
Previsão de tráfego de SEO com Profeta e Python
Publicados: 2021-03-16Definir metas e avaliar o cumprimento ao longo do tempo é um exercício muito interessante para entender o que somos capazes de alcançar e se a estratégia que utilizamos é eficaz ou não. No entanto, geralmente não é tão fácil definir essas metas, porque primeiro precisamos fazer uma previsão.
Criar uma previsão não é uma tarefa fácil, mas graças a alguns procedimentos de previsão disponíveis, nossa CPU e algumas habilidades de programação, podemos reduzir bastante sua complexidade. Neste post, vou mostrar como podemos fazer previsões precisas e como você pode aplicar isso ao SEO usando Python e a biblioteca Prophet e sem ter que ter superpoderes de cartomante.
Se você nunca ouviu falar sobre o Profeta, você pode se perguntar o que é. Resumindo, Prophet é um procedimento de previsão que foi lançado pela equipe Core Data Science do Facebook que está disponível em Python e R e que lida muito bem com outliers e efeitos sazonais para
fornecer previsões precisas e rápidas.
Quando falamos em previsão, precisamos levar em consideração duas coisas:
- Quanto mais dados históricos tivermos, mais preciso será nosso modelo e, portanto, nossas previsões.
- O modelo preditivo só será válido se os fatores internos permanecerem os mesmos e não houver fatores externos que o afetem. Isso significa que se, por exemplo, estivermos publicando um post por semana e começarmos a publicar dois posts por semana, esse modelo pode não ser válido para prever qual será o resultado dessa mudança de estratégia. Por outro lado, se houver uma atualização do algoritmo, o modelo também pode não ser válido. Tenha em mente que o modelo é construído com base em dados históricos.
Para aplicar isso ao SEO, o que vamos fazer é prever as sessões de SEO para o próximo mês seguindo os próximos passos:
- Obtendo dados do Google Analytics sobre as sessões orgânicas por um período de tempo específico.
- Treinando nosso modelo.
- Previsão do tráfego de SEO para o próximo mês.
- Avaliando quão bom nosso modelo é com o erro absoluto médio.
Quer saber mais sobre como funciona esse procedimento de previsão? Vamos começar então!
Obtendo os dados do Google Analytics
Podemos abordar a extração de dados do Google Analytics de duas maneiras: exportando um arquivo Excel da interface normal ou usando a API para recuperar esses dados.
Importando os dados de um arquivo Excel
A maneira mais fácil de obter esses dados do Google Analytics é indo até a seção Canais na barra lateral, clicando em Orgânicos e exportando os dados com o botão que fica no topo da página. Certifique-se de selecionar no menu suspenso na parte superior do gráfico a variável que deseja analisar, neste caso Sessões.
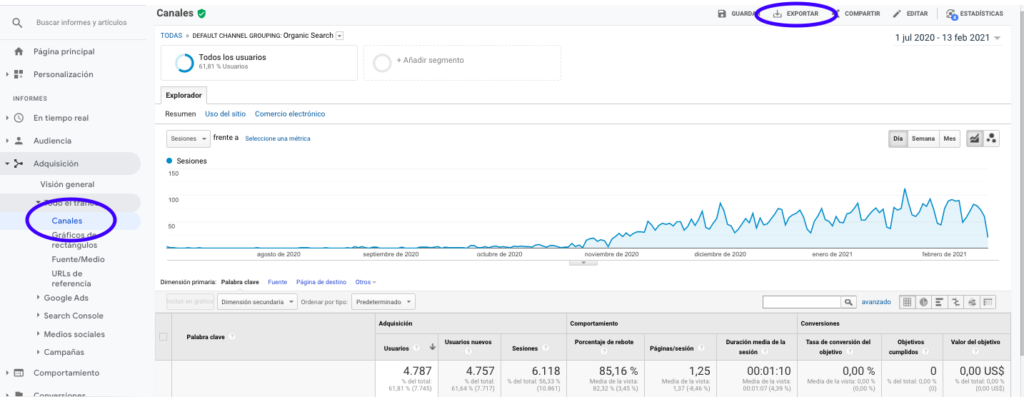
Depois de exportar os dados como um arquivo Excel, podemos importá-los para o nosso notebook com o Pandas. Observe que o arquivo Excel com esses dados conterá abas diferentes, portanto, a aba com o tráfego mensal precisa ser especificada como argumento no trecho de código abaixo. Também apagamos a última linha porque ela contém a quantidade total de sessões, o que distorceria nosso modelo.
