
Dlaczego przeszliśmy na przetwarzanie bezserwerowe, aby wdrażać niestandardowe kompilacje
Opublikowany: 2018-11-22
Zdjęcie autorstwa panumas nikhomkhai z Pexels
W ramach naszego zaangażowania w umożliwienie specjalistom ds. marketingu wydajności robienia więcej, mniej i bez zmartwień , zespoły TUNE zawsze poszukują nowych sposobów obsługi naszych klientów. W tym przypadku nasz zespół ds. inżynierii rozwiązań odkrył technologię, która upraszcza wdrażanie i obsługę niestandardowych kompilacji na naszej platformie. W rezultacie mogą teraz spędzać więcej czasu (i mniej pieniędzy) pracując z większą liczbą klientów w celu tworzenia potrzebnych im rozwiązań.
W TUNE jesteśmy dumni z tego, że dostarczamy elastyczną, wszechstronną platformę performance marketingu, która umożliwia sieciom i reklamodawcom zarządzanie ich kampaniami marketingu cyfrowego, relacjami z wydawcami, wypłatami i nie tylko — od razu po wyjęciu z pudełka, bez konieczności pisania nawet jednej linijki kodu . Ale czasami, tak jak w przypadku innych w pełni zarządzanych systemów SaaS, nasi klienci wymagają niestandardowych konfiguracji, funkcjonalności lub integracji, które można osiągnąć tylko przez zakasanie rękawów i uruchomienie starego edytora kodu. Niedawno przeszliśmy na nową technologię, która zmienia sposób budowania tych rozwiązań: przetwarzanie bezserwerowe.
W tym poście omówię problemy, które napotkaliśmy podczas opracowywania niestandardowego, kroki, które podjęliśmy, aby skonfigurować nasz proces kompilacji bezserwerowej, oraz sposób, w jaki ta nowa metodologia rozwiązuje problemy związane z kosztami i skalowaniem.
Wyzwanie: Nadążanie za zapotrzebowaniem na niestandardowe rozwiązania
Kiedy po raz pierwszy zakładaliśmy zespół ds. inżynierii rozwiązań w firmie TUNE, traktowaliśmy każdą niestandardową wersję klienta jako oddzielną wersję. Większość z tych kompilacji zawierała komponent front-end, który zwykle był wdrażany jako niestandardowa strona na naszej platformie, oraz komponent back-end, który składał się z serwera, bazy danych i wszelkiej innej infrastruktury wymaganej do utrzymania serwerów na bieżąco. -data i operacyjne.
Początkowo ta metodologia działała dla nas. Dzięki temu, że dysponujemy małym, szczupłym zespołem z kilkoma złożonymi, niestandardowymi kompilacjami, nasza metoda udostępniania i konfigurowania innego serwera dla każdej kompilacji sprawdziła się dla nas. Pozwoliło nam to na stworzenie niesamowitych wrażeń dla naszych klientów.
Ale wraz ze wzrostem liczby kompilacji zaczęliśmy napotykać problemy:
- Za dużo serwerów! Jak możesz sobie wyobrazić, udostępnienie co najmniej dwóch pudełek na kompilację doprowadziło do tego, że mamy zbyt wiele serwerów. Sama liczba serwerów i wszystkie związane z nimi problemy (takie jak aktualizacje zabezpieczeń i kopie zapasowe) kosztowały nas więcej czasu, niż chcielibyśmy przyznać.
- Utrzymuj te serwery w dobrym stanie. Ponieważ każdy serwer był osobną jednostką, byliśmy odpowiedzialni za upewnienie się, że każdy serwer jest zawsze aktywny i sprawny.
- PHP nie jest dla mnie. Większość naszych kompilacji jest tworzona z podstawowego obrazu Docker PHP. Jednak wraz z rozwojem naszego zespołu wiedzieliśmy, że zmuszanie ludzi do pisania kompilacji klientów w PHP 5.0, gdy byli kreatorami Pythona, nie ma żadnego sensu.
