
Controlando o rastreamento e a indexação: um guia de SEO para Robots.txt e tags
Publicados: 2019-02-19Otimizar o orçamento de rastreamento e bloquear bots de páginas de indexação são conceitos que muitos SEOs estão familiarizados. Mas o diabo está nos detalhes. Especialmente porque as melhores práticas mudaram significativamente nos últimos anos.
Uma pequena alteração em um arquivo robots.txt ou tags robots pode ter um impacto dramático em seu site. Para garantir que o impacto seja sempre positivo para o seu site, hoje vamos nos aprofundar em:
Otimizando o orçamento de rastreamento
O que é um arquivo Robots.txt
O que são Meta Robots Tags
O que são X-Robots-Tags
Diretivas de robôs e SEO
Lista de Verificação de Robôs de Melhores Práticas
Otimizando o orçamento de rastreamento
Um spider do mecanismo de pesquisa tem uma “provisão” para quantas páginas ele pode e deseja rastrear em seu site. Isso é conhecido como “orçamento de rastreamento”.
Encontre o orçamento de rastreamento do seu site no relatório "Estatísticas de rastreamento" do Google Search Console (GSC). Observe que o GSC é um agregado de 12 bots que nem todos são dedicados ao SEO. Ele também reúne bots do AdWords ou AdSense que são bots SEA. Assim, essa ferramenta fornece uma ideia do seu orçamento global de rastreamento, mas não sua repartição exata.
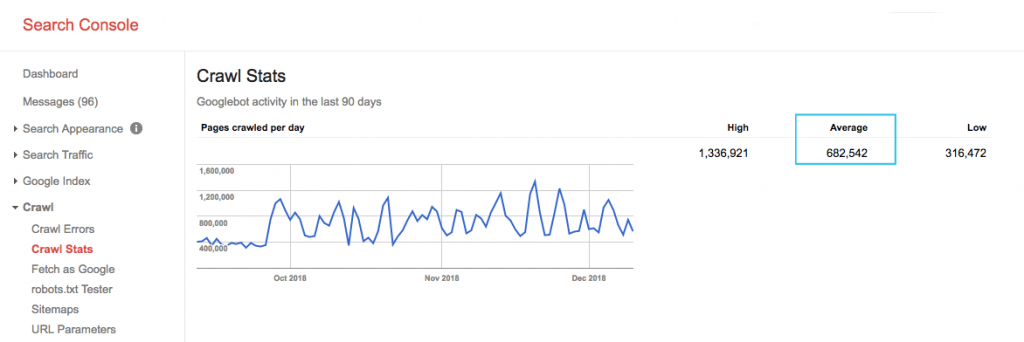
Para tornar o número mais acionável, divida a média de páginas rastreadas por dia pelo total de páginas rastreáveis em seu site – você pode solicitar o número ao seu desenvolvedor ou executar um rastreador de site ilimitado. Isso fornecerá uma taxa de rastreamento esperada para você começar a otimizar.
Quer ir mais fundo? Obtenha uma análise mais detalhada da atividade do Googlebot, como quais páginas estão sendo visitadas, bem como estatísticas de outros rastreadores, analisando os arquivos de registro do servidor do seu site.
Há muitas maneiras de otimizar o orçamento de rastreamento, mas um ponto de partida fácil é verificar o relatório "Cobertura" do GSC para entender o comportamento atual de rastreamento e indexação do Google.
