
Como prever receita de tráfego orgânico sem marca com base na posição do URL com Python
Publicados: 2022-05-24O que é previsão de SEO?
A previsão de SEO, ou estimativa de tráfego orgânico, é o processo de usar os dados do seu próprio site ou dados de terceiros para estimar o tráfego orgânico futuro do seu site, a receita de SEO e o ROI de SEO. Essa estimativa pode ser calculada usando muitos métodos diferentes com base em nossos dados.
Neste tutorial, queremos prever nossa receita orgânica sem marca e tráfego orgânico sem marca com base em nossas posições de URLs e sua receita atual. Isso pode nos ajudar, como SEOs, a obter mais adesão de outras partes interessadas: desde o aumento do orçamento mensal, trimestral ou anual até mais horas de trabalho do produto e da equipe de desenvolvimento.
Lembre-se de que este tutorial não se aplica apenas ao tráfego orgânico sem marca; fazendo algumas alterações e conhecendo o Python, você pode usá-lo para estimar o tráfego de suas páginas de destino.
Como resultado, podemos produzir uma Planilha Google como a imagem abaixo.
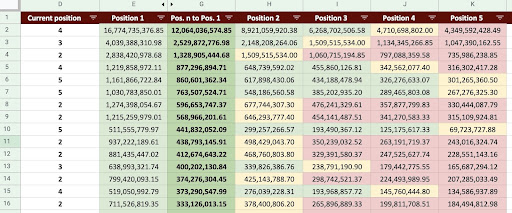
Imagem do Planilhas Google
Previsão de tráfego de SEO sem marca
A primeira pergunta que você pode fazer depois de ler a introdução é: “Por que calcular o tráfego orgânico sem marca?”.
Vamos considerar uma empresa como a Amazon. Quando você quiser comprar um livro ou uma máscara, basta pesquisar “comprar máscara amazon”.
As marcas costumam ser as mais lembradas e, quando você quer comprar algo, sua preferência é comprar o que precisa dessas empresas. Em cada setor, existem empresas de marca que afetam o comportamento dos usuários nas pesquisas do Google.
Se fôssemos verificar os dados do Google Search Console (GSC) da Amazon, provavelmente descobriríamos que ele recebe muito tráfego de consultas de marca e, na maioria das vezes, o primeiro resultado de consultas de marca é o site dessa marca.
Como um SEO, como eu, você provavelmente já ouviu muitas vezes que “Somente nossa marca ajuda nosso SEO!” Como podemos dizer “Não, não é esse o caso” e mostrar o tráfego e a receita de consultas sem marca?
É ainda mais complicado provar isso porque sabemos que os algoritmos do Google são muito complexos e é difícil separar distintamente as pesquisas com marca das sem marca. Mas é isso que torna o que fazemos como SEO ainda mais importante.
Neste tutorial, mostrarei como distinguir entre os dois – com marca e sem marca – e mostrar o quão poderoso o SEO pode ser.
Mesmo que sua empresa não tenha uma marca, você ainda pode ganhar muito com este artigo: você pode aprender a estimar os dados orgânicos do seu site.
SEO ROI com base na estimativa de tráfego
Não importa onde você esteja ou o que faça, há uma limitação de recursos; seja um orçamento ou simplesmente o número de horas na jornada de trabalho. Saber a melhor forma de alocar seus recursos desempenha um papel importante no retorno do investimento (ROI) geral e de SEO.
Um CMO, um vice-presidente de marketing ou um profissional de marketing de desempenho têm KPIs diferentes e exigem recursos diferentes para atingir seus objetivos. A melhor maneira de garantir que você obtenha o que precisa é provar sua necessidade, demonstrando os retornos que trará para a empresa. SEO ROI não é diferente. Quando chega a época de alocação de orçamento do ano e sua equipe deseja solicitar um orçamento maior, estimar seu ROI de SEO pode lhe dar vantagem na negociação. Depois de calcular a estimativa de tráfego sem marca, você pode avaliar melhor o orçamento necessário para alcançar os resultados desejados.
