
Rastreamento, indexação e Python: tudo o que você precisa saber
Publicados: 2021-05-31Eu gostaria de começar este artigo com uma equação muito simples: se suas páginas não forem rastreadas, elas nunca serão indexadas e, portanto, seu desempenho de SEO sempre sofrerá (e cheirará mal).
Como consequência disso, os SEOs precisam se esforçar para encontrar a melhor maneira de tornar seus sites rastreáveis e fornecer ao Google suas páginas mais importantes para indexá-los e começar a adquirir tráfego por meio deles.
Felizmente, temos muitos recursos que podem nos ajudar a melhorar a rastreabilidade do nosso site, como Screaming Frog, Oncrawl ou Python. Mostrarei como o Python pode ajudá-lo a analisar e melhorar sua facilidade de rastreamento e indicadores de indexação. Na maioria das vezes, esses tipos de melhorias também levam a melhores classificações, maior visibilidade nas SERPs e, eventualmente, mais usuários chegando ao seu site.
1. Solicitando indexação com Python
1.1. Para o Google
A solicitação de indexação para o Google pode ser feita de várias maneiras, embora infelizmente não esteja muito convencido de nenhuma delas. Vou orientá-lo através de três opções diferentes com seus prós e contras:
- Selenium e Google Search Console: do meu ponto de vista e depois de testá-lo e o resto das opções, esta é a solução mais eficaz. No entanto, após várias tentativas, é possível que haja um pop-up captcha que o quebre.
- Fazer ping em um sitemap: definitivamente ajuda a fazer com que os sitemaps sejam rastreados conforme solicitado, mas não URLs específicos, por exemplo, no caso de novas páginas terem sido adicionadas ao site.
- API de indexação do Google: não é muito confiável, exceto para emissoras e sites de plataformas de trabalho. Ajuda a aumentar as taxas de rastreamento, mas não a indexar URLs específicos.
Após esta rápida visão geral sobre cada método, vamos mergulhar neles um por um.
1.1.1. Selênio e Google Search Console
Essencialmente, o que faremos nesta primeira solução é acessar o Google Search Console de um navegador com Selenium e replicar o mesmo processo que seguiríamos manualmente para enviar muitas URLs para indexação com o Google Search Console, mas de forma automatizada.
Observação: não abuse desse método e envie uma página para indexação apenas se seu conteúdo tiver sido atualizado ou se a página for completamente nova.
O truque para poder fazer login no Google Search Console com o Selenium é acessar o OUATH Playground primeiro, conforme expliquei neste artigo sobre como automatizar o download do relatório de estatísticas de rastreamento do GSC.
#Importamos esses módulos
tempo de importação
do webdriver de importação de selênio
de webdriver_manager.chrome importar ChromeDriverManager
de selenium.webdriver.common.keys importar chaves
#Instalamos nosso Driver Selenium
driver = webdriver.Chrome(ChromeDriverManager().install())
#Acessamos a conta do playground OUATH para fazer login nos Serviços do Google
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#Esperamos um pouco para ter certeza de que a renderização está completa antes de selecionar elementos com XPath e introduzir nosso endereço de e-mail.
hora.dormir(10)
form1=driver.find_element_by_xpath('//*[@]')
form1.send_keys("<seu endereço de e-mail>")
form1.send_keys(Keys.ENTER)
#Mesmo aqui, esperamos um pouco e depois apresentamos nossa senha.
hora.dormir(10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys("<sua senha>")
form2.send_keys(Keys.ENTER)
Depois disso, podemos acessar nosso URL do Google Search Console:
driver.get('https://search.google.com/search-console?resource_id=seu_domínio”')
hora.dormir(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /div[1]/input[2]')
box.send_keys("sua_URL")
box.send_keys(Keys.ENTER)
hora.dormir(5)
indexação = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexação.clique()
hora.dormir(120)
Infelizmente, conforme explicado na introdução, parece que depois de várias solicitações, ele começa a exigir um captcha de quebra-cabeça para prosseguir com a solicitação de indexação. Como o método automatizado não pode resolver o captcha, isso é algo que prejudica essa solução.
