
[Webinar Digest] SEO na Orbicie: Nowe spojrzenie na duplikowanie treści
Opublikowany: 2019-11-20Seminarium internetowe „Nowe perspektywy na duplikaty treści” to ostatni odcinek serii SEO in Orbit, który zostanie wyemitowany 24 czerwca 2019 r. W tym odcinku dołącz do ambasadora OnCrawl, Omi Sido i Alexisa Sandersa, którzy zgłębiają kwestię powielania treści. Zajmują się takimi pytaniami, jak: Jak czynniki rankingowe i ewoluujące technologie wyszukiwania wpływają na sposób, w jaki radzimy sobie z duplikatami treści? Oraz: Jaka przyszłość czeka podobne treści w sieci?
SEO w Orbicie to pierwsza seria webinariów, która wysyła SEO w kosmos. W całej serii omawialiśmy teraźniejszość i przyszłość technicznego SEO z najlepszymi specjalistami SEO, a 27 czerwca 2019 r. wysłaliśmy ich najlepsze wskazówki w kosmos.
Obejrzyj powtórkę tutaj:
Przedstawiamy Alexis Sanders
Alexis Sanders pracuje jako Technical SEO Account Manager w Merkle. Zespół techniczny SEO zapewnia dokładność, wykonalność i skalowalność zaleceń technicznych agencji we wszystkich branżach. Jest współtwórcą bloga Moz i twórcą wyzwania TechnicalSEO.expert oraz podcastu SEO in Lab.
Ten odcinek był prowadzony przez Omi Sido. Omi jest doświadczonym międzynarodowym mówcą i jest znany w branży ze swojego humoru i umiejętności dostarczania praktycznych spostrzeżeń, z których widzowie mogą natychmiast zacząć korzystać. Od konsultacji SEO z niektórymi z największych na świecie firm telekomunikacyjnych i turystycznych po zarządzanie własnym SEO w HostelWorld i Daily Mail, Omi uwielbia zagłębiać się w złożone dane i znajdować jasne punkty. Obecnie Omi zajmuje stanowisko Senior Technical SEO w Canon Europe i jest ambasadorem OnCrawl.
Co to jest zduplikowana treść?
Omi podaje następującą definicję zduplikowanych treści:
Duplikować treści, które są podobne lub prawie podobne do treści znajdujących się pod innym adresem URL w tej samej (lub innej) witrynie internetowej.
Mit o karze za powielanie treści
Nie ma podwójnej kary za treść.
To jest problem z wydajnością. Nie chcemy, aby bot patrzył na dwa konkretne adresy URL i myślał, że są to dwie różne treści, które mogą znajdować się obok siebie w rankingu.
Alexis porównuje zrozumienie twojej strony przez bota do zdjęć Joey'a z 10 rzeczy, których w tobie nienawidzę: bot nie jest w stanie znaleźć istotnej różnicy między tymi dwiema wersjami.

Chcesz uniknąć posiadania dwóch dokładnie takich samych rzeczy, które muszą ze sobą konkurować w sytuacji w rankingu wyszukiwarek. Zamiast tego chcesz mieć jedno, skonsolidowane środowisko, które może pozycjonować i działać w wyszukiwarkach.
Różnica między tym, co widzą użytkownicy i boty
Użytkownik może zobaczyć jeden przekonujący adres URL, ale bot może nadal widzieć wiele wersji, które wyglądają zasadniczo tak samo.
– Wpływ na budżet indeksowania dla bardzo dużej witryny
W przypadku bardzo dużych witryn, takich jak Zillow czy Walmart, budżet indeksowania może się różnić dla różnych stron.
Jak omówiła Alexis w artykule z 2018 roku, opartym na prezentacji Frederica Dubuta na SMX East, budżety są ustalane na różnych poziomach – na poziomach subdomen, na różnych poziomach serwerów. Wyszukiwarki, czy to Google, czy Bing, chcą być grzecznymi robotami; nie chcą spowalniać wydajności rzeczywistych użytkowników. Za każdym razem, gdy wyczują zmianę w wydajności, wycofają się. Może to mieć miejsce na różnych poziomach, nie tylko na poziomie witryny.
Jeśli masz ogromną witrynę, chcesz mieć pewność, że zapewniasz najbardziej skonsolidowane środowisko, które jest odpowiednie dla Twoich użytkowników.
Czy zduplikowana treść jest treścią czy problemem technicznym?
Pomimo słowa „treść” w „zduplikowanej treści”, jest to po części problem techniczny.
