
Como responder a perguntas de dados complexas com dados do Oncrawl, fora do Oncrawl
Publicados: 2022-01-04Uma das vantagens do Oncrawl para SEO corporativo é ter acesso total aos seus dados brutos. Esteja você conectando seus dados de SEO a um fluxo de trabalho de BI ou ciência de dados, realizando suas próprias análises ou trabalhando de acordo com as diretrizes de segurança de dados da sua organização, os dados brutos de SEO e auditoria de sites podem servir a muitos propósitos.
Hoje veremos como usar os dados do Oncrawl para responder a questões de dados complexas.
O que é uma questão de dados complexos?
Questões de dados complexos são questões que não podem ser respondidas por uma simples pesquisa de banco de dados, mas requerem processamento de dados para obter a resposta.
Aqui estão alguns exemplos comuns de questões de dados “complexas” que os SEOs costumam ter:
- Criando uma lista de todos os links apontando para páginas que redirecionam para outras páginas com status 404
- Criando uma lista de todos os links e seu texto âncora apontando para páginas em uma segmentação com base em métricas não URL
Como responder a perguntas complexas de dados no Oncrawl
A estrutura de dados do Oncrawl é construída para permitir que quase todos os sites pesquisem dados quase em tempo real. Isso envolve o armazenamento de diferentes tipos de dados em diferentes conjuntos de dados para garantir que os tempos de consulta sejam reduzidos ao mínimo na interface. Por exemplo, armazenamos todos os dados associados a URLs em um conjunto de dados: código de resposta, número de links de saída, tipo de dados estruturados presentes, número de palavras, número de visitas orgânicas… E armazenamos todos os dados relacionados a links em um conjunto de dados separado: destino do link, origem do link, texto âncora…
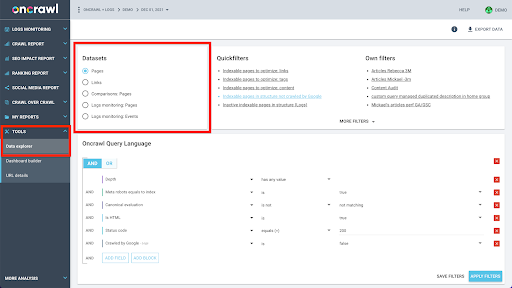
A junção desses conjuntos de dados é computacionalmente complexa e nem sempre suportada na interface do aplicativo Oncrawl. Quando você estiver interessado em pesquisar algo que exija a filtragem de um conjunto de dados para pesquisar algo em outro, recomendamos manipular os dados brutos por conta própria.
Como todos os dados do Oncrawl estão disponíveis para você, há muitas maneiras de unir conjuntos de dados e expressar consultas complexas.
Neste artigo, veremos um deles, usando o Google Cloud e o BigQuery, que é apropriado para conjuntos de dados muito grandes, como muitos de nossos clientes encontram ao examinar dados de sites com grandes volumes de páginas.
O que você precisará
Para seguir o método que discutiremos neste artigo, você precisará acessar as seguintes ferramentas:
- Oncrawl
- API do Oncrawl com a exportação de Big Data
- Armazenamento em nuvem do Google
- BigQuery
- Um script Python para transferir dados do Oncrawl para o BigQuery (construiremos isso durante o artigo).
Antes de começar, você precisará ter acesso a um relatório de rastreamento completo no Oncrawl.
Como aproveitar os dados do Oncrawl no Google BigQuery
O plano para o artigo de hoje é o seguinte:
- Primeiro, vamos garantir que o Google Cloud Storage esteja configurado para receber dados do Oncrawl.
- Em seguida, usaremos um script Python para executar as exportações de Big Data do Oncrawl para exportar os dados de um determinado rastreamento para um bucket do Google Cloud Storage. Exportaremos dois conjuntos de dados: páginas e links.
- Quando isso for feito, estaremos criando um conjunto de dados no Google BigQuery. Em seguida, criaremos uma tabela de cada uma das duas exportações no conjunto de dados do BigQuery.
- Por fim, experimentaremos consultar os conjuntos de dados individuais e, em seguida, os dois conjuntos de dados juntos para encontrar a resposta para uma pergunta complexa.
Configuração no Google Cloud para receber dados do Oncrawl
Para executar este guia em um ambiente sandbox dedicado, recomendamos que você crie um novo projeto do Google Cloud para isolá-lo de seus projetos em andamento existentes.
Vamos começar na casa do Google Cloud.
Na página inicial do Google Cloud, você tem acesso a muitas coisas além do Cloud Storage. Estamos interessados nos buckets do Cloud Storage, que estão disponíveis no nível de armazenamento em nuvem do Google Cloud Platform: 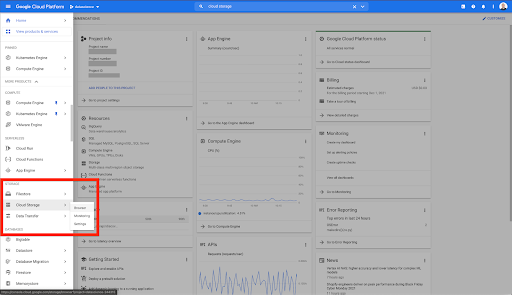
Você também pode acessar o navegador do Cloud Storage diretamente em https://console.cloud.google.com/storage/browser.