1.1.2. Fazer ping em um mapa do site
Os URLs do Sitemap podem ser enviados ao Google com o método ping. Basicamente, você só precisaria fazer uma solicitação para o seguinte endpoint introduzindo o URL do mapa do site como parâmetro:
http://www.google.com/ping?sitemap=URL/of/file
Isso pode ser automatizado muito facilmente com Python e solicitações, conforme expliquei neste artigo.
importar urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" resposta = urllib.request.urlopen(url)
1.1.3. API de indexação do Google
A API de indexação do Google pode ser uma boa solução para melhorar suas taxas de rastreamento, mas geralmente não é um método muito eficaz para indexar seu conteúdo, pois só deve ser usado se seu site tiver JobPosting ou BroadcastEvent incorporado em um VideoObject. No entanto, se você quiser experimentá-lo e testá-lo você mesmo, poderá seguir as próximas etapas.
Antes de tudo, para começar a usar essa API, você precisa acessar o Google Cloud Console, criar um projeto e uma credencial de conta de serviço. Depois disso, você precisará habilitar a API de indexação da Biblioteca e adicionar a conta de e-mail fornecida com as credenciais da conta de serviço como proprietário no Google Search Console. Talvez seja necessário usar a versão antiga do Google Search Console para adicionar este endereço de e-mail como proprietário.
Depois de seguir as etapas anteriores, você poderá começar a solicitar indexação e desindexação com esta API usando o próximo trecho de código:
de oauth2client.service_account importar ServiceAccountCredentials
importar httplib2
SCOPES = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
credenciais = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
se credenciais for Nenhum ou credenciais.invalid:
credenciais = tools.run_flow(fluxo, armazenamento)
http = credenciais.autorize(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
para iteração no intervalo (len(list_urls)):
conteudo = '''{
'url': "'''+str(list_urls[iteração])+'''",
'tipo': "URL_UPDATED"
}'''
resposta, conteúdo = http.request(ENDPOINT, método="POST", corpo=conteúdo)
imprimir(resposta)
imprimir (conteúdo)Se você quiser solicitar a desindexação, precisará alterar o tipo de solicitação de “URL_UPDATED” para “URL_DELETED”. O trecho de código anterior imprimirá as respostas da API com os horários de notificação e seus status. Se o status for 200, a solicitação terá sido feita com sucesso.
1.2. Para Bing
Muitas vezes quando falamos de SEO pensamos apenas no Google, mas não podemos esquecer que em alguns mercados existem outros motores de busca predominantes e/ou outros motores de busca que têm uma quota de mercado respeitável como o Bing.
É importante mencionar desde o início que o Bing já possui um recurso muito conveniente no Bing Webmaster Tools que permite solicitar o envio de até 10.000 URLs por dia na maioria dos casos. Às vezes, sua cota diária pode ser inferior a 10.000 URLs, mas você tem a opção de solicitar um incremento de cota se achar que precisa de uma cota maior para atender às suas necessidades. Você pode ler mais sobre isso nesta página.
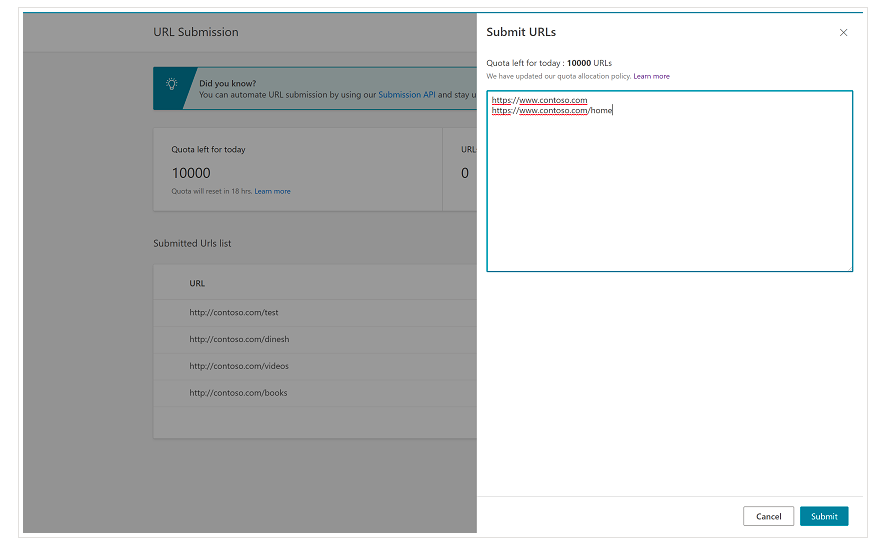
Esse recurso é realmente muito conveniente para envios de URLs em massa, pois você só precisará introduzir seus URLs em linhas diferentes na ferramenta de envio de URL da interface normal das Ferramentas do Bing para webmasters.
