
Importância da Rede Semântica para SEO: Criando Redes Semânticas de Conteúdo com Modelos de Consulta e Documentos – Estudo de Caso
Publicados: 2022-01-11Uma Rede Semântica está ligada ao conceito de uma base de conhecimento que pode representar informações do mundo real para coisas que possuem conexões relacionais. Uma base de conhecimento pode ter milhares de tipos de relações com bilhões de entidades e trilhões de fatos. Uma rede semântica pode ser criada a partir de qualquer existência do mundo real com características mútuas como peso, tamanho, tipo, cheiro ou cor. A relação entre Redes Semânticas e Web Semântica é criada por mecanismos de busca semântica e otimização.
As redes semânticas são usadas na análise semântica, desambiguação de sentido de palavras, criação de WordNet, teoria de grafos, processamento de linguagem natural, compreensão e geração. A perspectiva de uma Rede Semântica pode ser usada dentro da Otimização de Mecanismos de Busca Semântica, fornecendo uma rede de conteúdo semântico.
Neste estudo de caso de SEO, dois sites diferentes com dois métodos diferentes com a mesma perspectiva serão explicados com base nos modelos de consulta, documento, intenção e os pares entidade-atributo por trás deles.
Usando uma compreensão de como os mecanismos de pesquisa representam o conhecimento e como eles expandem sua representação do conhecimento, sou capaz de aproveitar isso para produzir resultados de classificação incríveis. Assim que você entender os conceitos básicos, explicarei como os apliquei aos dois sites diferentes e, em seguida, detalharei os métodos que usei.
Como as Redes Semânticas podem ajudar no Ranking do seu Site?
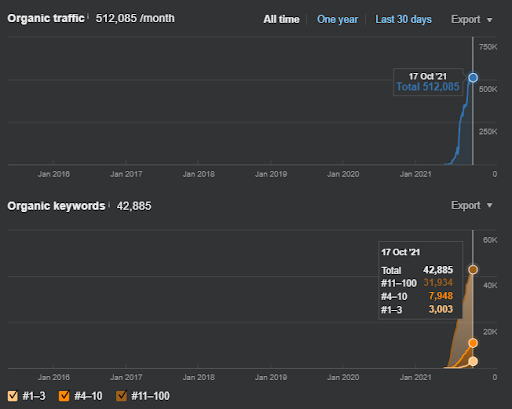
Abaixo, você encontrará os resultados brutos gerais do Projeto I.
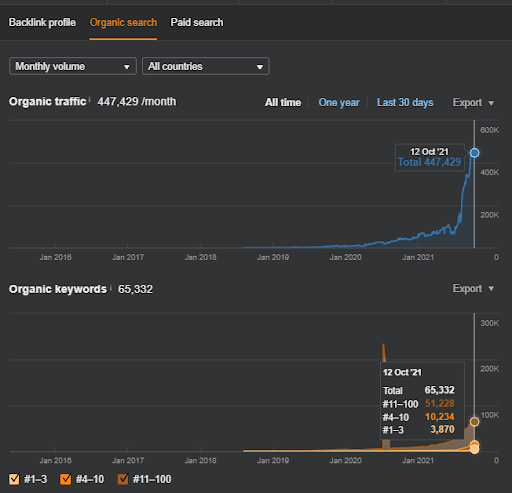
Resultados para o Project One, que é IstanbulBogaziciEnstitu.com. Para provar que as “Redes Semânticas” podem ser usadas para SEO com templates de consulta e documento, vou demonstrar duas redes de conteúdo diferentes do Project One. O Project One terá resultados muito melhores em um futuro próximo, graças à Semantic Content Network Two. O cliente será responsável pela implantação desta segunda rede, mas também explicarei sua lógica.
17 dias depois, aqui está o progresso feito no Projeto I: 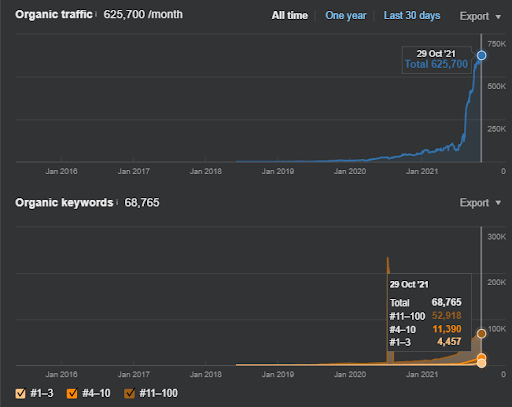
17 dias depois, o processo de reclassificação da Semantic Content Network está mais claro.
Os conceitos de rede de conteúdo semântico nos ajudam a entender o valor da consulta, intenção de pesquisa, comportamento e modelos de documentos para entidades do mesmo tipo. Neste estudo de caso de SEO focado em rede semântica, o estudo de caso anterior de autoridade tópica e SEO semântico será aprofundado por meio dos dois novos sites que usam redes de conteúdo criadas semanticamente em torno dos mesmos tipos de entidade.
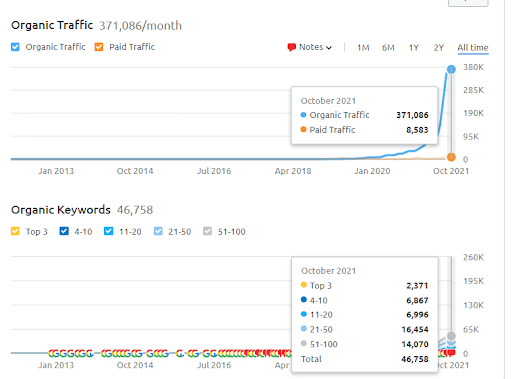
Este é o gráfico SEMRush do Primeiro Projeto. Também devo mencionar que este site perdeu a atualização do algoritmo Broad Core de junho, se não perdesse sua “Rankability”, os resultados seriam melhores. Para a próxima atualização do algoritmo de núcleo amplo, com melhor autoridade tópica, cobertura e dados históricos, ele pode recuperar a “classificação” facilmente.
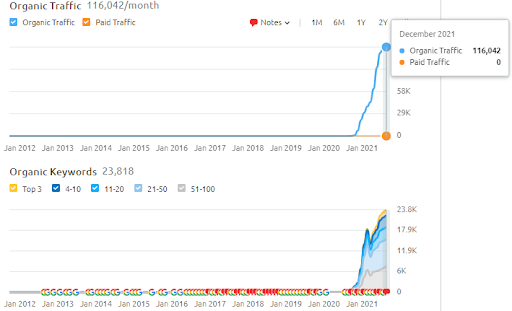
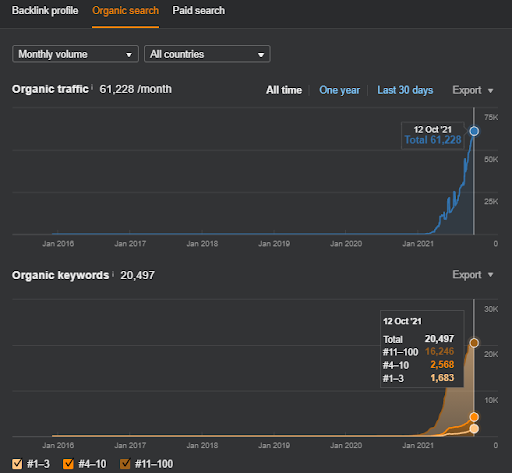
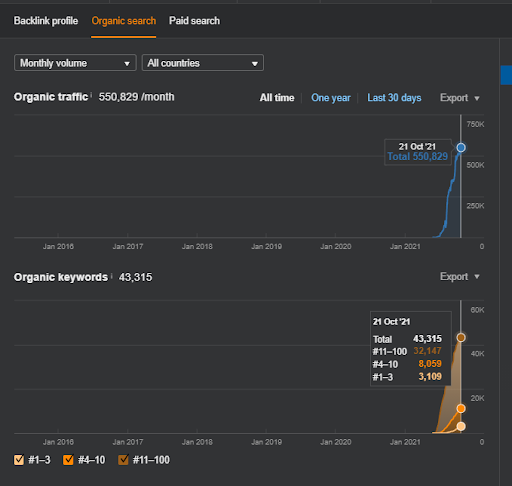
O nome do Segundo Projeto é Vizem.net. Ao contrário do Project One, você pode ver que o Vizem.net tem um aumento mais lento, mas constante. É porque eles usam as Redes de Conteúdo Semântico com perspectivas ligeiramente diferentes. Abaixo, você pode ver os resultados da Ahrefs do Segundo Projeto.
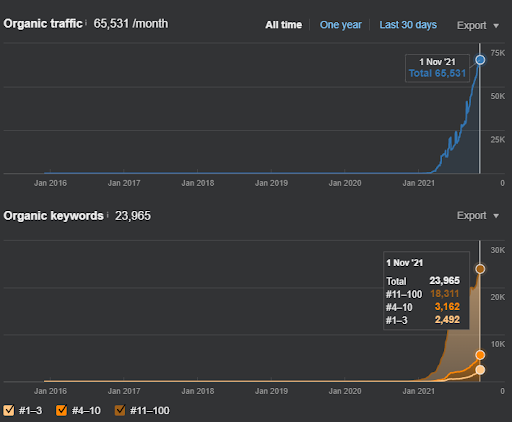
Os resultados do Segundo Projeto representam um “Processo Lento de Reclassificação”, melhorando gradualmente a Cobertura e Autoridade Tópica. Os termos “Re-ranking” e “Ranking inicial” serão explicados após os conceitos relacionados às Redes de Conteúdo Semânticas. Se você percebe a “estabilidade” dentro dos gráficos, é porque parei de publicar novos conteúdos na fonte. E isso afeta o processo de reclassificação, conforme você percebe a partir das contagens das 3 principais contagens de consultas. As relações “Momentum” e “Re-ranking” podem ser encontradas após as explicações dos conceitos fundamentais.
Abaixo, você pode encontrar os resultados SEMRush do Vizem.net.
O tráfego real deste site é 3x mais do que o número declarado no SEMRush. Você pode perceber a mesma “estabilidade” e os conceitos de “momentum” nesses gráficos também.
Enquanto escrevia o Estudo de Caso de SEO da Autoridade Tópica, agradeci a Bill Slawski por educar minha perspectiva. Repito isso para o Estudo de Caso de SEO da Rede de Conteúdo Semântica também. Para entender os conceitos de “Reclassificação” e “Classificação inicial”, deve-se ler “Como os mecanismos de pesquisa podem reclassificar os resultados da pesquisa”.
Em 18 de março de 2021, Oncrawl, RankSense e Holistic SEO & Digital publicaram um webinar Python SEO and Data Science. No webinar, o SERP foi gravado para animar as diferenças de resultados. Pode-se ver que o mecanismo de busca altera os rankings de determinadas fontes com outras com frequência semelhante.
Antes de continuar, sei que este é um longo artigo. Mas, na verdade, esta é uma breve explicação de uma metodologia de SEO altamente complexa. As redes de conteúdo semântico exigem muito pensamento ao projetá-las e meses de educação para clientes, autores e junto com a integração. Assim, neste artigo, quero focar nas definições dos conceitos com as melhores sugestões executáveis possíveis e importantes patentes do Google e de outros mecanismos de busca, artigos de pesquisa junto com seus próprios conceitos. Na versão longa (basicamente, um livro), concentrei-me no “ranking inicial” e no “reranking” das redes de conteúdo semântico.
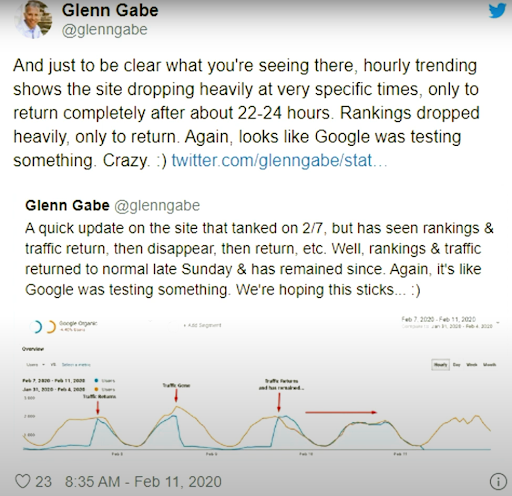
A partir de 11 de fevereiro de 2020, Glenn Gabe tem um bom exemplo para a metodologia de reclassificação e teste visual dos motores de busca.
Se você quiser saber mais, leia “Importância do Ranking Inicial e Re-ranking para SEO”.