O efeito da previsão de SEO na estratégia de SEO
Como sabemos, a cada 3 ou 6 meses revisamos nossa estratégia de SEO e a ajustamos para obter os melhores resultados possíveis. Mas o que acontece quando você não sabe onde está o maior lucro para sua empresa? Você pode tomar decisões, mas elas não serão tão eficazes quanto as decisões tomadas quando você tiver uma visão mais abrangente do tráfego do site.
A estimativa de receita de tráfego orgânico sem marca pode ser combinada com suas páginas de destino e segmentação de consultas para fornecer uma visão geral que o ajudará a desenvolver melhores estratégias como gerente de SEO ou estrategista de SEO.
As diferentes maneiras de prever o tráfego orgânico
Existem muitos métodos diferentes e scripts públicos na comunidade de SEO para prever o tráfego orgânico futuro.
Alguns desses métodos incluem:
- Previsão de tráfego orgânico em todo o site
- Previsão de tráfego orgânico nas páginas específicas (blog, produtos, categorias, etc) ou uma única página
- Previsão de tráfego orgânico nas consultas específicas (consultas contêm "comprar", "como fazer", etc.) ou uma consulta
- Previsão de tráfego orgânico para períodos específicos (especialmente para eventos sazonais)
Meu método é para páginas específicas e o prazo é de um mês.
[Estudo de caso] Impulsionando o crescimento em novos mercados com SEO na página
 Leia o estudo de caso
Leia o estudo de casoComo calcular a receita de tráfego orgânico
A maneira precisa é baseada em seus dados do Google Analytics (GA). Se o seu site for novo, você terá que usar ferramentas de terceiros. Prefiro evitar usar essas ferramentas quando você tem seus próprios dados.
Lembre-se de que você precisará testar os dados de terceiros que está usando em relação a alguns dos dados da sua página real para encontrar possíveis erros nos dados deles.
Como calcular a receita de tráfego de SEO sem marca com Python
Até agora, cobrimos muitos conceitos teóricos com os quais devemos estar familiarizados para entender melhor os diferentes aspectos de nosso tráfego orgânico e previsão de receita. Agora, vamos mergulhar na parte prática deste artigo.
Primeiro, vamos começar calculando nossa curva CTR. No meu artigo de curva de CTR no Oncrawl, explico dois métodos diferentes e também outros métodos que você pode usar fazendo algumas alterações no meu código. Eu recomendo que você leia primeiro o artigo da curva de cliques; ele fornece informações sobre este artigo.
Neste artigo, eu ajusto algumas partes do meu código para obter os resultados específicos que queremos na estimativa de tráfego. Em seguida, obteremos nossos dados do GA e usaremos a dimensão de receita do GA para estimar nossa receita.
Previsão da receita de tráfego orgânico sem marca com Python: Primeiros passos
Você pode executar esse código sozinho, sem conhecer nenhum Python. No entanto, prefiro que você saiba um pouco sobre a sintaxe do Python e conhecimento básico sobre as bibliotecas do Python que usarei neste código de previsão. Isso ajudará você a entender melhor meu código e personalizá-lo de uma maneira que seja útil para você.
Para executar este código, usarei o Visual Studio Code com a extensão Python da Microsoft, que inclui a extensão “Jupyter”. Mas você pode usar o próprio notebook Jupyter.
Para todo o processo, precisamos usar essas bibliotecas Python:
- Numpy
- Pandas
- Tradicionalmente
Além disso, importaremos algumas bibliotecas padrão do Python:
- JSON
- pprint
# Importando as bibliotecas que precisamos para o nosso processo importar json de pprint importar pprint importar numpy como np importar pandas como pd importar plotly.express como px
Etapa 1: calcular a curva de CTR relativa (curva de clique relativa)
Na primeira etapa, queremos calcular nossa curva de CTR relativa. Mas, qual é a curva CTR relativa?
