
7 błędów SEO widocznych na wolności (i jak ich uniknąć)
Opublikowany: 2022-06-12
Często otrzymujemy pytania od osób, które zastanawiają się, dlaczego ich witryna nie znajduje się w rankingu lub dlaczego nie jest indeksowana przez wyszukiwarki.
Ostatnio natknąłem się na kilka stron z poważnymi błędami, które można by łatwo naprawić, gdyby tylko właściciele wiedzieli, że to zajrzy. Chociaż niektóre błędy SEO są dość złożone, oto kilka często pomijanych błędów związanych z „trzaskaniem głową”.
Sprawdź więc te błędy SEO — i jak możesz ich uniknąć.
SEO Fail #1: Problemy z plikiem robots.txt
Plik robots.txt ma dużą moc. Instruuje roboty wyszukiwarek, co mają wykluczyć ze swoich indeksów.
W przeszłości widziałem, jak witryny zapominają o usunięciu jednego wiersza kodu z tego pliku po przeprojektowaniu witryny i umieszczają całą witrynę w wynikach wyszukiwania.
Kiedy więc witryna z kwiatami zwróciła uwagę na problem, zaczęłam od jednej z pierwszych sprawdzeń, jakie zawsze wykonuję w witrynie — spójrz na plik robots.txt.
Chciałem wiedzieć, czy plik robots.txt witryny blokuje wyszukiwarkom indeksowanie ich treści. Ale zamiast oczekiwanego pliku tekstowego zobaczyłem stronę oferującą dostarczenie kwiatów do Robots.Txt.
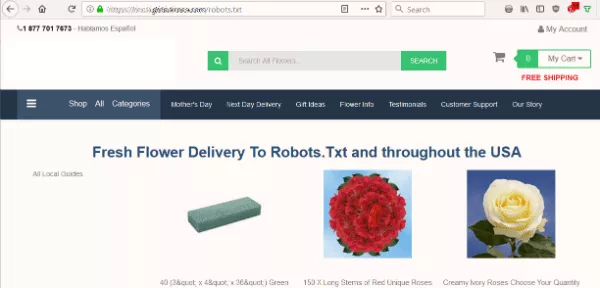
Witryna nie zawierała pliku robots.txt, który jest pierwszą rzeczą, której szuka bot podczas indeksowania witryny. To był ich pierwszy błąd. Ale wziąć ten plik jako miejsce docelowe… naprawdę?
SEO Fail #2: Autogeneracja oszalała
Po drugie, witryna automatycznie generowała nonsensowne treści. Prawdopodobnie dostarczyłby do Świętego Mikołaja lub innego tekstu, który umieściłem w adresie URL.
Uruchomiłem narzędzie Sprawdź stronę serwera, aby zobaczyć, jaki stan wyświetlała automatycznie wygenerowana strona. Gdyby to był błąd 404 (nie znaleziono), boty zignorowałyby stronę tak, jak powinny. Jednak nagłówek serwera strony wyświetlał stan 200 (OK). W rezultacie fałszywe strony dawały wyszukiwarkom zielone światło do indeksowania.
Wyszukiwarki chcą widzieć unikalne i znaczące treści na stronie. Tak więc indeksowanie tych stron niebędących stronami może zaszkodzić ich SEO.
SEO Fail 3: Błędy kanoniczne
Następnie sprawdziłem, co wyszukiwarki myślą o tej witrynie. Czy mogą przeszukiwać i indeksować strony?
Patrząc na kod źródłowy różnych stron zauważyłem kolejny poważny błąd.
Każda strona zawierała link kanoniczny wskazujący na stronę główną:
<link rel="canonical" href="https://www.domain.com/" />
Innymi słowy, wyszukiwarkom mówiono, że każda strona jest w rzeczywistości kopią strony głównej. Na podstawie tego tagu boty powinny ignorować pozostałe strony w tej domenie.
Na szczęście Google jest wystarczająco sprytny, aby dowiedzieć się, kiedy te tagi są prawdopodobnie używane przez pomyłkę. Więc nadal indeksował niektóre strony witryny. Ale ta uniwersalna kanoniczna prośba nie pomogła SEO witryny.
Jak uniknąć tych błędów SEO?
