
Capacitando a segurança bancária: aprendizado de máquina para detecção de fraudes
Publicados: 2023-11-14Com cada oportunidade surge uma ameaça. A mudança para a digitalização no setor bancário melhorou a experiência do cliente e expandiu as bases de clientes para populações anteriormente não bancárias. A desvantagem foi que as transações online e as soluções de pagamento digital abriram novos caminhos para os fraudadores explorarem.
As conclusões de uma pesquisa sobre fraude da KMPG indicam que os ataques cibernéticos estão aumentando em frequência e gravidade, resultando em perdas de bilhões de dólares.
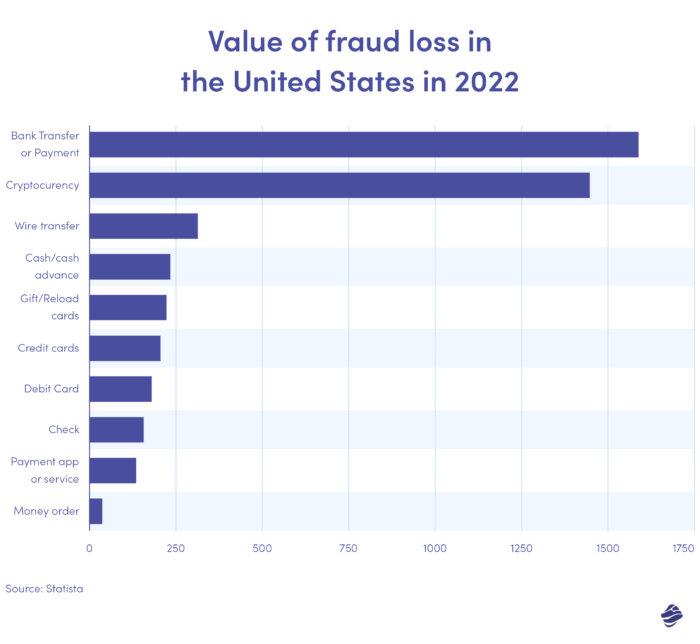
O gráfico acima ilustra o valor das perdas por fraude por método de pagamento nos Estados Unidos em 2022. As transferências bancárias e os pagamentos foram os mais elevados, com uma perda de 1,59 mil milhões de dólares.
Estas perdas forçaram as instituições bancárias a adotar novas soluções para detectar, mitigar e prevenir fraudes financeiras. Um desses métodos é a inteligência artificial (IA), especificamente o aprendizado de máquina.
Neste artigo, discutiremos tudo o que você precisa saber sobre aprendizado de máquina para detecção de fraudes , incluindo benefícios e aplicações da vida real.
Evolução da detecção de fraude
A detecção de fraude tradicional segue uma abordagem baseada em regras. Como o nome sugere, opera sob um conjunto de regras ou condições que determinam se uma transação é genuína ou fraudulenta. As condições comuns incluem a localização (a compra é fora da área habitual do utilizador?) e a frequência (o número e tipo de compra é habitual para o utilizador?).
Uma transação só é concluída quando atende às condições. Por exemplo, um cliente em Ohio repentinamente recebe uma cobrança de PDV na Nova Zelândia. A localização está fora do código de área do usuário, então o sistema sinaliza as transações como fraudulentas.
Existem várias desvantagens neste tipo de sistema de detecção de fraude.
- Produz um grande número de falsos positivos. É aqui que você bloqueia pagamentos de clientes genuínos.
- É inflexível. A abordagem baseada em regras utiliza resultados fixos, dificultando a adaptação às tendências da banca digital. Você deve mudar as regras para detectar novas formas de fraude.
- Não escala. Quando os dados aumentam, também aumenta o esforço necessário para evitá-los. Quaisquer alterações no sistema são feitas manualmente, tornando-o caro e demorado.
A detecção de fraude baseada em regras funciona. No entanto, as suas desvantagens tornam-no inadequado para ambientes digitais modernos. Não consegue reconhecer padrões e depende da intervenção humana.