Para mergulhar profundamente nos dados do mundo real para o Estudo de Caso de SEO, os conceitos para entender a Rede de Conteúdo Semântica devem ser processados com uma perspectiva de Entendimento-Comunicação do Mecanismo de Pesquisa.
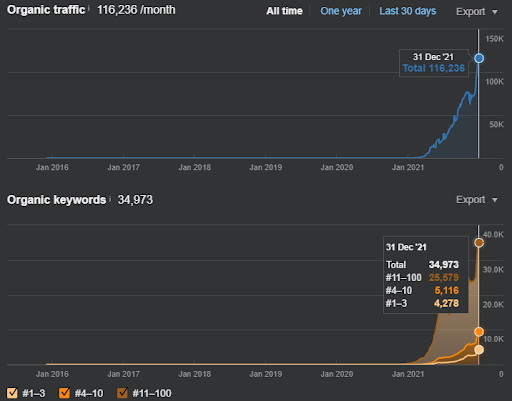
Como exemplo de reclassificação do Vizem.net, a situação atualizada pode ser vista acima. Nas próximas seções do Estudo de Caso de SEO, haverá mais explicações para os Algoritmos de Reclassificação do Google para SEO.
O que é uma Rede Semântica?
Uma rede semântica pode ser usada para conectar e analisar a internet das coisas. Pode ser benéfico para reconhecer os potenciais compradores no mercado de tecnologia ou apenas para análise de co-palavras para criação e agrupamento de redes de palavras-chave. Uma rede semântica pode ser usada para apoiar a navegação e revelar a estrutura das relações, ou a importância relativa de uma coisa para outra. A Rede Semântica possui os componentes abaixo:
- Semântica Lexical: Compreender qual palavra e conceito estão ligados a quais outros, com quais diferenças.
- Componente Estrutural: Entendendo qual nó está conectado a qual aresta com quais informações.
- Componente Semântica: Definição dos fatos.
- Parte procedimental: Ajuda a criar mais conexões entre os componentes.
Como as redes semânticas são multifuncionais, os algoritmos de PNL também podem ser usados para propósitos muito diversos, como ajudar na identificação de problemas de saúde complicados. A mesma estrutura de rede semântica pode ser implementada em várias outras áreas, desde que essas outras áreas tenham uma relação semântica entre si.
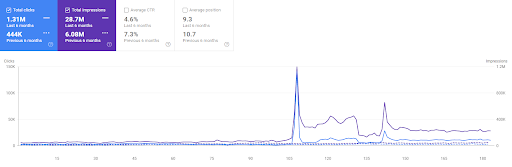
A comparação dos últimos 6 meses do Primeiro Projeto.
O que é uma base de conhecimento?
Uma base de conhecimento é uma biblioteca de informações com classificação em um formato legível por máquina. Uma base de conhecimento pode ser usada como uma enciclopédia que pode ser reduzida e aprofundada com base na consulta. Uma base de conhecimento pode ser formada com base em proposições, extração de fatos e extração de informações. A relação entre uma rede semântica e uma base de conhecimento é que tudo o que estiver na rede semântica será colocado na base de conhecimento ao extrair os fatos.
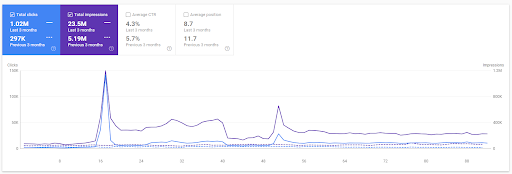
A comparação dos últimos 3 meses do Primeiro Projeto
O que é uma rede de conteúdo semântico?
A Rede de Conteúdo Semântica representa uma rede de conteúdo que foi preparada com base nos componentes e entendimento da rede semântica. Uma rede de conteúdo semântico pode incluir vários atributos de uma entidade ou entidades do mesmo grupo para fornecer uma base de conhecimento com mais detalhes.
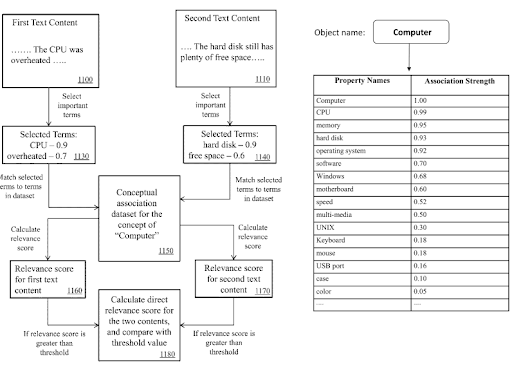
Dentro de uma rede de conteúdo semântico, os termos de domínio de conhecimento e triplos podem ser usados para sinalizar o objetivo principal de um documento e possíveis partes de conteúdo de vizinhança.
Um mecanismo de pesquisa pode comparar sua própria base de conhecimento com a base de conhecimento que pode ser gerada a partir do conteúdo de um site. Se o site tiver um alto nível de precisão e abrangência para diferentes camadas contextuais, o mecanismo de pesquisa pode melhorar sua própria base de conhecimento a partir do conteúdo do site. Se um mecanismo de pesquisa melhora e expande sua própria base de conhecimento de outra fonte na web aberta, é um sinal de confiança baseada em conhecimento de alto nível.
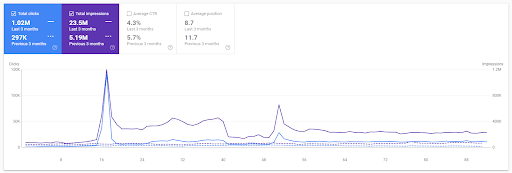
Comparação ano a ano dos últimos 3 meses com base no primeiro projeto.
O que é Confiança Baseada no Conhecimento?
A confiança baseada em conhecimento se concentra na web aberta baseada na “precisão das informações”, não no “PageRank”. É um algoritmo semelhante ao RankMerge. A confiança baseada em conhecimento envolve trigêmeos, extração de fatos, verificação de precisão e compreensão de texto, removendo a ambiguidade do texto. A confiança baseada em conhecimento pode ser adquirida fornecendo redes de conteúdo semântico que possuem os componentes fortemente conectados dentro do artigo, com base em camadas contextuais diferentes, mas relevantes.
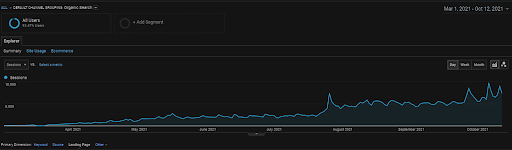
A Sessão Orgânica do Vizem.net da GA nos Últimos 6 Meses.
Abaixo, você verá um exemplo de uma apresentação de Confiança baseada em conhecimento de Luna Dong. Ele mostra como um mecanismo de pesquisa pode se concentrar nos “fatores de classificação internos” em vez dos fatores de classificação exógenos. Ele explica que um PageRank alto não pode representar alta qualidade e precisão para o conteúdo por si só. Portanto, ter um KBT (Confiança Baseada em Conhecimento) é importante.
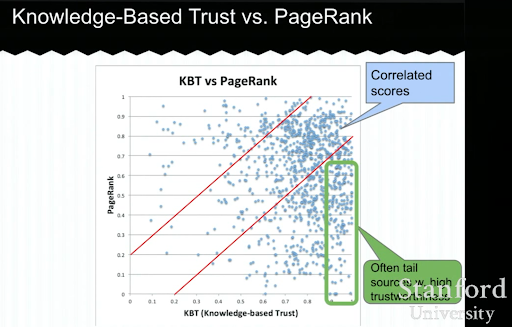
Muito obrigado a Arnout Hellemans que compartilhou esta palestra educacional comigo durante um bate-papo privado de SEO. Se você quiser saber mais sobre a confiança baseada no conhecimento: Seminário Stanford – Cofre do Conhecimento e Confiança Baseada no Conhecimento
O que é cobertura contextual?
Cobertura Contextual e Cobertura Tópica não são a mesma coisa que Domínio de Conhecimento e Domínio Contextual não são a mesma coisa. Uma cobertura contextual representa os ângulos de processamento de um conceito. Um conceito pode ser processado com base em seus pontos mútuos para as outras coisas. Como se a entidade fosse um país, sua postura diante da crise ambiental pode ser processada. Se outros países forem processados do mesmo ângulo, significa que estamos cobrindo um domínio contextual.

O Google Search Engine constrói seus documentos de pesquisa e patentes ao longo do tempo. A citação direita da seção acima é um atributo para os “vetores de contexto”, enquanto a seção esquerda é um atributo para a “taxonomia de frases”. O interessante é que, até o exemplo é o mesmo, que é “câmera digital”.
Os detalhes aprofundados e subpartes dessas combinações representam as camadas contextuais dentro de um domínio contextual. Cada entidade, seja ela nomeada ou não, tem muitos domínios contextuais. Assim, o Google extrai domínios mais contextuais e os usuários pesquisam consultas mais longas a cada ano. Quando o Processamento de Linguagem Natural e o Entendimento de Linguagem Natural são desenvolvidos, as consultas e os documentos se expandem juntos em termos de detalhes e contexto.
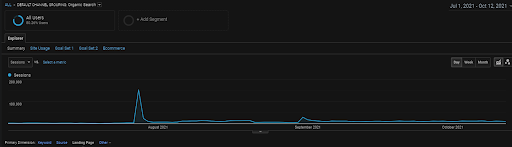
O gráfico GA Organic Sessions para os últimos 4 meses do Projeto BogaziciEnstitu. Devido ao “Fase de obtenção de dados históricos” do projeto, os detalhes aumentados não são claros para serem vistos como lineares.
Uma cobertura contextual pode ser entendida pelos “qualificadores de contexto”. Um qualificador de contexto pode ser um adjetivo, adverbial ou qualquer outra preposição, como frases que começam com “for, in, at, while, while”. As questões relacionadas à entidade abaixo não são as mesmas em termos de domínio contextual:
- Quais são as frutas mais úteis para crianças com insônia?
- Quais são as frutas mais úteis para crianças com ansiedade?
As perguntas relacionadas à entidade abaixo não são as mesmas em termos da camada contextual:
- Quais são as frutas mais úteis para crianças com insônia severa com mais de 6 anos?
- Quais são as frutas mais úteis para crianças com baixo nível de ansiedade com menos de 6 anos?
As questões relacionadas à entidade abaixo não são as mesmas em termos de domínios de conhecimento:
- Quais são os livros mais úteis para crianças com insônia severa com mais de 6 anos?
- Quais são os jogos mais úteis para crianças com baixo nível de ansiedade com menos de 6 anos?
Mas todas essas perguntas podem estar na mesma rede de conteúdo semântico porque são todas sobre o mesmo “conceito” e “área de interesse” com atividade de pesquisa semelhante e atividade do mundo real relacionada à pesquisa.
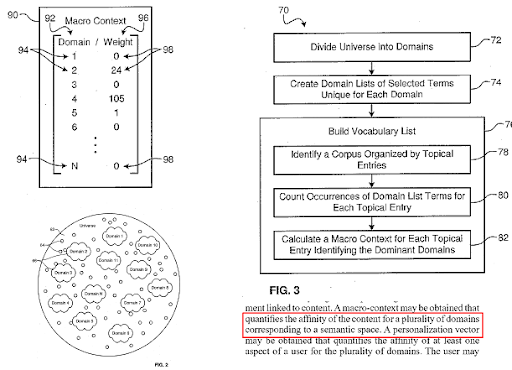
Um mecanismo de pesquisa divide a web em diferentes domínios de conhecimento e calcula as pontuações macro e micro de contexto para uma fonte, uma página da web e uma seção de página da web ao mesmo tempo.
Eu sei que tenho muitos conceitos novos para você, e como esta é a versão resumida deste artigo, não poderei falar sobre tudo aqui, mas em um futuro Curso de SEO Semântico, vou processar essas coisas como a diferença entre “atividade de pesquisa” e “atividade do mundo real relacionada à pesquisa”.
Vamos continuar um pouco para as coisas mais concretas.
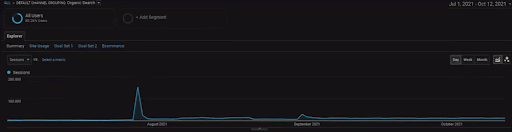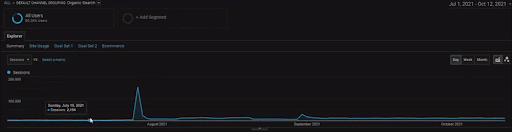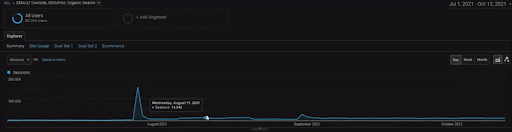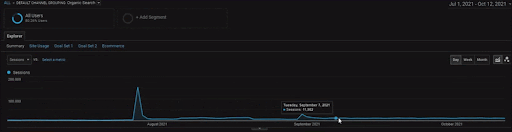
Para mostrar os detalhes do Projeto BogaziciEnstitu, você pode conferir a versão da imagem interativa. O processo de teste e reclassificação dos mecanismos de pesquisa fica mais claro neste projeto após o evento da fonte de dados históricos.