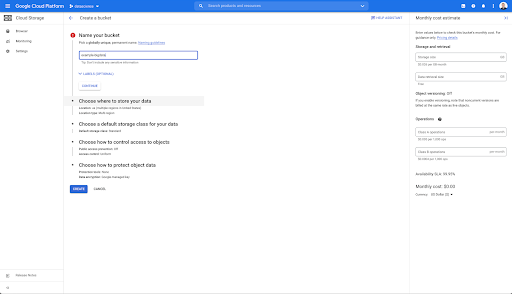
Em seguida, você precisa criar um bucket do Cloud Storage e conceder as permissões corretas para que a conta de serviço do Oncrawl possa gravar nele, com o prefixo de sua escolha.
O bucket do Google Cloud Storage servirá como um armazenamento temporário para manter as exportações de Big Data do Oncrawl antes de carregá-las no Google BigQuery.
Neste bucket, também criei duas pastas: “links” e “pages”: 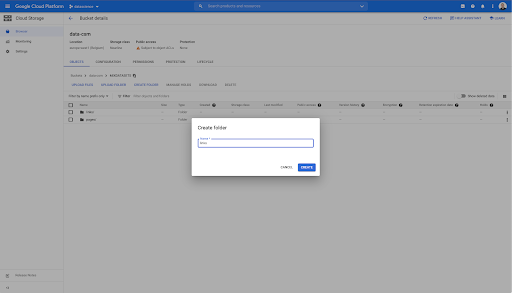
Exportando conjuntos de dados do Oncrawl
Agora que configuramos o espaço onde queremos salvar os dados, precisamos exportá-los do Oncrawl. Exportar para um bucket do Google Cloud Storage com Oncrawl é particularmente fácil, pois podemos exportar dados no formato correto e salvá-los diretamente no bucket. Isso elimina quaisquer etapas extras.
Como criar uma chave de API
A exportação de dados do Oncrawl no formato Parquet para BigQuery exigirá o uso de uma chave de API para atuar na API de forma programática, em nome do proprietário da conta Oncrawl. O aplicativo Oncrawl permite que os usuários criem chaves de API nomeadas para que sua conta esteja sempre bem organizada e limpa. As chaves de API também estão associadas a diferentes permissões (escopos) para que você possa gerenciar as chaves e suas finalidades.
Vamos nomear nossa nova chave como 'Chave de sessão de conhecimento'. O recurso de exportação de Big Data requer permissões de gravação na conta, pois estamos criando as exportações de dados. Para fazer isso, precisamos ter acesso de leitura no projeto e acesso de leitura e gravação na conta.
Agora temos uma nova chave de API, que copiarei para minha área de transferência.
Observe que, por motivos de segurança, você pode copiar a chave apenas uma vez . Se você esquecer de copiar a chave, será necessário excluí-la e criar uma nova.
Criando seu script Python
Eu construí um notebook do Google Colab para isso, mas vou compartilhar o código abaixo para que você possa criar suas próprias ferramentas ou seu próprio notebook.
1. Armazene sua chave de API em uma variável global
Primeiro, inicializamos o ambiente e declaramos a chave da API em uma variável global chamada “Oncrawl Token”. Então, nos preparamos para o resto do experimento:
#@title Acesse a API Oncrawl
#@markdown Forneça seu token de API abaixo para permitir que este notebook acesse seus dados Oncrawl:
# SEU TOKEN PARA A API ONCRAWL
ONCRAWL_TOKEN = "" #@param {type:"string"}
!pip instala prisão
de IPython.display import clear_output
clear_output()
print('Tudo carregado.') 
2. Crie uma lista suspensa para escolher o projeto Oncrawl com o qual deseja trabalhar
Então, usando essa chave, queremos ser capazes de escolher o projeto com o qual queremos jogar, obtendo a lista dos projetos e criando um widget suspenso dessa lista. Ao executar o segundo bloco de código, execute as seguintes etapas:
- Chamaremos a API Oncrawl para obter a lista dos projetos na conta usando a chave de API que acabou de ser enviada.
- Assim que tivermos a lista do projeto da resposta da API, formatamos como uma lista usando o nome do projeto, bem como o URL inicial do projeto.
- Armazenamos o ID do projeto que foi fornecido na resposta.
- Construímos um menu suspenso e o mostramos abaixo do bloco de código.