Além disso, os hackers não seguem um cronograma das 9h às 17h e podem implantar métodos sofisticados, como falsificação de localização e representação do comportamento do cliente, para enganar os sistemas de detecção de fraudes. Portanto, você precisa de um sistema igualmente desenvolvido que funcione 24 horas por dia, 7 dias por semana.
Entre no aprendizado de máquina.
O aprendizado de máquina é uma inteligência artificial (IA) que usa dados para treinar algoritmos de detecção de fraudes para descobrir padrões e relacionamentos de dados, obter insights e fazer previsões.
Você já está familiarizado com o aprendizado de máquina, mesmo que não o conheça. Por exemplo, sempre que você interage com uma postagem no Instagram, você alimenta o algoritmo com informações sobre o tipo de conteúdo que você gosta. Em seguida, ele vasculha o aplicativo em busca de conteúdo semelhante para adicionar ao seu feed.
Como o aprendizado de máquina transformará a detecção de fraudes
A detecção de fraudes no setor bancário usando aprendizado de máquina já está mudando o setor, com identificação e resposta mais rápidas, flexíveis e precisas às fraudes.
O sistema de IA analisa padrões nos dados do cliente e altera automaticamente as regras com base em ameaças históricas e emergentes.
Lembra daquela cobrança de PDV da Nova Zelândia que mencionamos anteriormente? A detecção de fraude por meio de aprendizado de máquina consideraria que o mesmo cartão bancário possui uma compra para um voo para aquele local. Portanto, o novo débito é provavelmente legítimo.
Dois modelos são usados para treinar algoritmos para detectar fraudes: aprendizado de máquina supervisionado e aprendizado de máquina não supervisionado.
Aprendizado de máquina supervisionado
O modelo de aprendizagem supervisionada alimenta algoritmos com grandes quantidades de dados marcados como fraudulentos ou não fraudulentos. O algoritmo estuda esses exemplos e aprende quais padrões e relacionamentos distinguem as transações legítimas das fraudulentas.
Este modelo de aprendizagem é demorado, pois requer marcação manual de dados. Além disso, seus conjuntos de dados devem estar corretamente rotulados e bem organizados. Uma transação marcada incorretamente afetará a precisão do algoritmo.
Além disso, ele aprende apenas com as entradas incluídas no conjunto de treinamento. Assim, as transações por meio dos recursos do seu aplicativo de mobile banking recém-lançado que não faziam parte dos dados históricos não seriam sinalizadas. Existe agora uma brecha para os fraudadores explorarem.
Aprendizado de máquina não supervisionado
O modelo de aprendizagem não supervisionado usa o mínimo de intervenção humana. O algoritmo aprende padrões e relacionamentos a partir de grandes quantidades de dados não marcados, agrupando conjuntos de dados com base em semelhanças e diferenças.
O objetivo é detectar atividades incomuns não incluídas no conjunto de dados de treinamento. Assim, a aprendizagem não supervisionada continua onde a aprendizagem supervisionada diminui e detecta novas fraudes.
Lembre-se de que você não precisa escolher entre um modelo de aprendizado de máquina supervisionado ou não supervisionado. Você pode usá-los juntos (modelo de aprendizagem semissupervisionado) ou de forma independente.
Benefícios do uso de ML para detecção de fraudes
Já sugerimos os benefícios da detecção de fraudes usando aprendizado de máquina no setor bancário, mas vamos discuti-los mais detalhadamente.
- Velocidade
Os cálculos de aprendizado de máquina acontecem rapidamente e fornecem decisões sobre fraudes em tempo real. Embora os algoritmos baseados em regras também decidam em tempo real, eles dependem de regras escritas para sinalizar fraudes.
O que acontece em novos cenários sem regras pré-definidas? Isso leva a falsos positivos ou falsos negativos.
