
Atualizações do Google Core: efeitos, problemas e soluções para sites YMYL
Publicados: 2019-12-04Neste estudo de caso, examinarei o Hangikredi.com, que é um dos maiores ativos financeiros e digitais da Turquia. Veremos subtítulos técnicos de SEO e alguns gráficos.
Este estudo de caso é apresentado em dois artigos. Este artigo trata da atualização do Google Core de 12 de março, que teve um forte efeito negativo no site, e o que fizemos para combatê-la. Analisaremos 13 problemas e soluções técnicas, bem como questões holísticas.
Leia a segunda parte para ver como apliquei o aprendizado desta atualização para me tornar um vencedor de todas as atualizações do Google Core.
Problemas e soluções: corrigindo os efeitos da atualização do Google Core de 12 de março
Até a atualização do algoritmo principal de 12 de março, tudo corria bem para o site, com base nos dados analíticos. Em um dia, depois que as notícias foram divulgadas sobre a atualização do algoritmo principal, houve uma grande queda nos rankings e uma grande frustração no escritório. Eu pessoalmente não vi esse dia porque só cheguei quando me contrataram para iniciar um novo Projeto e Processo de SEO 14 dias depois.
[Estudo de caso] Melhorando rankings, visitas orgânicas e vendas com análise de arquivos de log
 Leia o estudo de caso
Leia o estudo de casoO relatório de danos para o site da empresa após a atualização do algoritmo principal de 12 de março está abaixo:
- 36% de perda de sessão orgânica
- 65% de queda de cliques
- Perda de CTR de 30%
- 33% de perda orgânica de usuários
- 100.000 impressões perdidas por dia.
- 9,72% de perda de impressões
- 8.000 palavras-chave perdidas

Agora, como afirmamos no início do artigo do estudo de caso, devemos fazer uma pergunta. Não poderíamos perguntar “Quando a próxima atualização do algoritmo principal acontecerá?” porque já aconteceu. Restou apenas uma pergunta.
“Quais critérios diferentes o Google considerou entre mim e meu concorrente?”
Como você pode ver no gráfico acima e no relatório de danos, perdemos nosso tráfego principal e palavras-chave.
1. Problema: Vinculação Interna
Percebi que quando verifiquei pela primeira vez a contagem de links internos, o texto âncora e o fluxo de links, meu concorrente estava à minha frente.
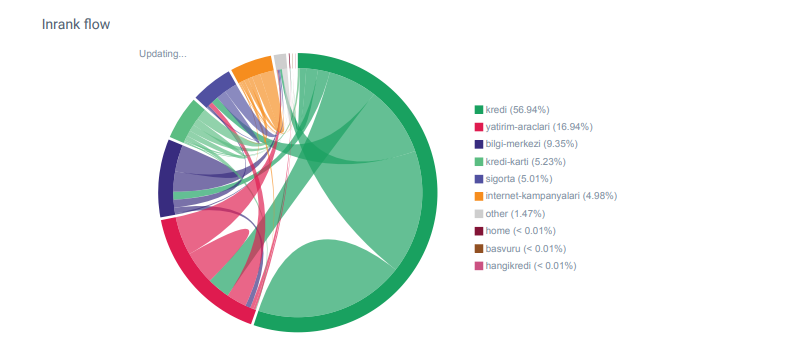
Relatório do Linkflow para as categorias do Hangikredi.com do OnCrawl
Meu principal concorrente tem mais de 340.000 links internos com milhares de textos âncora. Nestes dias, nosso site tinha apenas 70.000 links internos sem valiosos textos âncora. Além disso, a falta de links internos afetou o orçamento de rastreamento e a produtividade do site. Embora 80% do nosso tráfego tenha sido coletado em apenas 20 páginas de produtos, 90% do nosso site consistia em páginas de guia com informações úteis para os usuários. E a maioria de nossas palavras-chave e pontuação de relevância para consultas financeiras vem dessas páginas. Além disso, havia incontáveis páginas órfãs.
Por causa da falta de estrutura de links internos, quando fiz Log Analysis com o Kibana, notei que as páginas mais rastreadas eram as que recebiam menos tráfego. Além disso, quando emparelhei isso com a rede de links internos, descobri que as páginas corporativas de menor tráfego (Privacidade, Cookies, Segurança, Páginas Sobre Nós) têm o número máximo de links internos.
Como discutirei na próxima seção, isso fez com que o Googlebot removesse o fator de link interno do Pagerank quando rastreou o site, percebendo que os links internos não foram construídos como pretendido.
2. Problema: Arquitetura do Site, Pagerank Interno, Tráfego e Eficiência de Rastreamento
De acordo com a declaração do Google, links internos e textos âncora ajudam o Googlebot a entender a importância e o contexto de uma página da web. O Pagerank interno ou Inrank é calculado com base em mais de um fator. De acordo com Bill Slawski, links internos ou externos não são todos iguais. O valor de um link para o fluxo do Pagerank muda de acordo com sua posição, tipo, estilo e peso da fonte.

Se o Googlebot entender quais páginas são importantes para seu site, ele as rastreará mais e as indexará mais rapidamente. Links internos e design de Site-Tree correto são fatores importantes para isso. Outros especialistas também comentaram essa correlação ao longo dos anos:
“A maioria dos links fornece um pouco de contexto adicional por meio do texto âncora. Pelo menos deveriam, certo?”
–John Mueller, Google 2017“Se você tem páginas que considera importantes em seu site , não as enterre com 15 links de profundidade em seu site e não estou falando do tamanho do diretório, estou falando do real, você precisa clicar em 15 links para encontrar essa página se há uma página que é importante ou que tem grandes margens de lucro ou converte muito – bem – escalar que coloque um link para essa página da sua página raiz, é o tipo de coisa em que pode fazer muito sentido.”
–Matt Cutts, Google 2011“Se uma página for vinculada a outra com a palavra “contato” ou a palavra “sobre”, e a página vinculada incluir um endereço, esse local do endereço poderá ser considerado relevante para a página que faz essa vinculação.”
12 métodos de análise de links do Google que podem ter mudado - Bill Slawski
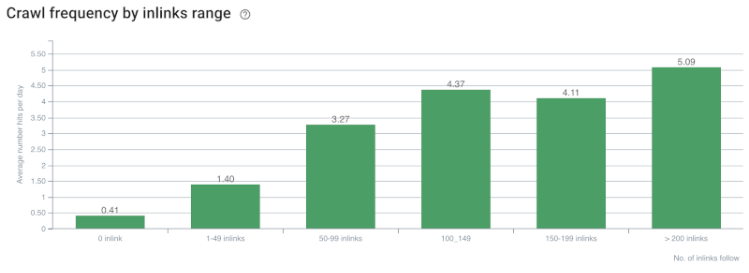
Taxa de rastreamento/demanda e correlação de contagem de links internos. Fonte: OnCrawl.
Até agora, podemos fazer estas inferências:
- O Google se preocupa com a profundidade dos cliques. Se uma página da web estiver mais próxima da página inicial, ela deve ser mais importante. Isso também foi confirmado por John Mueller em 1º de julho de 2018 em inglês Google Webmaster Hangout.
- Se uma página da web tem muitos links internos que apontam para ela, isso deve ser importante.
- Os textos âncora podem dar poder contextual a uma página da web.
- Um link interno pode transmitir diferentes valores de Pagerank com base em sua posição, tipo, peso da fonte ou estilo.
- Um Site-Tree amigável para UX que fornece mensagens claras sobre Autoridade de Página Interna para os rastreadores do mecanismo de pesquisa é uma escolha melhor para distribuição de Inrank e eficiência de rastreamento.
