
Significado estatístico do teste A/B: como e quando terminar um teste
Publicados: 2020-05-22
Em nossa análise recente de 28.304 experimentos executados por clientes do Convert, descobrimos que apenas 20% dos experimentos atingem o nível de significância estatística de 95%. A Econsultancy descobriu uma tendência semelhante em seu relatório de otimização de 2018. Dois terços de seus entrevistados veem um “vencedor claro e estatisticamente significativo” em apenas 30% ou menos de seus experimentos.
Portanto, a maioria dos experimentos (70-80%) são inconclusivos ou interrompidos cedo.
Destes, os que foram interrompidos cedo são um caso curioso, pois os otimizadores atendem à chamada para encerrar os experimentos quando consideram apropriado. Eles fazem isso quando podem “ver” um claro vencedor (ou perdedor) ou um teste claramente insignificante. Normalmente, eles também têm alguns dados para justificá-lo.
Isso pode não parecer tão surpreendente, já que 50% dos otimizadores não têm um “ponto de parada” padrão para seus experimentos. Para a maioria, isso é uma necessidade, graças à pressão de ter que manter uma certa velocidade de teste (XXX testes/mês) e a corrida para dominar sua competição.
Depois, há também a possibilidade de um experimento negativo prejudicar a receita. Nossa própria pesquisa mostrou que experimentos não vencedores, em média, podem causar uma redução de 26% na taxa de conversão !
Dito isso, encerrar os experimentos cedo ainda é arriscado…
… porque deixa a probabilidade de que, se o experimento tivesse a duração pretendida, alimentado pelo tamanho certo da amostra, seu resultado poderia ter sido diferente.
Então, como as equipes que encerram os experimentos antecipadamente sabem quando é hora de terminá-los? Para a maioria, a resposta está em criar regras de parada que agilizem a tomada de decisão, sem comprometer sua qualidade.
Afastando-se das regras de parada tradicionais
Para experimentos na web, um valor p de 0,05 serve como padrão. Essa tolerância de erro de 5% ou o nível de significância estatística de 95% ajuda os otimizadores a manter a integridade de seus testes. Eles podem garantir que os resultados sejam resultados reais e não por acaso.
Em modelos estatísticos tradicionais para testes de horizonte fixo — em que os dados de teste são avaliados apenas uma vez em um horário fixo ou em um número específico de usuários engajados — você aceitará um resultado como significativo quando tiver um valor p inferior a 0,05. Neste ponto, você pode rejeitar a hipótese nula de que seu controle e tratamento são os mesmos e que os resultados observados não são por acaso.
Ao contrário dos modelos estatísticos que fornecem a possibilidade de avaliar seus dados à medida que eles são coletados, esses modelos de teste proíbem que você analise os dados do seu experimento enquanto ele está em execução. Essa prática – também conhecida como espiar – é desencorajada em tais modelos porque o valor-p flutua quase diariamente. Você verá que um experimento será significativo em um dia e, no dia seguinte, seu valor-p aumentará a um ponto em que não será mais significativo.
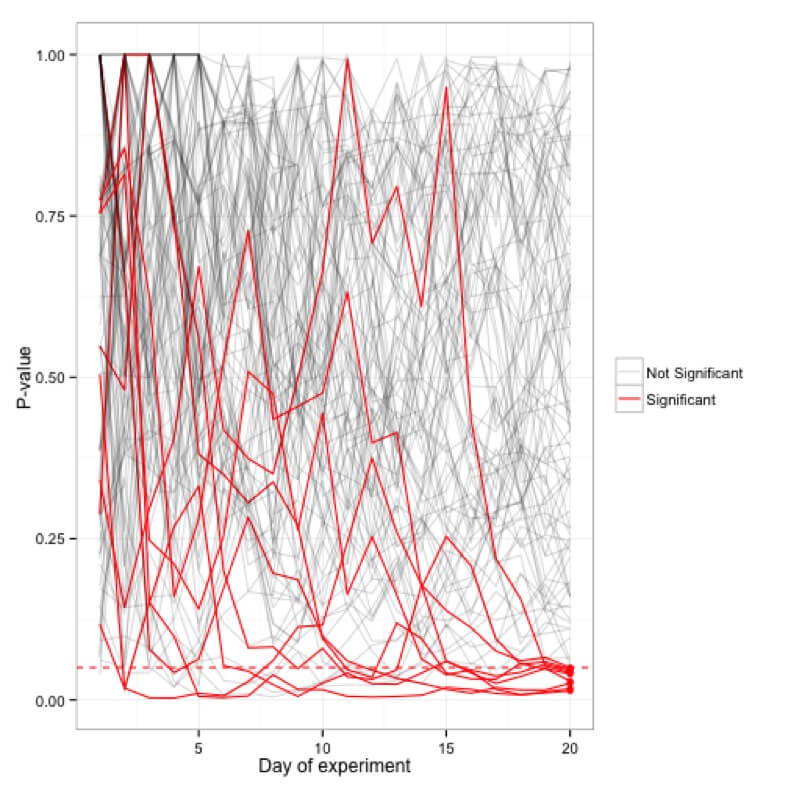
Simulações dos valores de p plotados para cem (20 dias) experimentos; apenas 5 experimentos acabam sendo significativos na marca de 20 dias, enquanto muitos ocasionalmente atingem o ponto de corte <0,05 nesse ínterim.
