
Zrozumienie sztucznej inteligencji: jak uczyliśmy komputerów języka naturalnego
Opublikowany: 2023-11-28Wyrażenia „sztuczna inteligencja” używa się w odniesieniu do komputerów od lat pięćdziesiątych XX wieku, ale do ubiegłego roku większość ludzi prawdopodobnie uważała, że sztuczna inteligencja to nadal bardziej science fiction niż rzeczywistość technologiczna.
Pojawienie się ChatGPT OpenAI w listopadzie 2022 r. nagle zmieniło postrzeganie ludzi na temat możliwości uczenia maszynowego – ale co dokładnie było w ChatGPT, co sprawiło, że świat usiadł i zdał sobie sprawę, że sztuczna inteligencja ma tu duże znaczenie?
Jednym słowem język – powodem, dla którego ChatGPT wydawał się tak niezwykłym krokiem naprzód, był fakt, że posługiwał się płynnie językiem naturalnym w sposób, w jaki żaden chatbot nigdy wcześniej nie był.
Oznacza to niezwykły nowy etap „przetwarzania języka naturalnego” (NLP), czyli zdolności komputerów do interpretowania języka naturalnego i generowania przekonujących odpowiedzi. ChatGPT opiera się na „modelu dużego języka” (LLM), który jest rodzajem sieci neuronowej wykorzystującej głębokie uczenie się trenowane na ogromnych zbiorach danych, które mogą przetwarzać i generować treści.
„W jaki sposób program komputerowy osiągnął taką płynność językową?”
Ale jak się tu dostaliśmy? W jaki sposób program komputerowy osiągnął taką płynność językową? Jak to brzmi tak bezbłędnie po ludzku?
ChatGPT nie powstał w próżni – opierał się na niezliczonej liczbie różnych innowacji i odkryć ostatnich dziesięcioleci. Seria przełomowych odkryć, które doprowadziły do powstania ChatGPT, była kamieniami milowymi w informatyce, ale można je postrzegać jako naśladujące etapy, w których ludzie nabywają język.
Jak uczymy się języka?
Aby zrozumieć, w jaki sposób sztuczna inteligencja osiągnęła ten etap, warto zastanowić się nad naturą samej nauki języków – zaczynamy od pojedynczych słów, a następnie łączymy je w dłuższe sekwencje, aż będziemy w stanie przekazać złożone koncepcje, pomysły i instrukcje.
Na przykład niektóre typowe etapy nabywania języka u dzieci to:
- Etap holofrastyczny: w wieku od 9 do 18 miesięcy dzieci uczą się używać pojedynczych słów opisujących ich podstawowe potrzeby lub pragnienia. Komunikowanie się za pomocą jednego słowa oznacza, że kładzie się nacisk na przejrzystość, a nie na kompletność pojęciową. Jeśli dziecko jest głodne, nie powie „Chcę trochę jedzenia” lub „Jestem głodny”, zamiast tego powie po prostu „jedzenie” lub „mleko”.
- Etap dwóch słów: W wieku 18–24 miesięcy dzieci zaczynają używać prostego grupowania dwóch słów, aby poprawić swoje umiejętności komunikacyjne. Teraz mogą komunikować swoje uczucia i potrzeby za pomocą wyrażeń takich jak „więcej jedzenia” lub „przeczytaj książkę”.
- Etap telegraficzny: W wieku 24–30 miesięcy dzieci zaczynają łączyć ze sobą wiele słów, tworząc bardziej złożone frazy i zdania. Liczba używanych słów jest nadal niewielka, ale zaczyna pojawiać się prawidłowa kolejność słów i większa złożoność. Dzieci zaczynają uczyć się podstawowych konstrukcji zdań, takich jak „chcę pokazać mamie”.
- Etap wielu słów: Po 30 miesiącach dzieci zaczynają przechodzić do etapu wielu słów. Na tym etapie dzieci zaczynają używać zdań bardziej poprawnych gramatycznie, złożonych i zawierających wiele zdań. Jest to ostatni etap nabywania języka i dzieci w końcu komunikują się za pomocą złożonych zdań, takich jak „Jeśli będzie padać, chcę zostać w domu i grać w gry”.
Jednym z pierwszych kluczowych etapów przyswajania języka jest umiejętność rozpoczęcia używania pojedynczych słów w bardzo prosty sposób. Zatem pierwszą przeszkodą, którą badacze sztucznej inteligencji musieli pokonać, było nauczenie modeli uczenia się prostych skojarzeń słów.
Model 1 – Nauka pojedynczych słów za pomocą Word2Vec (referat 1 i referat 2)
Jednym z wczesnych modeli sieci neuronowych, który próbował uczyć się w ten sposób skojarzeń słów, był Word2Vec, opracowany przez Tomaša Mikolova i grupę badaczy z Google. W 2013 r. opublikowano go w dwóch artykułach (co pokazuje, jak szybko rozwinęły się sprawy w tej dziedzinie).
Modele te szkolono, ucząc się kojarzenia słów, które były powszechnie używane razem. Podejście to opierało się na intuicji wczesnych pionierów lingwistyki, takich jak John R. Firth, który zauważył, że znaczenie można wyprowadzić ze skojarzeń słów: „Poznacie słowo po towarzystwie, w jakim ono przebywa”.
