
Como automatizar a modelagem do mix de marketing com uma planilha de feed de dados MMM
Publicados: 2022-06-16A modelagem do mix de marketing ou MMM está vendo um renascimento, mais de 60 anos desde que entrou em uso comum. Ao contrário da maioria dos métodos de atribuição de marketing, o MMM não exige dados no nível do usuário, em vez de modelar quais canais merecem crédito pelas vendas mapeando estatisticamente picos e quedas nos gastos para ações e eventos em seus canais de marketing. Atualizando da regressão linear simples para técnicas como regressão em cume ou métodos Bayesianos, a modelagem do mix de marketing está sendo reinventada para a era moderna.

Quer saber mais sobre o MMM?
Leia os prós e contras sobre modelagem de mix de marketing versus modelagem de atribuição
No entanto, existem grandes obstáculos a serem superados. A construção de um modelo pode levar de 3 a 6 meses, de acordo com o Meta/Facebook, que trabalha em sua biblioteca MMM de código aberto desde outubro de 2021. De acordo com suas estimativas, cerca de 50% do tempo é gasto coletando e limpando dados antes do início da modelagem. . Isso corresponde à minha experiência na Recast - e anteriormente à Harry's - bem como aos resultados de um estudo da CrowdFlower que descobriu que 60% do tempo de ciência de dados é gasto limpando e organizando dados.
Avanço rápido >>
- Limpeza de dados
- Construindo um modelo de mix de marketing
- Modelagem automatizada
A limpeza de dados é 60% do trabalho e como torná-lo 0%
Para construir um modelo preciso, você precisa de seus dados em um formato específico. Preparar os dados é demorado, portanto, os projetos de MMM levam mais tempo do que o necessário. Isso torna o MMM uma habilidade especializada e cara, de modo que a maioria das empresas pode construir apenas um ou dois modelos por ano. Se você puder automatizar o processo usando uma ferramenta como Supermetrics para criar um feed de dados MMM, poderá atualizar seu modelo regularmente, permitindo otimizar melhor seu orçamento de marketing.
Formato de dados tabulares
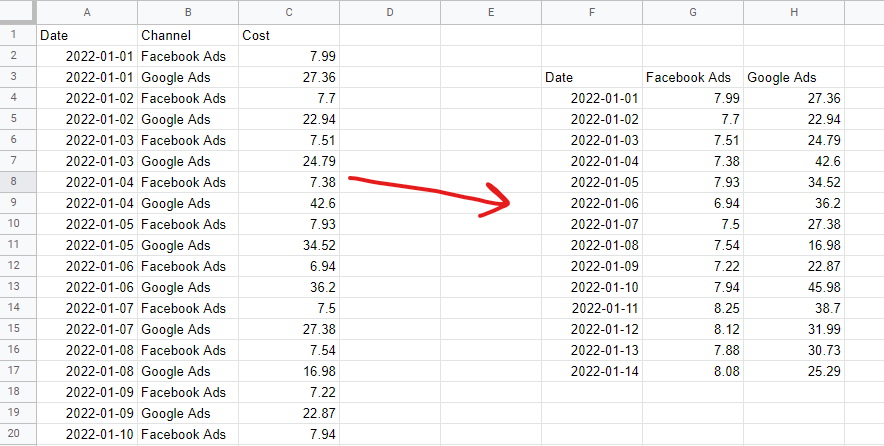
Para construir um modelo de mix de marketing, você deve ter seus dados dispostos em um formato tabular não empilhado. Isso significa uma linha por observação - geralmente dias ou semanas - e uma coluna por 'recurso' do modelo - normalmente gastos com mídia e variáveis orgânicas ou externas. Dados categóricos — por exemplo, uma lista de feriados nacionais — precisam ser codificados para variáveis fictícias — 1 quando for esse feriado, 0 quando não for.