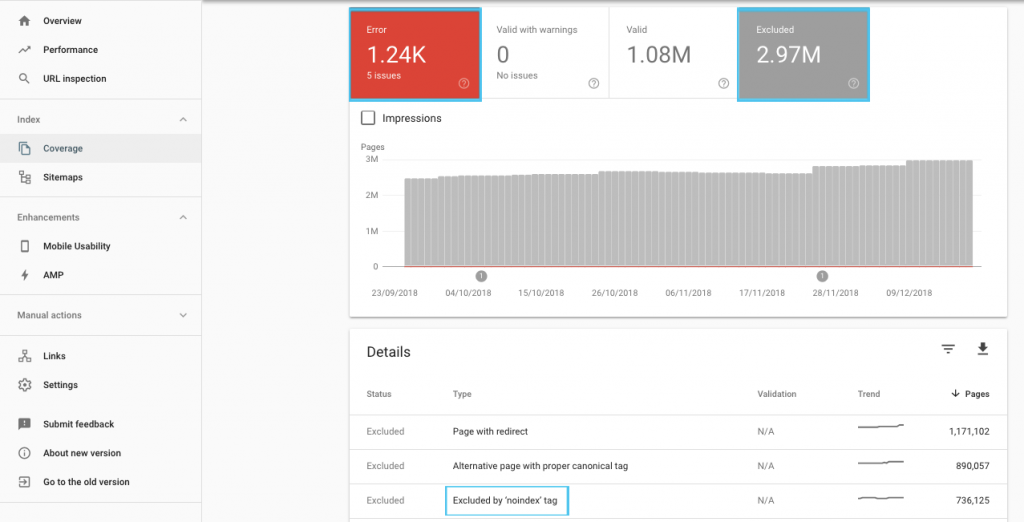
Se você vir erros como "URL enviado marcado como 'noindex'" ou "URL enviado bloqueado por robots.txt", trabalhe com seu desenvolvedor para corrigi-los. Para quaisquer exclusões de robôs, investigue-as para entender se são estratégicas do ponto de vista de SEO.
Em geral, os SEOs devem ter como objetivo minimizar as restrições de rastreamento em robôs. Melhorar a arquitetura do seu site para tornar as URLs úteis e acessíveis para os mecanismos de busca é a melhor estratégia.
O próprio Google observa que “uma arquitetura de informações sólida provavelmente será um uso muito mais produtivo de recursos do que focar na priorização de rastreamento”.
Dito isto, é benéfico entender o que pode ser feito com arquivos robots.txt e tags robots para orientar o rastreamento, a indexação e a transmissão do valor do link. E, mais importante, quando e como aproveitá-lo melhor para o SEO moderno.
[Estudo de caso] Gerenciando o rastreamento de bot do Google
 Leia o estudo de caso
Leia o estudo de casoO que é um arquivo Robots.txt
Antes de um mecanismo de pesquisa indexar qualquer página, ele verificará o arquivo robots.txt. Esse arquivo informa aos bots quais caminhos de URL eles têm permissão para visitar. Mas essas entradas são apenas diretivas, não mandatos.
Robots.txt não pode impedir de forma confiável o rastreamento como um firewall ou proteção por senha. É o equivalente digital de um sinal de “por favor, não entre” em uma porta destrancada.
Rastreadores educados, como os principais mecanismos de pesquisa, geralmente obedecerão às instruções. Rastreadores hostis, como raspadores de e-mail, spambots, malware e aranhas que verificam vulnerabilidades do site, geralmente não prestam atenção.
Além do mais, é um arquivo disponível publicamente . Qualquer um pode ver suas diretivas.
Não use seu arquivo robots.txt para:
- Para ocultar informações confidenciais. Use proteção por senha.
- Para bloquear o acesso ao seu site de teste e/ou desenvolvimento. Use a autenticação do lado do servidor.
- Para bloquear explicitamente rastreadores hostis. Use bloqueio de IP ou bloqueio de agente de usuário (também conhecido como impedir o acesso de um rastreador específico com uma regra em seu arquivo .htaccess ou uma ferramenta como CloudFlare).
Todo site deve ter um arquivo robots.txt válido com pelo menos um agrupamento de diretivas. Sem um, todos os bots recebem acesso total por padrão – portanto, cada página é tratada como rastreável. Mesmo que seja isso que você pretende, é melhor deixar isso claro para todos os interessados com um arquivo robots.txt. Além disso, sem um, os logs do seu servidor estarão repletos de solicitações com falha para robots.txt.
Estrutura de um arquivo robots.txt
Para ser reconhecido pelos rastreadores, seu robots.txt deve:
- Seja um arquivo de texto chamado “robots.txt”. O nome do arquivo diferencia maiúsculas de minúsculas. “Robots.TXT” ou outras variações não funcionarão.
- Estar localizado no diretório de nível superior de seu domínio canônico e, se relevante, subdomínios. Por exemplo, para controlar o rastreamento em todos os URLs abaixo de https://www.example.com, o arquivo robots.txt deve estar localizado em https://www.example.com/robots.txt e para subdomain.example.com em subdomínio.exemplo.com/robots.txt.
- Retorne um status HTTP de 200 OK.
