
Avaliando a qualidade das previsões de impacto causal
Publicados: 2022-02-15CausalImpact é um dos pacotes mais populares usados na experimentação de SEO. Sua popularidade é compreensível.
A experimentação de SEO fornece insights e maneiras interessantes para os SEOs relatarem o valor de seu trabalho.
No entanto, a precisão de qualquer modelo de aprendizado de máquina depende das informações de entrada fornecidas.
Simplificando, a entrada errada pode retornar a estimativa errada.
Neste post, mostraremos como o CausalImpact pode ser confiável (e não confiável). Também aprenderemos a ter mais confiança nos resultados de seus experimentos.
Primeiramente, forneceremos uma breve visão geral de como o CausalImpact funciona. Em seguida, discutiremos a confiabilidade das estimativas CausalImpact. Por fim, aprenderemos sobre uma metodologia que pode ser usada para estimar os resultados de seus próprios experimentos de SEO.
O que é Impacto Causal e como funciona?
CausalImpact é um pacote que usa estatísticas Bayesianas para estimar o efeito de um evento na ausência de um experimento. Essa estimativa é chamada de inferência causal.
A inferência causal estima se uma mudança observada foi causada por um evento específico.
É frequentemente usado para avaliar o desempenho de experimentos de SEO.
Por exemplo, quando dada a data de um evento, CausalImpact (CI) usará os pontos de dados antes da intervenção para prever os pontos de dados após a intervenção. Ele então comparará a previsão com os dados observados e estimará a diferença com um certo limite de confiança.
Além disso, grupos de controle podem ser usados para tornar as previsões mais precisas.
Diferentes parâmetros também terão um impacto na precisão da previsão:
- Tamanho dos dados de teste.
- Duração do período anterior ao experimento.
- Escolha do grupo de controle a ser comparado.
- Hiperparâmetros de sazonalidade.
- Número de iterações.
Todos esses parâmetros ajudam a fornecer mais contexto ao modelo e aumentar sua confiabilidade.
Oncrawl BI
 Descobrir
DescobrirPor que avaliar a precisão dos experimentos de SEO é importante?
Nos últimos anos, analisei muitos experimentos de SEO e algo me impressionou.
Muitas vezes, o uso de diferentes grupos de controle e prazos em conjuntos de testes idênticos e datas de intervenção produziu resultados diferentes.
Para ilustração, abaixo estão dois resultados do mesmo evento.
O primeiro retornou um declínio estatisticamente significativo. 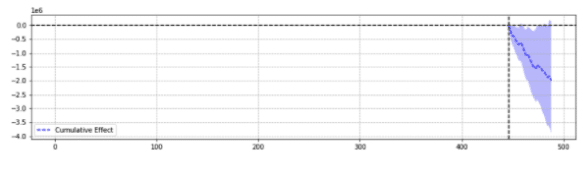
O segundo não foi estatisticamente significativo. 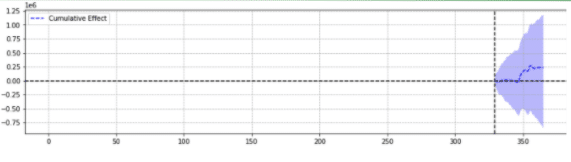
Simplificando, para o mesmo evento, resultados diferentes foram retornados com base nos parâmetros escolhidos.
É preciso se perguntar qual previsão é precisa.
No final das contas, “estatisticamente significativo” não deveria aumentar a confiança em nossas estimativas?
Definições
Para entender melhor o mundo dos experimentos de SEO, o leitor deve estar ciente dos conceitos básicos dos experimentos de SEO:
- Experimento : um procedimento realizado para testar uma hipótese. No caso de inferência causal, tem uma data de início específica.
- Grupo de teste : um subconjunto dos dados aos quais uma alteração é aplicada. Pode ser um site inteiro ou uma parte do site.
- Grupo de controle : um subconjunto dos dados ao qual nenhuma alteração foi aplicada. Você pode ter um ou vários grupos de controle. Pode ser um site separado no mesmo setor ou uma parte diferente do mesmo site.
