
Extraia dados da API do Google Search Console para análise de dados em Python
Publicados: 2022-03-01O Google Search Console (GSC) é definitivamente uma das ferramentas mais úteis para especialistas em SEO, pois permite obter informações sobre a cobertura do índice e principalmente as consultas para as quais você está classificando atualmente. Sabendo disso, muita gente analisa os dados do GSC usando planilhas e tudo bem, desde que você entenda que há muito mais espaço para melhorias com ferramentas como linguagens de programação.
Infelizmente, a interface do GSC é bastante limitada em termos de linhas exibidas (apenas 5.000) e período de tempo disponível, apenas 16 meses. É claro que isso pode limitar severamente sua capacidade de obter insights e não é adequado para sites maiores.
O Python permite que você obtenha dados GSC com facilidade e automatize cálculos mais complexos que exigiriam muito mais esforço em softwares de planilhas tradicionais.
Esta é a solução para um dos maiores problemas do Excel, ou seja, limite de linhas e velocidade. Hoje em dia, você tem muito mais alternativas para analisar dados do que antes e é aí que o Python entra em ação.
Você não precisa de nenhum conhecimento avançado de codificação para seguir este tutorial, apenas a compreensão de alguns conceitos básicos e alguma prática com o Google Colab.
Introdução à API do Google Search Console
Antes de começarmos, é importante configurar a API do Google Search Console. O processo é bem simples, tudo que você precisa é de uma conta do Google. Os passos são os seguintes:
- Crie um novo projeto no Google Cloud Platform. Você deve ter uma conta do Google e tenho certeza que você tem uma. Vá para o console e, em seguida, você deve encontrar uma opção na parte superior para criar um novo projeto.
- Clique no menu à esquerda e selecione “API e serviços”, você chegará a outra tela.
- Na barra de pesquisa na parte superior, procure "API do Google Search Console" e ative-a.
- Em seguida, vá para a guia “Credenciais”, você precisa de algum tipo de permissão para usar a API.
- Configure a tela de “consentimento”, pois isso é obrigatório. Não importa para o uso que vamos fazer se é público ou não.
- Você pode escolher "Desktop App" para o tipo de aplicativo
- Usaremos o OAuth 2.0 para este tutorial, você deve baixar um arquivo json e pronto.
Na verdade, essa é a parte mais difícil para a maioria das pessoas, especialmente para quem não está acostumado com as APIs do Google. Não se preocupe, os próximos passos serão muito mais fáceis e menos problemáticos.
Obtendo dados da API do Google Search Console com Python
Minha recomendação é que você use um notebook como Jupyter Notebook ou Google Colab. O último é melhor, pois você não precisa se preocupar com os requisitos. Portanto, o que vou explicar é baseado no Google Colab.
Antes de começarmos, atualize seu arquivo json para o Google Colab com o seguinte código:
dos arquivos de importação do google.colab arquivos.upload()
Então, vamos instalar todas as bibliotecas que precisaremos para nossa análise e vamos fazer uma melhor visualização da tabela com este trecho de código:
%%capturar #carregue o que for necessário !pip install git+https://github.com/joshcarty/google-searchconsole importar pandas como pd importar numpy como np importar matplotlib.pyplot como plt do google.colab importar data_table !git clone https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip instala umap-learn data_table.enable_dataframe_formatter() #para melhor visualização da tabela
Finalmente, você pode carregar a biblioteca searchconsole, que oferece a maneira mais fácil de fazer isso sem depender de funções longas. Execute o código a seguir com os argumentos que estou usando e certifique-se de que client_config tenha o mesmo nome do arquivo json carregado.
importar console de pesquisa conta = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
Você será redirecionado para uma página do Google para autorizar o aplicativo, selecione sua conta do Google e, em seguida, copie e cole o código que você receberá na barra do Google Colab.
