
Extraia automaticamente conceitos e palavras-chave de um texto (Parte I: Os métodos tradicionais)
Publicados: 2022-02-22No departamento de P&D da Oncrawl, buscamos cada vez mais aprimorar o conteúdo semântico de suas páginas da Web. Usando modelos de Machine Learning para processamento de linguagem natural (NLP), podemos comparar detalhadamente o conteúdo de suas páginas, criar resumos automáticos, completar ou corrigir as tags de seus artigos, otimizar o conteúdo de acordo com seus dados do Google Search Console , etc.
Em um artigo anterior, falamos sobre como extrair conteúdo de texto de páginas HTML. Desta vez, gostaríamos de falar sobre a extração automática de palavras-chave de um texto. Este tópico será dividido em dois posts:
- o primeiro abordará o contexto e os métodos chamados “tradicionais” com vários exemplos concretos
- o segundo, em breve, tratará de abordagens mais semânticas baseadas em transformadores e métodos de avaliação para fazer benchmark desses diferentes métodos
Contexto
Para além de um título ou resumo, que melhor forma de identificar o conteúdo de um texto, artigo científico ou página web do que com algumas palavras-chave. É uma maneira simples e muito eficaz de identificar o tema e os conceitos de um texto muito mais longo. Também pode ser uma boa maneira de categorizar uma série de textos: identificá-los e agrupá-los por palavras-chave. Sites que oferecem artigos científicos como PubMed ou arxiv.org podem oferecer categorias e recomendações com base nessas palavras-chave.
Palavras-chave também são muito úteis para indexação de documentos muito grandes e para recuperação de informações, um campo de especialização bem conhecido pelos motores de busca
A falta de palavras-chave é um problema recorrente na categorização automática de artigos científicos [1]: muitos artigos não possuem palavras-chave atribuídas. Portanto, métodos devem ser encontrados para extrair automaticamente conceitos e palavras-chave de um texto. Para avaliar a relevância de um conjunto de palavras-chave extraídas automaticamente, conjuntos de dados geralmente comparam as palavras-chave extraídas por um algoritmo com palavras-chave extraídas por vários humanos.
Como você pode imaginar, esse é um problema compartilhado pelos mecanismos de busca ao categorizar as páginas da web. Uma melhor compreensão dos processos automatizados de extração de palavras-chave permite entender melhor por que uma página da web está posicionada para tal ou tal palavra-chave. Ele também pode revelar lacunas semânticas que o impedem de classificar bem a palavra-chave que você segmentou.
Obviamente, existem várias maneiras de extrair palavras-chave de um texto ou parágrafo. Neste primeiro post, descreveremos as chamadas abordagens “clássicas”.
[Ebook] SEO de dados: a próxima grande aventura
 Leia o e-book
Leia o e-bookRestrições
No entanto, temos algumas limitações e pré-requisitos na escolha de um algoritmo:
- O método deve ser capaz de extrair palavras-chave de um único documento. Alguns métodos requerem um corpus completo, ou seja, várias centenas ou mesmo milhares de documentos. Embora esses métodos possam ser usados por mecanismos de pesquisa, eles não serão úteis para um único documento.
- Estamos em um caso de Machine Learning não supervisionado. Não temos em mãos um conjunto de dados em francês, inglês ou outros idiomas com dados anotados. Ou seja, não temos milhares de documentos com palavras-chave já extraídas.
- O método deve ser independente do domínio/campo lexical do documento. Queremos ser capazes de extrair palavras-chave de qualquer tipo de documento: artigos de notícias, páginas da web, etc. Observe que alguns conjuntos de dados que já têm palavras-chave extraídas para cada documento geralmente são medicina específica de domínio, ciência da computação etc.
- Alguns métodos são baseados em modelos POS-tagging, ou seja, a capacidade de um modelo de PNL de identificar palavras em uma frase pelo seu tipo gramatical: um verbo, um substantivo, um determinante. Determinar a importância de uma palavra-chave que é um substantivo em vez de um determinante é claramente relevante. No entanto, dependendo do idioma, os modelos de marcação POS às vezes são de qualidade muito irregular.
Sobre métodos tradicionais
Diferenciamos os métodos ditos “tradicionais” e os mais recentes que utilizam técnicas de PNL – Processamento de Linguagem Natural – como a incorporação de palavras e a incorporação contextual. Este tema será abordado em um post futuro. Mas primeiro, vamos voltar às abordagens clássicas, distinguimos duas delas:
- a abordagem estatística
- a abordagem do gráfico
A abordagem estatística dependerá principalmente das frequências de palavras e sua co-ocorrência. Partimos de hipóteses simples para construir heurísticas e extrair palavras importantes: uma palavra muito frequente, uma série de palavras consecutivas que aparecem várias vezes, etc. Os métodos baseados em gráficos irão construir um gráfico onde cada nó pode corresponder a uma palavra, grupo de palavras ou frase. Então cada arco pode representar a probabilidade (ou frequência) de observar essas palavras juntas.