Como o MuM está relacionado às redes de conteúdo semântico?
O aprendizado multitarefa com um transformador unificado ou o modelo unificado multitarefa treina modelos de linguagem para avaliar entradas visuais, bem como texto. É capaz de gerar texto junto com a compreensão. Além disso, o MuM é agnóstico de linguagem, ou seja, o SEO semântico depende da habilidade do idioma, mas não se restringe a um idioma. Como as entidades não têm uma linguagem e o significado é universal, o MuM aproveita as informações de vários idiomas e vários contextos em uma única base de conhecimento.
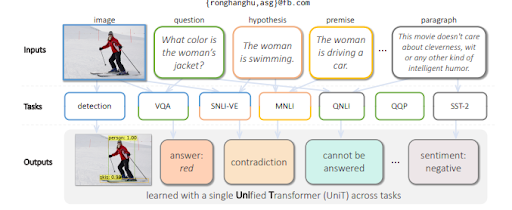
Para responder às perguntas de um visual, o MuM gera perguntas com base nos objetos detectados em uma imagem. Em um futuro próximo, perguntas relacionadas a áudio e vídeo também poderão ser geradas.
O MuM usa diferentes domínios para detecção de objetos e compreensão de linguagem natural com uma estrutura de codificador-decodificador de transformador. Cada entrada vem de uma área diferente da web aberta, enquanto todas elas são avaliadas a partir de um único decodificador compartilhado. Abaixo, você poderá ver mais um exemplo do trabalho de pesquisa.
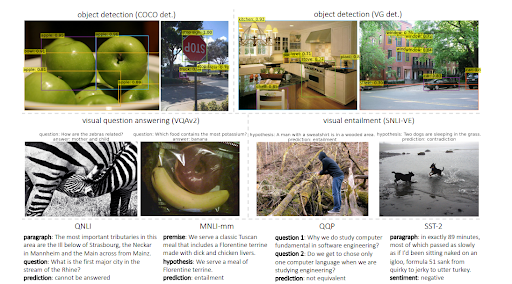
Como nota, o MuM pode ser 1000 vezes mais forte que o BERT, mas o BERT ainda é usado no Text Encoder do MuM. A principal vantagem do MuM é que ele pode ser usado para visuais e áudio diretamente, razão pela qual pode ser chamado de modelo “multitarefa”. A segunda vantagem é que ele remove todas as barreiras linguísticas diretamente. A terceira vantagem é que ele é capaz de conectar tudo a outra coisa sem a necessidade de intermediários extras. A quarta vantagem é que o MuM também pode gerar texto, ao contrário do BERT.
A conexão entre MuM, Base de Conhecimento, Redes Semânticas e Cobertura Contextual é que o mecanismo de busca é capaz de encontrar muito mais domínios contextuais por meio de qualificadores de contexto e suas combinações com possíveis domínios de conhecimento. Assim, uma Rede de Conteúdo Semântica bem estruturada, com um Mapa de Tópicos e Contexto de Origem adequados, pode melhorar a Confiança da base de Conhecimento, juntamente com a Autoridade de Tópicos.
Qual é o Contexto da Fonte?
O Contexto da Fonte representa duas coisas. A internet de pesquisa central da fonte e a atividade de pesquisa central que pode ser feita com a atividade de pesquisa relacionada. Para um site de comércio eletrônico, o contexto de origem é a compra de um produto específico ou um tipo específico de produto. Se for um site de viagens, o contexto da fonte está indo para algum lugar de outro lugar para diferentes tipos de alimentos, paisagens ou apenas negócios. Com base no Contexto da Fonte, o design da Rede de Conteúdo Semântica e o Mapa de Tópicos precisarão ser configurados posteriormente. Isso requer a escolha das seções centrais dentro do mapa tópico e seções suplementares dentro do mapa tópico.
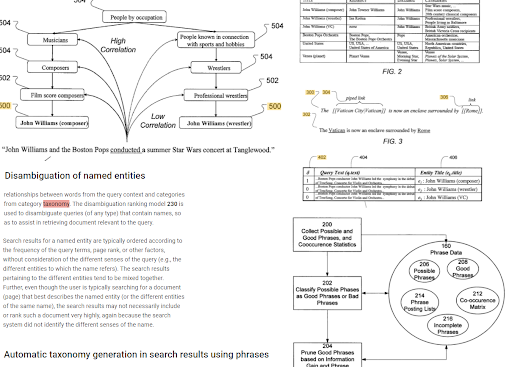
A indexação baseada em frases e a compreensão da pesquisa orientada a entidades estão conectadas entre si com base na semântica. Acima, a “Desambiguação de Entidade Nomeada” e a “Geração automática de taxonomia nos resultados da pesquisa usando frases” podem ser vistas juntas para determinar o “contexto”. As boas frases e as informações exclusivas, mas correlacionadas, para um tópico ajudarão a melhorar a classificação inicial e a reclassificação.
Novamente, alguns desses conceitos, a “configuração do mapa de tópicos”, “design de rede de conteúdo semântico” ainda não foram definidos, e este não é o lugar certo para isso. Mas, a atividade de pesquisa relacionada foi explicada junto com a intenção de pesquisa canônica e frases representativas para essas intenções de pesquisa canônica.
Antecedentes do Estudo de Caso de SEO Focado em Rede Semântica
Com base nos conceitos acima, usei Redes Semânticas para criar um Estudo de Caso de SEO. Veremos os dois projetos de sites que mencionei no início deste artigo e examinaremos os resultados e como implementei Redes Semânticas para produzi-los.
Para dar uma ideia de quão poderosas essas redes podem ser, os resultados relacionados a SEO para o Estudo de Caso de SEO focado em Rede Semântica estão listados abaixo.
- A Compreensão da Rede Semântica é uma necessidade para criar um Mapa Tópico adequado.
- Para ambos os projetos, o SEO técnico não é usado para isolar os efeitos do SEO semântico.
- A otimização da velocidade da página não é usada, pelo mesmo motivo.
- Design e otimização WUX (Website User Experience) não são usados.
- Backlinks (Referências externas e fluxo PageRank) não são usados.
- Ambas as marcas não possuem dados históricos. Vizem.net é completamente novo, BogaziciEnstitusu tem uma história mais antiga, mas era menor do que a empresa real.
- OnPage SEO ou outros verticais do SEO não são usados.
- Ambas as marcas têm um servidor melhor do que o exemplo anterior do Estudo de Caso de Autoridade Tópica.
Este estudo de caso de SEO focado em rede semântica ajudará as pessoas que desejam melhorar sua perspectiva de SEO semântico com duas metodologias e conceitos diferentes que se concentram em dois sites diferentes.
Projeto Dois: Vizem.net se concentra no Processo de Solicitação de Visto. Antes de escrever, publicar ou até mesmo lançar esses projetos, mostrei esses dois sites muitas vezes para meus outros clientes ou parceiros. E, Vizem.net iniciou sua jornada de “Autoridade Tópica” recentemente.
SEO baseado no Estudo de Caso de Redes Semânticas foi escrito em duas versões diferentes. Se você quiser ler todas as patentes relacionadas, documentos de pesquisa e exames profundamente detalhados, interpretações do ponto de vista do mecanismo de pesquisa enquanto entende melhor as árvores de decisão dos mecanismos de pesquisa, você pode ler a Importância do SEO de classificação inicial e reclassificação Artigo de Estudo de Caso com mais de 30.000 palavras. Se você não tem conhecimento teórico suficiente para SEO e histórico, pode continuar lendo o resumo executivo.
Abaixo, você pode ver o gráfico do Segundo Projeto (Vizem.net) da SEMRush.
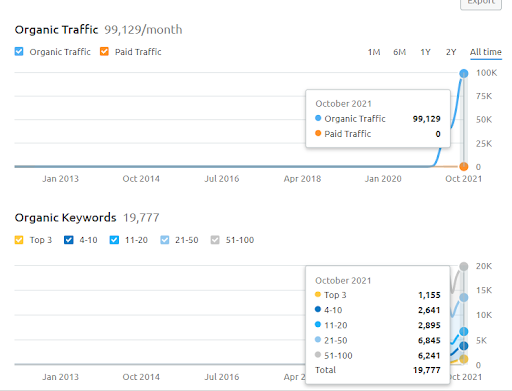
O gráfico SEMRush do Segundo Site. Vizem.net é uma fonte totalmente nova que visa indústrias com um alto nível de concorrentes enraizados, como “Aplicativo de Visto”. Especialmente, devido aos últimos eventos na Turquia, o nível de competição da indústria está aumentando. Assim, usar a perspectiva da Rede Semântica para criar uma Rede de Conteúdo é útil.
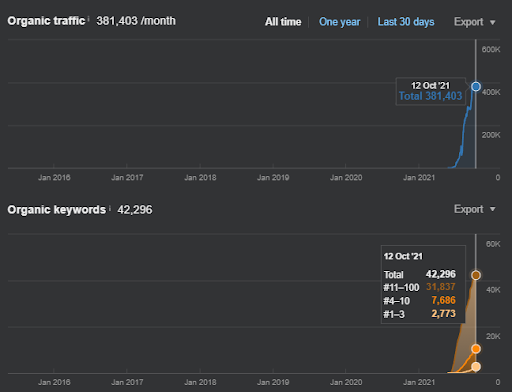
Primeiro Projeto: Istanbul Bogazici Enstitusu: Aumento de 600% de cliques orgânicos em 3 meses – Dados históricos alavancados e classificação inicial
IstanbulBogazici Enstitusu é um dos estudos de caso de SEO mais difíceis que realizei, não por causa dos motores de busca, mas por causa das pessoas e dos meus problemas de saúde. Assim, abandonei o projeto e não publiquei a terceira rede de conteúdo semântico que se destina a completar as relações semânticas com base no contexto da fonte. Mesmo que não tenha termos de domínio de conhecimento e frases contextuais implementadas corretamente, ele é configurado com níveis suficientes de conexões semânticas e precisão, para permitir um desempenho geral de pesquisa orgânica de mais de três milhões de sessões por mês se a terceira rede de conteúdo for publicado no futuro, respondendo também pelo efeito crescente da segunda rede de conteúdo semântico.
Abaixo, você verá as mudanças nos gráficos do IstanbulBogazici Enstitusu no GSC nos últimos 12 meses. O projeto foi lançado em maio de 2021 de forma adequada e finalizado em setembro de 2021 com a publicação de duas Redes de Conteúdo Semântico.
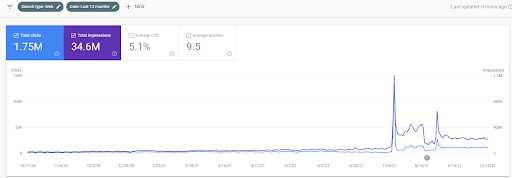
Abaixo você pode ver a versão mais detalhada. De 1.400 cliques diários a 140.000 cliques e, em seguida, mais de 10.000 cliques por dia podem ser vistos no desempenho da pesquisa orgânica
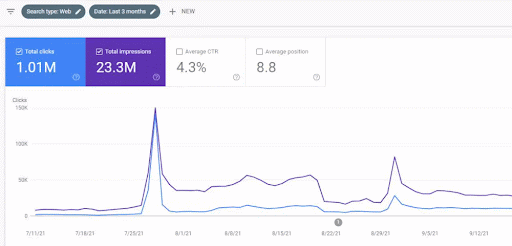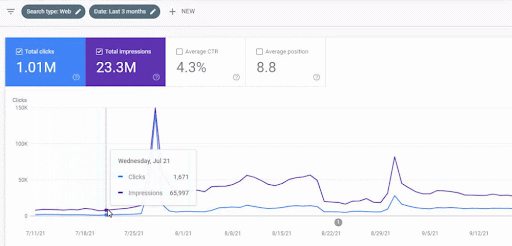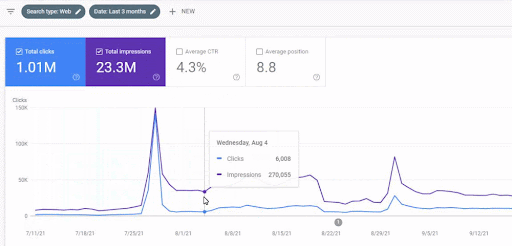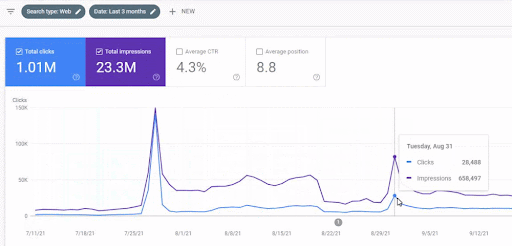
O aumento de tráfego da primeira rede de conteúdo após o lançamento pode ser visto abaixo.
