
Auditoria técnica de SEO em 11 etapas rápida e suja para a integridade geral do site
Publicados: 2020-02-27O SEO técnico é importante porque é o ponto de partida de qualquer projeto. Do ponto de vista de um especialista em SEO, cada site é um novo projeto. Um site deve ter uma base sólida para obter bons resultados e alcançar o KPI mais importante em SEO como rankings.
Cada vez que começo com um novo projeto, a primeira coisa que faço é uma auditoria técnica de SEO. Na maioria das vezes, corrigir problemas técnicos pode obter resultados surpreendentes assim que o site é rastreado novamente.
É engraçado para mim quando as pessoas falam sobre conteúdo e mais conteúdo, mas não dizem uma palavra sobre SEO técnico. Uma coisa é certa, a saúde do site e o SEO técnico são duas coisas importantes que serão cruciais em 2020. Não quero dizer que o conteúdo não seja importante. É, mas sem corrigir os problemas técnicos em um site, não acho que o conteúdo possa trazer resultados.
Já vi casos em que páginas importantes foram bloqueadas por diretivas no arquivo robots.txt, ou as páginas de categorias ou serviços mais importantes foram quebradas ou bloqueadas por meta robôs como noindex, nofollow. Como é possível ter sucesso sem priorizar corrigindo esses problemas?
Pode ser surpreendente ver o número de SEOs que não sabem identificar problemas técnicos para relatar a especialistas em desenvolvimento web para serem corrigidos. Lembrei-me de uma vez, enquanto trabalhava no campo corporativo, que criei uma planilha de checklist de auditoria Tech SEO para ser usada pela minha equipe. Naquela época, percebi que ter em mãos uma planilha de correção rápida como essa pode ajudar imensamente uma equipe e gerar um impulso rápido para um cliente. Por isso considero de extrema importância investir em uma ferramenta/software que possa te ajudar com diagnósticos e recomendações técnicas de SEO.
Vamos começar o processo prático sobre como realizar uma auditoria rápida de SEO de tecnologia que fará uma grande diferença. Este é um exercício rápido que levará cerca de uma hora para fazer, mesmo que você não seja um profissional. Para mim, usar uma ferramenta de SEO como o OnCrawl para avançar todas as coisas em cinco minutos sem ter que fazer todo o trabalho manual facilita minha vida.
Vou abordar as coisas mais importantes a serem verificadas ao realizar uma Auditoria Técnica de SEO. Há mais coisas que podemos verificar quanto a problemas na página, mas quero me concentrar apenas nas coisas que criarão problemas de indexação e desperdício de orçamento. Priorizar isso é a forma de garantir que as páginas mais importantes sejam rastreadas pelo Googlebot.
- Indexação
- arquivo robots.txt
- Meta-tag de robôs
- erros 4xx
- Mapas de site
- HTTP/HTTPS (segurança do site, conteúdo misto e problemas de conteúdo duplicado)
- Paginação
- página 404
- Profundidade e estrutura do site
- Cadeias de redirecionamento longas
- Implementação de tag canônica
1) Indexação
Esta é a primeira coisa a verificar. Muitas vezes a indexação pode ser afetada por uma configuração de plug-in ou qualquer pequeno erro, mas o impacto na localização pode ser enorme, já que hoje existem mais de 6,16 bilhões de páginas da web indexadas. Você precisa entender que qualquer buscador está se esforçando e até o Google precisa priorizar a página mais relevante para a experiência do usuário. Se você não considerar facilitar as coisas para o Googlebot, sua concorrência fará isso e ganhará muito mais confiança que vem com um site saudável.
Quando houver problemas de indexação, os problemas de saúde do seu site refletirão na perda de tráfego orgânico. O processo de indexação significa que um mecanismo de busca rastreia uma página da web e organiza as informações que posteriormente a oferecem na SERP. Os resultados dependem da relevância para a intenção do usuário. Se uma página da web não puder ou tiver problemas com o rastreamento, isso favorecerá outras páginas no mesmo nicho para ter uma vantagem.