1.2.1. API de indexação do Bing
A API de indexação do Bing pode ser usada com uma chave de API que precisa ser introduzida como um parâmetro. Essa chave de API pode ser obtida no Bing Webmaster Tools, acessando a seção de acesso à API e depois gerando a chave de API.
Depois que a chave da API for obtida, podemos brincar com a API com o seguinte trecho de código (você só precisa adicionar sua chave de API e a URL do seu site):
solicitações de importação
list_urls = ["https://www.example.com", "https://www.example/test2/"]
para y em list_urls:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
headers = {'Content-type': 'application/json; charset=utf-8'}
x = requests.post(url, data=myobj, headers=headers)
print(str(y) + ": " + str(x))Isso imprimirá a URL e seu código de resposta em cada iteração. Ao contrário da API de indexação do Google, essa API pode ser usada para qualquer tipo de site.
[Estudo de caso] Aumente a visibilidade melhorando a rastreabilidade do site para o Googlebot
 Leia o estudo de caso
Leia o estudo de caso2. Análise, criação e upload de Sitemaps
Como todos sabemos, os sitemaps são elementos muito úteis para fornecer aos robôs dos mecanismos de pesquisa os URLs que gostaríamos que eles rastreassem. Para permitir que os bots dos mecanismos de pesquisa saibam onde estão nossos mapas do site, eles devem ser carregados no Google Search Console e no Bing Webmaster Tools e incluídos no arquivo robots.txt para o restante dos bots.
Com o Python podemos trabalhar principalmente três aspectos diferentes relacionados aos mapas do site: sua análise, criação e upload e exclusão do Google Search Console.
2.1. Importação e análise de sitemap com Python
Advertools é uma ótima biblioteca criada por Elias Dabbas que pode ser usada para importação de sitemaps, bem como muitas outras tarefas de SEO. Você poderá importar sitemaps para Dataframes apenas usando:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
Esta biblioteca suporta mapas de site XML regulares, mapas de site de notícias e mapas de site de vídeo.
Por outro lado, se você estiver interessado apenas em importar as URLs do mapa do site, também poderá usar as solicitações da biblioteca e o BeautifulSoup.
solicitações de importação
de bs4 importe BeautifulSoup
r = requests.get("https://www.example.com/your_sitemap.xml")
xml = r.texto
sopa = BeautifulSoup(xml)
urls = sopa.find_all("loc")
urls = [[x.text] para x em urls]
Depois que o mapa do site for importado, você pode brincar com os URLs extraídos e realizar uma análise de conteúdo, conforme explicado por Koray Tugberk neste artigo.
2.2. Criação de Sitemaps com Python
Você também pode utilizar o Python para criar sitemaps.xml a partir de uma lista de URLs, conforme JC Chouinard explicou neste artigo. Isso pode ser especialmente útil para sites muito dinâmicos cujos URLs estão mudando rapidamente e, juntamente com o método de ping explicado acima, pode ser uma ótima solução fornecer ao Google os novos URLs e rastreá-los e indexá-los rapidamente.
Recentemente, Greg Bernhardt também criou um APP com Streamlit e Python para gerar sitemaps.
2.3. Carregando e excluindo sitemaps do Google Search Console
O Google Search Console possui uma API que pode ser usada principalmente de duas maneiras diferentes: extrair dados sobre o desempenho da web e manipular sitemaps. Neste post, vamos nos concentrar na opção de fazer upload e excluir sitemaps.
