
Mapa witryny XML: kluczowe zalecenia dotyczące optymalizacji
Opublikowany: 2021-03-26Plik Sitemap.xml w Twojej witrynie może służyć jako dobra nawigacja dla stron, które mają być indeksowane przez bota Google. Pomaga szybciej znaleźć strony główne, nawet jeśli nie masz dobrego linkowania wewnętrznego.
W tym artykule przedstawimy różne zalecenia dotyczące optymalizacji mapy witryny XML i dlaczego warto to zrobić.
Funkcjonalności i zalety
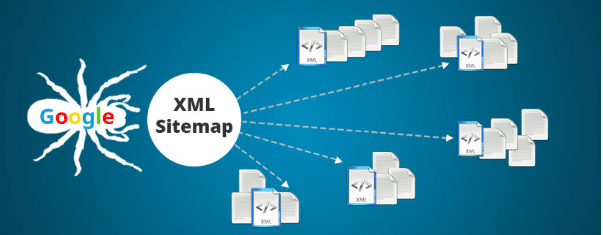
Ułatw botom pracę i daj możliwość otrzymywania „raportów” dotyczących stron i linków w Twojej witrynie, których nie można było łatwo znaleźć.
Niektóre z korzyści SEO są następujące:
- szybsze indeksowanie – wyszukiwarki znacznie szybciej znajdą nowe strony, dzięki czemu proces indeksowania i wyświetlania strony w wynikach wyszukiwania będzie szybszy. Osobliwością jest to, że może również pomóc w deindeksowaniu (więcej informacji tutaj);
- lepsze indeksowanie stron wewnętrznych – wyszukiwarki mogą znaleźć strony, które nie zostały znalezione podczas indeksowania witryny. Nie musi to jednak oznaczać, że wszystkie zostaną zindeksowane.
- monitorowanie indeksowanych stron. W połączeniu z Google Search Console możesz dowiedzieć się, które adresy URL są uwzględnione w mapie witryny XML indeksowanej przez Google.
Czy mapa witryny XML jest ważna?
Jest to ważne w przypadku witryn, które:
- nie mają dobrej struktury lub nie mają dobrego rozmieszczenia linków wewnętrznych;
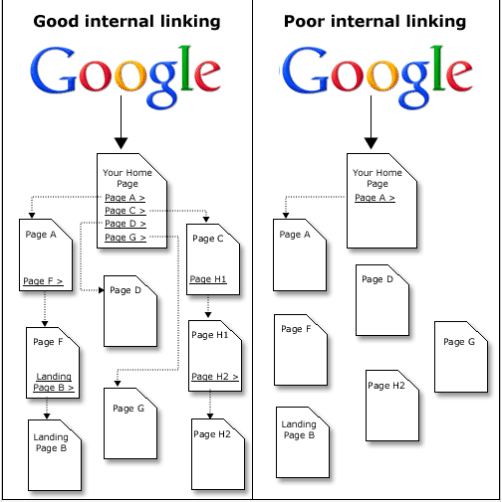
- mieć wiele stron – mapa witryny XML pomaga wyszukiwarkom znaleźć nowe lub zaktualizowane strony;
- nie masz wielu linków przychodzących – będzie to świetny sposób na znalezienie twoich stron.
Wymagania i formaty
Google obsługuje kilka formatów map witryn. Wszystkie formaty i standardy można znaleźć pod tym adresem: https://www.sitemaps.org/index.html.
Wszystkie formaty ograniczają mapę witryny do 50 MB (bez kompresji) i 50 000 adresów. Jeśli masz większy plik lub więcej adresów, będziesz musiał utworzyć plik indeksu ze wszystkimi mapami (opisany w artykule poniżej).
Główne zalecenia to:
- plik musi być zakodowany w UTF-8;
- musi zaczynać się tagiem otwartym i kończyć tagiem zamkniętym, takim jak …. ;
- określić standardowy protokół w tagu;
- główny tag dla każdego wpisu adresu URL ;
- podaj adres URL rozpoczynający się od protokołu (https lub http) w tagu, który musi brać udział w głównym tagu do zapisania.