Usando operadores de pesquisa, por exemplo:
Site: www.abc.com
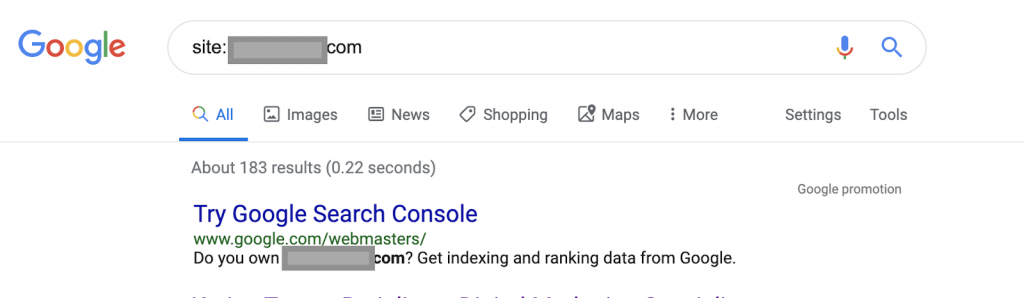
A consulta retornará 183 páginas indexadas pelo Google. Esta é uma estimativa aproximada do número de páginas que o Google indexou. Você pode verificar o Google Search Console para obter o número exato.
Você também deve usar um rastreador da Web como o OnCrawl para listar todas as páginas às quais o Google tem acesso. Isso mostra um número diferente, como você pode ver abaixo:
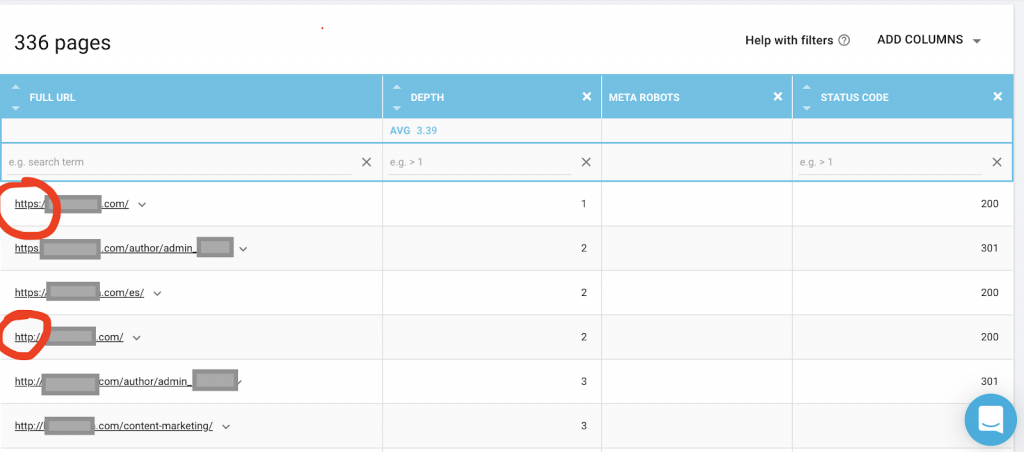
Este site tem quase o dobro de páginas rastreáveis do que páginas indexadas.
Isso pode revelar um problema de conteúdo duplicado ou até mesmo um problema de versão de segurança do site entre o problema HTTP e HTTPS. Vou falar sobre isso mais adiante neste artigo.
Nesse caso, o site foi migrado de HTTP para HTTPS. Podemos ver no OnCrawl que as páginas HTTP foram redirecionadas. As versões HTTP e HTTPS ainda são acessíveis ao Googlebot, e ele pode rastrear todas as páginas duplicadas, em vez de priorizar as páginas mais importantes que o proprietário deseja classificar, causando um desperdício de orçamento de rastreamento.
Outro problema comum entre sites negligenciados ou grandes sites, como sites de comércio eletrônico, são os problemas de conteúdo misto. Para encurtar a história, os problemas surgem quando sua página segura tem recursos como arquivos de mídia (mais frequentemente: imagens) carregados de uma versão não segura.
Como corrigi-lo:
Você pode pedir a um desenvolvedor da Web para forçar todas as páginas HTTP para a versão HTTPS e redirecionar endereços HTTP para HTTPS uma vez usando um código de status 301.