Primeiro, é importante criar ou usar um projeto existente do Google Cloud Console para obter uma credencial OUATH e ativar o serviço Google Search Console. JC Chouinard explica muito bem as etapas que você precisa seguir para acessar a API do Google Search Console com Python e como fazer sua primeira solicitação neste artigo. Basicamente, podemos fazer uso completo de seu código, mas apenas introduzindo uma alteração, nos escopos adicionaremos “https://www.googleapis.com/auth/webmasters” em vez de “https://www.googleapis.com /auth/webmasters.readonly”, pois usaremos a API não apenas para ler, mas para fazer upload e excluir sitemaps.

Uma vez que nos conectamos com a API, podemos começar a brincar com ela e listar todos os sitemaps de nossas propriedades do Google Search Console com o próximo trecho de código:
para site_url em Verify_sites_urls:
imprimir (site_url)
# Recuperar lista de sitemaps enviados
sitemaps = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
se 'sitemap' em sitemaps:
sitemap_urls = [s['path'] para s em sitemaps['sitemap']]
print (" " + "\n ".join(sitemap_urls))
Quando se trata de sitemaps específicos, podemos realizar três tarefas que elaboraremos nas próximas seções: upload, exclusão e solicitação de informações.
2.3.1. Carregar um mapa do site
Para fazer upload de um mapa do site com Python, precisamos apenas especificar a URL do site e o caminho do mapa do site e executar este código:
SITE = 'suapropriedade GSC' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2. Excluindo um mapa do site
O outro lado da moeda é quando gostaríamos de excluir um mapa do site. Também podemos excluir sitemaps do Google Search Console com Python usando o método “delete” em vez de “submit”.
SITE = 'suapropriedade GSC' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3. Solicitando informações dos mapas do site
Por fim, também podemos solicitar informações do mapa do site usando o método “get”.
SITE = 'suapropriedade GSC' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
Isso retornará uma resposta no formato JSON como: 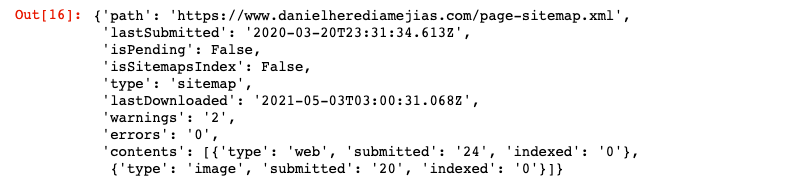
3. Análise de links internos e oportunidades
Ter uma estrutura de links internos adequada é muito útil para facilitar o rastreamento do seu site por robôs de busca. Alguns dos principais problemas que encontrei ao auditar vários sites com configurações técnicas muito sofisticadas são:
- Links introduzidos com eventos de clique: em resumo, o Googlebot não clica em botões, portanto, se seus links forem inseridos com um evento de clique, o Googlebot não poderá segui-los.
- Links renderizados do lado do cliente: apesar do Googlebot e outros mecanismos de pesquisa estarem se tornando muito melhores na execução de JavaScript, ainda é algo bastante desafiador para eles, então é muito melhor renderizar esses links no lado do servidor e servi-los no HTML bruto para robôs de mecanismos de pesquisa do que esperar que eles executem scripts JavaScript.
- Pop-ups de login e/ou age gate: pop-ups de login e age gate podem impedir que bots de mecanismos de pesquisa rastreiem o conteúdo que está por trás desses “obstáculos”.
- Uso excessivo de atributos nofollow: usar muitos atributos nofollow apontando para páginas internas valiosas impedirá que os bots dos mecanismos de pesquisa as rastreiem.
- Noindex e follow: tecnicamente, a combinação das diretivas noindex e follow deve permitir que os bots dos mecanismos de pesquisa rastreiem os links que estão nessa página. No entanto, parece que o Googlebot para de rastrear essas páginas com diretivas noindex depois de um tempo.
Com o Python, podemos analisar nossa estrutura de links internos e encontrar novas oportunidades de links internos no modo em massa.
