
Klucze do budowania działającego pliku Robots.txt
Opublikowany: 2020-02-18Boty, znane również jako Crawlers lub Spiders, to programy, które „przemieszczają się” w sieci automatycznie od strony internetowej do strony internetowej, wykorzystując linki jako drogę. Chociaż zawsze przedstawiały pewne ciekawostki, pliki robot.txt mogą być bardzo skutecznymi narzędziami. Wyszukiwarki, takie jak Google i Bing, używają botów do indeksowania treści internetowych. Plik robots.txt zawiera wskazówki dla różnych botów, których stron nie powinny indeksować w Twojej witrynie. Możesz także utworzyć link do mapy witryny XML z pliku robots.txt, aby bot miał mapę każdej strony, którą powinien zaindeksować.
Dlaczego plik robots.txt jest przydatny?
robots.txt ogranicza ilość stron, które bot musi przemierzać i indeksować w przypadku botów wyszukiwarek. Jeśli chcesz, aby Google nie indeksowało stron administracyjnych, możesz zablokować je w swoim pliku robots.txt, aby zapobiec przedostawaniu się strony do serwerów Google.
Oprócz zapobiegania indeksowaniu stron, plik robots.txt doskonale nadaje się do optymalizacji pod kątem budżetu indeksowania. Budżet indeksowania to liczba stron, które według Google będą indeksowane w Twojej witrynie. Zazwyczaj witryny o większym autorytecie i większej liczbie stron mają większy budżet indeksowania niż witryny o małej liczbie stron i niskim autorytecie. Ponieważ nie wiemy, jaki budżet indeksowania jest przypisany do naszej witryny, chcemy jak najlepiej wykorzystać ten czas, umożliwiając Googlebotowi dostęp do najważniejszych stron zamiast indeksowania stron, których nie chcemy indeksować.
Bardzo ważnym szczegółem, który musisz wiedzieć o pliku robots.txt, jest to, że chociaż Google nie będzie indeksować stron zablokowanych przez plik robots.txt, mogą one zostać zaindeksowane, jeśli strona zawiera link z innej witryny. Aby prawidłowo uniemożliwić indeksowanie stron i wyświetlanie ich w wynikach wyszukiwania Google, należy zabezpieczyć hasłem pliki na serwerze, użyć metatagu noindex lub nagłówka odpowiedzi albo całkowicie usunąć stronę (odpowiedź 404 lub 410). Więcej informacji na temat indeksowania i kontrolowania indeksowania można znaleźć w przewodniku po pliku robots.txt firmy OnCrawl.
[Studium przypadku] Zarządzanie indeksowaniem botów Google
 Przeczytaj studium przypadku
Przeczytaj studium przypadkuPrawidłowa składnia pliku Robots.txt
Składnia pliku robots.txt może być czasami nieco trudna, ponieważ różne roboty indeksujące różnie interpretują składnię. Ponadto niektóre nierenomowane roboty indeksujące traktują dyrektywy w pliku robots.txt jako sugestie, a nie jako definitywną zasadę, której muszą przestrzegać. Jeśli masz poufne informacje w swojej witrynie, ważne jest, aby oprócz blokowania robotów indeksujących za pomocą pliku robots.txt stosować ochronę hasłem
Poniżej wymieniłem kilka rzeczy, o których należy pamiętać podczas pracy nad plikiem robots.txt:
- Plik robots.txt musi znajdować się w domenie, a nie w podkatalogu. Roboty indeksujące nie sprawdzają plików robots.txt w podkatalogach.