O aprendizado de máquina detecta novos padrões automaticamente, analisando as atividades regulares dos clientes e calculando os resultados apropriados em milissegundos.
- Precisão
Os sistemas de detecção baseados em regras bloqueiam transações genuínas ou permitem transações fraudulentas porque não detectam nuances no comportamento do cliente.
Os sistemas de aprendizado de máquina consideram variáveis além das regras escritas, por exemplo, comportamento fraudulento conhecido. Essas variáveis ajudam a contextualizar a transação, diminuindo a taxa de falsos positivos.
- Flexibilidade
O aprendizado de máquina é flexível e reativo. A capacidade de autoaprendizagem permite que este sistema se ajuste a novos cenários e detecte novas ameaças. Os sistemas baseados em regras são rígidos e não possuem capacidades de aprendizagem. Portanto, só pode responder a atividades fraudulentas de acordo com regras pré-definidas.
- Eficiência
Algoritmos de aprendizado de máquina podem analisar milhares de dados de transações por segundo. Em vez de gastar mão de obra e despesas gerais investigando casos de fraude de baixa a moderada, o aprendizado de máquina pode processar fraudes repetitivas ou claras. Ele permite que os especialistas em fraudes se concentrem em padrões complexos que necessitam de visão humana.
- Escalabilidade
O aumento do volume de dados pressiona os sistemas baseados em regras. Novas regras aumentam a complexidade do sistema, dificultando a sua manutenção. Qualquer erro ou contradição pode tornar todo o modelo ineficaz.
Os sistemas de aprendizado de máquina são o oposto. Eles não apenas assimilam grandes volumes de novos dados, mas também melhoram.
Técnicas de aprendizado de máquina usadas na detecção de fraudes
Antes de examinarmos os diferentes algoritmos usados na detecção de fraudes por IA, vamos dar uma visão geral de como o sistema funciona.
O primeiro passo é a entrada de dados. A precisão do modelo depende do volume e da qualidade dos dados. Quanto mais dados de alta qualidade você adicionar, mais preciso se tornará o modelo.
Em seguida, o modelo analisa os dados e extrai os principais recursos que descrevem comportamentos normais versus comportamentos fraudulentos. Esses recursos incluem identidade do cliente (e-mail ou número de telefone), localização (IP ou endereço de entrega), métodos de pagamento (nome do titular do cartão e país de origem) e muito mais.
A terceira etapa é treinar o algoritmo (com mais dados) para distinguir entre transações genuínas e fraudulentas. O modelo recebe um conjunto de dados de treinamento e prevê a probabilidade de fraude em diversos casos. Assim que o algoritmo estiver suficientemente treinado, você estará pronto para iniciá-lo.
Agora, vamos dar uma olhada nos vários algoritmos que você pode usar.
1. Regressão logística
A regressão logística é um algoritmo de aprendizagem supervisionada. Calcula a probabilidade de fraude em escala binária – fraude ou não fraude – com base nos parâmetros do modelo.
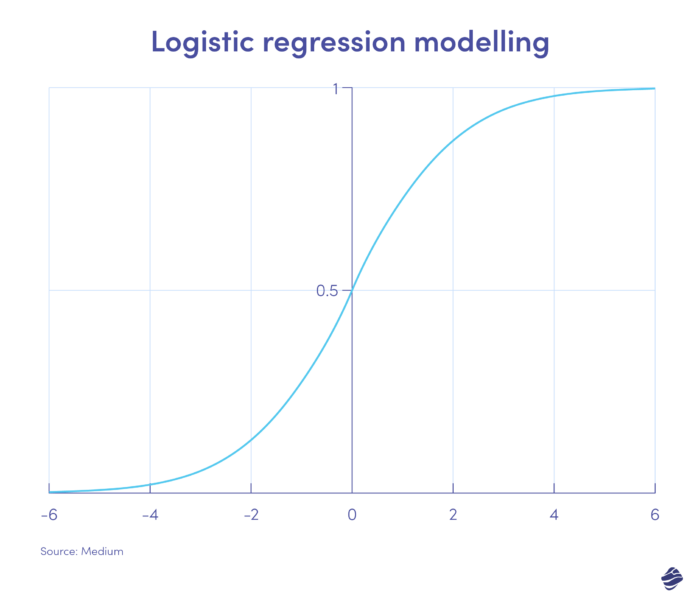
As transações que ficam no lado positivo do gráfico são provavelmente fraudulentas, enquanto as que estão no lado negativo são provavelmente legítimas.