Esta captura de tela mostra o 4º mês da Primeira Rede de Conteúdo Semântica.
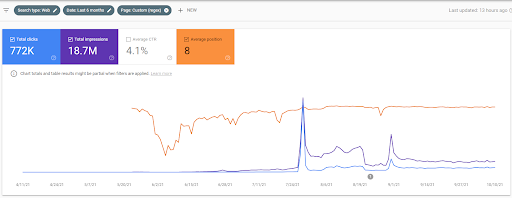
Como você pode ver no gráfico, todo o tráfego geral do site foi dominado e afetado pela Primeira Rede Semântica de Conteúdo, que se concentra nos “ramos educacionais”. A segunda rede de conteúdo que lancei com este site pode ser vista abaixo no Google Search Console. A captura de tela abaixo é do 16º dia da segunda rede de conteúdo semântico.
A classificação inicial e a reclassificação foram usadas no artigo porque definem as fases dos algoritmos de classificação junto com seus tipos e propósitos antes de testar uma fonte e uma página da Web da fonte dentro do SERP para consultas mais importantes que têm popularidade .
O que é a Primeira Rede de Conteúdo Semântico do Primeiro Projeto Focado?
“Rede de conteúdo semântico” usa uma rede semântica de uma base de conhecimento para explicar as relações principais, secundárias e terciárias entre as coisas dentro da base de conhecimento. Assim, a criação de uma rede de conteúdo semântico requer o desenho da próxima rede de conteúdo semântico com base no contexto da fonte que é a principal função do site. Nesse contexto, a primeira rede de conteúdo semântico se concentrou em “departamentos universitários, ramos educacionais e as necessidades de uma formação universitária dentro de uma organização e ramo específico”.
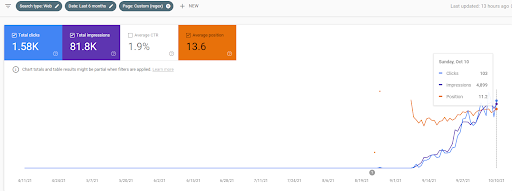
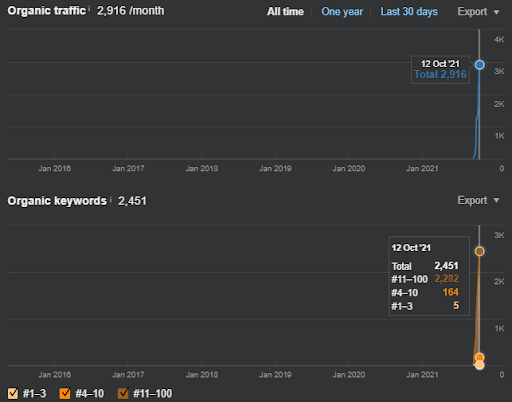
Abaixo, você encontrará o gráfico Ahrefs da Primeira Rede Semântica de Conteúdo.
Isso é cinco dias depois da captura de tela anterior.
“Raiz: istanbulbogazicienstitu.com/bolum”, após a primeira fase de classificação inicial, o processo de reclassificação é mais eficiente e produtivo.
Você pode ver a versão quatro dias depois como abaixo para apoiar a natureza da “reclassificação”.
O que é a Segunda Rede de Conteúdo Semântico do Primeiro Projeto Focado?
A segunda rede de conteúdo semântico focou nas ocupações, empregos, habilidades e educação necessária para essas habilidades, ou rotina. Com base na primeira rede de conteúdo semântico, a segunda rede de conteúdo semântico foi suportada. E, de acordo com os “modelos de consulta de modelos de intenção”, mais duas redes de subconteúdo semântico diferentes são criadas e colocadas com as “conexões relacionais” enquanto são conectadas aos níveis hierárquicos semelhantes superiores.
Eu sei que essas seções são complicadas para você porque você ainda não viu uma definição para as coisas abaixo.
- Rede de conteúdo semântico
- Contexto de origem
- Rede de subconteúdo semântico
- Base de conhecimento
- Conexões Relacionais
- Classificação inicial
- Reclassificação
- Cobertura contextual
- Classificação de comparação
- Extração de fatos
Depois de explicar o segundo site, ficará mais fácil entender esses conceitos e frases.
Vizem.net: de 0 a 9.000+ cliques diários por dia em 6 meses – classificação comparativa alavancada com cobertura contextual
Você pode ver o gráfico de Vizem.net nos últimos 12 meses. Para este projeto, devido ao Covid-19, tivemos muitos problemas econômicos, pois o investidor é do setor de academias. Assim, posso dizer que os problemas econômicos retardaram o projeto e causaram alguma latência para os “processos de reclassificação”.
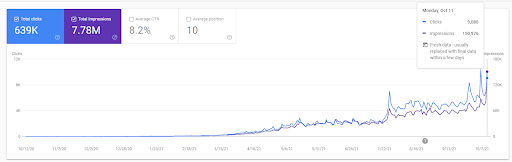
Para entender a classificação inicial e reclassificar um pouco mais, você pode usar o gráfico abaixo.
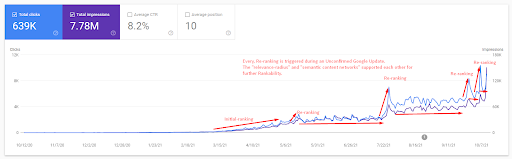
Algumas das definições relacionadas ao Ranking Inicial e ao Reranking do gráfico acima podem ser encontradas abaixo.
- Os grandes saltos de classificação aconteceram durante as atualizações não confirmadas do Google. Alguns testes deram alguns snippets em destaque e as pessoas também fizeram perguntas.
- Alguns testes do Google removeram os ganhos de FS e PAA.
- Todas as vezes, a linha do tempo entre dois processos de reclassificação foi menor.
- Os processos de reclassificação melhoraram a classificação da fonte sempre.
- A fonte sempre melhorou seu raio de relevância ao expandir os clusters de consulta.
Como apenas uma nota, posso deixar uma frase abaixo.
Se um mecanismo de pesquisa indexar sua página da web, isso não significa que o mecanismo de pesquisa entendeu a página da web. A indexação acontece mais rápido do que a compreensão e, na maioria das vezes, um mecanismo de pesquisa classifica uma página da web com previsões, “inicialmente”. Após o entendimento, acontece a “reclassificação”. 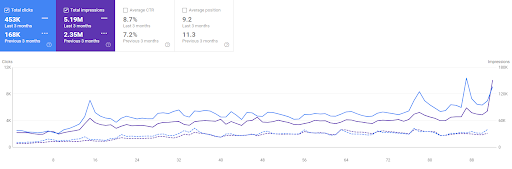
A comparação dos últimos 3 meses do Vizem.net
Como é a Rede de Conteúdo Semântico do Vizem.net?
Lembro-me que para muitos dos meus clientes, amigos ou grupos secretos de SEO, durante as reuniões, demonstrei esses dois sites dizendo: “eles vão explodir”. E, enquanto escrevo este artigo, estou lhe dizendo o seguinte:
Fique de olho na Rede de Conteúdo Semântico “istanbulbogazicienstitu.com/meslek”, porque ela vai explodir. E você pode encontrar um vídeo que publiquei antes de escrever este artigo, demonstrando os “Dados históricos” de um evento sazonal e seu efeito nos processos inicial e de reclassificação. Você pode ver abaixo.
Com base nisso, a Rede de Conteúdo Semântico do Vizem.net não é semelhante ao IstanbulBogazici Enstitusu, portanto, não usei um “nível intenso de cobertura tópica e aumento de dados históricos”, precisei criar a autoridade relacionada a determinados tipos de entidades, seus atributos e possíveis ações por trás das consultas para esses pares entidade-atributo. Vizem.net não tem apenas “ramos universitários educacionais”, ou as “ocupações e cursos online” dentro dele. Tem “países para pedidos de visto”. Assim, a criação de nível suficiente de Autoridade Tópica requer consistência ao longo do tempo com pelo menos 190 redes de conteúdo semântico diferentes.
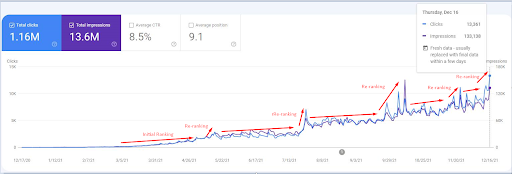
Uma captura de tela de 18 de dezembro de 2021. Você pode ver a reclassificação contínua e o aumento de impressões e cliques. Isso ocorre 4 semanas depois da captura de tela anterior.
Para ver os eventos de reclassificação, você pode comparar a versão simples do gráfico de desempenho de pesquisa orgânica que demonstra o efeito do SEO semântico. 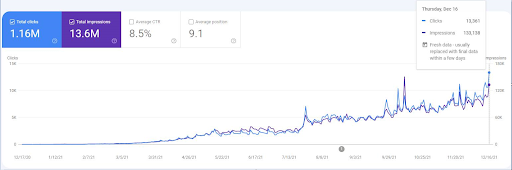
Essas 190 redes de conteúdo semântico diferentes são moldadas com base no próprio “país”, e os países são colocados no centro do mapa de tópicos com todas as camadas contextuais possíveis para melhorar a cobertura da atividade de pesquisa.
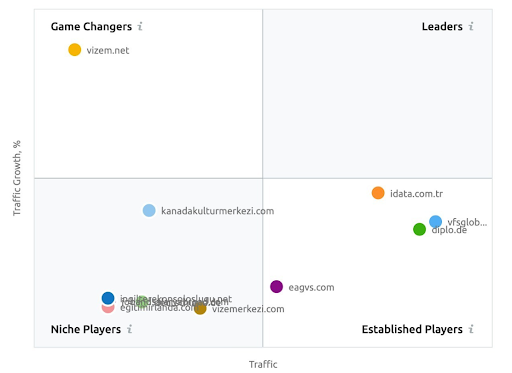
Uma captura de tela do SEMRush mostrando sua percepção do Vizem.net ao contrário de outros players do setor.
Também publiquei outro vídeo, apenas para Vizem.net. Neste vídeo, a última situação do site não existe, portanto, acredito, também fornece uma boa comparação entre hoje e aquele dia.
Por fim, publicar coisas irrelevantes em um artigo, segmento de site ou fonte irrelevante pode diminuir a relevância geral da entidade da web para o domínio de conhecimento específico. O Vizem.net mostrará seu valor real e a classificação no futuro será muito melhor.
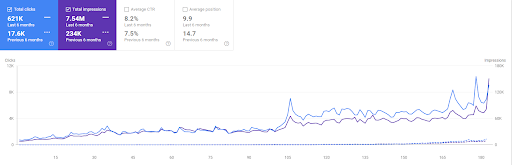
A comparação dos últimos 6 meses de Vizem.net.
Antes de continuar, sei que este é um longo artigo. Mas, na verdade, esta é uma breve explicação de uma metodologia de SEO altamente complexa. As redes de conteúdo semântico exigem muito pensamento ao projetá-las e meses de educação para clientes, autores e junto com a integração. Assim, neste artigo, quero focar nas definições dos conceitos com as melhores sugestões executáveis possíveis e importantes patentes do Google e de outros mecanismos de busca, artigos de pesquisa junto com seus próprios conceitos. Na versão longa (basicamente, um livro), concentrei-me no “ranking inicial” e no “reranking” das redes de conteúdo semântico.
Se você quiser saber mais, leia “Importância do Ranking Inicial e Re-ranking para SEO”.
Até agora, processamos as coisas abaixo.
- Rede Semântica
- Base de conhecimento
- Rede de conteúdo semântico
- Confiança baseada no conhecimento
- Cobertura contextual
- Domínio contextual e camadas
- Relevância do MuM para as redes de conteúdo semântico
- Contexto da fonte
Esses conceitos são para entender como as Redes de Conteúdo Semântico funcionam e como elas podem ser usadas com um mapa de tópicos. As próximas seções serão sobre como um mecanismo de busca classifica as redes de conteúdo semântico Inicialmente e posteriormente, Modificando. Neste contexto, as coisas abaixo serão processadas.
