
10 problemas técnicos comuns de SEO – e como identificá-los
Publicados: 2019-06-04Tendo realizado serviços de SEO em vários setores, às vezes você consegue identificar problemas comuns, especialmente ao trabalhar em um CMS comum, como WordPress, Shopify ou SquareSpace.
Aqui eu descrevi 10 problemas técnicos de SEO bastante comuns que você pode encontrar ao otimizar um site.
Não estou dizendo que essas questões definitivamente serão problemáticas para você ou seu cliente – muitas vezes o contexto ainda é muito importante. Nem sempre há uma solução de tamanho único, mas provavelmente ainda é bom ter cuidado com os cenários descritos abaixo.
1 – Arquivo Robots.txt bloqueando o acesso ao Googlebot
Isso não é novidade para a maioria dos SEOs técnicos, mas ainda é muito fácil negligenciar a verificação do arquivo robots – e não apenas no momento de executar uma auditoria técnica, mas como uma verificação recorrente.
Você pode usar uma ferramenta como o Search Console (a versão antiga) para analisar se o Google tem problemas de acesso, ou pode tentar rastrear seu site como Googlebot com uma ferramenta como OnCrawl (basta selecionar o User Agent). O OnCrawl obedecerá ao robots.txt, a menos que você diga o contrário.
Exporte os resultados do rastreamento e compare com uma lista conhecida de páginas em seu site e verifique se não há pontos cegos do rastreador.
Para mostrar que isso ainda acontece com bastante frequência, e para alguns sites bastante grandes, algumas semanas atrás, notei que a ferramenta Speed Test do Pingdom estava bloqueada no Google.
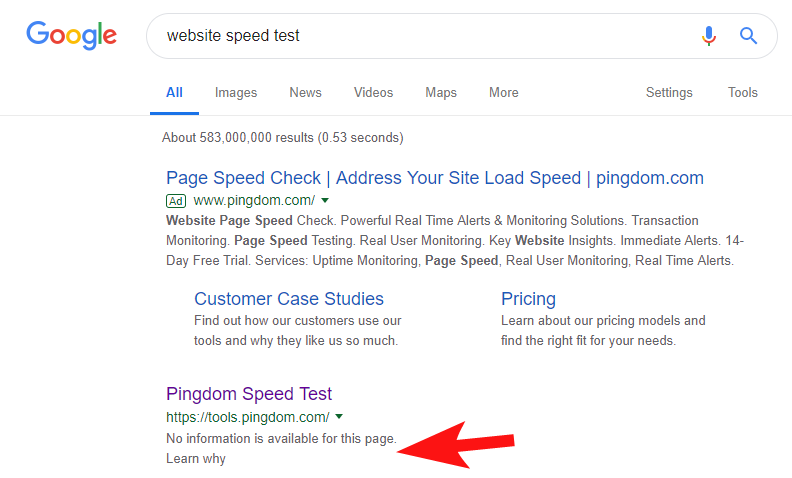
Olhando para o arquivo de robôs deles (e posteriormente tentando rastrear sua página do OnCrawl como Googlebot) confirmou minhas suspeitas de que eles estavam bloqueando o acesso ao site.
O arquivo robots.txt culpado é mostrado abaixo:

Entrei em contato com eles com um “FYI”, mas não tive resposta, mas alguns dias depois vi que tudo estava de volta ao normal. Ufa – eu poderia dormir facilmente de novo!
No caso deles, parecia que sempre que você varria seu site como parte de sua auditoria de velocidade, estava criando um URL incluindo esse caractere com hash destacado no arquivo robots acima.
Talvez eles estivessem sendo rastreados e até indexados de alguma forma, e eles quisessem controlar isso (o que seria muito compreensível). Nesse caso, eles provavelmente não testaram totalmente o impacto potencial – que provavelmente foi mínimo no final.
Aqui estão seus robôs atuais para quem estiver interessado.

Vale a pena notar que, em alguns casos, você pode acessar as alterações históricas do arquivo robots.txt usando o Internet Wayback Machine. Pela minha experiência, isso funciona melhor em sites maiores, como você pode imaginar – eles são rastreados com muito mais frequência pelo arquivador do Wayback Machine.
Não é a primeira vez que vejo um robots.txt ao vivo na natureza causando um pouco de estragos na SERPS. E definitivamente não será o último – é uma coisa tão simples de negligenciar (afinal, é literalmente um arquivo), mas verificá-lo deve fazer parte do cronograma de trabalho contínuo de todo SEO.
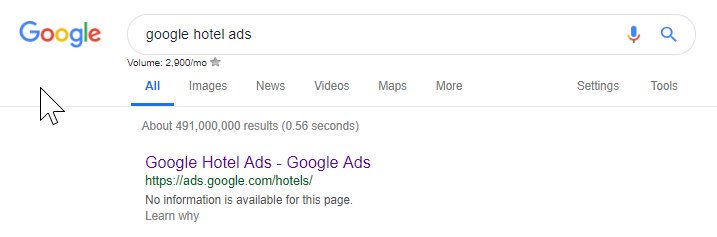
Pelo que foi dito acima, você pode ver que até o Google bagunça seu arquivo de robôs às vezes, bloqueando-se de acessar seu conteúdo. Isso pode ter sido intencional, mas olhando para o idioma do arquivo de robôs abaixo, de alguma forma duvido.
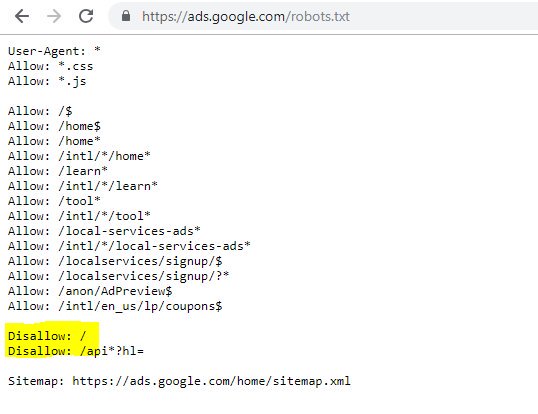
O destacado Disallow: / neste caso impediu o acesso a qualquer caminho de URL; seria mais seguro listar as seções específicas do site que não deveriam ser rastreadas.
2 – Problemas de configuração de domínio no nível DNS
Este é surpreendentemente comum, mas geralmente é uma solução rápida. Esta é uma daquelas mudanças de SEO de baixo custo e *potencialmente* de alto impacto que o SEO técnico adora.
Muitas vezes, com implementações de SSL, não consigo ver a versão de domínio não WWW configurada corretamente, como 302 redirecionando para a próxima URL e formando uma cadeia ou, no pior cenário, não carregando.
Um bom exemplo aqui é o site do Hotel Football.
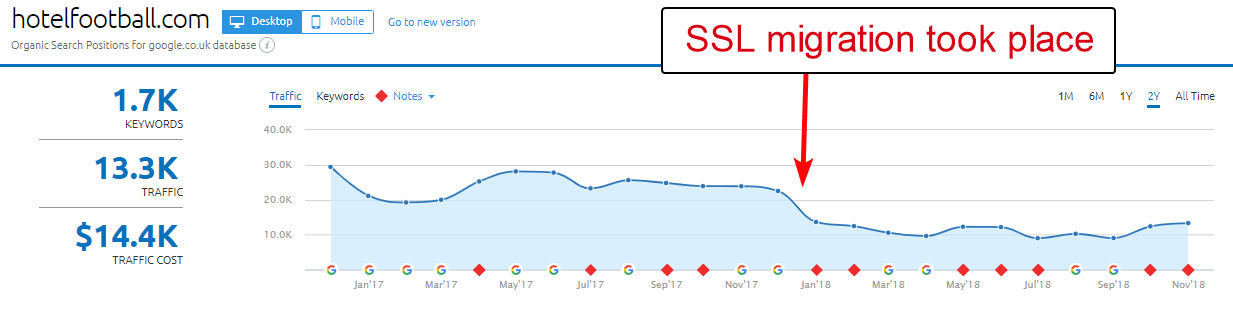
Eles passaram por uma migração SSL no início do ano passado, o que não deu muito certo para eles, a julgar pelo relatório de visão geral de domínio da SEMRush acima.