Aqui estão alguns métodos:
- Baseado em estatísticas
- TF-IDF
- ANCINHO
- YAKE
- Baseado em gráfico
- TextRank
- TopicRank
- Rank único
Todos os exemplos dados usam texto retirado desta página da web: Jazz au Tresor: John Coltrane – Impressions Graz 1962.
Abordagem estatística
Vamos apresentá-lo aos dois métodos Rake e Yake. Em um contexto de SEO, você já deve ter ouvido falar do método TF-IDF. Mas como requer um corpus documental, não trataremos aqui.
ANCINHO
RAKE significa Extração Automática Rápida de Palavras-chave. Existem várias implementações deste método em Python, incluindo rake-nltk. A pontuação de cada palavra-chave, também chamada de keyphrase por conter várias palavras, é baseada em dois elementos: a frequência das palavras e a soma de suas coocorrências. A constituição de cada frase-chave é muito simples, consiste em:
- cortar o texto em frases
- cortar cada frase em frases-chave
Na frase a seguir, tomaremos todos os grupos de palavras separados por elementos de pontuação ou palavras irrelevantes:
Pouco antes, Coltrane liderava um quinteto, com Eric Dolphy ao seu lado e Reggie Workman no contrabaixo.
Isso pode resultar nas seguintes frases-chave:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
Observe que as palavras irrelevantes são uma série de palavras muito frequentes, como “ the ”, “ in ”, “e” or “ it ”. Como os métodos clássicos geralmente se baseiam no cálculo da frequência de ocorrência das palavras, é importante escolher cuidadosamente suas palavras irrelevantes. Na maioria das vezes, não queremos ter palavras como >"to" , "the" or "de" em nossas propostas de frase-chave. De fato, essas palavras irrelevantes não estão associadas a um campo lexical específico e, portanto, são muito menos relevantes do que as palavras “ jazz ” ou “ saxophone ”, por exemplo.

Uma vez que isolamos várias frases-chave candidatas, damos a elas uma pontuação de acordo com a frequência das palavras e as co-ocorrências. Quanto maior a pontuação, mais relevantes devem ser as frases-chave.
Vamos tentar rapidamente com o texto do artigo sobre John Coltrane.
# snippet python para rake de rake_nltk import Rake # suponha que você já tenha o artigo na variável 'texto' rake = Rake(stopwords=FRENCH_STOPWORDS, max_length=4) rake.extract_keywords_from_text(texto) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
Aqui estão as primeiras 5 frases-chave:
“rádio público nacional austríaco”, “picos líricos mais paradisíacos”, “graz tem duas peculiaridades”, “saxofone tenor john coltrane”, “única versão gravada”
Existem algumas desvantagens nesse método. A primeira é a importância da escolha das palavras irrelevantes, pois elas são usadas para dividir uma frase em frases-chave candidatas. A segunda é que, quando as frases-chave são muito longas, elas geralmente terão uma pontuação mais alta por causa da co-ocorrência das palavras presentes. Para limitar o comprimento das frases-chave, definimos o método com max_length=4 .
YAKE
YAKE significa ainda outro extrator de palavras-chave. Este método é baseado no seguinte artigo YAKE! Extração de palavras-chave de documentos únicos usando vários recursos locais que datam de 2020. É um método mais recente que o RAKE, cujos autores propuseram uma implementação do Python disponível no Github.
Iremos, quanto ao RAKE, confiar na frequência e co-ocorrência de palavras. Os autores também adicionarão algumas heurísticas interessantes:
- vamos distinguir entre palavras em minúsculas e palavras em maiúsculas (ou a primeira letra ou a palavra inteira). Vamos supor aqui que palavras que começam com letra maiúscula (exceto no início de uma frase) são mais relevantes que outras: nomes de pessoas, cidades, países, marcas. Este é o mesmo princípio para todas as palavras em maiúsculas.
- a pontuação de cada frase-chave candidata dependerá de sua posição no texto. Se as frases-chave candidatas aparecerem no início do texto, elas terão uma pontuação maior do que se aparecerem no final. Por exemplo, os artigos de notícias geralmente mencionam conceitos importantes no início do artigo.
# snippet python para yake from yake import KeywordExtractor as Yake yake = Yake(lan="fr", stopwords=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(texto)
Assim como o RAKE, aqui estão os 5 principais resultados:
“Treasure Jazz”, “John Coltrane”, “Impressions Graz”, “Graz”, “Coltrane”
Apesar de algumas duplicações de certas palavras em algumas frases-chave, esse método parece bastante interessante.
Abordagem do gráfico
Este tipo de abordagem não está muito longe da abordagem estatística no sentido de que também calcularemos coocorrências de palavras. O sufixo Rank associado a alguns nomes de métodos, como TextRank , é baseado no princípio do algoritmo PageRank para calcular a popularidade de cada página com base em seus links de entrada e saída.
