
Ciência de dados orientada para negócios
Publicados: 2018-12-13Dizem que Cientista de Dados é o trabalho mais sexy do século 21 (e todos os Cientistas de Dados que conheci em várias conferências sabem disso). Mas quando eles falam apenas sobre a parte teórica do aprendizado de máquina, às vezes me pergunto se eles sabem por que seu trabalho é quente. A razão é que um Cientista de Dados sabe como combinar dados, habilidades técnicas e conhecimento de estatísticas para atingir as metas de negócios. Então, para fazer Data Science bem, você precisa pensar primeiro no negócio.
Conheço casos em que as empresas adicionaram ferramentas analíticas para rastrear o toque de cada usuário sem qualquer consideração sobre o que eles realmente desejam realizar. Eles reuniram muitos dados que não entendiam e não podiam usar para avançar seus negócios.
Não cometa tais erros! Pense em seus objetivos e na especificidade do setor em cada etapa do processo de Data Science. Quanto mais criativo você for, melhor será sua chance de sucesso. Para provar isso, vou mostrar alguns exemplos inspiradores de Data Science nas aplicações dos gigantes…
Como iniciar sua aventura de ciência de dados
Você já ouviu falar que muitas empresas usam o ML para aumentar sua receita, mas não tem ideia de como começar? Para não acabar com uma infraestrutura cara e dados inúteis (para atender às suas necessidades de negócios), você deve começar fornecendo respostas para as seguintes perguntas:
Quais são os objetivos de negócios do cliente? Como podemos usar os dados para alcançá-los?
Em seguida, você pode começar a planejar quais dados podem ser rastreados e usados.
Coleta de dados
Quais dados devemos coletar? A resposta a esta pergunta pode realmente surpreendê-lo. De acordo com Todd Yellin (VP de Inovação de Produto da Netflix), existem dois tipos de dados que podem ser usados: explícitos e implícitos [1]. No caso da Netflix, o explícito é quando o usuário literalmente avalia um filme. Por outro lado, estão implícitos os dados comportamentais – com base nos cliques do usuário e no uso do aplicativo. Qual tipo é mais valioso?
Não existe uma resposta universal para essa pergunta, mas na maioria dos casos, os dados implícitos seriam mais úteis . E isso porque... as pessoas mentem.
Considere o exemplo do homem que diz que ama documentários e os classifica com 5/5. Mas, como mostram os dados, ele assiste a esse gênero uma vez por ano. Ao mesmo tempo, ele assiste a séries populares toda sexta-feira à noite. E é porque ele está cansado depois do trabalho e só quer relaxar no sofá. Então, quais dados devem ser usados para preparar esse sistema de recomendação: classificação ou comportamento do usuário?
Para responder a essa pergunta, precisamos pensar no objetivo de negócio de seu desenvolvimento. O objetivo da Netflix é incentivar o usuário a assistir mais filmes. Eles começaram com o popular sistema de classificação de cinco estrelas. Ao perceberem que é mais provável que os usuários mencionados vejam Friends em vez de um filme sobre a Segunda Guerra Mundial, eles desenvolveram o sistema de recomendação baseado no comportamento do usuário. Eles também derrubaram a classificação de cinco estrelas e a substituíram por um sistema binário mais simples de polegar para cima e polegar para baixo.
Como este exemplo mostra, os dados coletados devem ser selecionados levando em consideração a especificidade do setor e devem trazer informações suficientes para entender as decisões e necessidades dos usuários. Mas aqui encontramos outro problema: dados comportamentais, textos e outros dados não estruturados são mais difíceis de analisar e usar em modelos de Machine Learning do que em modelos estruturados. Então agora é hora de falar sobre engenharia de recursos.
Engenharia de recursos
Para mostrar a importância da engenharia de recursos na ciência de dados, gostaria de citar Andrew Ng – cofundador do Google Brain e fundador do deeplearning.ai:
Criar recursos é difícil, demorado, requer conhecimento especializado. O aprendizado de máquina aplicado é basicamente engenharia de recursos. [2].
https://forum.stanford.edu/events/2011/2011slides/plenary/2011plenaryNg.pdf
Um exemplo interessante de uma abordagem orientada para o processamento de dados é o Booking.com, onde os usuários podem classificar os hotéis de 0 a 10. Mas se um animal festeiro avaliar o hotel muito bem, é uma boa escolha para famílias com crianças? Não necessariamente.