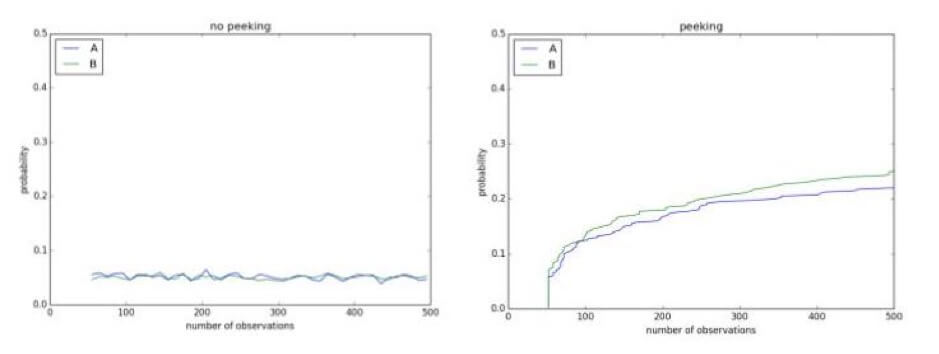
Espiar seus experimentos nesse ínterim pode mostrar resultados que não existem. Por exemplo, abaixo você tem um teste A/A usando um nível de significância de 0,1. Como é um teste A/A, não há diferença entre o controle e o tratamento. No entanto, após 500 observações durante o experimento em andamento, há mais de 50% de chance de concluir que são diferentes e que a hipótese nula pode ser rejeitada:
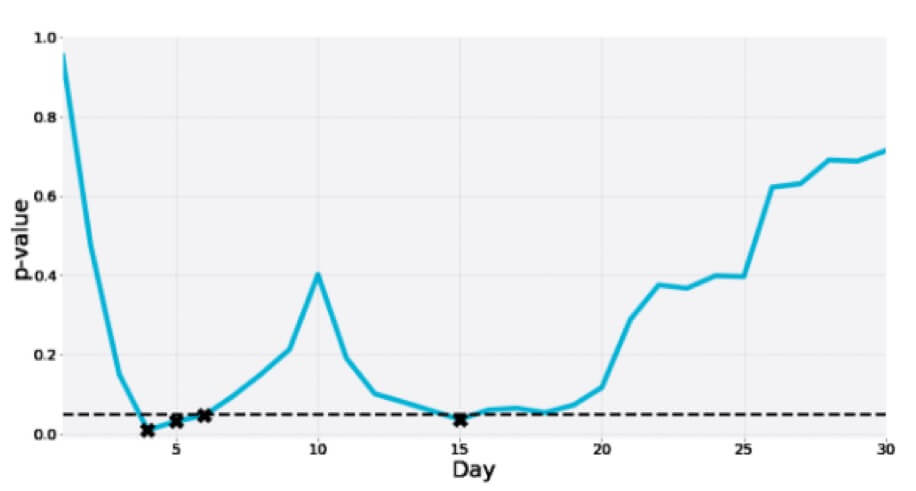
Aqui está outro de um teste A/A de 30 dias em que o valor p mergulha para a zona de significância várias vezes nesse ínterim apenas para finalmente ser muito mais do que o ponto de corte:
Relatar corretamente um valor p de um experimento de horizonte fixo significa que você precisa se comprometer previamente com um tamanho de amostra fixo ou duração de teste. Algumas equipes também adicionam um certo número de conversões a esse critério de interrupção do experimento e uma duração pretendida.