Eu tinha notado isso há algum tempo, pois trabalhei muito na indústria de viagens e hospitalidade - e com um grande amor pelo futebol, estava interessado em ver como era o site deles (além de como estava se saindo organicamente, é claro! ).
Isso foi realmente muito fácil de diagnosticar - o site tinha uma tonelada de backlinks extremamente bons, todos apontando para o domínio WWW não-SSL em http://www.hotelfootball.com/
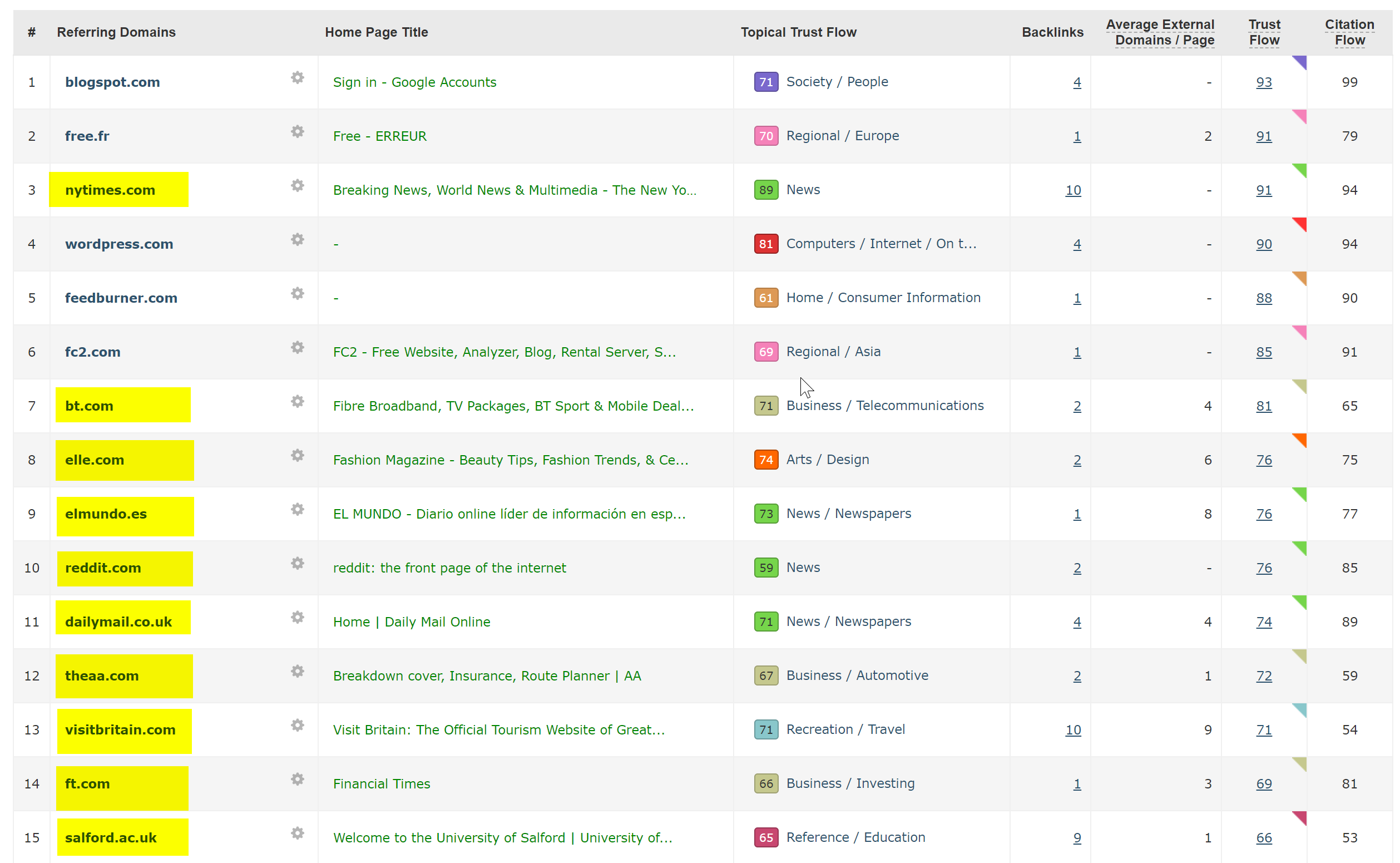
Se você tentar acessar esse URL acima, ele não será carregado. Ops. E tem sido assim por cerca de 18 meses, pelo menos. Entrei em contato com a agência que administra o site via Twitter para informá-los sobre isso, mas não tive resposta.
Com este, tudo o que eles precisam fazer é garantir que as configurações da zona DNS estejam corretas, com um registro “A” no local para a versão “WWW” do domínio, que aponta para o endereço IP correto (um CNAME também funcionaria). Isso impedirá que o domínio não resolva.
A única desvantagem, ou razão pela qual este demora tanto para resolver, é que pode ser complicado obter acesso ao painel de gerenciamento de domínio de um site, ou até mesmo que as senhas foram perdidas ou não é visto como de alta prioridade.
Enviar instruções para corrigir a uma pessoa não técnica que possui as chaves do nome de domínio nem sempre é uma boa ideia.
Eu gostaria muito de ver o impacto orgânico se/quando eles forem capazes de fazer o ajuste acima - especialmente considerando todos os backlinks que o domínio não WWW construiu desde que o hotel foi lançado pelos ex-jogadores de futebol do Manchester United Gary Neville, Ryan Giggs e companhia.
Embora eles estejam em primeiro lugar no Google para o nome do hotel (como você imagina), eles não parecem ter classificações fortes para nenhum de seus termos de pesquisa sem marca mais competitivos (eles estão atualmente na posição 10 no Google para “hotel perto de Old Trafford”).
Eles marcaram um gol contra com o acima - mas corrigir esse problema pode ajudar pelo menos de alguma forma a resolver isso.
Rastreador de SEO Oncrawl
 Saber mais
Saber mais3 – Rogue Pages no XML Sitemap
Novamente, isso é bastante básico, mas é estranhamente comum - ao revisar um sitemap XML de sites (que quase sempre está em domain.com/sitemap.xml ou domain.com/sitemap_index.xml, pode haver páginas listadas aqui que realmente não não precisa ser indexado.
Os culpados típicos incluem páginas de agradecimento ocultas (obrigado por enviar um formulário de contato), páginas de destino PPC que podem estar causando problemas de conteúdo duplicado ou outras formas de páginas/postagens/taxonomias que você já não indexou em outro lugar.
Incluí-los novamente no mapa do site XML pode enviar sinais conflitantes para os mecanismos de pesquisa – você realmente deve listar apenas as páginas que deseja que eles encontrem e indexem, que é principalmente o ponto do mapa do site.
Agora você pode usar o relatório prático no Search Console para descobrir se as páginas foram ou não incluídas em um sitemap XML de sites por meio da opção Inspecionar URL.
Se você tem um site relativamente pequeno, provavelmente pode revisar manualmente o mapa do site XML em seu navegador – caso contrário, baixe-o e compare-o com um rastreamento completo de seus URLs indexáveis.
Muitas vezes, você pode encontrar esse tipo de conteúdo inestimável e de baixa qualidade fazendo uma pesquisa site:domain.com no Google para retornar tudo o que foi indexado.
Vale a pena notar aqui que isso pode conter conteúdo antigo e não deve ser confiável para estar 100% atualizado, mas é uma verificação fácil para garantir que não haja um monte de conteúdo inchando seus esforços de SEO e consumindo orçamentos de rastreamento.
4 – Problemas com o Googlebot renderizando seu conteúdo
Este é digno de um artigo inteiro dedicado a ele, e eu pessoalmente sinto que passei uma vida inteira brincando com a ferramenta de busca e renderização do Google.
Muito já foi dito sobre isso (e sobre JavaScript) por alguns SEOs muito capazes, então não vou me aprofundar muito nisso, mas verificar como o Googlebot está renderizando seu site sempre será digno do seu tempo.