O exemplo abaixo ajudará a ilustrar esses conceitos:
Modificar o título (experimento) deve aumentar a CTR orgânica em 1% (hipótese) das páginas de produtos em cinco cidades (grupo de teste). As estimativas serão melhoradas usando um título inalterado em todas as outras cidades (grupo de controle).
Pilares da previsão precisa de experimentos de SEO
- Para simplificar, compilei alguns insights interessantes para profissionais de SEO que estão aprendendo como melhorar a precisão dos experimentos:
- Algumas entradas no CausalImpact retornarão estimativas erradas, mesmo quando estatisticamente significativas. Isso é o que chamamos de “falsos positivos” e “falsos negativos”.
- Não há uma regra geral que governe qual controle usar em um conjunto de teste. Um experimento é necessário para definir os melhores dados de controle a serem usados para um conjunto de teste específico.
- Usar CausalImpact com o controle certo e a duração certa dos dados do pré-período pode ser muito preciso, com o erro médio sendo tão baixo quanto 0,1%.
- Alternativamente, usar CausalImpact com o controle errado pode levar a uma alta taxa de erro. Experimentos pessoais mostraram variações estatisticamente significativas de até 20%, quando na verdade não houve mudança.
- Nem tudo pode ser testado. Alguns grupos de teste quase nunca retornam estimativas precisas.
- Experimentos com ou sem grupos de controle precisam de diferentes comprimentos de dados antes da intervenção.
Nem todos os grupos de teste retornarão estimativas precisas
Alguns grupos de teste sempre retornarão previsões imprecisas. Eles não devem ser usados para experimentação.
Grupos de teste com grandes variações anormais de tráfego geralmente retornam resultados não confiáveis.
Por exemplo, no mesmo ano um site teve uma migração de site, foi impactado pela pandemia de covid, e parte do site ficou “noindexed” por 2 semanas devido a um erro técnico. Fazer experimentos nesse site fornecerá resultados não confiáveis.
As conclusões acima foram reunidas através de uma extensa série de testes feitos usando a metodologia descrita abaixo.
Quando não estiver usando grupos de controle
- Usar um controle em vez de um simples pré-pós pode aumentar em até 18 vezes a precisão da estimativa.
- Usar 16 meses de dados anteriores foi tão preciso quanto usar 3 anos.
Ao usar grupos de controle
- Usar o controle certo geralmente é melhor do que usar vários controles. No entanto, um único controle aumenta os riscos de previsão equivocada nos casos em que o tráfego do controle varia muito.
- Escolher o controle certo pode aumentar a precisão em 10 vezes (por exemplo, um relatando +3,1% e o outro +4,1% quando na verdade era +3%).
- A maioria dos padrões de tráfego correlacionados entre dados de teste e dados de controle não significa necessariamente melhores estimativas.
- Usar 16 meses de dados anteriores NÃO foi tão preciso quanto usar 3 anos.
Cuidado com o tamanho dos dados antes dos experimentos
Curiosamente, ao experimentar com grupos de controle, usar 16 meses de dados anteriores pode causar uma taxa de erro muito intensa.
Na verdade, os erros podem ser tão grandes quanto estimar um aumento de 3x no tráfego quando não houve mudanças reais.
No entanto, o uso de 3 anos de dados removeu essa taxa de erro. Isso contrasta com experimentos simples pré-pós, em que essa taxa de erro não foi aumentada aumentando a duração de 16 para 36 meses.
Isso não significa que usar controles é ruim. É bem o contrário.
Ele simplesmente mostra como a adição de controle afeta as previsões.

Este é o caso quando há grandes variações no grupo de controle.
Essa dica é especialmente importante para sites que tiveram variações anormais de tráfego no ano passado (erro técnico crítico, pandemia de COVID etc.).
Como Avaliar a Previsão de Impacto Causal?
Agora, não há pontuação de precisão construída na biblioteca CausalImpact. Portanto, deve-se inferir o contrário.