- Use a sintaxe robots.txt válida – verifique usando a ferramenta de teste robots.txt do Google Search Console.
Um arquivo robots.txt é composto de agrupamentos de diretivas. As entradas consistem principalmente em:
- 1. User-agent: aborda os vários crawlers. Você pode ter um grupo para todos os robôs ou usar grupos para nomear mecanismos de pesquisa específicos.
- 2. Disallow: Especifica os arquivos ou diretórios a serem excluídos do rastreamento pelo agente do usuário acima. Você pode ter uma ou mais dessas linhas por bloco.
Para obter uma lista completa de nomes de agentes de usuário e mais exemplos de diretivas, confira o guia robots.txt no Yoast.
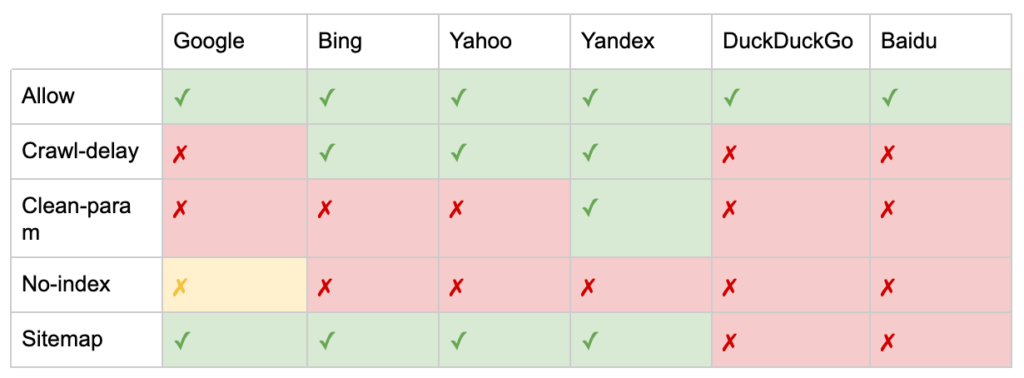
Além das diretivas “User-agent” e “Disallow”, existem algumas diretivas não padrão:
- Permitir: Especifique exceções para uma diretiva não permitir para um diretório pai.
- Atraso no rastreamento: Acelere os rastreadores pesados informando aos bots quantos segundos devem esperar antes de visitar uma página. Se você estiver recebendo poucas sessões orgânicas, o atraso no rastreamento pode economizar largura de banda do servidor. Mas eu investiria o esforço apenas se os rastreadores estivessem causando problemas de carga no servidor ativamente. O Google não reconhece esse comando, oferece a opção de limitar a taxa de rastreamento no Google Search Console.
- Clean-param: evite rastrear novamente o conteúdo duplicado gerado por parâmetros dinâmicos.
- Sem índice: projetado para controlar a indexação sem usar nenhum orçamento de rastreamento. Não é mais oficialmente suportado pelo Google. Embora haja evidências de que ainda possa ter impacto, não é confiável e não é recomendado por especialistas como John Mueller.
@maxxeight @google @DeepCrawl Eu realmente evitaria usar o noindex lá.
— ???? John ???? (@JohnMu) 1º de setembro de 2015
- Mapa do site: A maneira ideal de enviar seu mapa do site XML é por meio do Google Search Console e das Ferramentas do Google para webmasters de outros mecanismos de pesquisa. No entanto, adicionar uma diretiva de sitemap na base do arquivo robots.txt ajuda outros rastreadores que podem não oferecer uma opção de envio.
Limitações do robots.txt para SEO
Já sabemos que o robots.txt não pode impedir o rastreamento de todos os bots. Da mesma forma, não permitir rastreadores de uma página não impede que ela seja incluída nas páginas de resultados do mecanismo de pesquisa (SERPs).
Se uma página bloqueada tiver outros sinais de classificação fortes, o Google pode considerar relevante exibi-la nos resultados da pesquisa. Apesar de não ter rastreado a página.
Como o conteúdo desse URL é desconhecido para o Google, o resultado da pesquisa fica assim:

Para bloquear definitivamente a exibição de uma página em SERPs, você precisa usar uma metatag de robôs “noindex” ou um cabeçalho HTTP X-Robots-Tag.