Chodzi o to, że słowa o podobnym znaczeniu semantycznym częściej występują razem. Słowa „koty” i „psy” zazwyczaj występują razem częściej niż w przypadku słów takich jak „jabłka” czy „komputery”. Innymi słowy, słowo „kot” powinno być bardziej podobne do słowa „pies”, niż „kot” do „jabłko” lub „komputer”.
Interesującą rzeczą w programie Word2Vec jest sposób, w jaki został on przeszkolony w zakresie uczenia się tych skojarzeń słów:
- Odgadnij słowo docelowe: Model otrzymuje stałą liczbę słów jako dane wejściowe, w przypadku braku słowa docelowego i musiał odgadnąć brakujące słowo docelowe. Nazywa się to ciągłym workiem słów (CBOW).
- Odgadnij otaczające słowa: Model otrzymuje jedno słowo, a następnie ma za zadanie odgadnąć otaczające go słowa. Nazywa się to Skip-Gram i stanowi przeciwieństwo CBOW, ponieważ przewidujemy otaczające słowa.
Jedną z zalet tych podejść jest to, że nie trzeba mieć żadnych danych oznaczonych etykietami, aby wytrenować model – etykietowanie danych, na przykład opisywanie tekstu jako „pozytywny” lub „negatywny”, aby nauczyć się analizy nastrojów, jest w końcu powolną i pracochłonną pracą.
Jedną z najbardziej zaskakujących rzeczy w Word2Vec były złożone relacje semantyczne, które uchwycił za pomocą stosunkowo prostego podejścia szkoleniowego. Word2Vec wyprowadza wektory reprezentujące słowo wejściowe. Dokonując operacji matematycznych na tych wektorach, autorzy byli w stanie wykazać, że wektory słów nie tylko przechwytują podobne składniowo elementy, ale także złożone relacje semantyczne.
Relacje te są związane ze sposobem użycia słów. Przykładem, który zauważyli autorzy, był związek między słowami takimi jak „Król” i „Królowa” oraz „Mężczyzna” i „Kobieta”.
Ale chociaż był to krok naprzód, Word2Vec miał ograniczenia. Miało tylko jedną definicję na słowo – na przykład wszyscy wiemy, że „bank” może oznaczać różne rzeczy w zależności od tego, czy planujesz trzymać jeden, czy łowić z niego. Word2Vec nie przejmował się tym, miał tylko jedną definicję słowa „bank” i używał go we wszystkich kontekstach.
Przede wszystkim Word2Vec nie mógł przetwarzać instrukcji ani nawet zdań. Mógł jedynie przyjąć słowo jako dane wejściowe i wyprowadzić „osadzanie słów” lub reprezentację wektorową, której nauczył się dla tego słowa. Aby oprzeć się na tym fundamencie jednego słowa, badacze musieli znaleźć sposób na połączenie dwóch lub większej liczby słów w sekwencję. Możemy sobie wyobrazić, że jest to podobne do etapu przyswajania języka składającego się z dwóch słów.
Model 2 – Nauka sekwencji słów za pomocą RNN i sekwencji tekstu
Kiedy dzieci zaczną opanowywać użycie pojedynczych słów, próbują łączyć je w celu wyrażenia bardziej złożonych myśli i uczuć. Podobnie kolejnym krokiem w rozwoju NLP było rozwinięcie umiejętności przetwarzania sekwencji słów. Problem z przetwarzaniem sekwencji tekstu polega na tym, że nie mają one ustalonej długości. Zdanie może mieć różną długość, od kilku słów do długiego akapitu. Nie cała sekwencja będzie istotna dla ogólnego znaczenia i kontekstu. Musimy jednak być w stanie przetworzyć całą sekwencję, aby wiedzieć, które części są najbardziej istotne.
To właśnie tam pojawiły się rekurencyjne sieci neuronowe (RNN).
Opracowany w latach 90. XX wieku protokół RNN przetwarza dane wejściowe w pętli, w której dane wyjściowe z poprzednich etapów są przesyłane przez sieć podczas iteracji przez każdy krok w sekwencji.