#@title Selecione o site para analisar escolhendo o projeto Oncrawl correspondente
solicitações de importação
prisão de importação
importar ipywidgets como widgets
importar json
# Obter lista de projetos
resposta = requests.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
limite=1000,
sort='nome:asc'
),
headers={ 'Autorização': 'Portador '+ONCRAWL_TOKEN }
)
json_res = resposta.json()
#prepare dropdown para permitir que o usuário selecione um projeto
projetos = []
para item em json_res['projects']:
projects.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
saída = widgets.Saída()
dropdown_purpose = widgets.Dropdown(options = projetos, descrição="Projeto: ")
def dropdown_project_eventhandler(alterar):
output.clear_output()
com saída:
exibir (projetos)
dropdown_purpose.observe(dropdown_project_eventhandler, names='value')
display(dropdown_purpose) No menu suspenso que isso cria, você pode ver a lista completa do projeto ao qual a chave de API tem acesso. 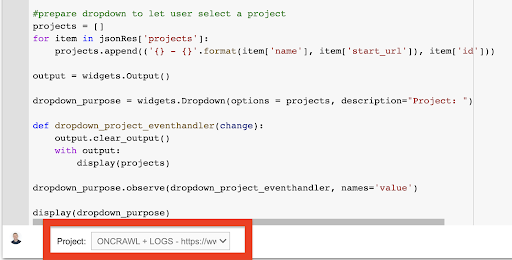
Para a demonstração de hoje, estamos usando um projeto de demonstração baseado no site Oncrawl.
3. Crie uma lista suspensa para escolher o perfil de rastreamento no projeto com o qual deseja trabalhar
Em seguida, decidiremos qual perfil de rastreamento usar. Queremos escolher um perfil de rastreamento neste projeto. O projeto de demonstração tem várias configurações de rastreamento diferentes: 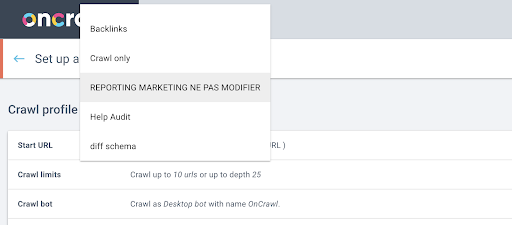
Nesse caso, estamos analisando um projeto que as equipes do Oncrawl costumam usar para experimentos, então vou escolher o perfil de rastreamento usado pela equipe de marketing para monitorar o desempenho do site do Oncrawl. Como esse deve ser o perfil de rastreamento mais estável, é uma boa opção para o experimento hoje.
Para obter o perfil de rastreamento, usaremos a API Oncrawl para solicitar o último rastreamento em cada perfil de rastreamento no projeto:
- Nós nos preparamos para consultar a API Oncrawl para o projeto em questão.
- Solicitaremos todos os rastreamentos retornados por ordem decrescente de acordo com a data "criada em".
solicitações de importação
importar json
importar ipywidgets como widgets
project_id = dropdown_purpose.value
# Obtenha detalhes do projeto (inclua todos os rastreamentos no projeto)
projeto = requests.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ 'Autorização': 'Portador '+ONCRAWL_TOKEN }).json()
# Agrupar rastreamentos por perfil de rastreamento (nome do rastreamento)
crawls_by_config = {}
tentar:
para rastrear no projeto['crawls']:
if crawl['status'] em ["done"]:
se crawl['crawl_config']['name'] não estiver em crawls_by_config.keys():
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
if len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
if crawl['status'] == "arquivado":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = Verdadeiro
exceto Exceção como e:
raise Exception("erro {} , {}".format(e, projeto))
# Construa a lista para a seleção suspensa
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) for k, v in crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list, description="Crawl configs: ")
def dropdown_cc_eventhandler(alterar):
output.clear_output()
com saída:
display(crawls_by_config)
if len(crawls_by_config.values()) == 0:
print('Nenhum rastreamento ao vivo encontrado neste projeto')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='valor')
display(dropdown_crawl_configs)Quando esse código for executado, a API Oncrawl nos responderá com a lista de rastreamentos descendo a propriedade “created at”.
Então, como queremos nos concentrar apenas nos rastreamentos concluídos, passaremos pela lista dos rastreamentos. Para cada rastreamento com status "concluído", salvaremos o nome do perfil de rastreamento e armazenaremos o ID do rastreamento.
Manteremos no máximo um rastreamento por perfil de rastreamento para não expor muitos rastreamentos.