Felizmente, também existem comentários de usuários que contêm mais informações de que precisamos. Booking.com usa análise de sentimentos e modelagem de tópicos para extrair os pontos fortes e fracos do hotel comentado e as preferências dos usuários em relação à acomodação.
Vamos considerar este exemplo:
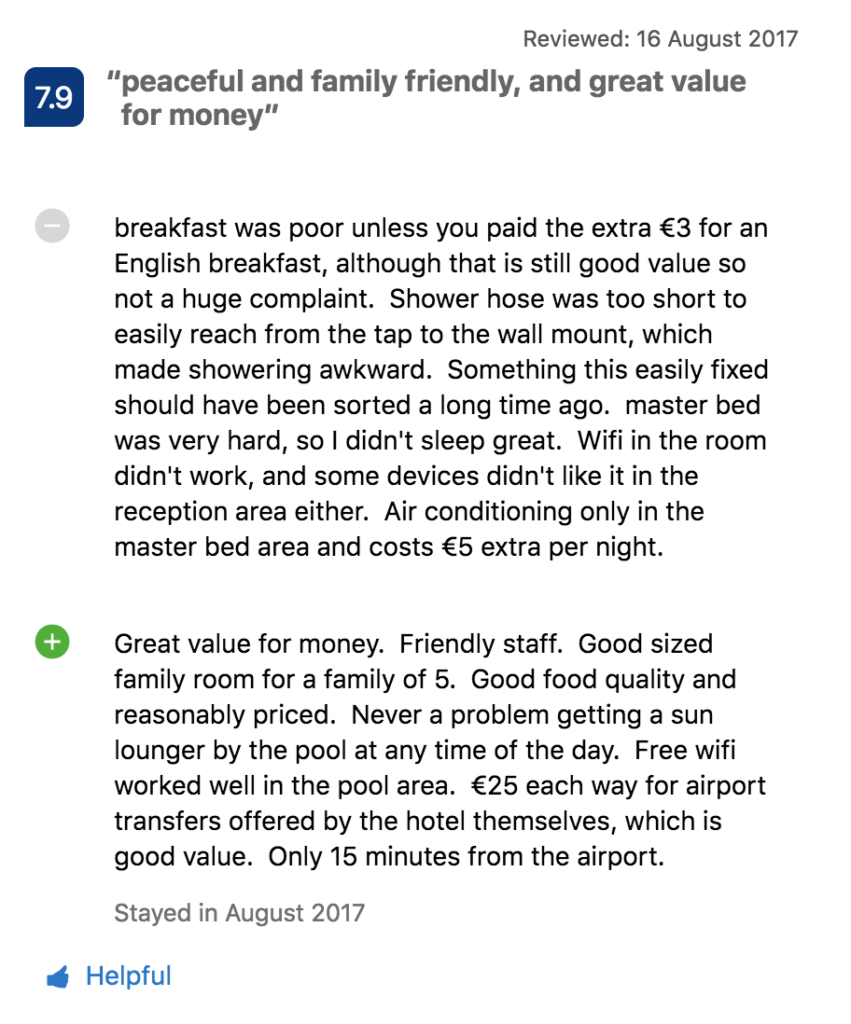
Um tópico Instalações do quarto tem sentimento negativo (o usuário reclama de chuveiro, cama, wifi e ar condicionado). Ao mesmo tempo, esse usuário elogia o Valor pelo preço do hotel, equipe e alimentação. O sistema também analisa o que não foi mencionado no comentário e, portanto, provavelmente não é importante para o usuário – no nosso exemplo pode ser a vida noturna.
Com esses insights, a plataforma pode oferecer hotéis mais adequados para usuários com perfil semelhante, neste caso, uma família com filhos que procura um lugar para passar férias em um hotel tranquilo por um preço razoável. Além disso, Booking.com classifica os comentários para mostrar as informações mais interessantes para o espectador no topo.
Isso leva a uma situação ganha-ganha: os usuários podem encontrar ofertas adaptadas às suas necessidades específicas com mais rapidez e facilidade, e a plataforma lucra porque essas ofertas são as que os usuários têm mais probabilidade de comprar.

Curioso sobre Ciência de Dados?
Saber maisProduto de dados
Você implantou produtos de dados com resultados satisfatórios? Não é hora de ser complacente. Como mostra o exemplo da Netflix [3] , o trabalho contínuo na melhoria do sistema pode trazer ganhos significativos. Uma recomendação de filme adequada é suficiente? O que mais poderíamos fazer?
Uma das abordagens prontas para uso da Netflix não é apenas recomendar filmes, mas também ilustrá-los com uma imagem que seria mais atraente para um determinado usuário. Digamos que eles recomendem você Good Will Hunting . Se você assistiu a muitas comédias românticas no passado, poderá ver a imagem de um casal se beijando, enquanto se for um fã de comédia, provavelmente terá uma foto de um comediante americano popular:

Com essa abordagem, é muito mais provável que um usuário percorrendo uma infinidade de opções encontre um filme que chame sua atenção.
Essa e outras estratégias de recomendação têm resultados surpreendentes – mais de 80% do conteúdo da plataforma é baseado em recomendações algorítmicas . Isso significa que é difícil para um usuário ficar sem coisas para assistir. Quando um programa termina, a Netflix está lá para sugerir o próximo.
Em seus negócios, isso oferece uma vantagem competitiva porque os usuários têm muito menos probabilidade de cancelar suas assinaturas. Essa aplicação extremamente bem-sucedida de Data Science foi alcançada principalmente pelo bom entendimento de seus negócios e usuários de aplicativos.
O sumário
Em uma das conferências de Data Science deste ano, um palestrante envolvido em previsões de risco de crédito disse:
Quando as pessoas me perguntam qual é basicamente o meu trabalho, eu respondo: eu trago valores de negócios com base em dados.
Para mim, essa é uma das melhores definições de Data Science. Não deve ser orientado apenas em seus fundamentos teóricos, mas principalmente nos negócios. Se você deseja criar um bom aplicativo de Machine Learning, precisa pensar em como os usuários se comportam em seu sistema e o que eles precisam. Com isso em mente, você alcançará seus objetivos de negócios com sucesso.