Para problemas de conteúdo misto, você pode verificar manualmente a fonte da página e procurar recursos carregados como “src=http://example.com/media/images”, o que é quase insano fazer isso especialmente para sites grandes. É por isso que precisamos usar uma ferramenta técnica de SEO.
2) Arquivo Robots.txt:
O arquivo robots.txt informa aos agentes de rastreamento quais páginas eles não devem rastrear. O guia de especificações do Robots.txt indica que o formato do arquivo deve ser texto simples com um tamanho máximo de 500 KB.
Eu recomendarei adicionar o mapa do site ao arquivo robots.txt. Nem todo mundo faz isso, mas acredito que seja uma boa prática. O arquivo robots.txt deve ser colocado em seu servidor hospedado em public_html e vai após o domínio raiz.
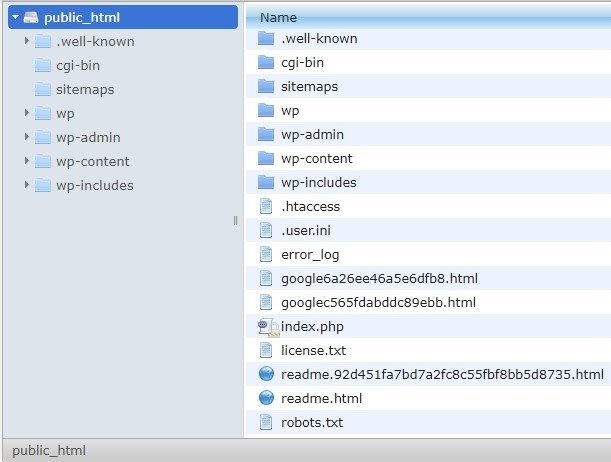
Podemos usar diretivas no arquivo robots.txt para evitar que os mecanismos de pesquisa rastreiem páginas desnecessárias ou páginas com informações confidenciais, como a página de administração, modelos ou carrinho de compras (/cart, /checkout, /login, pastas como /tag usadas em blogs) , adicionando essas páginas no arquivo robots.txt.
Conselho : Certifique-se de não bloquear a pasta de arquivos de mídia, pois isso excluirá suas imagens, vídeos ou outras mídias auto-hospedadas de serem indexadas. A mídia pode ser muito importante para a relevância da página, bem como para a classificação orgânica e o tráfego de imagens ou vídeos.
3) Tag Meta Robots
Este é um pedaço de código HTML que instrui os mecanismos de pesquisa a rastrear e indexar uma página, com todos os links dessa página. A tag HTML vai no cabeçalho da sua página da web. Existem 4 tags HTML comuns para robôs:
- Não siga
- Seguir
- Índice
- Sem índice
Quando não houver meta tags de robôs presentes, os mecanismos de pesquisa seguirão e indexarão o conteúdo por padrão.
Você pode usar qualquer combinação que melhor se adapte às suas necessidades. Por exemplo, usando o OnCrawl, descobri que uma “página de autor” deste site não possui meta robôs. Isso significa que, por padrão, a direção é (“seguir, indexar”)
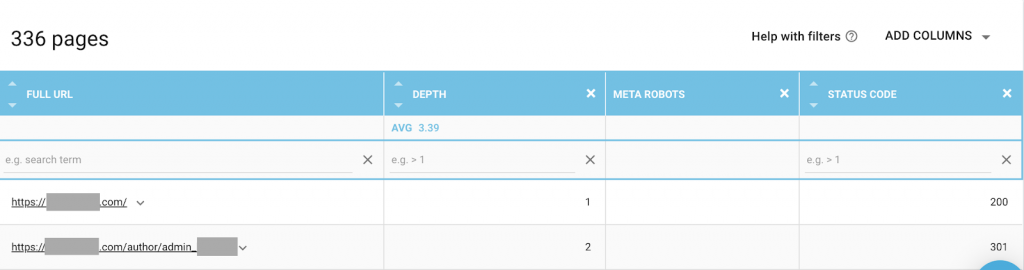
Deve ser (“noindex, nofollow”).
Por quê?