[Ebook] Automatizando SEO com Oncrawl
 Leia o e-book
Leia o e-bookTextRank
Este algoritmo vem do artigo TextRank: Bringing Order into Texts de 2004 e é baseado nos mesmos princípios do algoritmo PageRank . No entanto, em vez de construir um gráfico com páginas e links, vamos construir um gráfico com palavras. Cada palavra será ligada a outras palavras de acordo com sua co-ocorrência.
Existem várias implementações em Python. Neste artigo, apresentarei o pytextrank. Vamos quebrar uma de nossas restrições sobre a marcação POS. De fato, ao construir o gráfico, não incluiremos todas as palavras como nós. Apenas verbos e substantivos serão considerados. Como os métodos anteriores que usam palavras irrelevantes para filtrar candidatos irrelevantes, o algoritmo TextRank usa o tipo gramatical de palavras.
Aqui está um exemplo de uma parte do gráfico que será construída pelo algo : 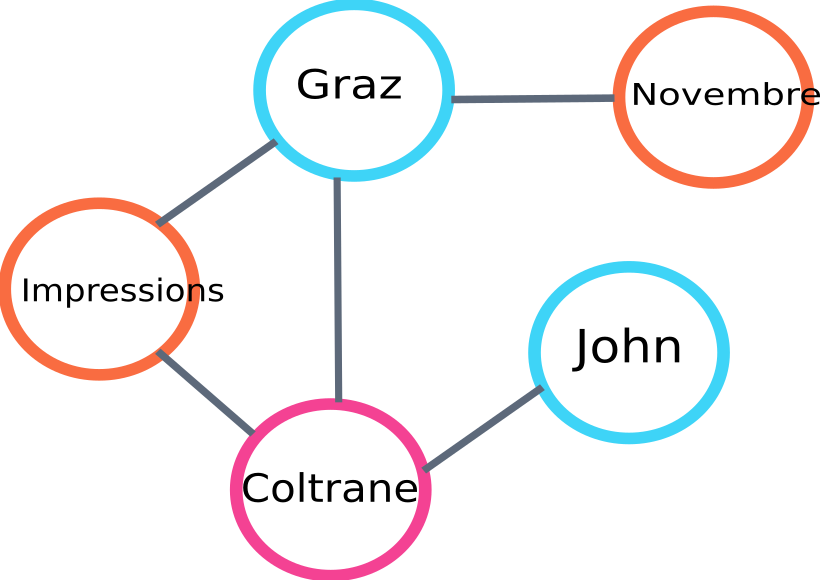
exemplo de gráfico de classificação de texto
Aqui está um exemplo de uso em Python. Observe que essa implementação usa o mecanismo de pipeline da biblioteca spaCy. É esta biblioteca que é capaz de fazer marcação POS.
# snippet python para pytextrank
importar espaço
importar pytextrank
# carrega um modelo francês
nlp = spacy.load("fr_core_news_sm")
# adiciona pytextrank ao pipe
nlp.add_pipe("textrank")
doc = nlp(texto)
textrank_keyphrases = doc._.phrases
Aqui estão os 5 principais resultados:
“Copenhague”, “novembre”, “Impressões Graz”, “Graz”, “John Coltrane”
Além de extrair frases-chave, o TextRank também extrai frases. Isso pode ser muito útil para fazer os chamados “resumos extrativos” – esse aspecto não será abordado neste artigo.
Conclusões
Dentre os três métodos aqui testados, os dois últimos nos parecem bastante relevantes para o assunto do texto. Para melhor comparar essas abordagens, obviamente teríamos que avaliar esses diferentes modelos em um número maior de exemplos. De fato, existem métricas para medir a relevância desses modelos de extração de palavras-chave.
As listas de palavras-chave produzidas por esses chamados modelos tradicionais fornecem uma excelente base para verificar se suas páginas estão bem direcionadas. Além disso, eles fornecem uma primeira aproximação de como um mecanismo de pesquisa pode entender e classificar o conteúdo.
Por outro lado, outros métodos usando modelos de PNL pré-treinados como BERT também podem ser usados para extrair conceitos de um documento. Ao contrário da chamada abordagem clássica, esses métodos geralmente permitem uma melhor captura da semântica.
Os diferentes métodos de avaliação, embeddings contextuais e transformadores serão apresentados em um segundo artigo sobre o assunto!
Aqui está a lista de palavras-chave extraídas deste artigo com um dos três métodos mencionados:
“métodos”, “palavras-chave”, “frases-chave”, “texto”, “palavras-chave extraídas”, “Processamento de linguagem natural”
Referências bibliográficas
- [1] Extração automática de palavras-chave aprimorada com mais conhecimento linguístico, Anette Hulth, 2003
- [2] Extração automática de palavras-chave de documentos individuais, Stuart Rose et. al, 2010
- [3] YAKE! Extração de palavras-chave de documentos únicos usando vários recursos locais, Ricardo Campos et. al, 2020
- [4] TextRank: Bringing Order into Texts, Rada Mihalcea et. al, 2004
Comece sua avaliação gratuita de 14 dias
 Comece seu teste
Comece seu teste