
Używanie Pythona i map witryn do kontrolowania strategii dotyczących treści
Opublikowany: 2020-10-08Zainteresowanie tym, co można zrobić w imieniu SEO z bibliotekami Pythona, nie jest już tajemnicą. Jednak większość osób z niewielkim doświadczeniem w programowaniu ma trudności z importowaniem i używaniem dużej liczby bibliotek lub wypychaniem, wyniki wykraczają poza to, co może zrobić zwykły robot indeksujący lub narzędzie SEO.
Właśnie dlatego biblioteka Pythona stworzona specjalnie dla SEO, SEM, SMO, SERP check i analizy treści jest przydatna dla każdego.
W tym artykule przyjrzymy się kilku rzeczom, które można zrobić za pomocą biblioteki Advertools Python dla SEO, stworzonej i rozwijanej przez Eliasa Dabbasa, i dla których widzę duży potencjał w SEO, PPC i możliwościach kodowania w bardzo krótkim czasie. Będziemy również używać niestandardowych skryptów Pythona wraz z innymi bibliotekami Pythona w sposób edukacyjny i adaptacyjny.
Zamierzamy zbadać, czego można się nauczyć o SEO z mapy witryny dzięki funkcji sitemap_to_df Eliasa Dabbasa, która pomaga w pobieraniu i analizowaniu map witryn XML (mapa witryny to dokument w formacie XML używany do zgłaszania wyszukiwarek indeksowanych i indeksowanych adresów URL).
Ten artykuł pokaże Ci, jak pisać niestandardowe kody Pythona do analizy różnych stron internetowych zgodnie z ich różną strukturą, jak interpretować dane pod kątem SEO oraz jak myśleć jak wyszukiwarka, jeśli chodzi o profile treści, adresy URL i struktury witryn .
Analiza skali treści i strategii witryny na podstawie mapy witryny
Mapa witryny to element witryny internetowej, który może przechwytywać wiele różnych rodzajów danych, takich jak częstotliwość publikowania treści w witrynie, kategorie treści, daty publikacji, informacje o autorze, temat treści…
W normalnych warunkach możesz zeskrobać mapę witryny za pomocą scrapy, przekonwertować ją na DataFrame za pomocą Pand i, jeśli chcesz, zinterpretować ją za pomocą wielu różnych bibliotek pomocniczych.
Ale w tym artykule użyjemy tylko Advertools i niektórych metod i atrybutów biblioteki Pandas. Niektóre biblioteki zostaną aktywowane w celu wizualizacji zebranych przez nas danych.
Zanurzmy się od razu i wybierzmy witrynę, aby użyć jej mapy witryny, aby uzyskać ważne informacje na temat SEO.
Wyodrębnianie i tworzenie ramek danych z map witryn za pomocą Advertools
W Advertools możesz odkrywać, przeglądać i łączyć wszystkie mapy witryn witryny za pomocą tylko jednego wiersza kodu.
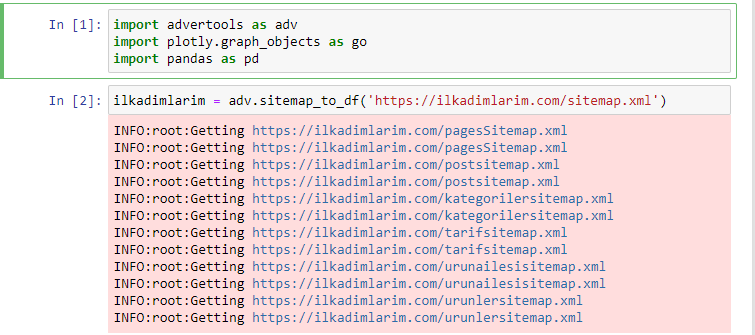
Uwielbiam używać Jupyter Notebook zamiast zwykłego edytora kodu lub IDE.
W pierwszej komórce zaimportowaliśmy Pandy i Advertools do zbierania i organizowania danych oraz Plotly.graph_objects do wizualizacji danych.
Polecenie adv.sitemap_to_df('sitemap address') po prostu zbiera wszystkie mapy witryn i ujednolica je jako DataFrame.
Jeśli zrobisz to samo za pomocą Pand i Advertools, możesz odkryć, który adres URL jest dostępny w danej mapie witryny.
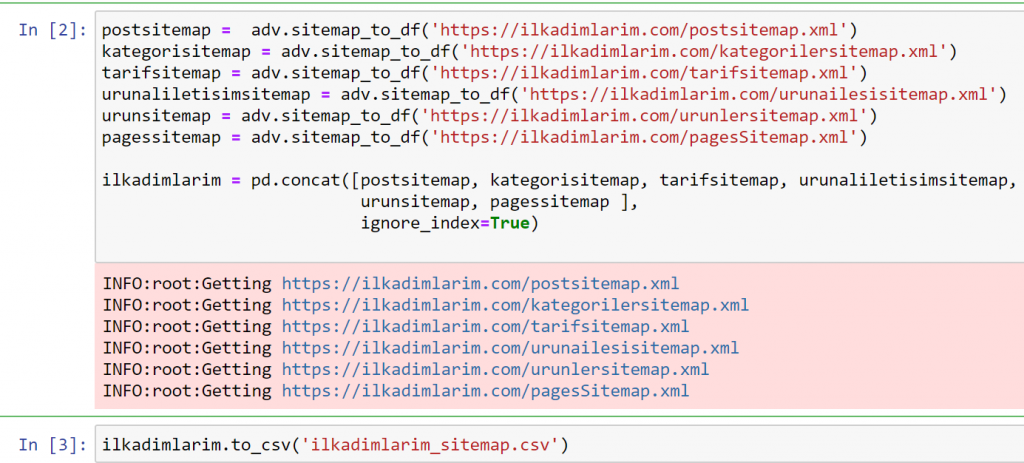
W powyższym przykładzie osobno ściągnęliśmy te same mapy witryn, a następnie połączyliśmy je z poleceniem pd.concat i przenieśliśmy wynik do CSV. W poprzednim przykładzie użyto pliku indeksu map witryn, w którym to przypadku funkcja pobiera wszystkie inne mapy witryn. Masz więc możliwość wybrania określonych map witryn, tak jak my tutaj, jeśli interesuje Cię konkretna sekcja witryny.
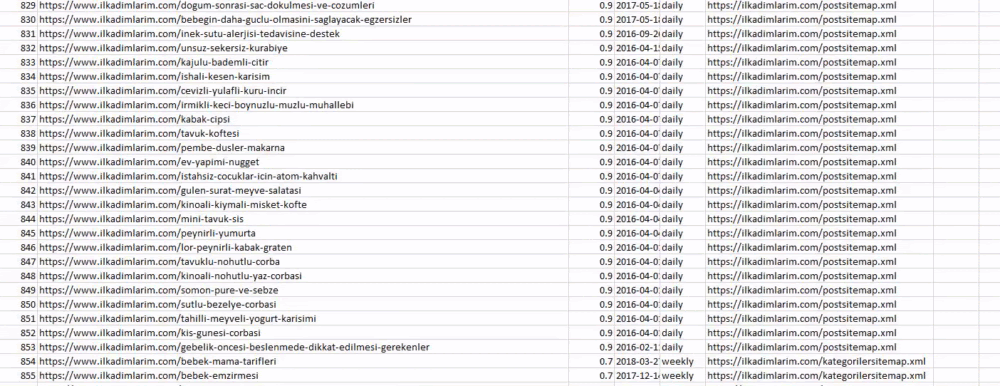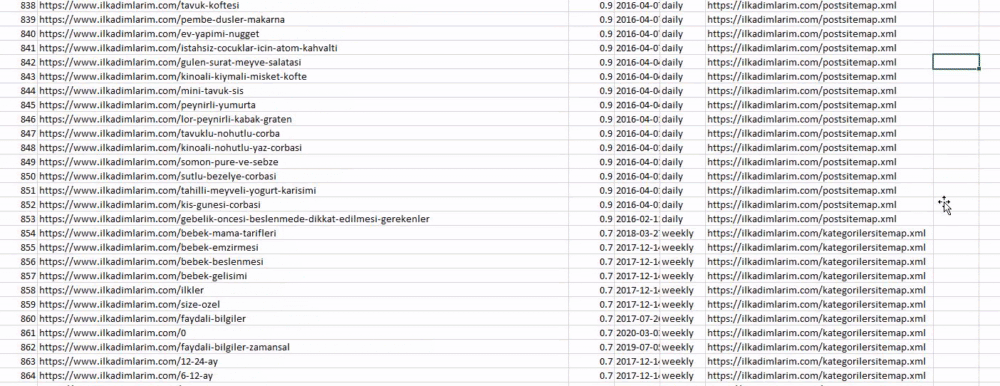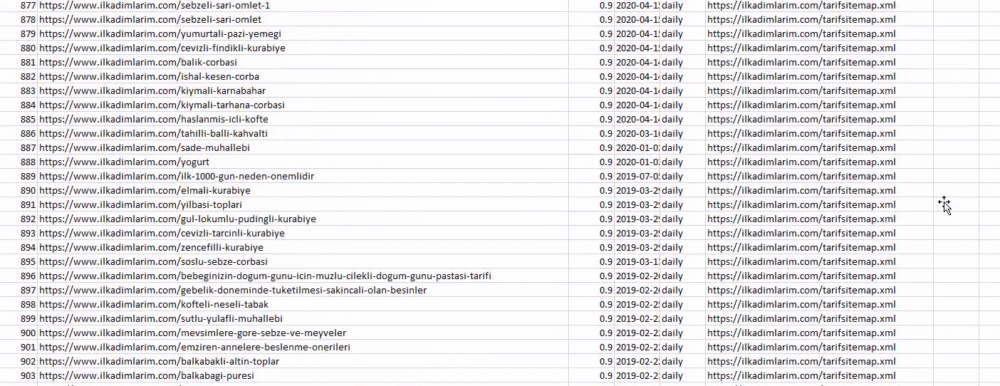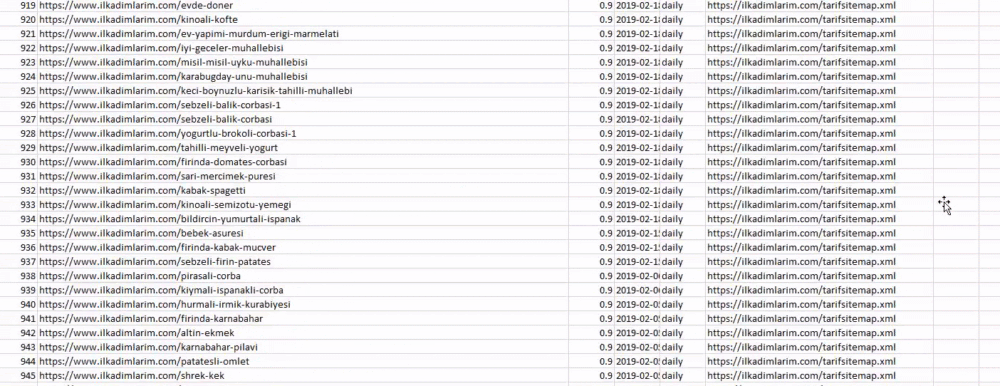
Powyżej możesz zobaczyć kolumnę z różnymi nazwami map witryn. ignore_index=True sekcja służy do uporządkowania numerów indeksów różnych ramek DataFrame, jeśli połączyłeś wiele z nich.
Dane dotyczące indeksowania³
 Ucz się więcej
Ucz się więcejCzyszczenie i przygotowywanie ramki danych mapy witryny do analizy treści w Pythonie
Aby zrozumieć profil treści witryny za pomocą mapy witryny, musimy ją przygotować w celu sprawdzenia ramki DataFrame, którą uzyskaliśmy za pomocą Advertools.
Do kształtowania naszych danych użyjemy kilku podstawowych poleceń z biblioteki Pandy:
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(kolumny = 'Bez nazwy: 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
„Ilkadimlarim” oznacza po turecku „moje pierwsze kroki” i jak możesz sobie wyobrazić, jest to strona poświęcona niemowlętom, ciąży i macierzyństwu.
Na tych liniach wykonaliśmy trzy operacje.
- Bez nazwy: usunęliśmy pustą kolumnę o nazwie 0 z DataFrame. Ponadto, jeśli użyjesz 'index = False ' z funkcją pd.to_csv() , nie zobaczysz kolumny 'Unnamed 0' na początku.
- Przekonwertowaliśmy dane w kolumnie Ostatnia modyfikacja na Data i godzina.
- Przenieśliśmy kolumnę „lastmod” na pozycję indeksu.
Poniżej możesz zobaczyć ostateczną wersję DataFrame.
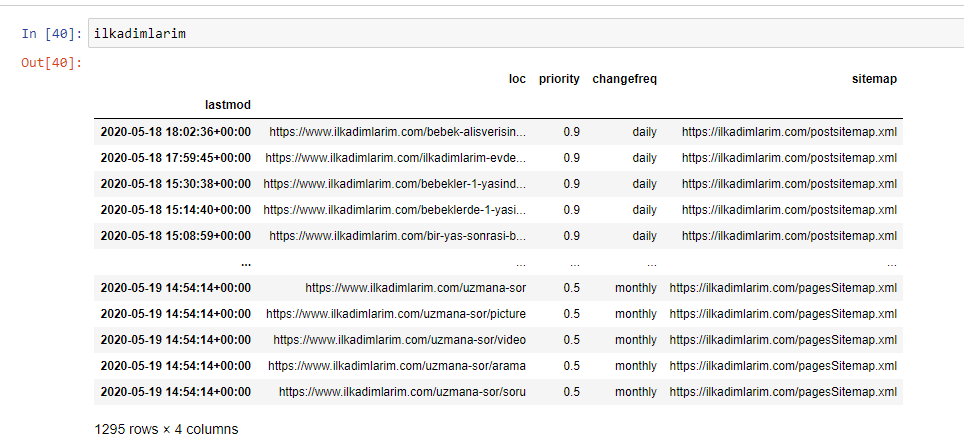
Wiemy, że Google nie używa informacji o priorytetach i częstotliwości zmian z map witryn. Nazywają to „torbą hałasu”. Ale jeśli przywiązujesz wagę do wydajności swojej witryny w innych wyszukiwarkach, przydatne może być również ich zbadanie. Osobiście nie przejmuję się zbytnio tymi danymi, ale nadal nie muszę ich usuwać z DataFrame.
