
Hakowanie wykresu tematu za pomocą Wikipedii i interfejsu Google Language API
Opublikowany: 2019-08-27Jeden z moich ulubionych decków do slajdów z ostatnich dziesięciu lat został wykonany przez Marka Johnstone'a w 2014 roku, kiedy był jeszcze w Distilled. Talia nazywała się Jak tworzyć lepsze pomysły na treści i przez kilka lat używałam jej jako mojej biblii, budując zespoły do ciężkiej pracy związanej z promocją treści.
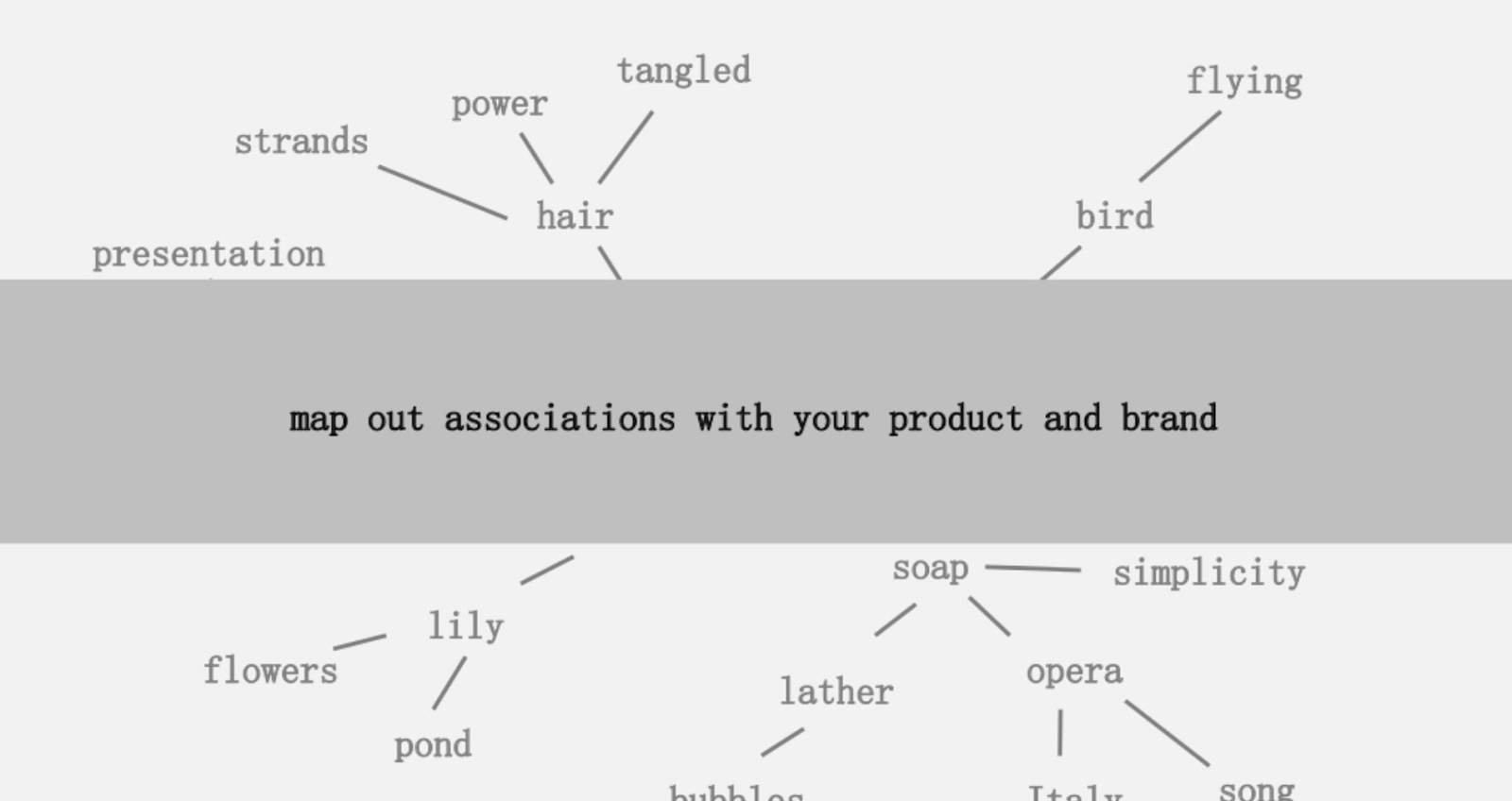
Jednym z zaproponowanych pomysłów było stworzenie wizualnego odwzorowania powiązań słów związanych z Twoim produktem lub marką, tak abyś mógł się cofnąć i poszukać sposobów na połączenie skojarzeń w coś interesującego. Celem jest produkcja pomysłów, które definiuje jako „ nowe połączenie wcześniej niepołączonych elementów w sposób, który dodaje wartości”.