Nesse caso, não bloqueie a página em robots.txt , pois a página deve ser rastreada para que a tag “noindex” seja vista e obedecida. Se o URL estiver bloqueado, todas as tags robots serão ineficazes.
Além disso, se uma página acumulou muitos links de entrada, mas o Google está impedido de rastrear essas páginas pelo robots.txt, enquanto os links são conhecidos pelo Google, o valor do link é perdido.
O que são Meta Robots Tags
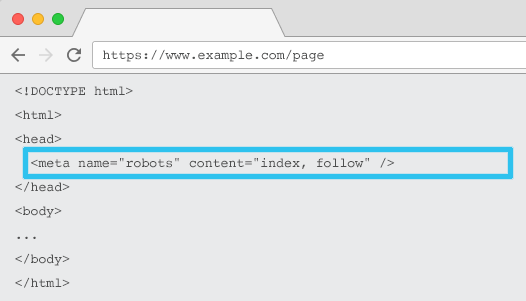
Colocado no HTML de cada URL, o meta name=”robots” informa aos rastreadores se e como “indexar” o conteúdo e se “seguir” (ou seja, rastrear) todos os links da página, repassando o valor do link.
Usando o meta name=“robots” geral, a diretiva se aplica a todos os rastreadores. Você também pode especificar um agente de usuário específico. Por exemplo, meta nome=”googlebot”. Mas é raro precisar usar várias meta tags de robôs para definir instruções para aranhas específicas.
Há duas considerações importantes ao usar meta tags de robôs:
- Semelhante ao robots.txt, as metatags são diretivas, não mandatos, portanto, podem ser ignoradas por alguns bots.
- A diretiva robots nofollow só se aplica a links nessa página. É possível que um rastreador siga o link de outra página ou site sem um nofollow. Portanto, o bot ainda pode chegar e indexar sua página indesejada.
Aqui está a lista de todas as diretivas de meta tags de robôs:
- index: diz aos mecanismos de pesquisa para mostrar esta página nos resultados de pesquisa. Este é o estado padrão se nenhuma diretiva for especificada.
- noindex: Diz aos mecanismos de pesquisa para não mostrar esta página nos resultados de pesquisa.
- follow: Diz aos motores de busca para seguirem todos os links nesta página e passarem equidade, mesmo que a página não esteja indexada. Este é o estado padrão se nenhuma diretiva for especificada.
- nofollow: Diz aos mecanismos de pesquisa para não seguir nenhum link nesta página ou passar o patrimônio.
- todos: Equivalente a “indexar, seguir”.
- none: Equivalente a “noindex, nofollow”.
- noimageindex: Diz aos motores de busca para não indexar nenhuma imagem nesta página.
- noarchive: Diz aos mecanismos de pesquisa para não mostrar um link em cache para esta página nos resultados da pesquisa.
- nocache: Igual ao noarchive, mas usado apenas pelo Internet Explorer e Firefox.
- nosnippet: instrui os mecanismos de pesquisa a não mostrarem uma meta descrição ou visualização de vídeo para esta página nos resultados da pesquisa.
- notranslate: Diz ao mecanismo de pesquisa para não oferecer tradução desta página nos resultados da pesquisa.
- unavailable_after: Diga aos mecanismos de pesquisa para não indexar mais esta página após uma data especificada.
- noodp: agora obsoleto, uma vez impediu os mecanismos de pesquisa de usar a descrição da página do DMOZ nos resultados da pesquisa.
- noydir: agora obsoleto, uma vez impediu o Yahoo de usar a descrição da página do diretório do Yahoo nos resultados de pesquisa.
- noyaca: Impede que o Yandex use a descrição da página do diretório Yandex nos resultados da pesquisa.
Conforme documentado pelo Yoast, nem todos os mecanismos de pesquisa suportam todas as metatags de robôs, ou até mesmo são claros o que eles fazem e o que não suportam.