2. Árvore de decisão
Uma árvore de decisão é um algoritmo de aprendizagem supervisionada, mas vai além dos algoritmos de regressão logística. É uma estrutura de decisão hierárquica que analisa os dados em níveis para determinar se uma transação é genuína ou fraudulenta.
Abaixo está uma ilustração de uma árvore de decisão para detecção de fraudes de cartão de crédito.
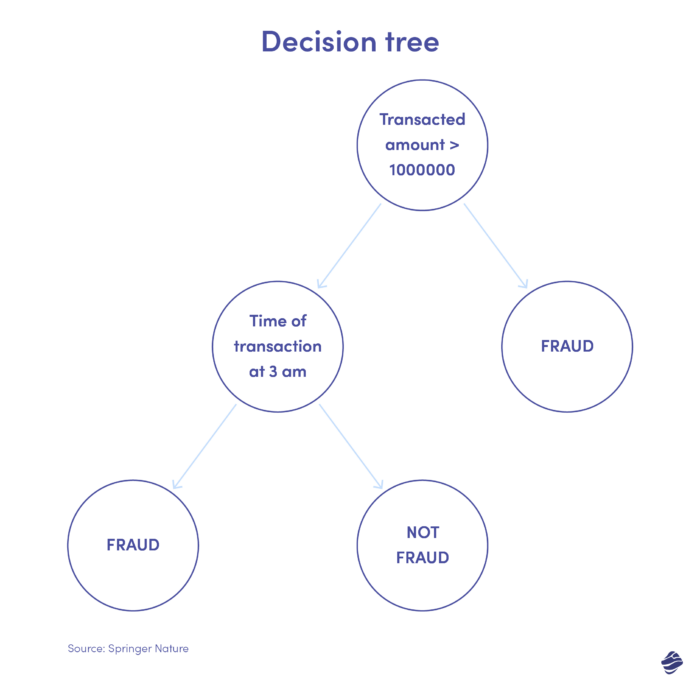
A condição para identificar se a transação é fraudulenta é o valor da transação. Se o valor da transação exceder um limite definido, o algoritmo a considera fraudulenta. Caso contrário, a árvore verifica outra condição – tempo de transação. Se o horário for incomum (aqui, 3 da manhã), é provável que seja uma fraude. Caso contrário, ele verifica outra condição. Isso continua.
3. Floresta Aleatória
A floresta aleatória é uma combinação de muitas árvores de decisão, onde cada árvore de decisão verifica diferentes condições – identidade, localização, etc.