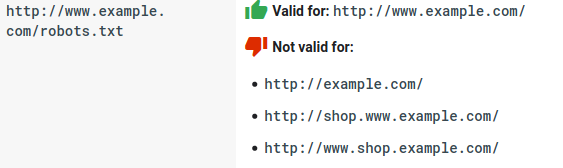
- Każda subdomena potrzebuje własnego pliku robots.txt:
- W pliku Robots.txt rozróżniana jest wielkość liter:
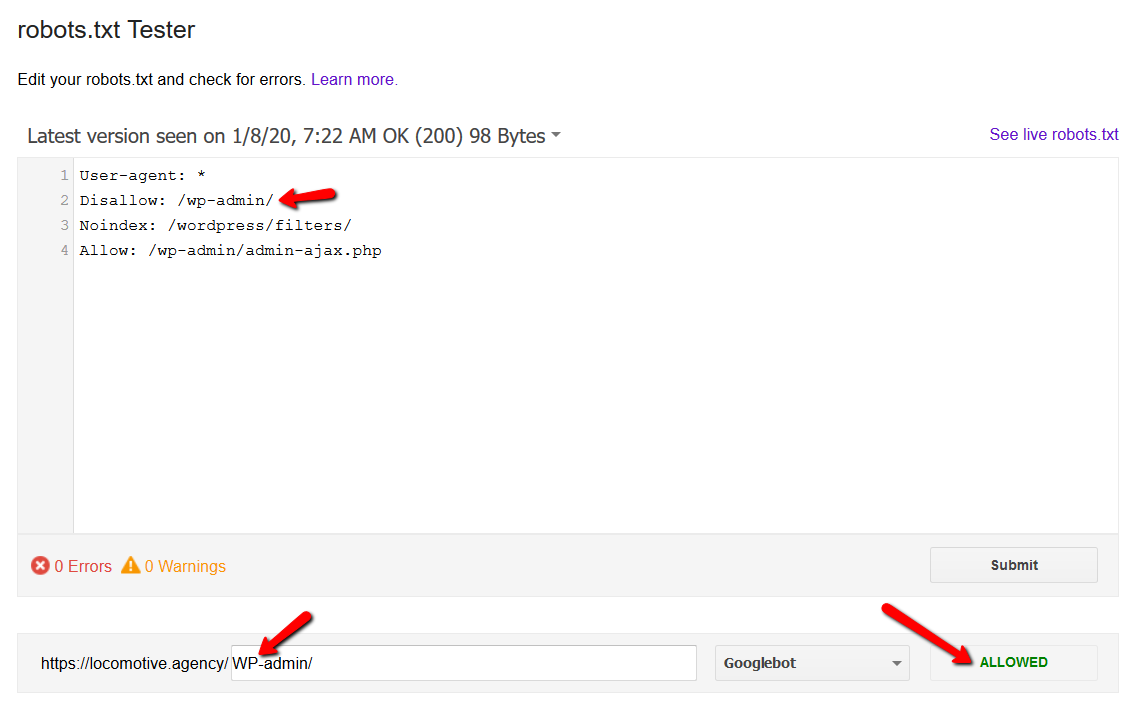
- Dyrektywa noindex: użycie noindex w pliku robots.txt będzie działać tak samo jak disallow. Google przestanie indeksować stronę, ale zachowa ją w swoim indeksie. @jroakes i ja stworzyliśmy test, w którym użyliśmy dyrektywy Noindex w artykule /wordpress/filters/ i przesłaliśmy stronę w Google. Na poniższym zrzucie ekranu widać, że pokazuje on, że adres URL został zablokowany:
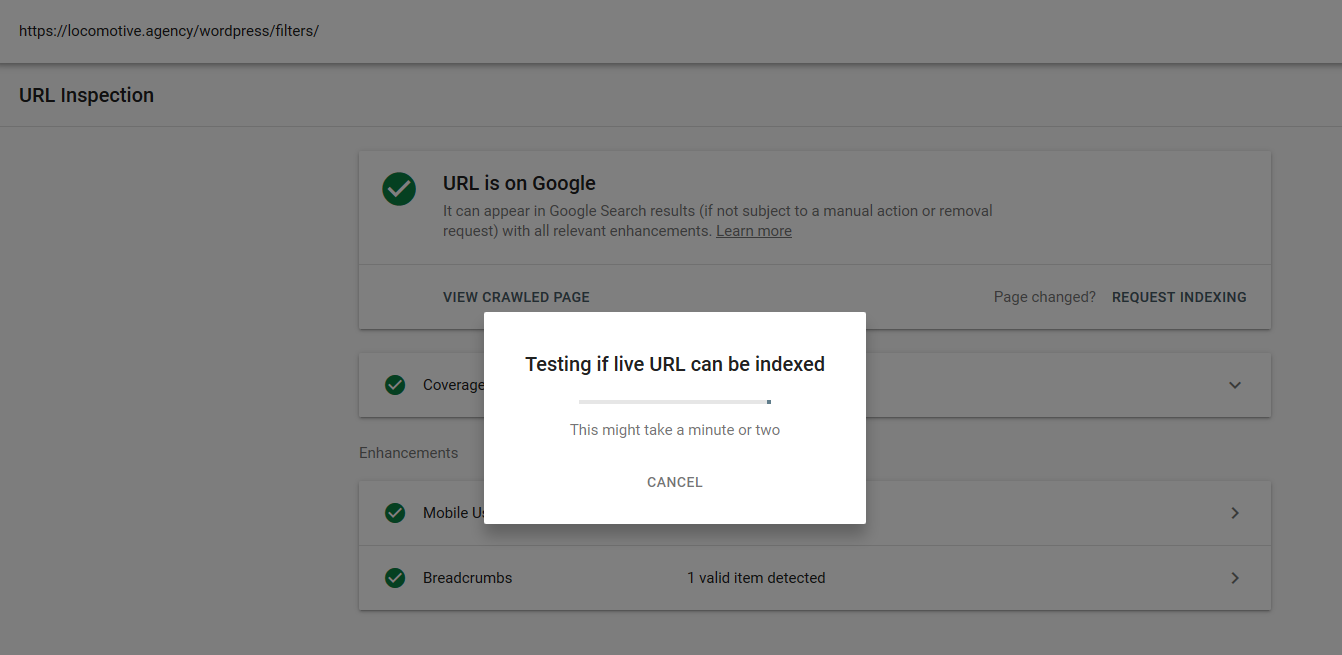
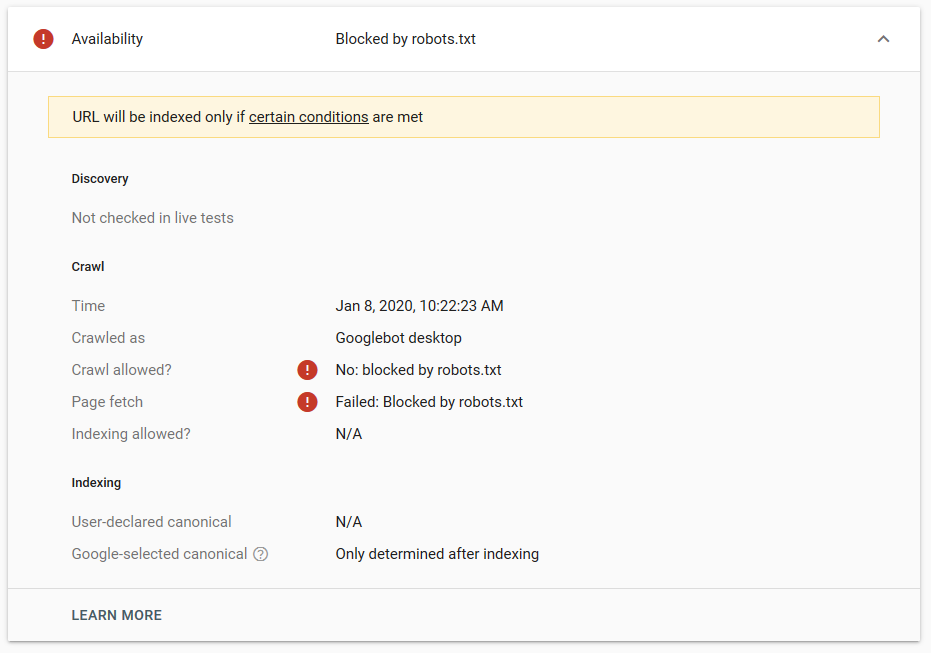
Przeprowadziliśmy kilka testów w Google i strona nigdy nie została usunięta z indeksu:

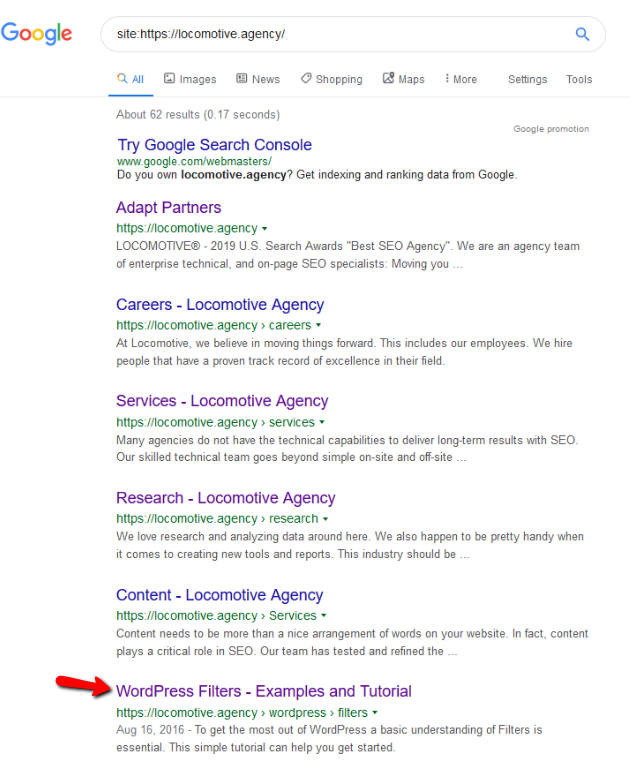
W zeszłym roku odbyła się dyskusja na temat dyrektywy noindex działającej w robots.txt, usuwającej strony, ale Google. Oto wątek, w którym Gary Illyes stwierdził, że to odchodzi. Na tym teście widzimy, że rozwiązanie Google jest na miejscu, ponieważ dyrektywa noindex nie usunęła strony z wyników wyszukiwania.