3.1. Análise de links internos com Python
Alguns meses atrás escrevi um artigo sobre como usar Python e a biblioteca Networkx para criar gráficos para exibir a estrutura de links internos de uma forma bem visual:
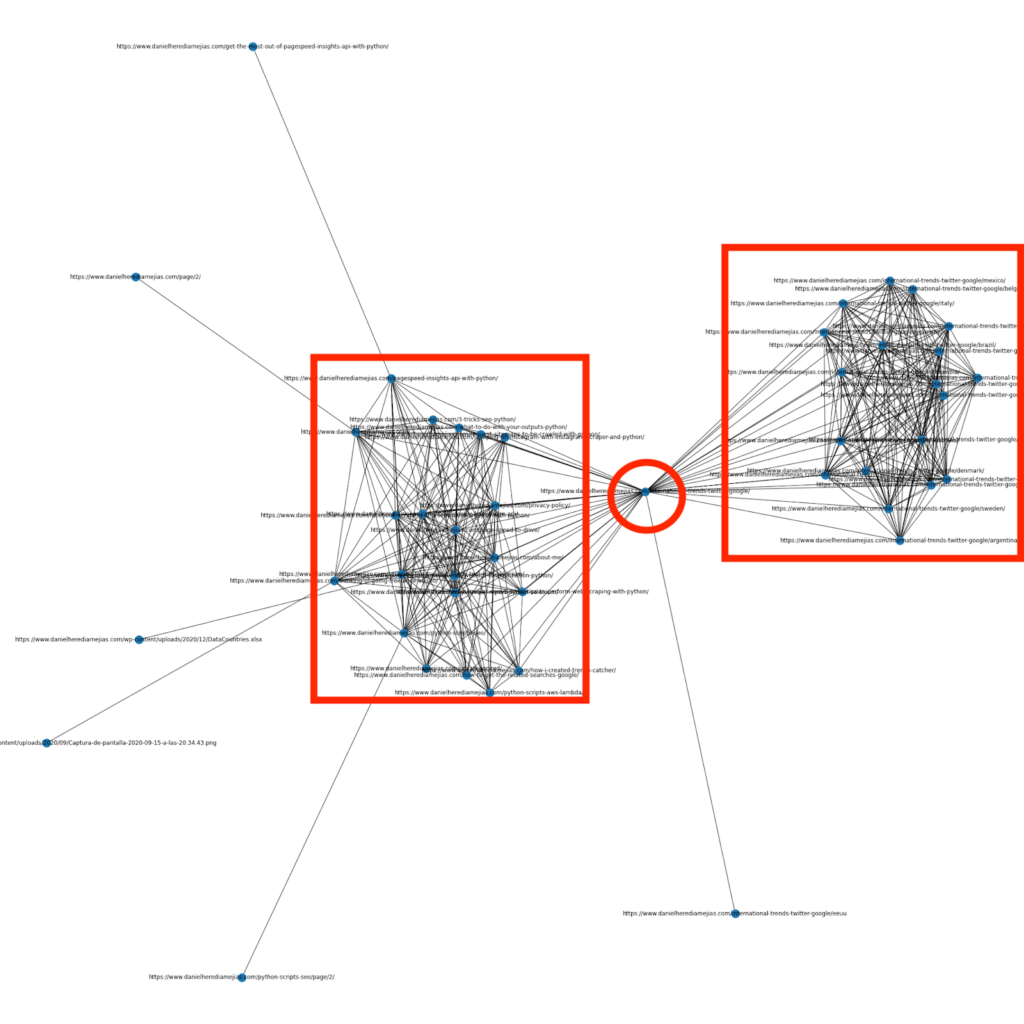
Isso é algo muito semelhante ao que você pode obter do Screaming Frog, mas a vantagem de usar Python para esse tipo de análise é que basicamente você pode escolher os dados que deseja incluir nesses gráficos e controlar a maioria dos elementos do gráfico, como como cores, tamanhos de nós ou até mesmo as páginas que você gostaria de adicionar.