- Classificação inicial
- Reclassificação
- Modelo de consulta
- Modelo de documento
- Modelo de intenção de pesquisa
- O que você deve fazer para alavancar as redes de conteúdo semântico
O que é a classificação inicial para SEO?
Este é um novo termo e conceito para SEO, mas antigo para motores de busca. A versão longa do “Estudo de caso de SEO focado na rede semântica” se concentra nos algoritmos de classificação baseados em algoritmos dependentes de consulta, dependentes de documentos, dependentes de fontes e várias patentes. A Recuperação de Informações Preditiva ou algoritmos de classificação preditiva tentam diminuir o custo de computação. E, mesmo que a indexação aconteça em um dia, a compreensão de um documento pode levar meses ou até anos. Calcular uma classificação inicial é, portanto, uma maneira de melhorar a qualidade da SERP enquanto diminui o custo. Algumas tarefas relacionadas ao mecanismo de pesquisa têm prioridade mais alta do que outras para manter o índice ativo, atualizado e com qualidade alta o suficiente.

O termo classificação inicial aparece em dezenas de milhares de diferentes patentes do Google e documentos de pesquisa porque é uma perspectiva clássica entre os construtores de mecanismos de busca. Assim, acima, você pode ver diferentes documentos de patentes com continuação dos mesmos parágrafos, e termos com pequenas alterações em torno do termo de classificação inicial.
A classificação inicial representa a classificação de um documento na SERP imediatamente após ser indexado. A classificação inicial de um documento representa a autoridade geral e a relevância da fonte para o tópico específico, modelo de consulta e intenção de pesquisa. O mesmo conteúdo pode ser classificado de forma diferente em termos de classificação inicial entre diferentes fontes. A classificação inicial é importante ao usar as redes de conteúdo semântico para ver a qualidade geral e o aumento da autoridade da fonte. Cada novo documento aumenta sua classificação inicial enquanto diminui o atraso de indexação se o design da rede de conteúdo semântico estiver estruturado corretamente.
A classificação inicial suporta o processo de reclassificação e sua eficiência para a fonte. E, “Rankability of a source” deve ser processado com esses dois termos, inicial e reclassificação.
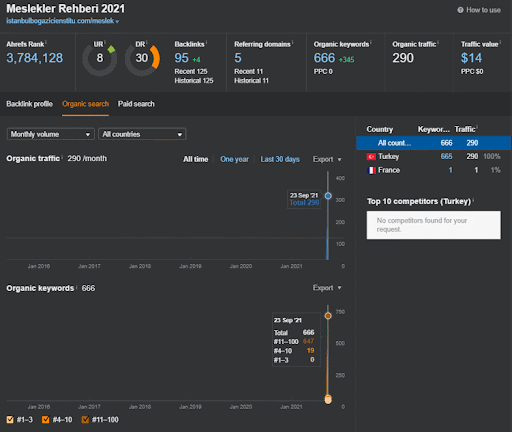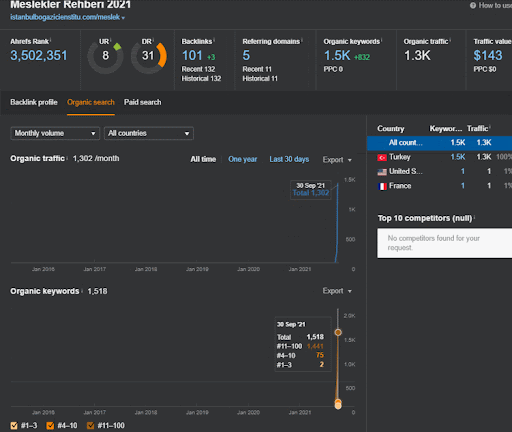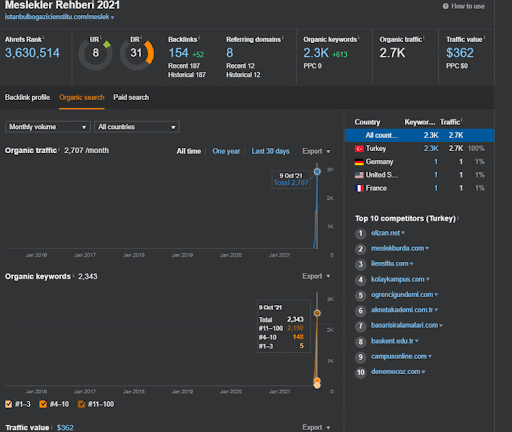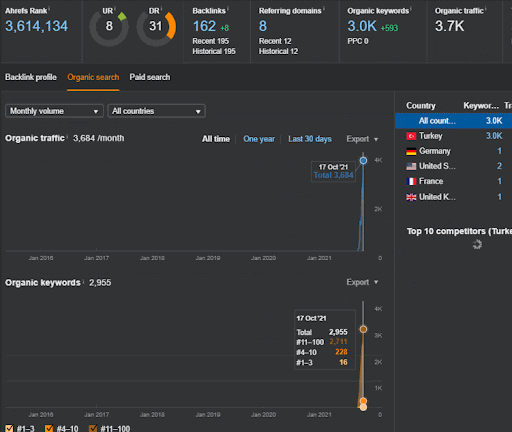
Você pode assistir aos primeiros 20 dias da mudança de desempenho orgânico da Segunda Rede de Conteúdo do Projeto I.
Nesse contexto, sempre que o Vizem.net publica um novo documento, ou sempre que o IstanbulBogazici Enstitu publica uma nova rede de conteúdo semântico, a classificação inicial é melhor do que antes, enquanto o conteúdo é indexado mais rapidamente.
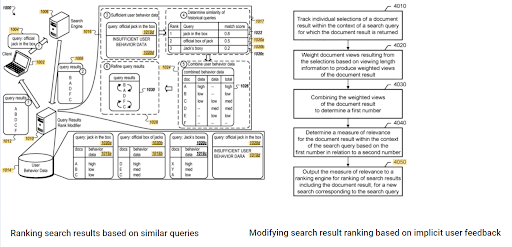
O destaque do ranking inicial e os dados históricos podem ser vistos entre essas duas patentes complementares do Google. Uma é para documentos iniciais e de reclassificação com base no feedback implícito do usuário. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 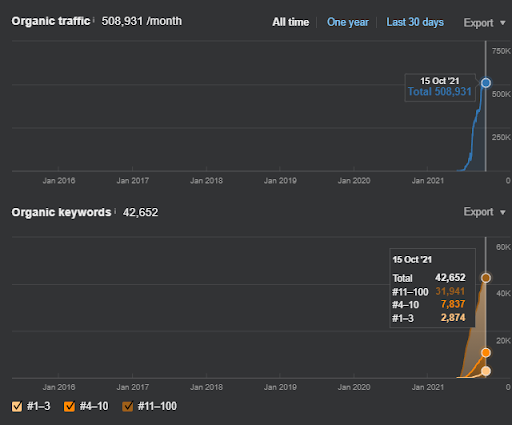
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 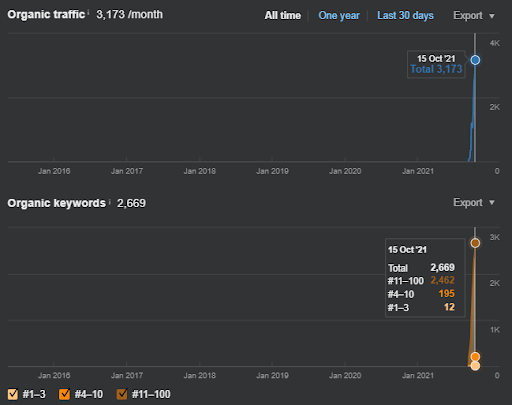
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 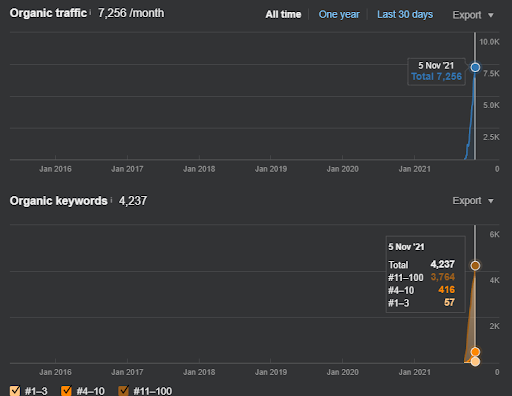
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 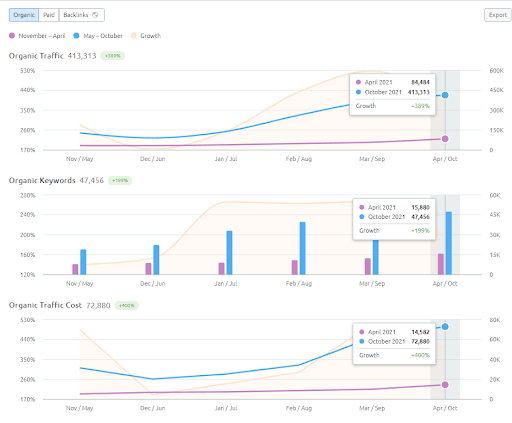
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Dados de rastreamento³
 Saber mais
Saber maisWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 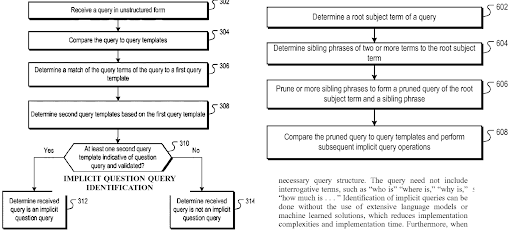
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
Sim, eles estão. O Ranking Probabilístico e o Ranking de Relevância Degradada são as colunas principais de um mecanismo de busca semântica para entender os usuários e criar a melhor SERP da mais alta qualidade possível, preparada para estados de possibilidades. 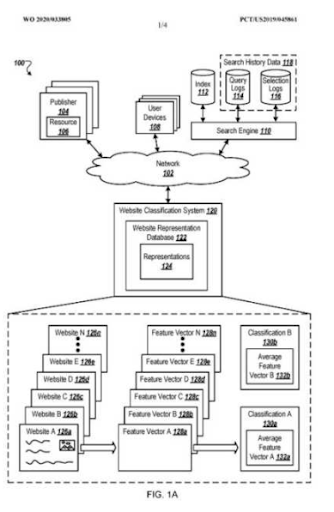
Anteriormente, para tornar “o design do site e a aparência ou a tonalidade” um argumento para a aprendizagem de representação para sites, Bill Slawski escreveu os “Vetores de Representação de Sites”.
O que é um modelo de intenção de pesquisa?
Um modelo de intenção de pesquisa pode ser representado pela necessidade por trás do modelo de consulta. Um modelo de documento de consulta pode ser unido com base em um modelo de intenção. Ter um modelo de intenção de pesquisa com o possível entendimento de "Classificação de relevância degradada" e "Classificação probabilística" ajudará a criar a melhor atividade de pesquisa possível e a cobertura de intenção de pesquisa com a ordem correta. Ao criar uma rede de conteúdo semântico, o mais importante é ajustar o modelo de intenção de consulta de documento com base no contexto da fonte para completar uma rede semântica baseada em um domínio de conhecimento, melhorando a cobertura contextual para melhorar a confiança baseada em conhecimento e autoridade tópica . 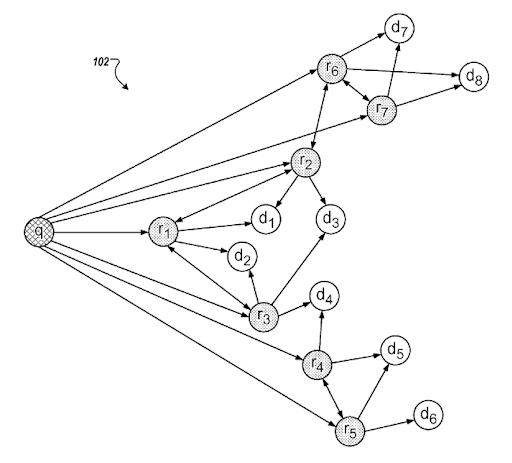
Uma seção de "Refinamentos de consulta com base na intenção inferida" do Google. Ele funciona por meio de clusters de consulta e modelos de intenção com conexões semânticas. Você pode experimentá-lo em diferentes níveis de taxonomia de frase.