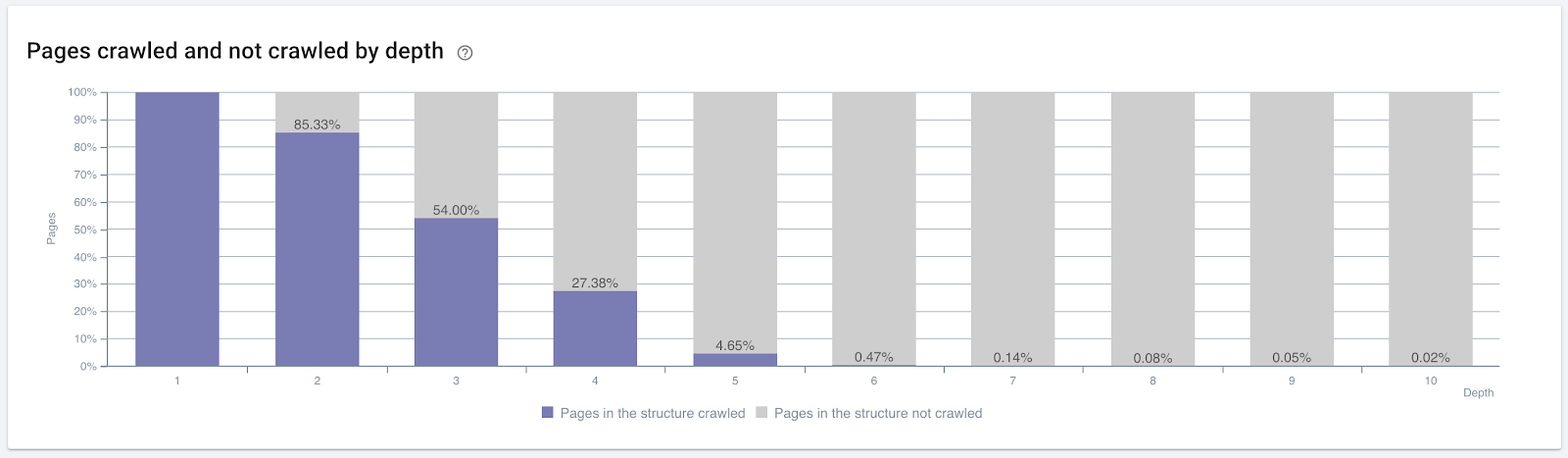
Porcentagem de páginas rastreadas por profundidade de clique. Fonte: OnCrawl.
Mas isso não é suficiente para entender a natureza e os efeitos dos links internos na eficiência do rastreamento.
Rastreador de SEO Oncrawl
 Saber mais
Saber maisSe suas páginas com links internos não criam tráfego ou são clicadas, isso dá sinais que indicam que sua árvore do site e estrutura de links internos não são construídos de acordo com a intenção do usuário. E o Google sempre tenta encontrar suas páginas mais relevantes com intenção do usuário ou entidades de pesquisa. Temos outra citação de Bill Slawski que deixa esse assunto mais claro:
“Se um recurso estiver vinculado a um número de recursos desproporcional em relação ao tráfego recebido pelo uso desses links, esse recurso poderá ser rebaixado no processo de classificação.”
A atualização da Groundhog acabou de acontecer no Google? — Bill Slawski“O índice de qualidade da seleção pode ser maior para uma seleção que resulta em um longo tempo de permanência (por exemplo, maior que um período de tempo limite) do que o índice de qualidade da seleção para uma seleção que resulta em um curto tempo de permanência.”
A atualização da Groundhog acabou de acontecer no Google? — Bill Slawski
Então temos mais dois fatores:
- Tempo de permanência na página vinculada.
- Tráfego do usuário produzido pelo link.
A contagem de links internos e o estilo/posição não são os únicos fatores. O número de usuários que seguem esses links e suas métricas de comportamento também são importantes. Além disso, sabemos que links e páginas que são clicados/visitados são rastreados pelo Google muito mais do que links e páginas que não são clicados ou visitados.
“Nós avançamos cada vez mais para entender as seções de um site para entender a qualidade dessas seções.”
John Mueller, 2 de maio de 2017, Hangout para webmasters do Google em inglês.
À luz de todos esses fatores, compartilharei dois resultados diferentes e diferentes do Pagerank Simulator:
Esses cálculos de Pagerank são feitos com a suposição de que todas as páginas são iguais, incluindo a página inicial. A diferença real é determinada pela hierarquia de links.
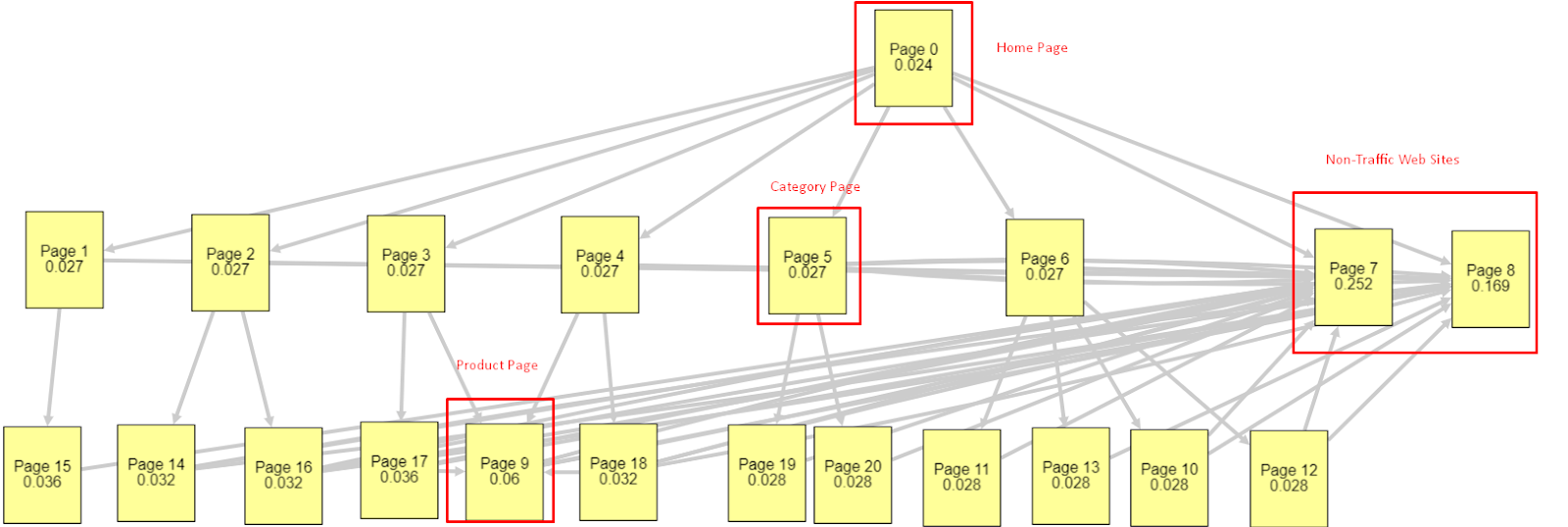
O exemplo mostrado aqui está mais próximo da estrutura de links internos antes de 12 de março. PR da página inicial: 0,024, PR da página da categoria: 0,027, PR da página do produto: 0,06, PR das páginas da Web sem tráfego: 0,252.
Como você pode notar, o Googlebot não pode confiar nessa estrutura de links internos para calcular o pagerank interno e a importância das páginas internas. Páginas sem tráfego e sem produtos têm 12 vezes mais autoridade do que a página inicial. Tem mais do que páginas de produtos.

Este exemplo está mais próximo de nossa situação antes da atualização do algoritmo principal de 5 de junho. PR da página inicial: 0,033, página da categoria: 0,037, página do produto: 0,148 e PR das páginas sem tráfego: 0,037.
Como você pode notar, a estrutura de links internos ainda não está correta, mas pelo menos as Páginas da Web Sem Tráfego não têm mais PR do que Páginas de Categoria e Páginas de Produto.
Qual é mais uma prova de que o Google tirou o link interno e a estrutura do site do escopo do Pagerank de acordo com o fluxo de usuários e solicitações e intenções? É claro que o comportamento do Googlebot e as correlações de Inlink Pagerank e Ranking:
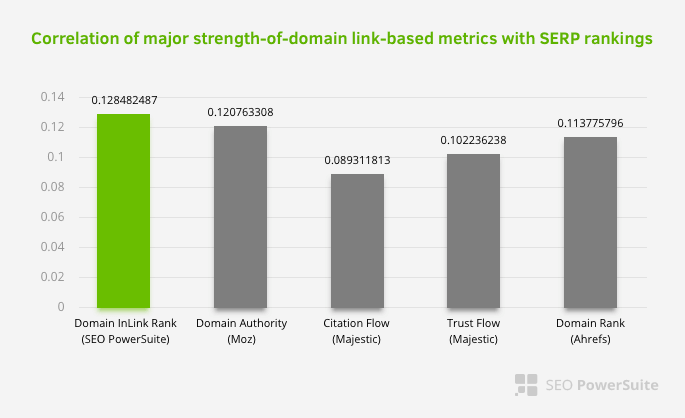
Isso não significa que a rede de links internos, especialmente, seja mais importante do que outros fatores. A perspectiva de SEO que se concentra em um único ponto nunca pode ser bem-sucedida. Em uma comparação entre ferramentas de terceiros, mostra que o valor do Pagerank interno está progredindo em relação a outros critérios.