A execução de algumas verificações por meio de ferramentas on-line pode ajudar a descobrir pontos cegos do Googlebot (áreas do site que eles não podem acessar), problemas com seu ambiente de hospedagem, recursos problemáticos de queima de JavaScript e até problemas de dimensionamento de tela.
Normalmente, essas ferramentas de terceiros são bastante úteis para diagnosticar o problema (o Google até informa quando um recurso é bloqueado devido ao seu arquivo de robôs, por exemplo), mas às vezes você pode se encontrar andando em círculos.
Para mostrar um exemplo ao vivo de um site problemático, vou dar um tiro no pé e fazer referência ao meu próprio site pessoal – e a um tema WordPress particularmente frustrante que estou usando.
Às vezes, ao executar uma inspeção de URL no Search Console, recebo o aviso "A página não é compatível com dispositivos móveis" (veja abaixo).
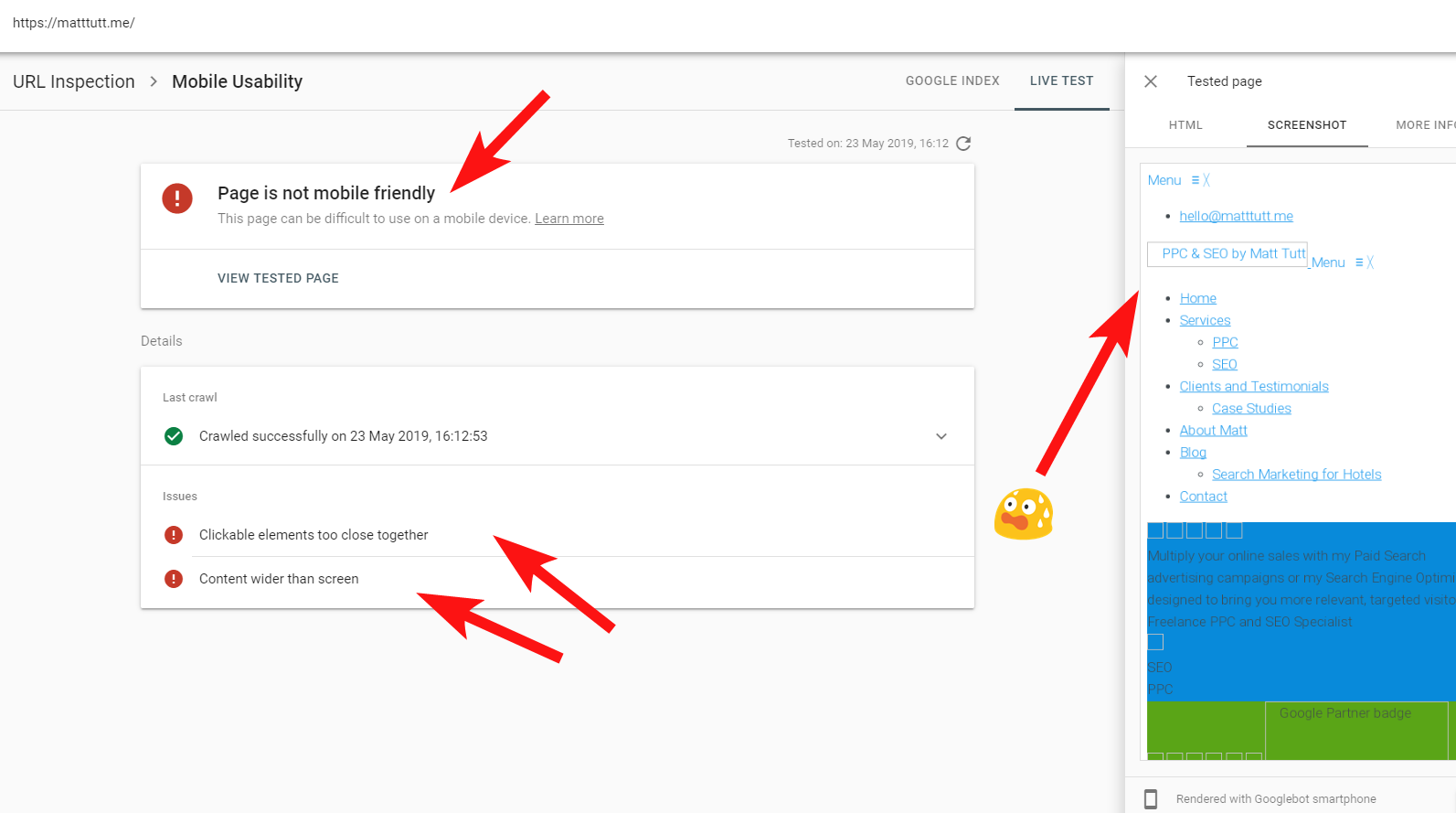
Ao clicar na guia Mais informações (canto superior direito), é fornecida uma lista de recursos que não podem ser acessados pelo Googlebot, principalmente CSS e arquivos de imagem.
Isso é provável, pois o Googlebot nem sempre pode fornecer toda a "energia" para renderizar a página - às vezes é porque o Google tem medo de travar meu site (o que é meio que eles) e outras vezes eu posso estar limitado, pois eles usaram muitos recursos para buscar e renderizar meu site já.
Às vezes, por causa do que foi dito acima, vale a pena executar esses testes algumas vezes em intervalos espalhados para obter uma história mais verdadeira. Também recomendo verificar os logs do servidor, se possível, para verificar como o Googlebot acessou (ou não acessou) o conteúdo do seu site.
404 ou outros status ruins para esses recursos seriam claramente um mau sinal, especialmente se forem consistentes.
No meu caso, o Google chama a atenção para o site por não ser compatível com dispositivos móveis, o que é principalmente resultado de certos arquivos de estilo CSS falharem durante a renderização, o que pode soar com razão.
Para tornar as coisas mais confusas, ao executar o Teste de compatibilidade com dispositivos móveis do Google ou ao usar qualquer outra ferramenta de terceiros, nenhum problema é detectado: o site é compatível com dispositivos móveis.
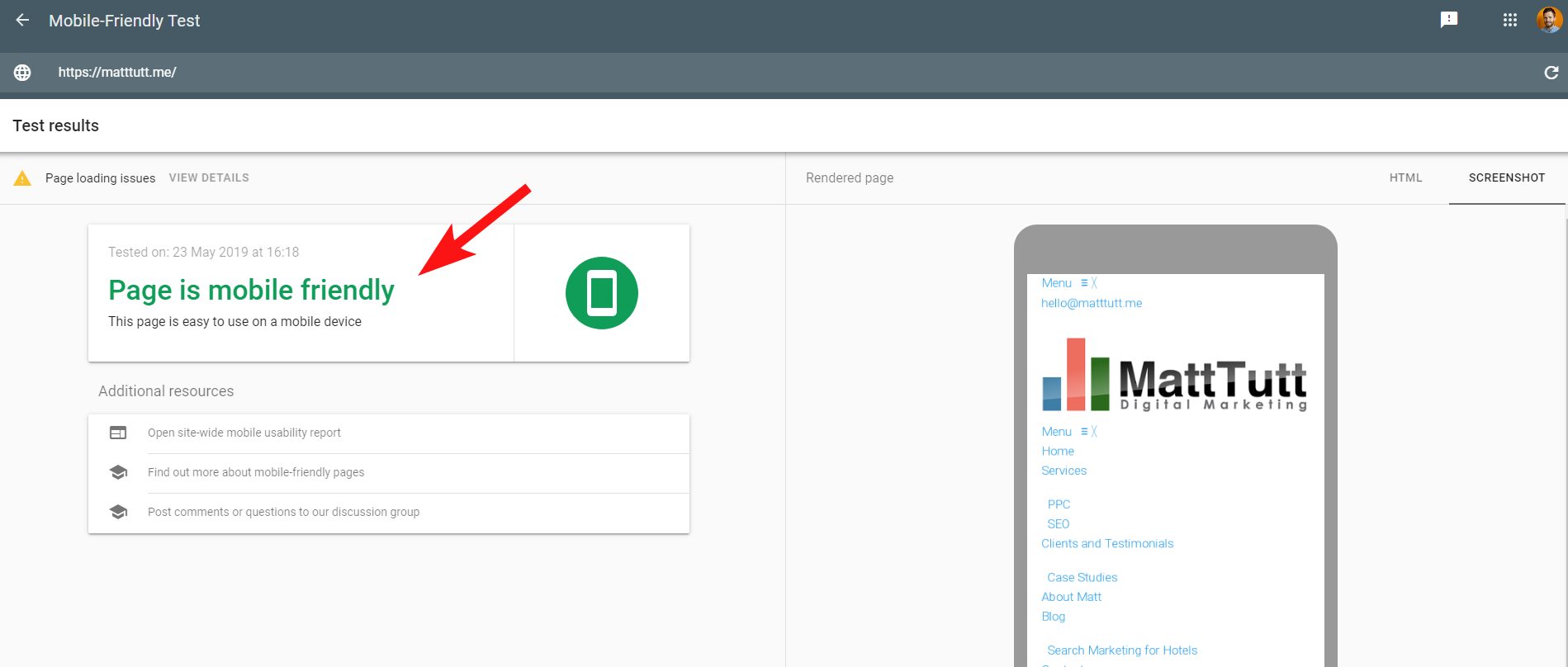
Essas mensagens conflitantes do Google podem ser complicadas para SEO e desenvolvedores da web decodificarem. Para entender melhor, entrei em contato com John Mueller, que sugeriu que eu verificasse meu host (sem problemas) e que o arquivo CSS pode realmente ser armazenado em cache pelo Google.