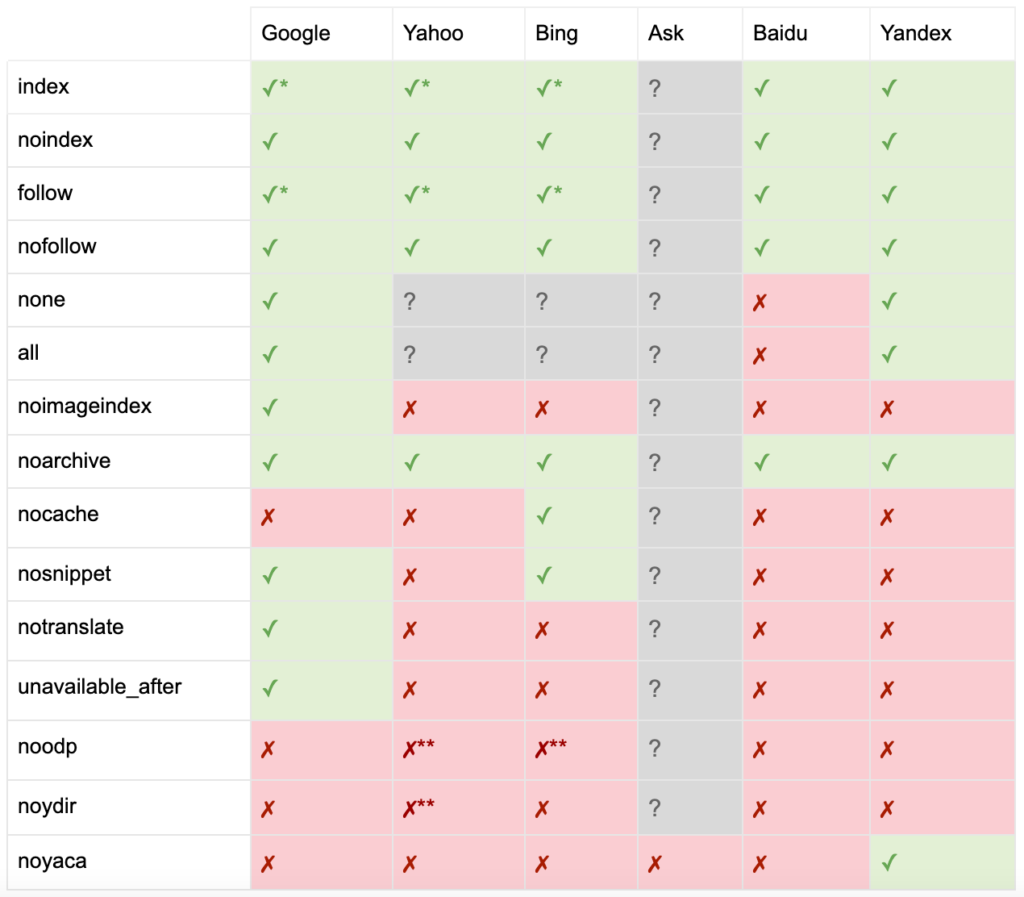
* A maioria dos mecanismos de busca não possui documentação específica para isso, mas assume-se que o suporte para a exclusão de parâmetros (por exemplo, nofollow) implica suporte para o equivalente positivo (por exemplo, follow).
** Embora os atributos noodp e noydir ainda possam ser 'suportados', os diretórios não existem mais e é provável que esses valores não façam nada.
Normalmente, as tags robots serão definidas como “index, follow”. Alguns SEOs consideram a adição dessa tag no HTML tão redundante quanto o padrão. O contra-argumento é que uma especificação clara de diretivas pode ajudar a evitar qualquer confusão humana.

Observe: URLs com uma tag “noindex” serão rastreados com menos frequência e, se estiverem presentes por muito tempo, eventualmente levarão o Google a não seguir os links da página.
É raro encontrar um caso de uso para “nofollow” em todos os links em uma página com uma metatag de robôs. É mais comum ver “nofollow” adicionado em links individuais usando um atributo de link rel=”nofollow”. Por exemplo, você pode considerar adicionar um atributo rel=”nofollow” a comentários gerados pelo usuário ou links pagos.
É ainda mais raro ter um caso de uso de SEO para diretivas de tags de robôs que não abordam a indexação básica e seguem o comportamento, como armazenamento em cache, indexação de imagens e manipulação de snippets, etc.
O desafio com meta tags de robôs é que elas não podem ser usadas para arquivos não HTML, como imagens, vídeos ou documentos PDF. É aqui que você pode recorrer aos X-Robots-Tags.