Antes de passar para alguns exemplos concretos e sugestões para ajudá-lo a criar uma rede de conteúdo semântica melhor, devo dizer que mesmo a versão simples deste estudo de caso de SEO requer alto nível de compreensão e habilidades de comunicação. Assim, apesar de achar que dou informação de alto nível, sei que o curso de SEO Semântico que vou criar vai mostrar mais e melhores exemplos concretos. 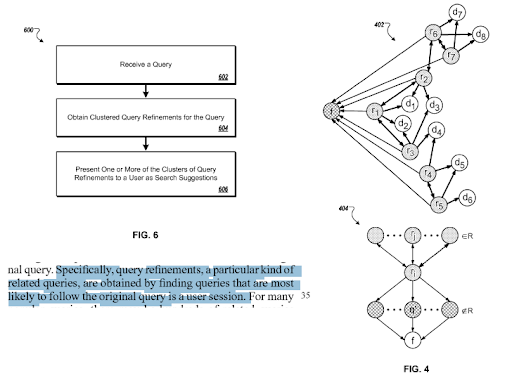
A mesma patente explica as conexões adequadas entre diferentes “caminhos de consulta” e “mudanças de contexto”.
O que você deve saber sobre como aproveitar as redes de conteúdo semântico?
Para criar uma Rede de Conteúdo Semântica, às vezes até mesmo um resumo e design de conteúdo semântico simples pode levar uma hora, se você colocar todos os detalhes relevantes com base na semântica lexical, ou nos tipos de relação entre entidades e frases. Usando vários ângulos ao mesmo tempo, como indexação baseada em frases e os vetores de palavras ou vetores de contexto para calcular a relevância contextual de um conteúdo geral para um domínio contextual, ou sua relevância com base nos tipos de subconteúdo individuais, requer alto nível de compreensão semântica do mecanismo de pesquisa.
Assim, usar uma metodologia generativa facilitará tudo com os conceitos que expliquei acima, porque mesmo que você prepare perfeitamente cada parte da rede de conteúdo semântico, os autores e redatores não conseguirão escrevê-la, ou os gerentes de conteúdo não será capaz de seguir sua visão. Assim, isso pode te cansar à toa, e fazer você sair de um projeto como eu fiz para alguns desses Projetos de Estudo de Caso de SEO depois de provar o conceito de maneira bastante, viva e auditável.
As sugestões abaixo serão apenas para etapas fáceis de executar e breves que o ajudarão.
1. Não use links fixos da barra lateral de todas as redes de rede de conteúdo semântico
Cada link deve ter uma descrição de conexão entre dois documentos de hipertexto, como cada palavra em uma página da web. O uso de HTML semântico pode ajudar a especificar a posição e a função de um documento em uma página da Web, ajudando os mecanismos de pesquisa a ponderar as seções de maneira diferente em termos de contexto.
No exemplo do Vizem.net, não usei o mesmo design da barra lateral. A barra lateral não mostrava os posts mais recentes, nem os mais críticos. As barras laterais mostram apenas os atributos das entidades centrais, e não são fixas, são dinâmicas. Em outras palavras, com base na hierarquia dentro do mapa de tópicos, as redes da rede de conteúdo semântico mudam mesmo se estiverem na barra lateral. 
Pensar nos modelos Reasonable Surfer e Cautious Surfer pode ajudar um SEO a criar uma maior relevância entre diferentes documentos de hipertexto.
Além disso, o link flui em termos de destaque, e a popularidade deve seguir o contexto da fonte a partir das melhores conexões possíveis. Abaixo, você pode ver as seções da barra lateral com códigos HTML semânticos ajustados. 
De acordo com a hierarquia do artigo que está ativo na sessão do usuário, as abas, a ordem das abas, os links dentro das abas serão alterados. O exemplo acima é da hierarquia de breadcrumb abaixo. ![]()
2. Apoie as redes de conteúdo semântico com o PageRank
Mesmo que o PageRank externo não seja obrigatório das fontes externas, se você puder usá-lo, perceberá que a classificação inicial e a reclassificação serão melhores. Para ambos os projetos, eu não os usei, mas desta vez, não era o propósito. Para Vizem.net, havia problemas econômicos, e eu não queria gastar o orçamento em relações públicas e divulgação digital. Para o Istanbul BogaziciEnstitusu, organizei algumas “fontes interconectadas localmente” para apoiar a autenticidade da fonte para o tópico específico, mas, novamente, a empresa não conseguiu implementar isso devido a questões orçamentárias e de disciplina organizacional. 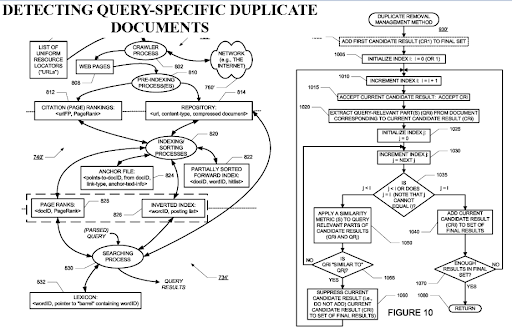
A detecção de documentos duplicados específicos da consulta é uma perspectiva importante dos mecanismos de pesquisa, porque o PageRank pode ajudar um documento a ser filtrado como valioso mesmo se estiver duplicado. Como as redes de conteúdo semântico altamente organizadas podem ser semelhantes entre si, o fluxo PageRank e os dados históricos são úteis.
Quando se trata de escolher o ponto de fluxo externo do PageRank para esses tipos de redes de conteúdo semântico, use as fontes com dados históricos. No meu caso, eu havia organizado esses pontos de extremidade do PageRank anteriormente, antes de lançar e publicar a primeira rede de conteúdo semântico. Dessa forma, consegui pegar referências externas de concorrentes diretos, mas quando publiquei a rede de conteúdo semântico, os concorrentes desistiram de vincular a fonte porque viram o aumento em massa da fonte como concorrente.
Essa situação nos leva à terceira sugestão. Se pudéssemos usar o fluxo PageRank de referências externas, o processo de reclassificação seria mais rápido e a classificação inicial seria maior.
3. Use textos âncora diferentes do rodapé, cabeçalho e conteúdo principal para as partes proeminentes da rede de conteúdo semântico
Os textos âncora ou o “texto do link” do ponto de vista do mecanismo de busca sinalizam a relevância de um documento de hipertexto para outro. De acordo com o documento original do PageRank, a contagem de links é proporcional ao fluxo do PageRank. Mas, mais tarde, o Google mudou isso para evitar o “enchimento de links” e limitou os links que podem realmente passar no PageRank. Com base nisso, são desenvolvidos os modelos TrustRank, Cautious Surfer, Hilltop Algorithm ou Reasonable Surfer Models. 
Estes são dois links para as duas redes de conteúdo semântico diferentes para o BogaziciEnstitusu, mas como não implementei melhorias técnicas de SEO ou UX, você pode perceber o “barato” dos designs dos botões.
Segundo o Google, o mesmo link não pode passar o PageRank uma segunda vez para outra página da web, enquanto o PageRank será passado apenas a partir do primeiro link. E, na forma original do algoritmo PageRank, um documento de hipertexto pode se vincular para melhorar seu PageRank, ou redirecionamentos 301 podem ser usados para obter o PageRank do documento de destino do link. Ambas as situações criaram técnicas antigas de Black Hat, como redirecionar uma página da web para outra temporariamente apenas para obter seu PageRank. Isso foi desde os dias em que os SEOs conseguiam ver o PageRank de uma página da web do Google Search Console ou do SERP. Mais tarde, o Google começou a diminuir o PageRank a cada redirecionamento, enquanto Danny Sullivan explicou que os redirecionamentos 301 passarão totalmente pelo PageRank. Além de todas essas mudanças, o importante aqui é que mesmo que o segundo link não passe no PageRank, ainda assim ele passa a relevância do texto do link. 
Seções proeminentes da rede de conteúdo semântico foram vinculadas a partir da página inicial com base nos “refinamentos de consulta intermediária” que incluem os “verbos, predicados” ou “atividades do pesquisador”.
Assim, as seções proeminentes da Rede de conteúdo semântico devem ser vinculadas a partir do menu de cabeçalho e rodapé com as seções de taxonomia mais altas, e os textos dos links devem ser diferentes uns dos outros. Nesses exemplos, usei os links de cabeçalho com os textos de link proeminentes, mas curtos, enquanto mantive os exemplos de rodapé por mais tempo. 
Uma seção da “Indexação de tags de âncora em um sistema de rastreador da web”, resume a importância de um texto âncora e texto de anotação para posicionar uma página da web dentro dos clusters de consulta e clusters de página da web.
Se a seção Rede de conteúdo semântico for muito proeminente, para passar o PageRank e a prioridade de rastreamento corretamente, vinculei as seções mais importantes com textos de link adequados e parágrafos explicativos que incluem os atributos proeminentes com diferentes variações de N-Grams relevantes. 
Esta é a segunda área vinculada da página inicial do Vizem.net, está atrás de um acordeão e se concentra nos países dentro das consultas e vincula a seção intermediária da rede de conteúdo semântico.
Nota: Em torno dos Textos Âncora, sempre foi utilizado um “texto de anotação” planejado para melhorar a precisão do propósito do link.
4. Limitar a restrição de contagem de links e combinar os links de desktop e móveis e o conteúdo principal
Ambos os projetos estão restritos a ter menos de 150 links internos por página da web. Com a ajuda do HTML semântico, os locais dos links e as funções dos links ficam claros para os rastreadores. O IstanbulBogazici Enstitusu tinha mais de 450 links por página da web, e alguns deles eram autolinks (um link da mesma página para a mesma página). A pior parte é que metade desses links não existia na versão móvel do conteúdo. 
A pontuação de manutenção de URL, a pontuação de rastreamento e outros tipos de pontuação podem ser usados para determinar a proeminência de um link no mapa de URL interno, e as tags de identificação de documento nas diferentes camadas podem ser usadas para classificar o índice com base em pontuações de relevância independentes de consulta.
Como o Google usa indexação somente para celular, se o conteúdo não existir na versão para celular, ele será ignorado e não será usado para fins de avaliação e classificação de relevância. Assim, o conteúdo móvel e de desktop foi configurado para ser combinado entre si. Mesmo que o Google tolere as incompatibilidades de conteúdo entre as versões para desktop e móvel, ainda dificulta o entendimento e a classificação de uma página da Web para os mecanismos de pesquisa. 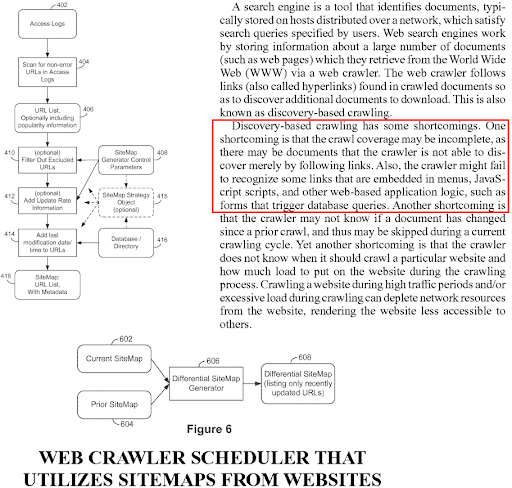
Um mecanismo de pesquisa pode gerar um mapa do site para o site, e esse mapa do site pode ser gerado novamente em um loop, se os links e os metadados da URL não corresponderem entre os agentes do usuário ou linhas do tempo. Assim, é importante manter o caminho de rastreamento curto, a fila de rastreamento breve e os links internos consistentes.
Juntamente com os links entre as diferentes páginas da web, também são usados links para as subseções das páginas da web com a “tabela do conteúdo” e os “Fragmentos de URL”. Esses fragmentos de URL segmentam uma subseção específica da página da Web enquanto a nomeiam corretamente, e a seção específica foi colocada em uma tag de seção com um h2. Com a ajuda de fragmentos de URL com os “links de navegação na página”, foi mais fácil direcionar um usuário do SERP para a seção específica da página da web, enquanto as seções inferiores do conteúdo ficaram mais proeminentes para satisfazer a necessidade por trás do consulta.
5. Tenha uma disciplina de nível militar para seus projetos de SEO
Este é um tópico totalmente diferente e outro artigo pode ser escrito para definir o que significa a disciplina de nível militar ou por que é útil para um projeto de SEO. Mas, devo dizer que durante esses últimos 2 meses, treinei muitos CEOs e SEOs de outras agências junto com suas equipes para ver se o design do meu curso funcionará bem ou não.