Qual é a curva CTR relativa?
Vamos começar falando sobre a 'curva CTR absoluta'. Quando calculamos a curva de CTR absoluta, dizemos que a CTR mediana (ou CTR média) da primeira posição é de 36% e da segunda posição é de 20%, e assim por diante.
Na curva de CTR relativa, instante de porcentagem, dividimos a mediana de cada posição pela CTR da primeira posição. Por exemplo, a curva de CTR relativa da primeira posição seria 0,36 / 0,36 = 1, a segunda seria 0,20 / 0,36 = 0,55 e assim por diante.
Talvez você esteja se perguntando por que é útil calcular isso? Pense em uma página classificada na primeira posição, que tenha 44% de CTR. Se esta página for para a posição dois, a curva CTR não diminui para 20%, é mais provável que a CTR diminua para 44% * 0,55 = 24,2%.
1. Obtendo dados de tráfego orgânico de marca e sem marca do GSC
Para nosso processo de cálculo, precisamos obter nossos dados do GSC. Na primeira vez, todos os dados serão baseados em consultas de marca e, na próxima vez, todos os dados serão baseados em consultas sem marca.
Para obter esses dados, você pode usar métodos diferentes: de scripts Python ou do complemento “Search Analytics for Sheets” do Planilhas Google. Vou usar o explorador de API GSC.
A saída desses dados são dois arquivos JSON que mostram o desempenho de cada página. Um arquivo JSON que mostra o desempenho das páginas de destino com base nas consultas de marca e o outro mostra o desempenho das páginas de destino com base nas consultas sem marca.
Para obter dados do GSC API explorer, siga estas etapas:
- Acesse https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Maximize o explorador de API que está no canto superior direito da página.
- No campo “
siteUrl”, insira seu nome de domínio. Por exemplo “https://www.example.com” ou “ http:http://your-domain.com”. - No corpo da requisição, primeiro precisamos definir os parâmetros “
startDate” e “endDate”. Minha preferência são os últimos 30 dias. - Em seguida, adicionamos “
dimensions” e selecionamos “page” para esta lista. - Agora adicionamos “
dimensionFilterGroups” para filtrar nossas consultas. Uma vez para as consultas de marca e uma segunda para consultas sem marca. - No final, definimos nosso “
rowLimit” para 25.000. Se as páginas do seu site que recebem tráfego orgânico todo mês são mais de 25K, você deve modificar o corpo da sua solicitação. - Depois de fazer cada solicitação, salve a resposta JSON. Para desempenho com marca, salve o arquivo JSON como “
branded_data.json” e para desempenho sem marca, salve o arquivo JSON como “non_branded_data.json”.
Depois de entendermos os parâmetros em nosso corpo de solicitação, a única coisa que você precisa fazer é copiar e colar abaixo dos corpos de solicitação. Considere substituir seus nomes de marca por “ brand variation names ”.
Você deve separar os nomes das marcas com um pipeline ou “ | ”. Por exemplo, “ amazon|amazon.com|amazn ”.