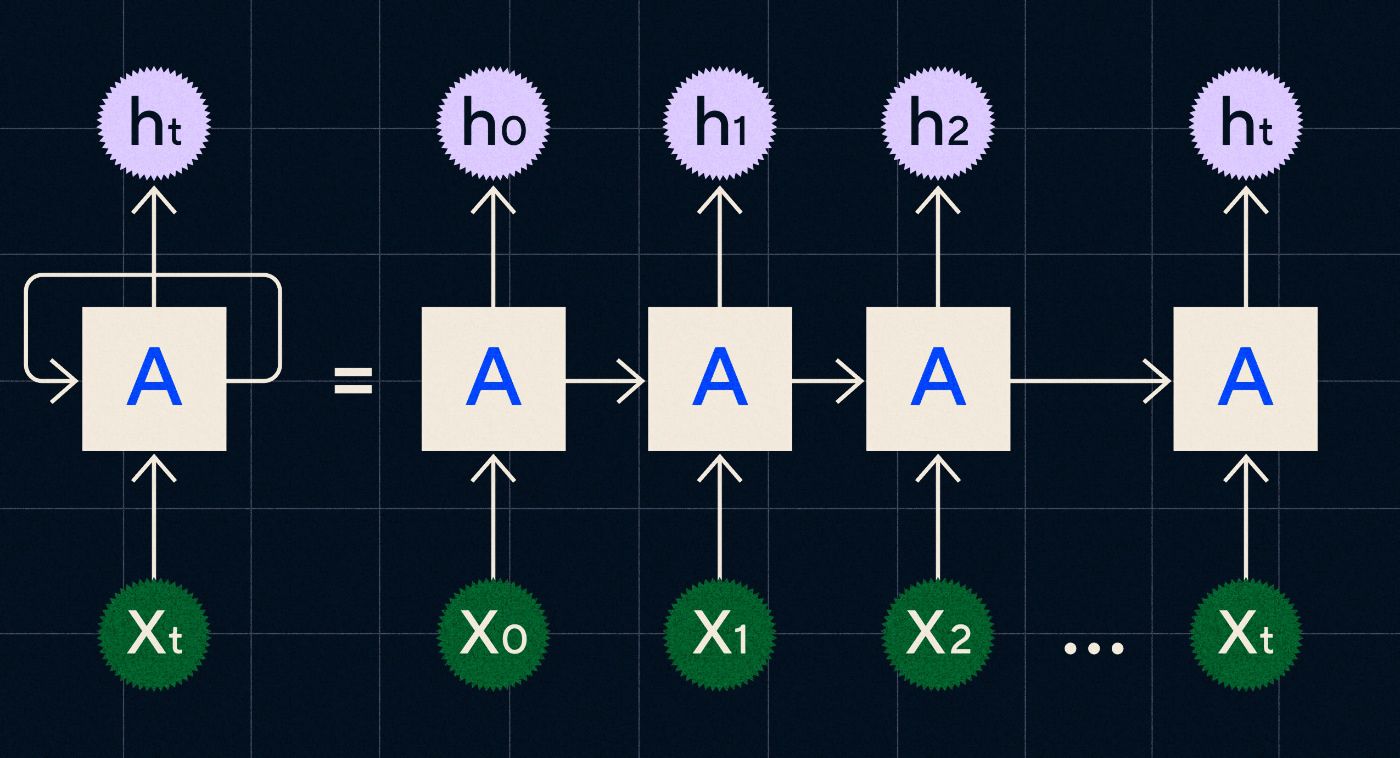
Źródło: wpis na blogu Christophera Olaha na temat RNNs
Powyższy diagram pokazuje, jak zobrazować RNN jako serię sieci neuronowych (A), w których dane wyjściowe z poprzedniego kroku (h0, h1, h2…ht) są przenoszone do następnego kroku. Na każdym etapie nowe dane wejściowe (X0, X1, X2… Xt) są również przetwarzane przez sieć.
Sieci RNN (a konkretnie sieci pamięci długoterminowej lub LSTM, specjalny typ RNN wprowadzony przez Seppa Hochreitera i Jurgena Schmidhubera w 1997 r.) umożliwiły nam stworzenie architektury sieci neuronowych, które mogłyby wykonywać bardziej złożone zadania, takie jak translacja.
W 2014 roku Ilya Sutskever (współzałożyciel OpenAI), Oriol Vinyals i Quoc V Le w Google opublikowali artykuł, w którym opisali modele Sequence to Sequence (Seq2Seq). W artykule pokazano, jak można wytrenować sieć neuronową, aby pobierała tekst wejściowy i zwracała tłumaczenie tego tekstu. Można to traktować jako wczesny przykład generatywnej sieci neuronowej, w której dajesz jej monit, a ona zwraca odpowiedź. Jednak zadanie zostało naprawione, więc jeśli zostało przeszkolone w zakresie tłumaczenia, nie można było go „zachęcić” do zrobienia czegokolwiek innego.
Pamiętaj, że poprzedni model, Word2Vec, mógł przetwarzać tylko pojedyncze słowa. Jeśli więc przekażesz mu zdanie typu „dentysta wyciągnął mi ząb”, po prostu wygeneruje wektor dla każdego słowa, tak jakby nie były ze sobą powiązane.
Jednakże porządek i kontekst są ważne w przypadku zadań takich jak tłumaczenie. Nie możesz po prostu przetłumaczyć pojedynczych słów, musisz przeanalizować sekwencje słów, a następnie wypisać wynik. To tutaj sieci RNN umożliwiły modelom Seq2Seq przetwarzanie słów w ten sposób.