O Search Console usa um Web Rendering Service (WRS) mais antigo em comparação com a Mobile-Friendly Tool, então hoje em dia costumo dar mais peso ao último.
Com o Google anunciando um Googlebot mais recente com os recursos de renderização mais recentes, tudo isso pode ser alterado, portanto, vale a pena manter-se atualizado sobre quais ferramentas são melhores para usar nas verificações de renderização.
Outra dica aqui - se você quiser ver uma renderização rolável completa de uma página, você pode alternar para a guia HTML da ferramenta de teste móvel do Google, pressionar CTRL + A para destacar todo o código HTML renderizado, copiar e colar em um editor de texto e salve como um arquivo HTML.
Abrindo isso no seu navegador (dedos cruzados, às vezes depende do CMS usado!) E o benefício disso é que você pode verificar como qualquer site é renderizado – você não precisa de acesso ao Search Console.
5 – Sites invadidos e backlinks com spam
Isso é muito divertido de pegar e muitas vezes pode se infiltrar em sites que estão sendo executados em versões mais antigas do WordPress ou outras plataformas CMS que exigem atualizações de segurança regulares.
Com este cliente (um spa de beleza), notei alguns termos de pesquisa estranhos aparecendo no Search Console.
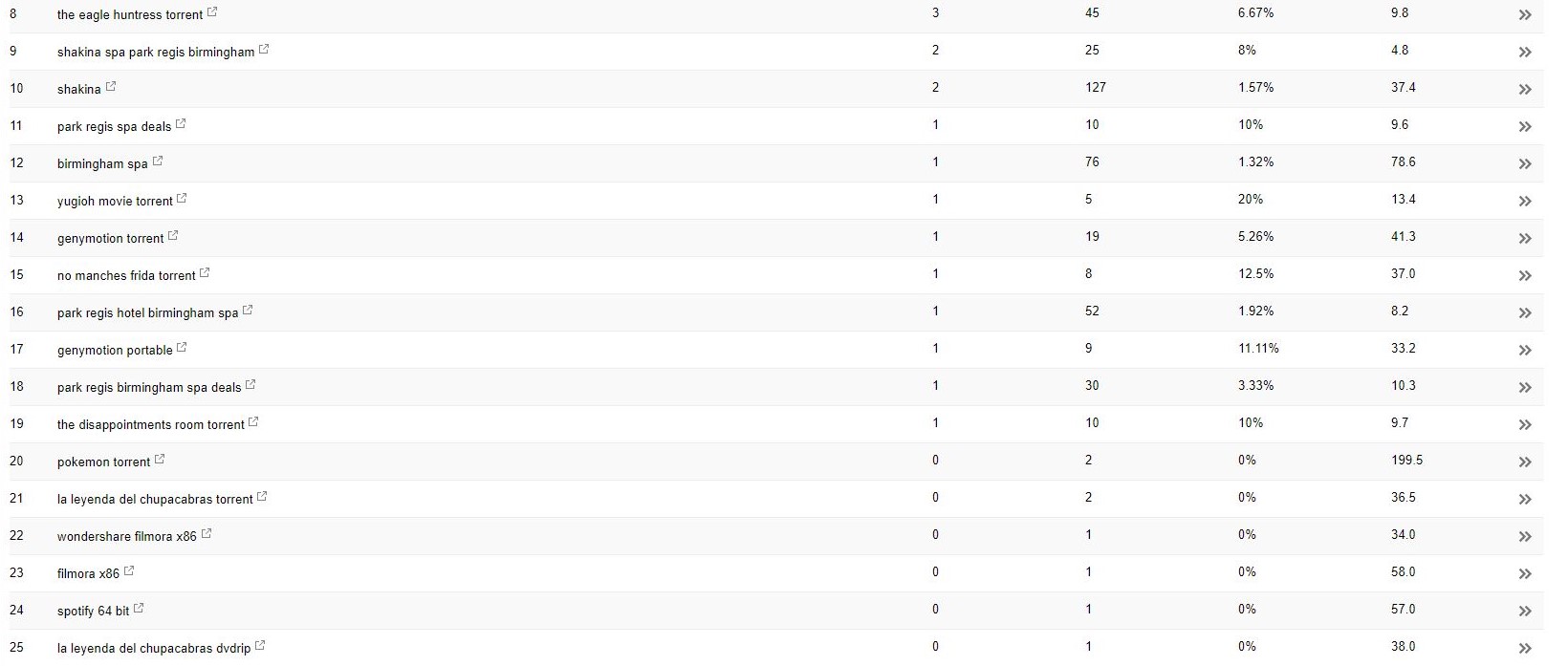
Surpreendentemente, eles não apenas tiveram impressões no Search Console, mas também cliques – o que significa que algo deve ter sido indexado no domínio.
A julgar pelas consultas, era claramente muito spam, e não algo que o cliente gostaria que seus negócios fossem associados.
Fazendo uma simples busca “site:domain.com” no Google desenterrou centenas de páginas de supostos torrents que o cliente supostamente estava hospedando em seu site.