Ainda não terminamos, você deve selecionar a propriedade para a qual precisará de dados. Você pode verificar facilmente suas propriedades em account.webproperties para ver o que deve escolher.
property_name = input('Insira o nome do seu site conforme listado no GSC: ')
webproperty=account[str(property_name)]
Quando terminar, você executará uma função personalizada para criar um objeto contendo nossos dados.
def extract_gsc_data(webproperty, start, stop, *args):
se a propriedade da web não for Nenhum:
print(f'Extraindo dados para {webproperty}')
gsc_data = webproperty.query.range(iniciar, parar).dimension(*args).get()
retornar gsc_data
senão:
print('Propriedade da Web não encontrada, selecione a correta')
retornar Nenhum
A ideia da função é pegar a propriedade que você definiu antes e um período de tempo, na forma de datas de início e término, junto com as dimensões.
A escolha de poder selecionar dimensões é crucial para especialistas em SEO, pois permite entender se você precisa de um certo nível de granularidade. Por exemplo, você pode não estar interessado em obter a dimensão de data, em alguns casos.
Minha sugestão é sempre escolher a consulta e a página, pois a interface do Google Search Console pode exportá-los separadamente e é muito chato mesclá-los sempre. Esse é outro benefício da API do Search Console.
No nosso caso, também podemos obter diretamente a dimensão da data, para mostrar alguns cenários interessantes em que você precisa levar em consideração o tempo.
ex = extract_gsc_data(webproperty, '2021-09-01', '2021-12-31', 'consulta', 'página', 'data')
Selecione um prazo adequado, considerando que para propriedades maiores você precisará esperar muito tempo. Para este exemplo, estou considerando apenas um período de 3 meses, o que é suficiente para obter informações valiosas da maioria dos conjuntos de dados, em média.
Você pode selecionar até uma semana se estiver lidando com uma grande quantidade de dados, o que nos importa é o processo.
O que vou mostrar aqui é baseado em dados sintéticos ou dados reais modificados para servir de exemplo. Como consequência, o que você vê aqui é totalmente realista e pode refletir cenários do mundo real.
Limpeza de dados
Para quem não sabe, não podemos usar nossos dados como estão, existem algumas etapas extras para garantir que estamos funcionando corretamente. Antes de tudo, temos que converter nosso objeto em um dataframe Pandas, uma estrutura de dados com a qual você deve estar familiarizado, pois é a base da análise de dados em Python.
df = pd.DataFrame(data=ex) df.head()
O método head pode mostrar as primeiras 5 linhas do seu conjunto de dados, é muito útil dar uma olhada na aparência dos seus dados. Podemos contar quantas páginas temos usando uma função simples.
Uma boa maneira de remover duplicatas é converter um objeto em um conjunto, pois conjuntos não podem conter elementos duplicados.
Alguns dos trechos de código foram inspirados no caderno de Hamlet Batista e outro de Masaki Okazawa.
Removendo termos de marca
A primeira coisa a fazer é remover palavras-chave de marca, estamos procurando as consultas que não contêm nossos termos de marca. Isso é bastante simples de fazer com uma função personalizada e geralmente você terá um conjunto de termos de marca.
Para fins demonstrativos, você não precisa filtrar todos eles, mas faça isso para análises reais. É uma das etapas de limpeza de dados mais importantes em SEO, caso contrário você corre o risco de apresentar resultados enganosos.
domain_name = str(input('Inserir termos de marca separados por vírgula: ')).replace(',', '|')
importar re
domain_name = re.sub(r"\s+", "", domain_name)
print('Remova todos os espaços usando RegEx:\n')
df['Marca/Sem marca'] = np.where(
df['query'].str.contains(domain_name), 'Brand', 'Sem marca'
)
Vamos adicionar uma nova coluna ao nosso conjunto de dados para reconhecer a diferença entre as duas classes. Podemos visualizar através de tabelas ou barplots o quanto elas representam o número total de consultas.
Não vou mostrar o barplot porque é muito simples e acho que uma tabela é melhor para este caso.
brand_count_df = df['Marca/Sem marca'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Percentage'] = brand_count_df['counts']/sum(brand_count_df['counts'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
Você pode ver rapidamente qual é a proporção entre palavras-chave de marca e sem marca para ter uma ideia de quanto você vai remover do seu conjunto de dados. Não existe uma proporção ideal aqui, embora você definitivamente queira ter uma porcentagem maior de palavras-chave sem marca.