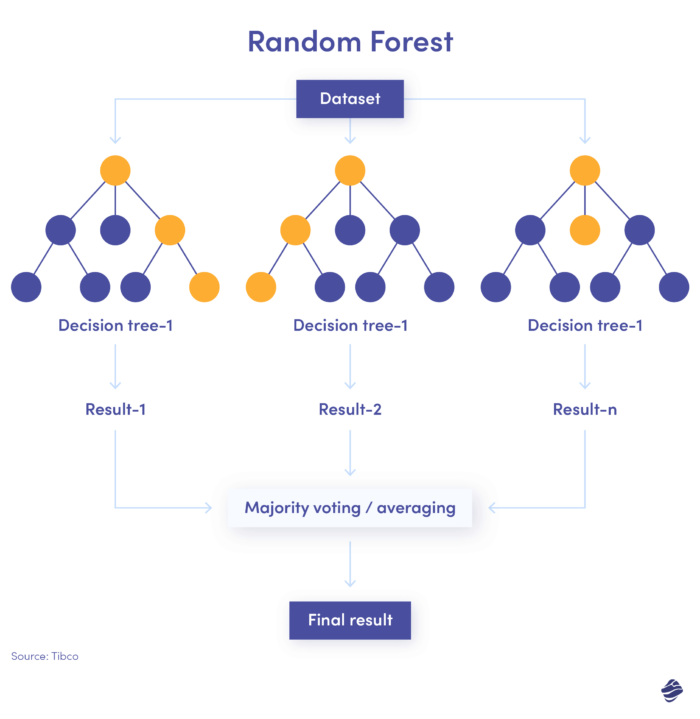
Depois de verificar todos os parâmetros, cada subárvore oferece uma decisão. O total combinado determina se a transação é genuína ou fraudulenta.

4. Redes Neurais
As redes neurais são algoritmos complexos e não supervisionados. Inspiradas no cérebro humano, as redes neurais processam dados em múltiplas camadas para extrair recursos de alto nível. Esse algoritmo anda de mãos dadas com o aprendizado profundo, que pode reconhecer padrões em imagens, texto, áudio e outros dados.
Aqui está uma versão simplificada de uma rede neural.
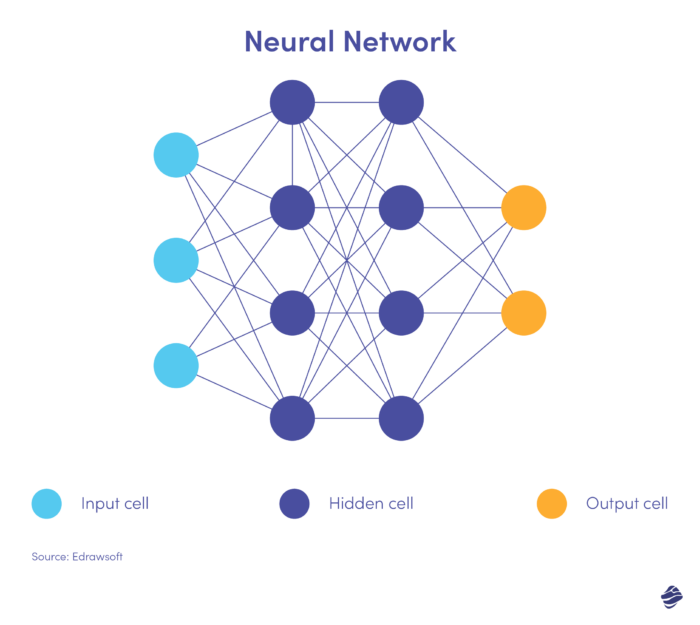
Uma rede neural possui três camadas: entrada, oculta e saída. A camada de entrada processa os dados, a camada oculta analisa os dados da camada de entrada para identificar padrões ocultos e a camada de saída classifica os dados.
As redes neurais profundas possuem várias camadas ocultas. Eles são ótimos para identificar relacionamentos não lineares e detectar cenários de fraude sem precedentes.
5. Máquina de vetores de suporte
Máquinas de vetores de suporte (SVM) são algoritmos de aprendizado supervisionado que prevêem, classificam e detectam valores discrepantes.