O resultado é esse novo menu suspenso criado a partir da lista de perfis de rastreamento no projeto. Vamos escolher o que queremos. Isso levará o último rastreamento executado pela equipe de marketing: 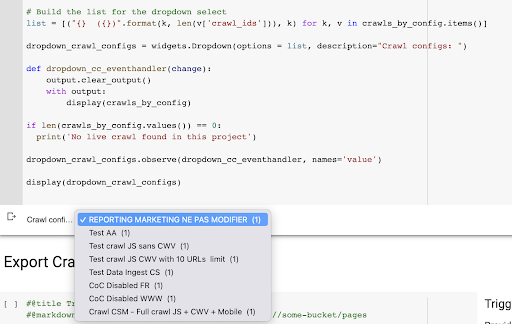
4. Identifique o último rastreamento com o perfil que queremos usar
Já temos o ID de rastreamento associado ao último rastreamento no perfil escolhido. Ele está oculto no dicionário de objetos “crawl_by_config”. 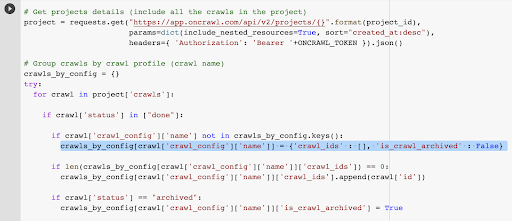
Você pode verificar isso facilmente na interface: Encontre o último rastreamento concluído nesta análise de perfil. 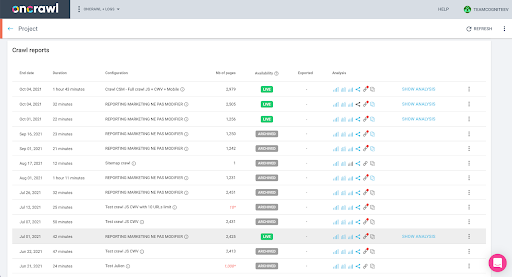
Se clicarmos para visualizar a análise, veremos que o ID de rastreamento termina com E617. 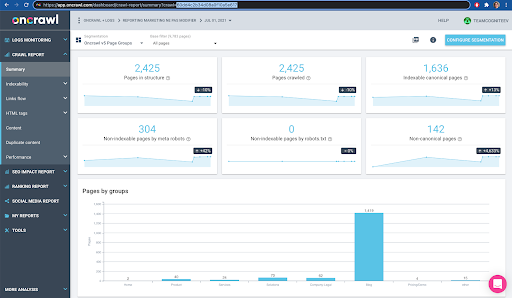
Vamos apenas tomar nota do ID de rastreamento para fins de demonstração hoje.
Claro, se você já sabe o que está fazendo, pode pular as etapas que acabamos de abordar para chamar a API Oncrawl para obter a lista de projetos e a lista de rastreamentos por perfil de rastreamento: você já tem o ID de rastreamento do interface, e este ID é tudo que você precisa para executar a exportação.
As etapas que executamos até agora são simplesmente para facilitar o processo de obtenção do último rastreamento de determinado perfil de rastreamento de determinado projeto, considerando o que a chave de API tem acesso. Isso pode ser útil se você estiver fornecendo essa solução para outros usuários ou se quiser automatizá-la.
5. Exporte os resultados do rastreamento
Agora, veremos o comando de exportação:
#@title Acionar a exportação de bigdata
#@markdown Forneça seu bucket do GCS e o prefixo gs://some-bucket/pages
# SEU BALDE GCS
gcs_bucket = #@param {type:"string"}
gcs_prefix = #@param {type:"string"}
# Obtém o último ID de rastreamento de determinado projeto/perfil de rastreamento
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Carga útil do modelo para consulta de exportação de dados
carga = {
"data_export": {
"data_type": 'página',
"resource_id": last_crawl_id,
"output_format": 'parquet',
"target": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
# Aciona a exportação
export = requests.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
# Exibir resposta da API
exibir (exportar)
# Armazena o ID de exportação para uso futuro
export_id = export['data_export']['id']Queremos exportar para o bucket do Cloud Storage que configuramos anteriormente.
Dentro disso, vamos exportar as páginas para o último ID de rastreamento:
- O último ID de rastreamento é obtido da lista de IDs de rastreamento, que é armazenada em algum lugar no dicionário “crawls_by_config”, que foi criado na etapa 3.
- Queremos escolher o correspondente ao menu suspenso na etapa 4, então usamos o atributo value do menu suspenso.
- Em seguida, extraímos o atributo crawl_ID. Esta é uma lista. Manteremos os 50 principais itens da lista. Precisamos fazer isso porque na etapa 2, como você deve se lembrar, quando criamos o dicionário crawls_by_config, armazenamos apenas um ID de rastreamento por nome de configuração.
Configurei campos de entrada para facilitar o fornecimento do bucket e prefixo ou pasta do Google Cloud Storage para onde queremos enviar a exportação. 
Para fins de demonstração, hoje, estaremos gravando na pasta “mixed dataset”, em uma das pastas que já configurei. Quando configurarmos nosso bucket no Google Cloud Storage, você vai lembrar que preparei pastas para exportação de “links” e para exportação de “páginas”.
Para a primeira exportação, queremos exportar as páginas para a pasta “pages” para o último ID de rastreamento usando o formato de arquivo Parquet. 
Nos resultados abaixo, você verá o payload que deve ser enviado para o endpoint de exportação de dados, que é o endpoint para solicitar uma exportação de Big Data usando uma chave de API:
# Carga útil do modelo para consulta de exportação de dados
carga = {
"data_export": {
"data_type": 'página',
"resource_id": last_crawl_id,
"output_format": 'parquet',
"target": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
Isso contém vários elementos, incluindo o tipo do conjunto de dados que você deseja exportar. Você pode exportar o conjunto de dados de página, o conjunto de dados de link, o conjunto de dados de clusters ou o conjunto de dados de dados estruturados. Se você não sabe o que pode ser feito, pode inserir um erro aqui e, ao chamar a API, receberá uma mensagem informando que a escolha do tipo de dados deve ser página ou link ou cluster ou dados estruturados. A mensagem se parece com isso:

{'fields': [{'message': 'Não é uma escolha válida. Deve ser "page", "link", "cluster", "structured_data".',
'nome': 'tipo_dados',
'type': 'invalid_choice'}],
'type': 'invalid_request_parameters'}
Para fins do experimento de hoje, exportaremos o conjunto de dados da página e o conjunto de dados do link em exportações separadas.
