
O que é uma curva CTR e como calculá-la com Python?
Publicados: 2022-03-22A curva de CTR, ou em outras palavras, a taxa de cliques orgânicos com base na posição, é um dado que mostra quantos links azuis em uma página de resultados do mecanismo de pesquisa (SERP) obtêm CTR com base em sua posição. Por exemplo, na maioria das vezes, o primeiro link azul na SERP obtém o maior CTR.
No final deste tutorial, você poderá calcular a curva de CTR do seu site com base em seus diretórios ou calcular a CTR orgânica com base em consultas de CTR. A saída do meu código Python é uma caixa perspicaz e um gráfico de barras que descreve a curva de CTR do site.
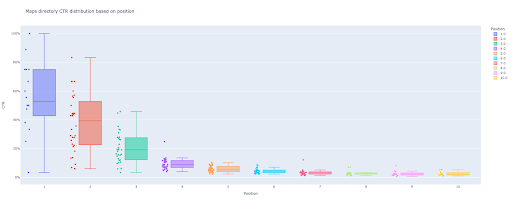
Se você é iniciante e não conhece a definição de CTR, explicarei mais na próxima seção.
O que é CTR orgânico ou taxa de cliques orgânicos?
A CTR vem da divisão de cliques orgânicos em impressões. Por exemplo, se 100 pessoas pesquisarem por “maçã” e 30 pessoas clicarem no primeiro resultado, a CTR do primeiro resultado será 30 / 100 * 100 = 30%.
Isso significa que a cada 100 pesquisas, você obtém 30% delas. É importante lembrar que as impressões no Google Search Console (GSC) não são baseadas na aparência do link do seu site na janela de visualização do buscador. Se o resultado aparecer na SERP do buscador, você obtém uma impressão para cada uma das buscas.
Quais são os usos da curva CTR?
Um dos tópicos importantes em SEO são as previsões de tráfego orgânico. Para melhorar os rankings em algum conjunto de palavras-chave, precisamos alocar milhares e milhares de dólares para obter mais compartilhamentos. Mas a pergunta no nível de marketing de uma empresa é muitas vezes: “É rentável para nós alocar esse orçamento?”.
Além disso, além do tópico de alocação de orçamento para projetos de SEO, precisamos obter uma estimativa do aumento ou diminuição do nosso tráfego orgânico no futuro. Por exemplo, se virmos um de nossos concorrentes tentando nos substituir em nossa posição no ranking SERP, quanto isso nos custará?
Nesta situação ou em muitos outros cenários, precisamos da curva CTR do nosso site.
Por que não usamos estudos de curva CTR e usamos nossos dados?
Respondendo de forma simples, não há nenhum outro site que tenha as características do seu site na SERP.
Há muita pesquisa para curvas de CTR em diferentes setores e diferentes recursos de SERP, mas quando você tem seus dados, por que seus sites não calculam a CTR em vez de confiar em fontes de terceiros?
Vamos começar a fazer isso.
Calculando a curva de CTR com Python: Introdução
Antes de mergulharmos no processo de cálculo da taxa de cliques do Google com base na posição, você precisa conhecer a sintaxe básica do Python e ter um entendimento básico das bibliotecas comuns do Python, como o Pandas. Isso ajudará você a entender melhor o código e personalizá-lo do seu jeito.
Além disso, para esse processo, prefiro usar um notebook Jupyter.
Para calcular a CTR orgânica com base na posição, precisamos usar estas bibliotecas Python:
- Pandas
- Tradicionalmente
- Kaleido
Além disso, usaremos estas bibliotecas padrão do Python:
- SO
- json
Como eu disse, vamos explorar duas formas diferentes de calcular a curva CTR. Algumas etapas são as mesmas nos dois métodos: importar os pacotes Python, criar uma pasta de saída de imagens de plotagem e definir tamanhos de plotagem de saída.