Pode-se observar como outros modelos de aprendizado de máquina estimam a precisão de suas previsões e perceber que a Soma dos Erros dos Quadrados (SSE) é uma métrica muito comum.
A soma dos erros dos quadrados, ou soma dos quadrados dos resíduos, calcula a soma de todas as (n) diferenças entre as expectativas (yi) e os resultados reais (f(xi)), ao quadrado. 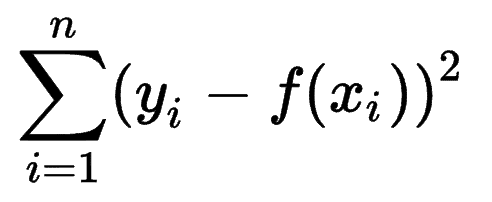
Quanto menor o SSE, melhor o resultado.
O desafio é que, com experimentos pré-pós no tráfego de SEO, não há resultados reais.
Embora nenhuma alteração tenha sido feita no local, algumas alterações podem ter ocorrido fora do seu controle (por exemplo, atualização do algoritmo do Google, novo concorrente etc.). O tráfego de SEO também não varia em um número fixo, mas varia progressivamente para cima e para baixo.
Especialistas em SEO podem se perguntar como superar o desafio.
Apresentando variações falsas
Para ter certeza do tamanho da variação causada por um evento, o experimentador pode introduzir variações fixas em diferentes pontos no tempo e ver se CausalImpact estimou com sucesso a mudança.
Melhor ainda, o especialista em SEO pode repetir o processo para diferentes grupos de teste e controle.
Usando Python, variações fixas foram introduzidas nos dados em diferentes datas de intervenção para o pós-período.
A soma dos erros dos quadrados foi então estimada entre a variação relatada por CausalImpact e a variação introduzida.
A ideia fica assim:
- Escolha um teste e controle os dados.
- Introduzir intervenções falsas nos dados reais em datas diferentes (por exemplo, aumento de 5%).
- Compare as estimativas CausalImpact para cada uma das variações introduzidas.
- Calcule a soma dos erros dos quadrados (SSE).
- Repita a etapa 1 com vários controles.
- Escolha o controle com o menor SSE para experimentos do mundo real
A Metodologia
Com a metodologia abaixo, criei uma tabela que pude usar para identificar qual controle tinha as melhores e piores taxas de erro em diferentes momentos.
Primeiro, escolha um teste e dados de controle e introduza variações de -50% a 50%.
Em seguida, execute CausalImpact (CI) e subtraia as variações relatadas por CI para a variação que você realmente introduziu.
Depois, calcule os quadrados dessas diferenças e some todos os valores.
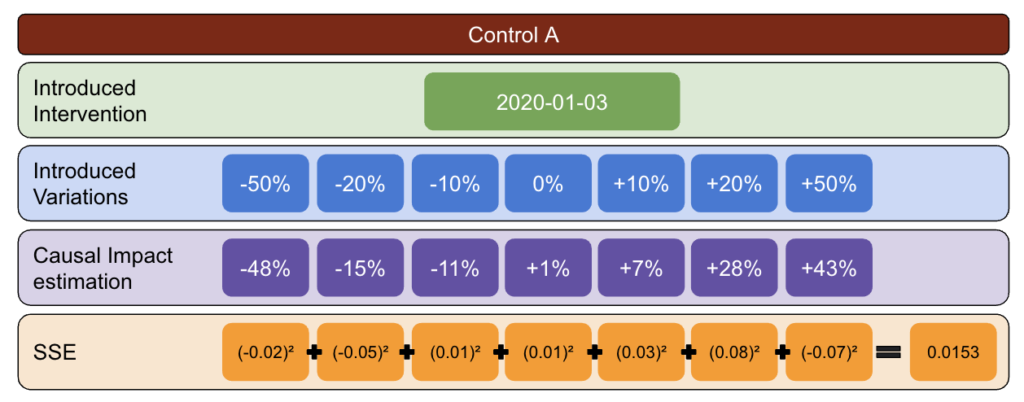
Em seguida, repita o mesmo processo em datas diferentes para reduzir o risco de um viés causado por uma variação real em uma data específica.
