
Czym są wektory słów i jak doładowuje je znaczniki strukturalne?
Opublikowany: 2021-07-28Jak definiujesz wektory słów? W tym poście przedstawię Ci pojęcie wektorów słownych. Omówimy różne typy osadzania słów, a co ważniejsze, jak działają wektory słów. Wtedy będziemy mogli zobaczyć wpływ wektorów słów na SEO, co pozwoli nam zrozumieć, w jaki sposób znaczniki Schema.org dla danych strukturalnych mogą pomóc w wykorzystaniu wektorów słów w SEO.
Czytaj dalej ten post, jeśli chcesz dowiedzieć się więcej na te tematy.
Zanurzmy się od razu.
Czym są wektory słów?
Wektory słów (nazywane także osadzaniami słów) to rodzaj reprezentacji słowa, który umożliwia słowom o podobnym znaczeniu mieć równą reprezentację.
Mówiąc prościej: wektor słowny jest wektorową reprezentacją określonego słowa.
Według Wikipedii:
Jest to technika stosowana w przetwarzaniu języka naturalnego (NLP) do przedstawiania słów do analizy tekstu, zwykle jako wektor o wartościach rzeczywistych, który koduje znaczenie słowa, dzięki czemu słowa znajdujące się blisko przestrzeni wektorowej mogą mieć podobne znaczenie.
Poniższy przykład pomoże nam to lepiej zrozumieć:
Spójrz na te podobne zdania:
Miłego dnia . i miłego dnia.
Ledwo mają inne znaczenie. Jeśli zbudujemy wyczerpujące słownictwo (nazwijmy to V), będzie to V = {Miej, dobrze, świetnie, dzień} łącząc wszystkie słowa. Moglibyśmy zakodować to słowo w następujący sposób.
Wektorowa reprezentacja słowa może być zakodowanym w jednym gorącym wektorze , gdzie 1 reprezentuje pozycję, w której słowo istnieje, a 0 reprezentuje resztę
Mieć = [1,0,0,0,0]
a=[0,1,0,0,0]
dobry=[0,0,1,0,0]
świetnie=[0,0,0,0,1,0]
dzień=[0,0,0,0,1]
Załóżmy, że nasz słownik zawiera tylko pięć słów: król, królowa, mężczyzna, kobieta i dziecko. Moglibyśmy zakodować słowa jako:
Król = [1,0,0,0,0]
Królowa = [0,1,0,0,0]
Mężczyzna = [0,0,1,00]
Kobieta = [0,0,0,1,0]
Dziecko = [0,0,0,0,1]
Rodzaje osadzania słów (wektory słów)
Osadzanie słów to jedna z takich technik, w której wektory reprezentują tekst. Oto niektóre z bardziej popularnych typów Osadzanie słów:
- Osadzanie oparte na częstotliwości
- Osadzanie oparte na prognozach
Nie będziemy tutaj zagłębiać się w osadzanie oparte na częstotliwości i osadzanie oparte na przewidywaniach, ale poniższe przewodniki mogą okazać się pomocne w zrozumieniu obu:
Intuicyjne zrozumienie osadzania słów i szybkie wprowadzenie do Bag-of-Words (BOW) i TF-IDF do tworzenia funkcji z tekstu
Krótkie wprowadzenie do WORD2Vec
Chociaż osadzanie oparte na częstotliwości zyskało popularność, nadal istnieje luka w zrozumieniu kontekstu słów i ograniczona ich reprezentacja.
Osadzanie oparte na przewidywaniu (WORD2Vec) zostało stworzone, opatentowane i wprowadzone do społeczności NLP w 2013 roku przez zespół naukowców kierowany przez Tomasa Mikolova w Google.
Według Wikipedii algorytm word2vec wykorzystuje model sieci neuronowej do uczenia skojarzeń słów z dużego korpusu tekstu (duży i ustrukturyzowany zbiór tekstów).
Po nauczeniu taki model może wykrywać słowa synonimiczne lub sugerować dodatkowe słowa do zdania częściowego. Na przykład za pomocą Word2Vec możesz łatwo stworzyć takie wyniki: Król – mężczyzna + kobieta = Królowa, co uznano za wynik niemal magiczny.