W przypadku wielu błędów witryny z kwiatami, oto poprawki:
- Przygotuj prawidłowy plik robots.txt, aby poinformować wyszukiwarki, jak przeszukiwać i indeksować witrynę. Nawet jeśli jest to pusty plik, powinien istnieć w katalogu głównym Twojej domeny.
- Wygeneruj odpowiedni element linku kanonicznego dla każdej strony. I nie odsuwaj strony, którą chcesz zindeksować.
- Wyświetlaj niestandardową stronę 404, gdy adres URL strony nie istnieje. Upewnij się, że zwraca kod serwera 404, aby dać wyszukiwarkom jasny komunikat.
- Uważaj na strony generowane automatycznie. Unikaj tworzenia nonsensownych lub duplikatów stron dla wyszukiwarek i użytkowników.
Nawet jeśli nie masz problemów z witryną, warto okresowo sprawdzać te kwestie, na wszelki wypadek.
Aha, i nigdy nie umieszczaj tagu kanonicznego na swojej stronie 404 , zwłaszcza wskazującej na swoją stronę główną… po prostu tego nie rób.
SEO Fail #4: Overnight Rankingi Freefall
Czasami prosta zmiana może być kosztownym błędem. Ta historia pochodzi z doświadczenia z jednym z naszych klientów SEO.
Kiedy rozszerzenie .org ich nazwy domeny stało się dostępne, zdobyli je. Na razie w porządku. Ale ich następny ruch doprowadził do katastrofy.
Natychmiast utworzyli przekierowanie 301 kierujące nowo nabytą domenę .org do ich głównej witryny .com. Ich rozumowanie miało sens — aby uchwycić krnąbrnych użytkowników, którzy mogą wpisać niewłaściwe rozszerzenie.
Ale następnego dnia zadzwonili do nas szaleńczo. Ich ruch w witrynie nie istniał. Nie mieli pojęcia dlaczego.
Kilka szybkich kontroli wykazało, że ich rankingi wyszukiwania zniknęły z Google z dnia na dzień. Nie trzeba było zbyt wielu pytań i odpowiedzi, aby dowiedzieć się, co się stało.
Wprowadzają przekierowanie, nie biorąc pod uwagę ryzyka. Poszperaliśmy trochę i odkryliśmy, że .org ma podłą przeszłość.

Poprzedni właściciel witryny .org używał jej do spamowania. Wraz z przekierowaniem Google przypisywał całą tę truciznę do głównej witryny firmy! Przywrócenie pozycji strony w Google zajęło nam tylko dwa dni.
Jak uniknąć tego niepowodzenia SEO?
Zawsze sprawdzaj profil linków i historię każdej nazwy domeny, pod którą się zarejestrujesz.
Wykwalifikowany konsultant SEO może to zrobić. Istnieją również narzędzia, które możesz uruchomić, aby zobaczyć, jakie szkielety mogą leżeć w szafie witryny.
Za każdym razem, gdy wybieram nową domenę, lubię pozostawić ją w stanie uśpienia na co najmniej sześć miesięcy do roku, zanim spróbuję coś z tego zrobić. Chcę, aby wyszukiwarki wyraźnie odróżniały nowe wcielenie mojej witryny od jej poprzedniego życia. To dodatkowy środek ostrożności, który chroni Twoją inwestycję.
Porażka SEO nr 5: Strony, które nie znikną
Czasami witryny mogą mieć inny problem — zbyt wiele stron w indeksie wyszukiwania.
Wyszukiwarki czasami zachowują strony, które nie są już ważne. Jeśli użytkownicy trafiają na strony błędów po przejściu z wyników wyszukiwania, jest to złe wrażenia użytkownika.
Niektórzy właściciele witryn z frustracji podają poszczególne adresy URL w pliku robots.txt. Mają nadzieję, że Google zrozumie podpowiedź i przestanie je indeksować.
Ale to podejście zawodzi! Jeśli Google respektuje plik robots.txt, nie będzie indeksować tych stron. Tak więc Google nigdy nie zobaczy stanu 404 i nie dowie się, że strony są nieprawidłowe.
Jak uniknąć tego błędu SEO?
Pierwsza część poprawki polega na tym, aby nie blokować tych adresów URL w pliku robots.txt. CHCESZ, aby boty się czołgały i wiedziały, jakie adresy URL powinny zostać usunięte z indeksu wyszukiwania.