importar pandas como pd
df = pd.read_excel ('.xlsx', sheet_name= "")
df = df.drop(len(df) - 1)
Podemos desenhar com Matplotlib como os dados se parecem:
do matplotlib importar pyplot
df["Sessões"].plot(title = "Sessões")
pyplot.show() 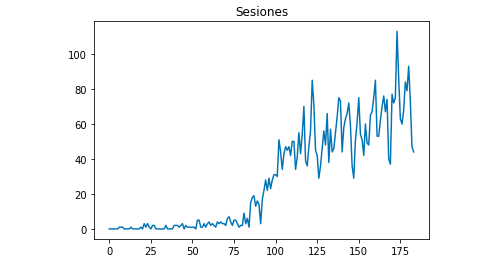
Usando a API do Google Analytics
Antes de tudo, para usar a API do Google Analytics, precisamos criar um projeto no console do desenvolvedor do Google, habilitar o serviço de relatórios do Google Analytics e obter as credenciais. Jean-Christophe Chouinard explica muito bem neste artigo como configurar isso.
Uma vez que as credenciais são obtidas, precisamos autenticar antes de fazer nossa solicitação. A autenticação precisa ser feita com o arquivo de credenciais que foi obtido inicialmente no console do desenvolvedor do Google. Também precisaremos anotar em nosso código o GA View ID da propriedade que gostaríamos de usar.
da compilação de importação apiclient.discovery
de oauth2client.service_account importar ServiceAccountCredentials
ESCOPOS = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
VISÃO_
credenciais = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES)
analytics = build('analyticsreporting', 'v4', credenciais=credencias)Após a autenticação, só precisamos fazer a solicitação. O que precisamos usar para obter os dados sobre as sessões orgânicas de cada dia é:
resposta = analytics.reports().batchGet(body={
'requestRequests': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'Métricas': [
{"expression": "ga:sessões"}
], "dimensões": [
{"name": "ga:data"}
],
"filtersExpression":"ga:channelGrouping=~Orgânico",
"includeEmptyRows": "true"
}]}).executar()Observe que selecionamos o intervalo de tempo em dateRanges. No meu caso, vou recuperar dados de 1º de setembro até 31 de janeiro: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
Depois disso, precisamos apenas buscar o arquivo de resposta para anexar a uma lista os dias com suas sessões orgânicas:
valores_lista = [] para x em resposta["reports"][0]["data"]["rows"]: list_values.append([x["dimensions"][0],x["metrics"][0]["values"][0]])
Como você pode ver, usar a API do Google Analytics é bastante simples e pode ser usado para muitos objetivos. Neste artigo, expliquei como você pode usar a API do Google Analytics para criar alertas para detectar páginas com baixo desempenho.

Adaptando as listas para Dataframes
Para usar o Prophet, precisamos inserir um Dataframe com duas colunas que precisam ser nomeadas: “ds” e “y”. Se você importou os dados de um arquivo Excel, já o temos como Dataframe, então você só precisará nomear as colunas “ds” e “y”:
df.columns = ['ds', 'y']
Caso você tenha feito uso da API para recuperar os dados, precisamos transformar a lista em um dataframe e nomear as colunas conforme necessário:
de pandas importar DataFrame df_sessions = DataFrame(list_values,columns=['ds','y'])
Treinando o modelo
Uma vez que tenhamos o Dataframe com o formato necessário, podemos determinar e treinar nosso modelo com muita facilidade com:
importar fbprophet de fbprophet import Profeta modelo = Profeta() model.fit(df_sessions)
Fazendo nossas previsões
Finalmente, após treinar nosso modelo, podemos começar a prever! Para prosseguir com as previsões, primeiro precisamos criar uma lista com o intervalo de tempo que gostaríamos de prever e ajustar o formato de data e hora:
da importação de pandas para_datetime previsão_dias = [] para x no intervalo (1, 28): data = "2021-02-" + str(x) forecast_days.append([data]) forecast_days = DataFrame(forecast_days) forecast_days.columns = ['ds'] forecast_days['ds']= to_datetime(forecast_days['ds'])
Neste exemplo eu uso um loop que irá criar um dataframe que conterá todos os dias de fevereiro. E agora é só usar o modelo que foi treinado anteriormente:
previsão = model.predict(forecast_days)
Podemos desenhar um gráfico destacando o período de tempo previsto:
do matplotlib importar pyplot model.plot(previsão) pyplot.show()
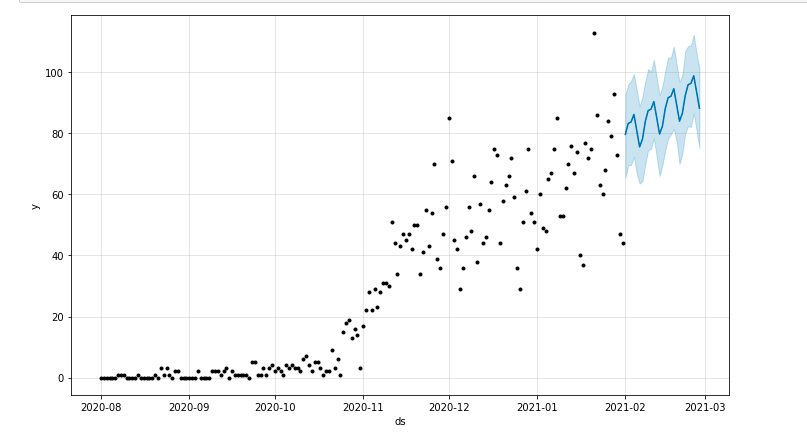
Avaliação do modelo
Finalmente, podemos avaliar a precisão do nosso modelo eliminando alguns dias dos dados que são usados para treinar o modelo, prevendo as sessões para esses dias e calculando o erro absoluto médio.
Como exemplo, o que vou fazer é eliminar do dataframe original os últimos 12 dias de janeiro, prevendo as sessões para cada dia e comparando o tráfego real com o previsto.
Primeiro, eliminamos do dataframe original os 12 últimos dias com pop e criamos um novo dataframe que incluirá apenas os 12 dias que serão usados para a previsão:
trem = df_sessions.drop(df_sessions.index[-12:]) future = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
Agora treinamos o modelo, fazemos a previsão e calculamos o erro médio absoluto. Ao final, podemos traçar um gráfico que mostrará a diferença entre os valores reais previstos e os reais. Isso é algo que aprendi com este artigo escrito por Jason Brownlee.
de sklearn.metrics importar mean_absolute_error
importar numpy como np
da matriz de importação numpy
#Treinamos o modelo
modelo = Profeta()
model.fit(trem)
#Adapte o dataframe usado para os dias de previsão para o formato exigido pelo Profeta.
futuro = lista(futuro)
futuro = DataFrame(futuro)
future = future.rename(columns={0: 'ds'})
# Fazemos a previsão
previsão = model.predict(futuro)
# Calculamos o MAE entre os valores reais e os valores previstos
y_true = df_sessions['y'][-12:].values
y_pred = previsão['yhat'].values
mae = mean_absolute_error(y_true, y_pred)
# Traçamos o resultado final para uma compreensão visual
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, label='Real')
pyplot.plot(y_pred, label='Previsto')
pyplot.legend()
pyplot.show()
print(mae) 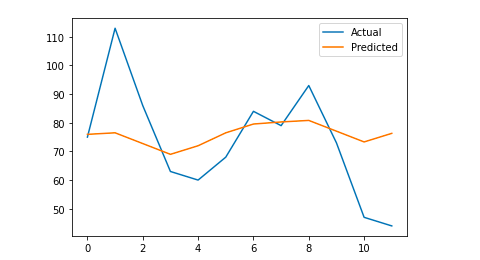
Meu erro absoluto médio é 13, o que significa que meu modelo previsto atribui a cada dia 13 sessões a mais do que as reais, o que parece ser um erro aceitável.
Isso é tudo, pessoal! Espero que você tenha achado este artigo interessante e possa começar a fazer suas previsões de SEO para definir metas.
Indo além: OnCrawl Labs
Se você gostou de prever seu tráfego com esse método, também estará interessado no OnCrawl Labs, o laboratório de ciência de dados e aprendizado de máquina do OnCrawl que oferece projetos pré-codificados para seus fluxos de trabalho de SEO.
Na previsão de SEO, o OnCrawl Labs ajudará você a refinar suas projeções de SEO:
- Obtenha uma melhor compreensão das teorias e do processo por trás do algoritmo Profeta do Facebook
- Analise um segmento de tráfego, como tráfego apenas em palavras-chave de cauda longa ou apenas palavras-chave de marca…
- Siga um processo passo a passo para configurar eventos históricos, ajustando sua influência e sua probabilidade de recorrência.