- To staje się drogie. Gdy wszystkie nasze serwery zostały wdrożone na ec2/RDS, zaczęliśmy dostrzegać znaczne miesięczne koszty.
- Bezpieczeństwo przede wszystkim. Ponieważ usługi te obsługiwały poufne dane klientów, musieliśmy zapewnić metodę uwierzytelniania naszych publicznych adresów URL, aby zapewnić bezpieczeństwo tych danych.
- Croni są twardzi. Wiele usług zaplecza składało się ze skryptów cron i nie mieliśmy skutecznego sposobu na zarządzanie nimi.
Gdy pojawiły się te wyzwania, wiedzieliśmy, że musimy znaleźć prostszy, bardziej opłacalny sposób na zapewnienie funkcjonalności zaplecza kompilacjom naszych klientów. Ale po długiej debacie i braku wyraźnego lidera w poszukiwaniu rozwiązania zaczynały nam brakować pomysłów. (Ponadto, ponieważ popyt na nowe niestandardowe konstrukcje rósł jak szalony, czas zdecydowanie nie był po naszej stronie.)
Rozwiązanie: obliczenia bezserwerowe na ratunek
Jeśli nie słyszałeś o przetwarzaniu bezserwerowym , możesz zastanawiać się nad tym samym, co my, gdy po raz pierwszy o tym usłyszeliśmy. Jak wykonać kod bez serwera? (Nie martw się; twoje podstawowe zrozumienie programowania jest nadal poprawne i nie, nie nadużyliśmy specjalnej oferty happy hour przed napisaniem tego).
„Serverless” to naprawdę mylące określenie nowej technologii, ponieważ — nie bądźmy niemądrzy — na pewno nadal istnieje serwer wykonujący kod. Czym właściwie jest serverless?
Przetwarzanie bezserwerowe to model wykonywania przetwarzania w chmurze, w którym dostawca chmury działa jako serwer, dynamicznie zarządzając alokacją zasobów maszynowych. – Wikipedia
Bezserwerowe rozwiązania chmurowe umożliwiają tworzenie i uruchamianie aplikacji i usług bez myślenia o kłopotach związanych z serwerami. Zasadniczo przetwarzanie bezserwerowe pozwala robić to, co robisz najlepiej: pisać kod.
Proces konfiguracji bezserwerowej
Aby pokazać, jak działa technologia bezserwerowa, omówię czynności, które wykorzystaliśmy do skonfigurowania tej funkcji.
Uwaga: istnieje wielu dostawców usług w chmurze z funkcją bezserwerową. W tym przykładzie używamy AWS Lambda .

- Najpierw utwórz nową funkcję Lambda i wybierz „ Plany ”. Następnie wpisz „ http ” w polu słowa kluczowego i wybierz mikroserwis-http-endpoint Pythona lub Node. (Projekty to gotowe bloki kodu, które mają przyspieszyć programowanie. Jak niesamowite jest to?) Po dokonaniu wyboru kliknij „ Konfiguruj ”.
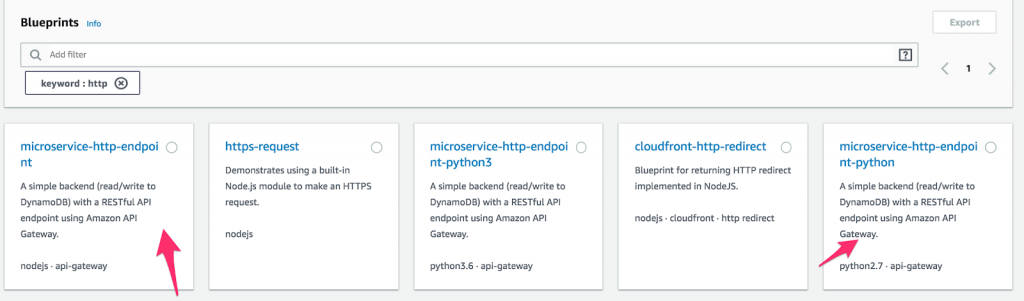
Jak skonfigurować funkcję w AWS Lambda.