– Źródła powielania – [07:50]
Istnieje wiele czynników, które mogą powodować duplikację. Nawet częściowa lista może wydawać się ciągła w nieskończoność:
- Powtarzające się strony
- Witryny inscenizacyjne
- URL-e HTTP vs HTTPS
- Różne subdomeny
- Różne przypadki
- Różne rozszerzenia plików
- Ukośnik na końcu
- Strony indeksowe
- Parametry adresu URL
- Fasety
- Sortuje
- Wersja do druku
- Strona przejścia
- Spis
- Treść syndykowana
- Komunikaty PR
- Ponowne publikowanie treści
- Plagiatowane treści
- Zlokalizowane treści
- Cienka zawartość
- Tylko-obrazy
- Wyszukiwanie w witrynie wewnętrznej
- Oddzielna witryna mobilna
- Nieunikalna treść
- …
– Podział problemów pomiędzy SEO techniczne a treścią
W rzeczywistości te źródła zduplikowanych treści można podzielić na źródła techniczne i deweloperskie oraz źródła oparte na treści, a niektóre z nich znajdują się w nakładającej się strefie między nimi.
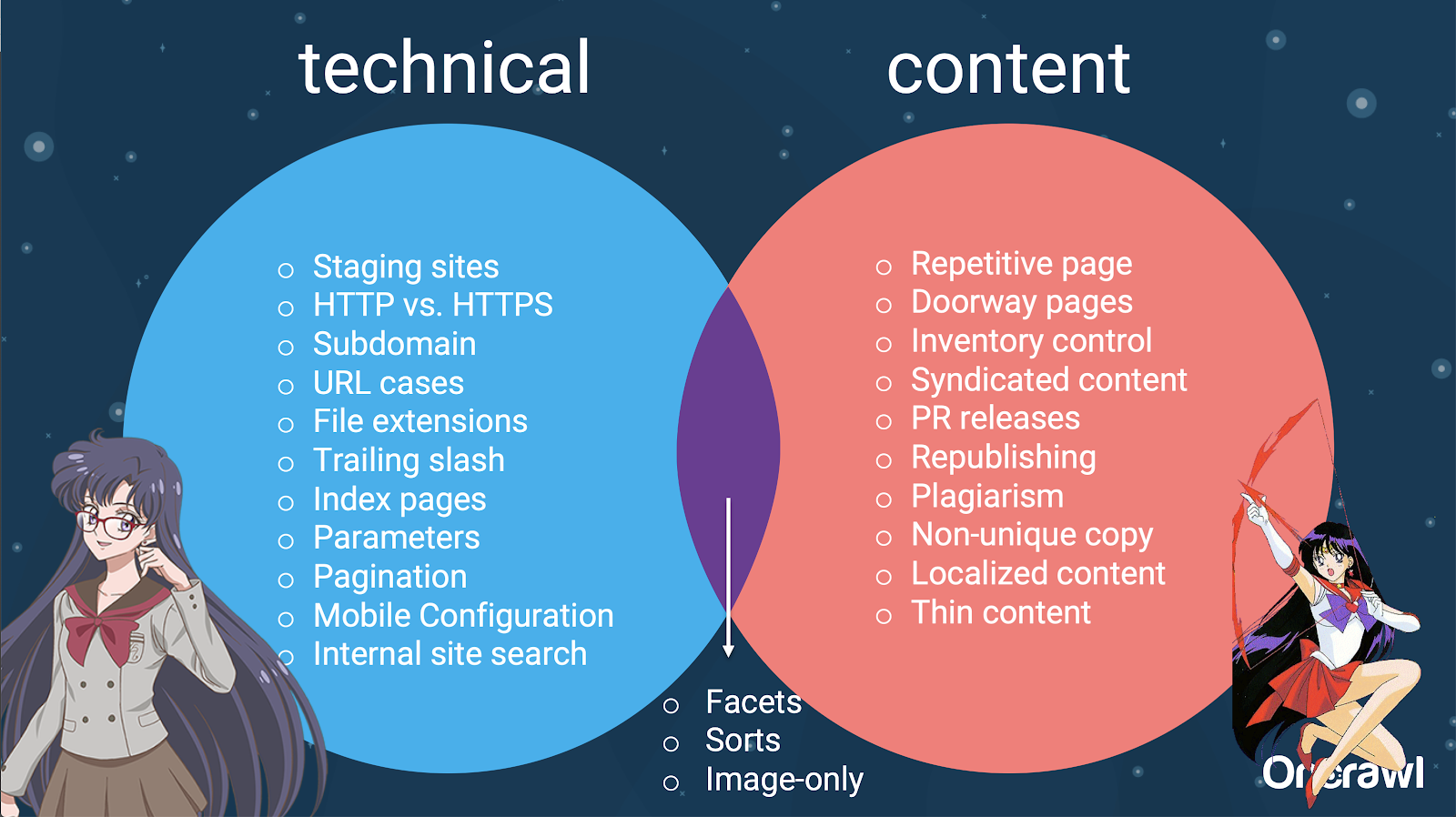
To sprawia, że zduplikowana treść jest problemem między zespołami, co jest częścią tego, co czyni ją tak interesującą.