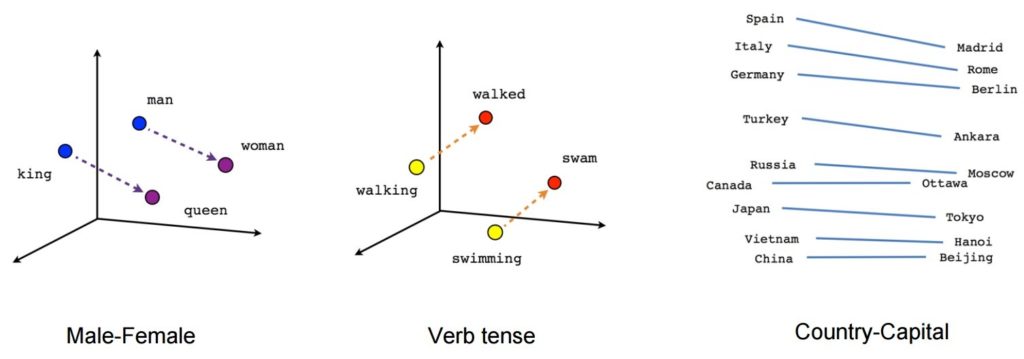 Źródło obrazu: Tensorflow
Źródło obrazu: Tensorflow
- [król] – [mężczyzna] + [kobieta] ~= [królowa] (inny sposób myślenia jest taki, że [król] – [królowa] koduje tylko płciową część [monarchy])
- [chodzenie] – [pływanie] + [pływanie] ~= [chodzenie] (lub [pływanie] – [pływanie] koduje tylko „czas przeszły” czasownika)
- [Madryt] – [Hiszpania] + [Francja] ~= [Paryż] (lub [Madryt] – [Hiszpania] ~= [Paryż] – [Francja], który prawdopodobnie jest z grubsza „stolicą”)
Źródło: Brainslab Digital
Wiem, że to trochę techniczne, ale Stitch Fix stworzył fantastyczny post o związkach semantycznych i wektorach słów.
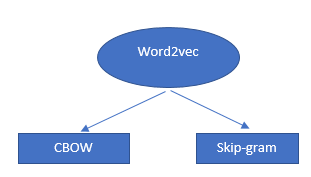
Algorytm Word2Vec nie jest pojedynczym algorytmem, ale połączeniem dwóch technik, które wykorzystują kilka metod sztucznej inteligencji, aby połączyć rozumienie ludzkie i maszynowe. Ta technika jest niezbędna do rozwiązywania wielu problemów NLP.
Te dwie techniki to:
- – CBOW (Ciągły worek słów) lub model CBOW
- – Skip-gram model.
Oba są płytkimi sieciami neuronowymi, które dostarczają prawdopodobieństw dla słów i okazały się pomocne w zadaniach takich jak porównywanie słów i analogia słów.
Jak działają wektory słów i word2vecs
Word Vector to model AI opracowany przez Google, który pomaga nam rozwiązywać bardzo złożone zadania NLP.
„Modele Word Vector mają jeden główny cel, o którym powinieneś wiedzieć:
Jest to algorytm, który pomaga Google w wykrywaniu związków semantycznych między słowami”.
Każde słowo jest zakodowane w wektorze (jako liczba reprezentowana w wielu wymiarach), aby dopasować wektory słów, które pojawiają się w podobnym kontekście. Dlatego dla tekstu powstaje gęsty wektor.
Te modele wektorowe odwzorowują semantycznie podobne frazy do pobliskich punktów na podstawie równoważności, podobieństw lub pokrewieństwa idei i języka
[Studium przypadku] Zwiększanie wzrostu na nowych rynkach dzięki SEO na stronie
 Przeczytaj studium przypadku
Przeczytaj studium przypadkuWord2Vec- Jak to działa?
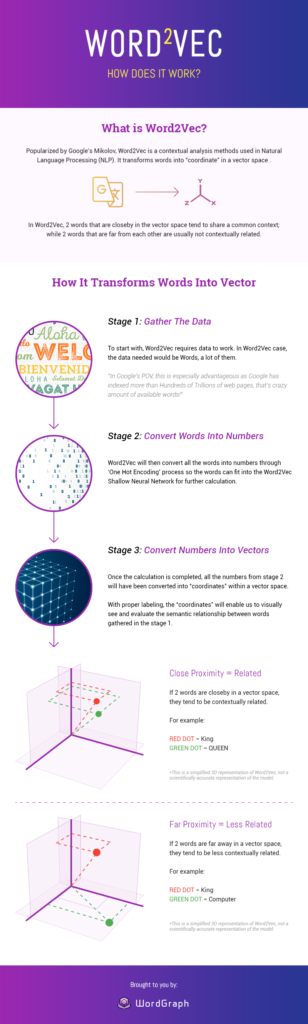
Źródło obrazu: Seopressor
Plusy i minusy Word2Vec
Widzieliśmy, że Word2vec jest bardzo skuteczną techniką generowania podobieństwa dystrybucyjnego. Poniżej wymieniłem niektóre z jego innych zalet:
- Nie ma trudności ze zrozumieniem koncepcji Word2vec. Word2Vec nie jest tak skomplikowany, że nie zdajesz sobie sprawy z tego, co dzieje się za kulisami.