Potrzebujemy jeszcze jednej linii kodu do kategoryzacji map witryn w innej kolumnie.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
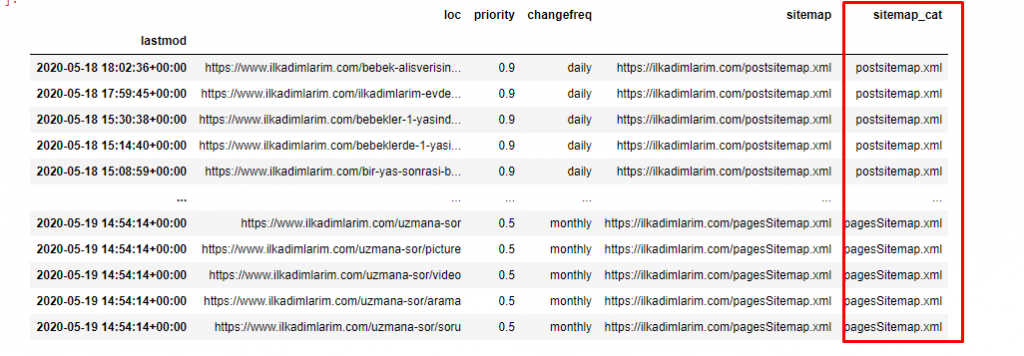
W Pandas możesz dodawać nowe kolumny lub wiersze do DataFrame lub możesz je łatwo aktualizować. Utworzyliśmy nową kolumnę z fragmentem kodu DataFrame['new_columns'] . DataFrame['nazwa_kolumny'].str umożliwia nam wykonywanie różnych operacji poprzez zmianę typu danych w kolumnie. Dane ciągu w kolumnie związanej z .split ('/') dzielimy przez znak / i umieszczamy na liście. Za pomocą .str [liczba] tworzymy zawartość nowej kolumny, wybierając konkretny element z tej listy.
Analiza profilu treści według liczby i rodzajów map witryn
Po umieszczeniu map witryn w innej kolumnie według ich typów, możemy sprawdzić, jaki % treści znajduje się w każdej mapie witryny. W ten sposób możemy również wnioskować, która część serwisu jest ważniejsza.
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name'] wybiera kolumnę, którą chcemy wykonać.
- value_counts() zlicza częstotliwość wartości w kolumnie.
- normalize=True przyjmuje stosunek wartości dziesiętnych.
- Ułatwiamy czytanie, powiększając liczby dziesiętne o *100.
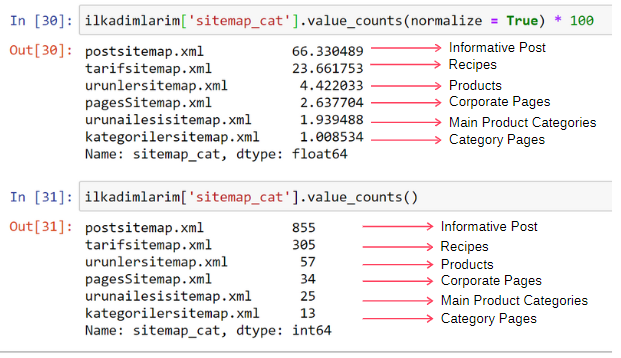
Widzimy, że 65% treści znajduje się w mapie witryny postów, a 23% w mapie witryny z przepisami. Mapa witryny produktu ma tylko 2% treści.
To pokazuje, że mamy stronę internetową, która musi tworzyć treści informacyjne dla szerokiego grona odbiorców, aby sprzedawać własne produkty. Sprawdźmy, czy nasza teza jest poprawna.
Zanim przejdziemy dalej, musimy zmienić nazwę kolumny ilkadimlarim['sitemap_cat'] na 'URL_Count' za pomocą poniższego kodu:
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- Funkcja rename() jest przydatna do modyfikowania nazw kolumn lub indeksów w celu połączenia danych i ich znaczenia na głębszym poziomie.
- Zmieniliśmy nazwę kolumny na stałą dzięki atrybutowi 'inplace=True' .
- Możesz również zmienić style liter w kolumnach i indeksach za pomocą ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) . To zapisuje tylko pierwsze litery każdej kolumny w Ilkadimlarim pisane wielkimi literami.

Teraz możemy kontynuować.
Aby zobaczyć te informacje w jednej ramce, możesz użyć poniższego kodu:
(ilkadimlarim['sitemap_cat']
.liczba_wartości()
.do_ramki()
.assign(percentage=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', percent='{:.1%}')))
- to_frame() służy do wyświetlania w ramkach wartości mierzonych przez value_counts() w wybranej kolumnie.
- assign() służy do dodawania pewnych wartości do ramki.
- lambda odnosi się do funkcji anonimowych w Pythonie.
- W tym przypadku funkcja Lambda i typy map witryn są podzielone przez całkowitą liczbę map witryn za pomocą metody Pandas div() .
- style() określa sposób zapisu określonych wartości końcowych.
- Tutaj ustalamy, ile cyfr jest zapisywanych po kropce za pomocą metody format() .
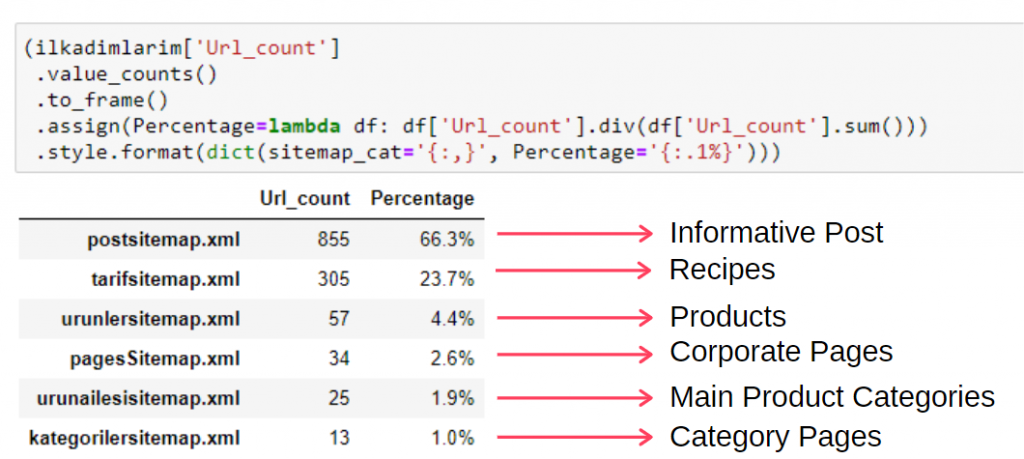
Dlatego dostrzegamy znaczenie marketingu treści dla tej witryny. Możemy również sprawdzić trendy publikowania ich artykułów z roku na rok za pomocą dwóch pojedynczych linijek kodu, aby dokładniej zbadać ich sytuację.
Badanie i wizualizacja trendów publikowania treści według roku za pomocą map witryn i języka Python
Dokonaliśmy dopasowania treści i intencji badanej strony według kategorii mapy witryny, ale nie dokonaliśmy jeszcze klasyfikacji czasowej. W tym celu użyjemy metody resample() .
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample to metoda z biblioteki Pandas. resample('A') sprawdza serię danych pod kątem rocznej ramki DataFrame. Tygodniami możesz używać „W”, a miesiącami możesz używać „M”.
Loc tutaj symbolizuje indeks; count oznacza, że chcesz policzyć sumę przykładowych danych.
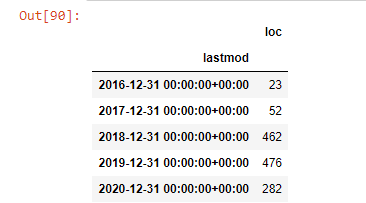
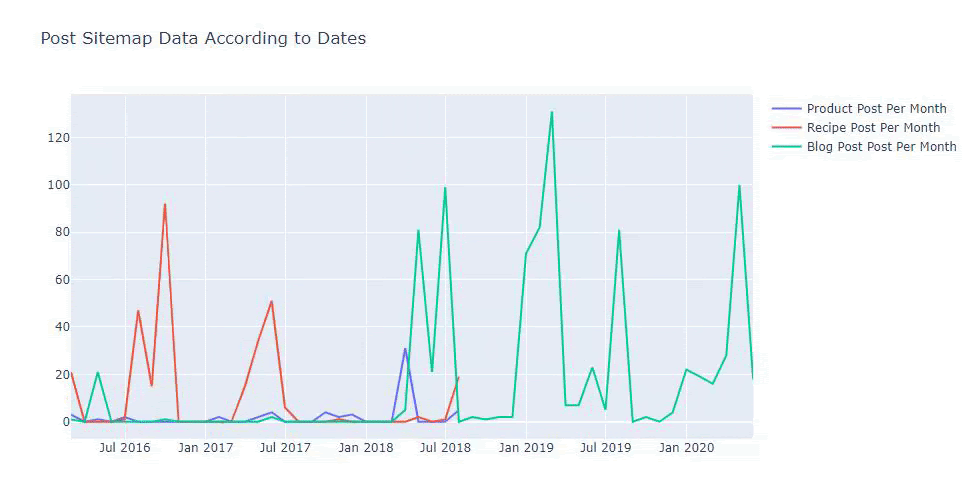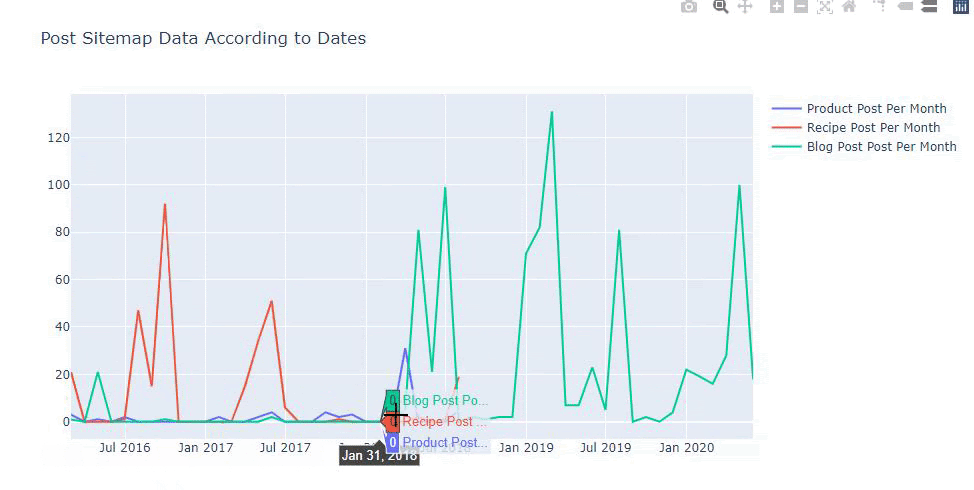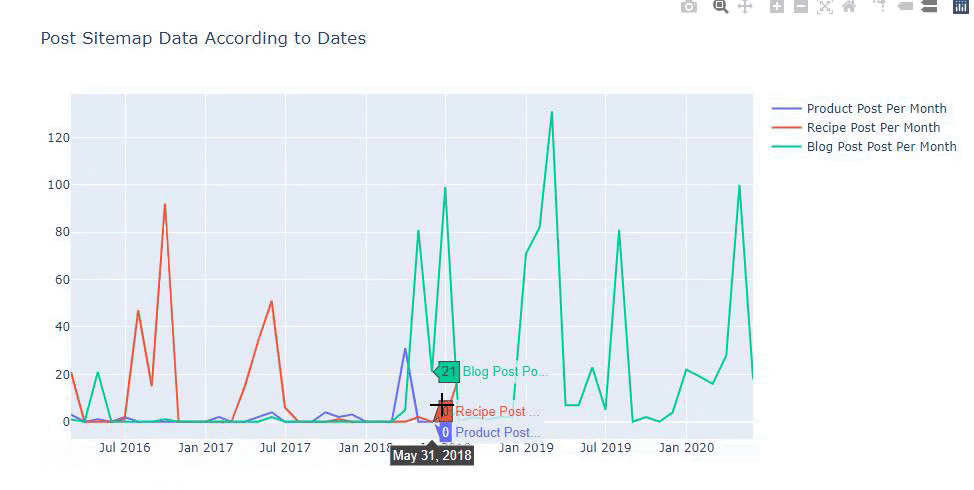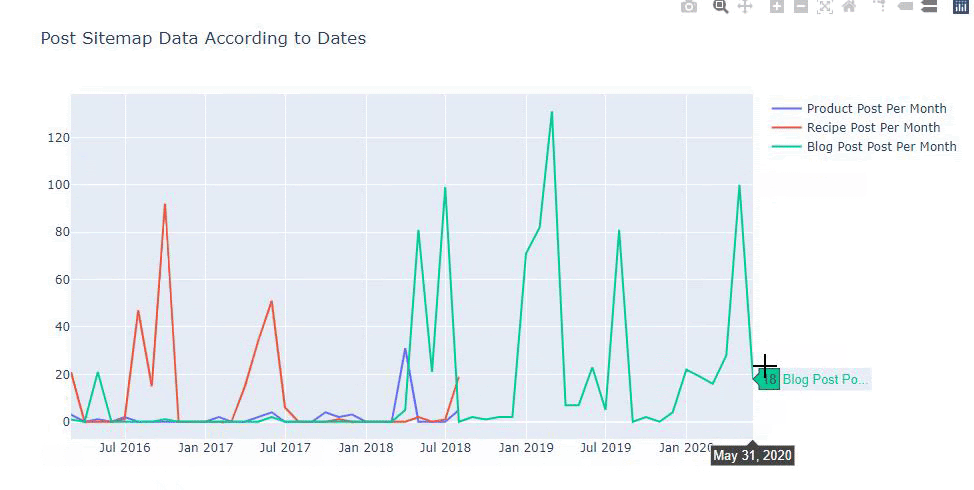
Widzimy, że zaczęli publikować artykuły w 2016 roku, ale ich główny trend wydawniczy wzrósł po 2017 roku. Możemy to również umieścić w grafice za pomocą Plotly Graph Objects.