Jak znaleźć duplikaty treści
Większość zduplikowanych treści jest niezamierzona. W przypadku firmy Omi oznacza to wspólną odpowiedzialność zespołów ds. treści i zespołów technicznych za znajdowanie i naprawianie zduplikowanych treści.
– Ulubione narzędzie Omi: Grammarly
Grammarly jest ulubionym narzędziem Omi do wyszukiwania duplikatów treści – i nie jest to nawet narzędzie SEO. Używa narzędzia do sprawdzania plagiatu. Prosi wydawcę treści, aby sprawdził, czy nowy fragment treści został już opublikowany w innym miejscu.
– Ilość niezamierzonych duplikatów treści
Inżynierowie doskonale znają problem niezamierzonego powielania treści. W książce Wprowadzenie do pobierania informacji (2008), która jest wyraźnie przestarzała, oszacowali, że około 40% sieci w tamtym czasie było zduplikowanych.

– Ustalanie priorytetów strategii radzenia sobie z duplikatami treści
Aby poradzić sobie z duplikatami treści, powinieneś:
- Zacznij od poznania swojej podróży użytkownika, która pomoże Ci zrozumieć, gdzie pasuje każdy element treści. Może to być niezwykle trudne, zwłaszcza gdy strony internetowe powstały 20 lat temu, kiedy nie wiedzieliśmy, jak duże staną się lub jak będą się skalować. Wiedza o tym, gdzie znajduje się Twój użytkownik w dowolnym momencie swojej podróży, pomoże Ci ustalić priorytety w niektórych kolejnych krokach.