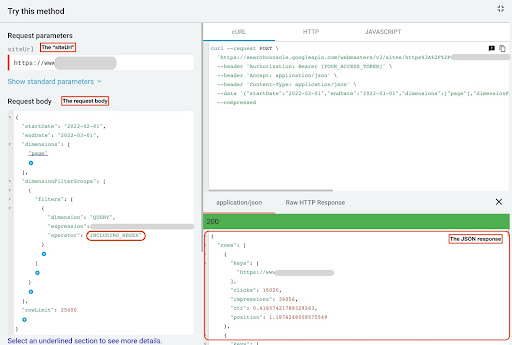
Explorador de API GSC
Corpo da solicitação com marca:
{
"data de início": "2022-02-01",
"endDate": "2022-03-01",
"dimensões": [
"página"
],
"dimensionFilterGroups": [
{
"filtros": [
{
"dimensão": "QUERY",
"expression": "nomes de variação de marca",
"operador": "INCLUDING_REGEX"
}
]
}
],
"linhaLimite": 25000
}
Corpo da solicitação sem marca:
{
"data de início": "2022-02-01",
"endDate": "2022-03-01",
"dimensões": [
"página"
],
"dimensionFilterGroups": [
{
"filtros": [
{
"dimensão": "QUERY",
"expression": "nomes de variação de marca",
"operador": "EXCLUDING_REGEX"
}
]
}
],
"linhaLimite": 25000
}
2. Importando os dados para nosso notebook Jupyter e extraindo diretórios de sites
Agora, precisamos carregar nossos dados em nosso notebook Jupyter para poder modificá-lo e extrair o que queremos dele. Vamos continuar de onde paramos acima.
Para carregar dados de marca, você precisa executar este bloco de código:
# Criando um DataFrame para o desempenho de URLs do site na marca e consultas de marca
com open("./branded_data.json") como json_file:
branded_data = json.loads(json_file.read())["rows"]
branded_df = pd.DataFrame(branded_data)
# Renomeando a coluna 'chaves' para a coluna 'página de destino' e convertendo a lista de 'página de destino' em um URL
branded_df.rename(columns={"keys": "landing page"}, inplace=True)
branded_df["landing page"] = branded_df["landing page"].apply(lambda x: x[0])
Para desempenho sem marca de páginas de destino, você precisará executar este bloco de código:
# Criando um DataFrame para o desempenho dos URLs do site nas consultas sem marca
com open("./non_branded_data.json") como json_file:
non_branded_data = json.loads(json_file.read())["rows"]
non_branded_df = pd.DataFrame(non_branded_data)
# Renomeando a coluna 'chaves' para a coluna 'página de destino' e convertendo a lista de 'página de destino' em um URL
non_branded_df.rename(columns={"keys": "landing page"}, inplace=True)
non_branded_df["landing page"] = non_branded_df["landing page"].apply(lambda x: x[0])
Carregamos nossos dados, então precisamos definir o nome do nosso site para extrair seus diretórios.
# Definindo o nome do seu site entre aspas. Por exemplo, 'https://www.example.com/' ou 'http://mydomain.com/' SITE_NAME = "https://www.seu_dominio.com/"
Só precisamos extrair os diretórios do desempenho sem marca.
# Obtendo cada diretório de página de destino (URL)
non_branded_df["directory"] = non_branded_df["landing page"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Em seguida, imprimimos os diretórios para selecionar quais são importantes para esse processo. Você pode selecionar todos os diretórios para obter uma visão melhor do seu site.

# Para obter todos os diretórios na saída, precisamos manipular as opções do Pandas
pd.set_option("display.max_rows", Nenhum)
# Diretórios de sites
non_branded_df["diretório"].value_counts()
Aqui, você pode inserir os diretórios que são importantes para você.
""" Escolha quais diretórios são importantes para obter sua curva de CTR.
Insira os diretórios na variável 'important_directories'.
Por exemplo, 'produto, etiqueta, categoria de produto, revista'. Separe os valores do diretório com vírgula.
"""
IMPORTANT_DIRECTORIES = "seu_diretórios_importantes"
IMPORTANTE_DIRETÓRIOS = IMPORTANTE_DIRETÓRIO.split(",")
3. Rotular as páginas com base em sua posição e calcular a curva de CTR relativa
Agora precisamos rotular nossas páginas de destino com base em sua posição. Fazemos isso porque precisamos calcular a curva de CTR relativa de cada diretório com base na posição de sua página de destino.
# Rotulando posições sem marca
para i no intervalo (1, 11):
non_branded_df.loc[
(non_branded_df["position"] >= i) & (non_branded_df["position"] < i + 1),
"etiqueta de posição",
] = eu
Em seguida, agrupamos as páginas de destino com base em seu diretório.