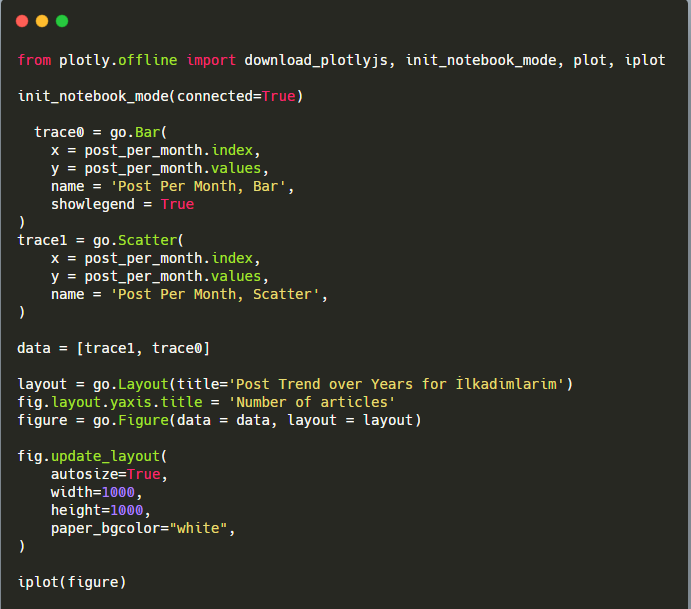
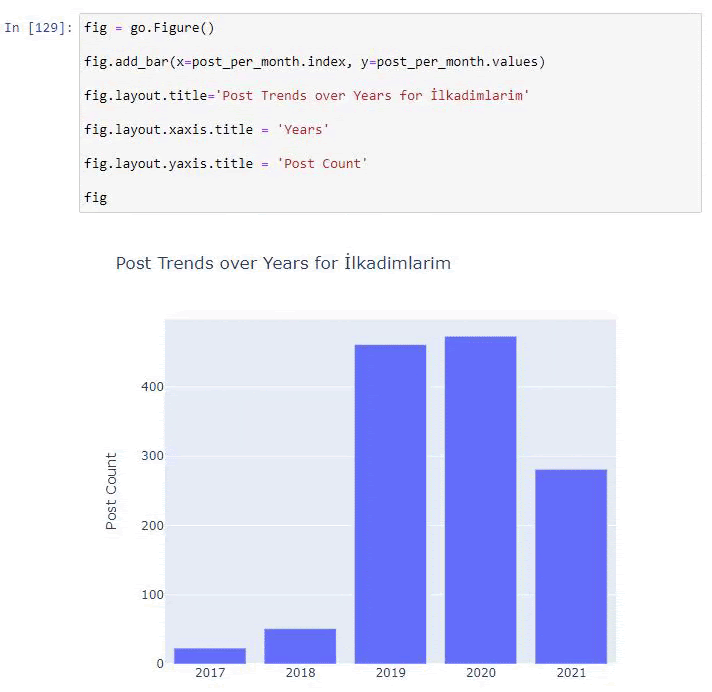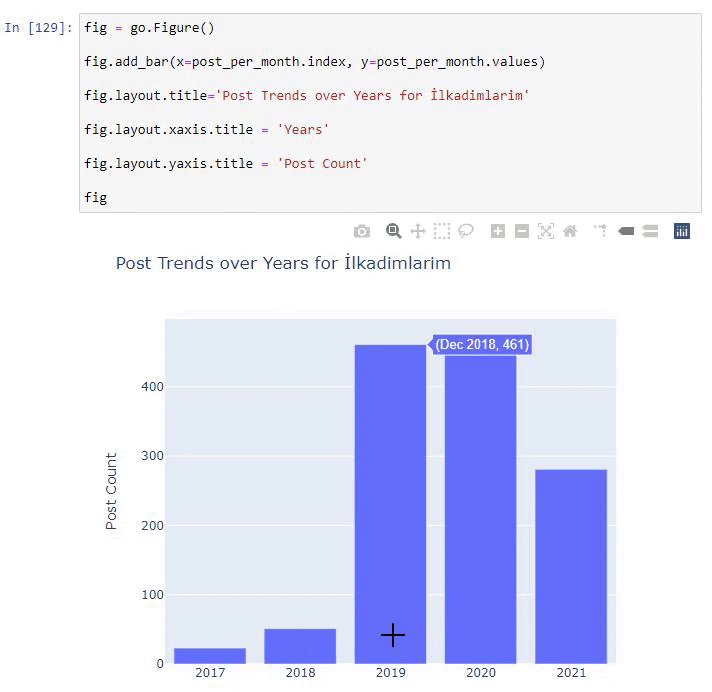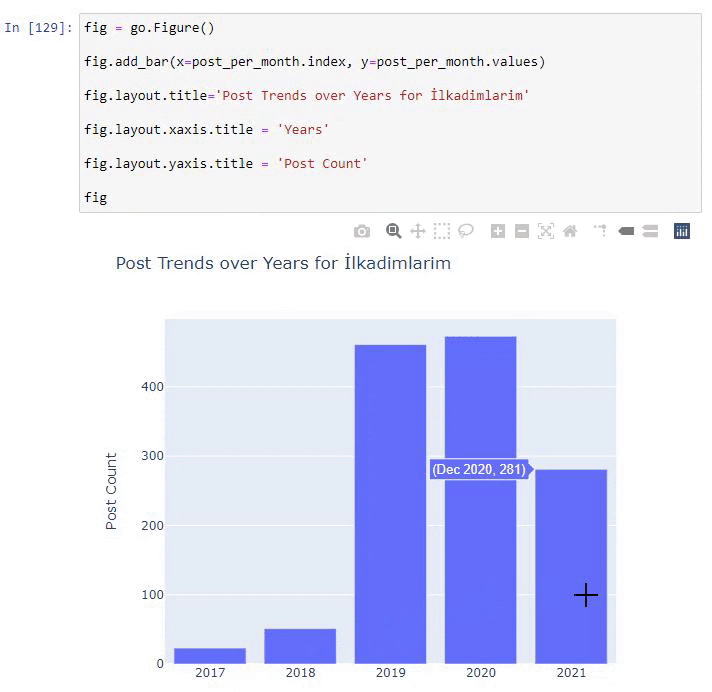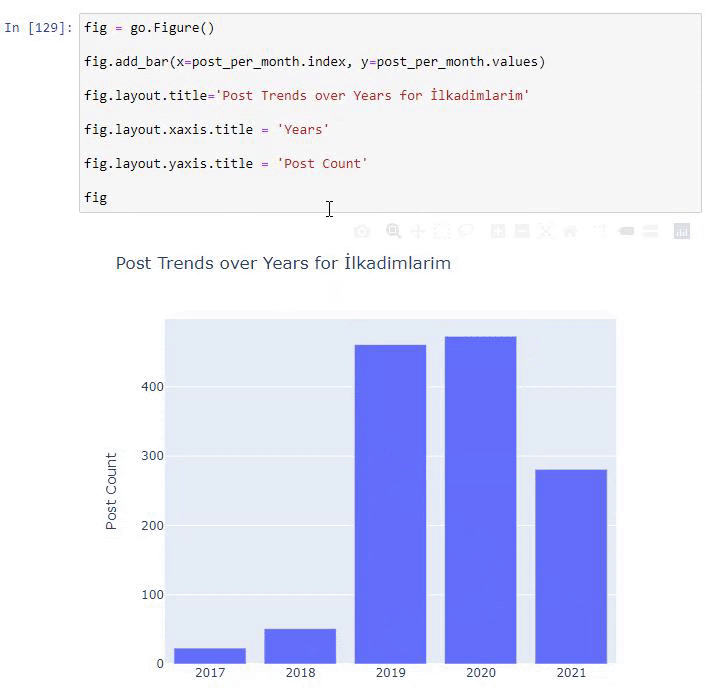
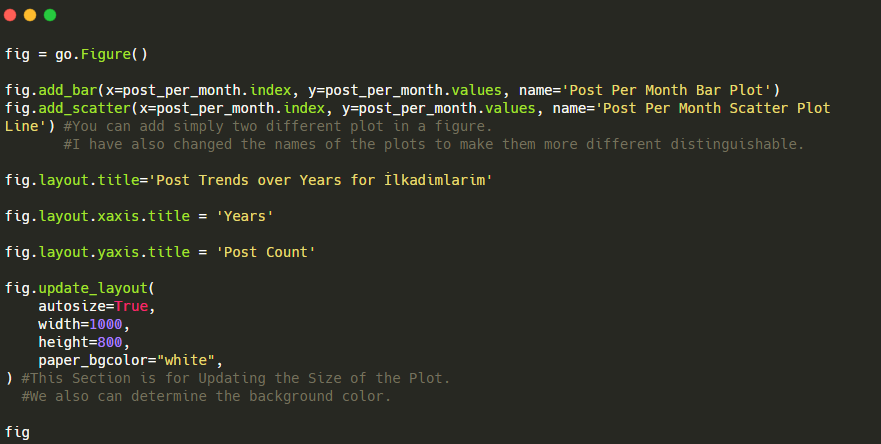
Wyjaśnienie tego fragmentu kodu Plotly Bar Plot:
- fig = go.Figure() służy do tworzenia figury.
- fig.add_bar() służy do dodawania wykresu słupkowego do figury. Określamy również, jakie osie X i Y będą znajdować się w nawiasach.
- Rys.layout służy do tworzenia ogólnego tytułu dla figury i osi.
- W ostatniej linii wywołujemy wykres, który stworzyliśmy za pomocą polecenia fig, które jest równe go.Figure()
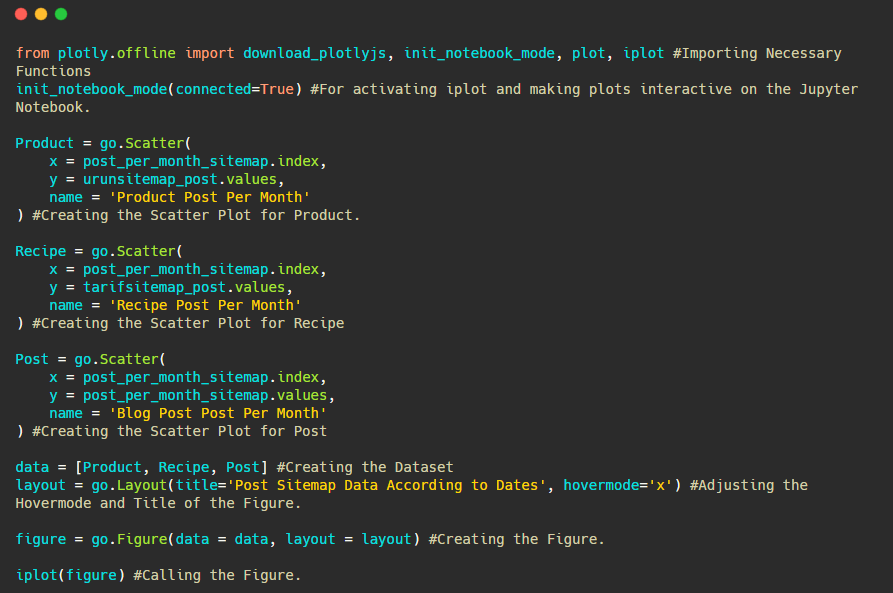
Poniżej znajdziesz te same dane według miesiąca, z wykresem rozrzutu i wykresem słupkowym:
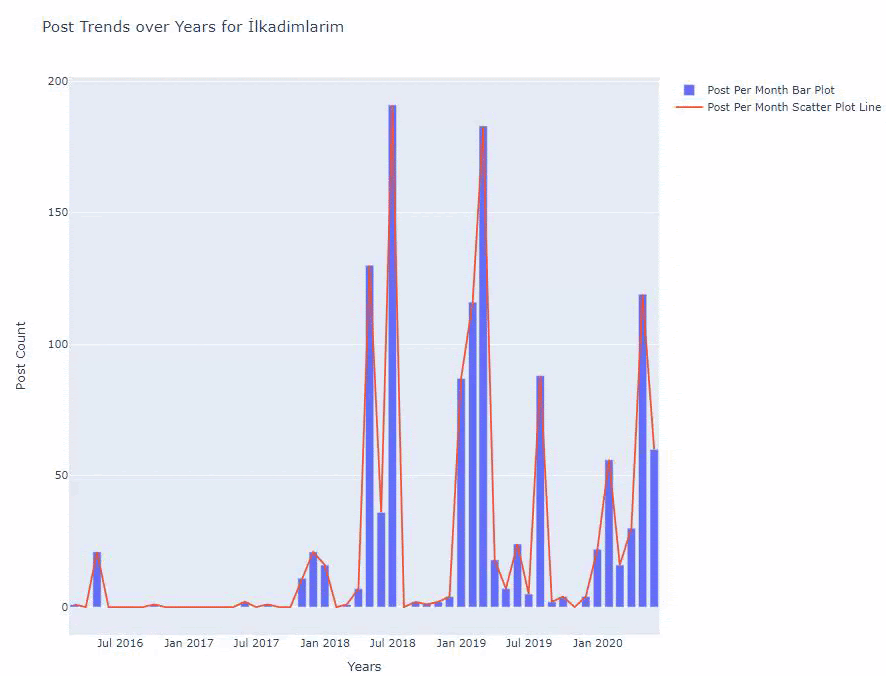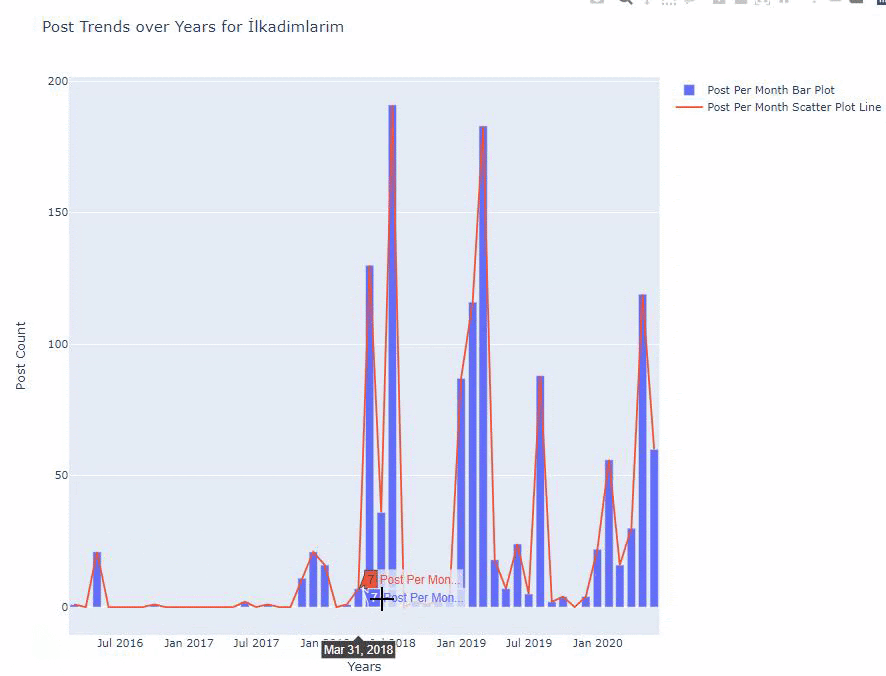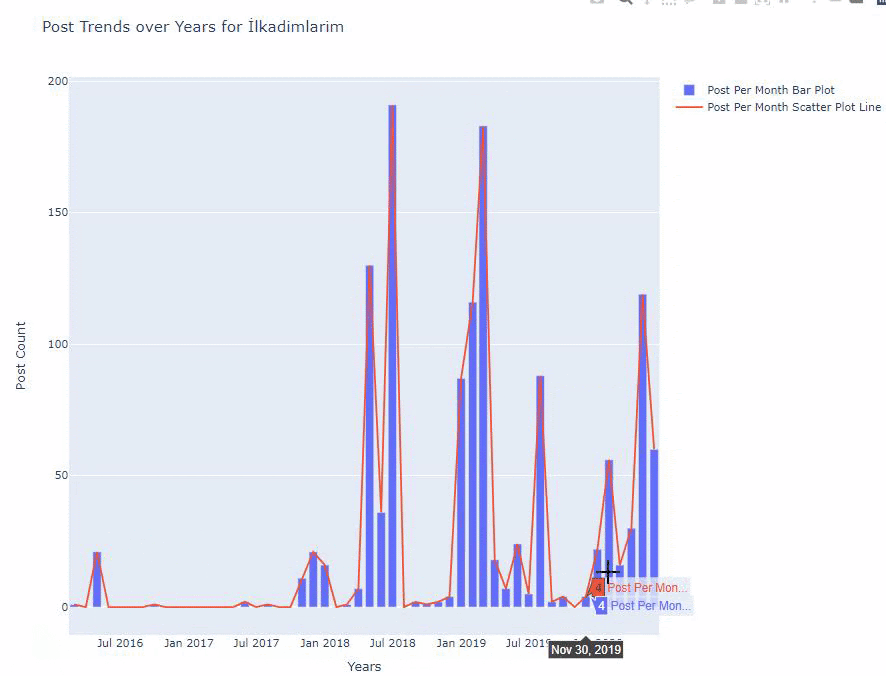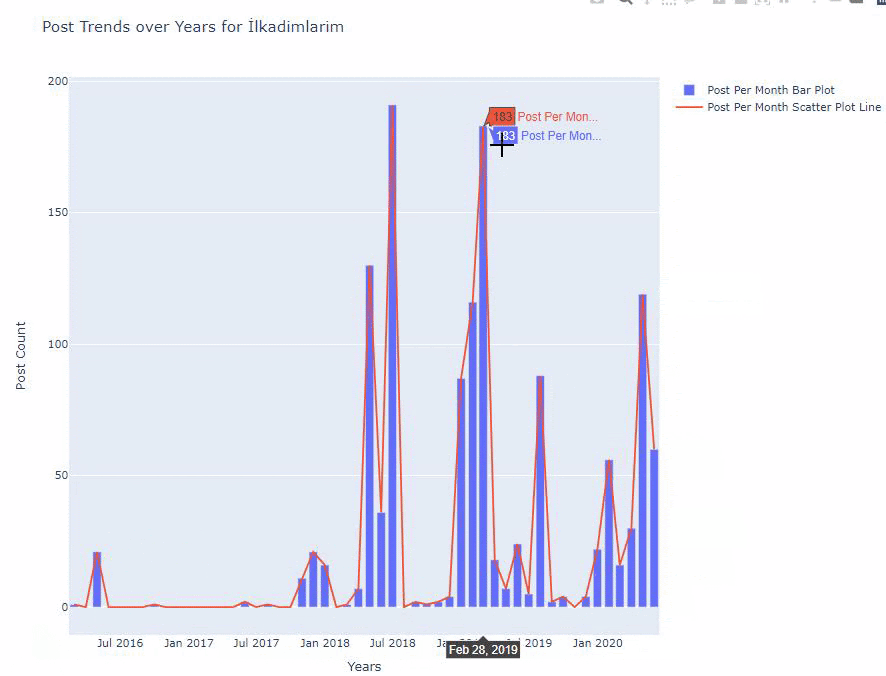
Oto kody do stworzenia tej figury:
Dodaliśmy drugi wykres za pomocą fig.add_scatter() , a także zmieniliśmy nazwy za pomocą atrybutu name. fig.update_layout() służy do zmiany rozmiaru i koloru tła wykresu.
