
Semantyczne grupowanie słów kluczowych w Pythonie
Opublikowany: 2021-04-19W świecie pełnym cyfrowych mitów marketingowych wierzymy, że wymyślanie praktycznych rozwiązań codziennych problemów jest tym, czego potrzebujemy.
W PEMAVOR zawsze dzielimy się naszą wiedzą i doświadczeniem, aby zaspokoić potrzeby entuzjastów marketingu cyfrowego. Dlatego często publikujemy bezpłatne skrypty Pythona, które pomogą Ci zwiększyć ROI.
Nasze klastrowanie słów kluczowych SEO w Pythonie utorowało drogę do uzyskania nowych spostrzeżeń dla dużych projektów SEO, z zaledwie mniej niż 50 wierszami kodu Pythona.
Ideą tego skryptu było umożliwienie grupowania słów kluczowych bez płacenia „wygórowanych opłat”… cóż, wiemy, kto…
Ale zdaliśmy sobie sprawę, że ten skrypt sam w sobie nie wystarczy. Potrzebny jest inny skrypt, abyście mogli lepiej zrozumieć swoje słowa kluczowe: musicie być w stanie „ pogrupować słowa kluczowe według znaczenia i relacji semantycznych”. ”
Teraz nadszedł czas, aby zrobić krok dalej w Pythonie dla SEO .
Dane dotyczące indeksowania³
 Ucz się więcej
Ucz się więcejTradycyjny sposób grupowania semantycznego
Jak wiecie, tradycyjną metodą semantyki jest budowanie modeli word2vec , a następnie grupowanie słów kluczowych za pomocą funkcji Word Mover's Distance .
Ale te modele wymagają dużo czasu i wysiłku, aby je zbudować i trenować. Dlatego chcielibyśmy zaoferować Państwu prostsze rozwiązanie. 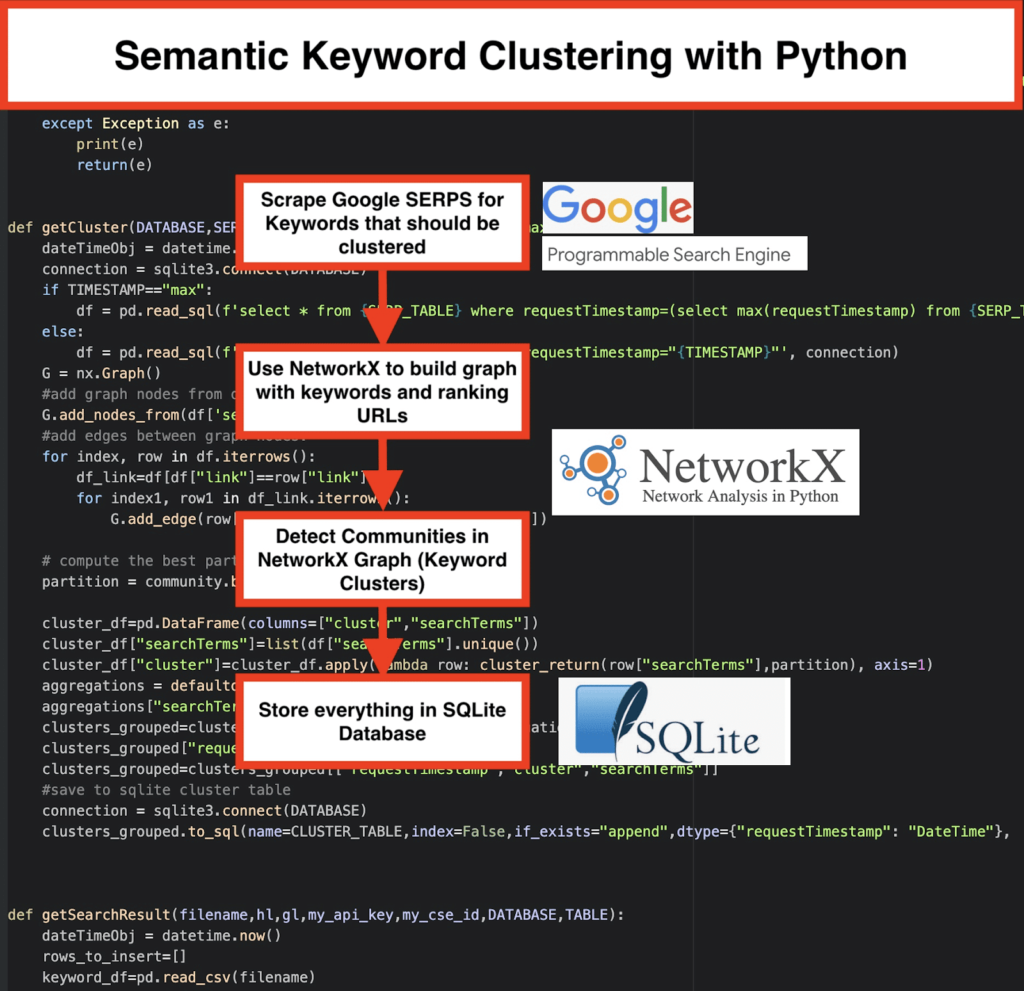
Wyniki Google SERP i odkrywanie semantyki
Google korzysta z modeli NLP, aby oferować najlepsze wyniki wyszukiwania. To jak otwieranie puszki Pandory, a my dokładnie o tym nie wiemy.