O que são X-Robots-Tags
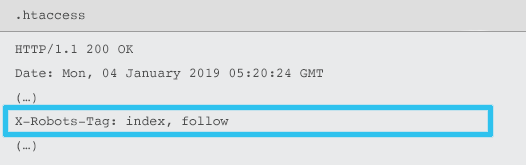
X-Robots-Tag são enviados pelo servidor como um elemento do cabeçalho de resposta HTTP para uma determinada URL usando arquivos .htaccess e httpd.conf.
Qualquer diretiva de metatag de robôs também pode ser especificada como uma X-Robots-Tag. No entanto, um X-Robots-Tag oferece alguma flexibilidade e funcionalidade adicionais.
Você usaria X-Robots-Tag sobre tags meta robots se quiser:
- Controle o comportamento dos robôs para arquivos não HTML, em vez de apenas para arquivos HTML.
- Controle a indexação de um elemento específico de uma página, em vez da página como um todo.
- Adicione regras sobre se uma página deve ou não ser indexada. Por exemplo, se um autor tiver mais de 5 artigos publicados, indexe sua página de perfil.
- Aplique diretivas index & follow em todo o site, em vez de em uma página específica.
- Use expressões regulares.
Evite usar meta-robôs e x-robots-tag na mesma página – isso seria redundante.
Para visualizar X-Robots-Tags, você pode usar o recurso “Fetch as Google” no Google Search Console.
Diretivas de robôs e SEO
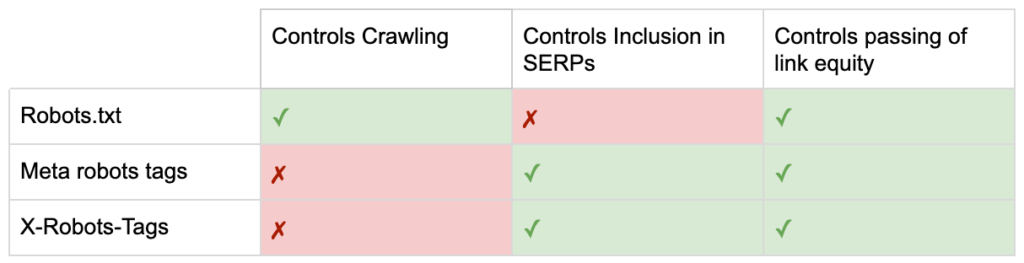
Então agora você conhece as diferenças entre as três diretivas de robôs.
O robots.txt tem como objetivo economizar o orçamento de rastreamento, mas não impede que uma página seja exibida nos resultados da pesquisa. Ele atua como o primeiro gatekeeper do seu site, direcionando os bots para não acessarem antes que a página seja solicitada.
Ambos os tipos de tags de robôs se concentram no controle da indexação e na passagem do patrimônio do link. As metatags de robôs só são efetivas após o carregamento da página . Enquanto os cabeçalhos X-Robots-Tag oferecem controle mais granular e são eficazes depois que o servidor responde a uma solicitação de página.
Com esse entendimento, os SEOs podem evoluir a maneira como usamos as diretivas de robôs para resolver os desafios de rastreamento e indexação.
Bloqueando bots para economizar largura de banda do servidor
Problema: Ao analisar seus arquivos de log, você verá muitos agentes do usuário consumindo largura de banda, mas devolvendo pouco valor.
- Rastreadores de SEO, como MJ12bot (da Majestic) ou Ahrefsbot (da Ahrefs).
- Ferramentas que salvam conteúdo digital offline, como Webcopier ou Teleport.
- Motores de busca que não são relevantes em seu mercado, como Baiduspider ou Yandex.
Solução sub-ótima: bloquear esses spiders com robots.txt, pois não é garantido que seja honrado e é uma declaração bastante pública, que pode fornecer informações competitivas às partes interessadas.
Abordagem de melhor prática: A diretiva mais sutil de bloqueio de agente de usuário. Isso pode ser feito de diferentes maneiras, mas geralmente é feito editando seu arquivo .htaccess para redirecionar quaisquer solicitações de aranha indesejadas para uma página 403 – Proibida.
Páginas internas de pesquisa de sites usando orçamento de rastreamento
Problema: em muitos sites, as páginas internas de resultados de pesquisa do site são geradas dinamicamente em URLs estáticos, que consomem o orçamento de rastreamento e podem causar conteúdo fraco ou problemas de conteúdo duplicado se indexados.