Następnie skonfiguruj przekierowanie 301 na starym adresie URL. Wyślij odwiedzającego (i wyszukiwarki) na najbliższą stronę zastępczą w witrynie. To dba o odwiedzających, niezależnie od tego, czy pochodzą z wyszukiwania, czy z bezpośredniego linku.
Porażka SEO nr 6: Utracony kapitał linków
Skorzystałem z łącza ze strony internetowej uniwersytetu i zostałem powitany błędem 404 (nie znaleziono).
Nie jest to niczym niezwykłym, z wyjątkiem tego, że łącze prowadziło do /home.html — poprzedniego adresu URL strony głównej witryny.
W pewnym momencie musieli zmienić architekturę swojej witryny i usunąć stary /home.html, tracąc przekierowanie w shuffle.
Jak na ironię, ich strona 404 mówi, że możesz zacząć od strony głównej, do której starałem się dotrzeć w pierwszej kolejności.
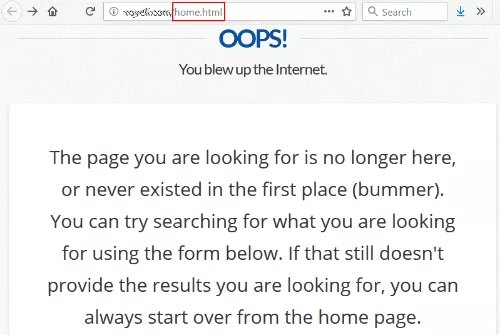
Można się założyć, że ta strona chciałaby mieć ładny link od szanowanego uniwersytetu do ich strony głównej. A osiągnięcie tego jest całkowicie pod ich kontrolą. Nie muszą nawet kontaktować się z witryną z linkami.
Jak naprawić tę awarię?
Aby naprawić ten link, wystarczy umieścić przekierowanie 301 wskazujące /home.html na bieżącą stronę główną. (Zobacz nasz artykuł o tym, jak skonfigurować przekierowanie 301, aby uzyskać instrukcje).
Aby uzyskać dodatkowe środki, przejdź do Google Search Console i przejrzyj Raport stanu pokrycia indeksów. Przyjrzyj się wszystkim stronom, które są zgłaszane jako zwracające błąd 404, i pracuj nad naprawieniem jak największej liczby błędów.
Porażka SEO nr 7: niepowodzenie kopiowania/wklejania
Rozpoczyna się przeprojektowanie witryny, tagi kanoniczne są gotowe, a nowy Menedżer tagów Google jest zainstalowany. Jednak nadal istnieją problemy z rankingiem. W rzeczywistości jedna nowa strona docelowa nie wyświetla żadnych użytkowników w Google Analytics.
Zespół programistów odpowiada, że zrobili wszystko zgodnie z książką i poszli za przykładami co do joty.
Mają dokładnie rację. Poszli za przykładami — włączając w to pozostawienie w przykładowym kodzie! Po skopiowaniu i wklejeniu programiści zapomnieli wprowadzić informacje o własnej witrynie docelowej.
Oto trzy przykłady, na które nasi analitycy natknęli się w kodzie witryny:
- <link rel="canonical" href="http://example.com/">
- 'analyticsAccountNumber': 'UA-123456-1'
- _gaq.push(['_setAccount', 'UA-000000-1']);
Jak uniknąć tego niepowodzenia SEO?
Kiedy coś nie działa dobrze, spójrz poza tylko „czy ten element w kodzie źródłowym?” Może się zdarzyć, że w kodzie HTML nigdy nie zostały określone prawidłowe kody weryfikacyjne, numery kont i adresy URL.
Błędy się zdarzają, a ludzie są tylko ludźmi. Mam nadzieję, że te przykłady pomogą Ci uniknąć podobnych błędów SEO. Na Twoją korzyść opracowaliśmy szczegółowy przewodnik po SEO, w którym znajdziesz wskazówki i najlepsze praktyki SEO.
Ale niektóre kwestie SEO są bardziej złożone niż myślisz. Jeśli masz problemy z indeksowaniem, służymy pomocą. Zadzwoń do nas lub wypełnij formularz, a skontaktujemy się z Tobą.
Polub ten post? Zasubskrybuj naszego bloga, aby nowe posty były dostarczane do Twojej skrzynki odbiorczej.