Kluczem do modeli Seq2Seq był projekt sieci neuronowej, w której wykorzystano dwie sieci RNN ustawione jeden po drugim. Jednym z nich był koder, który zamieniał dane wejściowe z tekstu na osadzenie, a drugi był dekoderem, który jako dane wejściowe pobierał osadzania wysyłane przez koder:
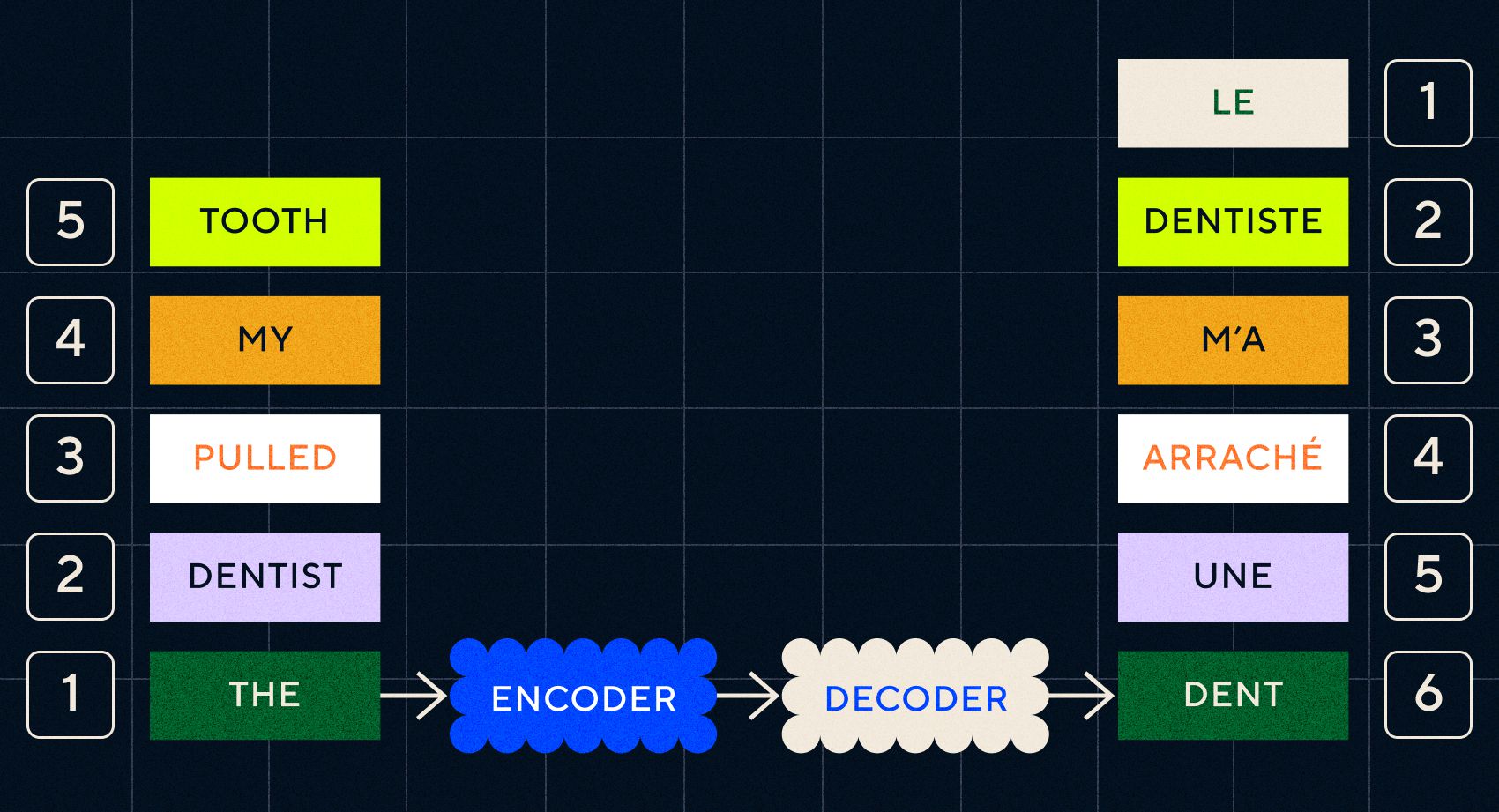
Gdy koder przetworzy dane wejściowe na każdym etapie, rozpoczyna przekazywanie danych wyjściowych do dekodera, który zamienia elementy osadzone w przetłumaczony tekst.
Wraz z ewolucją tych modeli widzimy, że zaczynają one w jakiejś prostej formie przypominać to, co widzimy dzisiaj w przypadku ChatGPT. Jednak możemy również zobaczyć, jak ograniczone były te modele w porównaniu. Podobnie jak w przypadku rozwoju własnego języka, aby naprawdę poprawić umiejętności językowe, musimy dokładnie wiedzieć, na co zwracać uwagę, aby tworzyć bardziej złożone frazy i zdania.
Model 3 – Uczenie się przez uwagę i skalowanie z Transformersami
Zauważyliśmy wcześniej, że na etapie telegraficznym dzieci zaczynają tworzyć krótkie zdania składające się z dwóch lub więcej słów. Jednym z kluczowych aspektów tego etapu nabywania języka jest to, że dzieci zaczynają uczyć się, jak konstruować prawidłowe zdania.
Modele RNN i Seq2Seq pomogły modelom językowym przetwarzać wiele sekwencji słów, ale nadal miały ograniczoną długość zdań, które mogły przetworzyć. W miarę wzrostu długości zdania musimy zwracać uwagę na większość elementów zdania.
Weźmy na przykład następujące zdanie: „W pomieszczeniu było tak duże napięcie, że można je było kroić nożem”. Dużo się tam dzieje. Aby wiedzieć, że nie przecinamy tutaj czegoś dosłownie nożem, musimy połączyć „cięcie” z „napięciem” wcześniej w zdaniu.
W miarę zwiększania się długości zdania coraz trudniej jest określić, które słowa się do których odnoszą, aby wywnioskować właściwe znaczenie. W tym miejscu sieci RNN zaczęły napotykać ograniczenia i potrzebowaliśmy nowego modelu, aby przejść do kolejnego etapu przyswajania języka.