Solução subótima: não permita o diretório com robots.txt. Embora isso possa evitar armadilhas do rastreador, isso limita sua capacidade de classificação para as principais pesquisas de clientes e para que essas páginas passem o valor do link.
Abordagem de prática recomendada: mapeie consultas relevantes e de alto volume para URLs amigáveis para mecanismos de pesquisa existentes. Por exemplo, se eu pesquisar por “telefone samsung”, em vez de criar uma nova página para /search/samsung-phone, redirecione para o arquivo /phones/samsung.
Onde isso não for possível, crie um URL baseado em parâmetro. Você pode especificar facilmente se deseja que o parâmetro seja rastreado ou não no Google Search Console.
Se você permitir o rastreamento, analise se essas páginas são de qualidade alta o suficiente para classificar. Caso contrário, adicione uma diretiva “noindex, follow” como uma solução de curto prazo enquanto você cria estratégias para melhorar a qualidade dos resultados para auxiliar o SEO e a experiência do usuário.
Parâmetros de bloqueio com robôs
Problema: parâmetros de string de consulta, como aqueles gerados por navegação ou rastreamento facetado, são notórios por consumir o orçamento de rastreamento, criar URLs de conteúdo duplicados e dividir os sinais de classificação.
Solução sub-ótima: Proibir o rastreamento de parâmetros com robots.txt ou com uma metatag de robôs “noindex”, pois ambos (o primeiro imediatamente, o segundo por um período mais longo) impedirão o fluxo do patrimônio do link.
Abordagem de prática recomendada: certifique-se de que cada parâmetro tenha um motivo claro de existência e implemente regras de ordenação, que usam chaves apenas uma vez e evitam valores vazios. Adicione um atributo de link rel=canonical a páginas de parâmetros adequadas para combinar a capacidade de classificação. Em seguida, configure todos os parâmetros no Google Search Console, onde há opções mais granulares para comunicar as preferências de rastreamento. Para obter mais detalhes, consulte o guia de manipulação de parâmetros do Search Engine Journal.
Bloqueando Áreas de Administrador ou Conta
Problema: impede que o mecanismo de pesquisa rastreie e indexe qualquer conteúdo privado.
Solução subótima: usar robots.txt para bloquear o diretório, pois isso não garante a manutenção de páginas privadas fora das SERPs.
Abordagem de prática recomendada: use proteção por senha para impedir que os rastreadores acessem as páginas e um fallback da diretiva “noindex” no cabeçalho HTTP.
Bloqueando páginas de destino de marketing e páginas de agradecimento
Problema: muitas vezes você precisa excluir URLs não destinados à pesquisa orgânica, como e-mail dedicado ou páginas de destino de campanha de CPC. Da mesma forma, você não quer que as pessoas que não se converteram visitem suas páginas de agradecimento por meio de SERPs.
Solução subótima: não permita os arquivos com robots.txt, pois isso não impedirá que o link seja incluído nos resultados da pesquisa.
Abordagem de prática recomendada: use uma metatag “noindex”.
Gerenciar conteúdo duplicado no local
Problema: alguns sites precisam de uma cópia de conteúdo específico por motivos de experiência do usuário, como uma versão amigável para impressão de uma página, mas desejam garantir que a página canônica, e não a página duplicada, seja reconhecida pelos mecanismos de pesquisa. Em outros sites, o conteúdo duplicado se deve a práticas de desenvolvimento inadequadas, como renderizar o mesmo item para venda em URLs de várias categorias.
Solução abaixo do ideal: não permitir os URLs com robots.txt impedirá que a página duplicada transmita quaisquer sinais de classificação. Noindexing para robôs, eventualmente levará o Google a tratar os links como “nofollow” também, impedirá que a página duplicada transmita qualquer valor de link.
Abordagem de prática recomendada: se o conteúdo duplicado não tiver motivo para existir, remova a fonte e o redirecionamento 301 para a URL amigável do mecanismo de pesquisa. Se houver uma razão para existir, adicione um atributo de link rel=canonical para consolidar os sinais de classificação.
Conteúdo reduzido das páginas relacionadas à conta acessível
Problema: as páginas relacionadas à conta, como login, registro, carrinho de compras, checkout ou formulários de contato, geralmente são de conteúdo leve e oferecem pouco valor para os mecanismos de pesquisa, mas são necessárias para os usuários.