Fontes de dados combinadas
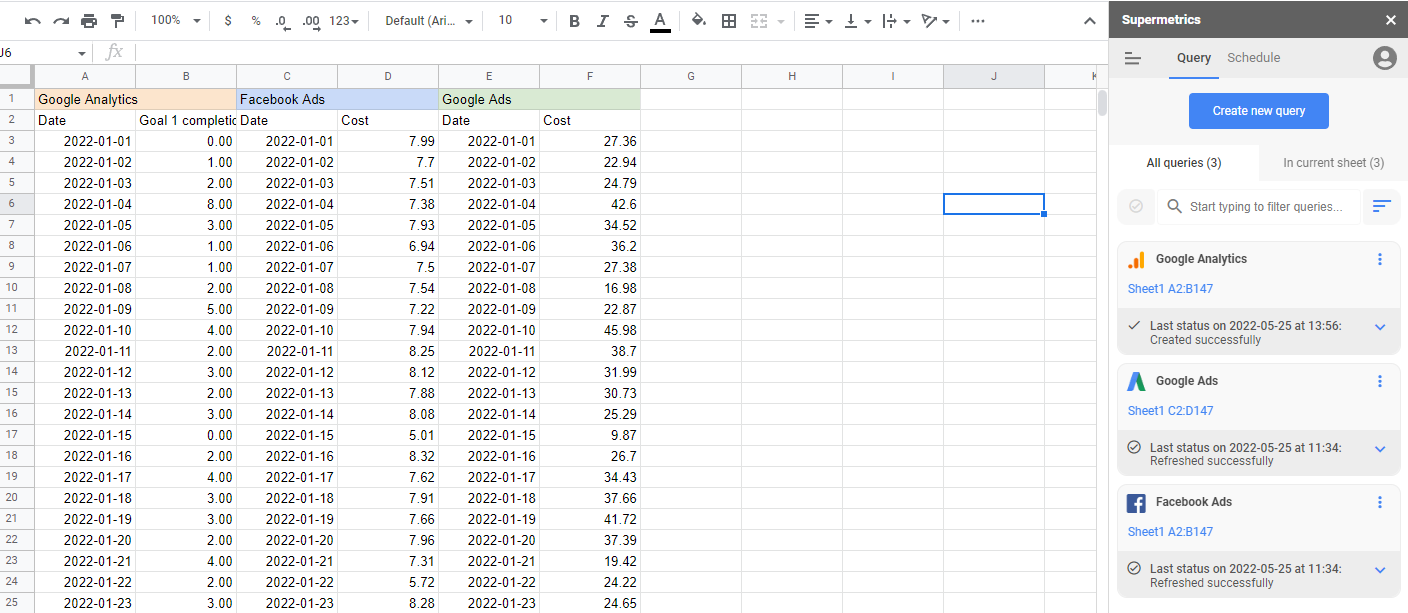
Para criar um modelo de atribuição de marketing, você precisa ter todos os seus dados de marketing em um só lugar. Isso é o que a Supermetrics trata para você automaticamente. Com mais de 90 conectores, todos os seus gastos de marketing, eventos e atividades podem ser reunidos em um só lugar, manipulados conforme necessário e depois exportados para o formato e local de que você precisa.
Exportando para o Planilhas Google
Depois de ter uma conta Supermetrics, basta acessar Extensões > Complementos > Obter complementos e instalá-lo. Ele solicitará que você se autentique com sua conta do Google vinculada à sua conta Supermetrics e, em seguida, a barra lateral aparecerá no menu de extensões.
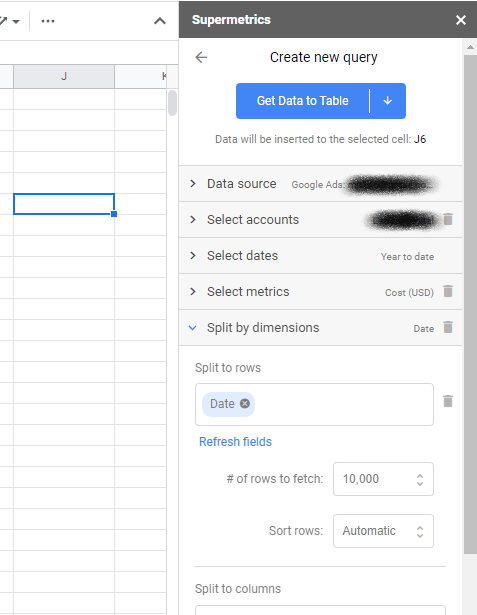
Feito isso, você pode iniciar a barra lateral—se ainda não tiver sido iniciada—e clicar para criar uma nova consulta. As consultas são como você decide quais dados extrair e de quais contas. Ao selecionar uma das plataformas de anúncios, como Facebook Ads e Google Ads, você será solicitado a autenticar e conceder acesso ao Supermetrics.