„Pomyśl o próbie podsumowania rozmowy, która staje się coraz dłuższa, przy ustalonym limicie słów. Z każdym krokiem zaczynasz tracić coraz więcej informacji”
W 2017 roku grupa badaczy z Google opublikowała artykuł, w którym zaproponowano technikę umożliwiającą modelom lepsze zwrócenie uwagi na ważny kontekst fragmentu tekstu.
Opracowali sposób, w jaki modele językowe mogły łatwiej wyszukiwać potrzebny kontekst podczas przetwarzania wejściowej sekwencji tekstu. Nazwali to podejście „architekturą transformatorową” i stanowiło ono największy jak dotąd krok naprzód w przetwarzaniu języka naturalnego.
Ten mechanizm wyszukiwania ułatwia modelowi identyfikację, które z poprzednich słów zapewniało większy kontekst dla aktualnie przetwarzanego słowa. Sieci RNN starają się zapewnić kontekst, przekazując na każdym etapie zagregowany stan wszystkich słów, które zostały już przetworzone. Pomyśl o próbie podsumowania rozmowy, która staje się coraz dłuższa, przy ustalonym limicie słów. Z każdym krokiem zaczynasz tracić coraz więcej informacji. Zamiast tego transformatory ważyły słowa (lub tokeny, które nie są całymi słowami, ale ich częściami) w oparciu o ich znaczenie dla bieżącego słowa pod względem jego kontekstu. Ułatwiło to przetwarzanie coraz dłuższych sekwencji słów bez wąskiego gardła występującego w RNN. Ten nowy mechanizm uwagi umożliwił również przetwarzanie tekstu równolegle, a nie sekwencyjnie, jak w przypadku RNN.
Wyobraźmy sobie więc zdanie w stylu: „Zwierzę nie przeszło przez ulicę, bo było zbyt zmęczone”. W przypadku RNN musiałby reprezentować wszystkie poprzednie słowa na każdym kroku. W miarę wzrostu liczby słów między „to” a „zwierzę” RNN staje się coraz trudniejszy w określeniu właściwego kontekstu.

Dzięki architekturze transformatora model ma teraz możliwość wyszukiwania słowa, które najprawdopodobniej odnosi się do „to”. Poniższy diagram pokazuje, jak modele transformatorów potrafią skupić się na „zwierzęcej” części tekstu, próbując przetworzyć zdanie.
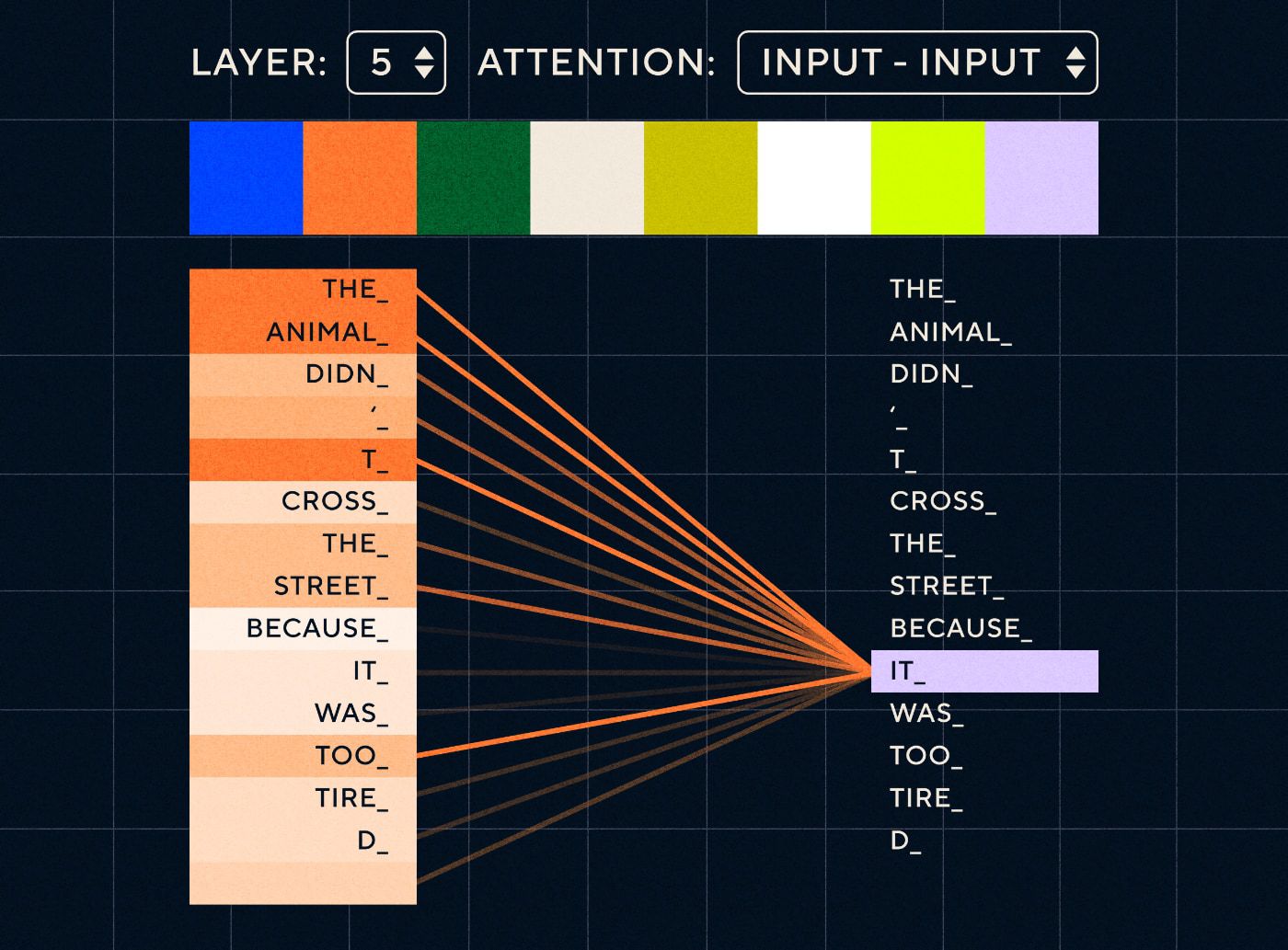
Źródło: Ilustrowany Transformator
Powyższy diagram przedstawia uwagę w warstwie 5 sieci. Na każdej warstwie model pogłębia swoje rozumienie zdania i „zwraca uwagę” na konkretną część danych wejściowych, która jego zdaniem jest bardziej istotna dla etapu, który aktualnie przetwarza, tj. zwierzę” zamiast „tego” w tej warstwie. Źródło: ilustrowany Transformator
Pomyśl o tym jak o bazie danych, z której może pobrać słowo z najwyższym wynikiem, które najprawdopodobniej jest powiązane z „to”.
Dzięki temu rozwojowi modele językowe nie ograniczały się do analizowania krótkich sekwencji tekstowych. Zamiast tego możesz użyć dłuższych sekwencji tekstowych jako danych wejściowych. Wiemy, że kontaktowanie dzieci z większą liczbą słów poprzez „zaangażowaną rozmowę” pomaga poprawić ich rozwój językowy.