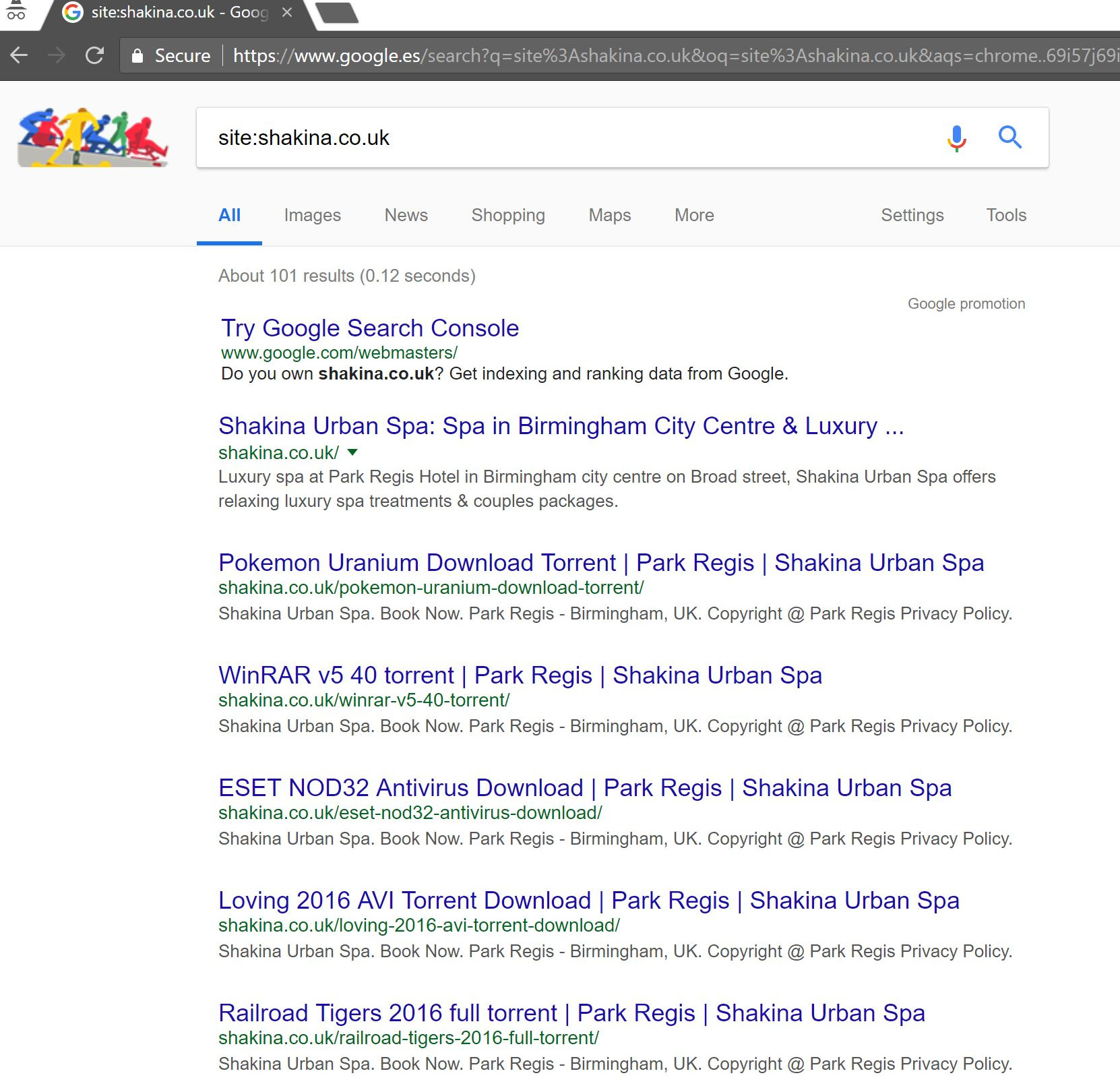
Visitar qualquer um desses URLs realmente resultou em um 404 - mas eles ainda estavam indexados (também verifiquei vários User Agents e todos eles obtiveram o mesmo erro 404).
Em seguida, executei o domínio através do verificador de backlinks do Majestic e ele forneceu uma longa lista de backlinks de qualidade muito baixa apontando para essas páginas nos sites dos clientes - o que provavelmente estava ajudando a indexá-los.
Observar a Nuvem Âncora do Majestic dos backlinks realmente mostrou a extensão do problema.


A única correção aqui foi rejeitar todos esses backlinks por domínio e, em seguida, executar uma varredura limpa da instalação do WordPress na esperança de limpar qualquer injeção de código ou instalar uma nova cópia do WordPress.
Se você estiver realmente preocupado com o conteúdo indexado em casos como o acima, também poderá fornecer um código de status 410 para realmente esclarecer as coisas com os rastreadores de pesquisa.
O acima seria adequado para os sites que receberam avisos legais devido a reivindicações de direitos autorais de produtores de filmes – o que às vezes pode ocorrer em situações como essa se o problema não for resolvido rapidamente.
6 – Configurações ruins de SEO internacional
Sendo baseado na Espanha, mas navegando na internet em meu inglês nativo, muitas vezes me vejo sendo redirecionado automaticamente para uma versão em espanhol de um site.
Embora eu entenda a lógica (estou baseado na Espanha, portanto, quero navegar no site em espanhol), é muito chato do ponto de vista da experiência do usuário e, se não for feito corretamente, também pode causar um pouco de estragos no seu SEO internacional.
Sites como o Google Ads levam isso a outro nível – fazendo uso de JavaScript Angular para gerar conteúdo dinamicamente com base na minha localização, nem mesmo passando por um redirecionamento de página de qualquer tipo e carregando o conteúdo diretamente no DOM.
Meu método preferido de escolha quando vários idiomas estão disponíveis é redirecionar 302 um usuário para um idioma com base nas configurações do navegador da Internet.
Portanto, se alguém tiver o alemão como idioma padrão no Google Chrome, provavelmente ficará à vontade para ler o site em alemão, independentemente de sua localização física.
Isso também ajuda a superar as dificuldades quando alguém está baseado em uma região onde vários idiomas são falados, como na Suíça, onde o francês, o italiano, o alemão e o romanche são usados.
Também é fundamental para fins de usabilidade garantir que haja uma opção de alternar idiomas com base em sua preferência - caso eles desejem alternar.
Em um caso, trabalhei com um hotel sediado em Barcelona, onde um script de redirecionamento de linguagem JavaScript foi adicionado a um site sem considerar o impacto do SEO.
Esse script redirecionava os usuários com base na configuração de idioma do navegador (o que não é tão ruim por si só) por meio de um redirecionamento JavaScript do lado do cliente.
Infelizmente, neste caso, o script não foi configurado corretamente devido a uma configuração estranha dos links permanentes dos sites e, quando combinado com o fato de que a tag HTML lang estava faltando em todas as páginas do site, o Googlebot enlouqueceu…
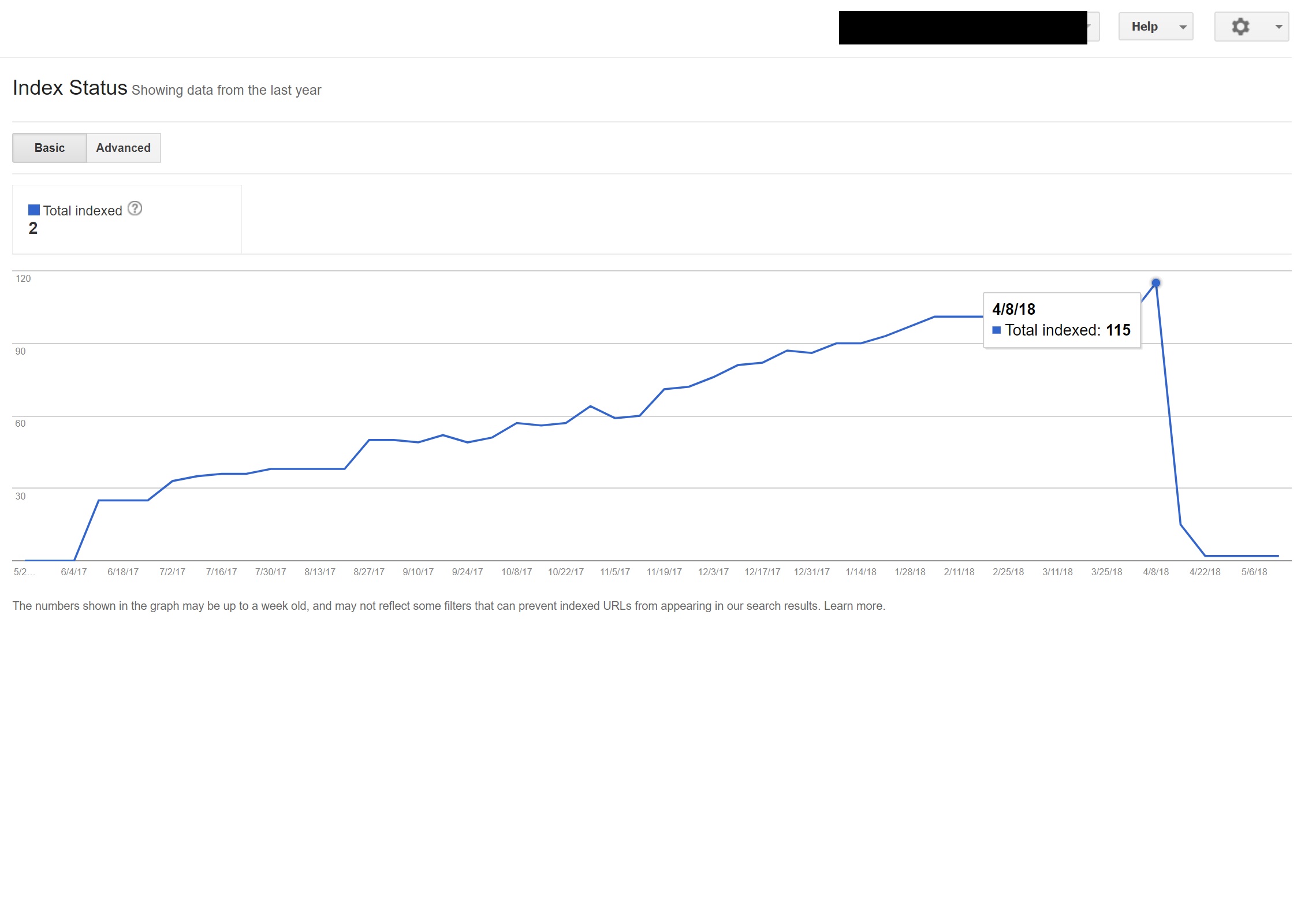
Neste exemplo, quase todo o conteúdo não inglês no site foi desindexado pelo Google, porque estava sendo redirecionado para páginas que não existiam, servindo assim a vários erros 404.
