
Como extrair conteúdo de texto relevante de uma página HTML?
Publicados: 2021-10-13Contexto
No departamento de P&D da Oncrawl, buscamos cada vez mais agregar valor ao conteúdo semântico de suas páginas web. Utilizando modelos de aprendizado de máquina para processamento de linguagem natural (PLN), é possível realizar tarefas com real valor agregado para SEO.
Essas tarefas incluem atividades como:
- Ajustando o conteúdo de suas páginas
- Fazendo resumos automáticos
- Adicionando novas tags aos seus artigos ou corrigindo as existentes
- Otimizando o conteúdo de acordo com seus dados do Google Search Console
- etc.
O primeiro passo nesta aventura é extrair o conteúdo de texto das páginas da web que esses modelos de aprendizado de máquina usarão. Quando falamos de páginas web, isso inclui o HTML, JavaScript, menus, mídia, cabeçalho, rodapé, … Extrair conteúdo de forma automática e correta não é fácil. Através deste artigo, proponho explorar o problema e discutir algumas ferramentas e recomendações para realizar esta tarefa.
Problema
Extrair conteúdo de texto de uma página da web pode parecer simples. Com algumas linhas de Python, por exemplo, algumas expressões regulares (regexp), uma biblioteca de análise como BeautifulSoup4, e pronto.
Se você ignorar por alguns minutos o fato de que mais e mais sites usam mecanismos de renderização JavaScript como Vue.js ou React, analisar HTML não é muito complicado. Se você deseja contornar esse problema aproveitando nosso rastreador JS em seus rastreamentos, sugiro que leia “Como rastrear um site em JavaScript?”.
No entanto, queremos extrair um texto que faça sentido, que seja o mais informativo possível. Quando você lê um artigo sobre o último álbum póstumo de John Coltrane, por exemplo, você ignora os menus, o rodapé, … e obviamente, você não está visualizando todo o conteúdo HTML. Esses elementos HTML que aparecem em quase todas as suas páginas são chamados de clichê. Queremos nos livrar dele e manter apenas uma parte: o texto que traz informações relevantes.
Portanto, é apenas este texto que queremos passar para os modelos de aprendizado de máquina para processamento. Por isso é fundamental que a extração seja a mais qualitativa possível.
Soluções
No geral, gostaríamos de nos livrar de tudo o que “permanece” no texto principal: menus e outras barras laterais, elementos de contato, links de rodapé, etc. Existem vários métodos para fazer isso. Estamos principalmente interessados em projetos Open Source em Python ou JavaScript.
jusText
jusText é uma implementação proposta em Python a partir de uma tese de doutorado: “Removing Boilerplate and Duplicate Content from Web Corpora”. O método permite que blocos de texto de HTML sejam categorizados como “bons”, “ruins”, “muito curtos” de acordo com diferentes heurísticas. Essas heurísticas são baseadas principalmente no número de palavras, na proporção texto/código, na presença ou ausência de links, etc. Você pode ler mais sobre o algoritmo na documentação.
trafilatura
O trafilatura, também criado em Python, oferece heurísticas sobre o tipo de elemento HTML e seu conteúdo, por exemplo, comprimento do texto, posição/profundidade do elemento no HTML ou contagem de palavras. A trafilatura também utiliza o jusText para realizar alguns processamentos.
legibilidade
Você já notou o botão na barra de URL do Firefox? É o Reader View: permite remover o clichê das páginas HTML para manter apenas o conteúdo do texto principal. Bastante prático para usar em sites de notícias. O código por trás desse recurso é escrito em JavaScript e é chamado de legibilidade pela Mozilla. É baseado no trabalho iniciado pelo laboratório Arc90.
Aqui está um exemplo de como renderizar esse recurso para um artigo do site France Musique. 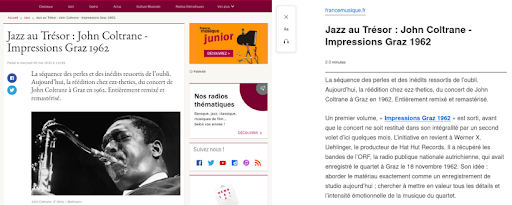
À esquerda, é um extrato do artigo original. À direita, é uma renderização do recurso Reader View no Firefox.
Outros
Nossa pesquisa sobre ferramentas de extração de conteúdo HTML também nos levou a considerar outras ferramentas:
- jornal: uma biblioteca de extração de conteúdo bastante dedicada a sites de notícias (Python). Esta biblioteca foi usada para extrair o conteúdo do corpus OpenWebText2.
- caldeirapy3 é uma porta Python da biblioteca boilerpipe.
- biblioteca dragnet Python também inspirada no boilerpipe.