Em seguida, podemos simplesmente descartar todas as linhas marcadas como com marca e prosseguir com outras etapas.
#apenas selecione palavras-chave sem marca df = df.loc[df['Marca/Sem marca'] == 'Sem marca']
Preenchendo valores ausentes e outras etapas
Se o seu conjunto de dados apresentar valores ausentes (ou NAs no jargão), você terá várias opções. Os mais comuns são descartar todos ou preenchê-los com um valor de espaço reservado como 0 ou a média dessa coluna.
Não existe uma resposta correta e ambas as abordagens têm seus prós e contras, além de riscos. Para dados do Google Search Console, meu melhor conselho é colocar um valor de espaço reservado como 0, para subestimar o efeito de algumas métricas.
df.fillna(0, inplace = True)
Antes de passarmos para a análise de dados real, precisamos ajustar nossos recursos, ou seja, as colunas do nosso conjunto de dados. A posição é especialmente interessante, pois queremos usá-la para algumas tabelas dinâmicas legais.
Podemos arredondar a posição para um número inteiro, o que serve ao nosso propósito.
df['position'] = df['position'].round(0).astype('int64')
Você deve seguir todas as outras etapas de limpeza descritas acima e depois ajustar a coluna de data.
Estamos extraindo meses e anos com a ajuda de pandas. Você não precisa ser tão específico se estiver trabalhando com um prazo menor, este é um exemplo que leva em consideração meio ano.
#converter data para o formato adequado df['date'] = pd.to_datetime(df['date']) #extrair meses df['mês'] = df['data'].dt.mês #extrair anos df['ano'] = df['data'].dt.ano
[Ebook] SEO de dados: a próxima grande aventura
 Leia o e-book
Leia o e-bookAnálise exploratória de dados
A principal vantagem do Python é que você pode fazer as mesmas coisas que faz no Excel, mas com muito mais opções e mais fácil. Vamos começar com algo que todo analista conhece muito bem: tabelas dinâmicas.
Analisando a CTR média por grupo de posições
Analisando a média A CTR por grupo de posições é uma das atividades mais perspicazes, pois permite entender a situação geral de um site. Aplique o pivô e então vamos plotá-lo.
pd.options.display.float_format = '{:.2%}'.format
query_analysis = df.pivot_table(index=['position'], values=['ctr'], aggfunc=['mean'])
query_analysis.sort_values(by=['position'], ascendente=True).head(10)
ax = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('Posição média')
ax.set_ylabel('CTR')
ax.set_title('CTR por posição média')
ax.grid('ligado')
ax.get_legend().remove()
plt.xticks(rotação=0)
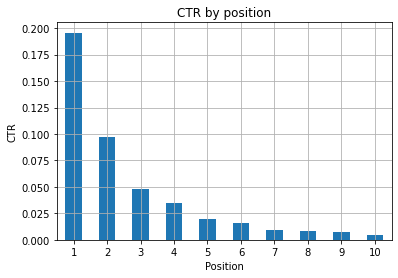
Figura 1: Representando a CTR por posição para detectar anomalias.
O cenário ideal aqui é ter uma CTR melhor no lado esquerdo do gráfico, pois normalmente os resultados na Posição 1 devem apresentar uma CTR muito maior. Tenha cuidado, porém, você pode ver alguns casos em que os 3 primeiros pontos têm uma CTR menor do que o esperado e você precisa investigar.
Por favor, considere também os casos extremos, por exemplo, aqueles em que a posição 11 é melhor do que ser o primeiro. Conforme explicado na documentação do Google para o Search Console, essa métrica não segue a ordem que você pode pensar a princípio.
Além disso, acrescenta que essa métrica é uma média, pois a posição do link muda a cada vez e é impossível ter 100% de precisão.
Às vezes, suas páginas têm uma classificação alta, mas não são convincentes o suficiente, então você pode tentar corrigir o título. Como esta é uma visão geral de alto nível, você não verá diferenças granulares, portanto, espere agir rapidamente se esse problema for em grande escala.
Fique atento também quando um grupo de páginas em posições mais baixas tem uma CTR média mais alta do que aquelas em lugares melhores.