# Agrupando páginas de destino com base em seu valor de 'diretório' non_brand_grouped_df = non_branded_df.groupby(["diretório"])
Vamos definir a função para calcular a curva CTR relativa.
def each_dir_relative_ctr_curve(dir_df, chave):
"""A função calcula cada curva de CTR relativa IMPORTANT_DIRECTORIES.
"""
# Agrupando "non_brand_grouped_df" com base no valor de seu 'rótulo de posição'
dir_grouped_df = dir_df.groupby(["rótulo de posição"])
# Uma lista para salvar a CTR mediana de cada posição
median_ctr_list = []
# Armazenando cada diretório como uma chave, e é "median_ctr_list" como valor
directories_median_ctr = {}
# Loop sobre cada grupo "dir_grouped_df"
para i no intervalo (1, 11):
# Um try-except para lidar com as situações em que um diretório, por exemplo, não possui dados para a posição 4
tentar:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"])))
exceto:
median_ctr_list.append(0)
# Calculando a curva CTR relativa
directories_median_ctr[key] = np.array(median_ctr_list) / np.array(
[median_ctr_list[0]] * 10
)
retornar diretórios_median_ctr
Depois de definir a função, nós a executamos.
# Loop sobre diretórios e executando a função 'each_dir_relative_ctr_curve'
directories_median_ctr_dict = dict()
para chave, item em non_brand_grouped_df:
se digitar IMPORTANT_DIRECTORIES:
directories_median_ctr_dict.update(each_dir_relative_ctr_curve(item, chave))
pprint(directory_median_ctr_dict)
Agora, carregaremos o desempenho de nossas páginas de destino, com e sem marca, e calcularemos a curva de CTR relativa para nossos dados sem marca. Por que fazemos isso apenas para dados que não são de marca? Porque queremos prever o tráfego orgânico sem marca e a receita.
Etapa 2: prever a receita de tráfego orgânico sem marca
Nesta segunda etapa, veremos como recuperar nossos dados de receita e prever nossa receita.
1. Mesclando dados orgânicos de marca e sem marca
Agora, mesclaremos nossos dados com e sem marca. Isso nos ajudará a calcular a porcentagem de tráfego orgânico sem marca em cada página de destino em comparação com todo o tráfego.
# 'main_df' é uma combinação de 'dados do site inteiro' e 'dados não relacionados à marca' DataFrames.
# Usando este DataFrame, você pode descobrir onde a maioria dos nossos cliques e impressões
# vem de consultas sem marca.
main_df = non_branded_df.merge(
branded_df, on="landing page", suffixes="_non_brand", "_branded")
)
Em seguida, modificamos as colunas para remover as inúteis.
# Modificando as colunas 'main_df' para aquelas que precisamos
main_df = main_df[
[
"página de destino",
"clicks_non_brand",
"ctr_non_brand",
"diretório",
"etiqueta de posição",
"clicks_branded",
]
]
Agora, vamos calcular a porcentagem de cliques sem marca em relação ao total de cliques de uma página de destino.
# Calculando a porcentagem de cliques de consultas sem marca com base nas páginas de destino para todos os cliques da página de destino
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_branded"]),
eixo=1,
)
[Ebook] Automatizando SEO com Oncrawl
 Leia o e-book
Leia o e-book2. Carregando a receita do tráfego orgânico
Assim como para recuperar os dados do GSC, temos várias maneiras de obter os dados do GA: podemos usar o "complemento do Planilhas do Google Analytics" ou a API do GA. Neste tutorial, prefiro usar o Google Data Studio (GDS) devido à sua simplicidade.
Para obter os dados do GA do GDS, siga estas etapas:
- No GDS, crie um novo relatório ou explorador e uma tabela.
- Para a dimensão adicionar “landing page” e para a métrica, devemos adicionar “Revenue”.