W tym artykule przyjmiemy znacznie bardziej lewostronne podejście, używając Pythona, Google Language API, wraz z Wikipedią, aby zbadać powiązania encji, które istnieją z tematu źródłowego. Celem jest widok wysokiego poziomu relacji jednostek na wykresie tematycznym. Ten artykuł nie jest dla przeciętnego czytelnika. Czytelnicy, którzy są zaznajomieni z Pythonem i mają przynajmniej podstawowy poziom umiejętności kodowania, uznają go za znacznie bardziej pouczający.
Pomysł
Podążając za pomysłem Marka Johnstone'a na mapowanie, pomyślałem, że byłoby interesujące pozwolić Google i Wikipedii zdefiniować strukturę tematu, zaczynając od tematu źródłowego lub strony internetowej. Celem jest wizualne zbudowanie mapowania relacji z głównym tematem na wykresie przypominającym drzewo, który można przeglądać w poszukiwaniu połączeń i ewentualnie generować pomysły dotyczące treści. Poniższy obraz przedstawia wstępny pomysł na projekt.
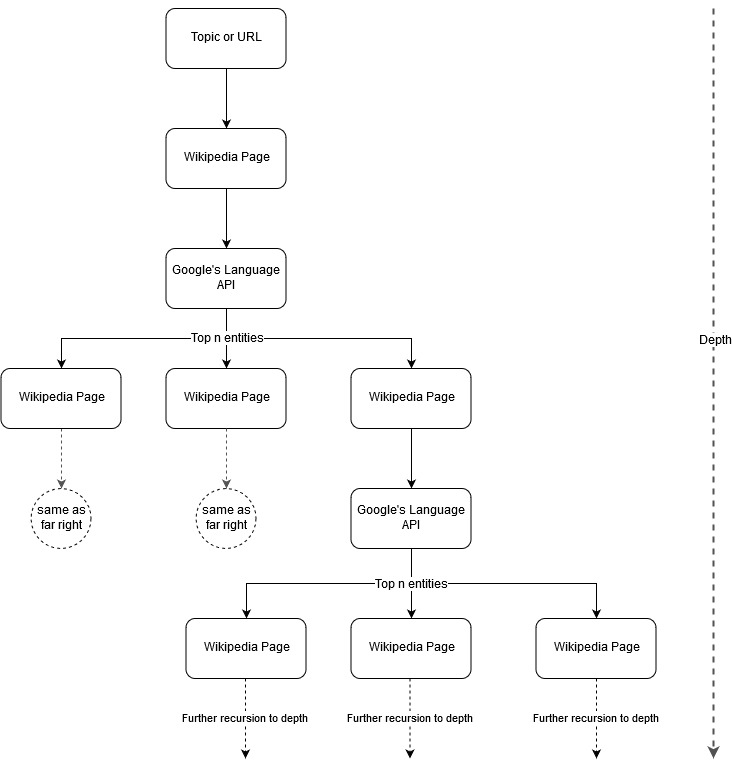
Zasadniczo nadajemy narzędziu temat lub adres URL i pozwalamy interfejsowi API języka Google wybrać pierwsze n (3 w naszych przykładach) encje (w tym adresy URL Wikipedii) dla każdej strony encji, a my rekursywnie tworzymy wykres sieci dla każdej znalezionej encji do maksymalnej głębokości.