Niedawno na Twitterze pojawił się inny interesujący wątek od Christiana Oliveiry, w którym podzielił się kilkoma szczegółami, które należy wziąć pod uwagę podczas pracy nad plikiem robots.txt.
- Jeśli chcemy mieć ogólne reguły i reguły tylko dla Googlebota, musimy zduplikować wszystkie ogólne reguły w zestawie reguł User-agent: Google bot. Jeśli nie zostaną uwzględnione, Googlebot zignoruje wszystkie reguły:

- Innym mylącym zachowaniem jest to, że priorytet reguł (wewnątrz tej samej grupy User-Agent) nie jest określany przez ich kolejność, ale przez długość reguły.
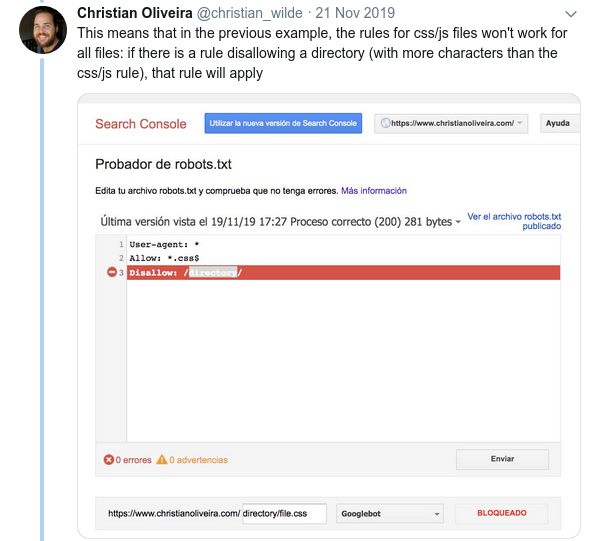
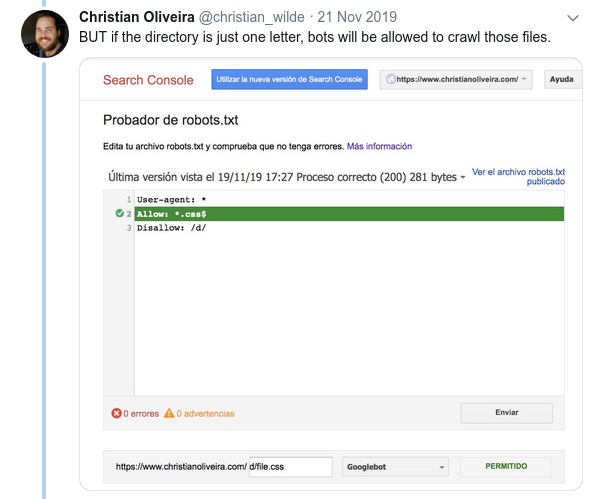
- Teraz, gdy masz dwie reguły o tej samej długości i odwrotnym zachowaniu (jedna zezwalająca na indeksowanie, a druga uniemożliwiająca), obowiązuje mniej restrykcyjna reguła:
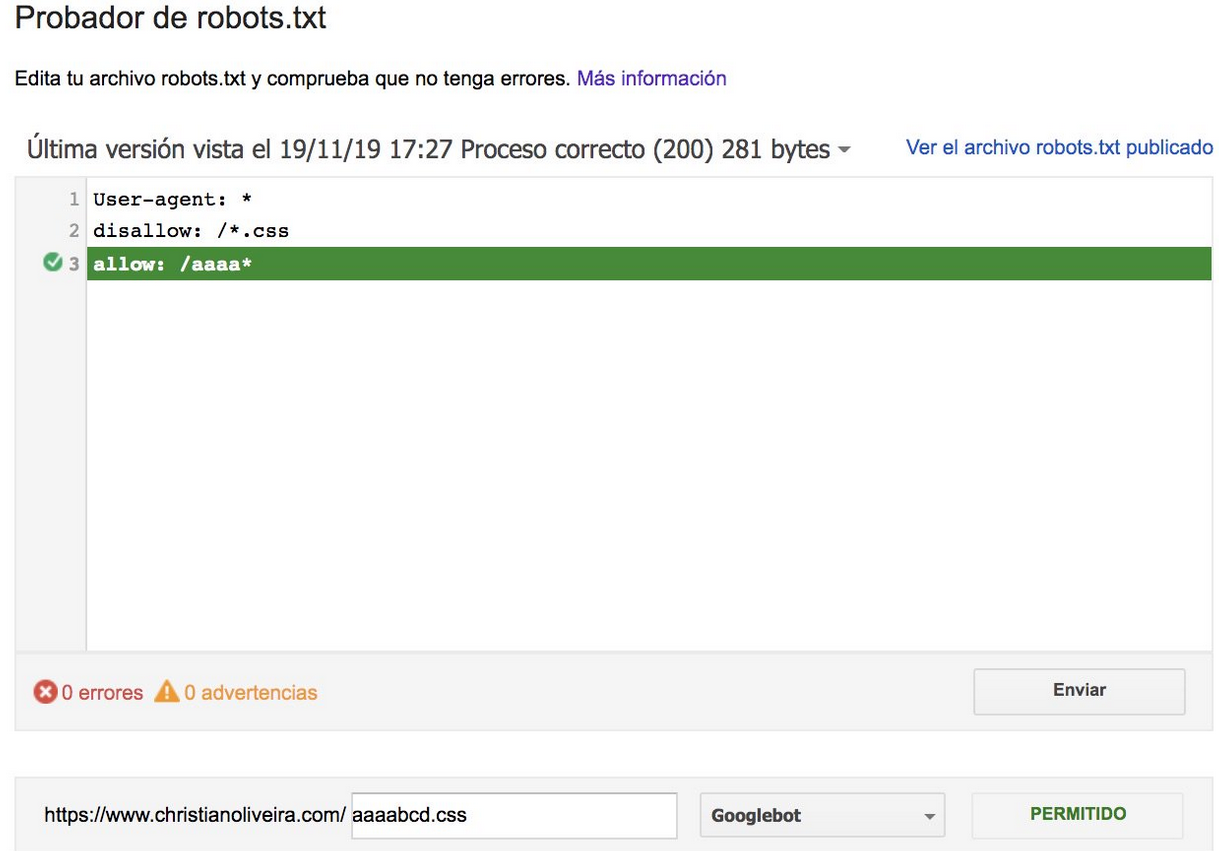
Więcej przykładów znajdziesz w specyfikacji robots.txt dostarczonej przez Google.