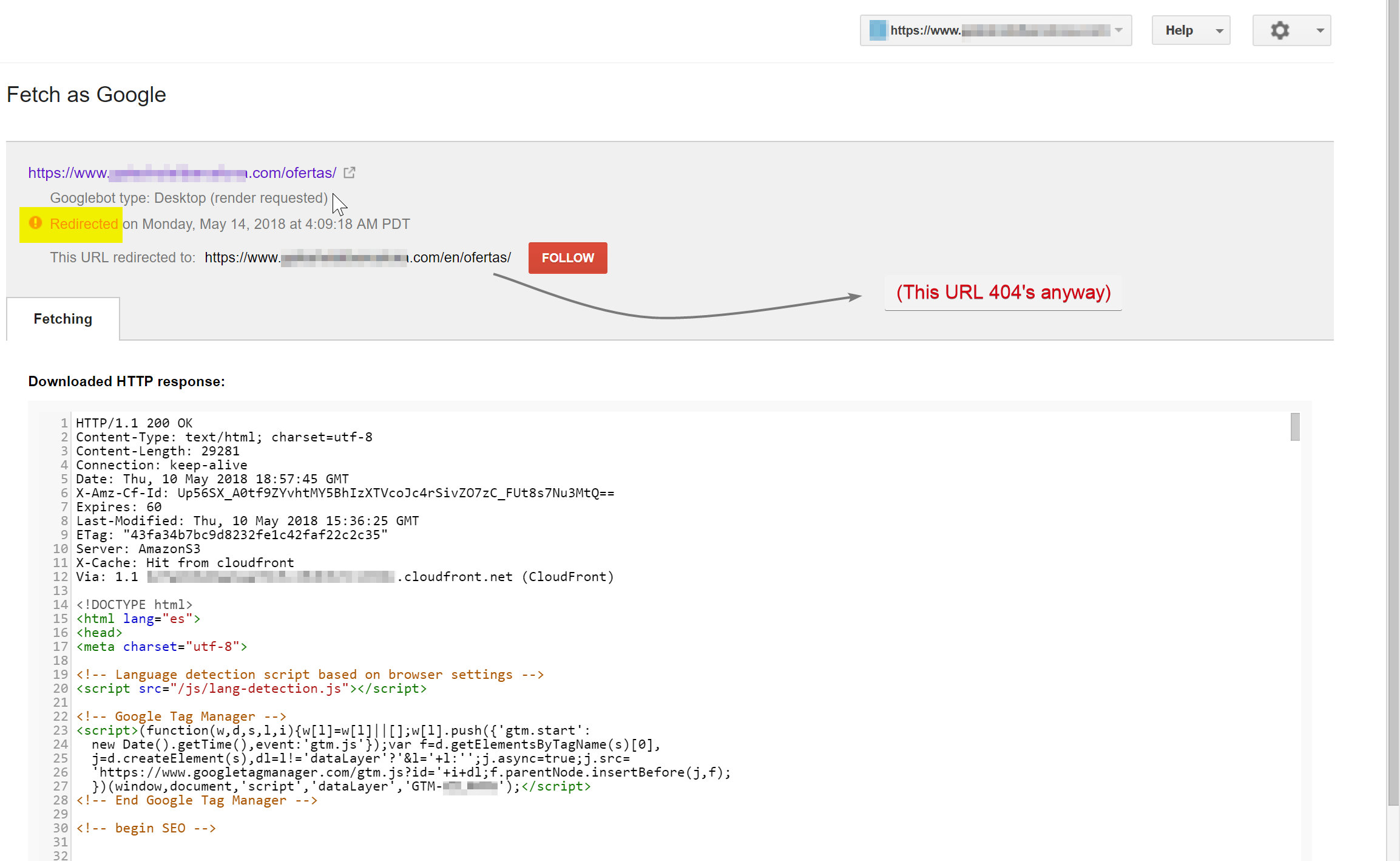
O Googlebot estava tentando rastrear o conteúdo em espanhol (que existia em hotelname.com/ofertas) e estava sendo redirecionado para hotelname.com/en/ofertas – uma URL inexistente.
Surpreendentemente, neste caso, o Googlebot estava seguindo todos esses redirecionamentos JavaScript e, como não conseguiu encontrar esses URLs, foi forçado a removê-los de seu índice.
No caso acima, consegui confirmar isso acessando os logs do servidor do site, filtrando para o Googlebot e verificando onde ele estava recebendo 404's.
A remoção do script de redirecionamento de JavaScript defeituoso resolveu o problema e, felizmente, as páginas traduzidas não foram desindexadas por muito tempo.
É sempre uma boa ideia testar as coisas completamente – investir em uma VPN pode ajudar a diagnosticar esses tipos de cenários ou até mesmo alterar sua localização e/ou idioma no navegador Chrome.
[Estudo de caso] Como lidar com auditorias em vários locais
 Leia o estudo de caso
Leia o estudo de caso7 – Conteúdo duplicado
Conteúdo duplicado é um problema bastante comum e bem discutido, e há muitas maneiras de verificar se há conteúdo duplicado em seu site – Richard Baxter escreveu recentemente um ótimo artigo sobre o assunto.
No meu caso, o problema é provavelmente um pouco mais simples. Tenho visto regularmente sites publicando ótimo conteúdo, geralmente como uma postagem de blog, mas quase instantaneamente compartilhando esse conteúdo em um site de terceiros como o Medium.com.
O Medium é um ótimo site para redirecionar o conteúdo existente para alcançar públicos mais amplos, mas deve-se ter cuidado com a forma como isso é abordado.
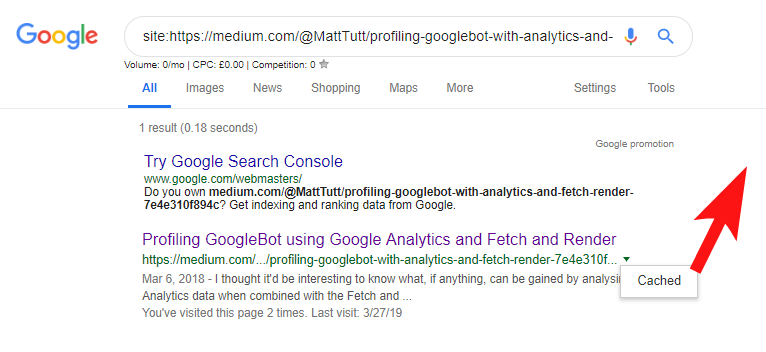
Ao importar conteúdo do WordPress para o Medium, durante esse processo o Medium usará a URL do seu site como sua tag canônica. Então, em teoria, deve ajudar a dar ao seu site o crédito pelo conteúdo, como a fonte original.