De acordo com o Inlink Rank e pesquisa de correlação de classificação de Aleh Barysevich, as páginas com mais links internos têm classificações mais altas do que as outras páginas do site. De acordo com a pesquisa realizada de 4 a 6 de março de 2019, 1.000.000 de páginas foram analisadas de acordo com a métrica interna do Pagerank para 33.500 palavras-chave. Os resultados desta pesquisa realizada pelo SEO PowerSuite foram comparados com as diferentes métricas do Moz, Majestic e Ahrefs e deram resultados mais precisos.
Aqui estão alguns dos números de links internos do nosso site antes da atualização do algoritmo principal de 12 de março:
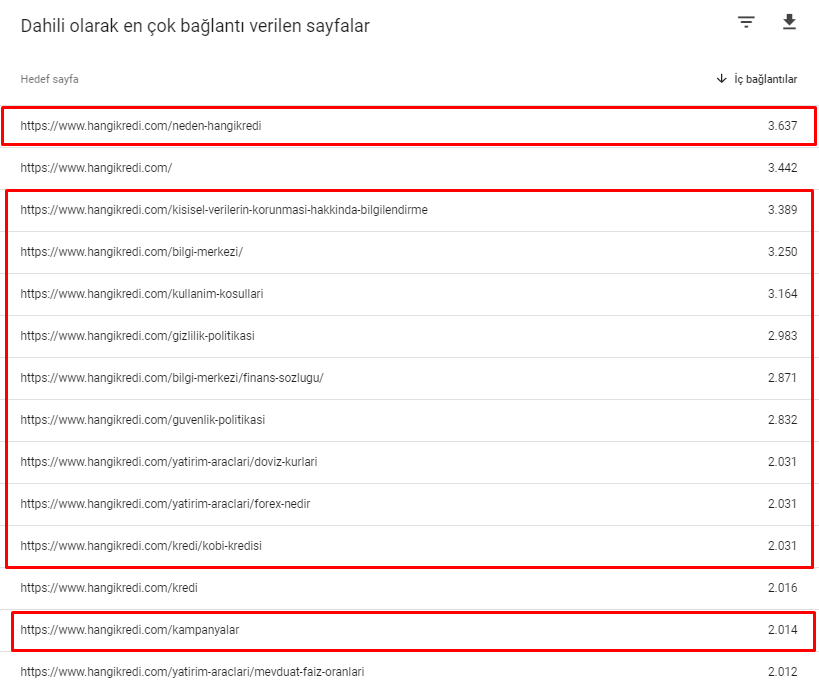
Como você pode ver, nosso esquema de conexão interna não refletiu a intenção e o fluxo do usuário. As páginas que recebem menos tráfego (páginas de produtos menores) ou que nunca recebem tráfego (em vermelho) estavam diretamente na profundidade do 1º clique e recebem PR da página inicial. E alguns tinham ainda mais links internos do que a página inicial.
À luz de tudo isso, há apenas os dois últimos pontos que podemos mostrar sobre esse assunto.
- Taxa de rastreamento/demanda para as páginas mais vinculadas internamente
- Link Sculpting e Pagerank
Entre 1º de fevereiro e 31 de março, aqui estão as páginas que o Googlebot rastreou com mais frequência:
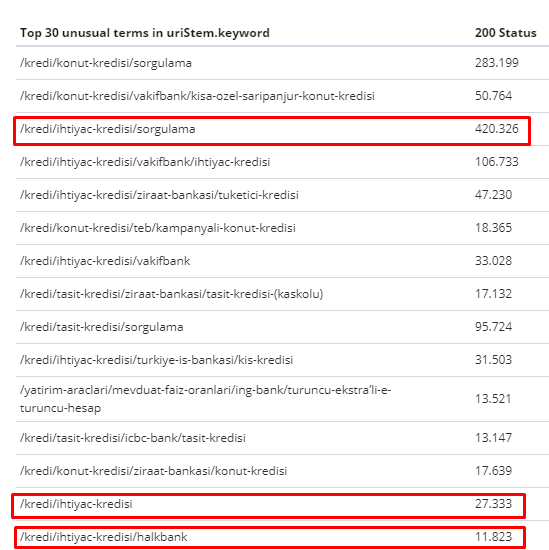
Como você pode notar, as páginas rastreadas e as páginas que possuem mais links internos são completamente diferentes umas das outras. As páginas com mais links internos não eram convenientes para a intenção do usuário; eles não têm palavras-chave orgânicas ou qualquer tipo de valor de SEO direto. (
Os URLs nas caixas vermelhas são nossas categorias de página de produto mais visitadas e importantes. As outras páginas desta lista são a segunda ou terceira categoria mais visitada e importante.)
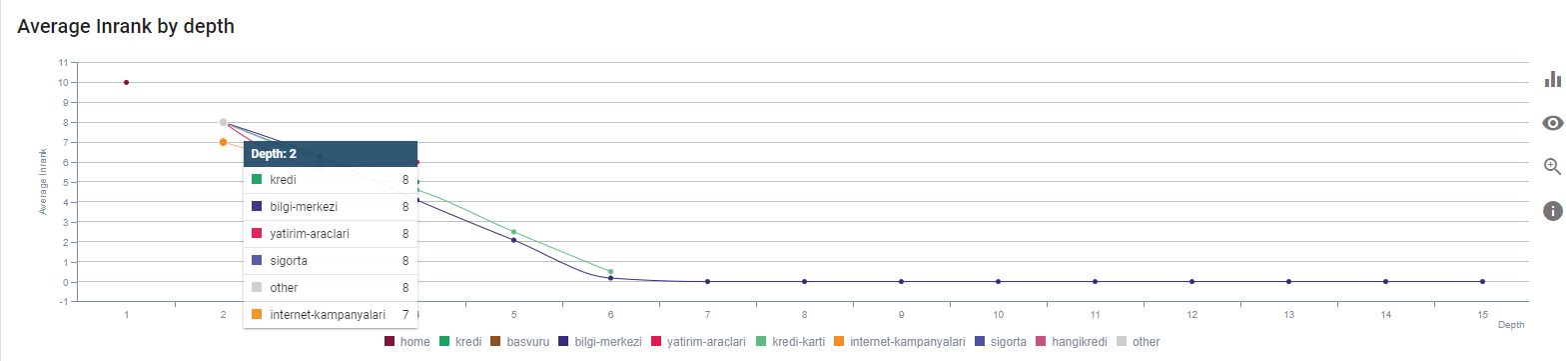
Nosso Inrank atual por profundidade de página. Fonte: Oncrawl.
O que é Link Sculpting e o que fazer com links internamente nofollowed?
Ao contrário do que a maioria dos SEOs acredita, os links marcados com uma tag “nofollow” ainda passam o valor interno do Pagerank. Para mim, depois de todos esses anos, ninguém narrou esse elemento de SEO melhor do que Matt Cutts em seu Pagerank Sculpting Article de 15 de junho de 2009.