- Architektura Word2Vec jest bardzo wydajna i łatwa w użyciu. W porównaniu z innymi technikami trenuje się szybko.
- Szkolenie jest tutaj prawie całkowicie zautomatyzowane, więc dane oznaczone przez ludzi nie są już potrzebne.
- Ta technika działa zarówno w przypadku małych, jak i dużych zestawów danych. W rezultacie jest to model łatwy do skalowania.
- Jeśli znasz pojęcia, możesz łatwo odtworzyć całą koncepcję i algorytm.
- Wyjątkowo dobrze oddaje podobieństwo semantyczne.
- Dokładne i wydajne obliczeniowo
- Ponieważ takie podejście nie jest nadzorowane, jest to bardzo czasochłonne pod względem wysiłku.
Wyzwania Word2Vec
Koncepcja Word2vec jest bardzo wydajna, ale kilka punktów może być nieco trudnych. Oto kilka najczęstszych wyzwań.
- Podczas opracowywania modelu word2vec dla zestawu danych debugowanie może być dużym wyzwaniem, ponieważ model word2vec jest łatwy do opracowania, ale trudny do debugowania.
- Nie zajmuje się niejasnościami. Tak więc w przypadku słów o wielu znaczeniach Osadzanie będzie odzwierciedlać średnią tych znaczeń w przestrzeni wektorowej.
- Nie można obsłużyć słów nieznanych lub słów OOV: Największym problemem związanym z word2vec jest niemożność obsługi słów nieznanych lub poza słownictwem (OOV).
Wektory słowne: zmiana zasad w optymalizacji pod kątem wyszukiwarek?
Wielu ekspertów SEO uważa, że Word Vector wpływa na pozycję witryny w wynikach wyszukiwania.
W ciągu ostatnich pięciu lat firma Google wprowadziła dwie aktualizacje algorytmów, które kładą wyraźny nacisk na jakość treści i kompleksowość językową.
Cofnijmy się o krok i porozmawiajmy o aktualizacjach:
Koliber
W 2013 roku Hummingbird udostępnił wyszukiwarkom możliwość analizy semantycznej. Wykorzystując i włączając teorię semantyki do swoich algorytmów, otworzyli nową drogę do świata wyszukiwania.
Google Hummingbird był największą zmianą w wyszukiwarce od czasu Caffeine w 2010 roku. Swoją nazwę zawdzięcza temu, że jest „precyzyjny i szybki”.
Według Search Engine Land, Hummingbird zwraca większą uwagę na każde słowo w zapytaniu, zapewniając, że brane jest pod uwagę całe zapytanie, a nie tylko poszczególne słowa.

Głównym celem Hummingbird było dostarczanie lepszych wyników dzięki zrozumieniu kontekstu zapytania, a nie zwracaniu wyników dla określonych słów kluczowych.
„Google Hummingbird został wydany we wrześniu 2013 r.”
RangaBrain
W 2015 roku Google ogłosił RankBrain, strategię wykorzystującą sztuczną inteligencję (AI).
RankBrain to algorytm, który pomaga Google dzielić złożone zapytania wyszukiwania na prostsze. RankBrain konwertuje zapytania z „ludzkiego” języka na język, który Google może łatwo zrozumieć.
Google potwierdziło użycie RankBrain 26 października 2015 r. w artykule opublikowanym przez Bloomberg.
BERT
21 października 2019 r. BERT rozpoczął wdrażanie w systemie wyszukiwania Google
BERT oznacza Bidirectional Encoder Representations from Transformers, technikę opartą na sieciach neuronowych używaną przez Google do wstępnego szkolenia w przetwarzaniu języka naturalnego (NLP).