3.2. Encontrando novas oportunidades de links internos com Python
Além de analisar as estruturas do site, você também pode usar o Python para encontrar novas oportunidades de links internos, fornecendo várias palavras-chave e URLs e iterando essas URLs pesquisando os termos fornecidos em seus conteúdos.
Isso é algo que pode funcionar muito bem com exportações de Semrush ou Ahrefs para encontrar links internos contextuais poderosos de algumas páginas que já estão ranqueando por palavras-chave e, portanto, que já possuem algum tipo de autoridade.
Você pode ler mais sobre esse método aqui.
4. Velocidade do site, 5xx e páginas de erro soft
Conforme declarado pelo Google nesta página sobre o que o orçamento de rastreamento significa para o Google, tornar seu site mais rápido melhora a experiência do usuário e aumenta a taxa de rastreamento. Por outro lado, também existem outros fatores que podem afetar o orçamento de rastreamento, como páginas de erro soft, conteúdo de baixa qualidade e conteúdo duplicado no site.
4.1. Velocidade da página e Python
4.2.1 Analisando a velocidade do seu site com Python
A API do Page Speed Insights é super útil para analisar o desempenho do seu site em termos de velocidade da página e obter muitos dados sobre muitas métricas de velocidade de página diferentes (quase 50), além de Core Web Vitals.
Trabalhar com o Page Speed Insights com Python é muito simples, apenas uma chave de API e solicitações são necessárias para usá-la. Por exemplo:
importar urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #Observe que você pode inserir seu URL com o parâmetro URL e também pode modificar o parâmetro do dispositivo se desejar obter os dados para desktop. resposta = urllib.request.urlopen(url) dados = json.loads(resposta.read())
Além disso, você também pode prever com a calculadora Python e Lighthouse Scoring quanto sua pontuação geral de desempenho melhoraria no caso de fazer as alterações solicitadas para melhorar a velocidade da sua página, conforme explicado neste artigo.
4.2.2 Otimização e redimensionamento de imagens com Python
Relacionado à velocidade do site, o Python também pode ser usado para otimizar, compactar e redimensionar imagens, conforme explicado nestes artigos escritos por Koray Tugberk e Greg Bernhardt:
- Automatize a compactação de imagens com Python sobre FTP.
- Redimensione imagens com Python em massa.
- Otimize imagens via Python para SEO e UX.
4.2. 5xx e outros erros de extração de código de resposta com Python
Erros de código de resposta 5xx podem ser indicativos de que seu servidor não é rápido o suficiente para lidar com todas as solicitações que está recebendo. Isso pode ter um impacto muito negativo na sua taxa de rastreamento e também pode prejudicar a experiência do usuário.
Para garantir que seu site esteja funcionando conforme o esperado, você pode automatizar o download do relatório de estatísticas de rastreamento com Python e Selenium e ficar de olho em seus arquivos de log.
4.3. Extração de páginas de erro soft com Python
Recentemente, José Luis Hernando publicou um artigo em homenagem a Hamlet Batista sobre como automatizar a extração de relatórios de cobertura com Node.js. Essa pode ser uma solução incrível para extrair as páginas de erro soft e até mesmo os erros de resposta 5xx que podem afetar negativamente sua taxa de rastreamento.
Também podemos replicar esse mesmo processo com Python para compilar em apenas uma guia do Excel todas as URLs fornecidas pelo Google Search Console como errôneas, válidas com avisos, válidas e excluídas.
Primeiro, precisamos fazer login no Google Search Console conforme explicado anteriormente neste artigo com Python com Selenium. Depois disso, selecionaremos todas as caixas de status de URL, adicionaremos até 100 linhas por página e começaremos a iterar todos os tipos de URLs relatados pelo GSC e baixaremos todos os arquivos do Excel.