No entanto, o problema aqui é que ter tráfego de teste suficiente para alimentar todos os experimentos para uma parada ideal usando essa prática padrão é difícil para a maioria dos sites.
Aqui é onde o uso de métodos de teste sequenciais que suportam regras de parada opcionais ajuda.
Movendo-se para regras de parada flexíveis que permitem decisões mais rápidas
Os métodos de teste sequencial permitem que você acesse os dados de seus experimentos conforme eles aparecem e use seus próprios modelos de significância estatística para identificar os vencedores mais cedo, com regras de interrupção flexíveis.
As equipes de otimização nos níveis mais altos de maturidade de CRO geralmente criam suas próprias metodologias estatísticas para dar suporte a esses testes. Algumas ferramentas de teste A/B também têm isso embutido e podem sugerir se uma versão parece estar ganhando. E alguns oferecem controle total sobre como você deseja que sua significância estatística seja calculada, com seus valores personalizados e muito mais. Assim, você pode espiar e identificar um vencedor, mesmo em um experimento em andamento.

Estatístico, autor e instrutor do popular curso CXL sobre estatísticas de testes A/B, Georgi Georgiev é todo para esses métodos de testes sequenciais que permitem flexibilidade no número e no tempo de análises intermediárias:
“ O teste sequencial permite maximizar os lucros pela implantação antecipada de uma variante vencedora, bem como interromper os testes que têm pouca probabilidade de produzir um vencedor o mais cedo possível. O último minimiza as perdas devido a variantes inferiores e acelera os testes quando as variantes simplesmente não têm probabilidade de superar o controle. O rigor estatístico é mantido em todos os casos. ”
Georgiev até trabalhou em uma calculadora que ajuda as equipes a abandonar os modelos de teste de amostra fixos para um que pode detectar um vencedor enquanto um experimento ainda está em execução. Seu modelo leva em consideração muitas estatísticas e ajuda você a chamar testes cerca de 20 a 80% mais rápido do que os cálculos de significância estatística padrão, sem sacrificar a qualidade.
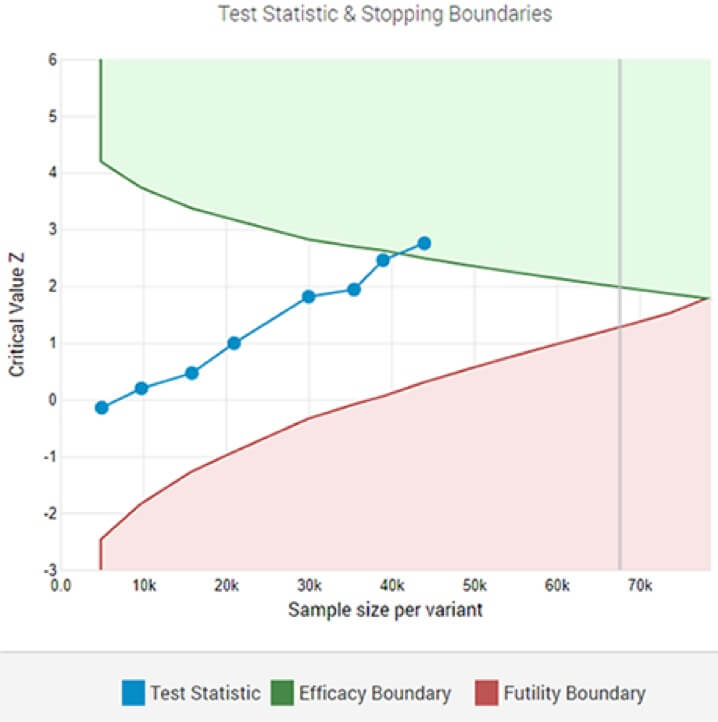
Um teste A/B adaptativo mostrando um vencedor estatisticamente significativo no limiar de significância designado após a 8ª análise interina.
Embora esses testes possam acelerar seu processo de tomada de decisão, há um aspecto importante que precisa ser abordado: o impacto real do experimento . Encerrar um experimento nesse ínterim pode levar você a superestimá-lo.