Por esta razão, você pode querer estender sua análise até a posição 15 ou mais, para detectar padrões estranhos.
Contagem de consultas por posição e medição dos esforços de SEO
Um aumento nas consultas para as quais você está classificando é sempre um bom sinal, mas não significa necessariamente melhores classificações no futuro. A contagem de consultas é o processo de contar o número de consultas para as quais você está classificando e é uma das tarefas mais importantes que você pode fazer com os dados do GSC.
As tabelas dinâmicas são uma grande ajuda mais uma vez, e podemos plotar os resultados.
ranking_queries = df.pivot_table(index=['position'], values=['query'], aggfunc=['count']) ranking_queries.sort_values(by=['position']).head(10)
O que você quer como especialista em SEO é ter uma contagem de consultas mais alta no lado esquerdo, os primeiros lugares. A razão é bastante natural, posições altas obtêm melhores CTRs em média, o que pode se traduzir em mais pessoas clicando em sua página.
ax = ranking_queries.head(10).plot(kind='bar')
ax.set_ylabel('Contagem de consultas')
ax.set_xlabel('Posição')
ax.set_title('Distribuição de classificação')
ax.grid('ligado')
ax.get_legend().remove()
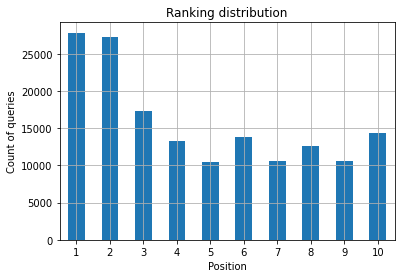
Figura 2: Quantas consultas tenho por posição?
O que importa é aumentar a contagem de consultas nas primeiras posições com o passar do tempo.
Brincando com a dimensão de data
Vamos ver como os cliques variam em um intervalo de tempo considerado, primeiro vamos obter a soma dos cliques:
clicks_sum = df.groupby('date')['clicks'].sum()
Estamos agrupando os dados por dimensão de data e obtendo a soma dos cliques de cada um deles, é um tipo de sumarização.
Agora estamos prontos para plotar o que obtivemos, o código será bem longo apenas para melhorar a visualização, não se assuste com isso.

# Soma de cliques no período
%config InlineBackend.figure_format = 'retina'
da figura de importação matplotlib.pyplot
figura(tamanho=(8, 6), dpi=80)
ax = clicks_sum.plot(color='vermelho')
ax.grid('ligado')
ax.set_ylabel('Soma de cliques')
ax.set_xlabel('Mês')
ax.set_title('Como os cliques variam mensalmente')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('italic')
xlab.set_size(10)
ylab.set_style('italic')
ylab.set_size(10)
ttl = ax.title
ttl.set_weight('negrito')
ax.spines['right'].set_color((.8,.8,.8))
ax.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='yellow')
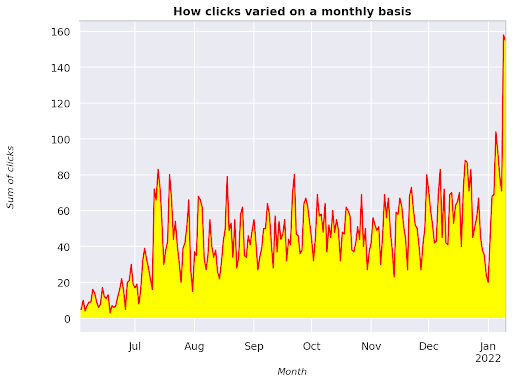
Figura 3: Plotando a soma dos cliques em relação à variável mês
Este é um exemplo a partir de junho de 2021 e indo direto para metade de janeiro de 2022. Todas as linhas que você está vendo acima têm o papel de deixar essa visualização mais bonita, você pode tentar brincar com ela para ver o que acontece.