Podobnie, dzięki nowemu mechanizmowi uwagi, modele językowe mogły analizować więcej i bardziej zróżnicowanych typów tekstowych danych szkoleniowych. Dotyczyło to artykułów w Wikipedii, forów internetowych, Twittera i wszelkich innych danych tekstowych, które można było przeanalizować. Podobnie jak w przypadku rozwoju dziecka, kontakt ze wszystkimi tymi słowami i ich użycie w różnych kontekstach pomogło modelom językowym rozwinąć nowe i bardziej skomplikowane zdolności językowe.
To właśnie w tej fazie zaczęliśmy obserwować wyścig skalowania, podczas którego ludzie rzucali coraz więcej danych na te modele, aby zobaczyć, czego mogą się nauczyć. Dane te nie musiały być oznaczane przez ludzi – badacze mogli po prostu przeszukać Internet, wprowadzić je do modelu i zobaczyć, czego się nauczyli.
„Modele takie jak BERT pobiły każdy dostępny rekord przetwarzania języka naturalnego. W rzeczywistości zestawy danych testowych użyte do tych zadań były zdecydowanie zbyt proste dla tych modeli transformatorów.
Na szczególną uwagę zasługuje model BERT (ang. Bilateral Encoder Representations from Transformers) z kilku powodów. Był to jeden z pierwszych modeli wykorzystujących funkcję uwagi, stanowiącą rdzeń architektury Transformer. Po pierwsze, BERT działał dwukierunkowo, ponieważ mógł przeglądać tekst zarówno po lewej, jak i po prawej stronie bieżącego wejścia. Różniło się to od RNN, które mogły przetwarzać tekst tylko sekwencyjnie od lewej do prawej. Po drugie, BERT zastosował także nową technikę uczenia zwaną „maskowaniem”, która w pewnym sensie zmusiła model do poznania znaczenia różnych danych wejściowych poprzez „ukrywanie” lub „maskowanie” losowych żetonów, aby mieć pewność, że model nie będzie mógł „oszukiwać” i skoncentruj się na jednym tokenie w każdej iteracji. I wreszcie BERT można dostosować do wykonywania różnych zadań NLP. Do tych zadań nie trzeba było go szkolić od podstaw.
Wyniki były niesamowite. Modele takie jak BERT pobiły każdy dostępny rekord przetwarzania języka naturalnego. W rzeczywistości zestawy danych testowych użyte do tych zadań były zdecydowanie zbyt proste dla tych modeli transformatorów.
Teraz mieliśmy możliwość uczenia dużych modeli językowych, które posłużyły jako modele podstawowe dla nowych zadań przetwarzania języka naturalnego. Wcześniej ludzie przeważnie szkolili swoje modele od zera. Ale teraz wstępnie wytrenowane modele, takie jak BERT i wczesne modele GPT, były tak dobre, że nie było sensu robić tego samodzielnie. W rzeczywistości modele te były tak dobre, że ludzie odkryli, że mogą wykonywać nowe zadania na podstawie stosunkowo niewielkiej liczby przykładów – opisywano ich jako „uczniów z małą liczbą strzałów”, podobnie jak większość ludzi nie potrzebuje zbyt wielu przykładów, aby zrozumieć nowe koncepcje.
