
Pipeline de Business Intelligence baseado em serviços da AWS – estudo de caso
Publicados: 2019-05-16Nos últimos anos, vimos um aumento no interesse pela análise de big data. Executivos, gerentes e outras partes interessadas nos negócios usam Business Intelligence (BI) para tomar decisões informadas. Ele permite que eles analisem informações críticas imediatamente e tomem decisões com base não apenas em sua intuição, mas no que podem aprender com o comportamento real de seus clientes.
Quando você decide criar uma solução de BI eficaz e informativa, um dos primeiros passos que sua equipe de desenvolvimento precisa dar é planejar a arquitetura do pipeline de dados. Existem várias ferramentas baseadas em nuvem que podem ser aplicadas para construir esse pipeline, e não há uma solução que seja a melhor para todos os negócios. Antes de decidir sobre uma opção específica, você deve considerar sua pilha de tecnologia atual, preços de ferramentas e o conjunto de habilidades de seus desenvolvedores. Neste artigo, mostrarei uma arquitetura construída com ferramentas da AWS que foi implantada com sucesso como parte do aplicativo Timesheets.
Visão geral da arquitetura
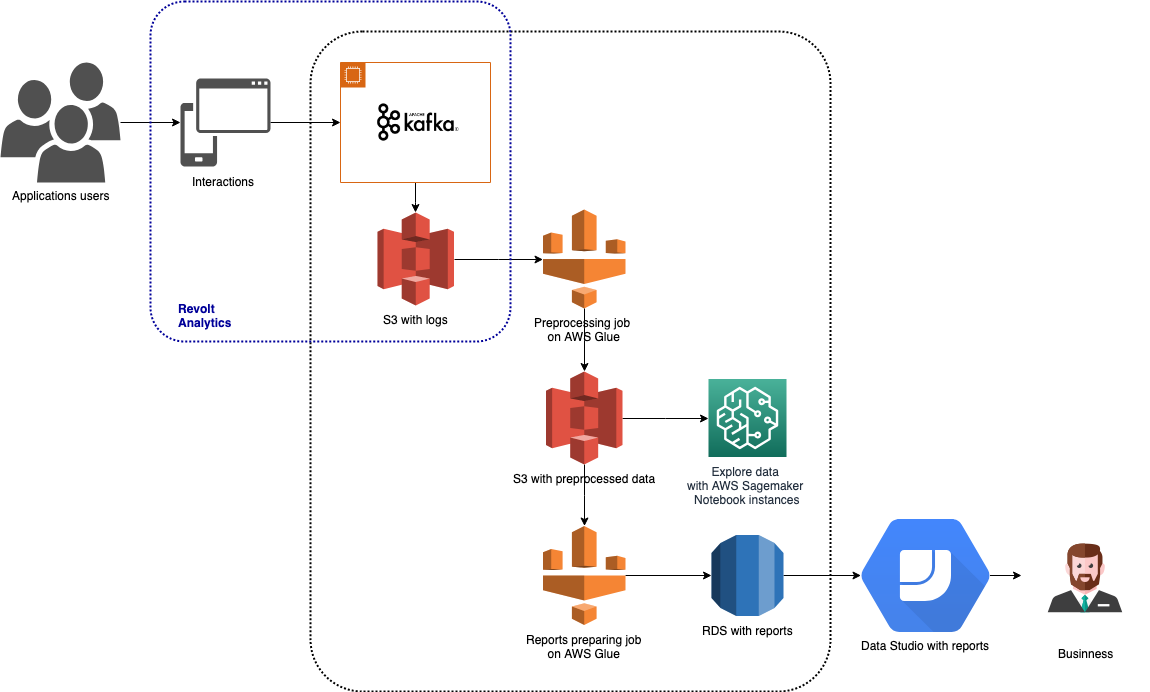
O Timesheets é uma ferramenta para rastrear e relatar o tempo dos funcionários. Pode ser usado via web, iOS, Android e aplicativos de desktop, chatbot integrado ao Hangouts e Slack e ação no Google Assistant. Como existem muitos tipos de aplicativos disponíveis, também há muitos dados diversos para rastrear. Os dados são coletados via Revolt Analytics, armazenados no Amazon S3 e processados com AWS Glue e Amazon SageMaker. Os resultados da análise são armazenados no Amazon RDS e são usados para criar relatórios visuais no Google Data Studio. Essa arquitetura é apresentada no gráfico acima.
Nos parágrafos a seguir, descreverei brevemente cada uma das ferramentas de Big Data usadas nessa arquitetura.
Análise de revolta
Revolt Analytics é uma ferramenta desenvolvida pela Miquido para rastrear e analisar dados de aplicativos de todos os tipos. Para simplificar a implementação do Revolt em sistemas clientes, foram construídos SDKs para iOS, Android, JavaScript, Go, Python e Java. Uma das principais características do Revolt é o seu desempenho: todos os eventos são enfileirados, armazenados e enviados em pacotes, o que garante que sejam entregues de forma rápida e eficiente. O Revolt dá ao proprietário do aplicativo a capacidade de identificar usuários e rastrear seu comportamento no aplicativo. Isso nos permite construir modelos de aprendizado de máquina que agregam valor, como sistemas de recomendação totalmente personalizados e modelos de previsão de churn, e para criação de perfil de cliente com base no comportamento do usuário. O Revolt também fornece um recurso de sessionalização. O conhecimento sobre os caminhos e o comportamento do usuário nos aplicativos pode ajudá-lo a entender as metas e as necessidades de seus clientes.