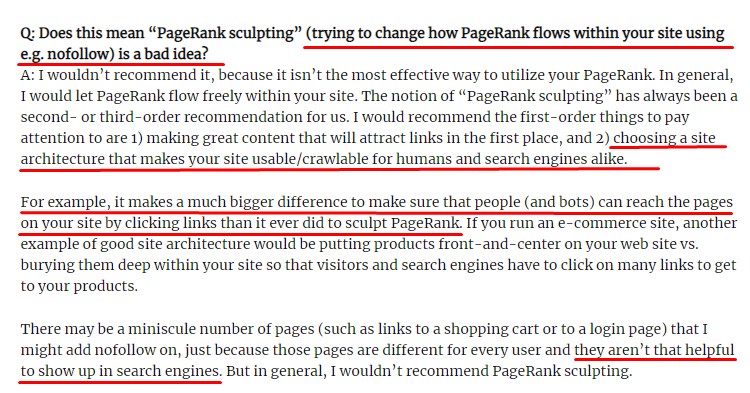
Uma parte útil para o Link Sculpting, que mostra o real propósito do Pagerank Sculpting.
“Eu recomendaria não usar nofollow para esculpir o PageRank em um site , porque provavelmente não faz o que você acha que faz.”
–John Mueller, Google 2017
Se você tem páginas da web inúteis em termos de Google e usuários, você não deve marcá-las com “nofollow”. Não vai parar o fluxo Pagerank. Você deve proibi-los do arquivo robots.txt. Dessa forma, o Googlebot não os rastreará, mas também não passará o Pagerank interno para eles. Mas você deve usar isso apenas para páginas realmente inúteis, como Matt Cutts disse dez anos atrás. Páginas que fazem redirecionamentos automáticos para marketing de afiliados ou páginas sem conteúdo são alguns exemplos convenientes aqui.
Solução: estrutura de links internos melhor e mais natural
Nosso concorrente tinha uma desvantagem. Seu site tinha mais texto âncora, mais links internos, mas sua estrutura não era natural e útil. O mesmo texto âncora foi usado com a mesma frase em cada página do site. O parágrafo de entrada de cada página foi coberto com esse conteúdo repetitivo. Cada usuário e mecanismo de pesquisa pode reconhecer facilmente que esta não é uma estrutura natural que considera o benefício do usuário.
Então, decidi três coisas a fazer para corrigir a estrutura de links internos:
- A Arquitetura de Informações do Site ou Site-Tree deve seguir um caminho diferente dos links colocados no conteúdo. Deve seguir mais de perto a mente do usuário e uma rede neural de palavras-chave.
- Em cada parte do conteúdo, as palavras-chave secundárias devem ser usadas junto com as palavras-chave principais da página segmentada.
- Os textos âncora devem ser naturais, adaptados ao conteúdo, e devem ser usados em um ponto diferente de cada página com atenção à percepção do usuário
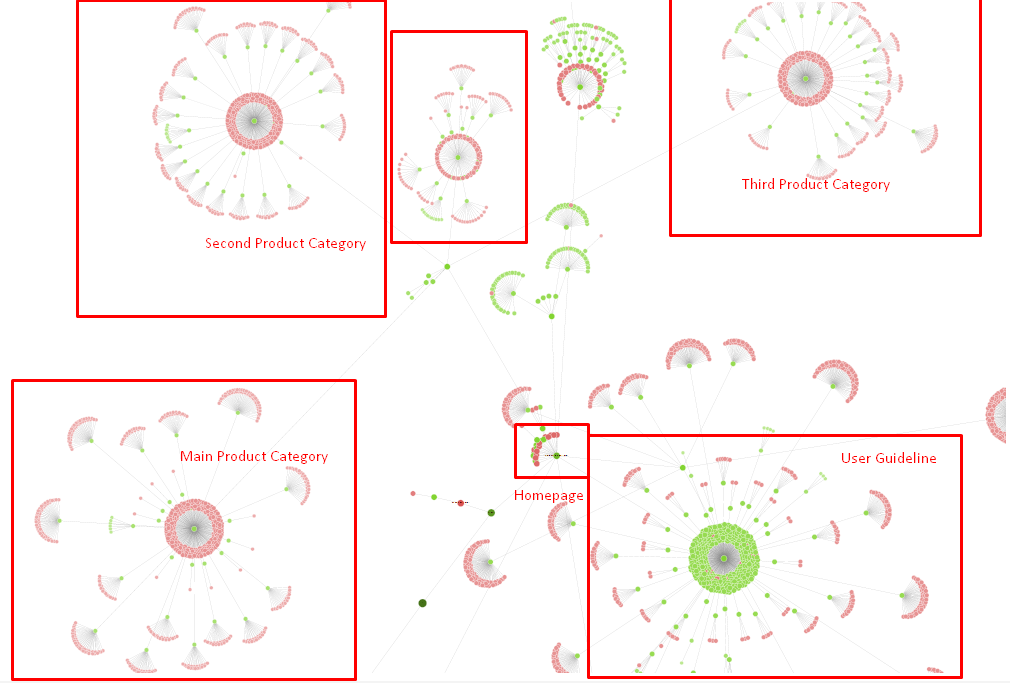
Nossa árvore do site e uma parte da estrutura do inlink por enquanto.
No diagrama acima, você pode ver nosso link interno atual e a árvore do site.
Algumas das coisas que fizemos para corrigir esse problema estão abaixo:
- Criamos mais 30.000 links internos com âncoras úteis.
- Usamos pontos naturais e palavras-chave para o usuário.
- Não usamos frases e padrões repetitivos para links internos.
- Demos os sinais certos ao Googlebot sobre o Inrank de uma página da web.
- Examinamos os efeitos da estrutura correta de links internos na eficiência do rastreamento por meio da Análise de log e vimos que nossas principais páginas de produtos foram mais rastreadas em comparação com as estatísticas anteriores.
- Criou mais de 50.000 links internos para páginas órfãs.
- Usou links internos da página inicial para alimentar as subpáginas e criou mais fontes de links internos na página inicial.
- Para proteger o Pagerank Power, também usamos a tag nofollow para alguns links externos desnecessários. (Não se tratava de links internos, mas serve ao mesmo objetivo.)
3. Problema: Estrutura de Conteúdo
O Google diz que para sites YMYL, confiabilidade e autoridade são muito mais importantes do que para outros tipos de sites.

Antigamente, as palavras-chave eram apenas palavras-chave. Mas agora são também entidades bem definidas, singulares, significativas e distinguíveis. Em nosso conteúdo, havia quatro problemas principais:
- Nosso conteúdo foi curto. (Normalmente, a duração do conteúdo não é importante. Mas, neste caso, eles não continham informações suficientes sobre os tópicos.)
- Os nomes de nossos escritores não eram singulares, significativos ou distinguíveis como uma entidade.
- Nosso conteúdo não era amigável aos olhos. Em outras palavras, não era um conteúdo “fast-food”. Era conteúdo sem subtítulos.
- Usamos linguagem de marketing. No espaço de um parágrafo, poderíamos identificar o nome da marca e sua publicidade para o usuário.
- Havia muitos botões que direcionavam os usuários para as páginas de produtos das páginas informativas.
- No conteúdo de nossas páginas de produtos, não havia informações suficientes ou diretrizes abrangentes.
- O design não era amigável. Estávamos usando basicamente a mesma cor para fonte e plano de fundo. (Esse ainda é o caso devido a problemas de infraestrutura.)
- Imagens e vídeos não eram vistos como parte do conteúdo.
- A intenção do usuário e a intenção de pesquisa para uma palavra-chave específica não eram consideradas importantes antes.
- Havia muito conteúdo duplicado, desnecessário e repetitivo para o mesmo tópico.
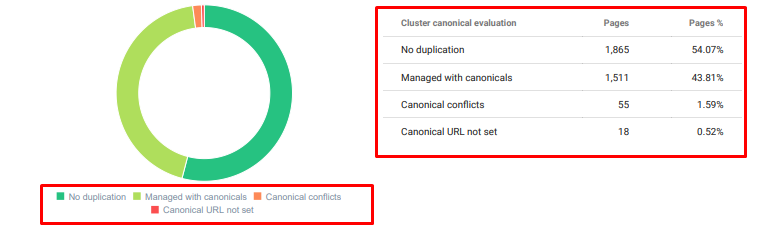
Auditoria de conteúdo duplicado Oncrawl a partir de hoje.
Solução: melhor estrutura de conteúdo para a confiança do usuário
Ao verificar um problema em todo o site, usar um programa de auditoria em todo o site como assistente é a melhor maneira de organizar o tempo gasto em projetos de SEO. Como na seção de links internos, usei o Oncrawl Site Audit junto com outras ferramentas e inspeções Xpath.