Był to ogromny punkt zwrotny w rozwoju tych modeli i ich możliwości językowych. Teraz musieliśmy po prostu lepiej radzić sobie z instrukcjami rzemieślniczymi.
Model 4 – Nauka instrukcji z InstructGPT
Jedną z rzeczy, których dzieci uczą się na ostatnim etapie przyswajania języka, na etapie wielowyrazowym, jest umiejętność używania słów funkcyjnych do łączenia elementów niosących informację w zdaniu. Słowa funkcyjne mówią nam o związku między różnymi słowami w zdaniu. Jeśli chcemy tworzyć instrukcje, modele językowe będą musiały być w stanie tworzyć zdania zawierające słowa treści i słowa funkcyjne, które oddają złożone relacje. Na przykład w poniższej instrukcji słowa funkcyjne wyróżniono pogrubioną czcionką:
- „ Chcę , żebyś napisał list…”
- „Powiedz mi , co myślisz o powyższym tekście”
Zanim jednak mogliśmy spróbować wyszkolić modele językowe, aby postępowały zgodnie z instrukcjami, musieliśmy dokładnie zrozumieć, co już wiedzieli o instrukcjach.
OpenAI GPT-3 został wydany w 2020 roku. Był to rzut oka na możliwości tych modeli, ale nadal musieliśmy zrozumieć, jak odblokować podstawowe możliwości tych modeli. Jak moglibyśmy wejść w interakcję z tymi modelami, aby nakłonić je do wykonania różnych zadań?
Na przykład GPT-3 pokazał, że zwiększenie rozmiaru modelu i danych szkoleniowych umożliwiło to, co autorzy nazwali „meta-uczeniem się” – w tym przypadku model językowy rozwija szeroki zestaw umiejętności językowych, z których wiele było nieoczekiwanych, i może je wykorzystać umiejętności zrozumienia danego zadania.
„Czy model byłby w stanie zrozumieć intencję instrukcji i wykonać zadanie, zamiast po prostu przewidywać następne słowo?”
Pamiętaj, że modele językowe GPT-3 i wcześniejsze nie zostały zaprojektowane do rozwijania tych umiejętności – szkolono je głównie tak, aby po prostu przewidywały następne słowo w sekwencji tekstu. Jednak dzięki postępom w zakresie sieci RNN, Seq2Seq i sieci uwagi modele te były w stanie przetwarzać więcej tekstu w dłuższych sekwencjach i lepiej skupiać się na odpowiednim kontekście.
Możesz myśleć o GPT-3 jako o teście, aby zobaczyć, jak daleko możemy to zajść. Jak duże moglibyśmy zrobić modele i ile tekstu moglibyśmy w nich umieścić? Następnie, zamiast po prostu podawać modelowi tekst wejściowy do uzupełnienia, moglibyśmy użyć tekstu wejściowego jako instrukcji. Czy model byłby w stanie zrozumieć intencję instrukcji i wykonać zadanie, zamiast po prostu przewidywać następne słowo? W pewnym sensie przypominało to próbę zrozumienia, na jakim etapie przyswajania języka osiągnęły te modele.
Obecnie określamy to jako „podpowiadające”, ale w 2020 r., kiedy ukazał się artykuł, była to bardzo nowa koncepcja.
Halucynacje i wyrównanie
Jak wiemy, problem z GPT-3 polegał na tym, że nie radził sobie zbyt dobrze z instrukcjami zawartymi w tekście wejściowym. GPT-3 potrafi wykonywać instrukcje, ale łatwo traci uwagę, rozumie jedynie proste instrukcje i ma tendencję do zmyślania. Innymi słowy, modele nie są „dopasowane” do naszych intencji. Zatem problem nie polega teraz tak bardzo na poprawie umiejętności językowych modeli, ale raczej na ich zdolności do wykonywania instrukcji.
Warto zauważyć, że GPT-3 nigdy tak naprawdę nie był szkolony według instrukcji. Nie powiedziano, czym jest instrukcja, czym różni się od innego tekstu lub w jaki sposób ma postępować zgodnie z instrukcjami. W pewnym sensie został „oszukany” i nakłonił go do „ukończenia” podpowiedzi, tak jak w przypadku innych sekwencji tekstu. W rezultacie OpenAI musiało wytrenować model, który byłby w stanie lepiej wykonywać instrukcje jak człowiek. Zrobili to w artykule trafnie zatytułowanym Szkolenie modeli językowych w zakresie postępowania zgodnie z instrukcjami na podstawie opinii ludzi, opublikowanym na początku 2022 r. InstructGPT okazał się prekursorem ChatGPT jeszcze w tym samym roku.
Kroki opisane w tym dokumencie zostały również wykorzystane do szkolenia ChatGPT. Szkolenie instruktażowe składało się z 3 głównych etapów:
- Krok 1 – Dopracuj GPT-3: Ponieważ GPT-3 wydawał się dobrze radzić sobie z nauką w kilku krokach, uznano, że byłoby lepiej, gdyby został dostrojony na podstawie wysokiej jakości przykładów instrukcji. Celem było ułatwienie dostosowania intencji zawartej w instrukcji do wygenerowanej odpowiedzi. Aby to zrobić, OpenAI poprosił ludzi zajmujących się etykietowaniem o utworzenie odpowiedzi na niektóre pytania przesłane przez osoby korzystające z GPT-3. Używając prawdziwych instrukcji, autorzy mieli nadzieję uchwycić realistyczny „rozkład” zadań, do wykonania których użytkownicy próbowali zmusić GPT-3. Wykorzystano je do dostrojenia GPT-3, aby poprawić jego zdolność szybkiego reagowania.