Em seguida, você escolherá a conta da qual deseja extrair dados e o período. Por fim, escolha suas métricas – geralmente custo ou impressões para MMM – e dimensões – selecione apenas a data para ser consistente com o formato tabular.
Opcionalmente, você pode adicionar um filtro se precisar selecionar um conjunto específico de campanhas. Por exemplo, se você tiver 'YT: ' no nome de suas campanhas do YouTube, talvez queira selecioná-las como uma origem separada e, em seguida, duplique a consulta e filtre para cada um de seus outros tipos de campanha.
Quando você terminar sua consulta, certifique-se de ter selecionado a célula para onde deseja que os dados sejam inseridos e clique em 'Obter dados para a tabela'. Se errar, basta duplicar a consulta e colocá-la no lugar certo, excluindo a outra.
Acho útil colocar o nome de cada fonte em uma célula acima da tabela para saber de onde estou extraindo os dados. O resultado deve ficar assim:
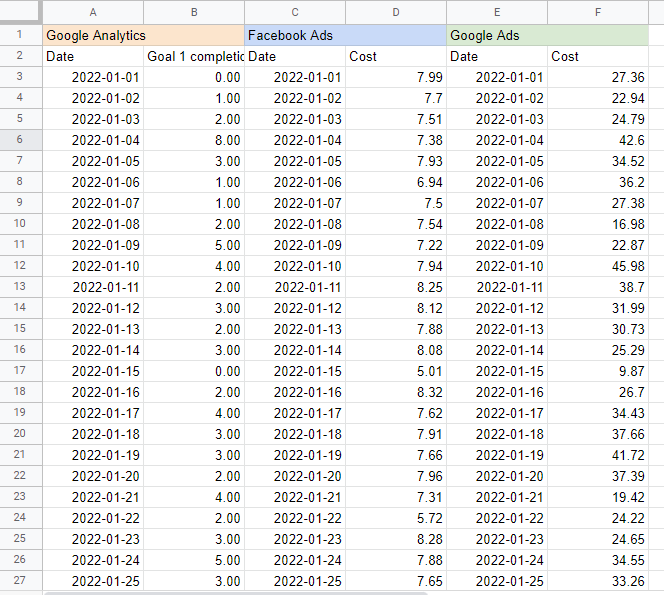
Como criar um modelo de mix de marketing no Planilhas Google
A modelagem do mix de marketing é uma ferramenta poderosa para atribuição, mas na verdade é mais acessível do que você imagina. A maioria dos praticantes usa código personalizado e estatísticas avançadas, mas você pode fazer o básico em uma tarde com nada mais do que Excel ou Planilhas Google.
Regressão linear com a função PROJ.LIN
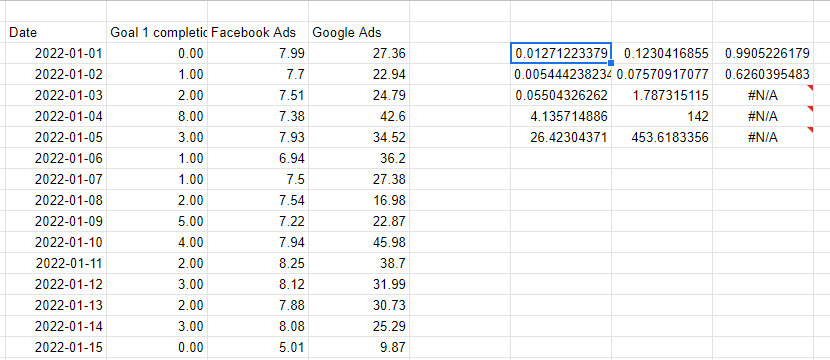
O Excel e o Google Sheets fornecem um método simples, a função PROJ.LIN, para fazer regressão linear multivariável. PROJ.LIN funciona passando a coluna que estamos tentando prever e, em seguida, várias colunas representando as variáveis que estamos usando para fazer a previsão. Os dois parâmetros finais são se queremos uma linha de interceptação – geralmente 1 para sim – e se queremos que a saída seja detalhada – contendo todas as estatísticas do modelo, não apenas os coeficientes.