tempo de importação
do webdriver de importação de selênio
de webdriver_manager.chrome importar ChromeDriverManager
de selenium.webdriver.common.keys importar chaves
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
hora.dormir(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys("<youremailaddress>")
searchBox.send_keys(Keys.ENTER)
hora.dormir(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
searchBox.send_keys("<suasenha>")
searchBox.send_keys(Keys.ENTER)
hora.dormir(5)
yourdomain = str(input("Insira aqui sua propriedade ou domínio http. Se for um domínio inclua: 'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] for i in range(len(df1["URL"]))]
df1['Tipo'] = valores da lista
list_results = df1.values.tolist()
senão:
df2 = pd.read_excel(seudominio.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + hoje + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df2["URL"]))]
df2['Tipo'] = valores da lista
list_results = list_results + df2.values.tolist()
df = pd.DataFrame(list_results, columns= ["URL","TimeStamp", "Tipo"])
df.to_csv('<filename>.csv', header=True, index=False, encoding = "utf-8")
A saída final se parece com: 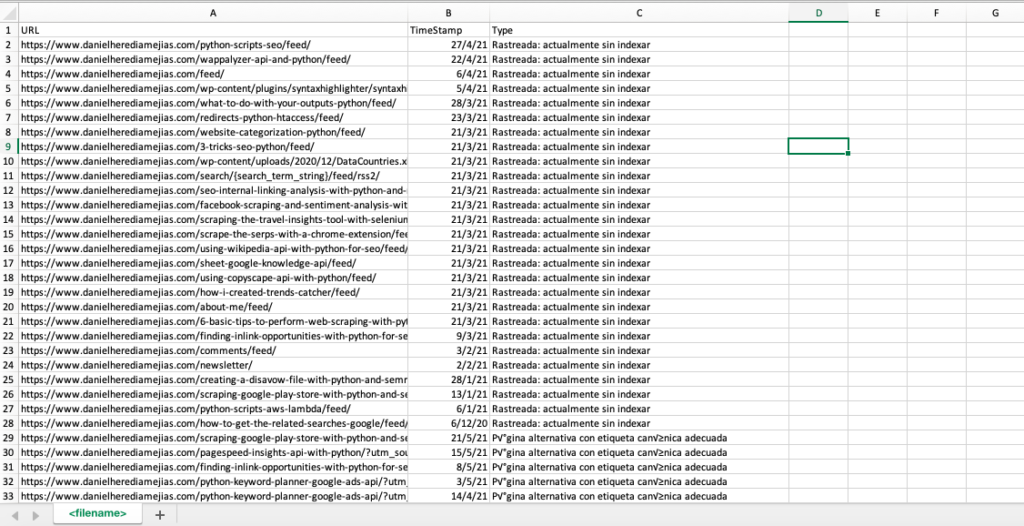
4.4. Análise de arquivo de log com Python
Além dos dados disponíveis no relatório de estatísticas de rastreamento do Google Search Console, você também pode analisar seus próprios arquivos usando o Python para obter muito mais informações sobre como os bots dos mecanismos de pesquisa estão rastreando seu site. Se você ainda não estiver usando um analisador de log para SEO, leia este artigo do SEO Garden, onde a análise de log com Python é explicada.
[Ebook] Quatro casos de uso para aproveitar a análise de log de SEO
Download de graça5. Conclusões finais
Vimos que o Python pode ser um grande trunfo para analisar e melhorar o rastreamento e a indexação de nossos sites de muitas maneiras diferentes. Também vimos como tornar a vida muito mais fácil automatizando a maioria das tarefas tediosas e manuais que exigiriam milhares de horas do seu tempo.
Devo dizer que infelizmente não estou totalmente convencido pelas soluções oferecidas no momento pelo Google para solicitar a indexação de um grande número de URLs, embora possa entender até certo ponto seu medo de oferecer uma solução melhor: muitos SEOs podem tender para abusar dele.
Em contraste com isso, existe o Bing, que oferece soluções excepcionais e convenientes para solicitar a indexação de URLs via API e até mesmo pela interface normal das Ferramentas do Bing para Webmasters.
Devido ao fato de que a API de indexação do Google tem espaço para melhorias, outros elementos como ter um sitemap acessível e atualizado no local, seus links internos, sua velocidade de página, suas páginas de erro soft e seu conteúdo duplicado e de baixa qualidade tornam-se ainda mais importantes para garantir que seu site está devidamente rastreado e suas páginas mais importantes estão indexadas.