Cada caso é um caso, mas este site é um pequeno blog pessoal. Há apenas um autor que publica no blog, e o domínio é o nome do autor. Nesse caso, a página “autor” não fornece informações adicionais, mesmo sendo gerada pela plataforma de blogs.
Outro cenário pode ser um site onde as categorias no blog são importantes. Quando o proprietário deseja classificar as categorias em seu blog, os meta-robôs devem ser (“seguir, indexar”) ou padrão nas páginas da categoria.
Em um cenário diferente, para um site grande e conhecido onde grandes especialistas em SEO escrevem artigos que são seguidos pela comunidade, o nome do autor no Google funciona como uma marca. Nesse caso, você provavelmente gostaria de indexar alguns nomes de autores.
Como você pode ver, os meta-robôs podem ser usados de muitas maneiras diferentes.
Como corrigi-lo:
Peça a um desenvolvedor da Web para alterar a meta-tag do robô conforme necessário. No caso acima, para um site pequeno, posso fazer isso sozinho acessando cada página e alterando-a manualmente. Se você estiver usando o WordPress, poderá alterar isso nas configurações do RankMath ou Yoast.
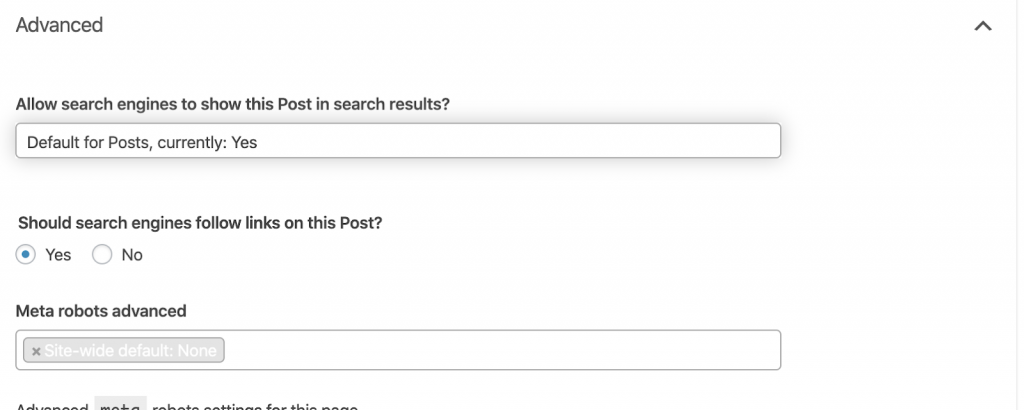
4) Erros 4xx:
Esses são erros no lado do cliente e podem ser 401, 403 e 404.
- 404 Página Não Encontrada:
Este erro ocorre quando uma página não está disponível no endereço de URL indexado. Ele pode ter sido movido ou excluído, e o endereço antigo não foi redirecionado corretamente usando a função 301 do servidor web. Os erros 404 são uma experiência ruim para os usuários e representam um problema técnico de SEO que deve ser resolvido. É uma boa coisa verificar frequentemente os 404s e corrigi-los, e não deixá-los para serem tentados repetidamente por agentes de rastreamento desperdiçando seu orçamento.
Como corrigi-lo:
Precisamos encontrar os endereços que retornam 404s e corrigi-los usando redirecionamentos 301 se o conteúdo ainda existir. Ou, se forem imagens, podem ser substituídas por novas mantendo o mesmo nome de arquivo.
- 401 não autorizado
Este é um problema de permissão. O erro 401 geralmente ocorre quando a autenticação é necessária, como nome de usuário e senha.
Como corrigi-lo:
Aqui estão duas opções: A primeira é bloquear a página dos mecanismos de pesquisa usando robots.txt. A segunda opção é remover o requisito de autenticação.
- 403 Proibido
Este erro é semelhante ao erro 401. O erro 403 acontece porque a página possui links que não são acessíveis ao público.

Como corrigi-lo:
Altere o requisito no servidor para permitir o acesso à página (somente se for um erro). Se você precisar que esta página fique inacessível, remova todos os links internos e externos da página.