Sempre que vejo sucesso e um alto nível de apego às sessões de educação que realizo, há uma forte vontade e perseverança. O principal problema é que o SEO semântico é muito mais difícil do que os outros verticais de SEO. O SEO técnico é universal e tem até guias escritos para cada etapa. O OnPage SEO, ou WUX and Layout Design, pode ser rastreado com medidas numéricas. Quando se trata de Semântica, é a prática de unir a perspectiva de uma máquina que funciona com base em um sistema adaptativo complexo com homo-sapiens que não entendem como a máquina funciona.
Esta distinção requer uma base concreta que deve ser colocada desde o primeiro dia do projeto. Na maioria das vezes, eu uso as regras abaixo.
- Os designs de conteúdo e a rede de conteúdo semântica não precisam ser lógicos para um autor ou escritor.
- A tarefa do gerenciador de conteúdo é auditar a compatibilidade do conteúdo com o design do conteúdo.
- A tarefa do autor é escrever o conteúdo com as informações relacionadas que incluem um alto nível de precisão e detalhe.
- Os links, definições, evidências, comparações, proposições, referências devem ser feitas com exemplos concretos, não com bobagens.
- Cada palavra desnecessária é uma diluição do contexto e do conceito.
Quando você lê, pode parecer fácil de implementar, mas não é tão fácil. Assim, posso dizer que eu estava prestes a demitir alguns de meus próprios funcionários. Estou feliz por não ter feito isso, pelo menos por enquanto. Em condições normais, haverá muitas perguntas que serão feitas, se o proprietário da pergunta não for um SEO ou proprietário da empresa, não responda. Economize sua energia no armazenamento de dados do mecanismo de pesquisa que armazenará seu feedback positivo, não o feedback redundante e irrelevante para os rankings.
6. Expanda a fonte com relevância contextual
Esta seção é totalmente sobre a compreensão da necessidade do Google de criar o MuM. Quando você cria um Mapa de Tópicos, ele incluirá muitas Redes de Conteúdo Semântico que fornecerão uma Base de Conhecimento melhor no nível do site. Assim, ao publicar essas subseções, elas devem poder se conectar ao contexto da fonte, ou podem alterar a forma como o mecanismo de pesquisa vê a fonte, e o tema do site pode mudar para outro domínio de conhecimento. Por exemplo, conectar coisas em torno de conceitos e áreas de interesse com ações possíveis requer entender as conexões de significados complicados entre si. Tornar essas conexões claras para um usuário, um escritor e também uma máquina ao mesmo tempo é o processo de criação da Rede de Conteúdo Semântico. 
Para conseguir isso, cada nova seção do site deve poder ser conectada à seção central do mapa de tópicos. Essas pontes contextuais podem ser vistas no próprio design e explicação do LaMDA do Google.
Eu me deparo com muitas perguntas como “devo escrever sobre outro assunto”, “se eu tiver dois nichos diferentes, vai prejudicar?”. Se você conectar todas essas subseções, segmentos de sites como componentes fortemente conectados, essas redes de conteúdo semântico se apoiarão para obter melhores classificações em vez de dividir a identidade da marca e a autoridade tópica para dois tópicos diferentes e irrelevantes.
7. Crie tráfego real e audite com a segmentação personalizada do Google Analytics
O tráfego real é conectado ao RankMerge da mesma forma que o Knowledge-based Trust está conectado ao PageRank. Em breve, estou pensando em escrever outro artigo com o título de “Quando o PageRank mente…” para explicar por que o mecanismo de busca tenta afetar o PageRank com sinais laterais. Na verdade, o PageRank não é um sinal definitivo que mostra a autoridade, experiência e confiabilidade de uma fonte. Pode ser um sinal de classificação e um fator, mas não pode ser confiável sozinho. RankMerge é o processo de unir o tráfego do site e o PageRank de forma que o site faça sentido para o mecanismo de busca. Alto PageRank e baixo tráfego podem sinalizar o “tráfego impopular” ou a “manipulação do PageRank”.
Assim, para melhorar os dados históricos da fonte, usei os eventos sazonais de SEO e aumentei as consultas “marca + termo genérico”. O tráfego direto e as páginas da web marcadas aumentam com o tráfego real e autêntico.
Esses tipos de dados ajudam um mecanismo de pesquisa a confiar nele para classificá-lo cada vez mais alto na SERP.
Para poder auditar esse tráfego real que vem da Rede de Conteúdo Semântica, um SEO pode criar um segmento personalizado do Google Analytics para ver como eles chegam como tráfego direto. Além disso, metas personalizadas podem ser criadas, como criar uma possível jornada de pesquisa da primeira rede de conteúdo semântico para a segunda rede de conteúdo. Esta é a prova de conceito de que a rede semântica é construída em torno dos interesses, conceitos e possíveis ações relacionadas à busca.
Abaixo, você encontrará apenas um exemplo para uma das páginas da web que são colocadas na primeira rede de conteúdo semântico para demonstrar o tráfego direto adquirido via tráfego orgânico. 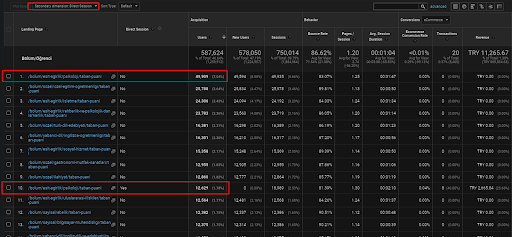
Nos últimos 3 meses, apenas uma página da primeira rede de conteúdo semântico foi usada pelos 49.000 usuários orgânicos. E, 12.900 usuários extras vieram como tráfego direto que foi adquirido pela busca orgânica pela primeira vez. E as métricas de sessão/página e a duração média da sessão são maiores para esses segmentos de usuários.
Como dito anteriormente, um mecanismo de pesquisa pode agrupar consultas, documentos, intenções, conceitos, interesses, ações, mas também pode agrupar usuários. Se um grupo de usuários deixa feedbacks positivos enquanto cria um valor de marca adicionando essas páginas da web aos favoritos, digitando diretamente na barra de endereços e pesquisando os termos genéricos junto com o nome da marca, isso mostra que a fonte melhora sua autoridade e o mecanismo de pesquisa é capaz de reconhecer tudo, desde o SERP, Chrome e seus próprios endereços DNS. 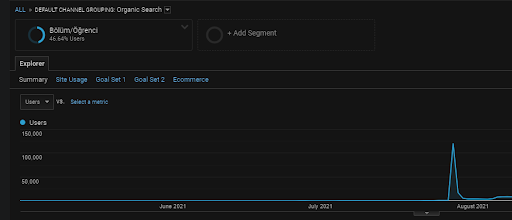
Acima, você pode ver o segmento de usuário da Primeira Rede de Conteúdo. Você pode criar um segmento de usuário para cada rede de conteúdo semântico com metas personalizadas e também pode adicionar segmentos de subusuário para as redes de subconteúdo semântico.
8. Suporte a redes de conteúdo semântico com subseções baseadas em atividades de pesquisa
Esta seção também é sobre resolução de atributo de entidade e análise, que é outro tópico. Mas, simplificando, alguns atributos dessas entidades com base em domínios contextuais devem ser colocados em uma hierarquia inferior, não na hierarquia superior. Neste caso, o “Vizem.net” pode dar um exemplo melhor, enquanto para o Bogazici Enstitusu, pode ser demonstrado com “Salários de Ocupações” e “Pontos de Exame de Universidades”. Esses dois atributos proeminentes foram colocados com base nos modelos de consulta e documento para as redes de subconteúdo semântico. 
A identificação de unidades semânticas de dentro de uma consulta de pesquisa é outra patente do Google que divide as frases em diferentes categorias semânticas e agrega a relevância de um documento com base em sua proximidade com todas as variações da consulta.
Em um estudo de caso de SEO anterior, eu não segui esse tipo de estrutura, criei um caminho de rastreamento baseado na “cronologia” e nos links internos que são estritamente limitados. Nesses artigos, a quantidade de links internos colocados no conteúdo principal é maior que a anterior.
9. Use palavras temáticas nos URLs
Se o Google encontrar dois URLs diferentes com o mesmo conteúdo sem nenhum sinal de canonização, ele escolherá o curto como o canônico. Porque, URLs curtos são mais fáceis de analisar, resolver e solicitar. Quando você tem trilhões de páginas da web que você atualiza bilhões de vezes todos os dias, até mesmo as letras em URLs podem mostrar o “equilíbrio custo/qualidade” de um site. Como eu disse antes, o “custo de recuperar” deve ser menor que o “custo de não recuperar”. Se você deseja ser entendido por um mecanismo de pesquisa, deve colocar os “sinais de contexto ordenados e complementares” em todos os níveis, incluindo os URLs. 
Uma seção do ranking “baseado em evidências” por meio de agregação de evidências. Ele explica como uma resposta pode ser combinada com uma pergunta.
Nesse contexto, na maioria das vezes, uso uma única palavra dentro da URL. Eles podem refletir a hierarquia e a estrutura da rede de conteúdo semântico. Alguns ainda pensam que a “contagem de camadas” na URL afeta a frequência de rastreamento, antes de 2019, era verdade. Mas, desde que o conteúdo faça sentido e satisfaça os usuários de um tópico popular ou proeminente, ele não será afetado por tal situação.
Para demonstrá-lo, você pode seguir o exemplo abaixo.
- Domínio-raiz/semantic-content-network-1/type-1/sub-content-network-part-for-type-1
- Domínio-raiz/semantic-content-network-2/type-2/sub-content-network-part-for-type-2
Essas duas redes de conteúdo semântico podem se vincular a partir da mesma hierarquia e também podem se vincular com base na relevância. Há mais coisas aqui sobre as quais podemos falar, como o “Conteúdo do Grupo de Entidades – Conteúdo do Tipo Hub”, mas é um tópico para outro dia.
Nota: A Terceira Rede de Conteúdo Semântica planejada também pode ser processada como uma “Rede de Conteúdo de Grupo Conceitual”. E, se for publicado, com o efeito da Segunda Rede Semântica de Conteúdo, o Tráfego Orgânico total pode ser superior a 3 milhões de sessões por mês.
10. Entenda a diferença entre aninhar e conectar
Como diferença metodológica prática, a conexão é a conexão de coisas semelhantes entre si com base em um domínio contextual, enquanto aninhamento é agrupar o conteúdo semelhante com o mesmo propósito. Esse agrupamento ajudará um mecanismo de pesquisa a encontrar conteúdo semelhante entre si mais rapidamente e a criação de um índice de qualidade de origem para esses grupos, ou esses conteúdos aninhados com base em uma rede semântica serão mais fáceis. 
Imagine que existem dois caminhos de rastreamento diferentes, conforme abaixo.
- Caminho de rastreamento 1: Encontra URLs aleatoriamente, sem modelo, semelhança e relevância contextual.
- Caminho de rastreamento 2: Encontra URLs que fazem sentido até mesmo a partir do próprio URL, com um modelo, alto nível de similaridade e relevância com base no contexto.
Se mesmo a partir do caminho de rastreamento, o conteúdo fizer sentido, o “ranking inicial” e o “reranking” serão melhores graças ao “disparo do reranking com base na compreensão da cobertura do mecanismo de pesquisa”.
Observação: o uso de links internos com taxonomia de frase de maneira adequada é importante para aninhamento e conexão.
Isso nos leva às duas últimas metodologias práticas compartilhando brevemente. E, esta seção está novamente relacionada ao alto nível de disciplina e suficiência organizacional. 
Uma patente de Trystan Upstill e Steven D. Baker por reconhecer os termos co-ocorrentes nas Listas HTML. A proeminência desta patente é que ela mostra o valor de uma única Lista HTML para determinar as listas de termos co-ocorrentes para um tópico ou uma parte da taxonomia de frases.
11. Entenda quando publicar uma rede de conteúdo semântico com uma frequência ajustada
Isso já foi explicado antes, mas em um desses projetos de estudo de caso de SEO, publiquei quase 400 conteúdos em um dia. Quando se trata do outro, comecei a publicar apenas 10 a 15 conteúdos de repente, depois aumentei a velocidade ao longo do tempo com firmeza até que os problemas econômicos relacionados ao Covid comecem.
Se uma nova fonte cria uma nova rede de conteúdo semântico, publicá-la no primeiro dia pode ser um pouco mais difícil do que você pensa, verificar todos os links internos, gramáticas e informações na página da web não é tão fácil. Mas, se todo o conteúdo for apenas de um único tópico, e um modelo de consulta, e se a fonte não tiver nenhum histórico sobre esse tópico, publicar a maior parte da rede de conteúdo semântico tem vantagens como indexação mais rápida, compreensão e reclassificação.