- Dodaj nazwę i rolę funkcji. Następnie wybierz wyzwalacz bramy API z opcją zabezpieczeń „ Otwórz za pomocą klucza API ”. Ta brama API zapewni publiczny adres URL, który uruchomi funkcję Lambda. Dodanie klucza API zapewnia metodę uwierzytelniania, która jest wysoce zalecana.
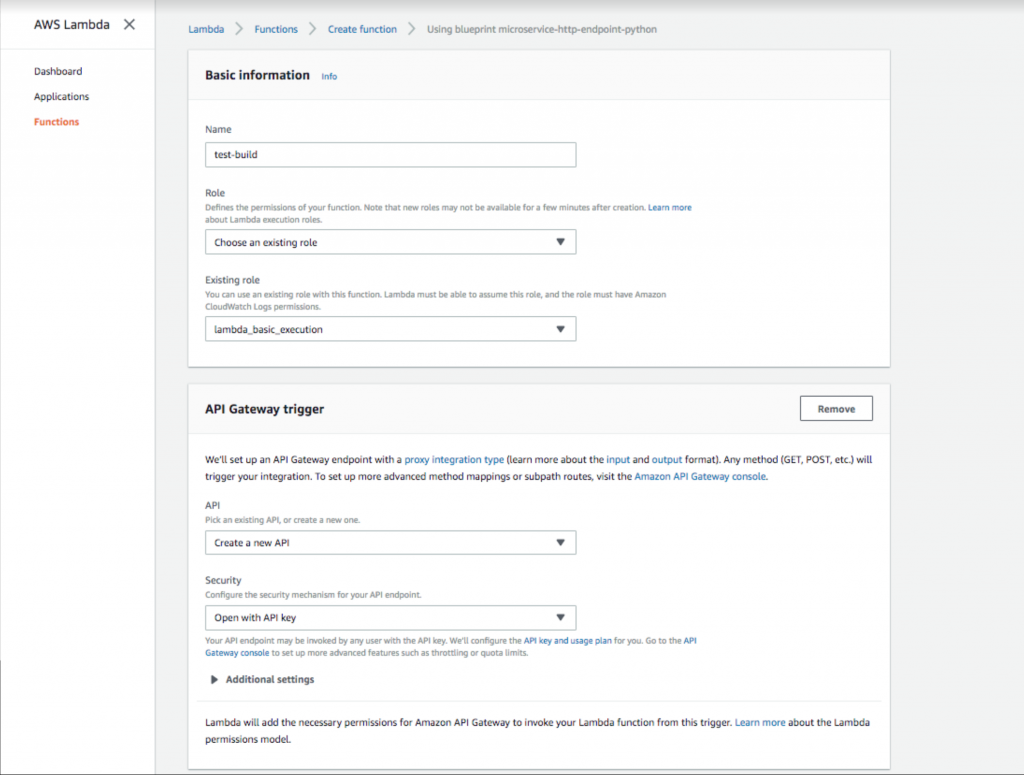
Konfigurowanie klucza otwartej bramy API w AWS Lambda.
- Po utworzeniu funkcji możesz teraz wprowadzać konfiguracje do swojego kodu. Jak widać, plan dał ci już fajny punkt wejścia, który pozwala na interakcję z tabelą Dynamo (jeśli chcesz dodać bazę danych). Cokolwiek znajduje się pod lambda_handler , zostanie wykonane po załadowaniu publicznego adresu URL. Ponieważ dodajemy również bazę danych, chodźmy do Dynamo i stwórzmy ją.
