
Co to jest usuwanie danych i jak z niego korzystać?
Opublikowany: 2017-09-13Co to jest pozyskiwanie danych?
Skrobanie danych, znane również jako web scraping, to proces importowania informacji z witryny internetowej do arkusza kalkulacyjnego lub pliku lokalnego zapisanego na komputerze. Jest to jeden z najskuteczniejszych sposobów uzyskiwania danych z sieci, a w niektórych przypadkach przesyłania tych danych do innej witryny. Popularne zastosowania skrobania danych obejmują:
- Badania treści internetowych/biznesowej analizy
- Ceny dla stron rezerwujących podróże/stron porównujących ceny
- Znajdowanie leadów sprzedażowych/przeprowadzanie badań rynkowych poprzez indeksowanie publicznych źródeł danych (np. Yell i Twitter)
- Wysyłanie danych produktów z witryny e-commerce do innego dostawcy online (np. Zakupy Google)
A ta lista tylko zarysowuje powierzchnię. Data scraping ma ogromną liczbę zastosowań – jest przydatny w każdym przypadku, gdy dane muszą zostać przeniesione z jednego miejsca do drugiego.
Podstawy skrobania danych są stosunkowo łatwe do opanowania. Zobaczmy, jak skonfigurować prostą akcję skrobania danych za pomocą programu Excel.
Pozyskiwanie danych za pomocą dynamicznych zapytań internetowych w programie Microsoft Excel
Konfigurowanie dynamicznego zapytania internetowego w programie Microsoft Excel to łatwa, wszechstronna metoda zbierania danych, która umożliwia skonfigurowanie źródła danych z zewnętrznej witryny internetowej (lub wielu witryn internetowych) w arkuszu kalkulacyjnym.
Obejrzyj ten doskonały samouczek wideo, aby dowiedzieć się, jak importować dane z Internetu do programu Excel — lub, jeśli wolisz, skorzystaj z pisemnych instrukcji poniżej:
- Otwórz nowy skoroszyt w programie Excel
- Kliknij komórkę, do której chcesz zaimportować dane
- Kliknij kartę „Dane”
- Kliknij „Pobierz dane zewnętrzne”
- Kliknij symbol „Z sieci”
- Zwróć uwagę na małe żółte strzałki, które pojawiają się w lewym górnym rogu strony internetowej i obok niektórych treści
- Wklej adres URL strony internetowej, z której chcesz zaimportować dane do paska adresu (zalecamy wybór witryny, w której dane są wyświetlane w tabelach)
- Kliknij „Idź”
- Kliknij żółtą strzałkę obok danych, które chcesz zaimportować
- Kliknij „Importuj”
- Pojawi się okno dialogowe „Importuj dane”
- Kliknij „OK” (lub zmień wybór komórek, jeśli chcesz)
Jeśli wykonałeś te czynności, powinieneś teraz widzieć dane z witryny w arkuszu kalkulacyjnym.
Wspaniałą cechą dynamicznych zapytań internetowych jest to, że nie tylko importują one dane do arkusza kalkulacyjnego jako jednorazową operację — dostarczają je, co oznacza, że arkusz kalkulacyjny jest regularnie aktualizowany o najnowszą wersję danych, tak jak są one wyświetlane w źródłowa strona internetowa. Dlatego nazywamy je dynamicznymi.
Aby skonfigurować częstotliwość aktualizowania importowanych danych przez dynamiczne zapytanie internetowe, przejdź do opcji „Dane”, następnie „Właściwości”, a następnie wybierz częstotliwość („Odświeżanie co X minut”).
Zautomatyzowane skrobanie danych za pomocą narzędzi
Zapoznanie się z używaniem dynamicznych zapytań internetowych w programie Excel to przydatny sposób na zrozumienie zjawiska scrapingu. Jeśli jednak zamierzasz regularnie używać danych do scrapingu w swojej pracy, dedykowane narzędzie do scrapingu danych może okazać się bardziej skuteczne.