- 400 Solicitação Inválida
Isso ocorre quando o navegador não consegue se comunicar com o servidor web. Esse erro geralmente ocorre por sintaxe de URL incorreta.
Como corrigi-lo:
Encontre links para esses URLs e corrija a sintaxe. Se isso não puder ser corrigido, você precisará entrar em contato com o desenvolvedor da Web para corrigi-los.
Nota: Podemos encontrar 400 erros com ferramentas ou no Google Console

5) Mapas do site
O mapa do site é uma lista de todos os URLs que o site contém. Ter um sitemap(s) melhora a localização porque ajuda os rastreadores a encontrar e entender seu conteúdo.
Temos diferentes tipos de sitemaps e precisamos garantir que todos estejam em boas condições.
Os mapas do site que devemos ter são:
- Mapa do site HTML: estará no seu site e ajudará os usuários a navegar e encontrar as páginas em seu site
- Sitemap XML: Este é um arquivo que ajudará os mecanismos de pesquisa a rastrear seu site (como prática recomendada, ele deve ser incluído no arquivo robots.txt).
- Mapa do site XML de vídeo: o mesmo que acima.
- Imagens XML do sitemap: Também é o mesmo que acima. É recomendável criar sitemaps separados para imagens, vídeos e conteúdo.
Para sites grandes, é recomendável ter vários sitemaps para melhor rastreabilidade, pois os sitemaps não devem conter mais de 50.000 URLs.
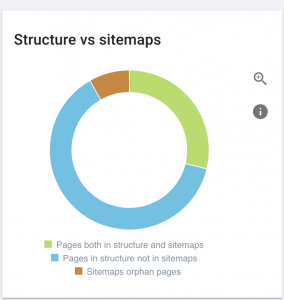
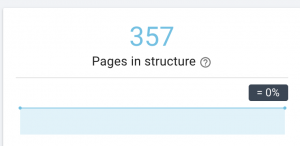
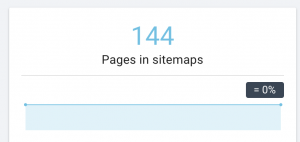
Este site tem problemas com o mapa do site.
Como corrigimos:
Corrigimos isso gerando diferentes sitemaps para: conteúdo, imagens e vídeos. Em seguida, os enviamos por meio do Google Search Console e também criamos um sitemap HTML para o site. Não precisamos de um desenvolvedor web para isso. Podemos usar qualquer ferramenta online gratuita para gerar mapas do site.
6) HTTP/HTTPS (conteúdo duplicado)
Muitos sites têm esses problemas como resultado da migração de HTTP para HTTPS. Se for esse o caso, o site mostrará as versões HTTP e HTTPS nos mecanismos de pesquisa. Como consequência desse problema técnico comum, os rankings são diluídos. Esses problemas também geram problemas de conteúdo duplicado.
![]()

Como corrigi-lo:
Peça a um desenvolvedor da Web para corrigir esse problema forçando todos os HTTP para HTTPS.
Nota : Nunca redirecione todo o HTTP para a página inicial do HTTPS, pois isso gerará erros soft 404. (Você deve dizer isso ao desenvolvedor da web; lembre-se de que eles não são SEOs.)
7) Paginação
Trata-se do uso de uma tag HTML (“rel = prev” e “rel = next”) que estabelece relações entre as páginas e mostra aos buscadores que o conteúdo apresentado em diferentes páginas deve ser identificado ou relacionado a uma única. A paginação é usada para limitar o conteúdo para UX e o peso de uma página para a parte técnica, mantendo-os abaixo de 3 MB. Podemos usar uma ferramenta gratuita para verificar a paginação.
A paginação deve ter referências autocanônicas e indicar um “rel = prev” e “rel = next”. As únicas informações duplicadas serão o meta título e a meta descrição, mas isso pode ser alterado pelos desenvolvedores para criar um pequeno algoritmo para que cada página tenha um meta título e uma meta descrição gerados.
Como corrigi-lo:
Peça a um desenvolvedor da Web para implementar tags HTML de paginação com tag autocanônica.