Możesz także zmienić tryb najechania, odległość między słupkami i nie tylko. Myślę, że wystarczy tylko udostępnić kody, ponieważ wyjaśnienie tutaj każdego kodu z osobna może spowodować, że odejdziemy od głównego tematu.
Możemy również porównywać trendy wydawnicze konkurencji według kategorii, jak poniżej:
Ten wykres został utworzony drugą metodą, jak widać nie ma różnicy, ale jedna z nich jest dość prosta.
Aby wykreślić częstotliwość i trend publikowania treści z trzech oddzielnych map witryn, musimy umieścić mapę witryny, która ma najdłuższy interwał, na osi X. W ten sposób możemy porównać częstotliwość, z jaką badana przez nas witryna publikuje różne rodzaje treści dla różnych celów wyszukiwania.
Kiedy przyjrzysz się odpowiednim kodom poniżej, zobaczysz, że nie różni się on zbytnio od powyższego.
Aby utworzyć wykres punktowy z wieloma osiami Y, możesz użyć poniższego kodu.
Istnieją inne metody, takie jak ujednolicenie różnych map witryn i użycie pętli for, aby kolumny używały wielu osi Y na wykresie punktowym, ale w przypadku tak małej witryny nie jest to potrzebne. W większości przypadków bardziej logiczne byłoby użycie tej metody na stronach internetowych z setkami map witryn.
Ponadto, ponieważ strona jest mała, grafika może wyglądać płytko, ale jak zobaczysz w dalszej części artykułu o witrynie z milionami adresów URL, taka grafika jest świetnym sposobem na porównanie różnych witryn, a także porównanie różnych kategorii tej samej stronie internetowej.
Badanie i wizualizacja kategorii treści, intencji i trendów publikowania za pomocą map witryn i języka Python
W tej sekcji sprawdzimy, czy napisali dużą liczbę treści w określonej domenie wiedzy, aby promować niewielką liczbę produktów, o czym mówiliśmy na początku artykułu. Dzięki temu możemy zobaczyć, czy mają partnerstwo merytoryczne z innymi markami, czy nie.
Aby pokazać, co jeszcze można znaleźć na mapach witryn, będziemy kontynuować trochę więcej kopania. Możemy również uzyskać pewne informacje z części „loc” mapy witryny, na przykład z innych.
Nie ma podziału na kategorie w adresach URL Ilkadimlarim. Jeśli witryna ma podział kategorii w swoich adresach URL, możemy dowiedzieć się znacznie więcej o dystrybucji treści. Jeśli nie, możemy uzyskać dostęp do tych samych danych, pisząc dodatkowy kod, ale tylko z mniejszą pewnością.
W tym momencie możesz sobie wyobrazić, o ile mniej kosztowne podziały adresów URL sprawiają, że wyszukiwarki, które indeksują miliardy witryn, mogą zrozumieć Twoją witrynę.
a = ilkadimlarim['loc'].str.contains("bebek|hamile|haftalik")
Bebek: kochanie
Hamile: w ciąży
Haftalik: co tydzień lub „tygodnie ciąży”
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
Metoda str() tutaj ponownie pozwala nam ustawić kolumnę, w której wybieramy określone operacje.
Za pomocą metody Contains() określamy dane, aby sprawdzić, czy są zawarte w danych przekonwertowanych na ciąg.
Tutaj „|” między terminami oznacza „lub” .
Następnie przypisujemy przefiltrowane dane do zmiennej i używamy metody resample() , której użyliśmy wcześniej.
Z drugiej strony metoda liczenia mierzy, które dane są używane i ile razy.
Wynik uzyskany za pomocą count() jest ponownie ujęty w to_frame() .
Ponadto str.contains() domyślnie przyjmuje wartości Regex, co oznacza, że możesz tworzyć bardziej skomplikowane warunki filtrowania przy mniejszej ilości kodu.
Innymi słowy, w tym momencie przypisujemy adresy URL zawierające słowa „dziecko”, „tydzień”, „w ciąży” do zmiennej w ilkadimlarim , a następnie umieszczamy datę publikacji adresów URL w odpowiednich warunkach dla tego filtra, który stworzony w ramce.
Następnie robimy to samo dla adresów URL zawierających słowo „aptamil”. Aptamil to nazwa produktu do żywienia niemowląt wprowadzonego przez Ilkadimlarim. Dlatego też możemy zwrócić uwagę na gęstość emisji treści informacyjnych i komercyjnych.
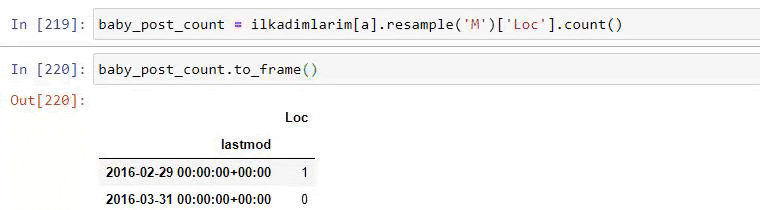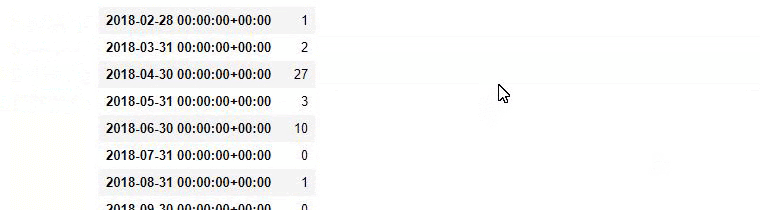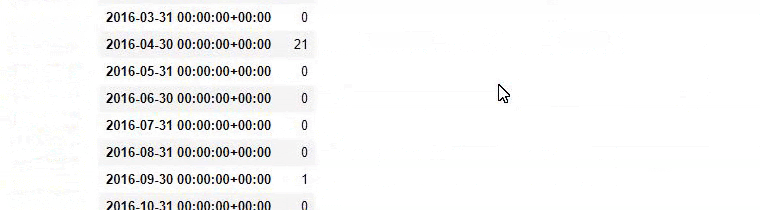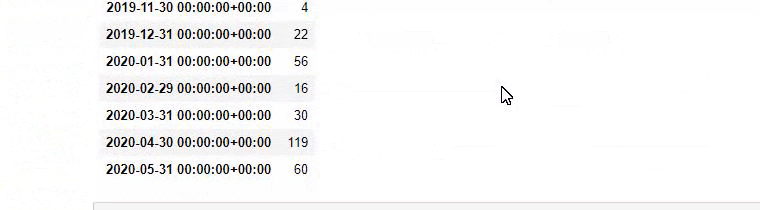
Możesz też zobaczyć harmonogramy publikowania dwóch różnych grup treści na przestrzeni lat dla różnych intencji wyszukiwania z większą pewnością i precyzyjnymi informacjami z adresów URL.
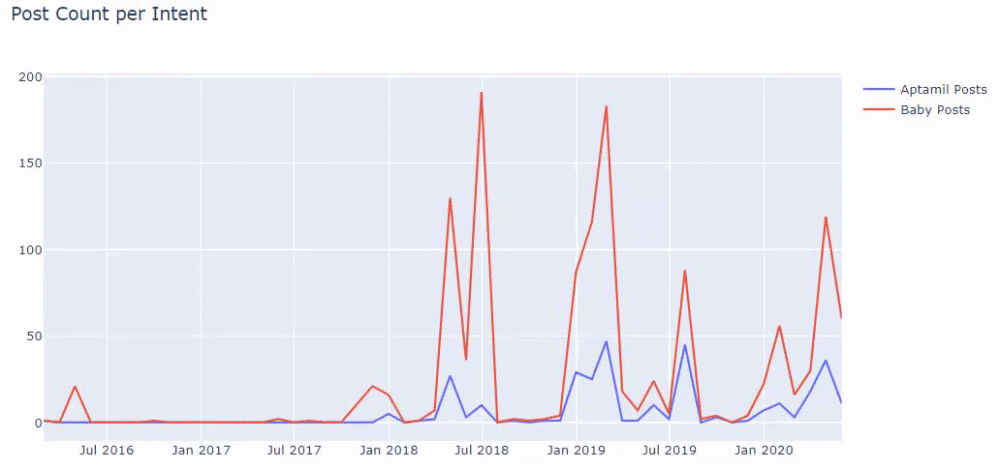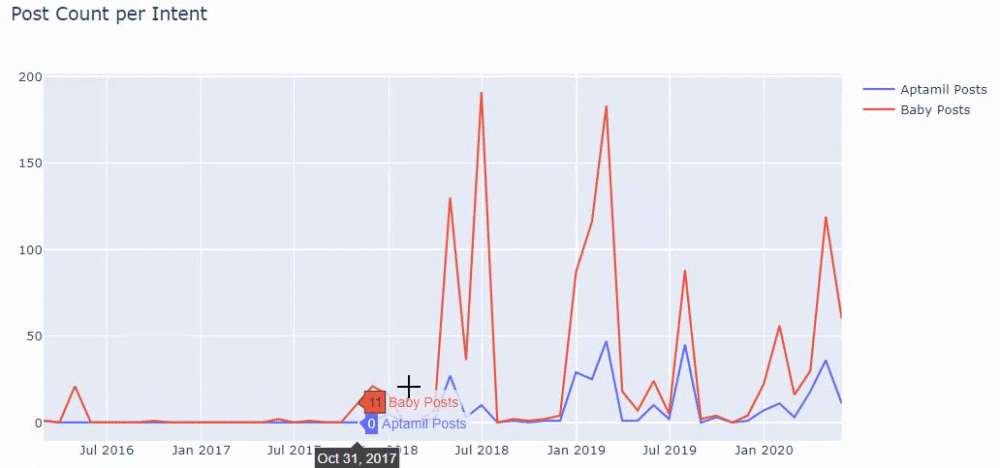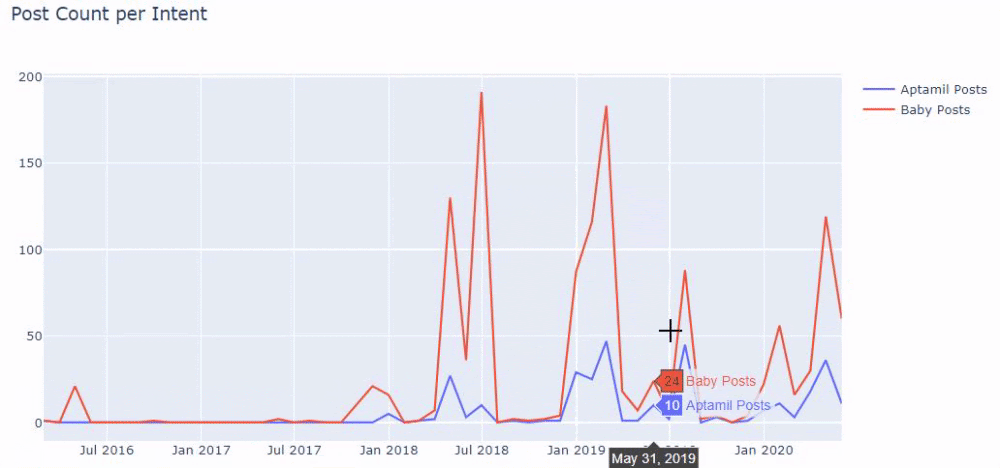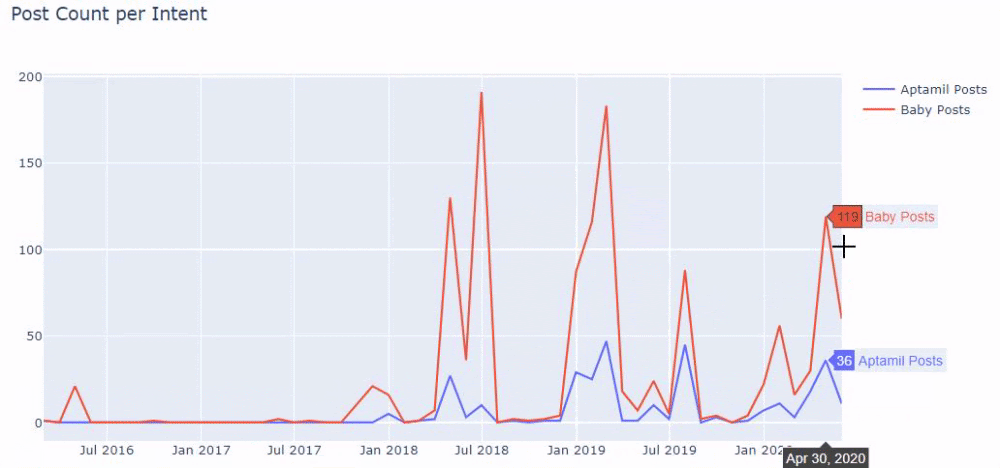
Kod do wygenerowania tego wykresu nie został udostępniony, ponieważ jest taki sam, jak ten użyty w poprzednim wykresie
Z pomocą operatorów wyszukiwania w Google otrzymuję 38 wyników, gdy chcę strony, na których słowo Aptamil jest używane w tekście kotwicy na Ilkadimlarim.com. Wiele z tych stron ma charakter informacyjny i zawiera linki do treści komercyjnych.