Contagem de consultas por posição, instantâneo mensal
Outra visualização legal que podemos plotar em Python é o mapa de calor, que é ainda mais visual do que um simples barplot. Vou mostrar como exibir a contagem de consultas ao longo do tempo e de acordo com sua posição.
importar seaborn como sns sns.set_theme() df_new = df.loc[(df['position'] <= 10) & (df['year'] != 2022),:] # Carregue o conjunto de dados de voos de exemplo e converta para formato longo df_heat = df_new.pivot_table(index = "position", columns = "month", values = "query", aggfunc='count') # Desenha um mapa de calor com os valores numéricos em cada célula f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = ["Setembro", "Outubro", "Novembro", "Dezembro"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Mês', ylabel='Posição', title = 'Como a contagem de consultas por posição muda com o tempo') #rotate Posicione os rótulos para torná-los mais legíveis plt.yticks(rotação=0)
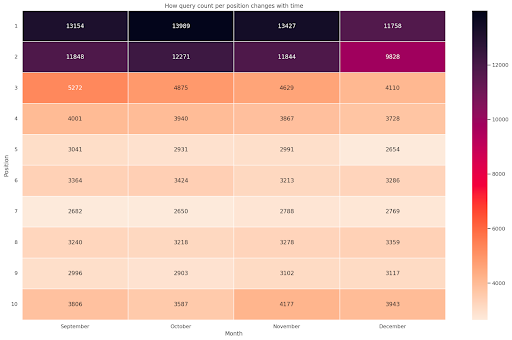
Figura 4: Mapa de calor mostrando o progresso da contagem de consultas de acordo com a posição e o mês.
Este é um dos meus favoritos, os mapas de calor podem ser bastante eficazes para exibir tabelas dinâmicas, como neste exemplo. O período abrange mais de 4 meses e, se você o ler horizontalmente, poderá ver como a contagem de consultas muda com o passar do tempo. Para a posição 10 você tem um pequeno aumento de setembro a dezembro, mas para a posição 2 você tem uma queda marcante, como mostra a cor roxa.
No cenário a seguir, você tem a maioria das consultas nos primeiros lugares, o que pode ser surpreendentemente incomum. Se isso acontecer, convém voltar e analisar o dataframe, procurando possíveis termos de marca, se houver.
Como você vê no código, não é tão difícil fazer gráficos complexos, desde que você tenha a lógica por trás.
A contagem de consultas deve aumentar com o tempo se você estiver fazendo as coisas “certas” e pudermos traçar a diferença em dois prazos diferentes. No exemplo que forneci, claramente não é o caso, especialmente para as primeiras posições, onde você deveria ter uma CTR mais alta.
Apresentando alguns conceitos básicos de PNL
Processamento de linguagem natural (NLP) é uma dádiva de Deus para SEO e você não precisa ser um especialista para aplicar os algoritmos básicos. N-grams são uma das ideias mais poderosas, mas simples, que podem fornecer insights com dados do GSC.
N-gramas são sequências contíguas de letras, sílabas ou palavras. Para nossa análise, as palavras serão a unidade de medida. Um n-grama é chamado bigrama quando os elementos adjacentes são dois (um par) e trigrama se são três, e assim por diante. Sugiro que você teste com diferentes combinações e vá até 5 gramas no máximo.
Dessa forma, você consegue identificar as frases mais comuns nas páginas de seus concorrentes ou avaliar as suas. Como o Google pode contar com indexação baseada em frases, é melhor otimizar para frases em vez de palavras-chave individuais, conforme mostrado pelas patentes do Google envolvendo esse tópico.
Conforme declarado na página acima pelo próprio Bill Slawski, o valor de entender os termos relacionados é de grande valor para a otimização e para seus usuários.
A biblioteca nltk é muito famosa por aplicativos de PNL e nos dá a possibilidade de remover palavras de parada em um determinado idioma, como o inglês. Pense neles como ruídos que você deseja remover, de fato, artigos e palavras muito frequentes não agregam valor algum na compreensão de um texto.
importar nltk
nltk.download('stopwords')
de palavras irrelevantes de importação nltk.corpus
stoplist = stopwords.words('inglês')
de sklearn.feature_extraction.text import CountVectorizer
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
# matriz de nggramas
ngrams = c_vec.fit_transform(df['query'])
# contagem de frequência de nggramas
count_values = ngrams.toarray().sum(axis=0)
# lista de nggramas
vocab = c_vec.vocabulary_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
).rename(columns={0: 'frequência', 1:'bigrama/trigrama'})
df_ngram.head(20).style.background_gradient()
Pegamos a coluna de consulta e contamos a frequência de bigramas para criar um dataframe armazenando bigramas e seu número de ocorrências.