Narzędzia do testowania pliku Robots.txt
Jeśli chcesz przetestować swój plik robots.txt, istnieje kilka narzędzi, które mogą ci pomóc, a także kilka repozytoriów github, jeśli chcesz stworzyć własne:
- Destylowany
- Google pozostawił tutaj narzędzie testowe robots.txt ze starej Google Search Console
- Na Pythonie
- W C++
Przykładowe wyniki: efektywne wykorzystanie pliku Robots.txt w e-commerce
Poniżej zamieściłem przypadek, w którym pracowaliśmy z witryną Magento, która nie miała pliku robots.txt. Magento, podobnie jak inne CMS, ma strony administracyjne i katalogi z plikami, których Google nie ma indeksować. Poniżej zamieściliśmy przykład niektórych katalogów zawartych w pliku robots.txt:
# # Ogólne katalogi Magento Nie zezwalaj: / aplikacja / Nie zezwalaj: / downloader / Nie zezwalaj: / błędy / Nie zezwalaj: / zawiera / Nie zezwalaj: / lib / Odrzuć: /pkginfo/ Nie zezwalaj: / muszla / Odrzuć: / var / # # Nie indeksuj strony wyszukiwania i niezoptymalizowanych kategorii linków Nie zezwalaj: /katalog/porównanie_produktu/ Disallow: /katalog/kategoria/widok/ Disallow: /katalog/produkt/widok/ Disallow: /katalog/produkt/galeria/ Nie zezwalaj: /przeszukiwanie katalogów/
Ogromna liczba stron, które nie miały być indeksowane, miała wpływ na budżet indeksowania, a Googlebot nie mógł indeksować wszystkich stron produktów w witrynie.
Na poniższym obrazku widać, jak wzrosła liczba zindeksowanych stron po 25 października, kiedy to zaimplementowano plik robots.txt:
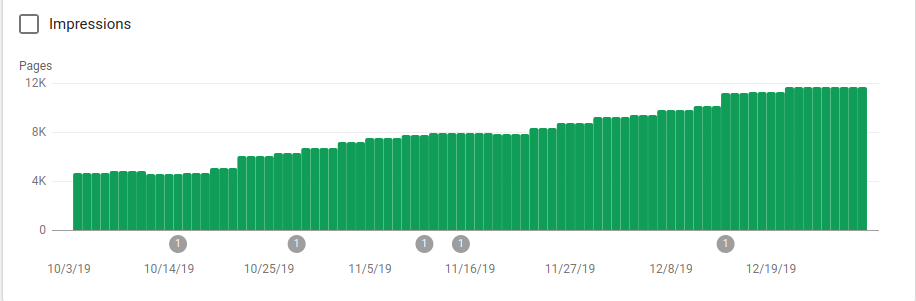
Oprócz blokowania kilku katalogów, które nie miały być indeksowane, roboty zawierały link do map witryn. Na poniższym zrzucie ekranu możesz zobaczyć, jak wzrosła liczba zindeksowanych stron w porównaniu z wykluczonymi stronami:
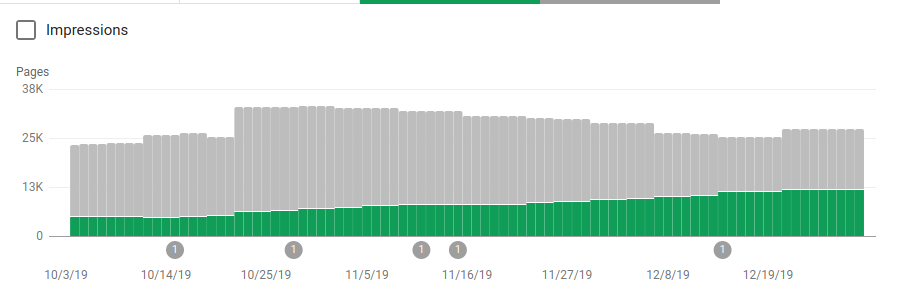
Istnieje pozytywny trend na zindeksowanych prawidłowych stronach, co pokazują zielone paski, a negatywny trend na wykluczonych stronach, które są reprezentowane przez szare paski.
Zawijanie
Czasami można nie docenić znaczenia pliku robots.txt, a jak widać z tego postu, przy jego tworzeniu należy wziąć pod uwagę wiele szczegółów. Ale praca się opłaca: pokazałem niektóre z pozytywnych wyników, jakie można uzyskać dzięki prawidłowemu skonfigurowaniu pliku robots.txt.