Krótko mówiąc, BERT pomaga komputerom zrozumieć język bardziej jak ludzie i jest to największa zmiana w wyszukiwaniu od czasu wprowadzenia RankBrain przez Google.
Nie jest zamiennikiem RankBrain, ale raczej dodatkową metodą zrozumienia treści i zapytań.
Google wykorzystuje BERT w swoim systemie rankingowym jako dodatek. Algorytm RankBrain nadal istnieje dla niektórych zapytań i będzie nadal istnieć. Ale kiedy Google uzna, że BERT może lepiej zrozumieć zapytanie, użyje tego.
Więcej informacji na temat BERT można znaleźć w tym poście autorstwa Barry'ego Schwartza, a także w szczegółowym omówieniu Dawn Anderson.
Oceń swoją witrynę za pomocą Word Vectors
Zakładam, że już stworzyłeś i opublikowałeś unikalne treści i nawet po ich ciągłym dopracowywaniu nie poprawia to twojego rankingu ani ruchu.
Zastanawiasz się, dlaczego tak się dzieje z tobą?
Może to wynikać z tego, że nie uwzględniłeś Word Vector: modelu AI Google.
- Pierwszym krokiem jest zidentyfikowanie wektorów słów z 10 najlepszych rankingów SERP dla Twojej niszy.
- Dowiedz się, jakich słów kluczowych używają Twoi konkurenci i czego możesz przeoczyć.
Stosując Word2Vec, który wykorzystuje zaawansowane techniki przetwarzania języka naturalnego i framework uczenia maszynowego, będziesz mógł zobaczyć wszystko w szczegółach.
Ale są to możliwe, jeśli znasz techniki uczenia maszynowego i NLP, ale możemy zastosować wektory słów w treści za pomocą następującego narzędzia:
WordGraph, pierwsze na świecie narzędzie do tworzenia wektorów słów
To narzędzie sztucznej inteligencji jest tworzone przy użyciu sieci neuronowych do przetwarzania języka naturalnego i przeszkolone w zakresie uczenia maszynowego.
W oparciu o sztuczną inteligencję WordGraph analizuje Twoje treści i pomaga poprawić ich trafność w rankingu Top 10 witryn internetowych.
Sugeruje słowa kluczowe, które są matematycznie i kontekstowo powiązane z Twoim głównym słowem kluczowym.
Osobiście łączę to z BIQ, potężnym narzędziem SEO, które działa dobrze z WordGraph.
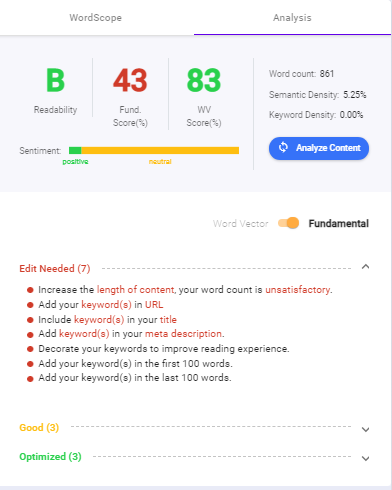
Dodaj swoje treści do narzędzia analizy treści wbudowanego w Biq. Pokaże Ci całą listę wskazówek SEO na stronie , które możesz dodać, jeśli chcesz zająć najwyższą pozycję.
W tym przykładzie możesz zobaczyć, jak działa analiza treści. Listy pomogą Ci opanować SEO na stronie i pozycjonować za pomocą praktycznych metod!
Jak wzmocnić wektory słów: używanie znaczników danych strukturalnych
Znacznik schematu lub dane strukturalne to rodzaj kodu (napisany w formacie JSON, Java-Script Object Notation) utworzony przy użyciu słownika schema.org, który pomaga wyszukiwarkom indeksować, organizować i wyświetlać zawartość.
Jak dodać uporządkowane dane
Ustrukturyzowane dane można łatwo dodać do swojej witryny, dodając wbudowany skrypt w swoim html
Poniższy przykład pokazuje, jak zdefiniować uporządkowane dane organizacji w najprostszym możliwym formacie.
Aby wygenerować znacznik schematu, używam generatora znaczników schematu (JSON-LD).
Oto przykład na żywo znaczników schematu dla https://www.telecloudvoip.com/. Sprawdź kod źródłowy i wyszukaj JSON.