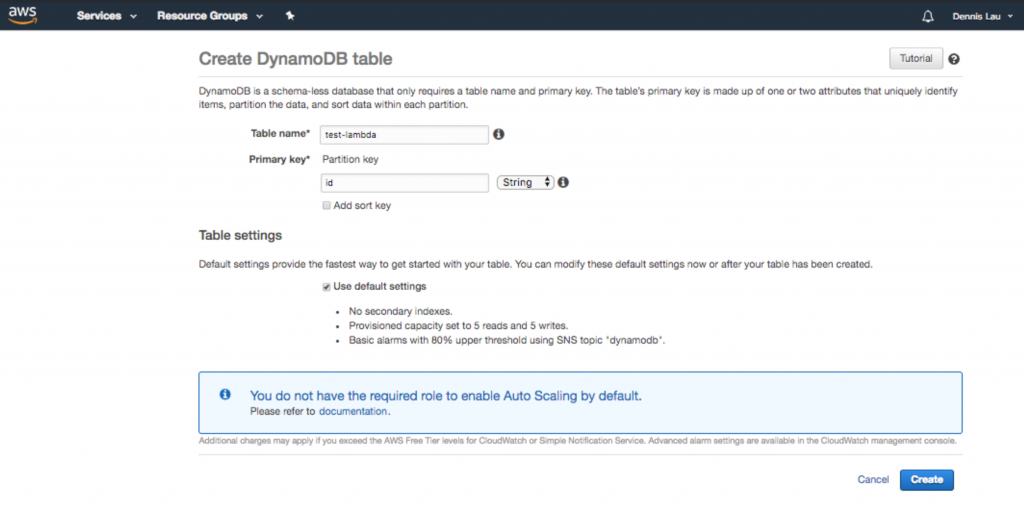
Tworzenie tabeli bazy danych Dynamo w AWS Lambda.
- Po utworzeniu tabeli Dynamo wykonajmy wywołanie tej funkcji Lambda z publicznego adresu URL. Wróć do swojej funkcji i kliknij ikonę „ API Gateway ” u góry. Powinieneś zobaczyć, że punkt końcowy i klucz API zostały już dla Ciebie utworzone.
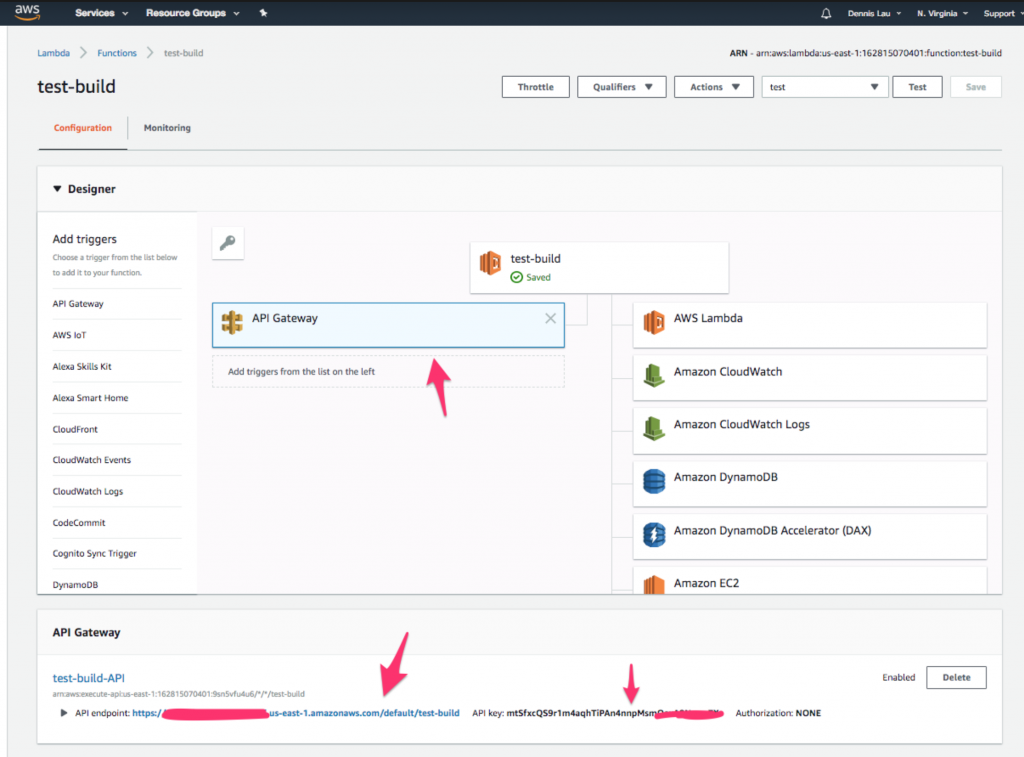
Gdzie znaleźć ikonę API Gateway w funkcjach AWS Lambda.