Em primeiro lugar, corrigir todos os problemas na seção de conteúdo levaria muito tempo. Naqueles dias de crise em colapso, o tempo era um luxo. Então decidi corrigir problemas de ganho rápido, como:
- Excluindo conteúdo duplicado, desnecessário e repetitivo
- Unificação de conteúdo curto e fino sem informações abrangentes
- Republicação de conteúdo sem subtítulos e estrutura rastreável
- Corrigindo o tom de marketing intensivo no conteúdo
- Excluindo muitos botões de chamada para ação do conteúdo
- Melhor Comunicação Visual com Imagens e Vídeos
- Tornar o conteúdo e as palavras-chave de destino compatíveis com a intenção do usuário e da pesquisa
- Usando e mostrando entidades financeiras e educacionais no conteúdo para confiança
- Usando a comunidade social para criar prova social de aprovação
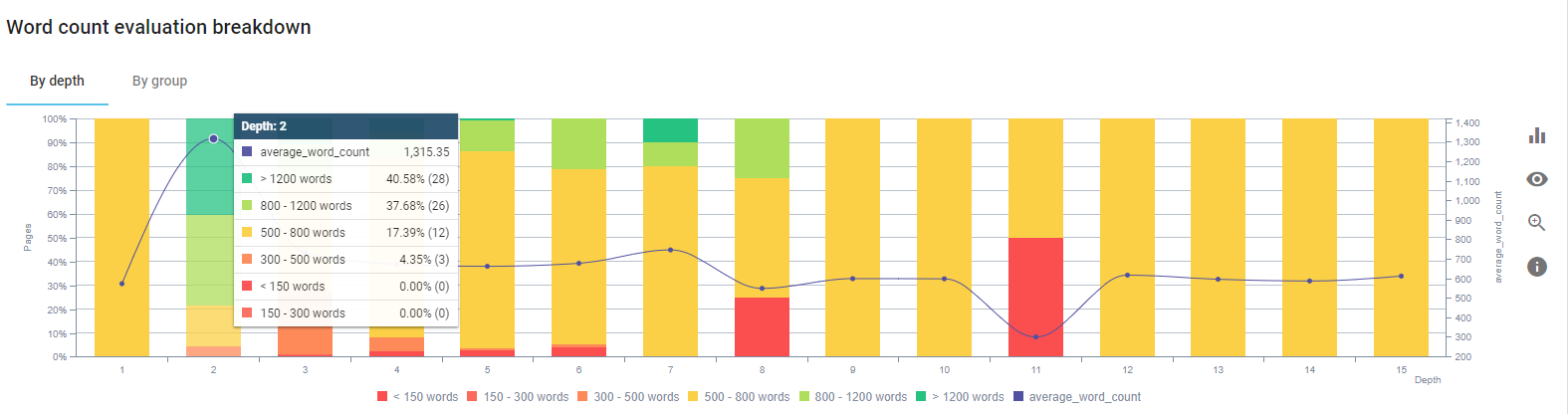

Nós nos concentramos em fixar o conteúdo das páginas de produtos e as páginas de guia mais próximas a elas.
No início desse processo, a maioria de nossas páginas de destino/diretrizes de produtos e transações tinham menos de 500 palavras sem informações abrangentes.
Em 25 dias, as ações que realizamos estão abaixo:
- Excluídas 228 páginas com conteúdo duplicado, desnecessário e repetitivo. (Os perfis de backlink do Ccontent foram verificados antes do processo de exclusão. E usamos códigos de status 301 ou 410 para melhor comunicação com o Googlebot.)
- Combinado mais de 123 páginas sem informações abrangentes.
- Subtítulos usados de acordo com sua importância e demanda do usuário no conteúdo.
- Botões de nome de marca e CTA excluídos com linguagem de estilo de marketing.
- Inclua texto nas imagens para reforçar o tópico principal.
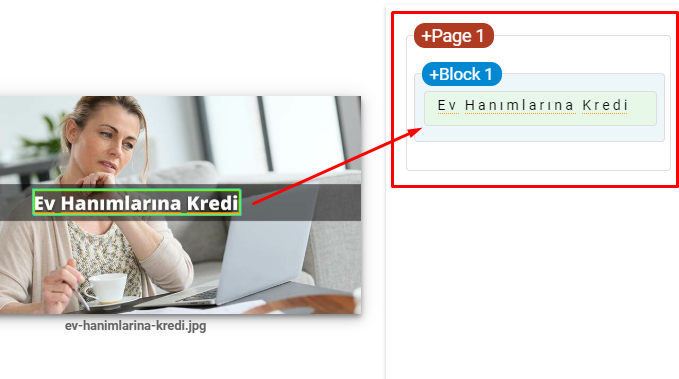
Esta é uma captura de tela do Vision AI do Google. O Google pode ler texto em imagens e detectar sentimentos e identidades dentro de entidades.
- Ativou a nossa rede social para atrair mais usuários.
- Examinamos a lacuna de conteúdo entre os concorrentes e nós e criamos mais de 80 novos conteúdos.
- Usou o Google Analytics, Search Console e Google Data Studio para determinar as páginas com baixo desempenho com alta taxa de rejeição e baixo tráfego.
- Pesquisei sobre Featured Snippets e suas palavras-chave e estrutura de conteúdo. Adicionamos os mesmos títulos e estrutura de conteúdo em nossos conteúdos relacionados. Isso aumentou nossos snippets em destaque.
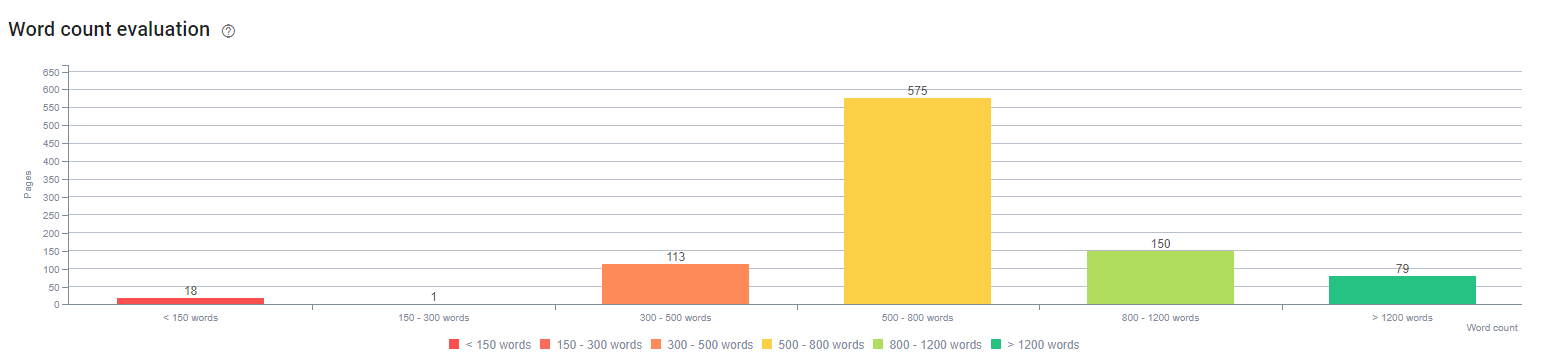
No início deste processo, nosso conteúdo era composto, em sua maioria, entre 150 e 300 palavras. Nosso tamanho médio de conteúdo aumentou em 350 palavras para todo o site.
4. Problema: poluição do índice, inchaço e tags canônicas
O Google nunca fez uma declaração sobre Poluição de Índice e, na verdade, não tenho certeza se alguém o usou como um termo de SEO antes ou não. Todas as páginas que não fazem sentido para o Google para uma pontuação de índice mais eficiente devem ser removidas das páginas de índice do Google. As páginas que causam poluição no índice são páginas que não geram tráfego há meses. Eles têm zero CTR e zero palavras-chave orgânicas. Nos casos em que eles possuem poucas palavras-chave orgânicas, eles teriam que se tornar um concorrente de outras páginas do seu site para as mesmas palavras-chave.
Além disso, realizamos pesquisas para o inchaço do índice e encontramos páginas indexadas ainda mais desnecessárias. Essas páginas existiam devido a uma estrutura incorreta de informações do site ou a uma estrutura de URL incorreta.