Esta etapa é realmente muito importante para analisar os sites dos concorrentes também. Você pode simplesmente raspar o texto e verificar quais são os n-grams mais comuns, ajustando o n a cada vez para ver se você identifica padrões diferentes nas páginas de alto nível.
Se você pensar sobre isso por um segundo, faz muito mais sentido, pois uma palavra-chave individual não diz nada sobre o contexto.
Frutas baixas
Uma das coisas mais bonitas a se fazer é checar as frutas mais baixas, aquelas páginas que você pode melhorar facilmente para ver bons resultados o mais cedo possível. Isso é crucial nos primeiros passos de cada projeto de SEO para convencer seus stakeholders. Portanto, se houver uma oportunidade de alavancar essas páginas, faça-o!
Nossos critérios para considerar uma página como tal são quantis de impressões e CTR. Em outras palavras, estamos filtrando as linhas que ficam entre os 80% principais das impressões, mas estão entre os 20% que recebem a CTR mais baixa. Essas linhas terão uma CTR pior do que 80% do restante.
top_impressions = df[df['impressions'] >= df['impressions'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('impressions', ascendente = False))
Agora você tem uma lista com todas as oportunidades classificadas por Impressões, em ordem decrescente.
Você pode pensar em outros critérios para definir o que é uma fruta de baixo custo, de acordo com as necessidades do seu site e seu tamanho.
Para sites menores, você pode considerar procurar por porcentagens mais altas, enquanto em sites grandes você já deve obter muitas informações com os critérios que estou usando.
[Ebook] SEO técnico para pensadores não técnicos
 Leia o e-book
Leia o e-bookApresentando o querycat: classificação e associações
O Querycat é uma biblioteca simples, porém poderosa, que apresenta mineração de regras de associação para palavras-chave de cluster e muito mais. Vou mostrar apenas as associações, pois elas são mais valiosas nesse tipo de análise.
Você pode aprender mais sobre essa biblioteca incrível dando uma olhada no repositório querycat GitHub.
Breve introdução sobre o aprendizado de regras de associação
O aprendizado de regras de associação é um método para encontrar regras que definem associações e coocorrências em conjuntos de itens. Isso é um pouco diferente de outro método de aprendizado de máquina não supervisionado, o chamado clustering.
O objetivo final é o mesmo, obter clusters de palavras-chave para entender como nosso site está se saindo em alguns tópicos.
O Querycat oferece a possibilidade de escolher entre dois algoritmos: Apriori e FP-Growth. Vamos escolher o último para melhores performances, então você pode ignorar o primeiro.
FP-Growth é uma versão melhorada do Apriori para encontrar padrões frequentes em conjuntos de dados. O aprendizado de regras de associação também é muito útil para transações de comércio eletrônico, você pode estar interessado em entender o que as pessoas compram juntas, por exemplo.
Nesse caso nosso foco é todo em consultas, mas o outro aplicativo que mencionei pode ser outra ideia útil para dados do Google Analytics.
Explicar esses algoritmos de uma perspectiva de estrutura de dados é bastante desafiador e, na minha opinião, não é necessário para suas tarefas de SEO. Vou apenas explicar alguns conceitos básicos para entender o que os parâmetros significam.
Os 3 elementos principais dos 2 algoritmos são:
- Suporte – Expressa a popularidade de um item ou conjunto de itens. Em palavras técnicas, é o número de transações em que a consulta X e a consulta Y aparecem juntas dividido pelo número total de transações.
Além disso, pode ser usado como limite para remover itens infrequentes. Muito útil para aumentar a significância estatística e o desempenho. Definir um bom suporte mínimo é muito bom. - Confiança – você pode pensar nisso como a probabilidade de co-ocorrência de termos.