Rastreador de SEO Oncrawl
 Decouvir
Decouvir8) Página personalizada 404 não encontrada
Uma resposta 404 é, como discutimos antes, um erro “ Não encontrado ” que leva os usuários a um link quebrado ou a uma página inexistente. Esta é uma oportunidade para redirecionar os usuários para o lugar certo. Existem ótimos exemplos de páginas 404 personalizadas. Este é um must-have.
Aqui está um exemplo de uma ótima página personalizada 404:

Como corrigi-lo:
Crie uma página 404 personalizada: pense em algo incrível para adicionar a ela. Transforme esse erro em uma oportunidade para o seu negócio.
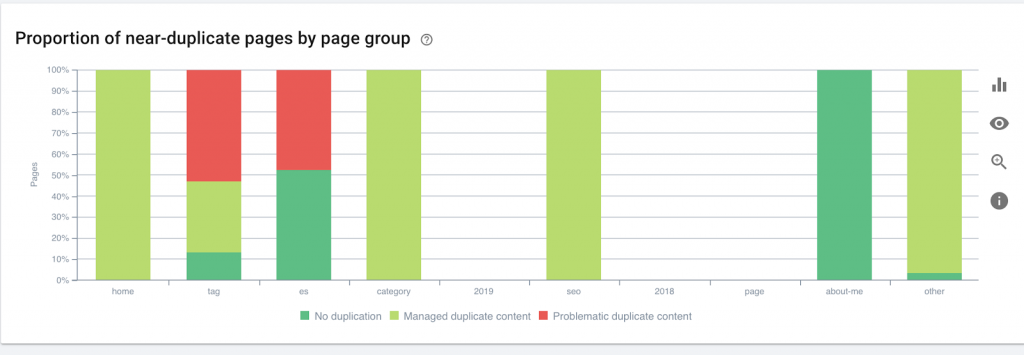
9) Profundidade/estrutura do local
A profundidade da página é o número de cliques em que sua página está localizada no domínio raiz. John Mueller, do Google, disse que “as páginas mais próximas da página inicial têm mais peso”. Por exemplo, vamos imaginar que a página aqui exija a seguinte navegação para ser acessada:

A página “tapetes” está a 4 cliques da página inicial. Recomenda-se não ter páginas localizadas a mais de 4 cliques de distância de casa, pois os mecanismos de pesquisa têm dificuldade em rastrear páginas mais profundas.
Este gráfico mostra o grupo de páginas por profundidade. Isso nos ajuda a entender se a estrutura de um site precisa ser reformulada.
Como corrigi-lo:
As páginas mais importantes devem estar mais próximas da página inicial do UX, para facilitar o acesso dos usuários e para uma melhor estrutura do site. É muito importante levar isso em consideração na hora de criar uma estrutura de site ou reestruturar um site.
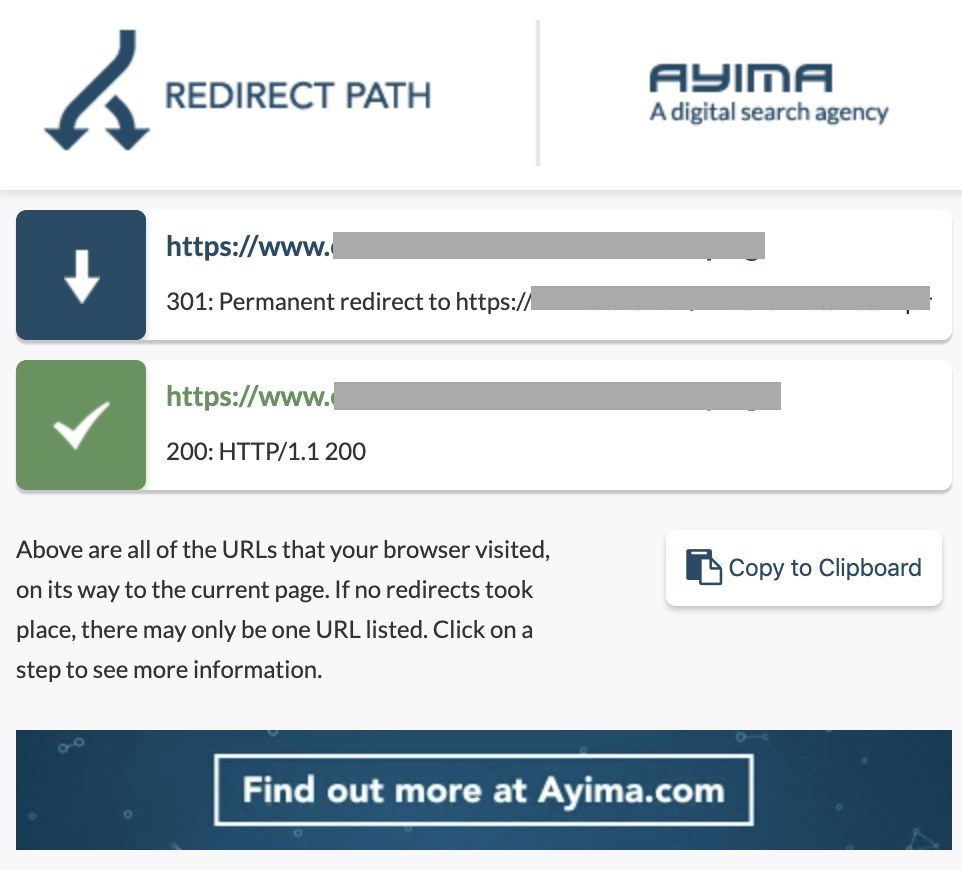
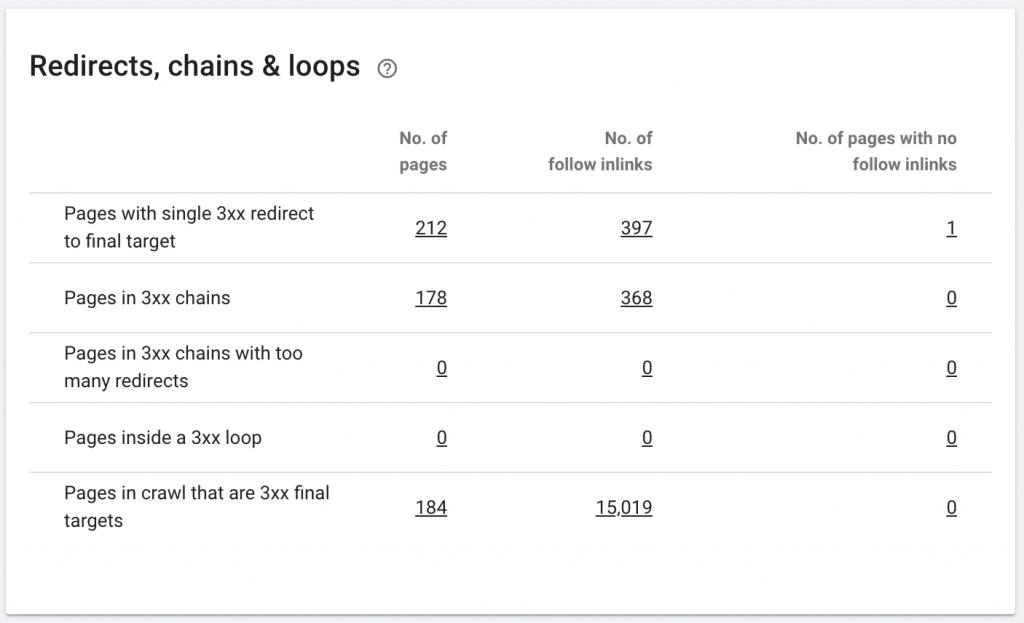
10. Redes de redirecionamento
Uma cadeia de redirecionamento ocorre quando uma série de redirecionamentos ocorre entre URLs. Essas cadeias de redirecionamento também podem criar loops. Ele também apresenta problemas para o Googlebot e desperdiça o orçamento de rastreamento.
Podemos identificar cadeias de redirecionamentos usando o caminho de redirecionamento da extensão do Chrome ou no OnCrawl.