Observe que as variáveis X que estamos usando para fazer a previsão precisam ser consecutivas, então acabei de referenciar as colunas à esquerda para repetir os valores um ao lado do outro.
Reprevisão com coeficientes do modelo
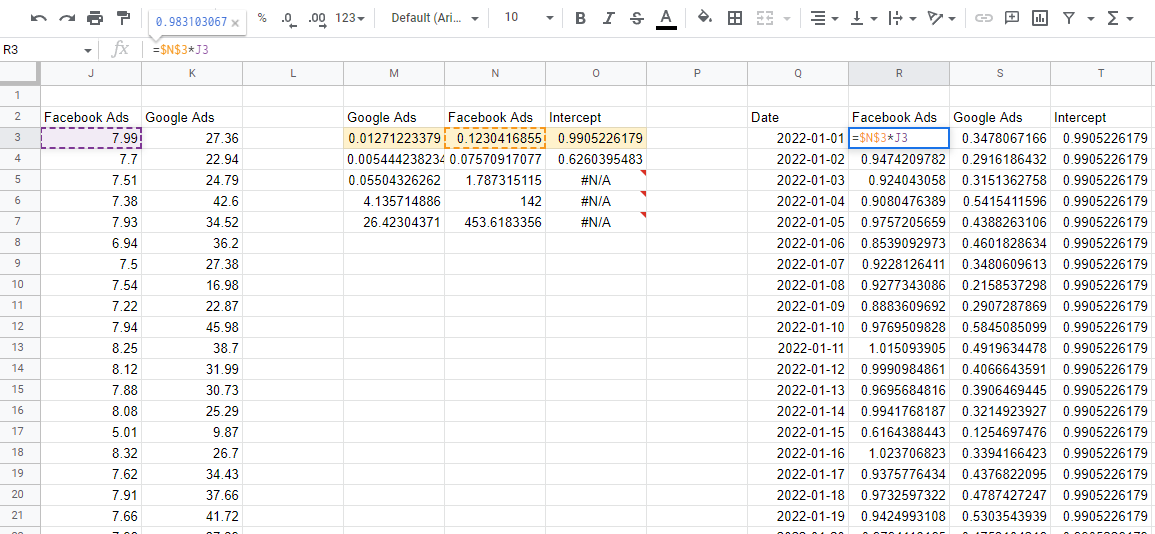
Agora que temos um modelo, precisamos usar os coeficientes para estimar o impacto de cada canal. Se pegarmos a linha superior de números, esses são os coeficientes, e os multiplicarmos pelos valores de entrada correspondentes de nossos dados - obteremos a contribuição de cada variável para as vendas totais.

Uma coisa a observar é que PROJ.LIN gera os coeficientes para trás. O primeiro valor a partir da esquerda é sempre a última variável que você insere, então eles continuam na ordem inversa até chegar ao último valor, que é a interceptação. Se você somar todos esses valores de contribuição, ele fornecerá as previsões do modelo, que você pode comparar com os valores reais para garantir que o modelo seja preciso.
Verificando as métricas de precisão do modelo
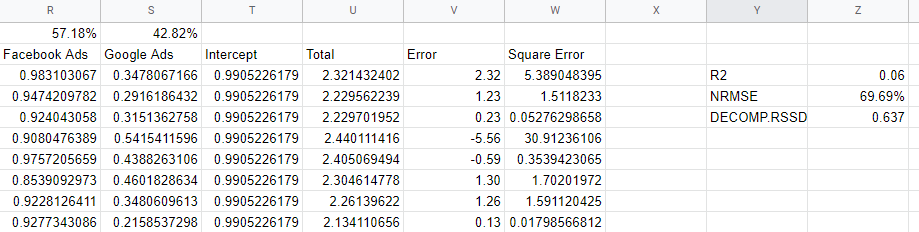
Como sabemos se nosso modelo é confiável? O modelo deve ajustar-se bem aos dados, deve ser capaz de prever novos dados não vistos e deve ter coeficientes plausíveis. Várias métricas de validação capturam esses requisitos.