Vamos começar com o conjunto de dados da página. Quando executo este bloco de código, imprimi a saída da chamada da API, que se parece com isso:
{'data_export': {'data_type': 'page',
'export_failure_reason': Nenhum,
'id': 'XXXXXXXXXXXXXXXX',
'output_format': 'parquet',
'output_format_parameters': Nenhum,
'output_row_count': Nenhum,
'output_size_in_bytes: 1634460016000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'status': 'SOLICITADO',
'alvo': 'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pages/'}}}
Isso me permite ver que a exportação foi solicitada.
Se quisermos verificar o status da exportação, é muito simples. Usando o ID de exportação que salvamos no final deste bloco de código, podemos solicitar o status da exportação a qualquer momento com a seguinte chamada de API:
# ESTADO DE EXPORTAÇÃO
export_status = requests.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json ()
display(export_status)
Isso indicará um status como parte do objeto JSON retornado:
{'data_export': {'data_type': 'page',
'export_failure_reason': Nenhum,
'id': 'XXXXXXXXXXXXXXXX',
'output_format': 'parquet',
'output_format_parameters': Nenhum,
'output_row_count': Nenhum,
'output_size_in_bytes': Nenhum,
'requested_at': 1638350549000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'status': 'EXPORTANDO',
'alvo': 'gcs',
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/pages/'}}} Quando a exportação for concluída ( 'status': 'DONE' ), podemos retornar ao Google Cloud Storage.
Se olharmos em nosso bucket e entrarmos na pasta “links”, ainda não há nada aqui porque exportamos as páginas. 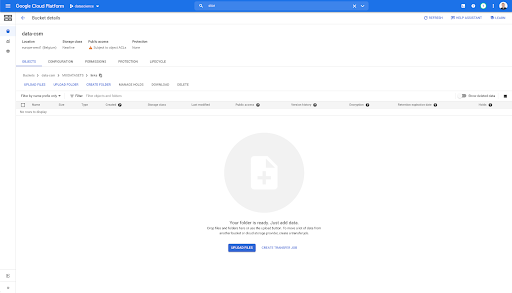
No entanto, quando olhamos na pasta “pages”, podemos ver que a exportação foi bem-sucedida. Temos um arquivo Parquet: 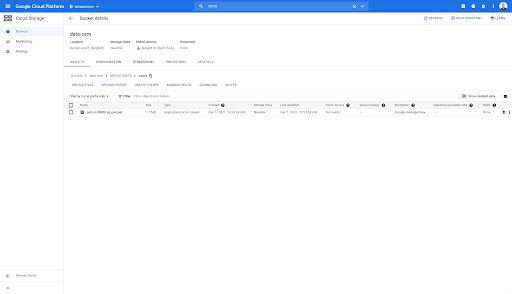
Nesta fase, o conjunto de dados de páginas está pronto para importação no BigQuery, mas primeiro vamos repetir as etapas acima para obter o arquivo Parquet para os links:
- Certifique-se de definir o prefixo de links.
- Escolha o tipo de dados “link”.
- Execute este bloco de código novamente para solicitar a segunda exportação.

Isso produzirá um arquivo Parquet na pasta “links”.
Como criar conjuntos de dados do BigQuery
Enquanto a exportação está em execução, podemos avançar e começar a criar conjuntos de dados no BigQuery e importar os arquivos Parquet em tabelas separadas. Então vamos juntar as mesas.
O que queremos fazer agora é brincar com o Google Big Query, que é algo disponível como parte do Google Cloud Platform. Você pode usar a barra de pesquisa na parte superior da tela ou ir diretamente para https://console.cloud.google.com/bigquery.
Como criar um conjunto de dados para seu trabalho
Precisaremos criar um conjunto de dados no Google BigQuery: 
Você precisará fornecer um nome ao conjunto de dados e escolher o local onde os dados serão armazenados. Isso é importante porque condiciona onde os dados são processados e não podem ser alterados. Isso pode ter um impacto se seus dados incluírem informações cobertas pelo GDPR ou outras leis de privacidade. 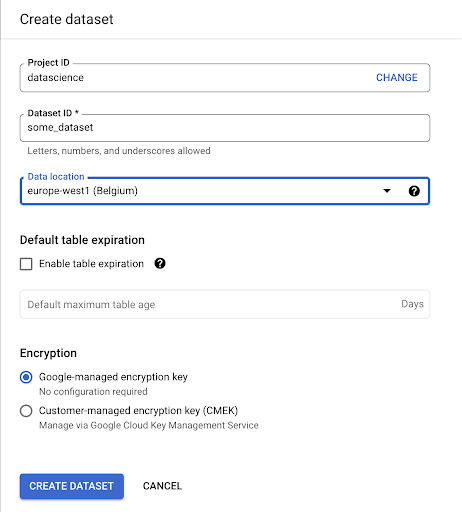
Este conjunto de dados está inicialmente vazio. Ao abri-lo, você poderá criar uma tabela, compartilhar o conjunto de dados, copiar, excluir e assim por diante.