- Krok 2 – Poproś ludzi o ocenę nowego i ulepszonego GPT-3: Aby ocenić nową, udoskonaloną instrukcję GPT-3, osoby zajmujące się etykietowaniem oceniały teraz wydajność modeli na podstawie różnych podpowiedzi, bez z góry określonej odpowiedzi. Ranking został powiązany z ważnymi czynnikami dopasowania, takimi jak bycie pomocnym, zgodnym z prawdą oraz nietoksycznym, stronniczym lub szkodliwym. Daj więc modelowi zadanie i oceń jego wydajność na podstawie tych wskaźników. Wyniki tego zadania rankingowego wykorzystano następnie do wyszkolenia oddzielnego modelu w celu przewidzenia, które wyniki będą prawdopodobnie preferowane przez osoby zajmujące się etykietowaniem. Model ten nazywany jest modelem nagrody (RM).
- Krok 3 – Wykorzystaj RM do szkolenia na większej liczbie przykładów: Wreszcie RM wykorzystano do szkolenia nowego modelu instrukcji w celu lepszego generowania odpowiedzi zgodnych z ludzkimi preferencjami.
Trudno jest w pełni zrozumieć, co się tutaj dzieje w przypadku uczenia się przez wzmacnianie na podstawie informacji zwrotnej od ludzi (RLHF), modeli wynagrodzeń, aktualizacji zasad i tak dalej.
Można o tym najprościej pomyśleć: jest to po prostu sposób na umożliwienie ludziom generowania lepszych przykładów postępowania zgodnie z instrukcjami. Zastanów się na przykład, jak próbowałbyś nauczyć dziecko dziękować:
- Rodzic: „Kiedy ktoś daje ci X, mówisz dziękuję”. To jest krok 1, przykładowy zbiór danych zawierający podpowiedzi i odpowiednie odpowiedzi
- Rodzic: „Co teraz powiesz Y?”. To jest krok 2, w którym prosimy dziecko o wygenerowanie odpowiedzi, a następnie rodzic ją oceni. "Tak to jest dobre."
- Wreszcie, podczas kolejnych spotkań rodzic będzie nagradzał dziecko na podstawie dobrych lub złych przykładów reakcji w podobnych scenariuszach w przyszłości. To jest krok 3, w którym ma miejsce zachowanie wzmacniające.
Ze swojej strony OpenAI twierdzi, że jedyne, co robi, to po prostu odblokowywanie możliwości, które były już obecne w modelach takich jak GPT-3, „ale były trudne do uzyskania jedynie poprzez szybką inżynierię”, jak to ujęto w artykule.
Innymi słowy, ChatGPT tak naprawdę nie uczy się „ nowych ” możliwości, ale po prostu uczy się lepszego „ interfejsu ” językowego, aby z nich korzystać.
Magia języka
ChatGPT wydaje się magicznym krokiem naprzód, ale w rzeczywistości jest wynikiem żmudnego postępu technologicznego na przestrzeni dziesięcioleci.
Patrząc na niektóre z najważniejszych osiągnięć w dziedzinie sztucznej inteligencji i NLP w ostatniej dekadzie, możemy zobaczyć, jak ChatGPT „stoi na ramionach gigantów”. Wcześniejsze modele najpierw nauczyły się identyfikować znaczenie słów. Następnie kolejne modele łączyły te słowa w całość i mogliśmy je wyszkolić do wykonywania zadań takich jak tłumaczenie. Kiedy już potrafili przetwarzać zdania, opracowaliśmy techniki, które umożliwiły tym modelom językowym przetwarzanie coraz większej ilości tekstu i rozwijanie umiejętności stosowania zdobytej wiedzy do nowych i nieprzewidzianych zadań. Następnie dzięki ChatGPT w końcu opracowaliśmy możliwość lepszej interakcji z tymi modelami, określając nasze instrukcje w formacie języka naturalnego.
„Ponieważ język jest nośnikiem naszych myśli, czy uczenie komputerów pełnej mocy języka doprowadzi do powstania niezależnej sztucznej inteligencji?”
Jednak ewolucja NLP ujawnia głębszą magię, na którą zwykle jesteśmy ślepi – magię samego języka i tego, jak my, ludzie, go nabywamy.
Nadal istnieje wiele otwartych pytań i kontrowersji dotyczących tego, w jaki sposób dzieci uczą się języka. Pojawiają się również pytania o to, czy istnieje wspólna struktura leżąca u podstaw wszystkich języków. Czy ludzie ewoluowali tak, aby używać języka, czy jest odwrotnie?
Ciekawostką jest to, że w miarę jak ChatGPT i jego potomkowie poprawiają swój rozwój językowy, modele te mogą pomóc w odpowiedzi na niektóre z tych ważnych pytań.
Wreszcie, skoro język jest nośnikiem naszych myśli, czy uczenie komputerów pełnej mocy języka doprowadzi do powstania niezależnej sztucznej inteligencji? Jak zawsze w życiu, jest jeszcze wiele do nauczenia się.
