
Co to jest ukryte indeksowanie semantyczne i jak to działa?
Opublikowany: 2020-04-02Utajone indeksowanie semantyczne (LSI) od dawna jest przedmiotem debaty wśród marketerów w wyszukiwarkach. Wyszukuj w wyszukiwarce termin „utajone indeksowanie semantyczne”, a spotkasz zarówno zwolenników, jak i sceptyków w równym stopniu. Nie ma jednoznacznego konsensusu co do korzyści płynących z rozważenia LSI w kontekście marketingu w wyszukiwarkach. Jeśli nie znasz tej koncepcji, ten artykuł podsumuje debatę na temat LSI, dzięki czemu będziesz mieć nadzieję, że zrozumiesz, co to oznacza dla Twojej strategii SEO.
Co to jest ukryte indeksowanie semantyczne?
LSI to proces występujący w przetwarzaniu języka naturalnego (NLP). NLP to podzbiór lingwistyki i inżynierii informacyjnej, skupiający się na tym, jak maszyny interpretują ludzki język. Kluczową częścią tego badania jest semantyka dystrybucji. Model ten pomaga nam zrozumieć i klasyfikować słowa o podobnym znaczeniu kontekstowym w dużych zbiorach danych.
Opracowany w latach 80. LSI wykorzystuje metodę matematyczną, która sprawia, że wyszukiwanie informacji jest dokładniejsze. Ta metoda działa poprzez identyfikację ukrytych relacji kontekstowych między słowami. Pomoże ci to rozbić w ten sposób:
- Utajone → Ukryte
- Semantyczny → Relacje między słowami
- Indeksowanie → Pobieranie informacji
Jak działa ukryte indeksowanie semantyczne?
LSI działa przy użyciu częściowej aplikacji Singular Value Decomposition (SVD). SVD to operacja matematyczna, która redukuje macierz do jej części składowych w celu uzyskania prostych i wydajnych obliczeń.
Analizując ciąg słów, LSI usuwa spójniki, zaimki i wspólne czasowniki, znane również jako słowa stop. To izoluje słowa, które składają się na główną „treść” frazy. Oto krótki przykład tego, jak to może wyglądać:
![]()
Słowa te są następnie umieszczane w Term Document Matrix (TDM). TDM to siatka 2D, która zawiera listę częstotliwości występowania każdego konkretnego słowa (lub terminu) w dokumentach w zestawie danych.
Funkcje ważenia są następnie stosowane do TDM. Prostym przykładem jest klasyfikowanie wszystkich dokumentów, które zawierają słowo o wartości 1 i wszystkich, które nie zawierają słowa o wartości 0. Gdy słowa występują w tych dokumentach z tą samą ogólną częstotliwością, nazywa się to współwystępowaniem . Poniżej znajdziesz podstawowy przykład TDM i sposób, w jaki ocenia on współwystępowanie wielu fraz:
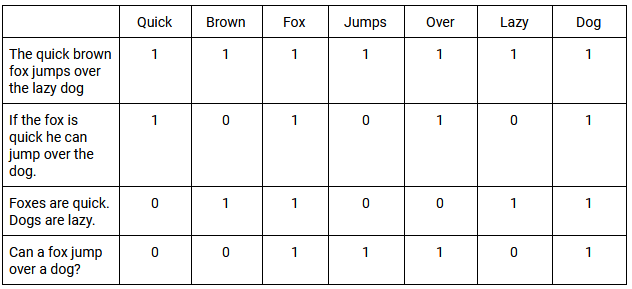
Korzystanie z SVD pozwala nam przybliżyć wzorce użycia słów we wszystkich dokumentach. Wektory SVD generowane przez LSI przewidują znaczenie dokładniej niż analizowanie poszczególnych terminów. Ostatecznie LSI może wykorzystać relacje między słowami, aby lepiej zrozumieć ich sens lub znaczenie w określonym kontekście.
[Studium przypadku] Zwiększanie wzrostu na nowych rynkach dzięki SEO na stronie
 Przeczytaj studium przypadku
Przeczytaj studium przypadkuW jaki sposób Latent Semantic Indexing zaangażowało się w SEO?
W swoich początkowych latach Google odkrył, że wyszukiwarki pozycjonują strony internetowe na podstawie częstotliwości danego słowa kluczowego. Nie gwarantuje to jednak najtrafniejszego wyniku wyszukiwania. Zamiast tego Google zaczął oceniać strony internetowe, które uważali za zaufanych arbitrów informacji.
Z czasem algorytmy Google będą z większą dokładnością odfiltrowywać niskiej jakości i nieistotne witryny. Dlatego marketerzy muszą zrozumieć znaczenie wyszukiwania, zamiast polegać na dokładnych użytych słowach. Właśnie dlatego Roger Montti opisał LSI jako „koła szkoleniowe dla wyszukiwarek” w artykule o przestarzałych poglądach na SEO, dodając, że LSI ma „niewielkie lub zerowe znaczenie dla dzisiejszej oceny witryn przez wyszukiwarki”.
Znaczenie zapytania wyszukiwania jest ściśle powiązane z intencją, która się za nim kryje. Google prowadzi dokument o nazwie Wskazówki dotyczące oceny jakości wyszukiwania. W niniejszych wskazówkach wprowadzają cztery przydatne kategorie intencji użytkownika:
- Know Query — reprezentuje szukanie informacji na dany temat. Wariantem tego jest zapytanie „Poznaj proste”, które ma miejsce wtedy, gdy użytkownicy wyszukują z myślą o konkretnej odpowiedzi.