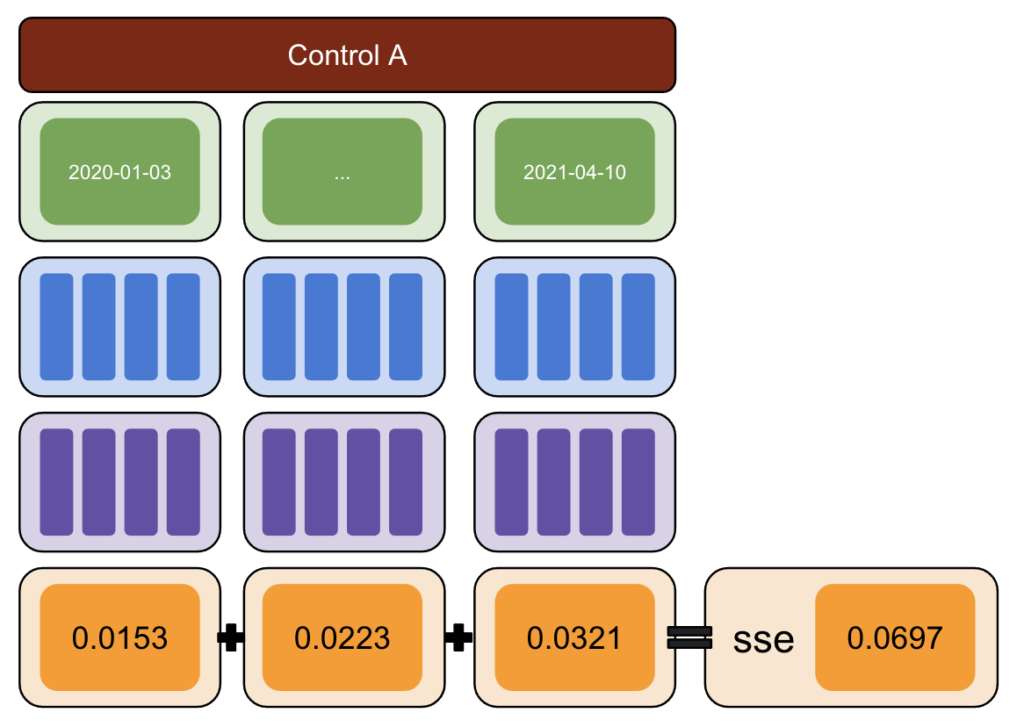
Novamente, repita com vários grupos de controle.
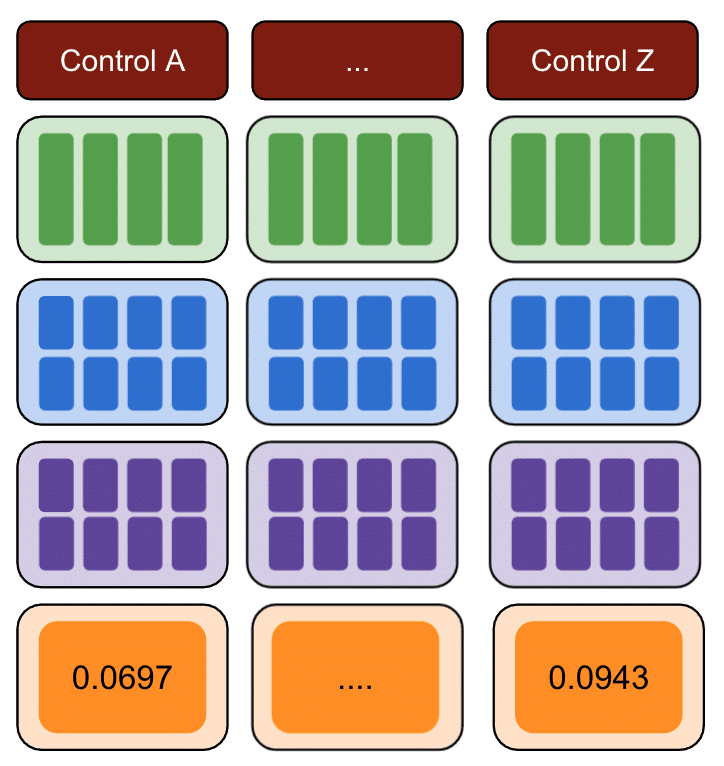
Por fim, o controle com o menor erro de soma dos quadrados é o melhor grupo de controle a ser usado para seus dados de teste.