Na minha situação, também houve um evento histórico com sazonalidade. Então, meu objetivo era ter um nível suficiente de posição média até que eu pudesse ser testado pelo mecanismo de pesquisa para as entidades específicas e atividades de pesquisa em relação às fontes mais antigas. Assim, publiquei a primeira Rede de Conteúdo Semântico com alto nível de preparação antes dos 45 dias do evento sazonal.
Então, você pode ver como o Search Engine testou a fonte repetidamente como abaixo. 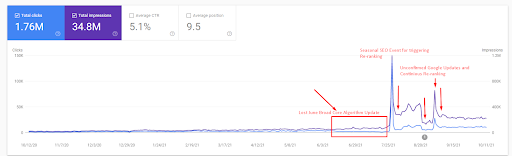
Uma explicação mais detalhada pode ser encontrada abaixo. 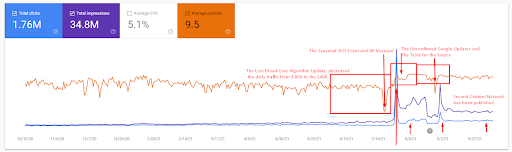
Uma verificação rápida de fatos pode ser encontrada abaixo para a explicação da captura de tela acima.
- A atualização do algoritmo Broad Core diminuiu o tráfego do site em mais de 200%.
- O site também perdeu mais de 15.000 consultas.
- Isso afetou a indexação geral da fonte para a nova rede de conteúdo semântico, pois o artigo detalhado do estudo de caso de SEO foi explicado melhor.
- Graças ao evento sazonal de SEO, a reclassificação aconteceu mais cedo e, após o evento sazonal de SEO, o mecanismo de pesquisa normalizou a classificação da fonte com base no tráfego real durante as atualizações não confirmadas.
- As consultas e os rankings adquiridos graças à Primeira Rede Semântica de Conteúdo e ao Evento Sazonal foram protegidos e aprimorados ainda mais.
- A primeira Rede de Conteúdo Semântico também apoiou a nova e a segunda Rede de Conteúdo Semântico.
A perda de consulta e a perda média de classificação também podem ser vistas no Ahrefs como abaixo. Você pode verificar o efeito do Google Broad Core Algorithm Update (GBCAU) de junho de 2021 junto com o efeito da atualização não confirmada. 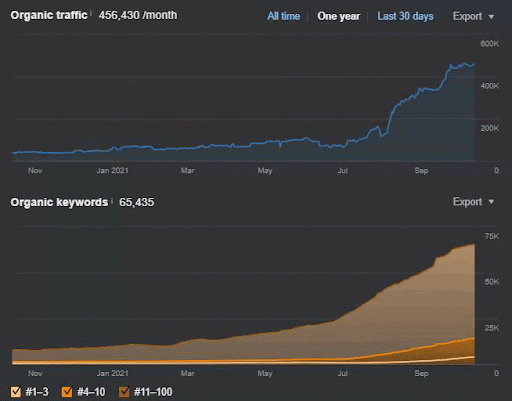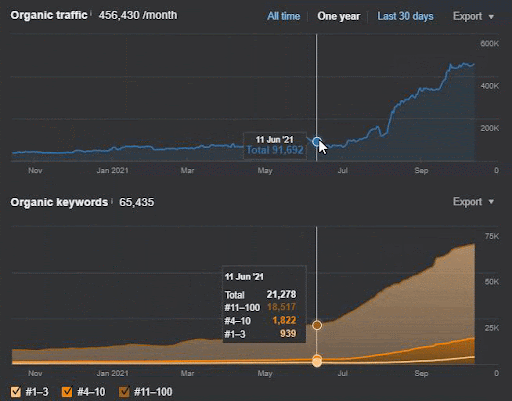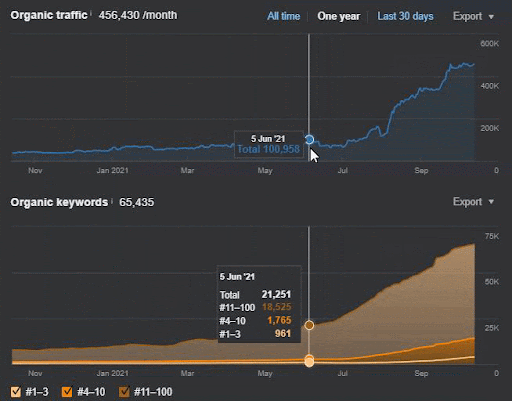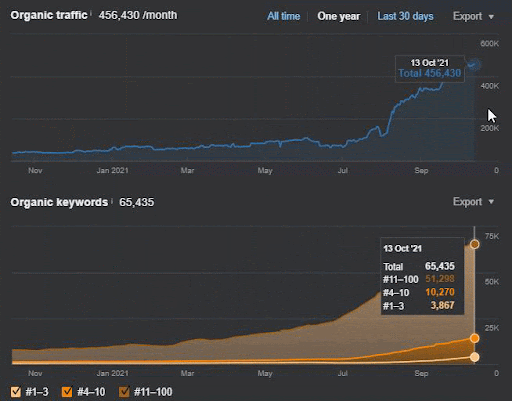
Assim, utilizar uma Rede de Conteúdo Semântica com múltiplas estratégias possíveis é uma necessidade. Mesmo que o GCBAU seja perdido, ainda assim, graças a outros fatores relacionados ao buscador natura pode ajudar um SEO. Assim, você pode imaginar por que explicar essas coisas para um autor ou um cliente é mais difícil do que o SEO técnico. SEO semântico não usa valores numéricos, ele usa conhecimento teórico que vem do entendimento do mecanismo de busca por meio de patentes, trabalhos de pesquisa, experiência e anúncios históricos.
12. Use a otimização de frases na página para uma melhor estrutura factual
Para ser honesto, mesmo a 10ª listagem é um tópico totalmente novo e pode exigir até mesmo escrever 20.000 palavras aqui. Mas, vou começar com um exemplo simples.
- X é Y.
- Y é X.
Para as frases de exemplo acima, você pode entender as coisas abaixo.
- As frases acima não são conteúdo duplicado.
- As proposições acima são duplicadas.
- As explicações relacionais entre duas frases são as mesmas.
- Os rótulos de função semântica são 100% diferentes.
- A saída do Reconhecimento de Entidade Nomeada é 100% a mesma.
A otimização de frases na página está relacionada aos algoritmos de geração de perguntas e às tecnologias de emparelhamento de perguntas e respostas. Um formato de pergunta requer um certo tipo de frase. E certos tipos de perguntas devem ser respondidas com certos tipos de frases. O formato do conteúdo, o NER e a Extração de Fatos serão afetados a partir da otimização da estrutura da frase. 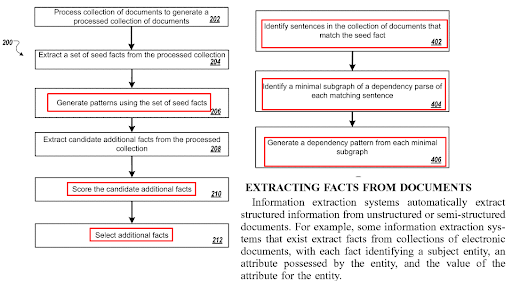
Os trigêmeos (um objeto, dois assuntos) podem ser extraídos e verificados em termos de precisão mais rapidamente. Duas frases semelhantes não significam que são duplicadas, significa que estão próximas uma da outra em termos de estrutura da frase. Desde que a proposição seja diferente, usar frases semelhantes entre modelos de documentos semelhantes para diferentes pares de intenção de consulta é uma necessidade para a criação de rede de conteúdo semântico. 
Estruturas de frases claras com um padrão adequado são úteis para tornar as partes de texto mais relevantes umas para as outras, ajudando um mecanismo de pesquisa a reconhecer entidades nomeadas, assuntos, atributos, juntamente com seus valores entre si.
Também ajudará a ver qual seção de um artigo pode ser melhorada e nas Redes Tópicas, onde seu conteúdo se classifica melhor para quais tipos de pares de palavras, vetores de palavras e intenções. Porque, se certos tipos de estruturas de frases para certos tipos de perguntas puderem ser observados em várias páginas da Web, isso ajudará nos testes A/B avançados de SEO com quantidades infinitas de amostras de dados e amostras de teste. Você pode criar vários designs de frases na página para verificar como um mecanismo de pesquisa extrai os fatos para compará-los. 
Quando se trata de dar os fatos, o “Cofre do Conhecimento” e o Luna Dong devem ser lembrados.
13. Forneça Informações do Mundo Real com Precisão e Consistência, Não Opiniões com Fluff
A precisão aqui significa poder ser comparado com valores numéricos, ou relações conceituais concretas. A consistência significa que você protege sua postura para a proposição específica. Por exemplo, não diga que “produto X é melhor para Y” para cada revisão de produto relacionada ao Y. Não dê proposições contraditórias em todo o site. E, se o produto é o melhor, qual é a prova disso? Material, o tamanho, ou a cor e o cheiro? Fluff dentro do texto significa que você usa palavras de ponte desnecessárias, ou não diz coisas que não são possíveis de provar, ou contradiz a verdade.
No contexto dessas instruções não-definitivas que são suportadas por alguns dos exemplos, você pode verificar um dos Modelos de Linguagem do Google que é KeALM.
É para gerar texto de um banco de dados com os modelos de dados para texto e para verificar a precisão do conteúdo. 
KELM é um exemplo de Auditoria de Precisão para as proposições com métodos text-to-data.
Este também é um pouco sobre a definição do “Triplet”, e “Extração de Informação Aberta para Entidades Desconhecidas”, mas como você sabe, esta é a versão resumida, e acho que já contei o suficiente. Basicamente, quando você fornece informações erradas em seu site, certifique-se de que o Google seja capaz de entendê-las para diminuir a Confiança Baseada em Conhecimento da fonte. Aqui, você também pode precisar saber que, como você pode expandir a base de conhecimento, um mecanismo de pesquisa pode alterar sua própria base de conhecimento com base em suas informações, se você tiver uma fonte correlacionada com PageRank e confiança na base de conhecimento com alta precisão e trigêmeos exclusivos.
14. Compreender a Árvore de Dependência Semântica para Entidades
Árvore de Dependência Semântica significa que atributos que sinalizam relacionamentos com outras entidades têm uma dependência hierárquica entre eles. A Árvore de Dependência Semântica pode ser observada verificando vários perfis e ângulos de entidades, como um país pode ser membro de uma organização e, como outra entidade, essa organização pode ter alguns outros atributos que podem ser atribuídos aos países conectados com relacionamentos inferidos.
Abaixo, você poderá ver um exemplo simples do Search Engine, diretamente. 
REALM é um método que usa Árvores de Dependência Semântica para extrair informações de texto ambíguo.
Na web aberta, a extração de informações abertas pode reconhecer novas entidades nomeadas e extrair essas mesmas entidades como ocorrendo concomitantemente com outras entidades. Essas co-ocorrências e atributos mútuos dentro do artigo podem atribuir um tipo de relação de contexto e candidato entre entidades. Com base nas conexões e no tipo da entidade, a árvore de dependência semântica pode ser criada. A mesma lógica também ocorre para a Semântica Lexical. A palavra “menino” tem alguns significados possíveis e alguns outros significados exatos. Por exemplo, um menino é um homem e provavelmente um adolescente que não é casado. Pode ser usado perto do aluno também. A palavra “rainha”, por outro lado, inclui outros significados laterais e exatos, como “feminino” e “ser governador”. Assim, ter algo para governar é uma hierarquia de árvore de dependência semântica natural que pode sinalizar alguns tipos de modelos de consulta, como “Queen of…” ou “For Quen”. These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 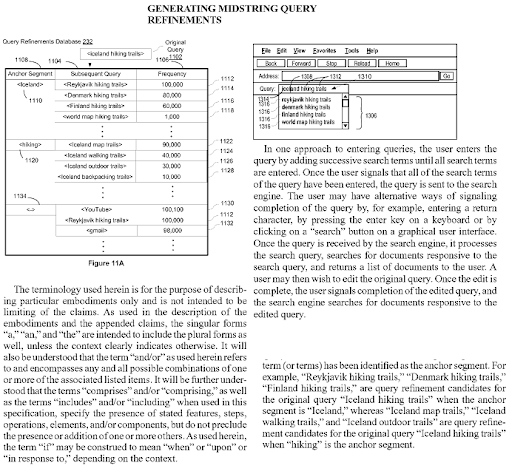
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.