Oto nasze przemyślenia na temat kilku najpopularniejszych narzędzi do scrapingu danych na rynku:
Skrobak danych (wtyczka Chrome)
Data Scraper umieszcza się bezpośrednio w rozszerzeniach przeglądarki Chrome, umożliwiając wybór spośród szeregu gotowych „przepisów” na zbieranie danych w celu wyodrębnienia danych z dowolnej strony internetowej załadowanej do przeglądarki.
To narzędzie działa szczególnie dobrze z popularnymi źródłami do scrapingu danych, takimi jak Twitter i Wikipedia, ponieważ wtyczka zawiera większą różnorodność opcji przepisów dla takich witryn.
Wypróbowaliśmy Data Scraper, wyszukując hashtag na Twitterze „#jourorequest”, aby znaleźć możliwości PR, korzystając z jednej z publicznych receptur tego narzędzia. Oto przykład danych, które otrzymaliśmy:
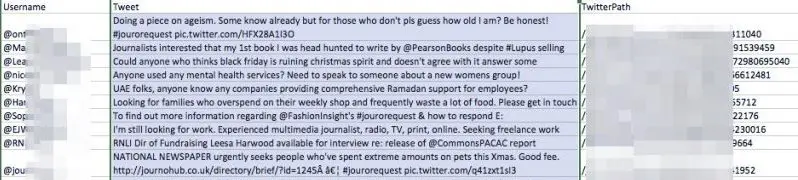
Jak widać, narzędzie dostarczyło tabelę z nazwą użytkownika każdego konta, które ostatnio opublikowało hashtag, a także ich tweet i adres URL
Posiadanie tych danych w tym formacie byłoby bardziej przydatne dla przedstawiciela PR niż po prostu przeglądanie danych w widoku przeglądarki Twittera z kilku powodów:
- Może posłużyć do stworzenia bazy kontaktów prasowych
- Możesz wracać do tej listy i łatwo znaleźć to, czego szukasz, podczas gdy Twitter stale aktualizuje
- Listę można sortować i edytować
- Daje Ci prawo własności do danych – które w każdej chwili można przełączyć w tryb offline lub zmienić
Jesteśmy pod wrażeniem Data Scraper, mimo że jego publiczne przepisy są czasami nieco szorstkie. Spróbuj zainstalować bezpłatną wersję w Chrome i pobaw się z wyodrębnianiem danych. Koniecznie obejrzyj film wprowadzający, który dostarczają, aby zorientować się, jak działa narzędzie i kilka prostych sposobów na wyodrębnienie żądanych danych.
WebHarvy
WebHarvy to narzędzie typu „wskaż i kliknij” w bezpłatnej wersji próbnej. Jego największą zaletą jest elastyczność — możesz użyć wbudowanej przeglądarki internetowej narzędzia, aby przejść do danych, które chcesz zaimportować, a następnie możesz utworzyć własne specyfikacje wyszukiwania, aby wyodrębnić dokładnie to, czego potrzebujesz ze strony źródłowej.
import.io
Import.io to bogaty w funkcje pakiet narzędzi do eksploracji danych, który wykonuje za Ciebie większość ciężkiej pracy. Ma kilka interesujących funkcji, w tym „Co się zmieniło?” raporty, które mogą powiadamiać Cię o aktualizacjach określonych witryn — idealne do dogłębnej analizy konkurencji.
W jaki sposób marketerzy korzystają ze scrapingu danych?
Jak już się zorientowałeś, zbieranie danych może się przydać niemal wszędzie, gdzie używane są informacje. Oto kilka kluczowych przykładów wykorzystania technologii przez marketerów:
Zbieranie różnych danych
Jedną z wielkich zalet scrapingu danych, mówi Marcin Rosiński, dyrektor generalny FeedOptimise, jest to, że może pomóc zebrać różne dane w jednym miejscu. „Crawling pozwala nam zebrać nieustrukturyzowane, rozproszone dane z wielu źródeł i zebrać je w jednym miejscu i ustrukturyzować” – mówi Marcin. „Jeśli masz wiele witryn kontrolowanych przez różne podmioty, możesz połączyć to wszystko w jeden kanał.