- Em seguida, você precisará criar um segmento personalizado no GA com base na origem e na mídia. Filtre o tráfego “Google/orgânico”. Após a criação do segmento, adicione-o à seção do segmento no GDS.
- Na etapa final, exporte a tabela e salve-a como “
landing_pages_revenue.csv”.
Exportação de csv de receita de páginas de destino
Vamos carregar nossos dados.
organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
Agora, precisamos anexar o nome do nosso site aos URLs das páginas de destino do GA.
Quando exportamos nossos dados do GA, as páginas de destino estão no formato relativo, mas nossos dados do GSC estão no formato absoluto.
Não se esqueça de verificar os dados das suas páginas de destino do GA. Nos conjuntos de dados com os quais trabalhei, descobri que os dados do GA precisam de uma pequena limpeza a cada vez.
# Concatenar URLs de páginas de destino do GA com SITE_NAME.
# Além disso, renomeando as colunas
organic_revenue_df.loc[:, "Página de destino"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
organic_revenue_df.rename(columns={"Página de destino": "página de destino", "Receita": "receita"}, inplace=True)
Agora, vamos mesclar nossos dados GSC com dados GA.
# Nesta etapa, eu mesclo 'main_df' com 'dk_organic_revenue_df' DataFrame que contém a porcentagem de dados de consultas sem marca main_df = main_df.merge(organic_revenue_df, on="landing page", how="left")
No final desta seção, fazemos uma pequena limpeza em nossas colunas DataFrame.
# Um pouco de limpeza do DataFrame 'main_df'
main_df = main_df[
[
"página de destino",
"clicks_non_brand",
"ctr_non_brand",
"diretório",
"etiqueta de posição",
"clicks_non_brand_percentage",
"receita",
]
]
3. Calculando a receita sem marca
Nesta seção, processaremos os dados para extrair as informações que procuramos.
Mas antes de mais nada, vamos filtrar nossas landing pages com base em “ IMPORTANT_DIRECTORIES ”:
# Removendo outras páginas de destino de diretórios, não incluídas em "IMPORTANT_DIRECTORIES"
main_df = (
main_df[main_df["diretório"].isin(IMPORTANT_DIRECTORIES)]
.dropna(subset=["receita"])
.reset_index(drop=True)
)
Agora, vamos calcular o tráfego de receita orgânica sem marca.
Defini uma métrica que não podemos calcular facilmente e é mais intuição do que qualquer outra coisa que nos leva a atribuir um número a ela.
A métrica “ brand_influence ” mostra a força da sua marca. Se você acredita que pesquisas não relacionadas a marcas geram menos vendas para sua empresa, diminua esse número; algo como 0,8 por exemplo.
# Se sua marca é tão forte que consultar sem sua marca pode vender tanto quanto consultar com sua marca, então 1 é bom para você.
# Pense em procurar um livro sem um nome de marca incluído em sua consulta. Quando você vê a Amazon, você compra em outros marketplaces ou lojas?
brand_influence = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["receita"] * x["clicks_non_brand_percentage"] * brand_influence, axis=1
)
Vamos traçar um gráfico de pizza para obter algumas informações sobre a receita sem marca com base nos diretórios importantes.
# Nesta célula, quero obter toda a receita de páginas de destino sem marca com base em seu diretório
non_branded_directory_dist_revenue_df = pd.pivot_table(
main_df,
index="diretório",
valores=["non_brand_revenue"],
aggfunc={"non_brand_revenue": "soma"},
)
pie_fig = px.pie(
non_branded_directory_dist_revenue_df,
valores="non_brand_revenue",
nomes=non_branded_directory_dist_revenue_df.index,
title="Receita sem marca baseada em diretórios de sites",
)
pie_fig.update_traces(textposition="dentro", textinfo="percent+label")
pie_fig.show()
Este gráfico mostra a distribuição de consultas sem marca em seu IMPORTANT_DIRECTORIES .