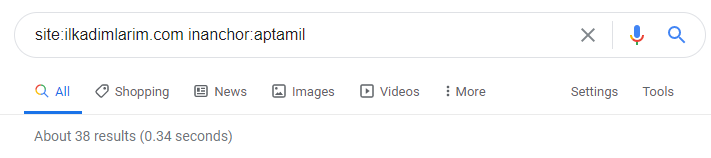
Nasza teza została potwierdzona.
„My First Steps” wykorzystuje setki materiałów informacyjnych na temat macierzyństwa, opieki nad dzieckiem i ciąży, aby dotrzeć do odbiorców docelowych. „Ilkadimlarim” łączy strony zawierające produkty Aptamil z tych treści i kieruje tam użytkowników.
Porównawcze profilowanie treści i analiza strategii treści za pomocą map witryn w Pythonie
Teraz, jeśli chcesz, zróbmy to samo dla firmy z tej samej branży i dokonaj porównania, aby zrozumieć ogólny aspekt tej branży i różnice w strategii między tymi dwiema markami.

Jako drugi przykład wybrałem Prima.com.tr, czyli Pampers, ale używa nazwy marki Prima w Turcji. Ponieważ Prima ma jedną mapę witryny, nie będziemy mogli klasyfikować według map witryn, ale przynajmniej mają różne przerwy w adresach URL. Mamy więc szczęście: będziemy musieli pisać mniej kodu.
Wyobraź sobie, o ile bardziej kosztowne są algorytmy, które Google musi dla Ciebie uruchomić, gdy tworzysz trudną do zrozumienia witrynę! Dzięki temu kalkulacja kosztów indeksowania będzie bardziej namacalna, nawet w odniesieniu do struktury adresu URL.
Aby dalej nie zwiększać objętości artykułu, nie umieszczamy kodów procesów podobnych do tych, które już przeprowadziliśmy.
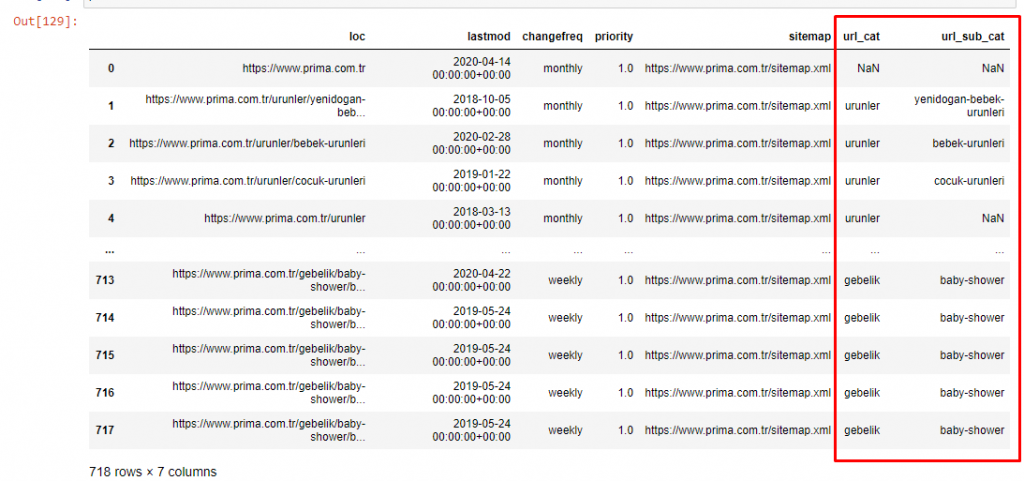
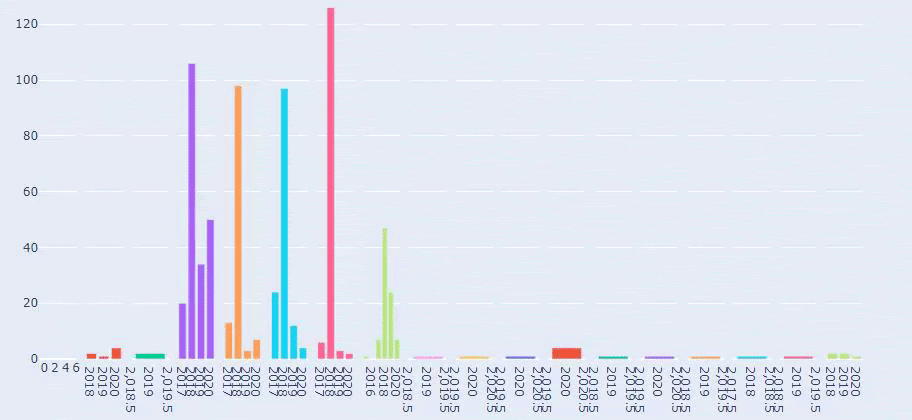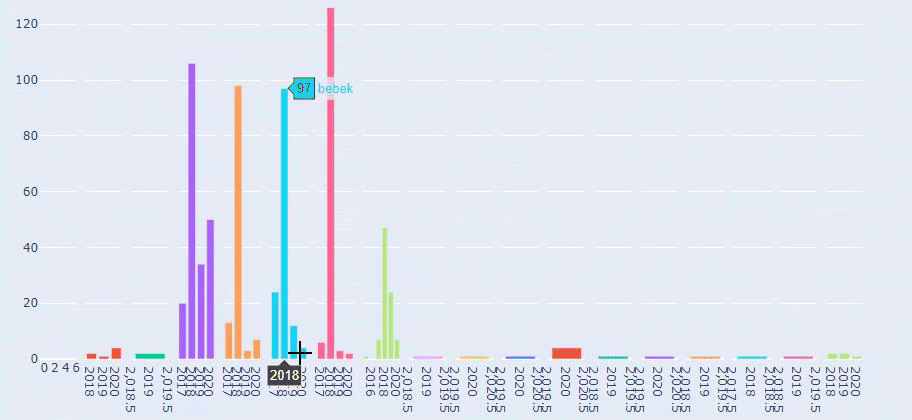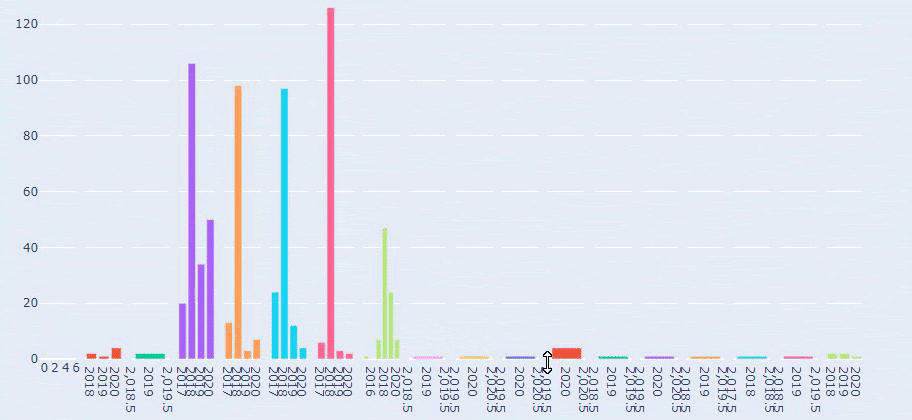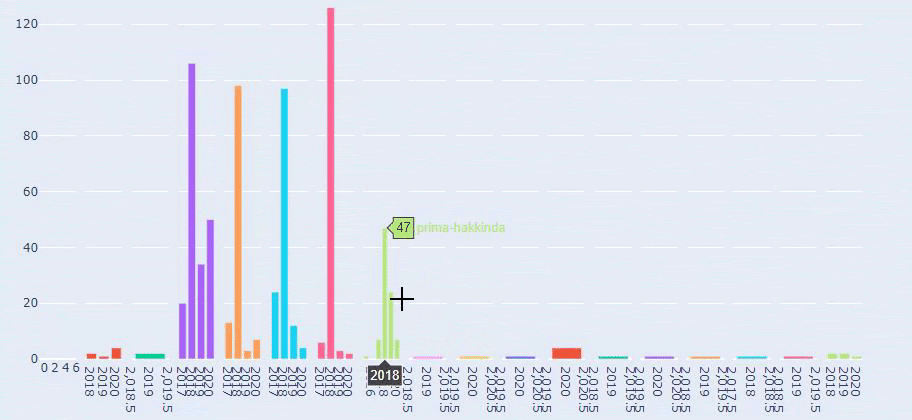
Teraz możemy zbadać ich rozkład kategorii treści według kategorii adresów URL i podkategorii adresów URL. Widzimy, że mają nadmierną ilość firmowych stron internetowych. Te korporacyjne strony internetowe są umieszczone w sekcji „prima-hakkinda” („O firmie Prima”). Ale kiedy sprawdzam je w Pythonie, widzę, że zunifikowali swoje produkty i korporacyjne strony internetowe w jednej kategorii. Możesz zobaczyć ich dystrybucję treści poniżej:

To samo możemy zrobić dla następujących podkategorii.
Warto zauważyć, że Prima używa „gebelik” (ciąża po turecku), która jest odmianą „hamilelik” (ciąża po arabsku) i oba oznaczają okres ciąży.

Teraz widzimy głębszą kategoryzację ich treści. 9,2% treści dotyczy zdrowej ciąży, 7,3% procesu wzrostu niemowląt, 8,3% treści dotyczy czynności, które można wykonać z niemowlętami, 0,7% dotyczy kolejności snu niemowląt. Istnieją nawet takie tematy, jak ząbkowanie (3,9%), bezpieczeństwo dziecka (1,9%) i ujawnianie ciąży rodzinie (1,4%). Jak widać, możesz poznać branżę za pomocą samych adresów URL i procentu ich dystrybucji.
Nie jest to idealna kategoryzacja, ale przynajmniej możemy zobaczyć trendy w mentalności i content marketingu naszych konkurentów oraz zawartość ich stron internetowych według kategorii. Sprawdźmy teraz częstotliwość publikowania treści według miesiąca.
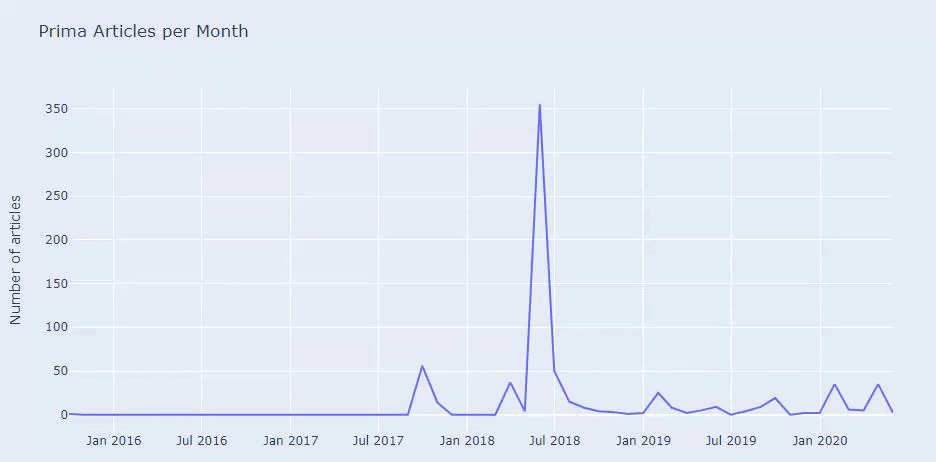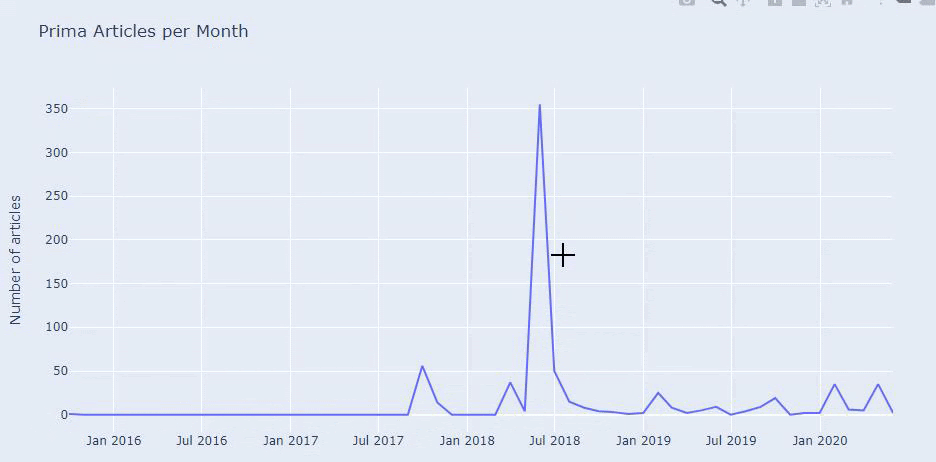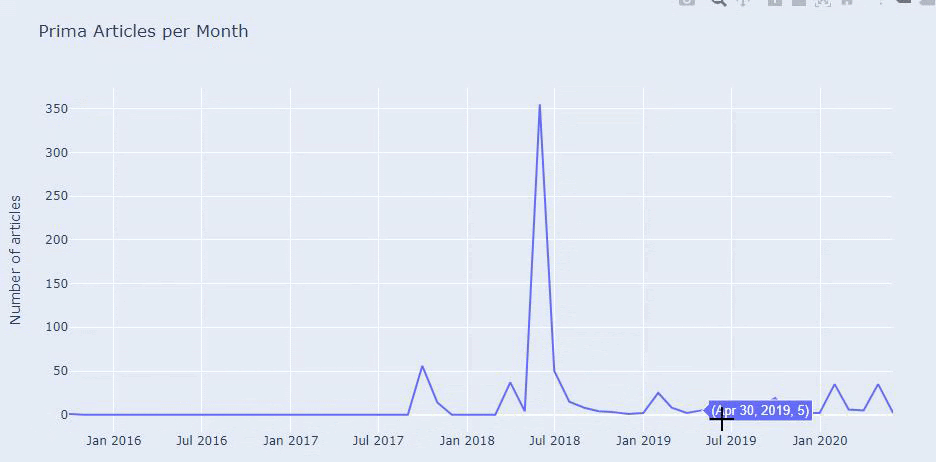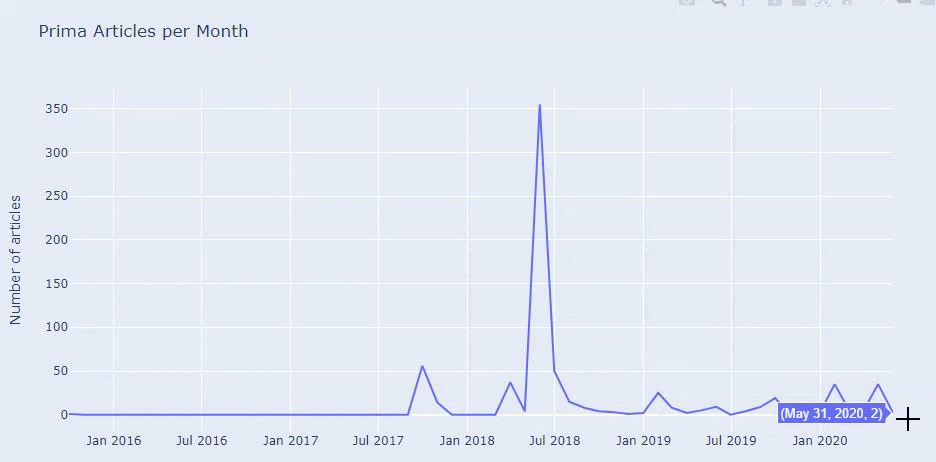
Widzimy, że opublikowali 355 artykułów w lipcu 2018 r. i według Sitemap od tego czasu ich zawartość nie jest odświeżana. Możemy również porównywać trendy wydawnicze ich treści według kategorii na przestrzeni lat. Jak widać, ich treść znajduje się głównie w czterech różnych kategoriach, a większość z nich jest publikowana w tym samym miesiącu.