Tło używanych narzędzi
Interfejs API języka Google
Interfejs API języka Google pozwala na przekazywanie go w postaci zwykłego tekstu lub kodu HTML i w magiczny sposób zwraca wszystkie różne jednostki powiązane z treścią. API robi więcej, ale w tej analizie skupimy się tylko na tej części. Oto lista typów encji, które zwraca:
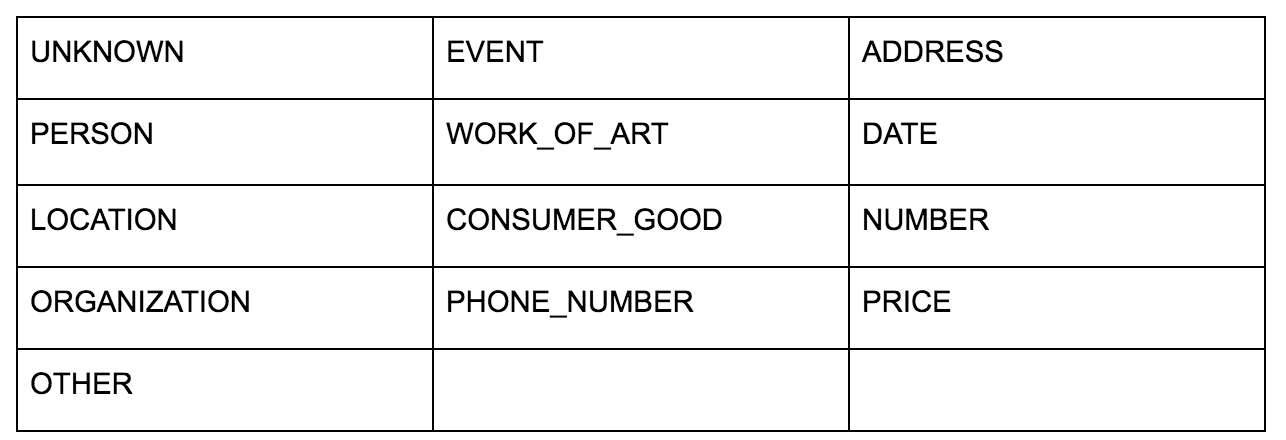
Identyfikacja jednostek od dawna jest fundamentalną częścią przetwarzania języka naturalnego (NLP), a poprawną terminologią dla tego zadania jest nazwane rozpoznawanie jednostek (NER). NER jest trudnym zadaniem, ponieważ wiele słów ma różne znaczenia w zależności od użytego kontekstu, więc narzędzia NLP lub interfejsy API muszą zrozumieć pełny kontekst otaczający terminy, aby móc prawidłowo zidentyfikować je jako konkretną jednostkę.
Dałem dość szczegółowy przegląd tego API, a w szczególności encji, w artykule na opensource.com, jeśli chcesz poznać kontekst przed zakończeniem tego artykułu.
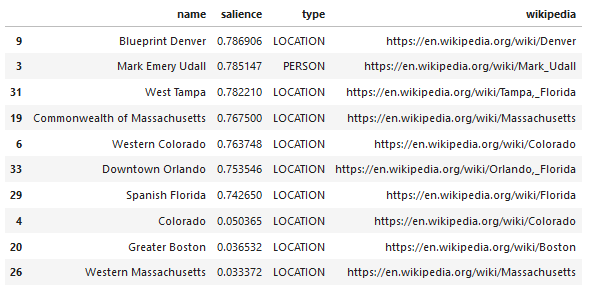
Jedną z interesujących funkcji interfejsu Google Language API jest, oprócz znajdowania odpowiednich jednostek, oznaczanie również ich powiązania z całym dokumentem (salience), a dla niektórych dostarcza powiązany artykuł z Wikipedii (wykres wiedzy) reprezentujący jednostkę.