Observar estimativas não ajustadas para o tamanho do efeito pode ser perigoso, adverte Georgiev. Para evitar isso, seu modelo usa métodos para aplicar ajustes que levam em conta o viés incorrido devido ao monitoramento interino. Ele explica como sua análise ágil ajusta as estimativas “dependendo do estágio de parada e do valor observado da estatística (overshoot, se houver)”. Abaixo, você pode ver a análise para o teste acima: (Observe como a elevação estimada é menor que a observada e o intervalo não está centrado em torno dela.)
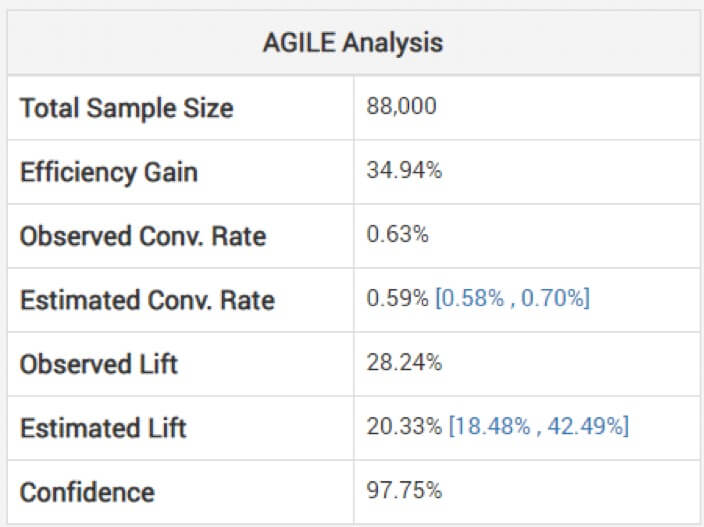
Portanto, uma vitória pode não ser tão grande quanto parece com base em seu experimento mais curto do que o pretendido.
A perda também precisa ser considerada, porque você ainda pode ter chamado erroneamente um vencedor muito cedo. Mas esse risco existe mesmo em testes de horizonte fixo. A validade externa, no entanto, pode ser uma preocupação maior ao chamar experimentos cedo em comparação com um teste de horizonte fixo de longa duração. Mas isso é, como explica Georgiev, “ uma simples consequência do tamanho da amostra menor e, portanto, da duração do teste. “
No final… Não se trata de vencedores ou perdedores…
… mas sobre melhores decisões de negócios, como diz Chris Stucchio.
Ou, como Tom Redman (autor de Data Driven: Profiting from Your Most Important Business Asset) afirma que nos negócios: “ freqüentemente há critérios mais importantes do que significância estatística. A questão importante é: “ O resultado se mantém no mercado, mesmo que apenas por um breve período de tempo? ''
E provavelmente será, e não apenas por um breve período, observa Georgiev, “ se for estatisticamente significativo e as considerações de validade externa forem abordadas de maneira satisfatória no estágio de design”.
Toda a essência da experimentação é capacitar as equipes a tomar decisões mais informadas. Então, se você puder transmitir os resultados — para os quais os dados de seus experimentos apontam — mais cedo, por que não?
Pode ser um pequeno experimento de interface do usuário para o qual você não consegue obter tamanho de amostra “suficiente”. Também pode ser um experimento em que seu desafiante esmaga o original e você pode simplesmente aceitar essa aposta!
Como Jeff Bezos escreve em sua carta aos acionistas da Amazon, grandes experimentos valem muito a pena:
“ Dada uma chance de dez por cento de um pagamento de 100 vezes, você deve fazer essa aposta todas as vezes. Mas você ainda vai estar errado nove em cada dez vezes. Todos nós sabemos que se você balançar para as cercas, você vai rebater muito, mas também vai rebater alguns home runs. A diferença entre beisebol e negócios, no entanto, é que o beisebol tem uma distribuição de resultados truncada. Quando você balança, não importa o quão bem você se conecte com a bola, o máximo de corridas que você pode conseguir são quatro. Nos negócios, de vez em quando, quando você se aproxima do prato, pode marcar 1.000 corridas. Essa distribuição de retornos de cauda longa é o motivo pelo qual é importante ser ousado. Grandes vencedores pagam por tantos experimentos. “
Chamar experimentos cedo, em grande medida, é como espiar todos os dias os resultados e parar em um ponto que garante uma boa aposta.