Criando tabelas para seus dados
Vamos criar uma tabela neste conjunto de dados. 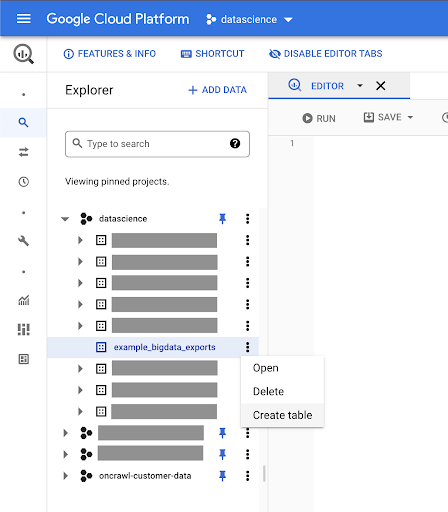
Você pode criar uma tabela vazia e fornecer o esquema. O esquema é a definição das colunas na tabela. Você pode definir o seu próprio ou navegar no Google Cloud Storage para escolher um esquema de um arquivo.
Usaremos esta última opção. Vamos navegar para o nosso bucket, depois para a pasta “pages”. Vamos escolher o arquivo de páginas. Há apenas um arquivo, então podemos selecionar apenas um, mas se a exportação tivesse gerado vários arquivos, poderíamos ter escolhido todos eles. 
Quando selecionamos o arquivo, ele detecta automaticamente que está no formato de arquivo Parquet. Queremos criar uma tabela chamada “pages”, e o esquema será definido pelo arquivo de origem. 
Quando carregamos um arquivo Parquet, ele incorpora um esquema. Em outras palavras, a definição das colunas da tabela que estamos criando será inferida a partir do esquema que já existe dentro do arquivo Parquet. É aqui que realmente uma parte da mágica acontece.
Vamos seguir em frente e simplesmente criar a tabela a partir do arquivo Parquet. 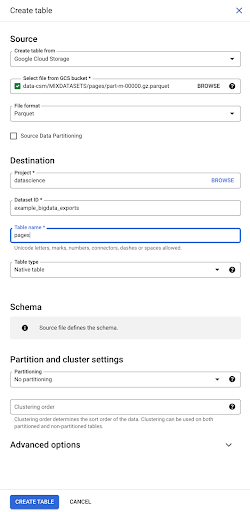
Na barra lateral esquerda, podemos ver agora que uma tabela apareceu dentro do nosso conjunto de dados, que é exatamente o que queremos:
Assim, agora temos o esquema da tabela de páginas com todos os campos que foram inferidos automaticamente do arquivo Parquet. Temos o Inrank, a profundidade da página, se a página for um redirecionamento e assim por diante e assim por diante: 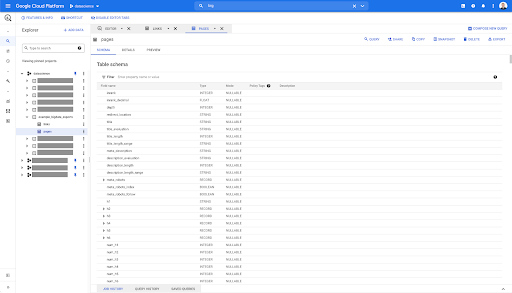
A maioria desses campos são os mesmos disponibilizados no Data Studio por meio do conector Oncrawl Data Studio e os mesmos que você vê no Data Explorer na interface Oncrawl. 
No entanto, existem algumas diferenças. Quando brincamos com a exportação de big data bruto, você tem todos os dados brutos.
- No Data Studio, alguns campos são renomeados, alguns campos são ocultados e alguns campos são adicionados, como o status.
- No Data Explorer, alguns campos são o que chamamos de “campos virtuais”, o que significa que podem ser uma espécie de atalho para um campo subjacente. Esses campos virtuais disponíveis no Data Explorer não serão listados no esquema, mas podem ser recriados com base no que estiver disponível no arquivo Parquet.
Vamos agora fechar esta tabela e fazer novamente para os links.
Para a tabela de links, o esquema é um pouco menor. 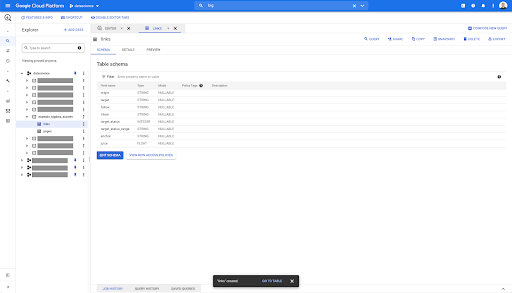
Ele contém apenas os seguintes campos:
- A origem do vínculo,
- O destino do link,
- A propriedade seguir,
- A propriedade interna,
- O estado do alvo,
- O intervalo do status de destino,
- O texto âncora e
- O suco ou capital comprado pelo link.