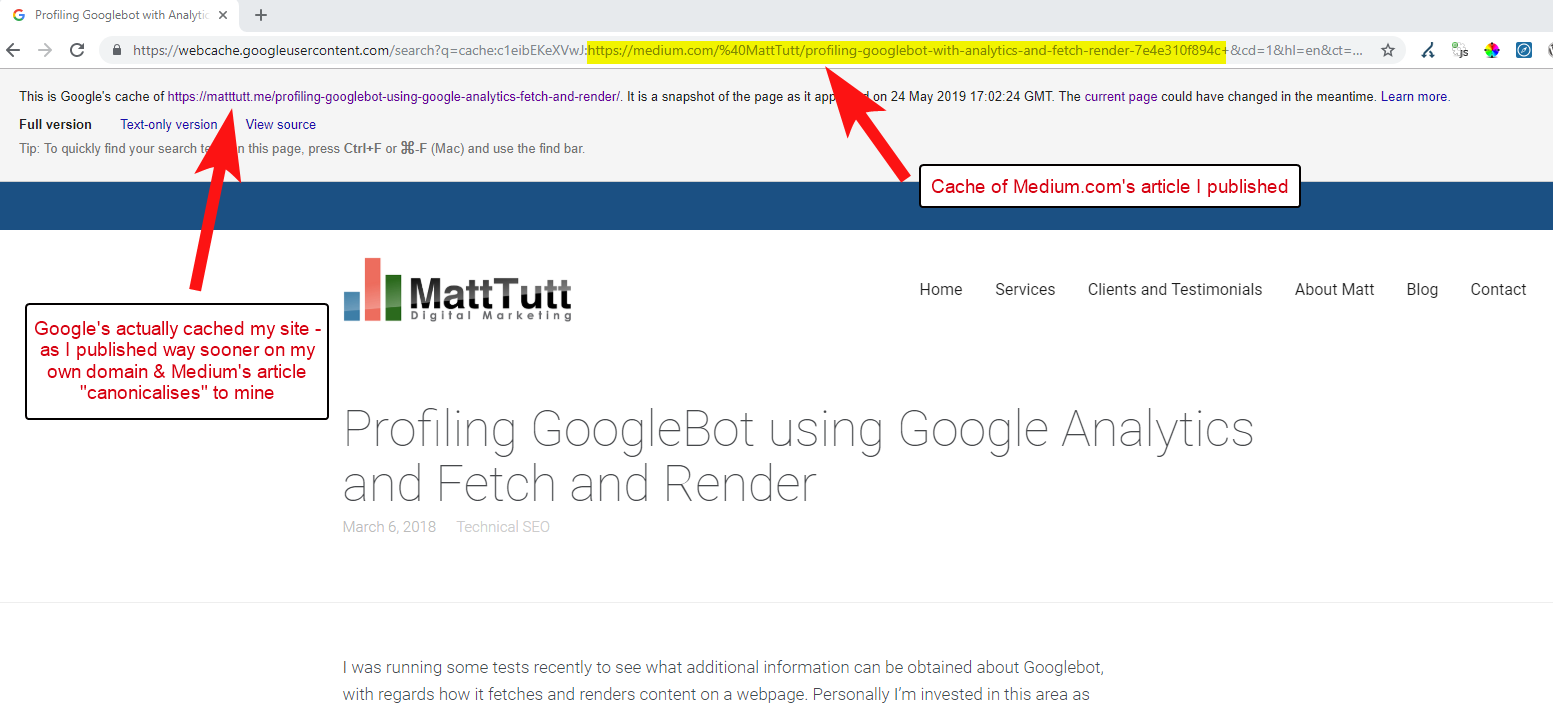
De algumas das minhas análises, embora nem sempre funcione assim.
Acredito que seja esse o caso porque quando um artigo é publicado no Medium sem primeiro permitir que o Google rastreie e indexe o artigo em seu domínio, se o artigo cair bem no Medium (o que é um pouco imprevisível), seu conteúdo será indexados e associados ao site do Medium, apesar de apontarem canônicos para o seu.
Uma vez que o conteúdo é adicionado ao Medium (e particularmente se for popular), você pode garantir que a peça será copiada e republicada na web em outro lugar quase instantaneamente – então, novamente, seu conteúdo está sendo duplicado em outro lugar.
Enquanto tudo isso está acontecendo, é provável que, se seu domínio for muito pequeno em termos de autoridade, o Google pode nem ter a chance de rastrear e indexar o conteúdo que você publicou - e pode até ser que o elemento de renderização do o rastreamento/índice ainda não foi concluído ou há um JavaScript pesado causando um grande atraso entre o rastreamento, a renderização e a indexação desse conteúdo.
Já vi situações em que uma grande empresa publica um ótimo artigo, mas no dia seguinte o publica como uma reflexão em um enorme blog de notícias do setor. Além disso, o site deles teve um problema em que o conteúdo era duplicado (e indexado) em https://domain.com e https://www.domain.com.
Poucos dias após a publicação, ao pesquisar uma frase exata do artigo entre aspas no Google, o site da empresa não estava em lugar nenhum. Em vez disso, o blog oficial da indústria estava em primeiro lugar, e outros reeditores estavam assumindo as próximas posições.
Nesse caso, o conteúdo foi associado ao blog do setor e, portanto, qualquer link que a peça ganhe beneficiará esse site - não o editor original.
Se você for redirecionar conteúdo em qualquer lugar da web, é provável que ele seja indexado, você deve realmente esperar até ter certeza absoluta de que foi indexado pelo Google em seu próprio domínio.
Você provavelmente trabalha duro para criar e elaborar seu conteúdo – não jogue tudo fora por querer republicar em outro lugar!
8 – Configuração de AMP incorreta (declaração de URL de AMP ausente)
Apenas alguns dos clientes que ajudei optaram por dar uma chance ao AMP, talvez com base em alguns dos muitos estudos de caso financiados pelo Google sobre seu uso.
Às vezes, eu nem sabia que um cliente tinha uma versão AMP de seu site – havia algum tráfego estranho aparecendo nos relatórios de referência do Google Analytics – onde a versão AMP do site estava vinculando à versão não AMP do site.
Nesse caso, as versões da página AMP não foram configuradas corretamente, pois não havia referência de URL do cabeçalho das páginas não AMP.

Sem informar aos mecanismos de pesquisa que uma página AMP existe em um URL específico, não há muito sentido em configurar o AMP – o ponto é que ele é indexado e retornado no SERPS para usuários móveis.
Adicionar a referência à sua página não AMP é uma maneira importante de informar ao Google sobre a página AMP, e é importante lembrar que as tags canônicas nas páginas AMP não devem ser auto-referenciadas: elas são vinculadas à página não AMP.
E, embora não seja realmente uma consideração técnica de SEO, vale a pena notar que você ainda precisa incluir o código de rastreamento nas páginas AMP se quiser relatar qualquer informação de tráfego e comportamento do usuário.
Normalmente, como parte de minhas auditorias de SEO, também gosto de executar algumas verificações básicas da implementação da análise - caso contrário, os dados fornecidos podem não ser tão úteis, especialmente se houver uma configuração de análise incorreta.