Dados de rastreamento³
 Saber mais
Saber maisAvaliação e recomendações
Antes de avaliar e comparar as diferentes ferramentas, queríamos saber se a comunidade de PNL utiliza algumas dessas ferramentas para preparar seu corpus (grande conjunto de documentos). Por exemplo, o conjunto de dados chamado The Pile usado para treinar GPT-Neo tem +800 GB de textos em inglês da Wikipedia, Openwebtext2, Github, CommonCrawl, etc. Assim como o BERT, o GPT-Neo é um modelo de linguagem que usa transformadores de tipo. Ele oferece uma implementação de código aberto semelhante à arquitetura GPT-3.

O artigo “The Pile: An 800GB Dataset of Diverse Text for Language Modeling” menciona o uso de jusText para grande parte de seu corpus do CommonCrawl. Este grupo de pesquisadores também tinha planejado fazer um benchmark das diferentes ferramentas de extração. Infelizmente, eles não conseguiram fazer o trabalho planejado devido à falta de recursos. Em suas conclusões, deve-se notar que:
- O jusText às vezes removia muito conteúdo, mas ainda oferecia boa qualidade. Dada a quantidade de dados que eles tinham, isso não era um problema para eles.
- trafilatura foi melhor em preservar a estrutura da página HTML, mas manteve muito clichê.
Para nosso método de avaliação, levamos cerca de trinta páginas da web. Extraímos o conteúdo principal “manualmente”. Em seguida, comparamos a extração de texto das diferentes ferramentas com esse conteúdo chamado de “referência”. Usamos a pontuação ROUGE, que é usada principalmente para avaliar resumos de texto automáticos, como métrica.
Também comparamos essas ferramentas com uma ferramenta “feita em casa” baseada em regras de análise de HTML. Acontece que trafilatura, jusText e nossa ferramenta caseira se saem melhor do que a maioria das outras ferramentas para essa métrica.
Aqui está uma tabela de médias e desvios padrão da pontuação ROUGE:
| Ferramentas | Significa | Padrão |
|---|---|---|
| trafilatura | 0,783 | 0,28 |
| Oncrawl | 0,779 | 0,28 |
| jusText | 0,735 | 0,33 |
| caldeirada3 | 0,698 | 0,36 |
| legibilidade | 0,681 | 0,34 |
| rede de arrasto | 0,672 | 0,37 |
Tendo em vista os valores dos desvios padrão, observe que a qualidade da extração pode variar muito. A forma como o HTML é implementado, a consistência das tags e o uso adequado da linguagem podem causar muita variação nos resultados da extração.
As três ferramentas com melhor desempenho são trafilatura, nossa ferramenta interna chamada “oncrawl” para a ocasião e jusText. Como o jusText é usado como substituto da trafilatura, decidimos usar a trafilatura como nossa primeira escolha. No entanto, quando o último falha e extrai zero palavras, usamos nossas próprias regras.
Observe que o código da trafilatura também oferece um benchmark em várias centenas de páginas. Ele calcula pontuações de precisão, pontuação f1 e precisão com base na presença ou ausência de determinados elementos no conteúdo extraído. Duas ferramentas se destacam: trafilatura e goose3. Você também pode querer ler:
- Escolhendo a ferramenta certa para extrair conteúdo da Web (2020)
- o repositório Github: benchmark de extração de artigos: bibliotecas de código aberto e serviços comerciais
Conclusões
A qualidade do código HTML e a heterogeneidade do tipo de página dificultam a extração de conteúdo de qualidade. Como os pesquisadores da EleutherAI – que estão por trás do The Pile e do GPT-Neo – descobriram, não existem ferramentas perfeitas. Há uma compensação entre o conteúdo às vezes truncado e o ruído residual no texto quando nem todo o clichê foi removido.
A vantagem dessas ferramentas é que elas são livres de contexto. Isso significa que eles não precisam de nenhum dado além do HTML de uma página para extrair o conteúdo. Utilizando os resultados do Oncrawl, poderíamos imaginar um método híbrido utilizando as frequências de ocorrência de determinados blocos HTML em todas as páginas do site para classificá-los como clichê.
Quanto aos conjuntos de dados usados nos benchmarks que encontramos na Web, eles geralmente são do mesmo tipo de página: artigos de notícias ou postagens de blog. Não incluem necessariamente sites de seguros, agências de viagens, e-commerce, etc., onde o conteúdo do texto às vezes é mais complicado de extrair.
No que diz respeito ao nosso benchmark e por falta de recursos, sabemos que cerca de trinta páginas não são suficientes para obter uma visão mais detalhada das pontuações. Idealmente, gostaríamos de ter um número maior de páginas da web diferentes para refinar nossos valores de referência. E também gostaríamos de incluir outras ferramentas como goose3, html_text ou inscriptis.