Jednak zamiast budować nasze modele, możemy użyć tego pola do pogrupowania słów kluczowych według ich semantyki i znaczenia.
Oto jak to robimy:
️ Najpierw wymyśl listę słów kluczowych dla danego tematu.
️ Następnie zeskrob dane SERP dla każdego słowa kluczowego.
️ Następnie tworzony jest wykres z zależnością między stronami rankingowymi a słowami kluczowymi.
️ Dopóki te same strony są wyświetlane w rankingu dla różnych słów kluczowych, oznacza to, że są ze sobą powiązane. Jest to podstawowa zasada tworzenia semantycznych klastrów słów kluczowych.
Czas złożyć wszystko w całość w Pythonie
Skrypt Pythona oferuje następujące funkcje:
- Korzystając z niestandardowej wyszukiwarki Google, pobierz SERP dla listy słów kluczowych. Dane są zapisywane w bazie danych SQLite . Tutaj powinieneś skonfigurować niestandardowy interfejs API wyszukiwania.
- Następnie skorzystaj z bezpłatnego limitu 100 żądań dziennie. Ale oferują również płatny plan za 5 USD za 1000 zadań, jeśli nie chcesz czekać lub masz duże zbiory danych.
- Lepiej wybrać rozwiązania SQLite, jeśli nie spieszysz się – wyniki SERP będą dołączane do tabeli przy każdym uruchomieniu. (Po prostu weź nową serię 100 słów kluczowych, gdy następnego dnia będziesz mieć limit).
- Tymczasem musisz ustawić te zmienne w skrypcie Python .
- CSV_FILE=”keywords.csv” => zapisz tutaj swoje słowa kluczowe
- JĘZYK = „en”
- KRAJ = „pl”
- KLUCZ_API=”xxxxxxx”
- CSE_ID="xxxxxxx"
- Uruchomienie
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)spowoduje zapisanie wyników SERP w bazie danych. - Klastrowanie jest realizowane przez siećx i moduł wykrywania społeczności. Dane są pobierane z bazy danych SQLite – klastrowanie jest wywoływane za pomocą
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - Wyniki klastrowania można znaleźć w tabeli SQLite — o ile nie zmienisz, domyślna nazwa to „keyword_clusters”.