Outro motivo para esse problema foi o uso incorreto de tags canônicas. Por mais de dois anos, as tags canônicas foram tratadas apenas como dicas para o Googlebot. Se forem usados incorretamente, o Googlebot não os calculará nem prestará atenção a eles ao avaliar o site. E também, para esse cálculo, você provavelmente consumirá seu orçamento de rastreamento de forma ineficiente. Devido ao uso incorreto da tag canônica, mais de 300 páginas de comentários com conteúdo duplicado foram indexadas.
O objetivo da minha teoria é mostrar ao Google apenas páginas de qualidade e necessárias com potencial de ganhar cliques e criar valor para os usuários.
Solução: corrigindo a poluição e o inchaço do índice
Primeiro, segui o conselho de John Mueller, do Google. Perguntei a ele se eu usava a tag noindex para essas páginas, mas ainda permitia que o Googlebot as seguisse, “eu perderia o valor do link e a eficiência do rastreamento?”
Como você pode imaginar, ele disse sim no início, mas depois sugeriu que o uso de links internos pode superar esse obstáculo.
Também descobri que usar tags noindex ao mesmo tempo que dofollow diminuiu a taxa de rastreamento do Googlebot nessas páginas. Essas estratégias me permitiram fazer com que o Googlebot rastreasse meu produto e páginas de diretrizes importantes com mais frequência. Também modifiquei minha estrutura de links internos conforme John Mueller aconselhou.
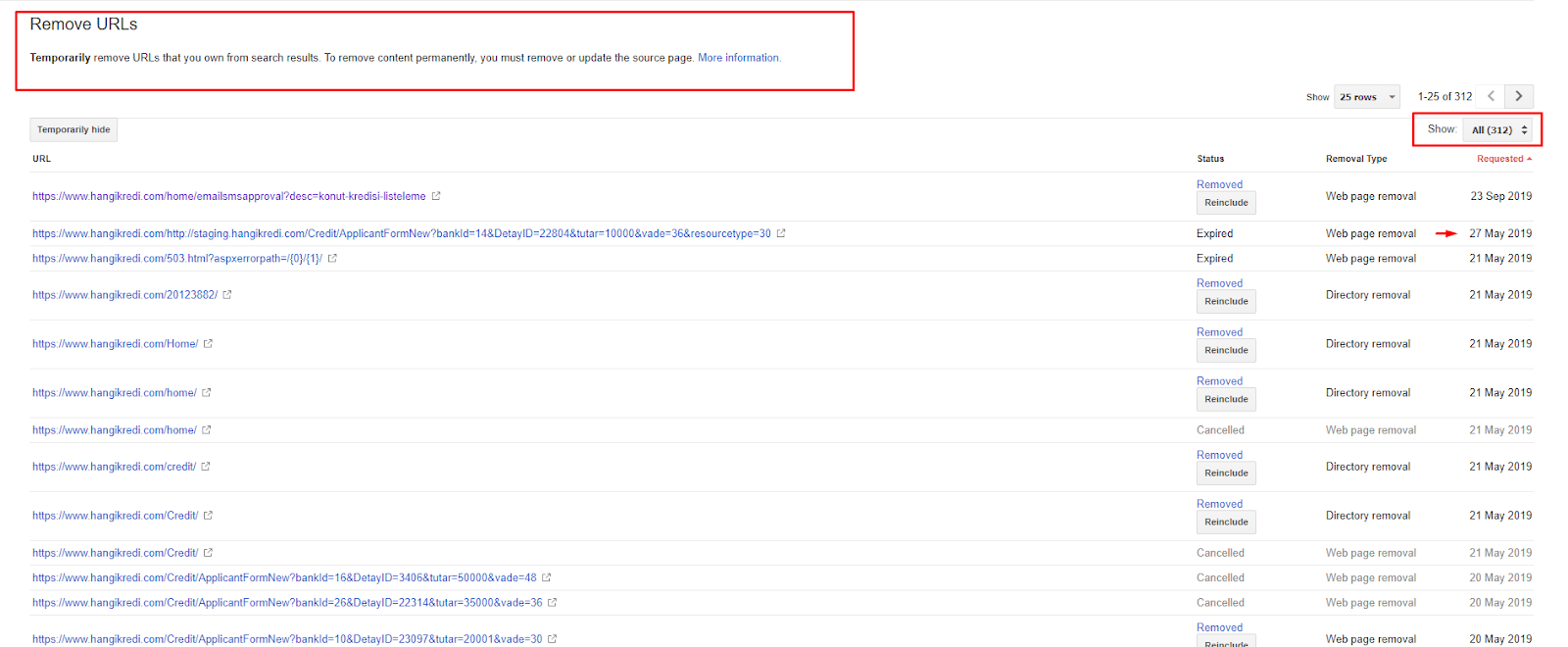
Em pouco tempo:
- Páginas indexadas desnecessárias foram descobertas.
- Mais de 300 páginas foram removidas do índice.
- A tag Noindex foi implementada.
- A estrutura de links internos foi modificada para as páginas que receberam links de páginas que foram removidas do índice.
- A eficiência e a qualidade do rastreamento foram examinadas ao longo do tempo.
5. Problema: Códigos de status incorretos
No início, notei que o Googlebot visita muitos conteúdos excluídos do passado. Até mesmo páginas de oito anos atrás ainda estavam sendo rastreadas. Isso ocorreu devido ao uso de códigos de status incorretos, especialmente para conteúdo excluído.
Há uma enorme diferença entre as funções 404 e 410. Um deles é para uma página de erro onde não existe conteúdo e o outro é para conteúdo excluído. Além disso, as páginas válidas também faziam referência a muitos URLs de fonte e conteúdo excluídos. Algumas imagens excluídas e recursos CSS ou JS também foram usados nas páginas publicadas válidas como recursos. Finalmente, havia muitas páginas 404 suaves e várias cadeias de redirecionamento e redirecionamentos temporários 302-307 para páginas redirecionadas permanentemente.
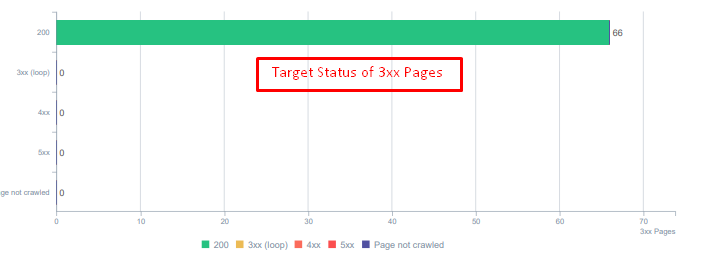
Códigos de status para ativos redirecionados hoje.
Solução: corrigindo códigos de status incorretos
- Cada código de status 404 foi convertido em código de status 410. (mais de 30.000)
- Cada recurso com código de status 404 foi substituído por um novo recurso válido. (mais de 500)
- Cada redirecionamento 302-307 foi convertido em redirecionamento 301 permanente. (mais de 1500)
- As cadeias de redirecionamento foram removidas dos ativos em uso.
- Todos os meses, recebemos mais de 25.000 acessos em páginas e recursos com código de status 404 em nossa Análise de Log. Agora, é menos de 50 para 404 códigos de status por mês e zero hits para 410 códigos de status…
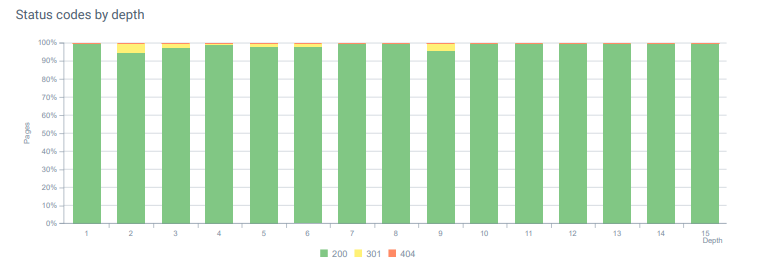
Códigos de status em toda a profundidade da página hoje.