# Importando bibliotecas necessárias para nosso processo importar SO importar json importar pandas como pd importar plotly.express como px importar plotly.io como pio importar caleido
Aqui criamos uma pasta de saída para salvar nossas imagens de plotagem.
# Criando pasta de saída de imagens de plotagem
se não os.path.exists('./output plot images'):
os.mkdir('./output plot images')
Você pode alterar a altura e a largura das imagens de plotagem de saída abaixo.
# Configurando a largura e a altura das imagens de plotagem de saída pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Vamos começar com o primeiro método baseado em consultas CTR.
Primeiro método: calcular a curva de CTR de um site inteiro ou de uma propriedade de URL específica com base na CTR de consultas
Em primeiro lugar, precisamos obter todas as nossas consultas com CTR, posição média e impressão. Eu prefiro usar um mês completo de dados do mês passado.
Para fazer isso, recebo dados de consultas da fonte de dados de impressão do site GSC no Google Data Studio. Como alternativa, você pode adquirir esses dados da maneira que preferir, como a API GSC ou o complemento "Search Analytics for Sheets" do Planilhas Google, por exemplo. Dessa forma, se seu blog ou páginas de produtos tiverem uma propriedade de URL dedicada, você poderá usá-los como fonte de dados no GDS.
1. Obtendo dados de consultas do Google Data Studio (GDS)
Para fazer isso:
- Criar um relatório e adicionar um gráfico de tabela a ele
- Adicione sua fonte de dados de "Impressão do site" ao relatório
- Escolha "consulta" para dimensão, bem como "ctr", "posição média" e "'impressão" para métrica
- Filtre as consultas que contêm o nome da marca criando um filtro (consultas que contêm marcas terão uma taxa de cliques mais alta, o que diminuirá a precisão de nossos dados)
- Clique com o botão direito do mouse na tabela e clique em Exportar
- Salve a saída como CSV
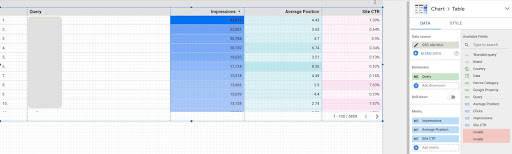
2. Carregando nossos dados e rotulando consultas com base em sua posição
Para manipular o CSV baixado, usaremos Pandas.
A melhor prática para a estrutura de pastas do nosso projeto é ter uma pasta 'data' na qual salvamos todos os nossos dados.
Aqui, por uma questão de fluidez no tutorial, não fiz isso.
query_df = pd.read_csv('./downloaded_data.csv')
Em seguida, rotulamos nossas consultas com base em sua posição. Eu criei um loop 'for' para rotular as posições de 1 a 10.
Por exemplo, se a posição média de uma consulta for 2,2 ou 2,9, ela será rotulada como “2”. Ao manipular a faixa de posição média, você pode obter a precisão desejada.
para i no intervalo (1, 11):
query_df.loc[(query_df['Posição Média'] >= i) & (
query_df['Posição Média'] < i + 1), 'rótulo da posição'] = i
Agora, agruparemos as consultas com base em sua posição. Isso nos ajuda a manipular os dados das consultas de cada posição de uma maneira melhor nas próximas etapas.
query_grouped_df = query_df.groupby(['position label'])
3. Filtrando consultas com base em seus dados para cálculo da curva de CTR
A maneira mais fácil de calcular a curva CTR é usar todos os dados das consultas e fazer o cálculo. No entanto; não se esqueça de pensar nessas consultas com uma impressão na posição dois em seus dados.
Essas consultas, com base na minha experiência, fazem muita diferença no resultado final. Mas a melhor maneira é tentar você mesmo. Com base no conjunto de dados, isso pode mudar.
Antes de iniciarmos esta etapa, precisamos criar uma lista para a saída do gráfico de barras e um DataFrame para armazenar nossas consultas manipuladas.