„Sekwencja przypadków użycia jest nieskończona”.
FeedOptimise oferuje szeroką gamę usług pobierania danych i dostarczania danych, o których można dowiedzieć się na ich stronie internetowej.

Przyspieszenie badań
Najprostszym zastosowaniem do scrapingu danych jest pobieranie danych z jednego źródła. Jeśli istnieje strona internetowa, która zawiera wiele danych, które mogą być dla Ciebie przydatne, najłatwiejszym sposobem uzyskania tych informacji na komputerze w uporządkowanym formacie będzie prawdopodobnie pobieranie danych.
Spróbuj znaleźć listę przydatnych kontaktów na Twitterze i zaimportuj dane za pomocą skrobania danych. To da Ci przedsmak tego, jak ten proces może wpasować się w Twoją codzienną pracę.
Wysyłanie pliku XML do witryn stron trzecich
Przesyłanie danych produktów z Twojej witryny do Zakupów Google i innych sprzedawców zewnętrznych to kluczowe zastosowanie pozyskiwania danych w handlu elektronicznym. Pozwala zautomatyzować potencjalnie żmudny proces aktualizacji danych produktów – co jest kluczowe, jeśli Twoje zapasy często się zmieniają.
„Scraping danych może wyprowadzić Twój kanał XML dla Zakupów Google” — mówi dyrektor marketingu Target Internet, Ciaran Rogers. „Pracowałem z wieloma sprzedawcami internetowymi, którzy nieustannie dodawali nowe SKU do swojej witryny, gdy produkty pojawiały się w magazynie. Jeśli Twoje rozwiązanie handlu elektronicznego nie generuje odpowiedniego pliku danych XML, który możesz podłączyć do swojego Centrum Sprzedawcy Google, aby reklamować swoje najlepsze produkty, które mogą stanowić problem. Często Twoje najnowsze produkty są potencjalnie najlepiej sprzedającymi się produktami, więc chcesz, aby były reklamowane, gdy tylko zostaną udostępnione. Użyłem zbierania danych do tworzenia aktualnych wykazów, które będą przesyłane do Google Merchant Center. To świetne rozwiązanie, a tak naprawdę jest tak wiele, które możesz zrobić z danymi, gdy już je zdobędziesz. Korzystając z pliku danych, możesz codziennie oznaczać produkty o najlepszej konwersji, aby udostępniać te informacje Google Adwords i zapewnić bardziej konkurencyjne stawki na te produkty. Po skonfigurowaniu wszystko jest całkowicie zautomatyzowane. Elastyczność dobrego kanału, nad którym masz kontrolę, jest świetna i może prowadzić do bardzo wyraźnych ulepszeń w tych kampaniach, które klienci uwielbiają”.
Istnieje możliwość samodzielnego skonfigurowania prostego pliku danych w Google Merchant Center. Oto jak to się robi:
Jak skonfigurować plik danych do Google Merchant Center
Korzystając z jednej z opisanych wcześniej technik lub narzędzi, utwórz plik, który wykorzystuje dynamiczne zapytanie w witrynie do importowania szczegółów produktów wymienionych w witrynie. Ten plik powinien być automatycznie aktualizowany w regularnych odstępach czasu.
Szczegóły powinny być określone w sposób określony tutaj.