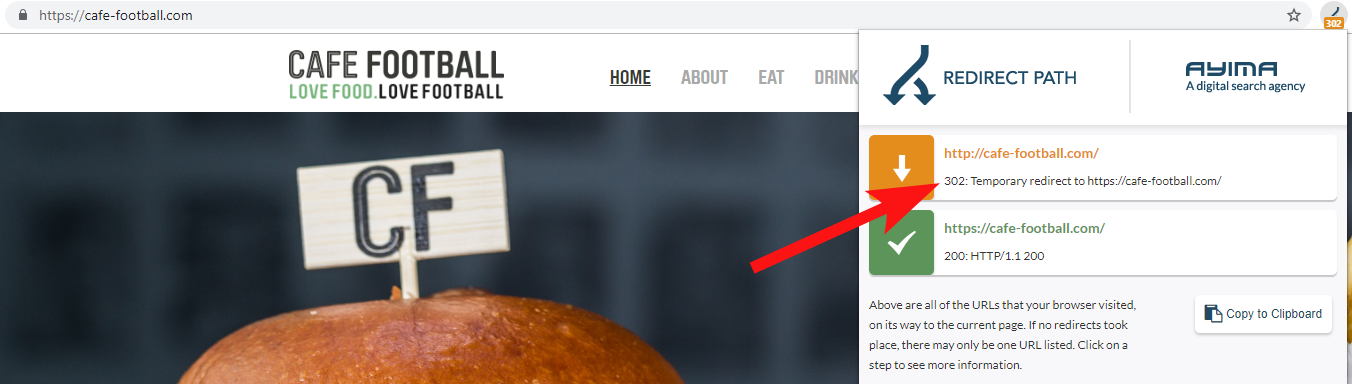
9 – Domínios Legados que redirecionam 302 ou formam uma cadeia de redirecionamentos
Ao trabalhar com uma grande marca de hotel independente nos EUA, que passou por várias mudanças de marca nos últimos anos (bastante comum no setor de hospitalidade), é importante monitorar como as solicitações anteriores de nomes de domínio se comportam.
Isso é fácil de esquecer, mas pode ser uma simples verificação semi-regular de tentar rastrear seu site antigo usando uma ferramenta como OnCrawl ou até mesmo um site de terceiros que verifica códigos de status e redirecionamentos.
Na maioria das vezes, você encontrará o domínio 302 redireciona para o destino final (301 é sempre a melhor aposta aqui) ou 302 para uma versão não WWW do URL antes de passar por vários outros redirecionamentos antes de atingir o URL final.
John Mueller, do Google, havia declarado antes que eles seguem apenas 5 redirecionamentos antes de desistir, embora também se saiba que para cada redirecionamento passado, parte do valor do link é perdido. Por essas razões, prefiro manter os redirecionamentos 301 o mais limpos possível.
O Redirect Path da Ayima é uma ótima extensão do navegador Chrome que mostra os status de redirecionamento enquanto você navega na web.
Outra maneira de detectar nomes de domínio antigos pertencentes a um cliente é pesquisando no Google o número de telefone dele, usando aspas de correspondência exata ou partes do endereço.
Uma empresa como um hotel não costuma mudar de endereço (pelo menos parte dele de qualquer maneira) e você pode encontrar diretórios/perfis de negócios antigos vinculados a um domínio antigo.
Usar uma ferramenta de backlink como Majestic ou Ahrefs também pode mostrar alguns links antigos de domínios anteriores, então esse também é um bom porto de escala – especialmente se você não estiver em contato direto com o cliente.
10 – Lidando mal com o conteúdo de pesquisa interna
Este é realmente um tópico sobre o qual escrevi antes aqui no OnCrawl – mas estou incluindo-o novamente porque ainda vejo conteúdo interno problemático acontecendo “na natureza” com muita frequência.
Comecei este artigo falando sobre o problema da diretiva robots.txt do Pingdom, que do meu lado parecia ser uma correção para evitar que o conteúdo que eles estavam produzindo fosse rastreado e indexado.
Qualquer site que forneça resultados de pesquisa interna ao Google como conteúdo, ou que produza muito conteúdo gerado pelo usuário, precisa ter muito cuidado com a maneira como o faz.
Se um site estiver veiculando resultados de pesquisa interna ao Google de maneira muito direta, isso poderá levar a algum tipo de penalidade manual. O Google provavelmente veria isso como uma experiência ruim do usuário – eles pesquisam por X e, em seguida, chegam a um site onde precisam filtrar manualmente o que desejam.
Em alguns casos, acredito que pode ser bom servir conteúdo interno, depende apenas do contexto e das circunstâncias. Um local de trabalho, por exemplo, pode querer exibir os últimos resultados de trabalho que são atualizados quase diariamente – então eles quase têm que lidar com isso.
O Indeed é um exemplo famoso de um site de empregos que talvez leve isso longe demais, gerando todo tipo de conteúdo com base em consultas de pesquisa populares (veja abaixo o que pode acontecer se você usar essa tática).
Apesar disso, de acordo com os dados da SEMRush, seu tráfego orgânico está indo muito bem – mas essas são linhas tênues, e se comportar assim coloca você em alto risco de uma penalidade do Google.
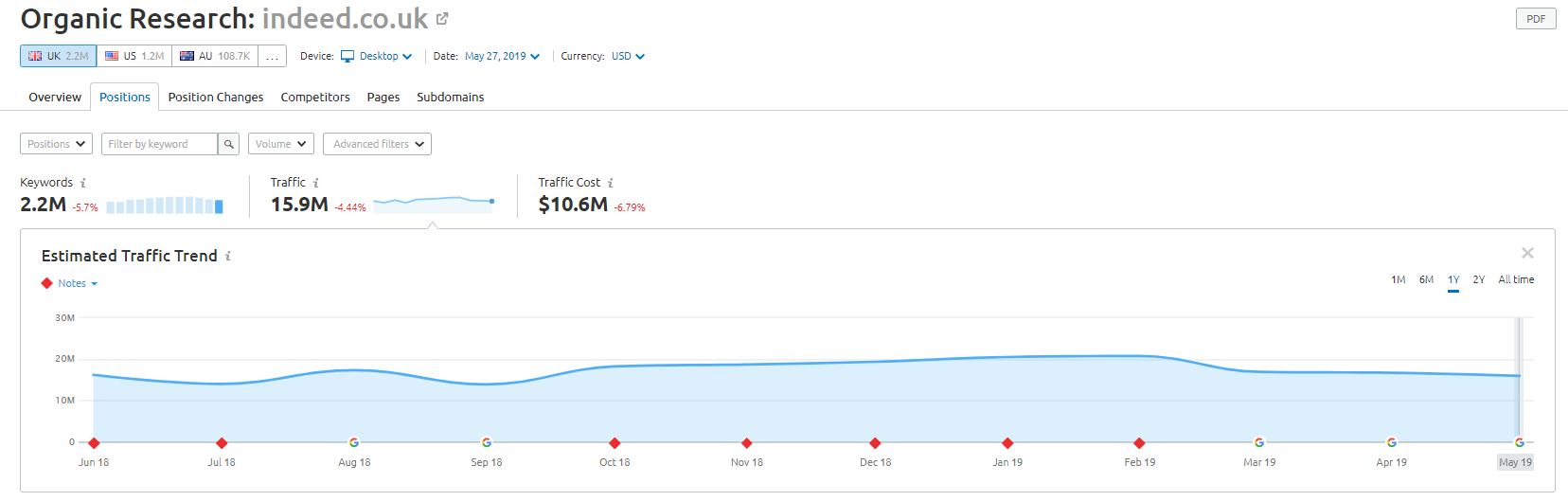
A loja online Wayfair.com é outra marca que gosta de navegar ao sabor do vento. Com milhões de URLs indexados (e muitos URLs de palavras-chave gerados automaticamente), eles estão indo muito bem em termos de tráfego orgânico – mas correm alto risco de serem penalizados por fornecer conteúdo dessa maneira aos mecanismos de pesquisa.
Ao implementar uma estrutura de site adequada, que envolve a categorização de todo o conteúdo, a construção de diferentes hierarquias pai/filho, até mesmo o uso de tags ou outras taxonomias personalizadas, você pode ajudar na navegação do cliente e do rastreador de pesquisa.
Usar truques como os acima pode ganhar a curto prazo, mas é improvável que faça muito por você a longo prazo. Isso torna fundamental obter a estrutura do site desde o início ou, pelo menos, planejá-la adequadamente com antecedência.
Empacotando
Os 10 erros discutidos neste artigo são alguns dos problemas técnicos mais comuns que encontro durante as auditorias do site.
Corrigir esses erros em seu site é o primeiro passo para garantir que seu site esteja tecnicamente íntegro. Depois que esses problemas são corrigidos, as auditorias técnicas podem se concentrar em problemas específicos do seu site.