# Criando um DataFrame para armazenar dados manipulados 'query_df' modificado_df = pd.DataFrame() # Uma lista para salvar cada média de posição para nosso gráfico de barras lista_ctr_média = []
Em seguida, fazemos um loop sobre os grupos query_grouped_df e anexamos as 20% principais consultas com base nas impressões ao modified_df modify_df.
Se o cálculo da CTR apenas com base nos 20% principais das consultas com mais impressões não for o melhor para você, você poderá alterá-lo.
Para fazer isso, você pode aumentar ou diminuir manipulando .quantile(q=your_optimal_number, interpolation='lower')] e your_optimal_number deve estar entre 0 e 1.
Por exemplo, se você deseja obter os 30% principais de suas consultas, your_optimal_num é a diferença entre 1 e 0,3 (0,7).
para i no intervalo (1, 11):
# Um try-except para lidar com as situações em que um diretório não possui dados para algumas posições
tentar:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['impressions'] >= query_grouped_df.get_group(i)['impressions']
.quantil(q=0,8, interpolação='menor')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modificado_df = modificado_df.append(tmp_df, ignore_index=True)
exceto KeyError:
mean_ctr_list.append(0)
# Excluindo 'tmp_df' DataFrame para reduzir o uso de memória
del [tmp_df]
4. Desenhando um gráfico de caixa
Este passo é o que estávamos esperando. Para desenhar gráficos, podemos usar Matplotlib, seaborn como um wrapper para Matplotlib ou Plotly.
Pessoalmente, acho que usar o Plotly é uma das melhores opções para profissionais de marketing que adoram explorar dados.
Comparado ao Mathplotlib, o Plotly é tão fácil de usar e com apenas algumas linhas de código, você pode desenhar um belo gráfico.
# 1. O gráfico de caixa
box_fig = px.box(modified_df, x='position label', y='Site CTR', title='Consulta a distribuição de CTR com base na posição',
points='all', color='position label', labels={'position label': 'Position', 'Site CTR': 'CTR'})
# Mostrando todos os dez ticks do eixo x
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Alterando o formato do tick do eixo y para porcentagem
box_fig.update_yaxes(tickformat=".0%")
# Salvando o gráfico no diretório 'imagens de plotagem de saída'
box_fig.write_image('./output plot images/queries box plot CTR curve.png')
Com apenas essas quatro linhas, você pode obter um belo gráfico de caixa e começar a explorar seus dados.
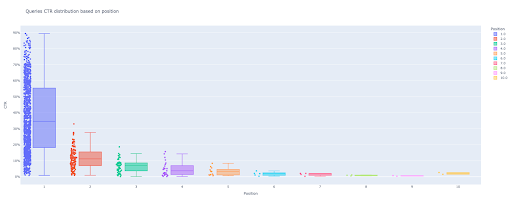
Se você quiser interagir com esta coluna, em uma nova célula, execute:
box_fig.show()
Agora, você tem um gráfico de caixa atraente na saída que é interativo.
Quando você passa o mouse sobre um gráfico interativo na célula de saída, o número importante em que está interessado é o “homem” de cada posição.
Isso mostra a CTR média para cada posição. Por causa da importância média, como você lembra, criamos uma lista que contém a média de cada posição. Em seguida, passaremos para a próxima etapa para desenhar um gráfico de barras com base na média de cada posição.
5. Desenhando um gráfico de barras
Como um gráfico de caixa, desenhar o gráfico de barras é muito fácil. Você pode alterar o title dos gráficos modificando o argumento title do px.bar() .
# 2. O gráfico de barras
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title='Consultas média de distribuição de CTR com base na posição',
labels={'x': 'Posição', 'y': 'CTR'}, text_auto=True)
# Mostrando todos os dez ticks do eixo x
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Alterando o formato do tick do eixo y para porcentagem
bar_fig.update_yaxes(tickformat='.0%')
# Salvando o gráfico no diretório 'imagens de plotagem de saída'
bar_fig.write_image('./output plot images/queries bar plot CTR curve.png')
Na saída, obtemos este gráfico:
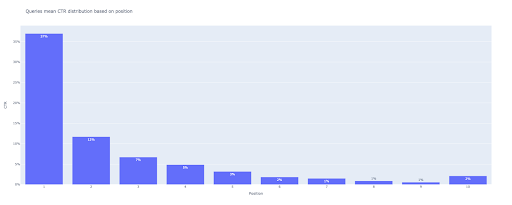
Assim como no box plot, você pode interagir com este plot executando bar_fig.show() .