Se você repetir cada uma das etapas para cada um dos seus dados de teste, o resultado variará.
Na tabela resultante, cada linha representa um grupo de controle, cada coluna representa um grupo de teste. Os dados dentro são o SSE.
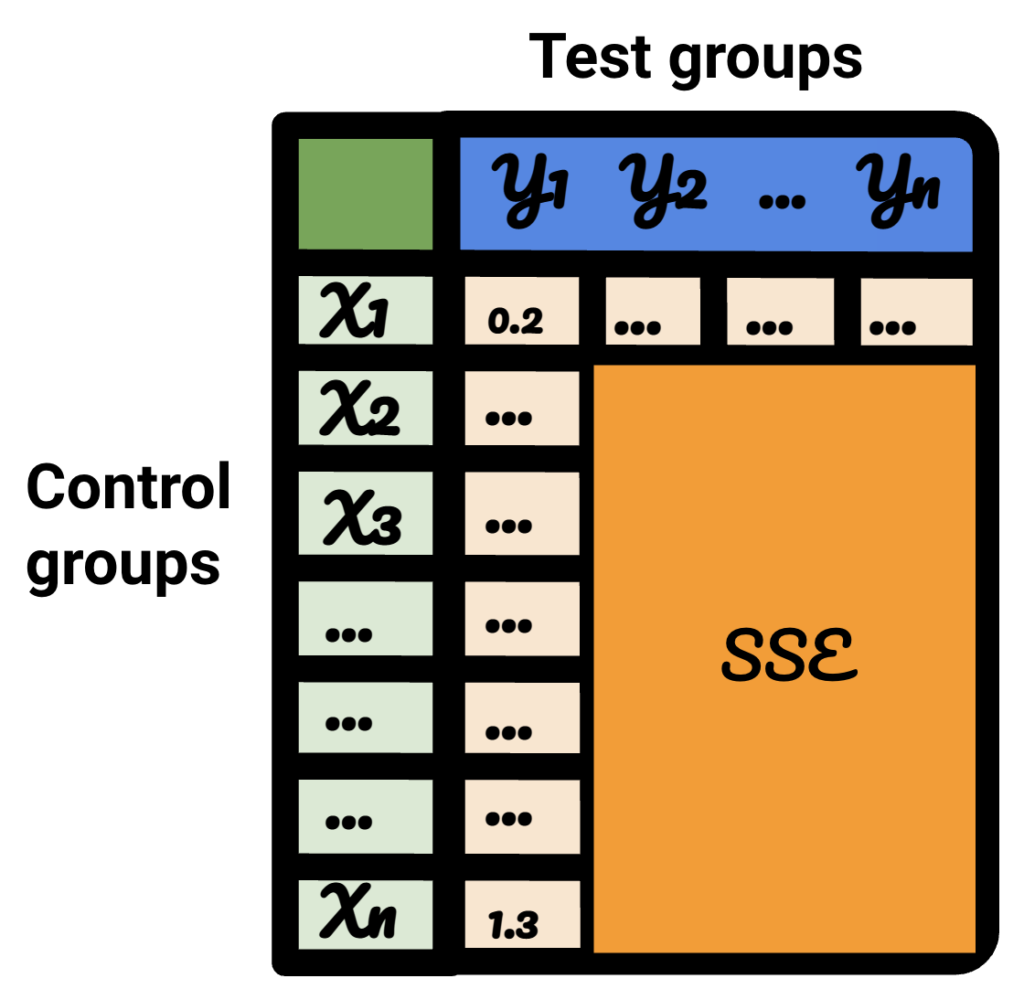
Classificando essa tabela, agora estou confiante de que, para cada um dos grupos de teste, posso selecionar o melhor grupo de controle para ele.