Como corrigi-lo:
Corrigir isso é muito fácil se você estiver trabalhando com um site WordPress. Basta ir ao redirecionamento e procurar a cadeia - exclua todos os links envolvidos na cadeia se essas alterações aconteceram há mais de 2-3 meses e deixe o último redirecionamento para a URL atual. Os desenvolvedores da Web também podem ajudar com isso fazendo todas as alterações necessárias no arquivo .htacces, se necessário. Você pode verificar e alterar as longas cadeias de redirecionamento em seus plugins de SEO.
11) Canônicos
Uma tag canônica informa aos mecanismos de pesquisa que a URL é uma cópia de outra página. Este é um grande problema que está presente em muitos sites. Não implementar canônicos da maneira correta, ou implementá-los, criará problemas de conteúdo duplicado.
Os canônicos são comumente usados em sites de comércio eletrônico onde um produto pode ser encontrado várias vezes em diferentes categorias, como: tamanho, cor, etc.

Você pode usar o OnCrawl para saber se suas páginas têm tags canônicas e se estão implementadas corretamente ou não. Você pode então explorar e corrigir quaisquer problemas.
Como corrigimos:
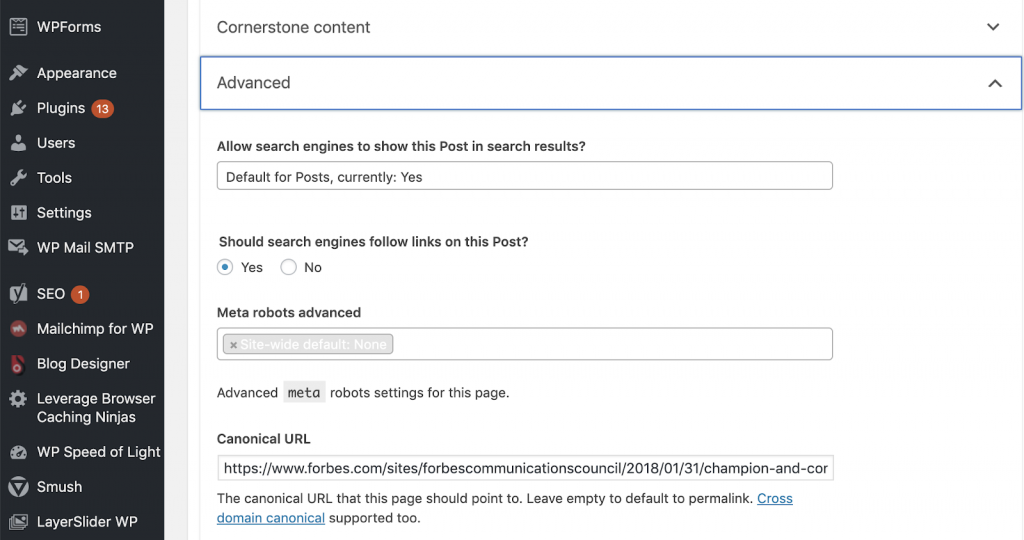
Podemos corrigir problemas canônicos usando Yoast SEO se estivermos trabalhando no WordPress. Vamos para o painel do WordPress e depois para Yoast -setting – advanced.
Executando sua própria auditoria
Os SEOs que desejam começar a mergulhar no SEO técnico precisam de um guia de etapas rápidas a serem seguidas para melhorar a saúde do SEO. Falando sobre SEO técnico com John Shehata, vice-presidente de Audience Grow da Conde Nast e fundador da NewzDash no Global Marketing Day em Nova York em outubro de 2019.
Eis o que ele me disse:
“Muitas pessoas na indústria de SEO não são técnicas. Agora, nem todo SEO entende como codificar e é difícil pedir às pessoas para fazerem isso. Algumas empresas, o que elas fazem é contratar desenvolvedores e treiná-los para se tornarem SEOs para preencher a lacuna técnica de SEO.”
Na minha opinião, os SEOs que não têm o conhecimento completo do código ainda podem se sair muito bem no Tech SEO sabendo como executar uma auditoria, identificando elementos-chave, relatando, solicitando implementação aos desenvolvedores da Web e, finalmente, testando as alterações.
Pronto para começar? Baixe a lista de verificação para esses principais problemas.