Dodatkowe opcjonalne atrybuty map witryn XML
Google nie używa tego atrybutu w swoich witrynach. Wszystkie pozostałe atrybuty są dostępne, ale zależy to od tego, czy zostaną odzwierciedlone. Dlatego pamiętaj, że Google nie traktuje tych tagów bardzo poważnie. Oni są:
- – przedstawia datę ostatniej zmiany pliku. Musi być w formacie W3C Datetime;
- – jak często strona będzie aktualizowana. Ta wartość zawiera ogólne informacje o wyszukiwarkach. Prawidłowe wartości mogą być zawsze, godzinowe, dzienne, tygodniowe, miesięczne, roczne, nigdy.
Należy pamiętać, że wartość tego znacznika jest traktowana bardziej jako wskazówka niż polecenie. Roboty widzą te informacje i biorą je pod uwagę, ale ostatecznie same decydują, czy z nich skorzystać, w zależności od wielu innych czynników.
- – Nadaje priorytet adresowi URL nad innymi adresami URL w Twojej witrynie. Prawidłowe wartości wahają się od 0,0. do 1,0.
Tutaj ponownie należy pamiętać, że ten priorytet jest względny i nie jest obowiązkowym warunkiem dla robotów, a przynajmniej nie jest jeszcze zaakceptowany jako taki. Jeśli jednak zdecydujesz się spróbować, skorzystaj z poniższego poradnika:
- 0–0,3: nieaktualne wiadomości, informacje, które nie są już aktualne, ale są przydatne z historycznego punktu widzenia;
- 4 – 0.7: Artykuły na blogu, kategorie stron, często zadawane pytania;
- 8 – 1.0: Strona główna, strony produktów, wszystkie strony z dobrze zoptymalizowaną treścią.
Poniższy przykład przedstawia mapę witryny, która zawiera tylko jeden adres URL i używa wszystkich opcjonalnych tagów zapisanych kursywą .
https://netpeak.bg
2018-09-15
miesięczny
0,8
Identyfikacja ważnych stron
Dodaj strony wysokiej jakości i te, które są dobrze zoptymalizowane. Ogólna jakość ma ogromne znaczenie dla lepszego rankingu. To poważny czynnik dla Google, który może dać ci poważny priorytet przed konkurencją.
Nie chcemy odwiedzać stron o niskiej jakości, podobnie jak boty Google. Jeśli poprowadzisz go do tysięcy stron, które nie są przydatne dla użytkowników i nie są dobrze zoptymalizowane, może to tylko zaszkodzić. Czym są strony wysokiej jakości? Mówiąc najprościej, są to strony, które:
- mieć wystarczającą ilość unikalnych treści;
- szybko angażować swoich użytkowników poprzez podpowiadanie działań (komentarze, recenzje itp.);
- zawierać obrazy, filmy itp .;
- nie naruszać zasad Google;
Strony otwarte do indeksowania
Budżet indeksowania ogólnie reprezentuje liczbę stron indeksowanych w jednostce czasu (dzień, tydzień, miesiąc itd.). Dlatego nie należy go niepotrzebnie marnować.
Strony zawierające metatag „Noindex” nie powinny być dodawane do mapy witryny. aby podążać za logicznym porządkiem, ważne jest dla wszystkiego.
Konieczne jest przeprowadzenie automatycznej kontroli i nie uwzględnianie adresów, które są zamknięte dla indeksowania.
Zaleca się przestrzeganie poniższych instrukcji:
- Jeśli strona https://example.com/category/product ma metatag „noindex”, nie powinna być uwzględniona w mapie XML witryny;

- Gdy strona jest zamknięta do indeksowania za pośrednictwem pliku robots.txt, nie powinna być uwzględniona w mapie XML:
Odrzuć: /kategoria/produkt
Noindex: /kategoria/produkt
- Jeśli strona jest zamknięta do indeksowania przez X-Robots-Tag w nagłówku HTTP, nie powinna być również uwzględniona w mapie XML witryny:
HTTP/1.1 200 OK
Data: wtorek, 25 maja 2010 21:42:43 GMT
(…)
X-Robots-Tag: noindex
(…)
Kanoniczne wersje stron
Dostęp do jednej strony za pośrednictwem wielu adresów URL o podobnej treści zostanie uznany przez Google za zduplikowany.