Zanim przejdziemy dalej, muszę powiedzieć, że dane mapy witryny mogą nie zawsze być poprawne. Na przykład dane Lastmod mogły zostać zaktualizowane dla wszystkich adresów URL, ponieważ odnowiły wszystkie mapy witryn w tym dniu. Aby obejść ten problem, możemy również sprawdzić, czy od tego czasu nie zmienili swojej zawartości, korzystając z Wayback Machine.
Nawet jeśli wygląda to podejrzanie, te dane mogą być prawdziwe. Wiele firm w Turcji ma tendencję do wydawania dużej liczby zamówień i publikowania treści na chwilę wcześniej. Kiedy sprawdzam liczbę słów kluczowych, widzę skok w tym okresie. Jeśli więc przeprowadzasz analizę porównawczą profilu treści i strategii, powinieneś również pomyśleć o tych kwestiach.
To jest porównanie trendów publikowania treści w każdej kategorii na przestrzeni lat dla Prima.com.tr
Teraz możemy porównać dwie różne kategorie treści stron internetowych i ich trendy wydawnicze.
Kiedy przyjrzymy się częstotliwości publikowania przez Primę artykułów o rozwoju dziecka, ciąży i macierzyństwie, widzimy podobieństwo do Ilkadimlarim:
- Większość artykułów została opublikowana w określonym czasie.
- Od dawna nie były aktualizowane.
- Liczba produktów i stron była bardzo niska w porównaniu z liczbą stron z treściami informacyjnymi.
- Niedawno dodali nowe produkty do swoich witryn.
Możemy uznać te cztery cechy za domyślny sposób myślenia w branży i możemy wykorzystać te słabości na korzyść naszej kampanii. W końcu jakość wymaga świeżości (jak stwierdził Amit Singhal, Google Fellow).
W tym momencie widzimy również, że branża nie jest zaznajomiona z zachowaniem Googlebota. Zamiast przesyłać 250 elementów treści w ciągu jednego dnia, a potem nie wprowadzać żadnych zmian przez rok, lepiej jest okresowo dodawać nową zawartość i regularnie aktualizować starą zawartość. W ten sposób możesz utrzymać jakość treści, Googlebot może łatwiej zrozumieć Twoją witrynę, a wartości częstotliwości indeksowania będą wyższe niż u konkurencji.
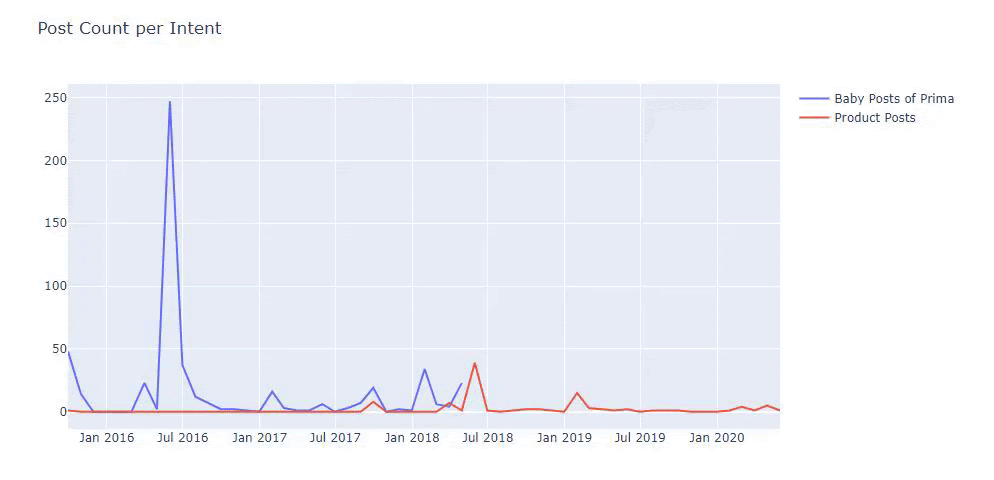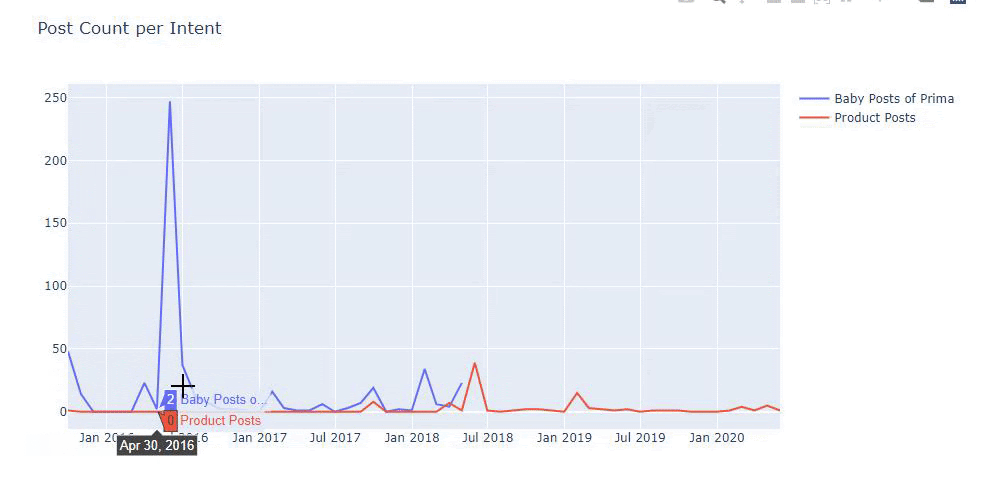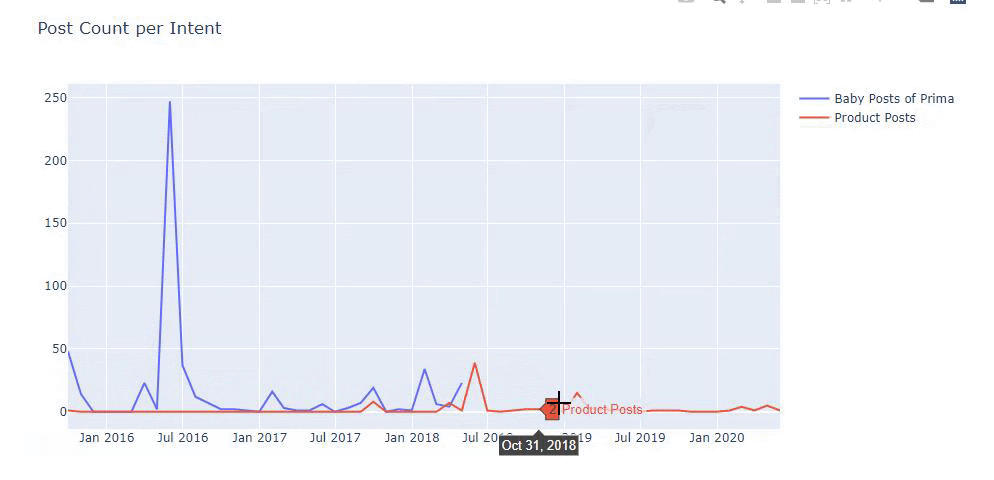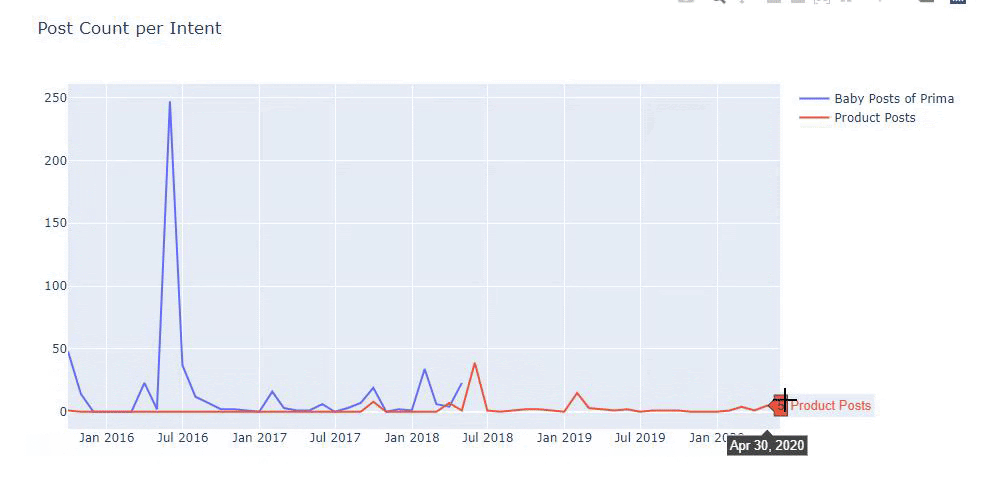
Użyłem poprzednich metod, aby odróżnić strony produktowe od stron informacyjnych i sprofilowałem najczęściej używane słowa w adresach URL. Posty dla dzieci oznaczają, że są to treści informacyjne.
Jak widać, jednego dnia dodali 247 treści. Ponadto nie publikowali ani nie odświeżali treści informacyjnych przez ponad rok, a jedynie od czasu do czasu dodawali nowe strony produktów.
Teraz porównajmy ich trendy wydawnicze na jednej figurze, ale z dwoma różnymi wątkami. Do stworzenia tej figury użyłem poniższych kodów:
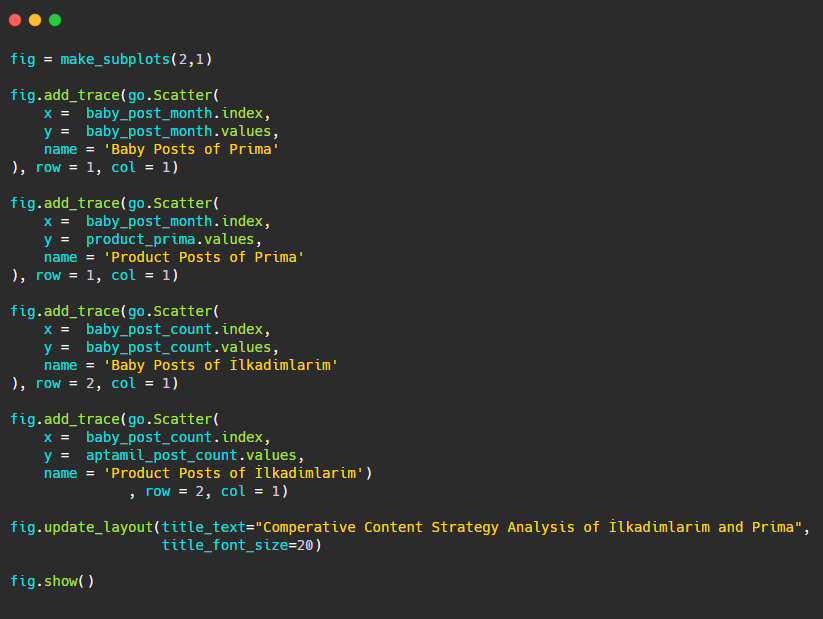
Ponieważ ta grafika różni się od poprzednich, chciałem pokazać kod. Tutaj dwie oddzielne działki są umieszczone na tej samej figurze. W tym celu wywołano metodę make_subplots poleceniem z plotly.subplots import make_subplots.
Została stworzona jako dwurzędowa i jednokolumnowa figura z make_subplots (2,1) .
Dlatego col i row są zapisywane na końcu śladów, a ich pozycje są określone. Jest to system, który każdy zaznajomiony z systemem siatki w CSS może łatwo rozpoznać.