- Elevação – A razão entre o suporte para (termo 1 e termo 2) e o suporte do termo 1. Podemos observar seu valor para obter insights sobre a relação entre os termos. Se maior que 1 os termos são correlacionados; se for menor que 1, é improvável que os termos tenham uma associação: se o elevador for exatamente 1 (ou próximo), não há relação significativa.
Mais detalhes são fornecidos neste artigo sobre o querycat escrito pelo autor da biblioteca.
Agora estamos prontos para passar para a parte prática.
importar gato de consulta
query_cat = querycat.Categorize(df, 'query', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', ascendente=False)
#criar grupo para filtrar categorias com menos de 15 cliques (número arbitrário)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
grupo de filtros
#aplicar filtro
df = df.merge(filtergroup, on=['category','category'], how='inner')
Filtramos categorias menos frequentes no processo, escolhi 15 como referência no meu caso. É apenas um número arbitrário, não há critério por trás disso.
Vamos verificar nossas categorias com o seguinte trecho:
df['category'].value_counts()
E as 10 categorias mais clicadas? Vamos verificar quantas consultas temos para cada um deles.
df.groupby('category').sum()['clicks'].sort_values(ascending=False).head(10)
O número a ser escolhido é arbitrário, certifique-se de escolher um que filtre uma boa porcentagem de grupos. Uma ideia em potencial é obter a mediana das impressões e diminuir os 50% mais baixos, desde que você queira excluir pequenos grupos.
Obtendo clusters e o que fazer com a saída
Minha recomendação é exportar seu novo dataframe para evitar executar o FP-Growth novamente, faça isso para economizar tempo útil.
Assim que tiver clusters, você deseja saber os cliques e as impressões de cada um deles para avaliar quais áreas precisam de mais melhorias.
grouped_df = df.groupby('category')[['clicks', 'impressions']].agg('sum')
Com alguma manipulação de dados conseguimos melhorar nossos resultados de associação e ter cliques e impressões para cada cluster.
group_ex = df.groupby(['category'])['query'].apply(' | '.join).reset_index()
#remover consultas duplicadas e classificá-las em ordem alfabética
group_ex['query'] = group_ex['query'].apply(lambda x: ' | '.join(sorted(list(set(x.split('|')))))))
df_final = group_ex.merge(grouped_df, on=['category', 'category'], how='inner')
df_final.head()
Agora você tem um arquivo CSV com todos os seus clusters de palavras-chave junto com cliques e impressões.
#save o arquivo csv e baixe-o para sua máquina local. Se você usa o Safari, considere mudar para o Chrome para baixar esses arquivos, pois pode não funcionar.
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
Na verdade, existem métodos melhores para clustering, este é apenas um exemplo de como você pode usar o querycat para executar várias tarefas para uso imediato. O principal objetivo aqui é obter o máximo de insights possível, especialmente para novos sites onde você não tem tanto conhecimento.
No momento, as melhores abordagens envolvem semântica, portanto, se você quiser se concentrar no agrupamento, sugiro que considere aprender gráficos ou embeddings.
No entanto, esses são tópicos avançados se você é iniciante e pode simplesmente experimentar alguns aplicativos Streamlit pré-criados disponíveis online.
Dados de rastreamento³
 Saber mais
Saber maisConclusão e o que vem a seguir
O Python pode oferecer uma grande ajuda na análise do seu site e pode ajudá-lo a combinar limpeza, visualização e análise de dados em um único local. A extração de dados da API GSC é definitivamente necessária para tarefas mais avançadas e é uma introdução “suave” à automação de dados.
Embora você possa fazer muitos cálculos mais avançados com o Python, minha recomendação é verificar o que faz sentido em termos de valor de SEO.
Por exemplo, a contagem de consultas é muito mais importante como um todo a longo prazo, pois você deseja que seu site seja considerado para mais consultas.
Usar notebooks é uma grande ajuda para empacotar código com comentários e esta é a principal razão pela qual sugiro que você se acostume com o Google Colab.
Este é apenas o começo do que a análise de dados pode oferecer a você, pois as melhores ideias vêm da mesclagem de diferentes conjuntos de dados.
O Google Search Console é uma ferramenta poderosa e totalmente gratuita, a quantidade de informações práticas que você pode obter dele é quase ilimitada em boas mãos.