Musisz użyć atrybutu „link rel canonical”, aby poinstruować bota, który jest „główną” stroną i który powinien być przeszukiwany i indeksowany.
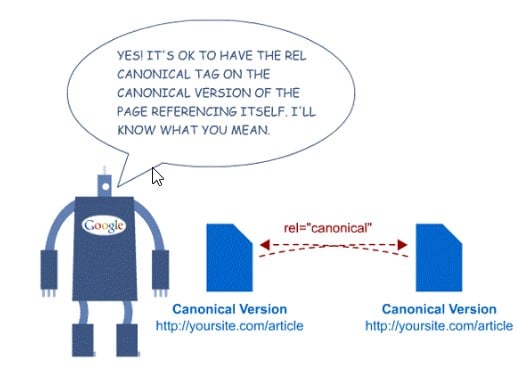
Na przykład, jeśli strona https://example.com/kategoria/produkt-1 ma kanoniczny adres https://example.com/produkt, to http://example.com/kategoria/produkt-1 nie powinien uczestniczyć w mapa witryny XML.
Powinieneś przeprowadzić automatyczną kontrolę, ponieważ automatyzacja procesów z pewnością przyniesie Ci mniej problemów i zaoszczędzi czas na ręczne inspekcje.
Strony, które zwracają 200 OK
Uwzględnij adresy, które zwracają odpowiedź 200 OK. Ważne jest, aby przeprowadzać automatyczne sprawdzenia i nie uwzględniać adresów, które zwracają odpowiedź inną niż 200 OK – na przykład 404, 301 itd.
Na przykład, jeśli strona https://example.com/product zwraca odpowiedź inną niż 200 OK, nie powinna brać udziału w mapie witryny.

Możesz użyć następującego narzędzia do sprawdzenia: https://soft.galinov.com/, aby to sprawdzić.
Strony z paginacji
Nie jest konieczne uwzględnienie absolutnie wszystkich stron w sitemap.xml. Bot jest na tyle sprytny, że jest w stanie przejść od pierwszej strony w odpowiedniej kategorii, jeśli jest ona odpowiednio opisana. Zaleca się wykonanie następujących czynności:
- zawierać tylko strony główne kategorii;
- zaznacz strony za pomocą rel = next / rel = prev, aby robot widział połączenie między nimi;
- każda strona paginacji powinna mieć kanoniczny przewodnik do siebie, a nie do strony głównej, ponieważ jeśli jest odwrotnie, będzie to oznaczać, że mówisz botowi „Nieważne, że mam 5000 produktów i 20 stron, oni są takie same jak pierwsza.”
Na przykład strona https://example.com/category/page-2 nie powinna brać udziału w mapie. Tutaj znajdziesz oficjalną opinię Google, a także ich rekomendacje:
Zminimalizuj rozmiar pliku
Google i Bing zwiększyły rozmiary plików z 10 MB do 50 MB w 2016 r., ale nadal dobrą praktyką jest utrzymywanie jak najmniejszej mapy witryny.

Oczywiście nie ma się czym martwić, ale jeśli mapa witryny zawiera ponad 50 000 adresów URL lub przekracza 50 MB, należy ją podzielić na więcej map XML. W takim przypadku odniesienia do wszystkich map XML powinny być opisane w osobnym pliku indeksu map witryn.
Co to jest plik indeksu mapy witryny XML
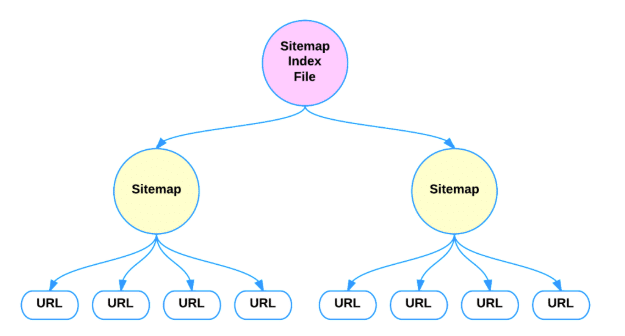
Możesz przesłać wiele plików map witryn, ale każdy plik musi być zgodny z powyższymi zasadami. Jeśli chcesz, możesz skompresować pliki za pomocą gzip, aby zmniejszyć ich rozmiar zgodnie z wymaganiami.