Em qualquer tabela do BigQuery, ao clicar na guia de visualização, você tem uma visualização da tabela sem consultar o banco de dados: 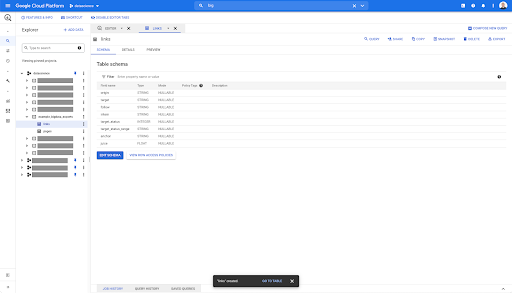
Isso lhe dá uma visão rápida do que está disponível nele. Na visualização da tabela de links acima, você tem uma visualização de cada linha e de todas as colunas.
Em alguns conjuntos de dados Oncrawl, você pode ver algumas linhas que abrangem várias linhas. Não tenho um exemplo para você, mas se for o caso, é porque alguns campos contêm uma lista de valores. Por exemplo, na lista de títulos h2 em uma página, uma única linha abrange várias linhas no Big Query. Veremos isso mais tarde se virmos um exemplo.
Criando sua consulta
Se você nunca criou uma consulta no BigQuery, agora é a hora de brincar com isso para se familiarizar com o funcionamento. O BigQuery usa SQL para pesquisar dados.
Como funcionam as consultas
Como exemplo, vamos ver todas as URLs e sua classificação…
SELECT url, inrank...
do conjunto de dados de páginas…
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` ...
onde o código de status da página é 200…
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ...
e mantenha apenas os 10 primeiros resultados:
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
Quando executarmos esta consulta, obteremos as primeiras 10 linhas da lista de páginas onde o código de status é 200.
Qualquer uma dessas propriedades pode ser modificada. f eu quero 1000 linhas em vez de 10, posso definir 1000 linhas:
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
Se eu quiser ordenar, posso fazer isso com “order-by”: isso me dará todas as linhas ordenadas por ordem decrescente de Inrank.
SELECT URL, inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
Esta é a minha primeira consulta. Posso salvá-lo se quiser, o que me dará a capacidade de reutilizar essa consulta mais tarde, se eu quiser: 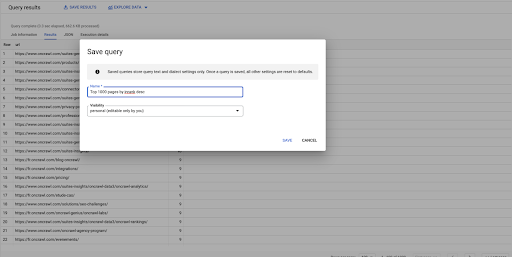
Usando consultas para responder a perguntas simples: listando todos os links internos para páginas com status 301
Agora que sabemos como compor uma consulta, vamos voltar ao nosso problema original.
Queríamos responder a perguntas de dados, simples ou complexas. Vamos começar com uma pergunta simples, como “quais são todos os links internos que apontam para páginas com status 301 (redirecionados) e onde posso encontrá-los?”
Criando uma nova consulta
Começaremos explorando como isso funciona.
Vou querer colunas para os seguintes elementos do banco de dados “links”:
- Origem
- Alvo
- Código de status de destino
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links`
Quero limitá-los apenas aos links internos, mas vamos imaginar que não me lembro do nome da coluna ou do valor que indica se o link é interno ou externo. Posso ir ao esquema para procurá-lo e usar a visualização para visualizar o valor: 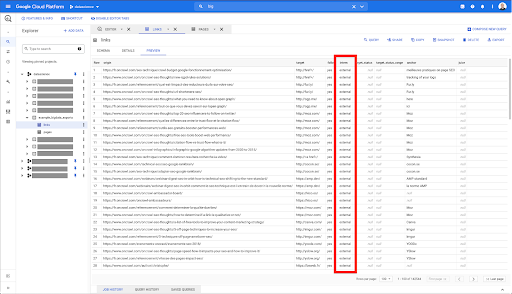
Isso me diz que a coluna se chama “interna” e o intervalo possível de valores é “externa” ou “interna”.
Na minha consulta, quero especificar “onde o interno é interno” e limitar os resultados aos primeiros 100 por enquanto:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE interno LIKE 'interno' LIMIT 100
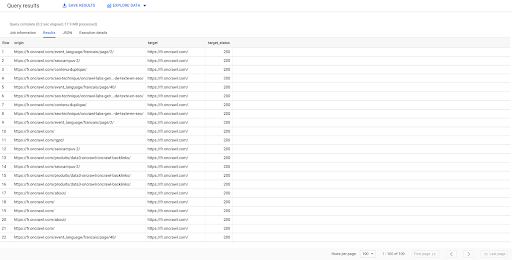
O resultado acima mostra a lista de links com seus status de destino. Temos apenas links internos, e temos 100 deles, conforme especificado na consulta.
Se quisermos ter apenas links internos para esse ponto para páginas redirecionadas, poderíamos dizer 'onde interno como status interno e destino é igual a 301':
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE interno LIKE 'interno' AND target_status = 301
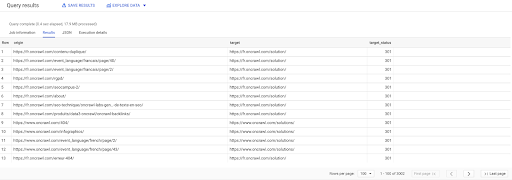
Se não soubermos quantos deles existem, podemos executar essa nova consulta e veremos que existem 3002 links internos com um status de destino de 301.