Poniżej zobaczysz pełny kod:
# Semantyczne grupowanie słów kluczowych przez Pemavor.com
# Autor: Stefan Neefischer (stefan.neefischer@gmail.com)
z googleapiclient.discovery importuj kompilację
importuj pandy jako PD
importuj Levenshtein
from datetime import datetime
z fuzzywuzzy importuj fuzz
z urllib.parse import urlparse
z importu tld get_tld
importuj langid
importuj json
importuj pandy jako PD
importuj numer jako np
importuj siećx jako nx
importuj społeczność
importuj sqlite3
importuj matematykę
importuj
z kolekcji importuj defaultdict
def cluster_return (termin wyszukiwania, partycja):
zwróć partycję[searchTerm]
def language_detection(str_lan):
lan=langid.classify(str_lan)
zwróć lan[0]
def extract_domain(url, remove_http=True):
uri = parsowanie url(adres URL)
jeśli usuń_http:
nazwa_domeny = f"{uri.netloc}"
w przeciwnym razie:
nazwa_domeny = f"{uri.netloc}://{uri.netloc}"
zwróć nazwę_domeny
def extract_mainDomain(url):
res = get_tld(url, as_object=True)
powrót res.fld
def współczynnik_rozmyty(str1,str2):
return fuzz.ratio(str1,str2)
def fuzzy_token_set_ratio(str1,str2):
zwróć fuzz.token_set_ratio(str1,str2)
def google_search(search_term, api_key, cse_id,hl,gl, **kwargs):
próbować:
service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False)
res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute()
zwrot res
z wyjątkiem Wyjątku, jak e:
druk(e)
zwrot(e)
def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs):
próbować:
service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False)
res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute()
zwrot res
z wyjątkiem Wyjątku, jak e:
druk(e)
zwrot(e)
def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"):
dateTimeObj = datetime.now()
połączenie = sqlite3.connect(BAZA DANYCH)
jeśli TIMESTAMP=="max":
df = pd.read_sql(f'select * from {SERP_TABLE} gdzie requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', połączenie)
w przeciwnym razie:
df = pd.read_sql(f'wybierz * z {SERP_TABLE} gdzie requestTimestamp="{TIMESTAMP}"', połączenie)
G = nx.Wykres()
#dodaj węzły wykresu z kolumny dataframe
G.add_nodes_from(df['searchTerms'])
#dodaj krawędzie między węzłami grafu:
dla indeksu wiersz w df.iterrows():
df_link=df[df["link"]==wiersz["link"]]
dla index1, row1 w df_link.iterrows():
G.add_edge(row["searchTerms"], row1['searchTerms'])
# oblicz najlepszą partycję dla społeczności (klastrów)
partycja = społeczność.best_partition(G)
cluster_df=pd.DataFrame(kolumny=["klaster","terminy wyszukiwania"])
cluster_df["searchTerms"]=list(df["searchTerms"].unique())
cluster_df["cluster"]=cluster_df.apply(lambda wiersz: cluster_return(row["searchTerms"],partycja), oś=1)
agregacje = defaultdict()
agregacje["searchTerms"]=' | '.Przystąp
clusters_grouped=cluster_df.groupby("klaster").agg(agregacje).reset_index()
clusters_grouped["requestTimestamp"]=dataTimeObj
clusters_grouped=clusters_grouped[["sygnatura czasowa żądania","klaster","warunki wyszukiwania"]]
#zapisz w tabeli klastrów sqlite
połączenie = sqlite3.connect(BAZA DANYCH)
clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection)
def getSearchResult(nazwa pliku,hl,gl,moj_klucz_api,moj_id_cse,BAZA DANYCH,TABELA):
dateTimeObj = datetime.now()
rows_to_insert=[]
słowo kluczowe_df=pd.read_csv(nazwa pliku)
słowa kluczowe=słowo_kluczowe_df.iloc[:,0].tolist()
dla zapytania w słowach kluczowych:
jeśli hl=="domyślnie":
wynik = google_search_default_language(zapytanie, my_api_key, my_cse_id,gl)
w przeciwnym razie:
wynik = google_search(zapytanie, my_api_key, my_cse_id,hl,gl)
jeśli w wyniku „elementy” i „zapytania” w wyniku :
dla pozycji w zakresie(0,len(wynik["elementy"])):
wynik["elementy"][pozycja]["pozycja"]=pozycja+1
wynik["items"][pozycja]["main_domain"]= extract_mainDomain(result["items"][pozycja]["link"])
wynik["items"][pozycja]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][pozycja]["tytuł"],zapytanie)
wynik["items"][pozycja]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][pozycja]["snippet"],query)