Oto przykładowe dane wyjściowe zwracane przez interfejs API (posortowane według istotności):
Programista Oncrawl
 Ucz się więcej
Ucz się więcejPyton
Python to język oprogramowania, który stał się popularny w przestrzeni nauki o danych ze względu na duży i rosnący zestaw bibliotek, które ułatwiają przyjmowanie, czyszczenie, manipulowanie i analizowanie dużych zbiorów danych. Korzysta również ze środowiska współpracy zwanego notatnikami Jupyter, które umożliwia użytkownikom łatwe testowanie i opisywanie kodu w bezproblemowy sposób.
W tej recenzji użyjemy kilku kluczowych bibliotek, które pozwolą nam zrobić kilka interesujących rzeczy z danymi NLP Google.
- Pandy: Pomyśl o możliwości napisania skryptu w programie Microsoft Excel, aby czytać, zapisywać, analizować lub zmieniać kolejność arkuszy kalkulacyjnych, a zorientujesz się, co robi Pandy. Pandy są niesamowite. (połączyć)
- Networkx: Networkx to narzędzie do konstruowania wykresów węzłów i krawędzi, które definiują relacje między węzłami. Posiada również wbudowaną obsługę kreślenia wykresów, dzięki czemu można je łatwo wizualizować. (połączyć)
- Pywikibot: Pywikibot to biblioteka, która umożliwia interakcję z Wikipedią w celu wyszukiwania, edytowania, znajdowania relacji itp. z całą zawartością każdej witryny Wikipedii. (połączyć)
Proces
Udostępniamy tutaj notatnik Google Colab, którego można używać do śledzenia. (Specjalne podziękowania dla Tylera Reardona za sprawdzenie stanu zdrowia w artykule i tym notatniku.)
Konfiguracja
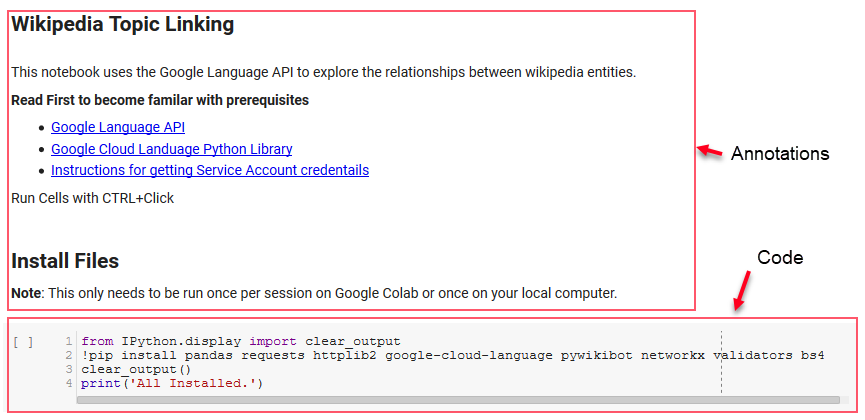
Kilka pierwszych komórek w notatniku zajmuje się instalowaniem niektórych bibliotek, udostępnianiem tych bibliotek Pythonowi oraz dostarczaniem poświadczeń i pliku konfiguracyjnego odpowiednio dla Google Language API i Pywikibot. Oto wszystkie biblioteki, które musimy zainstalować, aby narzędzie mogło działać:
- pandy
- upraszanie
- httplib2
- google-chmura-język
- pywikibot
- siećx
- walidatory
- Bs4
Uwaga: najtrudniejszą częścią uruchomienia tego notatnika jest uzyskanie danych logowania od Google w celu uzyskania dostępu do ich interfejsów API. Dla tych, którzy nie mają w tym doświadczenia, zajmie to około godziny. Połączyliśmy instrukcje uzyskiwania poświadczeń konta usługi w górnej części notesu, aby Ci pomóc. Poniżej znajduje się przykład, w jaki sposób uwzględniliśmy nasze.
Funkcje dla zwycięstwa
W komórce wskazanej przez „Zdefiniuj niektóre funkcje dla Google NLP” opracowujemy osiem funkcji, które obsługują takie rzeczy, jak wysyłanie zapytań do interfejsu API języka, interakcja z Wikipedią, wyodrębnianie tekstu ze strony internetowej oraz budowanie i kreślenie wykresów. Funkcje są zasadniczo małymi jednostkami kodu, które pobierają pewne dane ustawień, wykonują pewną pracę i coś produkują. Wszystkie funkcje są skomentowane, aby powiedzieć, jakie zmienne przyjmują i co produkują.