É isso! Com algumas linhas de código, obtemos a taxa de cliques orgânica com base na posição com nossos dados de consultas.
Se você tiver uma propriedade de URL para cada um de seus subdomínios ou diretórios, poderá obter essas consultas de propriedades de URL e calcular a curva de CTR para elas.
[Estudo de caso] Melhorando rankings, visitas orgânicas e vendas com análise de arquivos de log
 Leia o estudo de caso
Leia o estudo de casoSegundo método: calcular a curva de CTR com base nos URLs das páginas de destino para cada diretório
No primeiro método, calculamos nossa CTR orgânica com base na CTR de consultas, mas com essa abordagem, obtemos todos os dados de nossas páginas de destino e calculamos a curva de CTR para nossos diretórios selecionados.

Eu amo esse jeito. Como você sabe, a CTR de nossas páginas de produtos é muito diferente daquela de nossas postagens de blog ou de outras páginas. Cada diretório tem seu próprio CTR com base na posição.
De uma maneira mais avançada, você pode categorizar cada página do diretório e obter a taxa de cliques orgânicos do Google com base na posição de um conjunto de páginas.
1. Obtendo dados de páginas de destino
Assim como o primeiro método, existem várias maneiras de obter dados do Google Search Console (GSC). Nesse método, preferi obter os dados das páginas de destino do GSC API explorer em: https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
Para o que é necessário nessa abordagem, o GDS não fornece dados sólidos da página de destino. Além disso, você pode usar o complemento "Pesquisar Analytics para Planilhas" do Planilhas Google.
Observe que o Google API Explorer é adequado para sites com menos de 25 mil páginas de dados. Para sites maiores, você pode obter dados de páginas de destino parcialmente e concatená-los, escrever um script Python com um loop 'for' para obter todos os seus dados do GSC ou usar ferramentas de terceiros.
Para obter dados do Google API Explorer:
- Navegue até a página de documentação da API GSC “Search Analytics: query”: https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- Use o API Explorer que está no lado direito da página
- No campo "siteUrl", insira o endereço da propriedade do URL, como
https://www.example.com. Além disso, você pode inserir sua propriedade de domínio da seguinte formasc-domain:example.com - No campo “request body” adicione
startDateeendDate. Prefiro obter os dados do mês passado. O formato desses valores éYYYY-MM-DD - Adicione
dimensione defina seus valores para apage - Crie um “dimensionFilterGroups” e filtre as consultas com nomes de variação de marca (substituindo
brand_variation_namespor seus nomes de marca RegExp) - Adicione
rawLimite defina-o para 25000 - No final pressione o botão 'EXECUTAR'
Você também pode copiar e colar o corpo da solicitação abaixo:
{
"data inicial": "2022-01-01",
"endDate": "2022-02-01",
"dimensões": [
"página"
],
"dimensionFilterGroups": [
{
"filtros": [
{
"dimensão": "QUERY",
"expression": "brand_variation_names",
"operador": "EXCLUDING_REGEX"
}
]
}
],
"linhaLimite": 25000
}
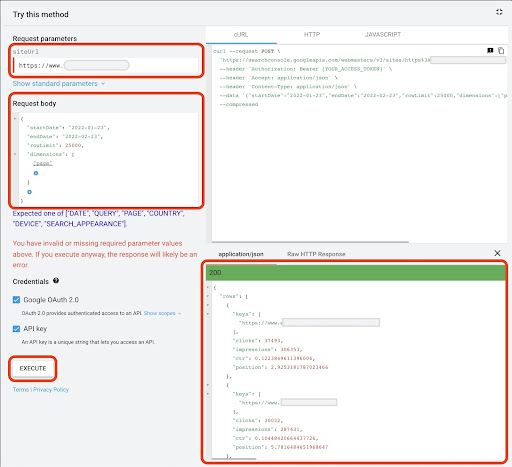
Após a requisição ser executada, precisamos salvá-la. Por causa do formato de resposta, precisamos criar um arquivo JSON, copiar todas as respostas JSON e salvá-lo com o nome de arquivo downloaded_data.json .