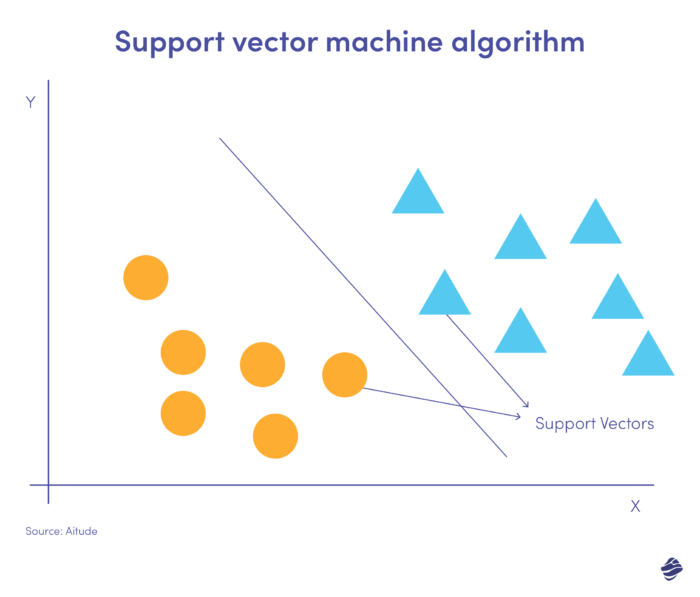
Esta ilustração linear do SVM mostra dois conjuntos de dados separados por uma linha reta chamada hiperplano. É o limite de decisão que classifica os dados como fraudulentos versus não fraudulentos.
Os pontos de dados mais distantes do hiperplano são facilmente classificados. Os vetores de suporte (mais próximos do hiperplano) são difíceis de categorizar. Esses valores discrepantes podem afetar a posição do hiperplano se removidos.
6. K-vizinho mais próximo
K-vizinho mais próximo (KNN) é um algoritmo de aprendizagem supervisionado. Ele opera com base na suposição de que itens semelhantes existem próximos uns dos outros.
Abaixo está uma ilustração simples.
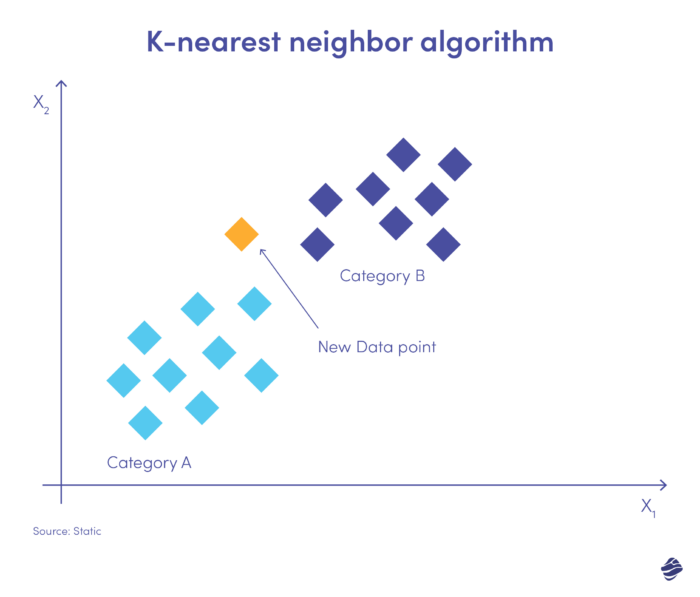
A nova entrada de dados precisa ser colocada na categoria A ou B. O algoritmo calcula a distância entre os pontos de dados usando uma equação matemática chamada distância euclidiana. O novo ponto de dados se enquadra no grupo com maior número de vizinhos. Se o conjunto de dados mais próximo estiver marcado como “fraude”, essa transação será classificada como fraudulenta.
Navegando por desafios e considerações estratégicas
Como toda tecnologia, há dificuldades crescentes associadas à integração do aprendizado de máquina para detecção de fraudes. Aqui estão alguns desafios comuns que você pode enfrentar.
Infraestrutura inadequada
Muitos sistemas bancários não conseguem analisar grandes quantidades de dados complexos. Além disso, a maioria dos dados é isolada e alojada em instalações de armazenamento separadas.
Infelizmente, não há solução rápida para esse problema. Você tem que investir em hardware e software apropriados.
Você precisará fazer parceria com uma agência experiente de desenvolvimento de aplicativos Fintech e configurar uma infraestrutura para selecionar automaticamente algoritmos apropriados para conjuntos de dados específicos, importar dados brutos e prepará-los para aprendizado de máquina, visualizar os dados, testar o algoritmo e muito mais.