Devemos ou não usar grupos de controle?
As evidências mostram que o uso de grupos de controle ajuda a ter melhores estimativas do que simples pré-pós.
No entanto, isso só é verdade se escolhermos o grupo de controle certo.
Quanto tempo deve ser o período de estimativa?
A resposta para isso depende dos controles que estamos selecionando.
Quando não estiver usando um controle, 16 meses de experiência anterior parecem suficientes.
Ao usar um controle, usar apenas 16 meses pode levar a grandes taxas de erro. Usar 3 anos ajuda a reduzir o risco de má interpretação.
Devemos usar 1 controle ou vários controles?
A resposta a essa pergunta depende dos dados do teste.
Dados de teste muito estáveis podem ter um bom desempenho quando comparados com vários controles. Nesse caso, isso é bom porque usar muito controle torna o modelo menos impactado por flutuações insuspeitas em um dos controles.
Em outros conjuntos de dados, usar vários controles pode tornar o modelo 10 a 20 vezes menos preciso do que usar um único.
Trabalho interessante na comunidade de SEO
CausalImpact não é a única biblioteca que pode ser usada para testes de SEO, nem a metodologia acima é a única solução para testar sua precisão.
Para aprender soluções alternativas, leia alguns dos incríveis artigos compartilhados por pessoas da comunidade de SEO.
Primeiro, Andrea Volpini escreveu um artigo interessante sobre como medir a eficácia do SEO usando a Análise CausalImpact.
Então, Daniel Heredia cobriu o pacote Profeta do Facebook para previsão de tráfego de SEO com Profeta e Python.
Embora a biblioteca do Profeta seja mais apropriada para previsões do que para experimentos, vale a pena aprender várias bibliotecas para obter uma compreensão firme do mundo das previsões.
Por fim, fiquei muito satisfeito com a apresentação de Sandy Lee no Brighton SEO, onde ele compartilhou insights de Data Science para testes de SEO e levantou algumas das armadilhas dos testes de SEO.
Coisas a considerar ao fazer experimentos de SEO
- As ferramentas de teste de divisão de SEO de terceiros são ótimas, mas também podem ser imprecisas. Seja cuidadoso ao escolher sua solução.
- Embora eu tenha escrito sobre isso no passado, você não pode fazer experimentos de teste de divisão de SEO com o Google Tag Manager, a menos que seja do lado do servidor. A melhor maneira é implantar por meio de CDNs.
- Seja ousado ao testar. Pequenas mudanças geralmente não são captadas pelo CausalImpact.
- O teste de SEO nem sempre deve ser sua primeira escolha.
- Existem alternativas para testar alterações menores, como tags de título. Testes A/B do Google Ads ou testes A/B na plataforma. Testes A/B reais são mais precisos do que testes de divisão de SEO e geralmente fornecem mais informações sobre a qualidade de seus títulos.
Resultados reproduzíveis
Neste tutorial, eu queria focar em como alguém poderia melhorar a precisão dos experimentos de SEO sem o ônus de saber codificar. Além disso, a fonte dos dados pode variar e cada site é diferente.
Portanto, o código Python que usei para produzir este conteúdo não fazia parte do escopo deste artigo.
No entanto, com a lógica, você pode reproduzir os experimentos acima.
Conclusão
Se você tivesse apenas uma lição a tirar deste artigo, seria que a análise CausalImpact pode ser muito precisa, mas sempre pode estar muito distante.
É muito importante para os SEOs que desejam usar este pacote entender com o que estão lidando. O resultado da minha própria jornada é que eu não confiaria no CausalImpact sem primeiro testar a precisão do modelo nos dados de entrada.