Se seu site for pequeno, como um site de empresa SASS, e os dados da sua página de destino tiverem menos de 1.000 páginas, você poderá definir facilmente sua data no GSC e exportar os dados das páginas de destino para a guia "PÁGINAS" como um arquivo CSV.
2. Carregando dados das páginas de destino
Para este tutorial, vou supor que você obtenha dados do Google API Explorer e os salve em um arquivo JSON. Para carregar esses dados temos que executar o código abaixo:
# Criando um DataFrame para os dados baixados
com open('./downloaded_data.json') como json_file:
landings_data = json.loads(json_file.read())['rows']
landings_df = pd.DataFrame(landings_data)
Além disso, precisamos alterar o nome de uma coluna para dar mais significado e aplicar uma função para obter URLs da página de destino diretamente na coluna "página de destino".
# Renomeando a coluna 'chaves' para a coluna 'página de destino' e convertendo a lista de 'página de destino' em um URL
landings_df.rename(columns={'keys': 'landing page'}, inplace=True)
landings_df['landing page'] = landings_df['landing page'].apply(lambda x: x[0])
3. Obtendo todos os diretórios raiz das páginas de destino
Antes de tudo, precisamos definir o nome do nosso site.
# Definindo o nome do seu site entre aspas. Por exemplo, 'https://www.example.com/' ou 'http://mydomain.com/' nome_do_site = ''
Em seguida, executamos uma função nos URLs da página de destino para obter seus diretórios raiz e vê-los na saída para escolhê-los.
# Obtendo cada diretório de página de destino (URL)
landings_df['directory'] = landings_df['landing page'].str.extract(pat=f'((?<={site_name})[^/]+)')
# Para obter todos os diretórios na saída, precisamos manipular as opções do Pandas
pd.set_option("display.max_rows", Nenhum)
# Diretórios de sites
landings_df['directory'].value_counts()
Em seguida, escolhemos para quais diretórios precisamos obter sua curva CTR.
Insira os diretórios na variável important_directories .
Por exemplo, product,tag,product-category,mag . Separe os valores do diretório com vírgula.
diretórios_importantes = ''
importante_diretórios = importante_diretórios.split(',')
4. Rotular e agrupar páginas de destino
Assim como as consultas, também rotulamos as páginas de destino com base em sua posição média.
# Rotulando a posição das páginas de destino
para i no intervalo (1, 11):
landings_df.loc[(landings_df['position'] >= i) & (
landings_df['position'] < i + 1), 'position label'] = i
Em seguida, agrupamos as landing pages com base em seu “diretório”.
# Agrupando páginas de destino com base em seu valor de 'diretório' landings_grouped_df = landings_df.groupby(['diretório'])
5. Gerando gráficos de caixa e barra para nossos diretórios
No método anterior, não usamos uma função para gerar os gráficos. No entanto; para calcular a curva de CTR para diferentes páginas de destino automaticamente, precisamos definir uma função.
# A função para criar e salvar cada gráfico de diretório
def cada_dir_plot(dir_df, chave):
# Agrupando as páginas de destino do diretório com base no valor de 'rótulo de posição'
dir_grouped_df = dir_df.groupby(['position label'])
# Criando um DataFrame para armazenar dados manipulados 'dir_grouped_df'
modificado_df = pd.DataFrame()
# Uma lista para salvar cada média de posição para nosso gráfico de barras
lista_ctr_média = []
'''
Fazer um loop sobre os grupos 'query_grouped_df' e anexar as 20% principais consultas com base nas impressões ao DataFrame 'modified_df'.