- Wykonaj zapytanie — odzwierciedla chęć zaangażowania się w określoną czynność, taką jak zakup lub pobranie online. Wszystkie te zapytania można zdefiniować poprzez poczucie „interakcji”.
- Zapytanie w witrynie — to jest, gdy użytkownicy szukają określonej witryny lub strony. Te wyszukiwania wskazują na wcześniejszą świadomość określonej witryny lub marki.
- Zapytanie dotyczące wizyty osobistej — użytkownik szuka fizycznej lokalizacji, takiej jak sklep stacjonarny lub restauracja.
Teoria stojąca za LSI – definiowanie kontekstowego znaczenia słowa w wyrażeniu – dała Google przewagę konkurencyjną. Jednak pojawił się pomysł, że „słowa kluczowe LSI” stały się nagle złotym biletem do sukcesu SEO.

Czy „Słowa kluczowe LSI” rzeczywiście istnieją?
Wiele znaczących publikacji pozostaje zdecydowanymi zwolennikami słów kluczowych LSI. Jednak kilka źródeł, takich jak analityk trendów Google dla webmasterów John Mueller, twierdzi, że to mit. Źródła te zaczęły podnosić następujące punkty:
- LSI został opracowany przed World Wide Web i nie miał być stosowany do tak dużego i dynamicznego zestawu danych.
- Amerykański patent na Latent Semantic Indexing, przyznany organizacji o nazwie Bell Communications Research Inc. w 1989 roku, wygasłby w 2008 roku. Dlatego, według Billa Slawskiego, Google używające LSI byłoby podobne do „korzystania z inteligentnego urządzenia telegraficznego do łączenia się z internet mobilny”.
- Google korzysta z RankBrain, metody uczenia maszynowego, która przekształca duże ilości tekstu w „wektory” – matematyczne jednostki, które pomagają komputerom zrozumieć język pisany. RankBrain dostosowuje sieć do stale rozwijającego się zbioru danych, dzięki czemu może być używany przez Google, w przeciwieństwie do LSI.
Ostatecznie, LSI ujawnia prawdę, której powinni przestrzegać marketerzy: badanie unikalnego kontekstu słowa pomaga nam lepiej zrozumieć intencje użytkownika niż słowa kluczowe upchane w treści. Nie musi to jednak koniecznie potwierdzać, że Google plasuje się w oparciu o LSI. Czy zatem można bezpiecznie powiedzieć, że LSI działa w SEO jako filozofia, a nie nauka ścisła?
Wróćmy do cytatu Rogera Montti o LSI jako „kołach treningowych dla wyszukiwarek”. Kiedy nauczysz się jeździć na rowerze, zdejmujesz kółka treningowe. Czy możemy założyć, że w 2020 roku Google nie korzysta już z kółek treningowych?
Możemy rozważyć ostatnią aktualizację algorytmu Google. W październiku 2019 r. Pandu Nayak, wiceprezes ds. wyszukiwania, ogłosił, że Google zaczął używać systemu AI o nazwie BERT (Bidirectional Encoder Representations from Transformers). Dotykając ponad 10% wszystkich zapytań, jest to jedna z największych aktualizacji Google w ostatnich latach.
Analizując zapytanie wyszukiwania, BERT bierze pod uwagę pojedyncze słowo w odniesieniu do wszystkich słów w tej konkretnej frazie. Ta analiza jest dwukierunkowa, ponieważ uwzględnia wszystkie słowa przed lub po określonym słowie. Usunięcie pojedynczego słowa może drastycznie wpłynąć na to, jak BERT rozumie unikalny kontekst frazy.
Stanowi to kontrast z LSI, które pomija wszelkie słowa stop w swojej analizie. Poniższy przykład pokazuje, jak usunięcie słów stop może zmienić sposób, w jaki rozumiemy frazę:
![]()
Pomimo tego, że jest słowem stop, „znajdź” jest sednem wyszukiwania, które zdefiniowalibyśmy jako zapytanie „odwiedziny osobiste”.
Więc co powinni zrobić marketerzy?
Początkowo sądzono, że LSI może pomóc Google w dopasowaniu treści do odpowiednich zapytań. Wydaje się jednak, że debata marketingowa wokół wykorzystania LSI nie doszła jeszcze do jednego wniosku. Mimo to marketerzy wciąż mogą podjąć wiele kroków, aby zapewnić, że ich praca pozostanie strategicznie istotna.
Po pierwsze, artykuły, teksty internetowe i płatne kampanie powinny być zoptymalizowane pod kątem synonimów i wariantów. To wyjaśnia, w jaki sposób ludzie o podobnych zamiarach inaczej używają języka.
Marketerzy muszą nadal pisać z autorytetem i jasnością. Jest to absolutna konieczność, jeśli chcą, aby ich treść rozwiązała konkretny problem. Problemem tym może być brak informacji lub potrzeba określonego produktu lub usługi. Gdy marketerzy to zrobią, pokazuje to, że naprawdę rozumieją intencje użytkownika.
Powinni też często korzystać z danych strukturalnych. Niezależnie od tego, czy jest to witryna internetowa, przepis czy najczęściej zadawane pytania, uporządkowane dane zapewniają Google kontekst, w którym można zrozumieć, co indeksuje.