- Będziesz potrzebować działającej hierarchii, aby zapewnić miejsce dla każdego rodzaju treści. Zrozumienie architektury informacji znajduje się naprawdę wysoko na etapie radzenia sobie z duplikatami treści.
- Nadaj priorytet zduplikowanej treści, która wpływa na wydajność. Powyższa częściowa lista źródeł jest zbyt długa, aby mogła być realistycznie zaatakowana za jednym razem.
- Zajmij się 100% duplikacją
- Sygnał zduplikowanej treści
- Dokonaj strategicznego wyboru sposobu postępowania z duplikacją: konsolidacja, tworzenie, usuwanie, optymalizacja
- Zajmij się skradzionymi treściami

– Narzędzia: Używanie segmentacji w OnCrawl
Alexis bardzo lubi możliwość segmentacji Twojej witryny w OnCrawl, co pozwala Ci zagłębić się w rzeczy, które mają dla Ciebie znaczenie.
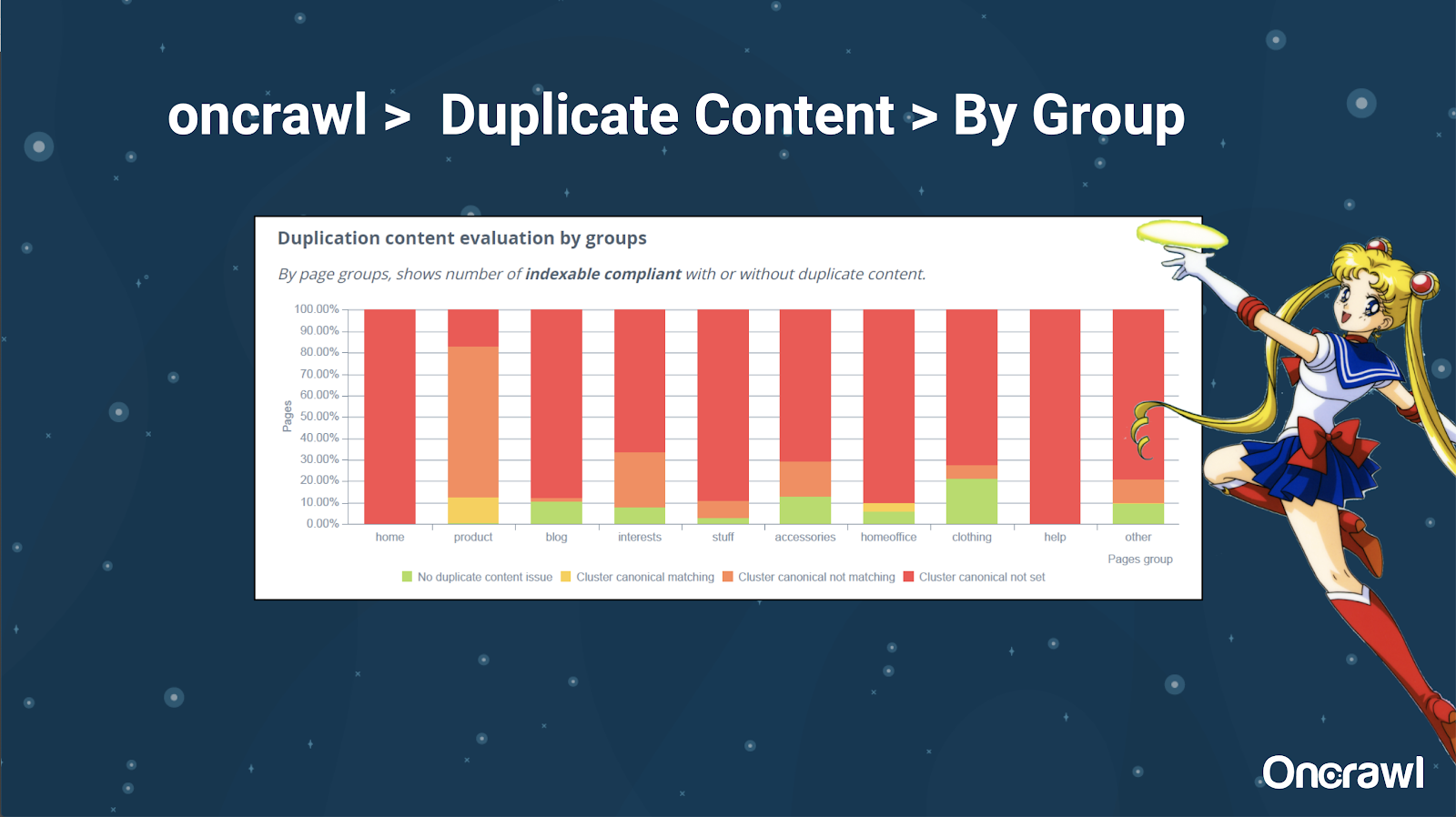
Strony różnych typów mają różne ilości duplikatów; pozwala to uzyskać widok sekcji, które mają najwięcej problemów. W powyższym przykładzie witryna wymaga dużo uwagi.
– Narzędzia: wyszukiwarka Google i GSC
Możesz także sprawdzić duplikaty treści za pomocą samej wyszukiwarki. W Google możesz:
- Użyj bezpośrednich cytatów
- Użyj witryny: wyszukiwania
- Korzystanie z dodatkowych operatorów, takich jak inurl:, intitle: lub filetype:

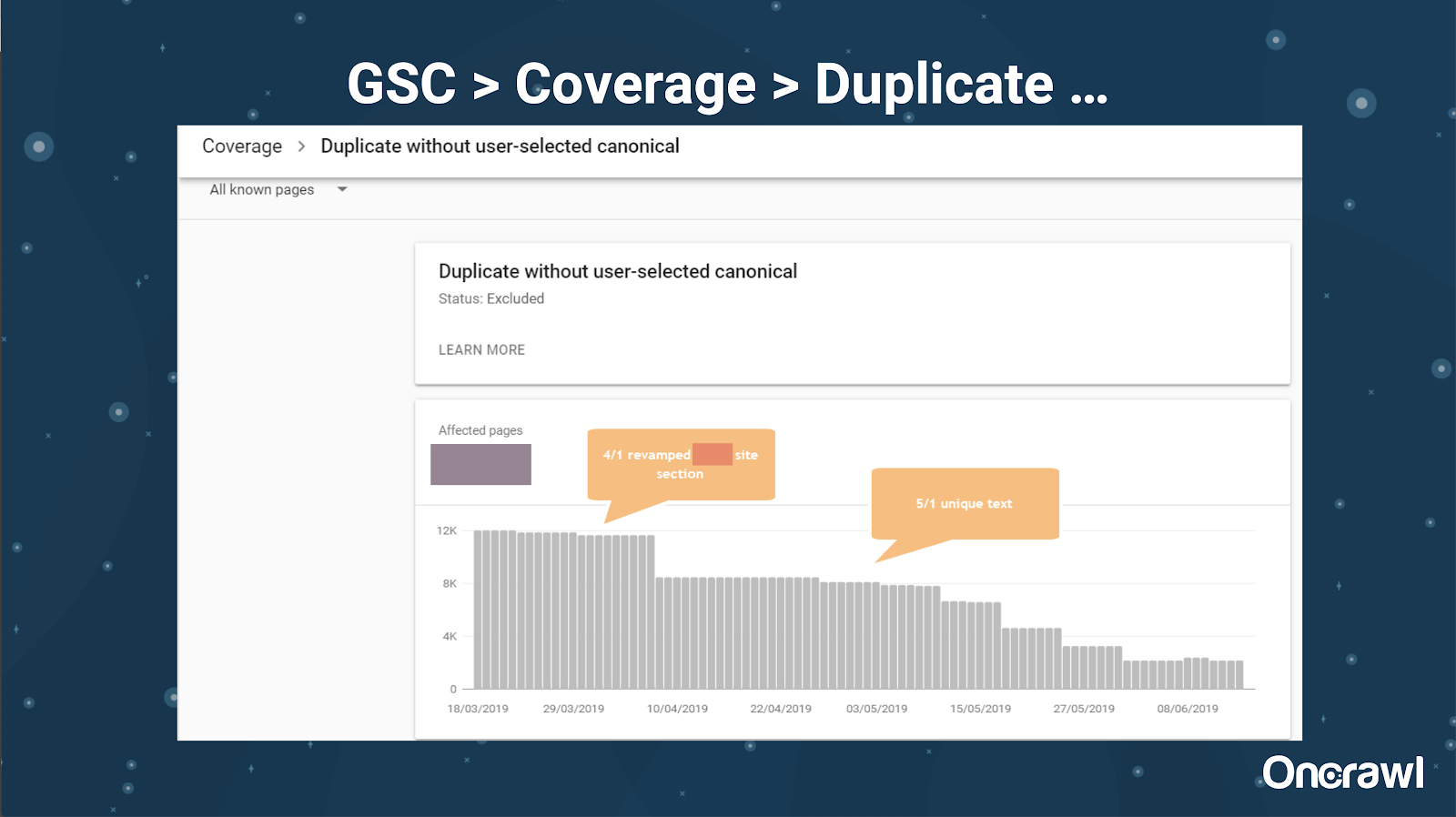
Google Search Console dodał również raport o zduplikowanych treściach, który jest bardzo przydatny w identyfikowaniu tego, co Google uważa za zduplikowane treści z ich strony.