Se o cálculo da CTR apenas com base nos 20% principais das consultas com mais impressões não for o melhor para você, você poderá alterá-lo.
Para alterá-lo, você pode aumentá-lo ou diminuí-lo manipulando '.quantile(q=your_optimal_number, interpolation='lower')]'.
'you_optimal_number' deve estar entre 0 e 1.
Por exemplo, se você deseja obter os 30% principais de suas consultas, 'your_optimal_num' é a diferença entre 1 e 0,3 (0,7).
'''
para i no intervalo (1, 11):
# Um try-except para lidar com as situações em que um diretório não possui dados para algumas posições
tentar:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['impressions'] >= dir_grouped_df.get_group(i)['impressions']
.quantil(q=0,8, interpolação='menor')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modificado_df = modificado_df.append(tmp_df, ignore_index=True)
exceto KeyError:
mean_ctr_list.append(0)
# 1. O gráfico de caixa
box_fig = px.box(modified_df, x='position label', y='ctr', title=f'{key} distribuição de CTR do diretório com base na posição',
points='all', color='position label', labels={'position label': 'Position', 'ctr': 'CTR'})
# Mostrando todos os dez ticks do eixo x
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Alterando o formato do tick do eixo y para porcentagem
box_fig.update_yaxes(tickformat=".0%")
# Salvando o gráfico no diretório 'imagens de plotagem de saída'
box_fig.write_image(f'./output plot images/{key} directory-Box plot CTR curve.png')
# 2. O gráfico de barras
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title=f'{key} distribuição média de CTR do diretório com base na posição',
labels={'x': 'Posição', 'y': 'CTR'}, text_auto=True)
# Mostrando todos os dez ticks do eixo x
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Alterando o formato do tick do eixo y para porcentagem
bar_fig.update_yaxes(tickformat='.0%')
# Salvando o gráfico no diretório 'imagens de plotagem de saída'
bar_fig.write_image(f'./output plot images/{key} directory-Bar plot CTR curve.png')
Depois de definir a função acima, precisamos de um loop 'for' para percorrer os dados dos diretórios para os quais queremos obter sua curva CTR.
# Fazendo um loop nos diretórios e executando a função 'each_dir_plot'
para chave, item em landings_grouped_df:
if key em diretórios_importantes:
each_dir_plot(item, chave)
Na saída, obtemos nossos gráficos na pasta output plot images .
Dica avançada!
Você também pode calcular as curvas de CTR dos diferentes diretórios usando a página de destino das consultas. Com algumas alterações nas funções, você pode agrupar consultas com base em seus diretórios de páginas de destino.
Você pode usar o corpo da solicitação abaixo para fazer uma solicitação de API no API Explorer (não se esqueça da limitação de 25.000 linhas):
{
"data inicial": "2022-01-01",
"endDate": "2022-02-01",
"dimensões": [
"consulta",
"página"
],
"dimensionFilterGroups": [
{
"filtros": [
{
"dimensão": "QUERY",
"expression": "brand_variation_names",
"operador": "EXCLUDING_REGEX"
}
]
}
],
"linhaLimite": 25000
}
Dicas para personalizar o cálculo da curva CTR com Python
Para obter dados mais precisos para calcular a curva CTR, precisamos usar ferramentas de terceiros.
Por exemplo, além de saber quais consultas possuem um trecho em destaque, você pode explorar mais recursos de SERP. Além disso, se você usar ferramentas de terceiros, poderá obter o par de consultas com a classificação da página de destino para essa consulta, com base nos recursos SERP.
Em seguida, rotular as páginas de destino com seu diretório raiz (pai), agrupar as consultas com base nos valores do diretório, considerar os recursos SERP e, finalmente, agrupar as consultas com base na posição. Para dados de CTR, você pode mesclar valores de CTR do GSC com suas consultas de pares.