- Teraz otwórz terminal i dodaj klucz API pod nagłówkiem „ x-api-key” , a następnie dodaj nazwę tabeli, którą utworzyłeś w parametrze ciągu zapytania TableName .

Wpisz swój klucz i nazwę bazy danych w terminalu, aby zakończyć.
- Najpierw utwórz nową funkcję Lambda i wybierz „ Plany ”. Następnie wpisz „ http ” w polu słowa kluczowego i wybierz mikroserwis-http-endpoint Pythona lub Node. (Projekty to gotowe bloki kodu, które mają przyspieszyć programowanie. Jak niesamowite jest to?) Po dokonaniu wyboru kliknij „ Konfiguruj ”.
Otóż to! Masz teraz działający, bezpieczny back-end połączony z bazą danych. Wystarczyło pięć prostych kroków.
Jak przetwarzanie bezserwerowe rozwiązało nasze wyzwania?
Teraz, gdy pokazaliśmy, jak skonfigurować kompilacje bezserwerowe, przyjrzyjmy się i zobaczmy, jak ten model oparty na chmurze radzi sobie z naszą listą kontrolną problemów.
- Za dużo serwerów! Bezserwerowe… co oznacza koniec z serwerami, prawda?
- Utrzymuj te serwery w dobrym stanie. Ponieważ przetwarzanie bezserwerowe jest zarządzane przez dostawcę chmury, czerpiesz korzyści z posiadania tych dostawców (wraz z ich sprawdzonymi w walce, sprawdzonymi metodami) do monitorowania serwerów. Dla tych z Was, którzy chcą grać w Sherlocka Holmesa, możecie również zobaczyć wszystkie logi serwera, które są wyświetlane przez waszą funkcję w Cloudwatch .
- PHP nie jest dla mnie. Modele bezserwerowe umożliwiają pisanie w C#, Pythonie, NodeJS, Go, a nawet Javie.
- To staje się drogie. W przypadku rozwiązań bezserwerowych koszty są mierzone na podstawie czasu wykonania (na 100 milisekund) i ilości przesyłanych danych. W przeciwieństwie do miesięcznych opłat, które obejmują czas bezczynności serwerów, płacisz tylko za to, z czego korzystasz. Przy kosztach tak niskich, jak 0,000000208 USD na 100 ms wykonania, przetwarzanie bezserwerowe może zaoszczędzić znaczną część gotówki.
- Bezpieczeństwo przede wszystkim. Czy bezserwerowy jest bezpieczny? Dzięki wbudowanemu systemowi uwierzytelniania klucza API możesz się założyć, że tak.
- Croni są twardzi. Z systemem zarządzania cron natywnie zbudowanym na Cloudwatch, po prostu ustaw okno czasowe i zapomnij o nim. Cloudwatch obsługuje wszystkie rejestrowanie i wykonywanie.
Końcowe przemyślenia
Dla zespołu inżynierów rozwiązań w firmie TUNE przejście na przetwarzanie bezserwerowe było przełomem. Łatwość użytkowania, oszczędność kosztów i funkcje przyjazne zwinności zmieniły sposób, w jaki obsługujemy wszystkie nowe wersje klientów. Bezserwerowe rozwiązania oparte na chmurze mają zmienić świat przetwarzania po stronie serwera. Nie wiem jak wy, ale jedno jest pewne: zespół inżynierów TUNE Solutions jest gotowy.
Aby dowiedzieć się więcej o platformie TUNE i świadczonych przez nas niestandardowych usługach programistycznych, odwiedź naszą stronę Profesjonalne usługi .