Unindo as tabelas: encontrando códigos de status finais de links que apontam para páginas redirecionadas
Em um site, muitas vezes você tem links para páginas que são redirecionadas. Queremos saber o código de status da página para a qual eles são redirecionados (ou o URL de destino final).
Em um conjunto de dados, você tem as informações sobre os links: a página de origem, a página de destino e seu código de status (como 301), mas não o URL para o qual uma página redirecionada aponta. E no outro, você tem as informações sobre os redirecionamentos e seus destinos finais, mas não a página original onde o link para eles foi encontrado.
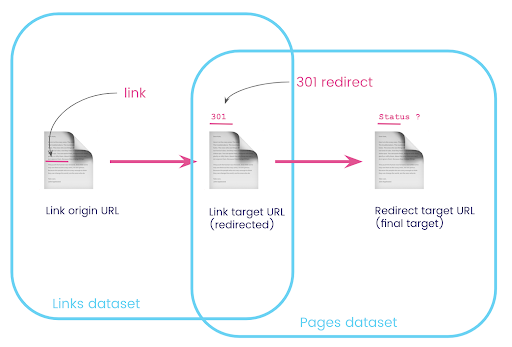
Vamos dividir isso:
Primeiro, queremos links para redirecionamentos. Vamos escrever isso. Nós queremos:
- A origem.
- O alvo. O destino deve ter um código de status 301.
- O destino final do redirecionamento.
Em outras palavras, no conjunto de dados de links, queremos:
- A origem do vínculo
- O destino do link
No conjunto de dados de páginas, queremos:
- Todos os destinos que são redirecionados
- O destino final do redirecionamento
Isso nos dará uma consulta como:
SELECT url, final_redirect_location, final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` AS páginas WHERE status_code = 301 OU status_code = 302
Isso deve me dar a primeira parte da equação.
Agora preciso de todos os links com links para a página que são os resultados da consulta que acabei de criar, usando aliases para meus conjuntos de dados e juntando-os no URL de destino do link e no URL da página. Isso corresponde à área de sobreposição dos dois conjuntos de dados no diagrama no início desta seção.
SELECIONAR links.origem, páginas.url, pages.final_redirect_location, pages.final_redirect_status A PARTIR DE Páginas AS de `datascience-oncrawl.example_bigdata_exports.pages` JUNTE `datascience-oncrawl.example_bigdata_exports.links` como links SOBRE links.target = páginas.url ONDE pages.status_code = 301 OR pages.status_code = 302 ORDENAR POR origem ASC
Nos resultados da consulta, posso renomear as colunas para deixar as coisas mais claras, mas já posso ver que tenho um link de uma página na primeira coluna, que vai para a página da segunda coluna, que por sua vez é redirecionada para a página na terceira coluna. Na quarta coluna, tenho o código de status do destino final: 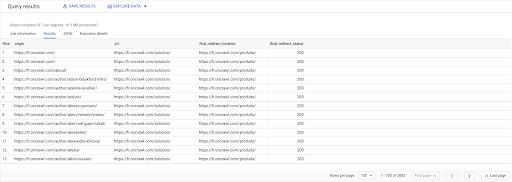
Agora posso dizer quais links apontam para páginas redirecionadas que não resolvem para 200 páginas. Talvez sejam 404s, por exemplo, o que me dá uma lista de links prioritários para corrigir.
Vimos anteriormente como salvar uma consulta. Também podemos salvar os resultados, para até 16.000 linhas de resultados: 
Podemos então usar esses resultados de muitas maneiras diferentes. Aqui estão alguns exemplos:
- Podemos salvá-lo como um arquivo CSV ou JSON localmente.
- Podemos salvá-lo como uma planilha do Google Sheets e compartilhá-lo com o restante da equipe.
- Também podemos exportá-lo diretamente para o Data Studio.
Dados como vantagem estratégica
Com todas essas possibilidades, é fácil usar as respostas para suas perguntas complexas estrategicamente. Você já pode ter experiência em conectar os resultados do BigQuery ao Data Studio ou a outras plataformas de visualização de dados, ou pode já ter um processo implementado que envia informações para uma equipe de engenharia ou até mesmo para um fluxo de trabalho de business intelligence ou análise de dados.
Se você incluiu as etapas deste artigo como parte de um processo, lembre-se de que pode automatizar todas as etapas no BigQuery: todas as ações que realizamos neste artigo também podem ser acessadas pela API do BigQuery. Isso significa que eles podem ser executados programaticamente como parte de um script ou ferramenta personalizada.
Quaisquer que sejam seus próximos passos, o primeiro passo é sempre acessar os dados brutos de SEO e do site. Acreditamos que esse acesso aos dados é uma das partes mais importantes da análise técnica: com o Oncrawl, você sempre terá acesso total aos seus dados brutos.
O acesso aos dados também significa que você pode ir além do que é possível na interface do Oncrawl e explorar todas as relações entre seus dados, não importa quão complexas sejam as perguntas que você está fazendo.