6. Problema: HTML semântico
Semântica refere-se ao que algo significa. O HTML semântico inclui tags que dão o significado do componente da página dentro de uma hierarquia. Com essa estrutura de código hierárquica, você pode dizer ao Google qual é o propósito de uma parte do conteúdo. Além disso, caso o Googlebot não consiga rastrear todos os recursos necessários para renderizar totalmente sua página, você pode pelo menos especificar o layout de sua página da web e as funções de suas partes de conteúdo para o Googlebot.
No Hangikredi.com, após a atualização do algoritmo do Google Core de 12 de março, eu sabia que não havia orçamento de rastreamento suficiente devido à estrutura não otimizada do site. Então, para fazer o Googlebot entender mais facilmente o objetivo, a função, o conteúdo e a utilidade da página da web, decidi usar o HTML semântico.
Solução: uso de HTML semântico
De acordo com as Diretrizes do Avaliador de Qualidade do Google, todo pesquisador tem uma intenção e cada página da web tem uma função de acordo com essa intenção. Para provar essas funções ao Googlebot, fizemos algumas melhorias em nossa estrutura HTML para algumas das páginas que são menos rastreadas pelo Googlebot.
- Usada a tag <main> para mostrar o conteúdo principal e a função da página.
- Usado <nav> para a parte de navegação.
- Usado <footer> para o rodapé do site.
- Usado <article> para o artigo.
- Usado tags <section> para cada tag de cabeçalho.
- Utilizadas as tags <picture>, <table>, <citation> para imagens, tabelas e citações no conteúdo.
- Usado, tag <aside> para o conteúdo suplementar.
- Corrigidos os problemas de hierarquia H1-H6 (apesar da última declaração do Google "usar dois H1 não é um problema", usando a estrutura correta, ajuda o Googlebot.)
- Como na seção Estrutura de conteúdo, também usamos HTML semântico para snippets em destaque, usamos tabelas e listas para obter mais resultados de snippets em destaque.

Para nós, este não foi um desenvolvimento implementável de forma realista para todo o site. Ainda assim, com cada atualização de design, continuamos a implementar tags HTML semântico para páginas da web adicionais.
7. Problema: Uso de Dados Estruturados
Assim como o uso de HTML semântico, os Dados Estruturados podem ser usados para mostrar as funções e definições de partes de páginas da web para o Googlebot. Além disso, Dados Estruturados são obrigatórios para rich results. Em nosso site, dados estruturados não foram usados ou, mais comumente, foram usados incorretamente até o final de março. Com o objetivo de criar melhores relações com as entidades em nosso site e nossas contas off-page, começamos a implementar Dados Estruturados.
Solução: uso correto e testado de dados estruturados
Para instituições financeiras e sites YMYL, os dados estruturados podem corrigir muitos problemas. Por exemplo, eles podem mostrar a identidade da marca, o tipo de conteúdo e criar uma visualização melhor do snippet. Usamos os seguintes tipos de dados estruturados para páginas individuais e em todo o site:
- Dados estruturados de perguntas frequentes para as principais páginas de produtos
- Dados estruturados de página da Web
- Dados Estruturados da Organização
- Dados estruturados de migalhas
8. Otimização de Sitemap e Robots.txt
Em Hangikredi.com, não há Sitemap dinâmico. O mapa do site existente na época não incluía todas as páginas necessárias e também incluía conteúdo excluído. Além disso, no arquivo Robots.txt, algumas das páginas de referência de afiliados com milhares de links externos não foram proibidas. Isso também incluiu alguns arquivos JS de terceiros que não estão relacionados ao conteúdo e outros recursos adicionais desnecessários para o Googlebot.
Os seguintes passos foram aplicados:
- Criou um sitemap_index.xml para vários sitemaps que são criados de acordo com as categorias do site para melhores sinais de rastreamento e melhor exame de cobertura.
- Alguns dos arquivos JS de terceiros e alguns arquivos JS desnecessários não foram permitidos no arquivo robots.txt.
- Páginas de afiliados com links externos e sem valor de landing page não foram permitidas, como mencionamos na seção de Pagerank ou Internal Link Sculpting.
- Corrigidos mais de 500 problemas de cobertura. (A maioria delas eram páginas indexadas apesar de não serem permitidas pelo Robots.txt.)
Você pode ver nossa taxa de rastreamento, carga e aumento de demanda no gráfico abaixo:
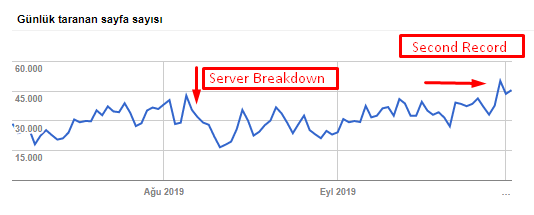
Contagem de páginas rastreadas por dia pelo Googlebot. Houve um aumento constante de páginas rastreadas por dia até 1º de agosto. Depois que um ataque causou uma falha no servidor no início de agosto, ele recuperou sua estabilidade em pouco mais de um mês.

A carga rastreada por dia pelo Googlebot evoluiu em paralelo com o número de páginas rastreadas por dia.
9. Corrigindo problemas de AMP
No site da empresa, cada página do blog tem uma versão AMP. Devido à implementação incorreta do código e aos canônicos AMP ausentes, todas as páginas AMP foram excluídas repetidamente do índice. Isso criou uma pontuação de índice instável e falta de confiança para o site. Além disso, as páginas AMP tinham termos e palavras em inglês por padrão no conteúdo turco.
- As tags canônicas foram corrigidas para mais de 400 páginas AMP.
- Implementações de código incorretas foram encontradas e corrigidas. (Foi principalmente devido à implementação incorreta de tags AMP-Analytics e AMP-Canonical.)
- Os termos em inglês por padrão foram traduzidos para o turco.
- A estabilidade de índice e classificação foi criada para o lado do blog do site da empresa.
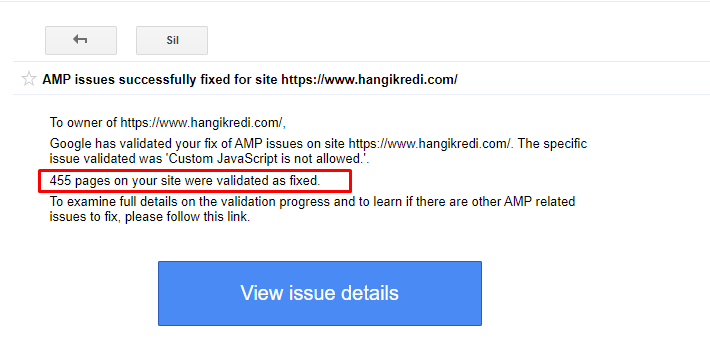
Uma mensagem de exemplo no GSC sobre melhorias de AMP
10. Problemas e soluções de metatag
Devido aos problemas de orçamento de rastreamento, às vezes em consultas de pesquisa críticas para páginas principais de produtos importantes, o Google não indexou ou exibiu conteúdo nas metatags. Em vez do meta-título, a listagem do SERP mostrava apenas o nome da empresa construído a partir de duas palavras. Nenhuma descrição do snippet foi exibida. Isso estava diminuindo nossa CTR e prejudicando nossa identidade de marca. Corrigimos esse problema movendo as metatags para o topo do nosso código-fonte, conforme mostrado abaixo.
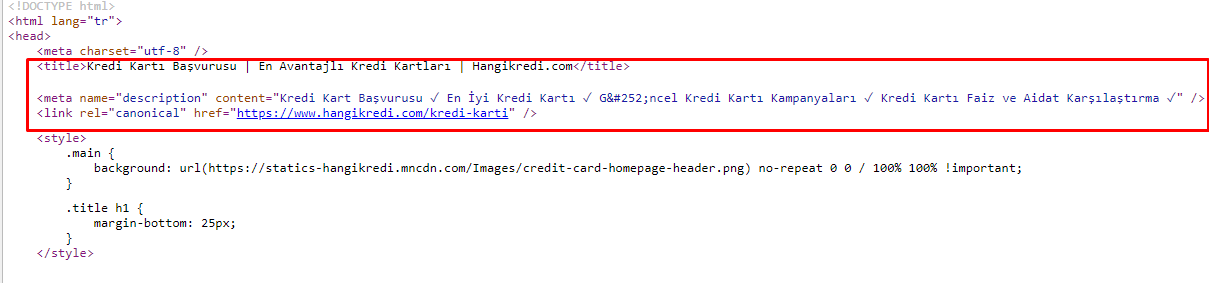
Além do orçamento de rastreamento, também otimizamos mais de 600 metatags para páginas transacionais e informativas:
- Comprimento de caracteres otimizado para dispositivos móveis.