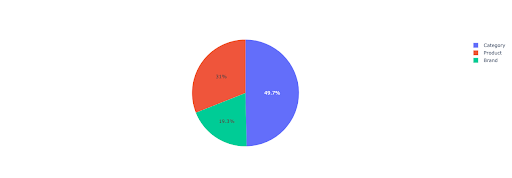
Distribuição de consultas sem marca
Com base nos dados da minha curva de CTR, vejo que não posso confiar na CTR para posições superiores a 5. Por isso, filtro meus dados com base na posição.
Você pode modificar o bloco de código abaixo com base em seus dados.
# Devido à precisão da CTR em nossa curva de CTR, acho que podemos pular os destinos com posição superior a 5. Por isso, filtrei outras páginas de destino main_df = main_df[main_df["position label"] < 6].reset_index(drop=True)
4. Calculando “Receita por clique” (RPC)
Aqui, criei uma métrica personalizada e a chamei de “Receita por clique” ou RPC. Isso nos mostra a receita gerada por cada clique sem marca.
Você pode usar essa métrica de diferentes maneiras. Encontrei uma página com alto RPC, mas poucos cliques. Quando verifiquei a página, descobri que ela foi indexada há menos de uma semana e podemos usar métodos diferentes para otimizar a página.
# Calculando a receita gerada a cada clique (RPC: Receita por clique)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], axis=1
)
5. Previsão da receita!
Estamos chegando ao fim, esperamos até agora para prever nossa receita orgânica sem marca.
Vamos executar os últimos blocos de código.
# A principal função para calcular a receita com base em diferentes posições
para índice, row_values em main_df.iterrows():
# Alternar entre a lista CTR de diretórios
ctr_curve = directories_median_ctr_dict[row_values["diretório"]]
# Faça um loop sobre a posição 1 a 5 e calcule a receita com base no aumento ou diminuição da CTR
para i no intervalo (1, 6):
if i == row_values["position label"]:
main_df.loc[index, i] = row_values["non_brand_revenue"]
senão:
# main_df.loc[índice, i + 1] ==
main_df.loc[index, i] = (
row_values["non_brand_revenue"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["position label"] - 1)]
)
# Calculando a métrica "N para 1". Isso mostra o aumento da receita quando sua classificação passa de "N" para "1"
main_df.loc[index, "N para 1"] = main_df.loc[index, 1] - main_df.loc[index, row_values["position label"]]
Olhando para a saída final, temos novas colunas. Os nomes dessas colunas são “1”, “2”, “3”, “4”, “5”.
O que esses nomes significam? Por exemplo, temos uma página na posição 3 e queremos prever sua receita se ela melhorar sua posição, ou queremos saber quanto perderemos se cairmos na classificação.
As colunas “1” e “2” mostram a receita da página quando a posição média desta página melhora e as colunas “4” e “5” mostram a receita desta página quando caímos no ranking.
A coluna “3” neste exemplo mostra a receita atual da página.
Além disso, criei uma métrica chamada “N para 1”. Isso mostra se a posição média desta página muda de “3” (ou N) para “1” e quanto a mudança pode afetar a receita.
Empacotando
Cobri muito neste artigo e agora é sua vez de sujar as mãos e prever sua receita de tráfego orgânico sem marca.
Essa é a maneira mais simples de usar essa previsão. Poderíamos tornar esse algoritmo mais complexo e combiná-lo com alguns modelos de ML, mas isso tornaria o artigo mais complicado.
Prefiro salvar esses dados em um CSV e enviá-los para uma planilha do Google. Ou, se eu planejo compartilhá-lo com os outros membros da minha equipe ou da organização, vou abri-lo com o Excel e formatar as colunas usando cores para facilitar a leitura.
Com base nesses dados, você pode prever seu ROI de tráfego orgânico sem marca e usá-lo em seu processo de negociação.