Qualidade e segurança dos dados
A qualidade dos dados é uma questão significativa para as instituições financeiras que procuram implementar a aprendizagem automática para deteção de fraudes. Os modelos de aprendizado de máquina não distinguem entre dados bons e ruins. Portanto, se o algoritmo estiver contaminado com dados irrelevantes ou incompletos, a precisão do seu modelo estará incorreta.
Soluções de ingestão de dados como o Amazon Kinesis coletam, limpam e transformam dados brutos, tornando-os adequados para modelos de machine learning. Depois que os dados estiverem limpos e organizados, você deverá separar os dados confidenciais e insensíveis. Criptografe informações confidenciais e armazene-as em instalações seguras. Você também deve limitar o acesso a esses dados.
Falta de talento
Apesar do que as pessoas temem, o aprendizado de máquina não está roubando empregos. É exatamente o oposto. Ainda precisamos de analistas de fraude para gerenciar casos complexos que exigem conhecimento e experiência humanos. Além disso, o aprendizado de máquina é uma tecnologia nova e não há especialistas suficientes na área.
Esta é uma boa notícia para quem procura emprego, mas não para instituições que não conseguem capitalizar todo o potencial da aprendizagem automática. Você pode superar esse obstáculo fazendo parceria com empresas com as habilidades necessárias para implementar o aprendizado de máquina.
Estudos de caso de detecção de fraude em bancos usando aprendizado de máquina
Agora, vejamos exemplos reais de detecção de fraudes no setor bancário usando aprendizado de máquina.
Detecção de fraude
O Danske Bank é uma empresa financeira multinacional dinamarquesa. É o maior banco da Dinamarca e um banco de retalho líder no Norte da Europa. Sob o sistema de detecção baseado em regras, o banco lutou para mitigar a fraude. Teve uma taxa de detecção de fraude de 40% e uma taxa de falsos positivos de 99,5%.
Trabalhando com a Teradata, uma empresa de software de dados, Danske integrou software de aprendizagem profunda para ajudar a identificar possíveis atividades fraudulentas. O resultado foi uma redução de 60% nos falsos positivos e um aumento de 50% nos verdadeiros positivos.
Contra lavagem de dinheiro
OakNorth é um banco de empréstimos comerciais no Reino Unido que fornece serviços financeiros comerciais e pessoais para empresas em expansão. O banco tinha um processo de triagem fragmentado, com um fornecedor para cheques contra lavagem de dinheiro e outro para clientes. Além disso, os rastreios de pessoas politicamente expostas (PEP) geraram muitos falsos positivos.
Trabalhando com a ComplyAdvantage, uma empresa de detecção de fraudes e AML, o banco integrou uma solução de triagem e monitoramento contínuo para agilizar a conformidade e consolidar dados. Isto facilitou a rápida transferência de dados entre as operações de empréstimo e poupança do banco.
Subscrição de crédito
A Hawaii USA Credit Union é a maior cooperativa de crédito do Havaí e uma das melhores cooperativas de crédito da revista Forbes. Queria ser competitiva em relação às empresas Fintech e aumentar a sua carteira de empréstimos pessoais sem aumentar o risco.
Trabalhando com a Zest AI, a cooperativa de crédito automatizou seus processos de tomada de decisão usando um modelo de empréstimo pessoal baseado em IA. O modelo utilizou 278 variáveis para fornecer insights mais profundos do que o sistema de pontuação de crédito VantageScore. O resultado foi um aumento de 21% na taxa de aprovação e uma taxa de fraude de inadimplência/pedido de empréstimo de 0%.
Principais considerações ao usar ML para detecção de fraudes
Embora a detecção de fraudes no setor bancário usando aprendizado de máquina seja eficiente, também é assustadora. Esses sistemas exigem muitos dados precisos ou os modelos não funcionam tão bem quanto deveriam.