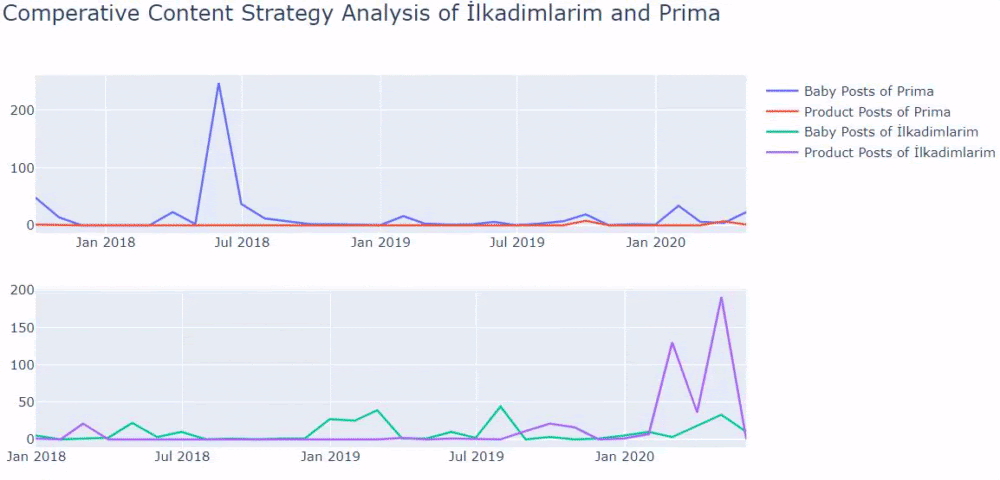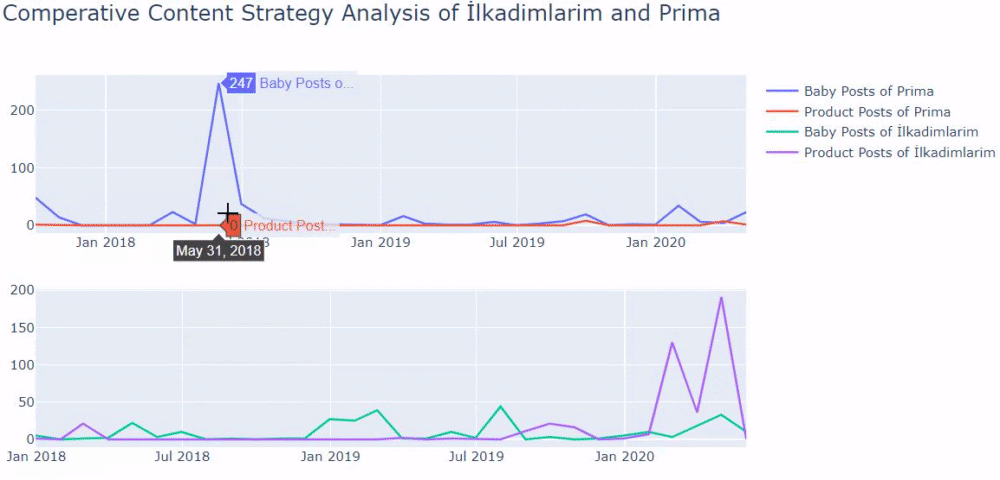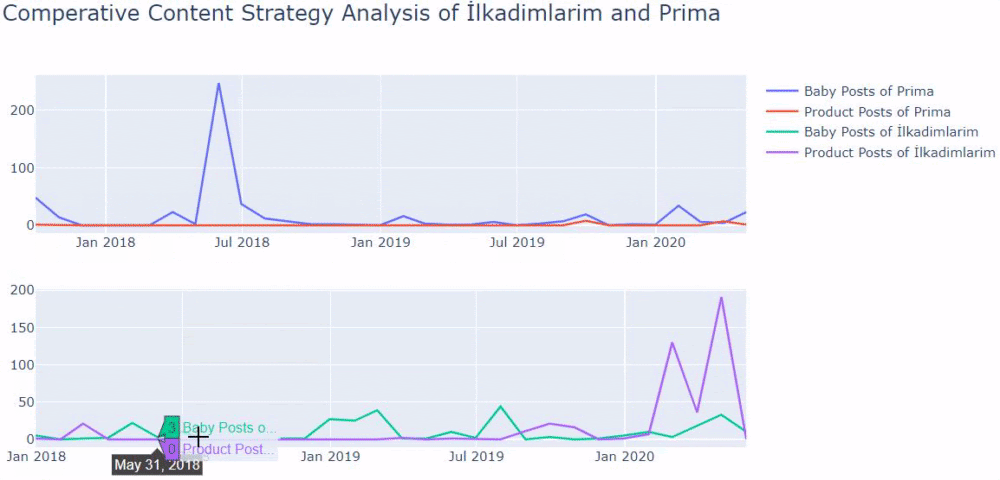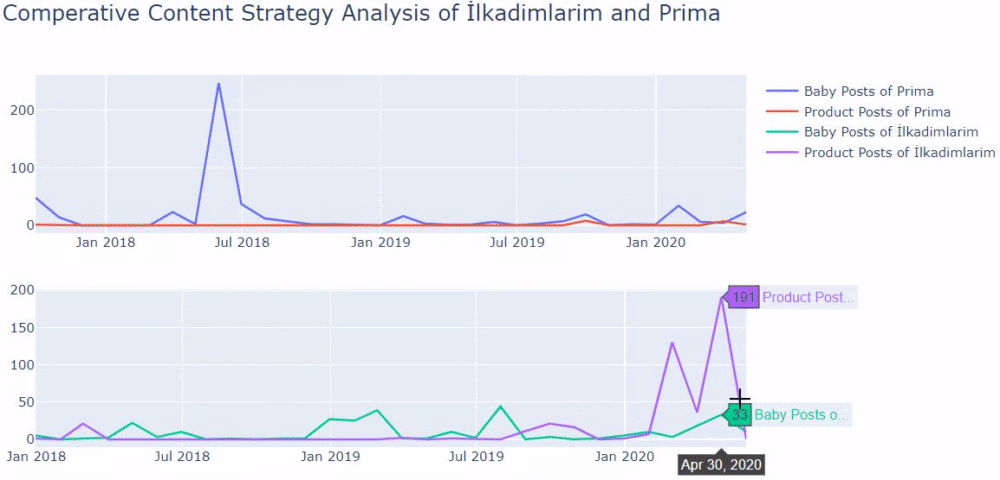
Jeśli masz klienta z tego samego sektora, możesz wykorzystać te dane do stworzenia strategii treści, aby zobaczyć słabości konkurencji i ich sieć zapytań/stron docelowych w SERP. Możesz także zrozumieć, jaką ilość treści należy opublikować w tej samej domenie wiedzy lub w tym samym celu użytkownika.
Przed zakończeniem tego, czego możemy się nauczyć z map witryn w ramach analizy strategii treści, możemy zbadać ostatnią witrynę o znacznie większej liczbie adresów URL z innej branży.
Analiza strategii treści wiadomości internetowych jednostek w zależności od walut za pomocą Pythona i map witryn
W tej sekcji użyjemy wykresu mapy termicznej Seaborna, a także niektórych bardziej wyszukanych metod kadrowania i ekstrakcji danych.

Elias Dabbas ma ciekawe i naprawdę przydatne Archiwum Kaggle w zakresie Data Science i SEO. W tym miesiącu otworzył dla mnie nową sekcję zestawu danych Kaggle dla tureckich witryn z wiadomościami, abym mógł napisać niezbędne kody i przeprowadzić analizę strategii treści za pomocą Advertools za pomocą map witryn.
Zanim zacznę używać tych technik na Kaggle, chciałbym pokazać w tym artykule kilka przykładów tego, co by się stało, gdybyśmy użyli tych samych technik na większych encjach sieciowych.
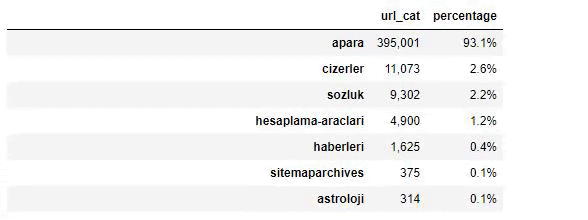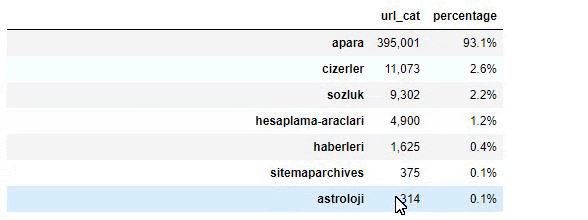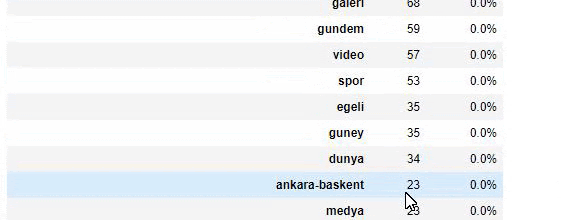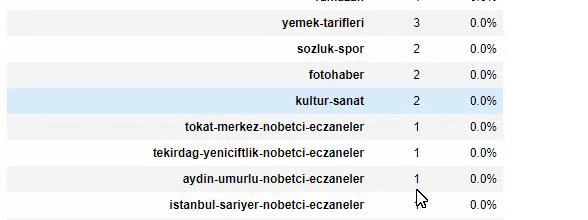
Analizując zawartość Gazety Sabah widzimy, że znaczna część jej zawartości (81%) znajduje się w kategorii zwanej „apara”. Mają też kilka dużych kategorii dla astrologii, obliczeń, słownika, pogody i wiadomości ze świata. (Para oznacza pieniądze po turecku)
W przypadku Sabah Newspaper możemy również analizować treści za pomocą map witryn, które zebraliśmy tylko za pomocą Advertools, ale ponieważ omawiana gazeta jest bardzo duża, nie preferowałem jej ze względu na dużą liczbę map witryn i zawartość różnych map witryn zawierających ten sam adres URL Kategoria.
Poniżej możesz również zobaczyć nadmiar map witryn z Advertools.
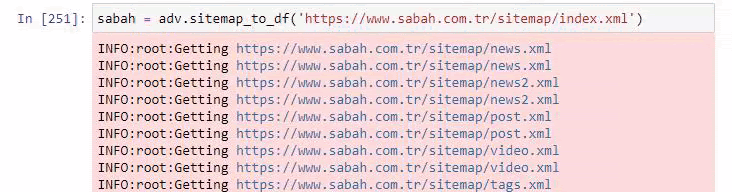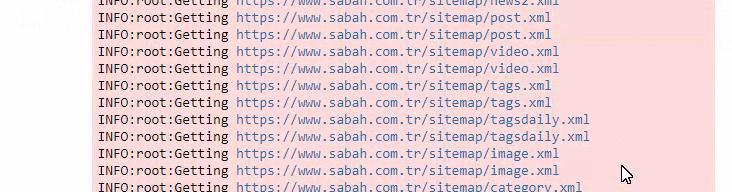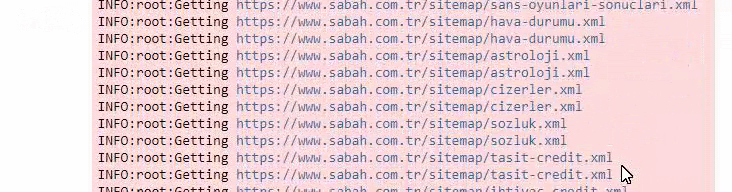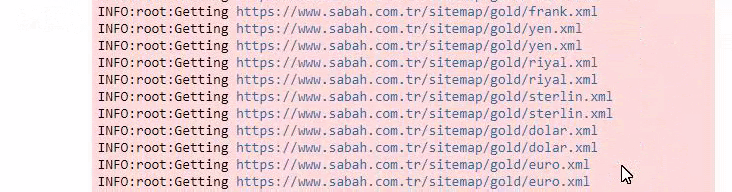
Możemy zauważyć, że mają różne mapy witryn dla tych samych kategorii adresów URL, takich jak złoto, kredyt, waluty, tagi, godziny modlitwy i godziny pracy apteki itp.
Krótko mówiąc, możemy osiągnąć te szczegóły, koncentrując się na podkategoriach adresów URL. Zamiast ujednolicać różne mapy witryn za pomocą zmiennych. Tak więc ujednoliciłem wszystkie mapy witryn za pomocą metody sitemap_to_df() Advertools, tak jak na początku artykułu.
Możemy również użyć innego zestawu funkcji stworzonych przez Eliasa Dabbasa do tworzenia lepszych ramek danych. Jeśli sprawdzisz funkcje dataset_utitilites, zobaczysz kilka przykładów. Poniższy kod podaje sumę i procent określonego wyrażenia regularnego adresu URL wraz ze skumulowaną sumą stylizowaną.
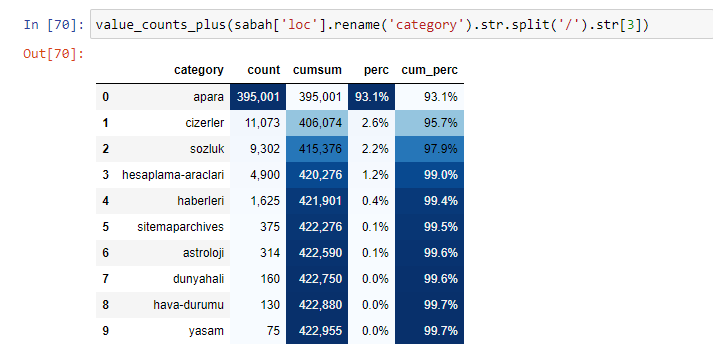
Jeśli zrobimy to samo z podziałem pod adresami URL gazety Sabah, otrzymamy następujący wynik.
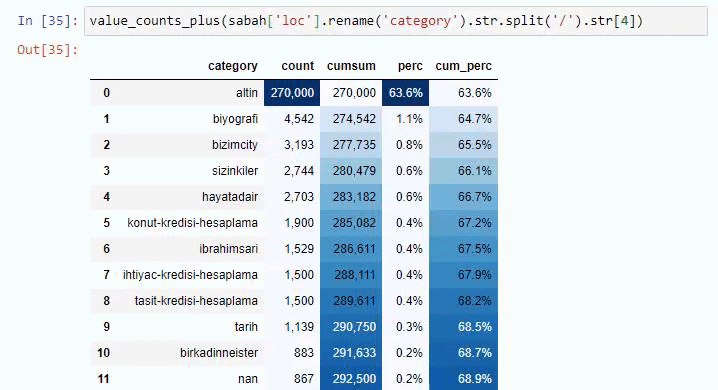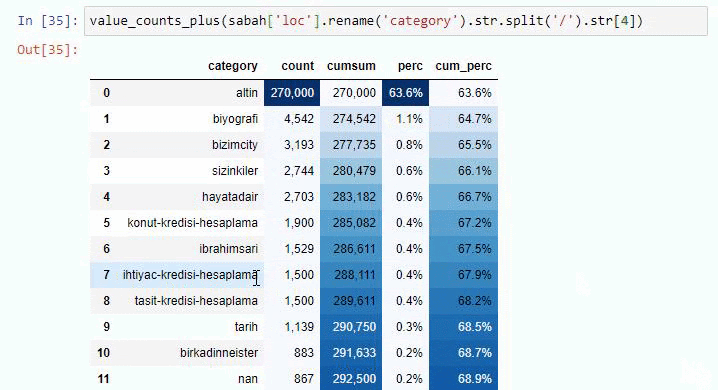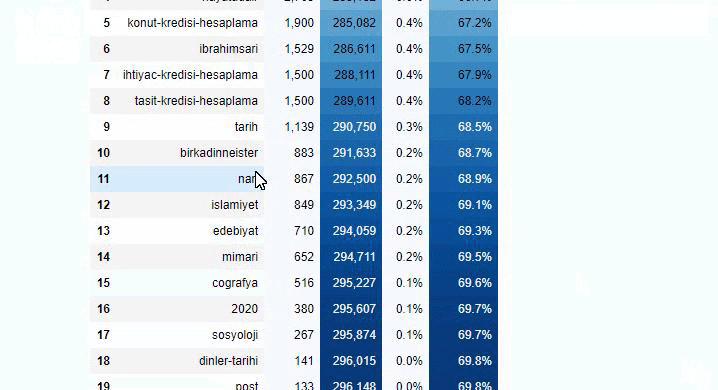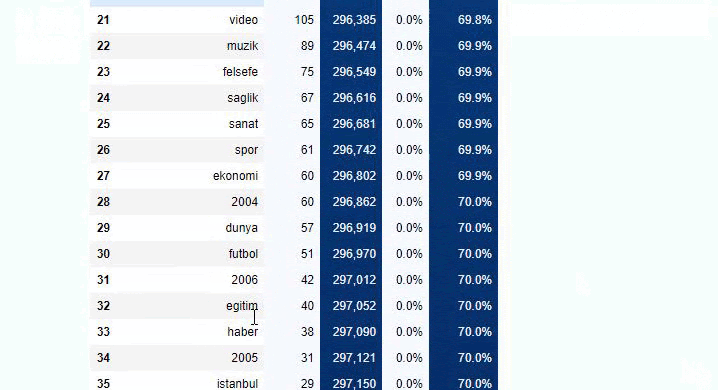
Możesz zwiększyć liczbę wierszy, które dana funkcja wyświetli, zmieniając wiersz poniżej. Ponadto, jeśli przyjrzysz się zawartości funkcji, zobaczysz, że jest ona podobna do tych, których używaliśmy wcześniej.