O Revolt pode ser instalado em qualquer infraestrutura que você escolher. Essa abordagem oferece controle total sobre custos e eventos rastreados. No caso do Quadro de Horários apresentado neste artigo, ele foi construído na infraestrutura da AWS. Graças ao acesso total ao armazenamento de dados, os proprietários de produtos podem facilmente obter informações sobre seus aplicativos e usar esses dados em outros sistemas.
Os SDKs da Revolt são adicionados a todos os componentes do sistema dos Quadros de Horários, que consiste em:
- Aplicativos para Android e iOS (criados com Flutter)
- Aplicativo de desktop (criado com Electron)
- Aplicativo Web (escrito em React)
- Backend (escrito em Golang)
- Hangouts e bate-papos on-line do Slack
- Ação no Google Assistente
O Revolt fornece aos administradores de Timesheets conhecimento sobre dispositivos (por exemplo, marca do dispositivo, modelo) e sistemas (por exemplo, versão do sistema operacional, idioma, fuso horário) usados pelos clientes do aplicativo. Além disso, envia vários eventos personalizados associados à atividade dos usuários nos aplicativos. Consequentemente, os administradores podem analisar o comportamento do usuário e entender melhor seus objetivos e expectativas. Eles também podem verificar a usabilidade dos recursos implementados e avaliar se esses recursos atendem às suposições do Product Owner sobre como eles seriam usados.

Cola AWS
O AWS Glue é um serviço ETL (extrair, transformar e carregar) que ajuda a preparar dados para tarefas analíticas. Ele executa trabalhos ETL em um ambiente sem servidor Apache Spark. Normalmente, consiste nos três elementos seguintes:
- Definição do rastreador – um rastreador é usado para verificar dados em todos os tipos de repositórios e fontes, classificá-los, extrair informações de esquema deles e armazenar os metadados sobre eles no Catálogo de Dados. Ele pode, por exemplo, verificar logs armazenados em arquivos JSON no Amazon S3 e armazenar suas informações de esquema no Data Catalog.
- Script de trabalho – os trabalhos do AWS Glue transformam dados no formato desejado. O AWS Glue pode gerar automaticamente um script para carregar, limpar e transformar seus dados. Você também pode fornecer seu próprio script Apache Spark escrito em Python ou Scala que executaria as transformações desejadas. Eles podem incluir tarefas como manipulação de valores nulos, sessionalização, agregações, etc.
- Acionadores – Crawlers e trabalhos podem ser executados sob demanda ou podem ser configurados para iniciar quando ocorrer um acionador especificado. Um gatilho pode ser um agendamento baseado em tempo ou um evento (por exemplo, uma execução bem-sucedida de um trabalho especificado). Essa opção oferece a capacidade de gerenciar sem esforço a atualização dos dados em seus relatórios.
Em nossa arquitetura de Quadros de Horários, esta parte do pipeline apresenta-se da seguinte forma:
- Um gatilho baseado em tempo inicia um trabalho de pré-processamento, que executa a limpeza de dados, atribui logs de eventos apropriados às sessões e calcula as agregações iniciais. Os dados resultantes desse trabalho são armazenados no AWS S3.
- O segundo gatilho é configurado para ser executado após a execução completa e bem-sucedida do trabalho de pré-processamento. Esse acionador inicia um trabalho que prepara dados que são usados diretamente nos relatórios analisados pelos Product Owners.
- Os resultados do segundo trabalho são armazenados em um banco de dados AWS RDS. Isso os torna facilmente acessíveis e utilizáveis em ferramentas de Business Intelligence como Google Data Studio, PowerBI ou Tableau.
AWS SageMaker
O Amazon SageMaker fornece módulos para criar, treinar e implantar modelos de machine learning.
Ele permite treinamento e ajuste de modelos em qualquer escala e permite o uso de algoritmos de alto desempenho fornecidos pela AWS. No entanto, você também pode usar algoritmos personalizados depois de fornecer uma imagem de encaixe adequada. O AWS SageMaker também simplifica o ajuste de hiperparâmetros com trabalhos configuráveis que comparam métricas para diferentes conjuntos de parâmetros de modelo.
Nos Quadros de Horários, as Instâncias do Notebook do SageMaker nos ajudam a explorar os dados, testar scripts ETL e preparar protótipos de gráficos de visualização para serem usados em uma ferramenta de BI para criação de relatórios. Essa solução oferece suporte e melhora a colaboração de cientistas de dados, pois garante que eles trabalhem no mesmo ambiente de desenvolvimento. Além disso, isso ajuda a garantir que nenhum dado sensível (que pode fazer parte da saída das células dos notebooks) seja armazenado além da infraestrutura da AWS porque os notebooks são armazenados apenas em buckets do AWS S3 e nenhum repositório git é necessário para compartilhar o trabalho entre colegas .
Embrulhar
Decidir quais ferramentas de Big Data e Machine Learning usar é crucial para projetar uma arquitetura de pipeline para uma solução de Business Intelligence. Essa escolha pode ter um impacto substancial nos recursos do sistema, nos custos e na facilidade de adicionar novos recursos no futuro. As ferramentas da AWS certamente merecem consideração, mas você deve selecionar uma tecnologia que se adeque à sua pilha de tecnologia atual e às habilidades de sua equipe de desenvolvimento.
Aproveite a nossa experiência na construção de soluções orientadas para o futuro e contacte-nos!