Então, aqui estão algumas dicas para otimizar o processo de aprendizado de máquina.
1. Limite o número de variáveis de entrada
Ao longo deste artigo, dissemos que mais é mais. Isso permanece verdadeiro em relação ao volume de dados. No entanto, menos é mais com o número de variáveis de detecção de fraude.
Os recursos típicos a serem considerados ao investigar fraudes incluem:
- endereço de IP
- Endereço de email
- Endereço para envio
- Valor médio do pedido/transação
A vantagem de menos recursos são tempos de treinamento de algoritmo mais curtos. Você também evita problemas de conjuntos de dados sobrepostos ou irrelevantes.
2. Garanta a conformidade regulatória
Prevenir fraudes é uma parte da segurança dos dados. A outra é a privacidade dos dados. Muitos países têm leis sobre como as instituições podem coletar, usar e armazenar dados de clientes. Existe a Lei de Proteção de Informações Pessoais (PIPL) da China, a Lei de Privacidade do Consumidor da Califórnia (CCPA) e o Regulamento Geral de Proteção de Dados (GDPR) da União Europeia, para citar alguns.
Essas leis têm implicações para os dados usados no aprendizado de máquina. O princípio principal da maioria das regulamentações de conformidade de privacidade de dados é aviso/consentimento. Você deve notificar e receber permissão para usar os dados do cliente para outros fins que não as solicitações do usuário, incluindo dados para treinamento de algoritmos de aprendizado de máquina.
A maneira mais simples de garantir a adesão aos padrões de privacidade é utilizar parceiros técnicos com recursos em conformidade com as regulamentações. Por exemplo, você deve fazer parceria com uma empresa de desenvolvimento de aplicativos bancários que saiba como manter a privacidade e segurança dos dados.
3. Defina um limite razoável
As regras de valor de transação têm requisitos mínimos para acionar uma resposta de aceitação ou rejeição. Você deseja um limite que equilibre a segurança e a experiência do usuário. Se o limite for muito rigoroso, você corre o risco de bloquear transações legítimas. Se o limite for muito baixo, você aumentará a taxa de fraudes bem-sucedidas.
Calcule seu apetite ao risco para encontrar o equilíbrio certo. Os níveis de risco diferem para cada instituição ou produto financeiro. Por exemplo, uma oferta bancária de microcrédito pode estabelecer um limite elevado para empréstimos de baixo valor. Um banco comercial não pode ser tão generoso com empréstimos hipotecários.
Antecipando o futuro
O futuro é agora, mas apenas 17% das organizações utilizam machine learning em programas antifraude. Não fique para trás.
Aqui estão alguns avanços que você pode esperar na segurança do seu banco por meio do aprendizado de máquina.
- Perfil de dispositivos : identifique os diferentes dispositivos que se conectam à sua rede bancária, analisando os recursos e comportamentos de qualquer dispositivo.
- Detecção e resposta automatizadas a anomalias : identifique comportamento fraudulento de dispositivos conhecidos e isole os sistemas afetados.
- Detecção de dia zero : identifique vulnerabilidades e malware anteriormente desconhecidos para proteger as organizações contra ataques cibernéticos.
- Mascaramento de dados : detecta e anonimiza automaticamente dados confidenciais.
- Insights escalonados : identifique tendências de fraude em vários dispositivos e locais.
- Política inovadora : use insights de aprendizado de máquina para impulsionar políticas de segurança relevantes.
Quer você seja uma instituição de gestão de patrimônio ou uma cooperativa de crédito, a IA e o aprendizado de máquina oferecem enormes oportunidades para detecção de fraudes.
No entanto, é fundamental lembrar que os hackers também utilizam estas tecnologias para contornar medidas de proteção. Atualize seus modelos de aprendizado de máquina para ficar à frente desses ataques. Você também pode fortalecer sua segurança baseada em IA com a boa e velha inteligência humana.