wynik["items"][pozycja]["title_matchScore_order"]=fuzzy_ratio(result["items"][pozycja]["tytuł"],zapytanie)
wynik["items"][pozycja]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][pozycja]["snippet"],query)
wynik["items"][pozycja]["snipped_language"]=language_detection(result["items"][pozycja]["snippet"])
dla pozycji w zakresie(0,len(wynik["elementy"])):
rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl,
"totalResults":result["zapytania"]["request"][0]["totalResults"],"link":result["items"][position]["link"],
"displayLink":result["elementy"][pozycja]["displayLink"],"main_domain":result["items"][position]["main_domain"],
"pozycja":wynik["elementy"][pozycja]["pozycja"],"snippet":wynik["elementy"][pozycja]["fragment"],
"snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"],
"snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["tytuł"],
"title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"],
})
df=pd.DataFrame(wiersze_do_wstawienia)
#zapisz wyniki serp w bazie danych sqlite
połączenie = sqlite3.connect(BAZA DANYCH)
df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection)
################################################## ################################################## ##########################################
#Przeczytaj mnie: #
################################################## ################################################## ##########################################
#1- Musisz skonfigurować niestandardową wyszukiwarkę Google. #
# Podaj klucz API i SearchId. #
# Ustaw również swój kraj i język, w którym chcesz monitorować wyniki SERP. #
# Jeśli nie masz jeszcze klucza API i identyfikatora wyszukiwania, #
# możesz wykonać czynności opisane w sekcji Wymagania wstępne na tej stronie https://developers.google.com/custom-search/v1/overview#prerequisites #
# #
#2- Musisz również wprowadzić nazwy bazy danych, tabeli serp i tabel klastrów, które będą używane do zapisywania wyników. #
# #
#3- wprowadź nazwę pliku csv lub pełną ścieżkę zawierającą słowa kluczowe, które będą używane dla serp #
# #
#4- W przypadku grupowania słów kluczowych wprowadź znacznik czasu dla wyników serp, które będą używane do grupowania. #
# Jeśli chcesz zgrupować ostatnie wyniki serpów, wpisz „max” jako znacznik czasu. #
# lub możesz wpisać konkretny znacznik czasu, np. „2021-02-18 17:18:05.195321” #
# #
#5- Przeglądaj wyniki przez przeglądarkę DB dla programu Sqlite #
################################################## ################################################## ##########################################
#nazwa pliku csv ze słowami kluczowymi dla serp
CSV_FILE="słowa kluczowe.csv"
# określ język
JĘZYK = "pl"
#określ miasto
KRAJ = "pl"
#google custom search json api key
API_KEY="WPROWADŹ KLUCZ TUTAJ"
#Identyfikator wyszukiwarki
CSE_
#sqlite nazwa bazy danych
DATABASE="słowa kluczowe.db"
#nazwa tabeli, aby zapisać w niej wyniki serp
SERP_TABLE="keywords_serps"
# uruchom serp dla słów kluczowych
getSearchResult(CSV_FILE,JĘZYK,KRAJ,API_KEY,CSE_ID,BAZA DANYCH,SERP_TABLE)
#nazwa tabeli, w której zostaną zapisane wyniki klastra.
CLUSTER_TABLE = "klastry_słów kluczowych"
#Wprowadź znacznik czasu, jeśli chcesz utworzyć klastry dla określonego znacznika czasu
#Jeżeli chcesz utworzyć klastry dla ostatniego wyniku serpa, wyślij go z wartością "max"
#TIMESTAMP="18.02.2021 17:18:05.195321"
TIMESTAMP="max"
#uruchom klastry słów kluczowych zgodnie z sieciami i algorytmami społeczności
getCluster(BAZA DANYCH,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)
Wyniki Google SERP i odkrywanie semantyki
Mamy nadzieję, że spodobał Ci się ten skrypt ze skrótem do grupowania słów kluczowych w semantyczne klastry bez polegania na modelach semantycznych. Ponieważ modele te są często zarówno złożone, jak i kosztowne, ważne jest, aby przyjrzeć się innym sposobom identyfikowania słów kluczowych, które mają wspólne właściwości semantyczne.
Traktując razem powiązane semantycznie słowa kluczowe, możesz lepiej zajmować się tematem, lepiej łączyć ze sobą artykuły w swojej witrynie i zwiększać pozycję witryny w danym temacie.