Verifique as funções no modelo para ver como calcular essas métricas.
Para usar o modelo, vá para 'Arquivo' > 'Fazer uma cópia' > 'Iniciar Supermetrics' na lista de complementos > duplique este arquivo para outra conta e prossiga para a seleção da conta.
R2 ou R-quadrado é uma medida de quanto da variância nos dados é explicada pelo modelo, e está entre 0 e 1: um bom modelo estaria acima de 0,7, mas qualquer coisa próxima de 1 provavelmente é suspeita. Perto de 0, como nosso modelo, é um sinal de que não estamos incluindo variáveis suficientes em nosso modelo e precisamos incorporar coisas como canais orgânicos, feriados e fatores macroeconômicos.
'Erro do quadrado médio da raiz normalizado' é como medimos a precisão, e é encontrado tomando a diferença entre as previsões do modelo e os valores reais e, em seguida, encontrando a raiz dos valores quadrados como uma porcentagem do valor real. Idealmente, isso é feito com base em dados não vistos - um grupo de validação - mas em nosso modelo simples, apenas calculamos o erro em relação aos dados na amostra.
O procedimento de raiz e quadrado lida com valores negativos para nós e atua para penalizar erros realmente grandes. Isso pode ser interpretado como a porcentagem do modelo está desativada em um determinado dia, portanto, é uma medida útil e intuitiva.
A plausibilidade é um grande tópico, e geralmente é algo sobre o qual um analista deve ter a palavra final. No entanto, é útil ter uma métrica que você possa calcular programaticamente para que você entenda até que ponto o modelo se desvia em termos de suas descobertas do mix de canais atual.
Decomp RSSD é uma métrica inventada pela equipe de Robyn no Facebook que mediu a diferença entre sua alocação de gastos atual e quais canais geraram os maiores efeitos, conforme previsto pelo modelo. Se o modelo dissesse que seu maior canal não gerou tantas vendas, então você teria um alto RSSD de Decomp.
No nosso caso, temos um valor alto de 0,6 porque o modelo dá muito crédito ao Facebook, o que representa um gasto pequeno.
Entrega de MMMs automaticamente e em escala
A modelagem do mix de marketing é uma dessas atividades infinitamente escaláveis. Você pode obter resultados decentes em uma tarde com Excel ou Google Sheets e Supermetrics, como fizemos aqui, mas você também pode passar 3 meses com uma equipe de 6 cientistas de dados escrevendo código personalizado com algoritmos sofisticados como Bayesian MCMC para construir algo mais robusto e preciso.
Há uma lista de verificação de recursos para a construção de um modelo avançado, alguns dos quais exigem conhecimento avançado de estatística. Adicione à mistura vários engenheiros de dados caros para construir pipelines de dados se você não usar o Supermetrics para automatizar essa parte para você.
Quer saber mais sobre automação de mix de modelagem?
Confira nosso artigo de modelagem de mix de marketing automatizado
Esteja avisado: MMM é difícil. Você pode gastar US$ 500, US$ 5.000 ou US$ 50 mil em modelagem e ver resultados totalmente diferentes em precisão e robustez. O que realmente importa é o custo de oportunidade de errar a alocação dos gastos de marketing.
Se você gastar US $ 10 mil por mês, um modelo de planilha uma vez por trimestre ficará bem. No entanto, se você está gastando mais de US $ 100.000 por mês, mesmo com um desconto de 5% pode custar dezenas de milhares de dólares ao longo de um ano.
Não tem certeza de qual modelo de acesso a dados você precisa para seu feed MMM?
Confira nosso artigo para escolher o ideal para o seu negócio
É aí que faz sentido investir em modelagem mais avançada. Conduza uma análise de compilação versus compra para decidir entre uma solução personalizada criada em bibliotecas de código aberto como o Robyn do Facebook ou um software de atribuição avançado como o que construímos na Recast.
Sobre o autor
Michael Kaminsky é um econometrista com formação em saúde e economia ambiental. Anteriormente, ele formou a equipe de ciência de marketing da marca de produtos masculinos Harry's antes de co-fundar a Recast.

Melhore o desempenho do seu negócio
combinando marketing e inteligência de negócios em seu data warehouse