Testowanie API
Poniższe dwie komórki pobierają adres URL, wyodrębniają tekst z adresu URL i pobierają jednostki z interfejsu Google Language API. Jeden pobiera tylko jednostki, które mają adresy URL Wikipedii, a drugi pobiera wszystkie jednostki z tej strony.
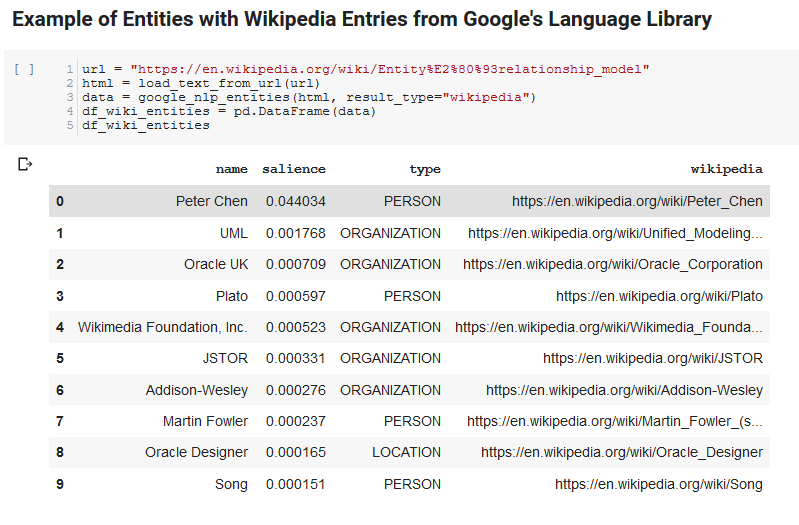
Był to ważny pierwszy krok, aby uzyskać poprawną część ekstrakcji treści i zrozumieć, jak działa interfejs API języka i zwraca dane.
Siećx
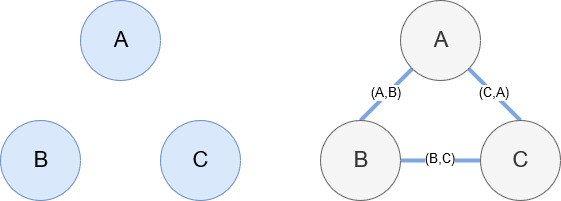
Networkx, jak wspomniano wcześniej, jest cudowną biblioteką, z którą można się dość intuicyjnie bawić. Zasadniczo musisz powiedzieć mu, jakie są twoje węzły i jak są połączone. Na przykład na poniższym obrazku podajemy Networkx trzy węzły (A,B,C). Następnie mówimy Networkx, że są połączone krawędziami (A,B), (B,C), (C,A) definiując relacje między węzłami. Do naszego użytku encje z adresami URL Wikipedii będą węzłami, a krawędzie są definiowane przez nowe encje znalezione na bieżącej stronie encji. Tak więc, jeśli przeglądamy stronę Wikipedii pod kątem jednostki A i na tej stronie odkryto jednostkę B, to jest to przepaść między jednostką A i jednostką B.
Kładąc wszystko razem
Następna sekcja notatnika nosi nazwę Rozgałęzienie tematów Wikipedii według adresu URL. Tutaj dzieje się magia. Wcześniej zdefiniowaliśmy specjalną funkcję (recurse_entities), która przechodzi rekursywnie przez strony w Wikipedii, podążając za nowymi jednostkami zdefiniowanymi przez Google Language API. Dodaliśmy również naprawdę niezręczną do zrozumienia funkcję (hierarchy_pos), którą pobraliśmy ze Stack Overflow, która dobrze radzi sobie z prezentowaniem wykresu przypominającego drzewo z wieloma węzłami. W komórce poniżej definiujemy dane wejściowe jako „Optymalizacja pod kątem wyszukiwarek” i określamy głębokość 3 (jest to liczba stron, które śledzi rekursywnie) oraz limit 3 (jest to liczba encji, które pobiera na stronę).