Solução subótima: não permita os arquivos com robots.txt, pois isso não impedirá que o link seja incluído nos resultados da pesquisa.
Abordagem de práticas recomendadas: para a maioria dos sites, essas páginas devem ser muito poucas e você pode não ver nenhum impacto no KPI da implementação do manuseio de robôs. Se você sentir necessidade, é melhor usar uma diretiva “noindex”, a menos que haja consultas de pesquisa para essas páginas.
Marcar páginas usando o orçamento de rastreamento
Problema: a marcação descontrolada consome o orçamento de rastreamento e geralmente leva a problemas de conteúdo limitado.
Soluções sub-ótimas: não permitir com robots.txt ou adicionar uma tag “noindex”, pois ambos impedirão a classificação de tags relevantes de SEO e (imediatamente ou eventualmente) impedirão a passagem do valor do link.
Abordagem de prática recomendada: avalie o valor de cada uma de suas tags atuais. Se os dados mostrarem que a página agrega pouco valor aos mecanismos de pesquisa ou usuários, redirecione-os 301. Para as páginas que sobrevivem ao abate, trabalhe para melhorar os elementos na página para que se tornem valiosos para usuários e bots.
Rastreamento de JavaScript e CSS
Problema: anteriormente, os bots não podiam rastrear JavaScript e outros conteúdos de mídia avançada. Isso mudou e agora é altamente recomendável permitir que os mecanismos de pesquisa acessem arquivos JS e CSS para, opcionalmente, renderizar páginas.
Solução abaixo do ideal: proibir arquivos JavaScript e CSS com robots.txt para economizar o orçamento de rastreamento pode resultar em uma indexação ruim e afetar negativamente as classificações. Por exemplo, bloquear o acesso do mecanismo de pesquisa ao JavaScript que veicula um anúncio intersticial ou redirecionar usuários pode ser visto como cloaking.
Abordagem de prática recomendada: verifique se há problemas de renderização com a ferramenta "Fetch as Google" ou obtenha uma visão geral rápida de quais recursos estão bloqueados com o relatório "Recursos bloqueados", ambos disponíveis no Google Search Console. Se algum recurso estiver bloqueado que possa impedir que os mecanismos de pesquisa renderizem a página corretamente, remova a não permissão do robots.txt.
Rastreador de SEO Oncrawl
 Saber mais
Saber maisLista de Verificação de Robôs de Melhores Práticas
É assustadoramente comum que um site tenha sido removido acidentalmente do Google por um erro de controle de robôs.
No entanto, o manuseio de robôs pode ser uma adição poderosa ao seu arsenal de SEO quando você sabe como usá-lo. Apenas certifique-se de proceder com sabedoria e cautela.
Para ajudar, aqui está uma lista de verificação rápida:
- Proteja informações privadas usando proteção por senha
- Bloqueie o acesso a sites de desenvolvimento usando a autenticação do lado do servidor
- Restringir rastreadores que consomem largura de banda, mas oferecem pouco valor de volta com o bloqueio de agente do usuário
- Certifique-se de que o domínio primário e quaisquer subdomínios tenham um arquivo de texto chamado “robots.txt” no diretório de nível superior que retorna um código 200
- Certifique-se de que o arquivo robots.txt tenha pelo menos um bloco com uma linha de agente do usuário e uma linha de não permissão
- Certifique-se de que o arquivo robots.txt tenha pelo menos uma linha de mapa do site, inserida como a última linha
- Valide o arquivo robots.txt no testador de robots.txt do GSC
- Certifique-se de que cada página indexável especifique suas diretivas de tags de robôs
- Certifique-se de que não há diretivas contraditórias ou redundantes entre robots.txt, metatags robots, X-Robots-Tags, arquivo .htaccess e manipulação de parâmetros GSC
- Corrija qualquer erro "URL enviado marcado como 'noindex'" ou "URL enviado bloqueado por robots.txt" no relatório de cobertura do GSC
- Entenda o motivo de quaisquer exclusões relacionadas a robôs no relatório de cobertura do GSC
- Certifique-se de que apenas as páginas relevantes sejam mostradas no relatório "Recursos bloqueados" do GSC
Vá verificar o manuseio de seus robôs e certifique-se de que está fazendo certo.