todos esses dados podem ajudá-lo a tomar melhores decisões sobre o que fazer para cada página, por exemplo, se você tiver uma lista de páginas com 404s, poderá vinculá-la a backlinks para determinar se está perdendo algum valor de link de domínios vinculados a páginas quebradas em seu site. Ou você pode verificar as páginas indexadas e quanto tráfego orgânico elas estão recebendo. Você pode identificar páginas indexadas que não recebem tráfego orgânico e trabalhar para otimizá-las (melhorando o conteúdo e a usabilidade) para ajudar a direcionar mais tráfego para essa página.
Com esses dados extras, você pode criar uma tabela de resumo em outra planilha. Você pode usar a fórmula =CONTARSE(intervalo, critérios) para contar os URLs em cada tipo de página (esta tabela pode complementar a tabela que AJ Kohn sugeriu acima). Você também pode usar outra fórmula para adicionar backlinks, visitas ou conversões que você extraiu para cada URL e mostrá-los em sua tabela de resumo com a seguinte fórmula =SUMIF (intervalo, critérios, [sum_range]). Você obteria algo assim:
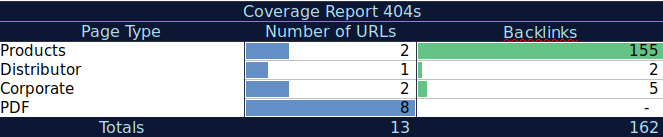
Eu realmente gosto de trabalhar com tabelas de resumo que podem me dar uma visão resumida dos dados e podem me ajudar a identificar as seções que eu preciso focar em corrigir primeiro.
Pensamentos finais
O que você precisa pensar ao trabalhar na correção de problemas e analisar os dados neste relatório é: Meu site está otimizado para rastreamento? Minhas páginas indexadas e válidas estão aumentando ou diminuindo? Páginas com erros estão aumentando ou diminuindo? Estou permitindo que o Google gaste tempo nos URLs que trarão mais valor para meus usuários ou está encontrando muitas páginas inúteis? Com as respostas a essas perguntas, você pode começar a fazer melhorias em seu site para que o Googlebot possa gastar seu orçamento de rastreamento em páginas que possam agregar valor aos seus usuários em vez de páginas inúteis. Você pode usar seu robots.txt para ajudar a melhorar a eficiência do rastreamento, remover URLs inúteis quando possível ou usar tags canônicas ou noindex para evitar conteúdo duplicado.
O Google continua adicionando funcionalidades e atualizando a precisão dos dados aos diferentes relatórios no Google Search Console, portanto, esperamos continuar a ver mais dados em cada uma das categorias do relatório de cobertura, bem como em outros relatórios no Google Search Console.