Format XML pliku indeksu jest bardzo podobny do normalnego formatu mapy witryny. Musi zawierać:
- otwórz i zamknij tag jako ;
- wpis dla każdej mapy witryny z głównym atrybutem XML ;
- do głównego atrybutu.
Uwzględniono również zalecany atrybut.
Uwaga: plik indeksu map witryn może zawierać tylko mapy znajdujące się w tej samej witrynie. Na przykład:
https://example.com/sitemap_index.xml może zawierać mapy pod adresem https://example.com, ale nie pod adresem https://www.saitprimer.com lub https://www.example.com
Podobnie jak w przypadku wszystkich innych plików, plik indeksu musi być zakodowany w UTF-8.
Poniższy przykład przedstawia indeks mapy witryny zawierający dwie mapy:
http://www.example.com/sitemap1.xml.gz
2018-10-01T18:23:17+00:00
http://www.example.com/sitemap2.xml.gz
2017-01-01
Opis wersji mobilnej
Musimy pomóc botowi Google w znalezieniu naszej zawartości i zrozumieniu powiązania między stronami na komputery i urządzenia mobilne. W mapie witryny XML należy dodać atrybut rel = „alternate” dla stron w wersji na komputery w następujący sposób:
xmlns:xhtml=”http://www.w3.org/1999/xhtml”>
http://www.example.com/strona-1/
<xhtml:link
rel=”alternatywny”
media=”tylko ekran i (maksymalna szerokość: 640px)”
href=”http://m.example.com/strona-1″ />
Pamiętaj, że każda strona na komputery musi odpowiadać jednej stronie wersji mobilnej. Nie zaleca się na przykład, aby kilka stron na komputery było połączonych za pomocą rel = „alternate” z jedną stroną wersji mobilnej i odwrotnie.
Musisz także sprawdzić, czy nie ma przekierowań. Ważne jest, aby strona desktopowa odpowiadała tej samej treści w wersji mobilnej, a nie przekierowywała na inną. Dodatkowe informacje tutaj.
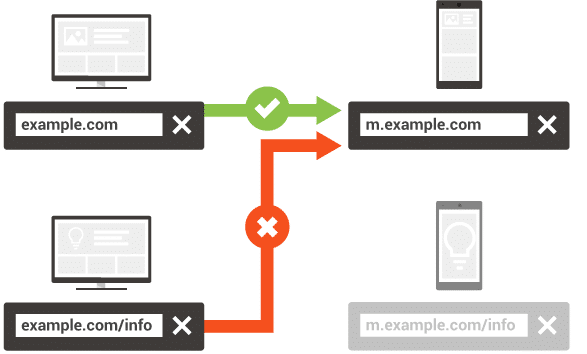
Jak boty mogą znaleźć Twoją mapę witryny XML
Kiedy zakończysz całą automatyzację procesu i prześlesz go na swój serwer (lub wygenerujesz przez wtyczkę), musisz zostawić wskazówkę, gdzie boty mogą go znaleźć.
Najlepszym sposobem jest umieszczenie linku do niego w pliku robots.txt. Nazywa się to również Sitemap Discovery i jest to coś, co Google, Bing i Yahoo wprowadziły w 2007 roku, aby pomóc swoim robotom znaleźć mapy witryn XML.
Wszystko, co musisz zrobić, to podać pełną ścieżkę do pliku mapy lub indeksu.

Prawidłowa transliteracja adresów
Oficjalna dokumentacja Google (Tworzenie i przesyłanie mapy witryny) podkreśla, że wszystkie wartości danych (w tym adresy URL) muszą zawierać tylko znaki ASCII. Nie może zawierać kodów kontrolnych ani znaków specjalnych, takich jak * lub {}.
Jeśli adres URL Twojej witryny zawiera te znaki, przy próbie jego dodania pojawi się błąd.
Prześlij swoją mapę do Google
Mapę witryny możesz przesłać do Google za pomocą Google Search Console.