- Prześlij ten plik na adres URL chroniony hasłem
- Przejdź do Google Merchant Center i zaloguj się (upewnij się najpierw, że Twoje konto Merchant Center jest prawidłowo skonfigurowane)
- Przejdź do produktów
- Kliknij przycisk plusa
- Wprowadź kraj docelowy i utwórz nazwę pliku danych
- Wybierz opcję „zaplanowane pobieranie”
- Dodaj adres URL pliku danych produktów wraz z nazwą użytkownika i hasłem wymaganym, aby uzyskać do niego dostęp
- Wybierz częstotliwość pobierania, która najlepiej pasuje do Twojego harmonogramu przesyłania produktów
- Kliknij Zapisz
- Twoje dane produktów powinny być teraz dostępne w Google Merchant Center. Upewnij się tylko, że klikniesz kartę „Diagnostyka”, aby sprawdzić jej stan i upewnić się, że wszystko działa bezproblemowo.
Ciemna strona skrobania danych
Istnieje wiele pozytywnych zastosowań skrobania danych, ale jest on również nadużywany przez niewielką mniejszość.
Najbardziej rozpowszechnionym niewłaściwym wykorzystaniem danych jest zbieranie wiadomości e-mail – zbieranie danych ze stron internetowych, mediów społecznościowych i katalogów w celu odkrycia adresów e-mail innych osób, które są następnie sprzedawane spamerom lub oszustom. W niektórych jurysdykcjach stosowanie zautomatyzowanych środków, takich jak zbieranie danych w celu zbierania adresów e-mail w celach komercyjnych, jest nielegalne i niemal powszechnie uważane za złą praktykę marketingową.
Wielu użytkowników Internetu przyjęło techniki pomagające zmniejszyć ryzyko przechwycenia ich adresu e-mail przez osoby zbierające wiadomości e-mail, w tym:
- Maskowanie adresu: zmiana formatu adresu e-mail podczas publikowania go publicznie, np. wpisując „patrick[at]gmail.com” zamiast „[email protected]”. Jest to łatwe, ale nieco zawodne podejście do ochrony adresu e-mail w mediach społecznościowych – niektóre kombajny będą szukać różnych zamazanych kombinacji, a także wiadomości e-mail w normalnym formacie, więc nie jest to całkowicie szczelne.
- Formularze kontaktowe: korzystanie z formularza kontaktowego zamiast umieszczania swojego adresu e-mail na swojej stronie internetowej.
- Obrazy: jeśli Twój adres e-mail jest prezentowany w formie graficznej na Twojej stronie internetowej, będzie to poza zasięgiem technologicznym większości osób zajmujących się zbieraniem wiadomości e-mail.
Przyszłość w zbieraniu danych
Niezależnie od tego, czy zamierzasz wykorzystywać w swojej pracy data scraping, czy nie, dobrze jest kształcić się w tym temacie, ponieważ w ciągu najbliższych kilku lat prawdopodobnie stanie się jeszcze ważniejszy.
Obecnie na rynku dostępna jest sztuczna inteligencja zgarniająca dane, która może wykorzystywać uczenie maszynowe, aby lepiej rozpoznawać dane wejściowe, które tradycyjnie tylko ludzie potrafili zinterpretować – na przykład obrazy.
Duże usprawnienia w zbieraniu danych z obrazów i filmów będą miały daleko idące konsekwencje dla marketerów cyfrowych. Ponieważ scraping obrazu staje się bardziej dogłębny, będziemy mogli dowiedzieć się znacznie więcej o obrazach online, zanim sami je zobaczymy – a to, podobnie jak scraping danych tekstowych, pomoże nam zrobić wiele rzeczy lepiej.
Jest też największy skrobak danych ze wszystkich – Google. Całe doświadczenie wyszukiwania w Internecie ulegnie zmianie, gdy Google będzie w stanie dokładnie wywnioskować tyle samo z obrazu, co ze strony kopii – a to podwójnie z perspektywy marketingu cyfrowego.
Jeśli masz jakiekolwiek wątpliwości, czy może się to zdarzyć w najbliższej przyszłości, wypróbuj interfejs API interpretacji obrazów Google, Cloud Vision, i daj nam znać, co myślisz. zdobądź darmowe członkostwo już teraz - absolutnie nie potrzebujesz karty kredytowej
DARMOWE CZŁONKOSTWO 