– Narzędzia: narzędzia do plagiatu
Podobnie jak Omi, Alexis używa również różnych narzędzi do plagiatu:
Quetext
Noplag
PaperRater
Gramatyka
CopyScape
Chcesz mieć pewność, że Twoje treści są nie tylko oryginalne, ale także z perspektywy bota, aby nie były postrzegane jako pochodzące z innego źródła.
Mogą również pomóc Ci znaleźć segmenty w artykule, które mogą być podobne do treści w innych miejscach w Internecie.
Alexis uwielbia to, jak mamy te narzędzia, które pozwalają nam być „empatycznymi w stosunku do robotów wyszukiwarek”, ponieważ nikt z nas nie jest robotem. Gdy narzędzia dają nam sygnały, że treść jest zbyt podobna, nawet jeśli wiemy, że istnieje różnica, to dobry znak, że jest coś, w co można się zagłębić.

– Narzędzia: Narzędzia gęstości słów kluczowych
Dwa przykłady narzędzi do zagęszczania słów kluczowych, z których korzysta Alexis, to:
TagCrowd
SEObook
Problemy zależne od rodzaju strony
Rozwiązanie problemu zduplikowanych treści naprawdę zależy od rodzaju publikowanej treści i rodzaju napotkanego problemu. Na przykład blogi nie spotykają się z takimi samymi przypadkami powielania treści, jak witryny e-commerce.
Pamiętne przypadki
Alexis dzieli się ostatnimi przypadkami klientów, w których znalazła pamiętne problemy z duplikacją treści.