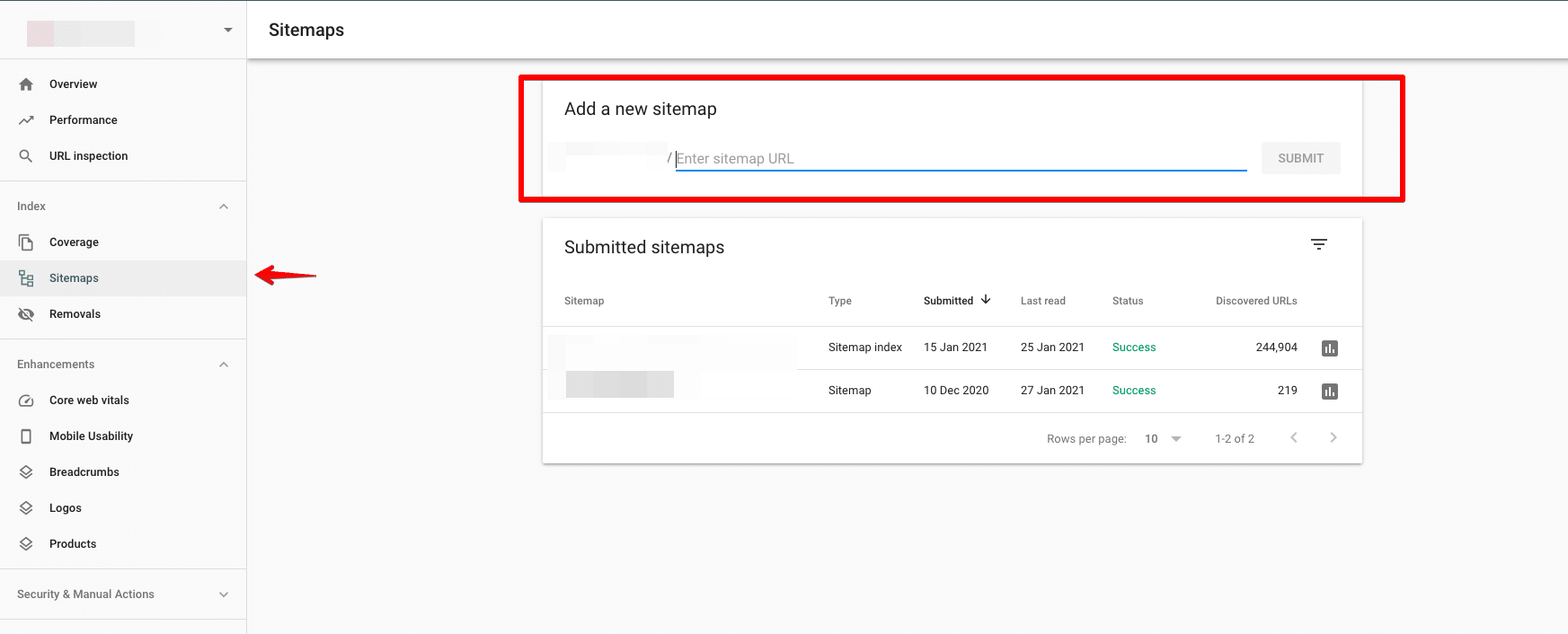
Sprawdź, czy nie ma błędów przed przesłaniem. Ważne jest, aby usunąć wszelkie błędy, które mogą być przeszkodą w indeksowaniu kluczowych stron docelowych.
W idealnym przypadku liczba zindeksowanych stron powinna być równa liczbie przesłanych stron.
Wniosek
- Bądź konsekwentny – jeśli strona jest zablokowana przez plik robots.txt lub „noindex”, lepiej, aby nie znajdowała się na Twojej mapie XML.
- Zautomatyzuj swój proces — wszystkie powyższe zalecenia powinny być dostępne do automatyzacji, ponieważ pozwoli to zaoszczędzić czas, pomoże zoptymalizować budżet indeksowania, a także oszczędzi wielu bólów głowy.
- Jeśli masz bardzo dużą witrynę, użyj pliku indeksu z różnymi mapami, co pozwoli zaoszczędzić czas serwera i obejmie wszystkie ważne strony witryny.