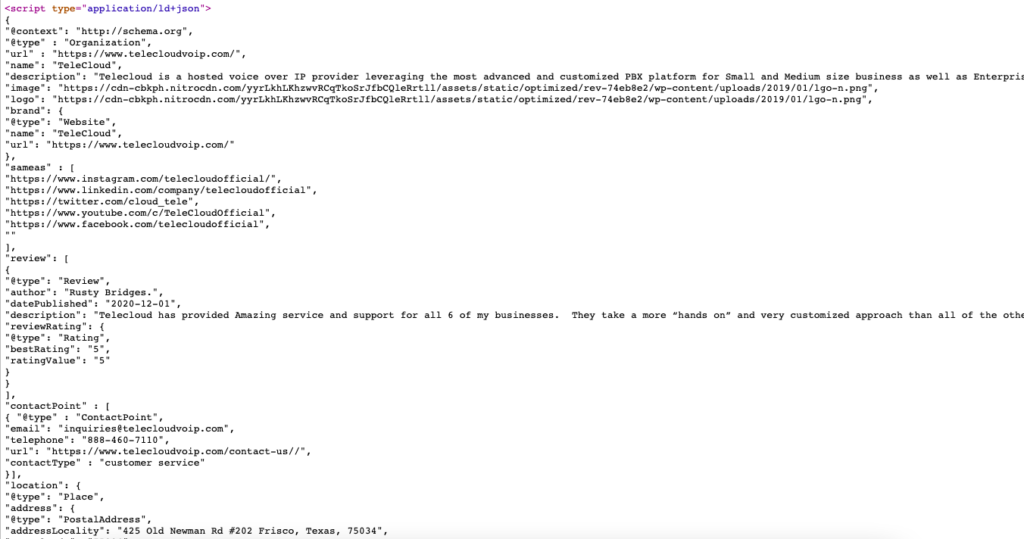
Po utworzeniu kodu znaczników schematu użyj Testu wyników z elementami rozszerzonymi Google, aby sprawdzić, czy strona obsługuje wyniki z elementami rozszerzonymi.
Możesz też użyć narzędzia Semrush Site Audit, aby przejrzeć elementy danych strukturalnych dla każdego adresu URL i określić, które strony kwalifikują się do wyświetlania w wynikach z elementami rozszerzonymi. 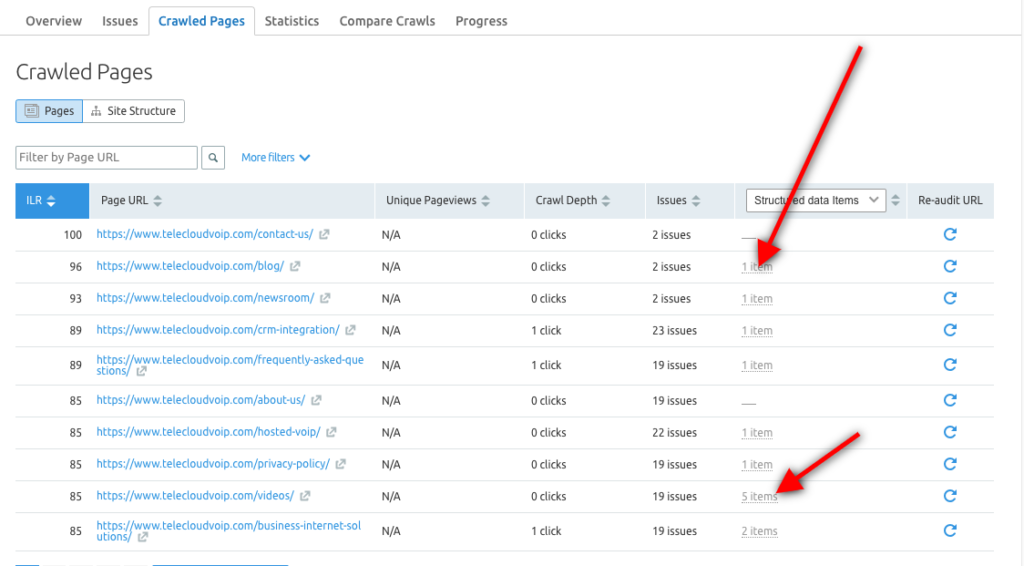
Dlaczego dane strukturalne są ważne dla SEO?
Dane strukturalne są ważne dla SEO, ponieważ pomagają Google zrozumieć, o czym jest Twoja witryna i strony, co skutkuje dokładniejszym rankingiem treści.