- Usou mais palavras-chave nos títulos
- Usou diferentes estilos de metatags e examinou a CTR, a lacuna de palavras-chave e as alterações de classificação
- Criei mais páginas com estrutura de árvore de site correta para direcionar melhor as palavras-chave secundárias graças a esses processos de otimização.
- Em nosso site, ainda temos diferentes meta títulos, descrições e títulos para testar o algoritmo do Google e a CTR do usuário de busca.
11. Problemas e soluções de desempenho de imagem
Os problemas de imagem podem ser divididos em dois tipos. Para conveniência do conteúdo e velocidade da página. Para ambos, o site da empresa ainda tem muito o que fazer.
Em março e abril, após a atualização negativa do algoritmo principal de 12 de março:
- As imagens não tinham tags alt ou tinham tags alt erradas.
- Eles não tinham títulos.
- Eles não tinham a estrutura de URL correta.
- Eles não tinham extensões de próxima geração.
- Eles não foram compactados.
- Eles não tinham a resolução certa para cada tamanho de tela do dispositivo.
- Não tinham legendas.
Para se preparar para a próxima atualização do algoritmo do Google Core:
- As imagens foram compactadas.
- Suas extensões foram parcialmente alteradas.
- Alt tags foram escritas para a maioria deles.
- Títulos e legendas foram corrigidos para o usuário.
- As estruturas de URL foram parcialmente corrigidas para o usuário.
- Encontramos algumas imagens não utilizadas que ainda estão sendo carregadas pelo navegador e as excluímos do sistema.
Por causa da infraestrutura do site, implementamos parcialmente as correções de SEO de imagem.
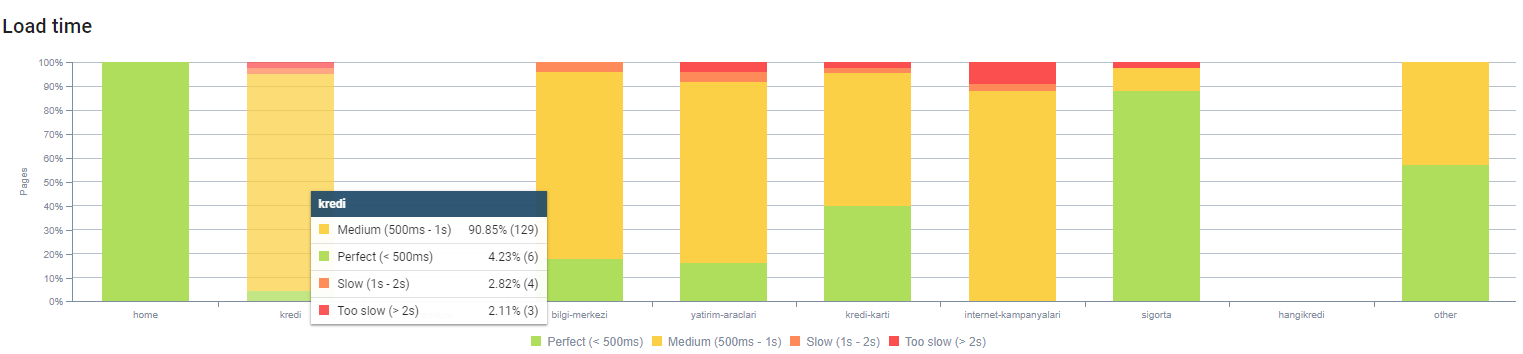
Você pode observar o tempo de carregamento da página pela profundidade da página acima. Como você pode ver, a maioria das páginas de produtos ainda são pesadas.
12. Problemas e soluções de cache, pré-busca e pré-carregamento
Antes da atualização do algoritmo principal de 12 de março, havia um sistema de cache solto no site da empresa. Algumas das partes do conteúdo estavam no cache, mas outras não. Isso foi especialmente um problema para as páginas de produtos porque elas eram 2x mais lentas do que as páginas de produtos de nossos concorrentes. A maioria dos componentes de nossas páginas da web são na verdade fontes estáticas, mas ainda não possuem Etags para informar o intervalo do cache.
Para se preparar para a próxima atualização do algoritmo do Google Core:
- Nós armazenamos em cache alguns componentes para cada página da web e os tornamos estáticos.
- Essas páginas eram importantes páginas de produtos.
- Ainda não usamos E-Tags por causa da infraestrutura do site.
- Especialmente imagens, recursos estáticos e algumas partes de conteúdo importantes agora são totalmente armazenadas em cache em todo o site.
- Começamos a usar o código dns-prefetch para alguns recursos terceirizados esquecidos.
- Ainda não usamos o código de pré-carregamento, mas estamos trabalhando na jornada do usuário no site para implementá-lo no futuro.
13. Otimização e Minificação de HTML, CSS e JS
Devido aos problemas de infraestrutura do site, não havia muitas coisas a fazer para a velocidade do site. Tentei preencher a lacuna com todos os métodos possíveis, incluindo a exclusão de alguns componentes da página. Para páginas de produtos importantes, limpamos a estrutura do código HTML, minificamos e compactamos.
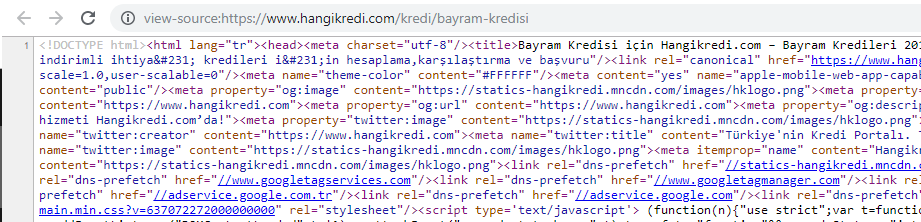
Uma captura de tela do código-fonte de uma de nossas páginas de produtos sazonais, mas importantes. O uso de dados estruturados de perguntas frequentes, redução de HTML, otimização de imagens, atualização de conteúdo e links internos nos deram a primeira classificação no momento certo. (A palavra-chave é "Bayram Kredisi" em turco, que significa "Crédito de férias")
Também implementamos CSS Factoring, Refactoring e JS Compression parcialmente com pequenos passos. Quando as classificações caíram, examinamos a diferença de velocidade do site entre as páginas do nosso concorrente e as nossas. Tínhamos escolhido algumas páginas urgentes que poderíamos agilizar. Também purificamos e compactamos parcialmente arquivos CSS críticos nessas páginas. Iniciamos o processo de remoção de alguns dos arquivos JS de terceiros usados por diferentes departamentos da empresa, mas eles ainda não foram removidos. Para algumas páginas de produtos, também conseguimos alterar a ordem de carregamento dos recursos.
Examinando os concorrentes
Além de todas as melhorias técnicas de SEO, inspecionar os concorrentes foi meu melhor guia para entender a natureza e os objetivos de uma atualização do algoritmo principal. Eu usei alguns programas úteis e úteis para acompanhar as mudanças de design, conteúdo, classificação e tecnologia do meu concorrente.
- Para alterações de classificação de palavras-chave, usei Wincher, Semrush e Ahrefs.
- Para menções de marca, usei Alertas do Google, BuzzSumo, Talkwalker.
- Para novos relatórios de ganhos de links e palavras-chave, usei o Alerta Ahrefs.
- Para alterações de conteúdo e design, usei o Visualping.
- Para mudanças de tecnologia, usei SimilarTech.
- Para o Google Update News and Inspection, usei principalmente o Sensor Semrush, Algoroo e CognitiveSEO Signals.
- Para inspecionar o histórico de URLs dos concorrentes, usei o Wayback Machine.
- Para velocidade do servidor dos concorrentes, usei Chrome DevTools e ByteCheck.
- Para o custo de rastreamento e renderização, usei “Qual é o custo do meu site”. (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.