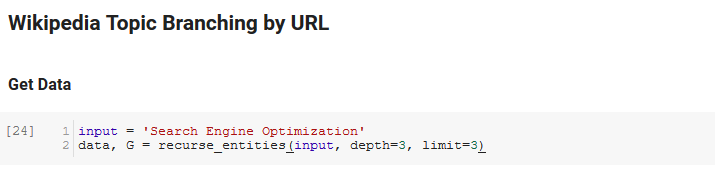
Uruchamiając go dla terminu „Search Engine Optimization” możemy zobaczyć następującą ścieżkę, którą obrało narzędzie, zaczynając od strony Wikipedii Search Engine Optimization (poziom 0) i podążając rekursywnie, strony do określonej maksymalnej głębokości (3).

Następnie bierzemy wszystkie znalezione encje i dodajemy je do Pandas DataFrame, co bardzo ułatwia zapisywanie jako plik CSV. Sortujemy te dane według istotności (czyli tego, jak ważna jest encja dla strony, na której została znaleziona), ale ten wynik jest nieco mylący w tym kontekście, ponieważ nie mówi, jak powiązana jest encja z pierwotnym terminem („ Optymalizacja wyszukiwarki"). Tę dalszą pracę pozostawiamy czytelnikowi.

Na koniec tworzymy wykres zbudowany przez narzędzie, aby pokazać powiązanie wszystkich podmiotów. W komórce poniżej parametry, które można przekazać do funkcji to: ( G : Wykres zbudowany wcześniej przez funkcję recurse_entities, w: szerokość wykresu, h: wysokość wykresu, c: okrąg procentowy wykres i nazwa pliku: plik PNG zapisany w folderze obrazów.)

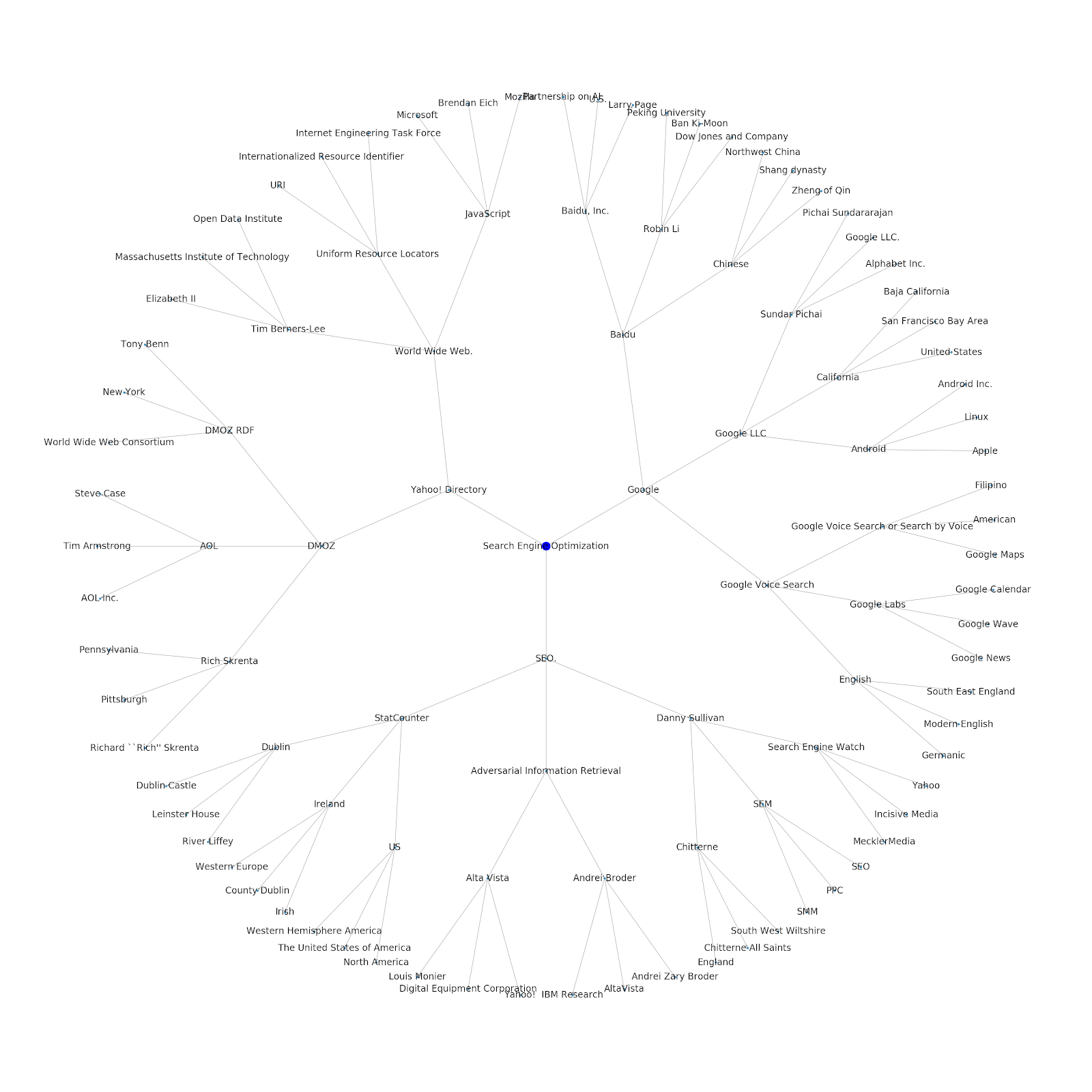