– Ogromnie duża witryna: wyniki po dodaniu unikalnych treści
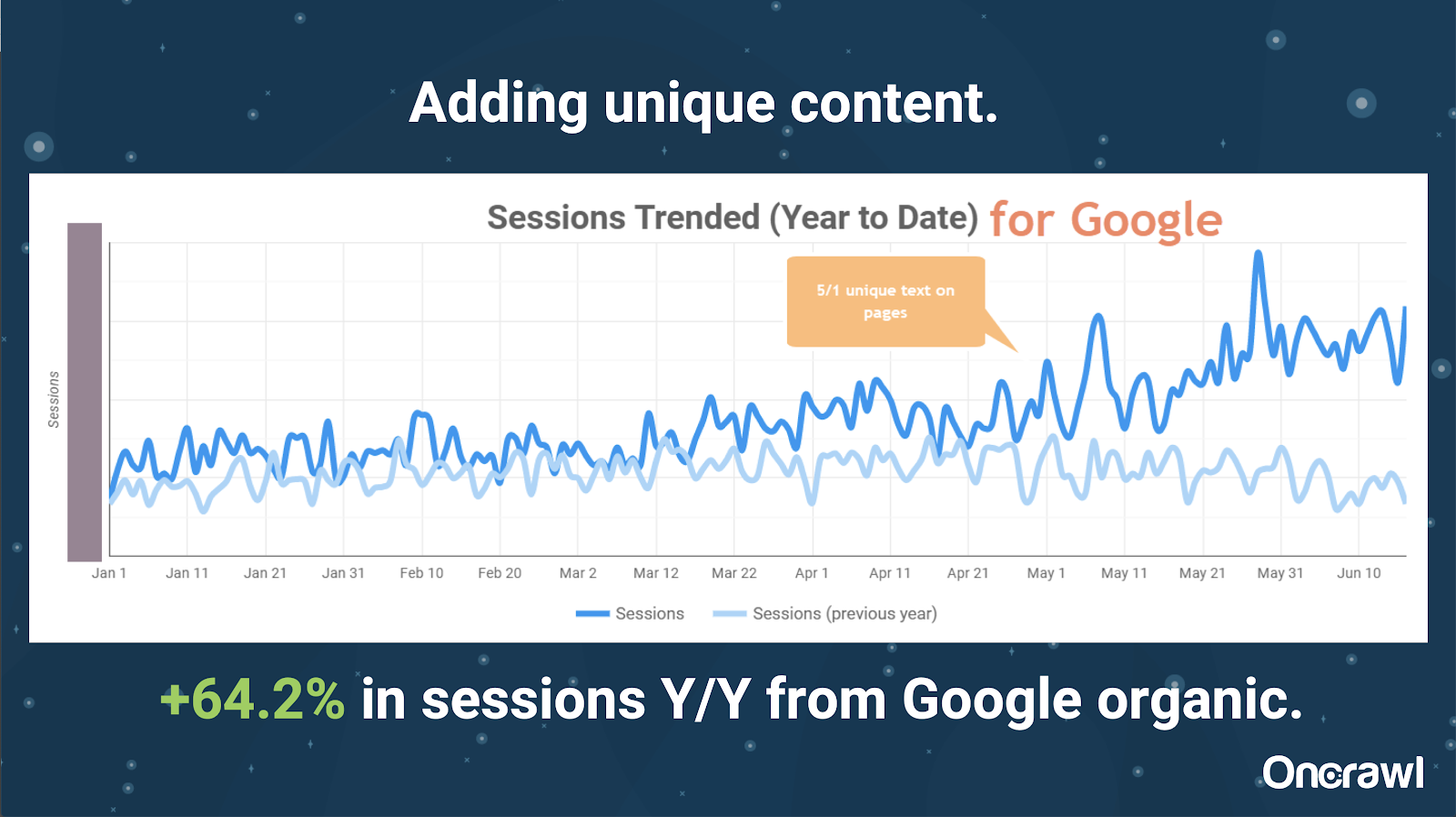
Ta witryna była bardzo duża i napotykała problemy z budżetem indeksowania. Ma 86 milionów stron, które nie zostały jeszcze zindeksowane, a zindeksowano tylko około 1% jego stron.
To jest witryna z nieruchomościami, więc wiele treści nie jest szczególnie unikatowe, a wiele ich stron jest bardzo, bardzo podobnych. Alexis zakończyła dodanie treści do strony, aby dodać informacje specyficzne dla lokalizacji, aby odróżnić strony. Zaskakujące było, jak szybko przyniosło to rezultaty. (To tylko organiczne dane Google).
Dla Alexis jest to dość ogólne studium przypadku. Tak długo, jak mówimy dzisiaj o EAT i podobnych rzeczach, pokazuje to, że gdy tylko wyszukiwarki postrzegają treści jako wyjątkowe i wartościowe, wciąż jest to nagradzane.