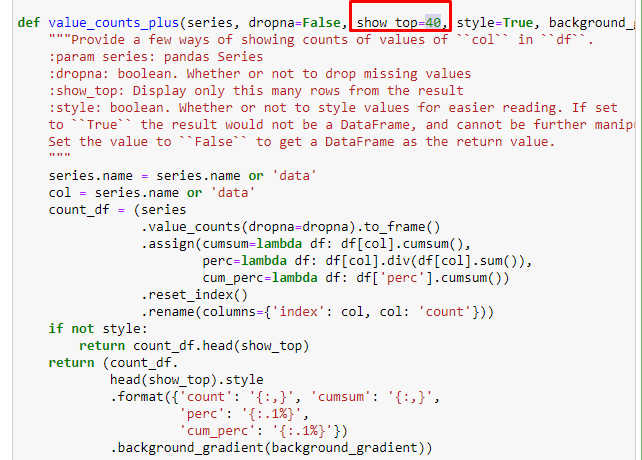
W podziałach podrzędnych widzimy różne podziały, takie jak „Historia religii”, „Biografia”, „Nazwy miast”, „Piłka nożna”, „Bizimcity (karykatura)”, „Kredyt hipoteczny”. Największy podział znajduje się w kategorii „Złoto”.
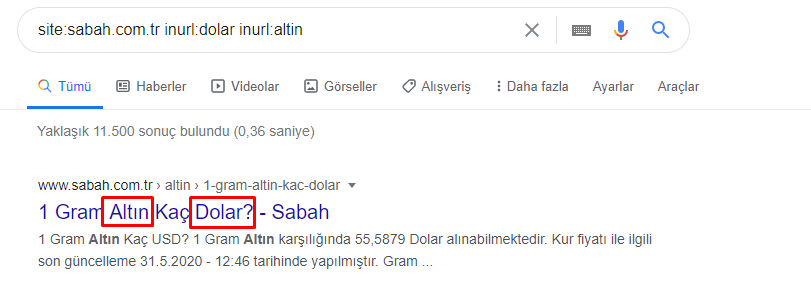
Jak więc gazeta może mieć 295 000 adresów URL z cenami złota?
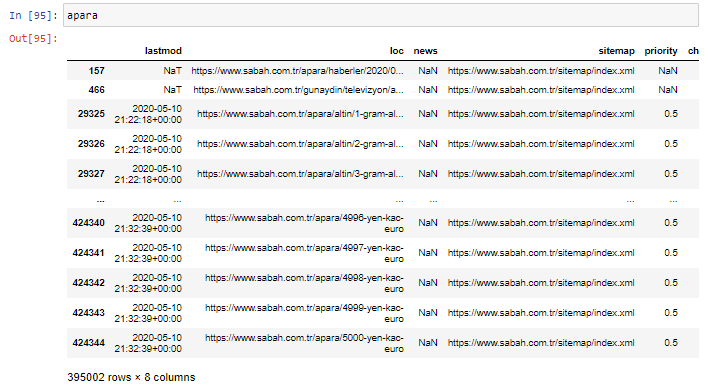
Przede wszystkim wrzucam do zmiennej wszystkie adresy URL zawierające „apara” w pierwszym podziale adresów URL Sabah Newspaper.
apara = sabah[sabah['loc'].str.contains('apara')]
Oto wynik:
Możemy również filtrować kolumny za pomocą metody .filter():
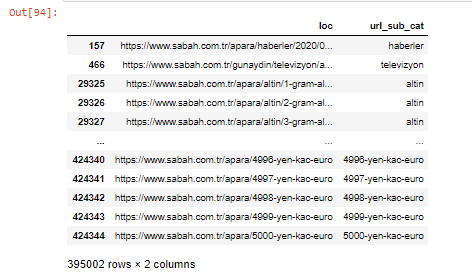
Teraz możemy zobaczyć na dole ramki DataFrame, dlaczego Sabah Newspaper ma nadmierną liczbę adresów URL Apara, ponieważ otwierają różne strony internetowe dla każdej kwoty kalkulacji waluty, takiej jak 5000 euro, 4999 euro, 4998 euro i więcej…
Ale zanim wyciągniemy jakiekolwiek wnioski, musimy mieć pewność, ponieważ ponad 250 000 z tych adresów URL należy do kategorii „altin (złoty)”.
apara.filter(['loc', 'url_sub_cat']).tail(60) pokaże nam ostatnie 60 wierszy tej ramki danych:

Możemy zrobić to samo w przypadku podziału złotych adresów URL w grupie Apara.
złoto = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
W tym momencie widzimy, że gazeta Sabah otworzyła 5000 różnych stron, aby przekonwertować każdą walutę na dolary, euro, złoto i TL (tureckie liry). Istnieje osobna strona obliczeniowa dla każdej jednostki pieniężnej od 1 do 5000. Poniżej możesz zobaczyć przykład pierwszych 85 i ostatnich 85 wierszy grupy złota. Dla każdego grama złota została otwarta osobna strona.


Nie mamy wątpliwości, że te strony są niepotrzebne, z dużą ilością powielanych treści i nadmiernie duże, ale Sabah Newspaper jest tak silną marką witryną, że Google nadal pokazuje ją w prawie każdym zapytaniu, na najwyższym poziomie.
W tym momencie możemy również zauważyć, że tolerancja kosztów indeksowania jest wysoka w przypadku starej witryny z wiadomościami o wysokim autorytecie.
Nie wyjaśnia to jednak, dlaczego kategoria złota ma więcej adresów URL niż inne.
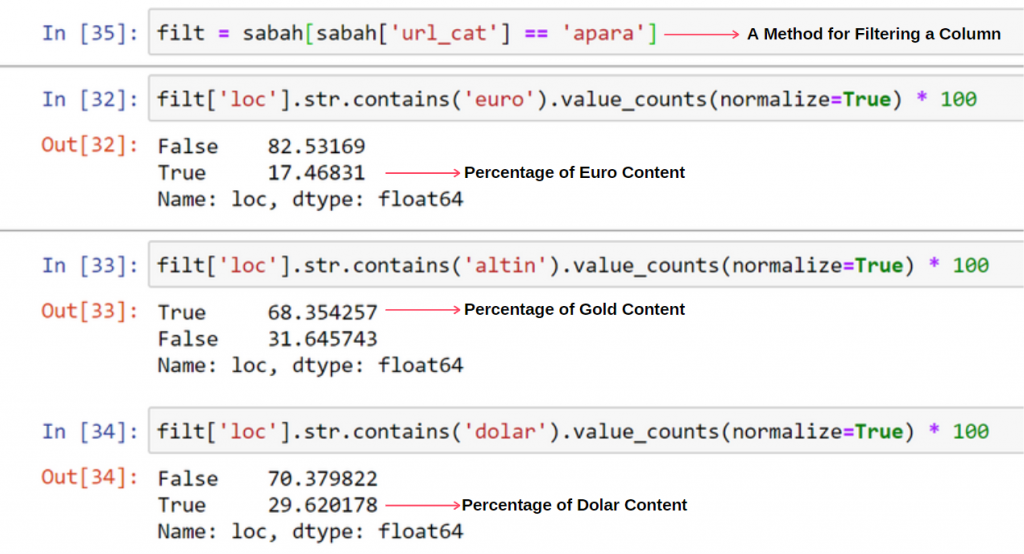
Nie widzę nic dziwnego w nakładających się wartościach sumujących się do ponad 100%.
Chyba, że czegoś mi brakuje?
Jak zauważysz, gdy dodamy wszystkie Prawdziwe Wartości, otrzymamy wynik 115,16%. Powód tego jest poniżej.
Nawet główna grupa ma takie przecięcie ze sobą. Moglibyśmy również przeanalizować te skrzyżowania, ale może to być tematem innego artykułu.
Widzimy, że 68% treści w grupie URL Apara jest związanych z GOLD.
Aby lepiej zrozumieć tę sytuację, pierwszą rzeczą, którą musimy zrobić, to zeskanować adresy URL w złotym załamaniu.
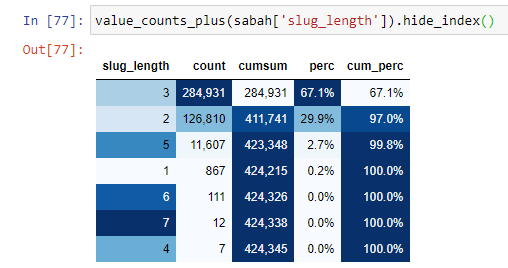
Kiedy klasyfikujemy adresy URL według liczby „/”, jakie mają od sekcji głównej, widzimy, że liczba adresów URL z maksymalnie 3 przerwami jest wysoka. Kiedy analizujemy te adresy URL, widzimy, że 270 000 z 3 adresów URL slug_length znajduje się w kategorii Gold.
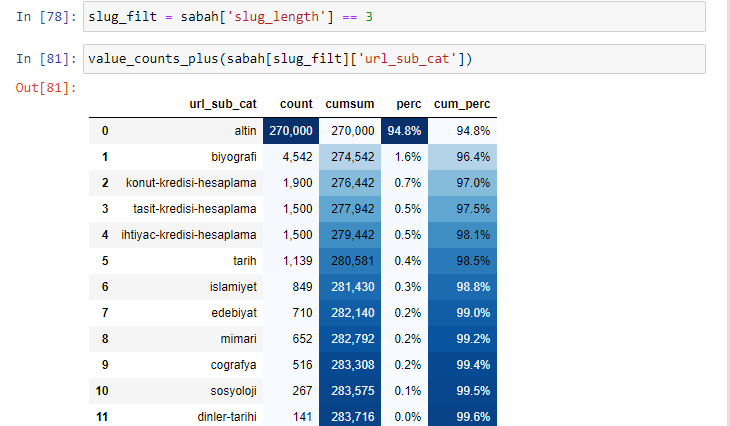
morning_filt = morning ['slug_length'] == 3 Oznacza to, że otrzymujesz tylko te, które są równe 3 z grupy danych typu danych int w określonej kolumnie określonej ramki danych. Następnie, w oparciu o te informacje, umieszczamy w ramkach adresy URL, które są dogodne dla danego warunku, z liczebnością, sumami i współczynnikami agregacji z sumą skumulowaną.
Kiedy wyodrębnimy najczęściej używane słowa ze złotych adresów URL, natkniemy się na słowa, które reprezentują „pełny”, „republika”, „ćwierć”, „gram”, „połowa”, „przodek”. Typy złota Ata i Republic są unikalne dla Turcji. Jeden z nich reprezentuje suwerenność turecką, a drugi założyciel republiki Kemal Ataturk. Dlatego ich liczba wyszukiwań zapytań jest wysoka.
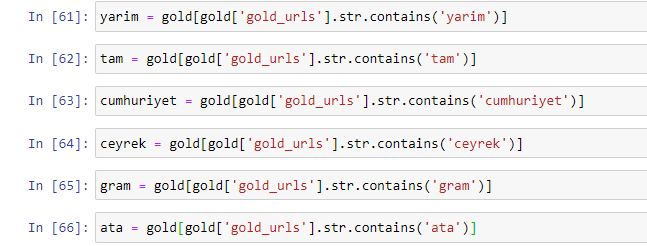
Przede wszystkim usunęliśmy popularne słowa znalezione w adresach URL i przypisaliśmy je do oddzielnych zmiennych. Następnie użyjemy tych zmiennych w Gold DataFrame, aby utworzyć kolumny specyficzne dla ich typów.
Po utworzeniu nowych kolumn poprzez zmienne musimy je przefiltrować wraz z wartościami boolowskimi.
Jak widać, byliśmy w stanie skategoryzować wszystkie złote adresy URL z 270 000 wierszy i 6 kolumnami. Głównym powodem dużej liczby stron dotyczących złota jest to, że dolar lub euro nie mają oddzielnych typów, podczas gdy złoto ma osobne typy. Jednocześnie różnorodność krzyżujących się stron między złotem a różnymi walutami jest wyższa niż w przypadku innych walut ze względu na ich tradycyjne zaufanie do narodu tureckiego.
Moim zdaniem wszystkie rodzaje złotych stron powinny być równomiernie rozłożone, prawda?
Możemy to łatwo przetestować za pomocą funkcji Heatmap w Seaborn.
importuj seaborn jako sns
importuj matplotlib.pyplot jako plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.pokaż()
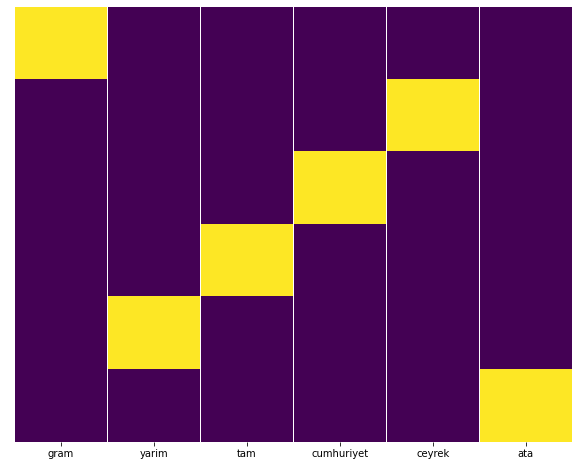
Tutaj, na Mapie Cieplnej, Prawdy w każdej kolumnie są po prostu zaznaczone. Jak widać, wielkość każdego jest symetryczna względem siebie i jest zgrabnie ułożona na mapie.
W związku z tym przyjęliśmy szerokie spojrzenie na politykę treści gazety Sabah.com.tr dotyczącą walut i obliczania walut.
W przyszłości będę pisać tureckie witryny z wiadomościami i ich strategie dotyczące treści w oparciu o mapy witryn Kaggle, które zostały uruchomione przez Eliasa Dabbasa, ale w tym artykule omówiliśmy wystarczająco dużo o tym, co można znaleźć zarówno w dużych, jak i małych witrynach z mapami witryn .
Wnioski i dania na wynos
Myślę, że widzieliśmy, jak łatwo jest zrozumieć witrynę dzięki płynnej i semantycznej strukturze adresów URL. Powinniśmy też pamiętać, jak cenna dla Google może być odpowiednia struktura adresu URL.
W przyszłości zobaczymy wielu SEO, którzy będą coraz bardziej zaznajomieni z data science, wizualizacją danych, programowaniem front-end i nie tylko… Widzę ten proces jako początek nieuniknionej zmiany: przepaść między SEO a programistami zostanie całkowicie zamknięta Za kilka lat.
Dzięki Pythonowi możesz posunąć ten rodzaj analizy jeszcze dalej: możliwe jest uzyskanie danych ze zrozumienia poglądów politycznych serwisu informacyjnego, do tego, kto pisze o czym, jak często iz jakimi uczuciami. Wolę nie wchodzić w to tutaj, ponieważ te procesy dotyczą bardziej czystej nauki o danych niż SEO (a ten artykuł jest już dość długi).
Ale jeśli jesteś zainteresowany, istnieje wiele innych rodzajów audytów, które można przeprowadzić za pomocą map witryn i Pythona, takich jak sprawdzanie kodów stanu adresów URL w mapie witryny.
Nie mogę się doczekać eksperymentowania i dzielenia się innymi zadaniami SEO, które możesz wykonać za pomocą Pythona i Advertools.