Dane strukturalne poprawiają zarówno doświadczenie robota wyszukiwania, jak i użytkownika, poprawiając SERP (strony wyników wyszukiwania) dzięki większej ilości informacji i dokładności.
Aby zobaczyć wpływ na wyszukiwarkę Google, przejdź do Search Console i w sekcji Skuteczność > Wyniki wyszukiwania > Wygląd wyszukiwania możesz wyświetlić zestawienie wszystkich typów wyników z elementami rozszerzonymi, takich jak „filmy” i „Najczęściej zadawane pytania”, oraz zobaczyć wygenerowane przez nie bezpłatne wyświetlenia i kliknięcia dla treści.
Oto niektóre zalety uporządkowanych danych:
- Dane strukturalne obsługują wyszukiwanie semantyczne
- Wspiera również Twój E-AT (wiedza, autorytatywność i zaufanie)
- Posiadanie uporządkowanych danych może również zwiększyć współczynniki konwersji, ponieważ więcej osób zobaczy Twoje oferty, co zwiększa prawdopodobieństwo, że kupią od Ciebie.
- Korzystając z danych strukturalnych, wyszukiwarki są w stanie lepiej zrozumieć Twoją markę, witrynę i treści.
- Wyszukiwarkom łatwiej będzie rozróżniać strony kontaktowe, opisy produktów, strony z przepisami, strony wydarzeń i recenzje klientów.
- Za pomocą uporządkowanych danych Google buduje lepszy, dokładniejszy wykres wiedzy i panel wiedzy o Twojej marce.
- Te ulepszenia mogą skutkować większą liczbą bezpłatnych wyświetleń i bezpłatnych kliknięć.
Dane strukturalne są obecnie używane przez Google do ulepszania wyników wyszukiwania. Gdy ludzie wyszukują Twoje strony internetowe za pomocą słów kluczowych, uporządkowane dane mogą pomóc Ci uzyskać lepsze wyniki. Wyszukiwarki zauważą Twoje treści bardziej, jeśli dodamy znaczniki schematu.
Możesz zaimplementować znaczniki schematu w wielu różnych elementach. Poniżej wymieniono kilka obszarów, w których można zastosować schemat:
- Artykuły
- Posty na blogu
- Artykuły z wiadomościami
- Wydarzenia
- Produkty
- Filmy
- Usługi
- Opinie
- Zagregowane oceny
- Restauracje
- Lokalny biznes
Oto pełna lista elementów, które można oznaczyć za pomocą schematu.
Dane strukturalne z osadzaniami jednostek
Termin „byt” odnosi się do reprezentacji dowolnego typu obiektu, pojęcia lub podmiotu. Podmiotem może być osoba, film, książka, pomysł, miejsce, firma lub wydarzenie.
Podczas gdy maszyny nie potrafią tak naprawdę zrozumieć słów, z osadzonymi bytami są w stanie łatwo zrozumieć relację między królem – królową = mężem – żoną
Osadzanie jednostek działa lepiej niż kodowanie z jednym gorącym kodem
Algorytm wektora słów jest używany przez Google do wykrywania związków semantycznych między słowami, a w połączeniu z ustrukturyzowanymi danymi otrzymujemy semantycznie ulepszoną sieć.
Używając uporządkowanych danych, przyczyniasz się do tworzenia bardziej semantycznej sieci. Jest to rozszerzona sieć, w której opisujemy dane w formacie do odczytu maszynowego.
Ustrukturyzowane dane semantyczne w Twojej witrynie pomagają wyszukiwarkom dopasować Twoje treści do odpowiednich odbiorców. Korzystanie z NLP, Machine Learning i Deep Learning pomaga zmniejszyć rozbieżność między tym, czego ludzie szukają, a dostępnymi tytułami.
Końcowe przemyślenia
Gdy już rozumiesz pojęcie wektorów słów i ich znaczenie, możesz zwiększyć skuteczność i wydajność swojej strategii wyszukiwania organicznego, wykorzystując wektory słów, osadzania jednostek i ustrukturyzowane dane semantyczne.
Aby uzyskać najwyższą pozycję w rankingu, ruch i konwersje, musisz używać wektorów słów, osadzania jednostek i uporządkowanych danych semantycznych, aby wykazać Google, że treść Twojej strony internetowej jest dokładna, precyzyjna i godna zaufania.