W tej witrynie przypadkowy problem z tagiem kanonicznym spowodował, że około 250 stron zostało wysłanych do niewłaściwego protokołu.
Jest to jeden przypadek, w którym znaczniki kanoniczne wskazywały niewłaściwą stronę główną, przesuwając strony HTTP w miejsce strony HTTPS.
Zmiany w ciągu ostatnich 18 miesięcy
Alexis napisała bardzo kompletny artykuł, Powiel treści i rozwiązania strategiczne, około 18 miesięcy przed tym webinarium. Pozycjonowanie zmienia się szybko i musisz stale odnawiać i ponownie oceniać swoją wiedzę.
Dla Alexis większość tego, co zostało wspomniane w artykule, jest nadal aktualne, z wyjątkiem rel=next/prev. Ma jednak nadzieję, że w ciągu najbliższych pięciu do dziesięciu lat przestanie mieć znaczenie.
Problemy techniczne obsługiwane przez programistów: zbyt ręczne
Wiele problemów związanych ze zduplikowaną zawartością, którą zajmują się programiści, jest zbyt ręcznych. Alexis uważa, że zamiast tego powinny być obsługiwane przez systemy CMS i Adobe. Na przykład nie powinieneś przechodzić ręcznie i upewnić się, że wszystkie kanoniczne są ustawione i spójne.
– Możliwości automatyzacji/powiadomień
Istnieje wiele możliwości automatyzacji w obszarze problemów technicznych ze zduplikowaną treścią. Na przykład: powinniśmy być w stanie natychmiast wykryć, czy jakieś linki przechodzą na HTTP, podczas gdy powinny iść na HTTPS, i je poprawić.
– Wiek witryny i starsza infrastruktura jako przeszkoda
Niektóre systemy zaplecza są zbyt stare, aby obsługiwać pewne zmiany i automatyzacje. Migracja starego systemu CMS do nowego jest niezwykle trudna. Omi podaje przykład migracji witryn firmy Canon do nowego, niestandardowego systemu CMS. To było nie tylko drogie, ale zajęło im 12 miesięcy.
Rel prev/next i komunikacja od Google
Czasami komunikacja z Google jest nieco zagmatwana. Omi przytacza przykład, w którym stosując rel=prev/next, jego klient zauważył znaczny wzrost wydajności w 2018 roku, pomimo ogłoszenia Google z 2019 roku, że te tagi nie były używane od lat.
– Brak uniwersalnych rozwiązań
Problem z SEO polega na tym, że to, co jedna osoba obserwuje na swojej stronie internetowej, niekoniecznie jest tym samym, co inny SEO widzi na swojej własnej stronie internetowej; nie ma jednego uniwersalnego SEO.
Zdolność Google do publikowania ogłoszeń, które są istotne dla wszystkich SEO, należy uznać za duży wyczyn, nawet niektóre z ich wypowiedzi są chybione, jak w przypadku rel=next/prev.
Nadzieje na przyszłość zarządzania duplikatami treści
Nadzieje Alexis na przyszłość:
- Mniej zduplikowanych treści technicznych (w miarę rozwoju systemów CMS).
- Więcej automatyzacji (testy jednostkowe i testy zewnętrzne). Na przykład narzędzia takie jak OnCrawl mogą regularnie indeksować Twoją witrynę i powiadamiać Cię, gdy tylko zauważą określone błędy.
- Automatycznie wykrywaj strony o wysokim podobieństwie i typy stron dla autorów i menedżerów treści. To zautomatyzowałoby niektóre weryfikacje, które są obecnie wykonywane ręcznie w narzędziach takich jak Grammarly: gdy ktoś próbuje opublikować, CMS powinien powiedzieć „to jest trochę podobne – czy na pewno chcesz to opublikować?” Patrzenie na pojedyncze strony internetowe, a także na porównanie między stronami ma dużą wartość.
- Google nadal ulepsza swoje istniejące systemy i wykrywanie.
- Być może system ostrzegania, aby eskalować problem Google, który nie używa odpowiedniego kanonicznego. Przydałaby się możliwość powiadomienia Google o problemie i jego rozwiązania.
Potrzebujemy lepszych narzędzi, lepszych narzędzi wewnętrznych, ale miejmy nadzieję, że w miarę rozwoju swoich systemów Google doda elementy, które trochę nam pomogą.