Dodaliśmy możliwość nadania mu początkowego tematu lub początkowego adresu URL. W tym przypadku przyjrzymy się podmiotom powiązanym z artykułem Problemy z indeksowaniem Google dalej, ale ten jest inny
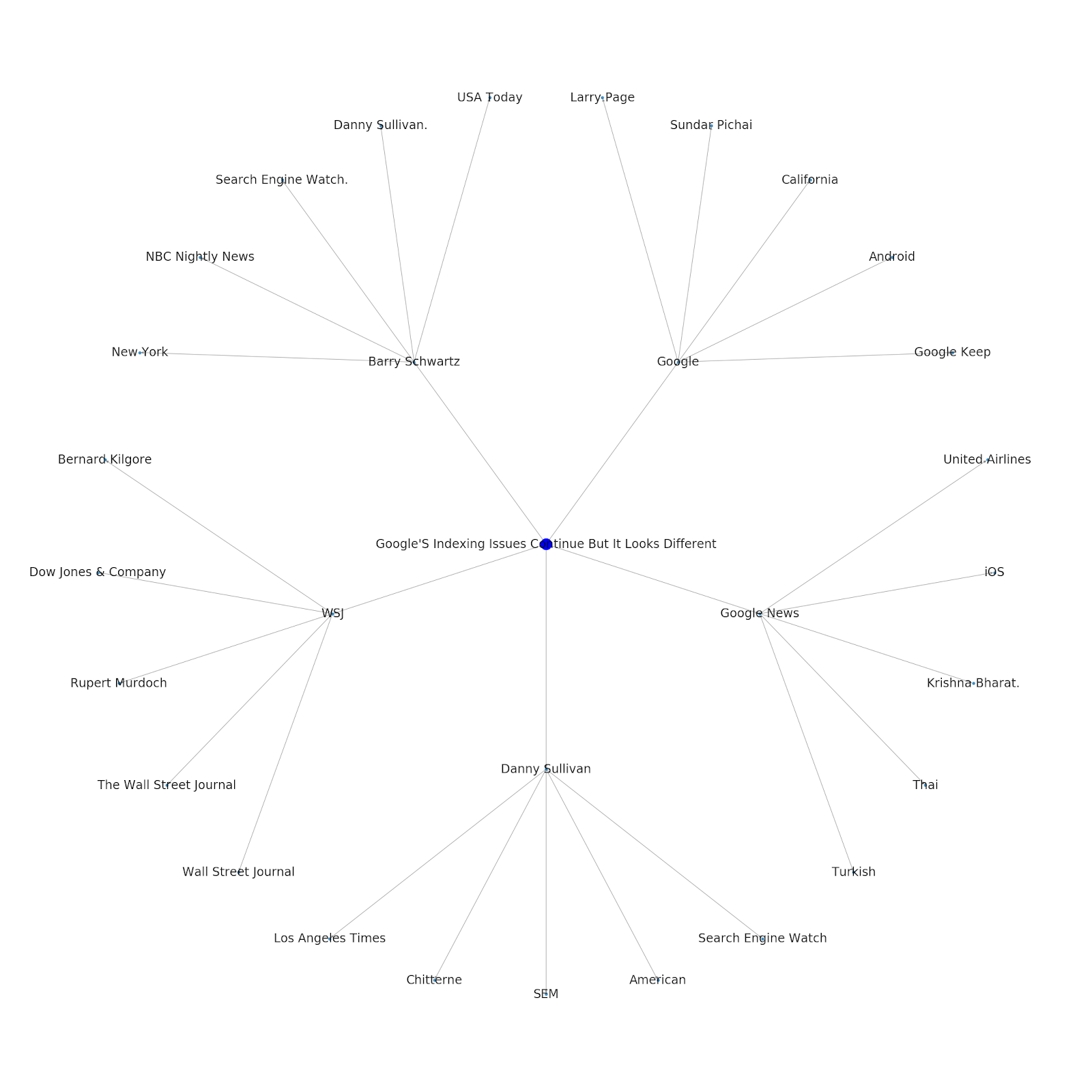
Oto wykres encji Google/Wikipedia dla Pythona.
Co to znaczy
Zrozumienie warstwy tematycznej Internetu jest interesujące z punktu widzenia SEO, ponieważ zmusza do myślenia w kategoriach tego, jak rzeczy są połączone, a nie tylko na podstawie indywidualnych zapytań. Ponieważ Google używa tej warstwy, aby dopasować podobieństwa poszczególnych użytkowników do tematów, jak wspomniano we wprowadzeniu do Google Discover, może to stać się ważniejszym przepływem pracy dla SEO skoncentrowanych na danych. Na powyższym wykresie „Python” można wywnioskować, że znajomość przez użytkownika tematów związanych z tematem źródłowym może być rozsądną miarą jego poziomu wiedzy w temacie źródłowym.
Poniższy przykład pokazuje dwóch użytkowników z zielonymi podświetleniami wskazującymi ich zainteresowania historyczne lub powiązania z powiązanymi tematami. Użytkownik po lewej, rozumiejący, czym jest IDE i rozumiejący, co oznaczają PyPy i CPython, byłby znacznie bardziej doświadczonym użytkownikiem Pythona niż ktoś, kto wie, że jest to język, ale niewiele więcej. Byłoby to łatwe do przekształcenia w wyniki liczbowe dla każdego tematu, dla każdego użytkownika.

Wniosek
Moim dzisiejszym celem było podzielenie się dość standardowym procesem, przez który przechodzę, aby przetestować i sprawdzić skuteczność różnych narzędzi lub interfejsów API przy użyciu notebooków Jupyter. Eksploracja wykresu tematycznego jest niezwykle interesująca i mamy nadzieję, że udostępnione narzędzia zapewnią Ci przewagę na starcie, aby rozpocząć samodzielne odkrywanie. Za pomocą tych narzędzi możesz tworzyć wykresy tematyczne, które badają wiele poziomów relacji, ograniczonych jedynie do limitu Google Language API (który wynosi 800 000 dziennie). (Aktualizacja: cena jest oparta na jednostkach 1000 znaków Unicode wysyłanych do interfejsu API i jest bezpłatna do 5 tys. jednostek. Ponieważ artykuły w Wikipedii mogą być długie, chcesz uważać na swoje wydatki. Napiwek dla Johna Murcha za wskazanie tego.) Jeśli ulepszycie notes lub znajdziecie ciekawe etui, mam nadzieję, że dacie mi znać. Możesz mnie znaleźć na @jroakes na Twitterze.