Ulubione sztuczki techniczne Alexis
Alexis ma kilka ulubionych sztuczek technicznych:
- Zdalna instancja komputera EC2. To naprawdę świetny sposób na dostęp do prawdziwego komputera w przypadku bardzo dużych indeksowań lub czegokolwiek, co wymaga dużej mocy obliczeniowej. Po skonfigurowaniu jest niezwykle szybki. Tylko upewnij się, że zakończysz go, gdy skończysz, ponieważ to kosztuje.
- Sprawdź mobilne pierwsze narzędzie testowe. Google wspomniał, że jest to najdokładniejszy obraz tego, na co patrzą. Wygląda na DOM.
- Przełącz klienta użytkownika na Googlebota. Dzięki temu dowiesz się, co naprawdę widzą Googleboty.
- Korzystanie z narzędzia robots.txt na stronie TechnicalSEO.com. Jest to jedno z narzędzi Merkle'a, ale Alexis naprawdę je uwielbia, ponieważ plik robots.txt może być czasami bardzo mylący.
- Użyj analizatora logów.
- Wykonane za pomocą kontrolera htaccess firmy Love.
- Używanie Google Data Studio do raportowania zmian (synchronizowanie Arkuszy z aktualizacjami, filtrowanie każdej strony według odpowiednich aktualizacji).
Techniczne problemy z SEO: robots.txt
Robots.txt jest naprawdę mylący.
Jest to archaiczny plik, który wygląda na to, że powinien obsługiwać RegEx, ale tak nie jest.
Ma różne reguły pierwszeństwa dla reguł odrzucania i zezwalania, które mogą być mylące.
Różne boty mogą ignorować różne rzeczy, nawet jeśli nie powinny.
Twoje założenia dotyczące tego, co jest słuszne, nie zawsze są słuszne.

Pytania i odpowiedzi
– HSTS: czy wymagany jest protokół dzielony?
Musisz mieć cały HTTPS dla duplikatów treści, jeśli masz HSTS.
– Czy przetłumaczona treść jest duplikatem treści?
Często, gdy używasz hreflang, używasz go do rozróżnienia między zlokalizowanymi wersjami w tym samym języku, na przykład amerykańska i irlandzka strona w języku angielskim. Alexis nie brałaby pod uwagę tej zduplikowanej treści, ale zdecydowanie zaleca upewnienie się, że masz poprawnie skonfigurowane tagi hreflang, aby wskazać, że jest to to samo doświadczenie, zoptymalizowane dla różnych odbiorców.
– Czy można używać tagów kanonicznych zamiast przekierowań 301 w przypadku migracji HTTP/HTTPS?
Przydałoby się sprawdzić, co tak naprawdę dzieje się w SERPach. Instynkt Alexis podpowiada, że byłoby to w porządku, ale zależy to od tego, jak faktycznie zachowuje się Google. W idealnym przypadku, jeśli są to dokładnie te same strony, chciałbyś użyć 301, ale widziała, jak kanoniczne tagi działają w przeszłości dla tego typu migracji. Ona nawet widziała, jak to się przypadkowo wydarzyło.
Z doświadczenia Omi wynika, że zdecydowanie sugerowałby używanie 301, aby uniknąć problemów: jeśli przenosisz witrynę, równie dobrze możesz przeprowadzić migrację poprawnie, aby uniknąć obecnych i przyszłych błędów.
– Efekt zduplikowanych tytułów stron
Załóżmy, że masz tytuł, który jest bardzo podobny dla różnych lokalizacji, ale treść jest bardzo różna. Chociaż nie jest to zduplikowana treść dla Alexis, uważa ona, że wyszukiwarki traktują to jako coś „ogólnego”, a tytuły są czymś, co można wykorzystać do zidentyfikowania obszarów z możliwymi problemami.
Tutaj możesz użyć wyszukiwania [site: + intitle: ].
Jednak tylko dlatego, że masz ten sam tag tytułu, nie spowoduje to problemu duplikatów treści.
Nadal powinieneś dążyć do unikalnych tytułów i opisów meta, nawet na stronach z paginacją lub na innych bardzo podobnych stronach. Nie wynika to z powielania treści, ale dotyczy sposobu, w jaki chcesz zoptymalizować sposób prezentacji swoich stron w SERP.
Najlepsza wskazówka
„Powielanie treści to wyzwanie zarówno techniczne, jak i content marketingowe”.
Pozycjonowanie w Orbicie powędrowało w kosmos
Jeśli przegapiłeś naszą podróż w kosmos 27 czerwca, złap ją tutaj i odkryj wszystkie wskazówki, które wysłaliśmy w kosmos.